
About The Author
Lyza Danger Gardner è una dev. Da quando ha co-fondato la startup Cloud Four di Portland, nell’Oregon, nel 2007, si è torturata ed entusiasmata con la …More aboutLyza↬
- 23 min read
- Coding,JavaScript,Tecniche,Service Workers
- Salvato per lettura offline
- Condividi su Twitter, LinkedIn


Non c’è scarsità di entusiasmo per la neonata API dei service worker, ora disponibile in alcuni browser popolari. Ci sono libri di cucina e post di blog, frammenti di codice e strumenti. Ma trovo che quando voglio imparare a fondo un nuovo concetto web, rimboccarmi le proverbiali maniche, immergermi e costruire qualcosa da zero è spesso l’ideale.
Gli urti e i lividi, gli intoppi e i bug in cui mi sono imbattuto questa volta hanno dei benefici: Ora capisco molto meglio i service worker, e con un po’ di fortuna posso aiutarvi ad evitare alcuni dei mal di testa che ho incontrato lavorando con la nuova API.
I service worker fanno un sacco di cose diverse; ci sono miriadi di modi per sfruttare i loro poteri. Ho deciso di costruire un semplice service worker per il mio sito web (statico, non complicato) che rispecchia approssimativamente le caratteristiche che l’obsoleta Application Cache API forniva – cioè:
- fare funzionare il sito web offline,
- aumentare le prestazioni online riducendo le richieste di rete per certe risorse,
- fornire un’esperienza di fallback offline personalizzata.
Prima di iniziare, vorrei riconoscere due persone il cui lavoro ha reso possibile tutto questo. In primo luogo, sono enormemente in debito con Jeremy Keith per l’implementazione dei service worker sul suo sito web, che è servito come punto di partenza per il mio codice. Sono stato ispirato dal suo recente post che descrive le sue esperienze di service worker in corso. Infatti, il mio lavoro è così pesantemente derivato che non ne avrei scritto se non per l’esortazione di Jeremy in un post precedente:
Quindi, se decidete di giocare con i Service Workers, per favore, per favore condividete la vostra esperienza.
In secondo luogo, ogni sorta di grande ringraziamento a Jake Archibald per la sua eccellente revisione tecnica e il suo feedback. È sempre bello quando uno dei creatori ed evangelisti delle specifiche dei service worker è in grado di metterti in riga!
Che cos’è un service worker?
Un service worker è uno script che si frappone tra il tuo sito web e la rete, dandoti, tra le altre cose, la possibilità di intercettare le richieste della rete e rispondere ad esse in diversi modi.
Per far funzionare il tuo sito web o la tua app, il browser recupera le sue risorse – come pagine HTML, JavaScript, immagini, font. In passato, la gestione di questo era principalmente prerogativa del browser. Se il browser non poteva accedere alla rete, probabilmente vedevi il suo messaggio “Ehi, sei offline”. C’erano tecniche che si potevano usare per incoraggiare il caching locale delle risorse, ma il browser spesso aveva l’ultima parola.
Questa non era una grande esperienza per gli utenti che erano offline, e lasciava gli sviluppatori web con poco controllo sul caching del browser.
Come Application Cache (o AppCache), il cui arrivo diversi anni fa sembrava promettente. Apparentemente ti permetteva di dettare come le diverse risorse dovevano essere gestite, in modo che il tuo sito web o la tua app potessero funzionare offline. Eppure la sintassi semplice di AppCache smentiva la sua natura confusa e la sua mancanza di flessibilità.
La nascente API del service worker può fare quello che faceva AppCache, e molto di più. Ma all’inizio sembra un po’ scoraggiante. Le specifiche richiedono una lettura pesante e astratta, e numerose API sono asservite ad essa o altrimenti collegate: cache, fetch, ecc. I lavoratori dei servizi comprendono così tante funzionalità: notifiche push e, presto, sincronizzazione in background. Rispetto ad AppCache, sembra… complicato.
Dove AppCache (che, tra l’altro, sta scomparendo) era facile da imparare ma terribile per ogni singolo momento successivo (la mia opinione), i lavoratori dei servizi sono più di un investimento cognitivo iniziale, ma sono potenti e utili, e si può generalmente tirarsi fuori dai guai se si rompono le cose.
Alcuni concetti di base sui lavoratori dei servizi
Un lavoratore dei servizi è un file con del JavaScript in esso. In quel file puoi scrivere JavaScript come lo conosci e lo ami, con alcune cose importanti da tenere a mente.
Gli script dei service worker vengono eseguiti in un thread separato nel browser dalle pagine che controllano. Ci sono modi per comunicare tra i worker e le pagine, ma vengono eseguiti in un ambito separato. Questo significa che non avrete accesso al DOM di quelle pagine, per esempio. Io visualizzo un service worker come una sorta di esecuzione in una scheda separata dalla pagina che influenza; questo non è affatto accurato, ma è un’utile metafora approssimativa per tenermi fuori dalla confusione.
JavaScript in un service worker non deve bloccare. Dovete usare API asincrone. Per esempio, non potete usare localStorage in un service worker (localStorage è un’API sincrona). Umoristicamente, anche sapendo questo, sono riuscito a correre il rischio di violarlo, come vedremo.
Registrazione di un service worker
Si rende effettivo un service worker registrandolo. Questa registrazione è fatta dall’esterno del service worker, da un’altra pagina o script sul tuo sito web. Sul mio sito web, uno script globale site.js è incluso in ogni pagina HTML. Registro il mio service worker da lì.
Quando registri un service worker, (opzionalmente) gli dici anche a quale ambito dovrebbe applicarsi. Puoi istruire un service worker solo per gestire qualcosa per una parte del tuo sito web (per esempio, '/blog/') o puoi registrarlo per tutto il tuo sito web ('/') come faccio io.
Ciclo di vita del service worker ed eventi
Un service worker fa il grosso del suo lavoro ascoltando gli eventi rilevanti e rispondendo ad essi in modi utili. Diversi eventi sono attivati in diversi punti del ciclo di vita di un service worker.
Una volta che il service worker è stato registrato e scaricato, viene installato in background. Il service worker può ascoltare l’evento install ed eseguire i compiti appropriati per questa fase.
Nel nostro caso, vogliamo approfittare dello stato install per mettere in pre-cache un mucchio di risorse che sappiamo di volere disponibili offline in seguito.
Dopo che la fase install è finita, il service worker viene attivato. Questo significa che il service worker ha ora il controllo delle cose all’interno del suo scope e può fare le sue cose. L’evento activate non è troppo eccitante per un nuovo service worker, ma vedremo come è utile quando si aggiorna un service worker con una nuova versione.
Esattamente quando avviene l’attivazione dipende se si tratta di un service worker nuovo di zecca o di una versione aggiornata di un service worker preesistente. Se il browser non ha una versione precedente di un dato service worker già registrato, l’attivazione avverrà immediatamente dopo il completamento dell’installazione.
Una volta che l’installazione e l’attivazione sono completate, non si verificheranno di nuovo fino a quando una versione aggiornata del service worker sarà scaricata e registrata.
Oltre all’installazione e all’attivazione, oggi guarderemo principalmente l’evento fetch per rendere utile il nostro service worker. Ma ci sono diversi eventi utili oltre a questo: eventi di sincronizzazione ed eventi di notifica, per esempio.
Per credito extra o per divertimento, puoi leggere di più sulle interfacce che i service worker implementano. È implementando queste interfacce che i service worker ottengono la maggior parte dei loro eventi e molte delle loro funzionalità estese.
L’API basata sulle promesse del service worker
L’API del service worker fa un uso pesante di Promises. Una promessa rappresenta l’eventuale risultato di un’operazione asincrona, anche se il valore effettivo non sarà noto fino a quando l’operazione non sarà completata in futuro.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});La funzione getAnAnswer… restituisce un Promise che (speriamo) alla fine sarà soddisfatto da, o risolto a, il answer che stiamo cercando. Poi, quel answer può essere dato in pasto a qualsiasi then funzione di gestione concatenata, o, nel triste caso di fallimento nel raggiungere il suo obiettivo, il Promise può essere rifiutato – spesso con una ragione – e catch funzioni di gestione possono prendersi cura di queste situazioni.
C’è di più per le promesse, ma cercherò di mantenere gli esempi qui semplici (o almeno commentati). Vi invito a fare qualche lettura informativa se siete nuovi alle promesse.
Nota: uso certe caratteristiche di ECMAScript6 (o ES2015) nel codice di esempio per i lavoratori di servizio perché i browser che supportano i lavoratori di servizio supportano anche queste caratteristiche. In particolare qui, sto usando funzioni freccia e stringhe template.
Altre necessità dei lavoratori di servizio
Nota anche che i lavoratori di servizio richiedono HTTPS per funzionare. C’è un’importante e utile eccezione a questa regola: I lavoratori di servizio funzionano per localhost su http insicuro, il che è un sollievo perché l’impostazione di SSL locale è a volte una faticaccia.
Fatto divertente: questo progetto mi ha costretto a fare qualcosa che avevo rimandato per un po’: ottenere e configurare SSL per il www sottodominio del mio sito web. Questa è una cosa che esorto la gente a considerare di fare perché praticamente tutte le nuove cose divertenti che colpiranno il browser in futuro richiederanno l’uso di SSL.
Tutta la roba che metteremo insieme funziona oggi in Chrome (io uso la versione 47). Da un giorno all’altro, Firefox 44 verrà spedito, e supporta i service worker. Is Service Worker Ready? fornisce informazioni dettagliate sul supporto nei diversi browser.
Registrazione, installazione e attivazione di un service worker
Ora che ci siamo occupati di un po’ di teoria, possiamo iniziare a mettere insieme il nostro service worker.
Per installare e attivare il nostro service worker, vogliamo ascoltare gli eventi install e activate e agire su di essi.
Possiamo iniziare con un file vuoto per il nostro service worker e aggiungere un paio di eventListeners. In serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registrazione del nostro service worker
Ora abbiamo bisogno di dire alle pagine del nostro sito web di usare il service worker.
Ricordo, questa registrazione avviene dall’esterno del service worker – nel mio caso, da uno script (/js/site.js) che è incluso in ogni pagina del mio sito web.
Nel mio site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-cache di asset statici durante l’installazione
Voglio usare la fase di installazione per pre-cache di alcuni asset sul mio sito.
- Pre-caching di alcune risorse statiche (immagini, CSS, JavaScript) che sono usate da molte pagine del mio sito web, posso accelerare i tempi di caricamento prendendole dalla cache, invece di recuperarle dalla rete nei successivi caricamenti di pagina.
- Pre-caching di una pagina di fallback offline, posso mostrare una bella pagina quando non posso soddisfare una richiesta di pagina perché l’utente è offline.
I passi per farlo sono:
- Dire all’evento
installdi aspettare e di non completare finché non ho fatto quello che devo fare usandoevent.waitUntil. - Aprire l’appropriato
cache, e metterci le risorse statiche usandoCache.addAll. Nel linguaggio delle progressive web app, queste risorse costituiscono il mio “guscio dell’applicazione”.
In /serviceWorker.js, espandiamo il gestore install:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Il service worker implementa l’interfaccia CacheStorage, che rende la proprietà caches disponibile globalmente nel nostro service worker. Ci sono diversi metodi utili su caches – per esempio, open e delete.
Puoi vedere Promises al lavoro qui: caches.open restituisce un Promise che si risolve in un oggetto cache una volta che ha aperto con successo la cache static; addAll restituisce anche un Promise che si risolve quando tutti gli oggetti che gli sono stati passati sono stati messi nella cache.
Dico al event di aspettare finché il Promise restituito dalla mia funzione handler si risolve con successo. Allora possiamo essere sicuri che tutti quegli elementi pre-cache vengano ordinati prima che l’installazione sia completa.
Confusioni in console
Stale Logging
Possibilmente non è un bug, ma certamente una confusione: Se si console.logdai lavoratori di servizio, Chrome continuerà a ri-visualizzare (piuttosto che cancellare) quei messaggi di log nelle successive richieste di pagina. Questo può far sembrare che gli eventi vengano sparati troppe volte o che il codice venga eseguito più e più volte.
Per esempio, aggiungiamo una dichiarazione log al nostro install handler:
self.addEventListener('install', event => { // … as before console.log('installing');});
install ad ogni caricamento di pagina. Invece, sta mostrando registri stantii. (Visualizza versione grande)Un errore quando le cose vanno bene
Un’altra cosa strana è che una volta che un service worker è installato e attivato, i successivi caricamenti di qualsiasi pagina nel suo ambito causeranno sempre un singolo errore nella console. Pensavo di fare qualcosa di sbagliato.

Cosa abbiamo fatto finora
Il service worker gestisce l’evento install e pre-cache alcune risorse statiche. Se si dovesse usare questo service worker e registrarlo, esso metterebbe effettivamente in pre-cache le risorse indicate, ma non sarebbe ancora in grado di sfruttarle offline.
Il contenuto di serviceWorker.js è su GitHub.
Gestione del Fetch con i Service Workers
Finora, il nostro service worker ha un gestore di install ben definito, ma non fa nulla oltre a questo. La magia del nostro service worker avverrà veramente quando gli eventi fetch saranno innescati.
Possiamo rispondere ai fetch in diversi modi. Usando diverse strategie di rete, possiamo dire al browser di provare sempre a recuperare certe risorse dalla rete (assicurandoci che il contenuto chiave sia fresco), mentre favoriamo le copie in cache per le risorse statiche – snellendo davvero i nostri carichi di pagina. Possiamo anche fornire un bel fallback offline se tutto il resto fallisce.
Ogni volta che un browser vuole andare a prendere una risorsa che è nell’ambito di questo service worker, possiamo sentirlo, sì, aggiungendo un eventListener in serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Ancora una volta, ogni fetch che cade nell’ambito di questo service worker (cioè il percorso) attiverà questo evento – pagine HTML, script, immagini, CSS, lo si nomina. Possiamo gestire selettivamente il modo in cui il browser risponde a ciascuna di queste ricerche.
Dovremmo gestire questo fetch?
Quando si verifica un evento fetch per una risorsa, la prima cosa che voglio determinare è se questo service worker deve interferire con il fetching della risorsa data. Altrimenti, non dovrebbe fare nulla e lasciare che il browser asserisca il suo comportamento predefinito.
Finiremo con una logica di base come questa in serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});La funzione shouldHandleFetch valuta una data richiesta per determinare se dobbiamo fornire una risposta o lasciare che il browser asserisca la sua gestione predefinita.
Perché non usare le promesse?
Per mantenere la predilezione del service worker per le promesse, la prima versione del mio gestore di eventi fetch era come questa:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Sembra logico, ma stavo facendo un paio di errori da principiante con le promesse. Giuro che ho percepito un odore di codice anche inizialmente, ma è stato Jake che mi ha messo in riga sugli errori dei miei modi. (Lezione: come sempre, se il codice sembra sbagliato, probabilmente lo è.)
I rifiuti delle promesse non dovrebbero essere usati per indicare, “Ho ottenuto una risposta che non mi piace”. Invece, i rifiuti dovrebbero indicare: “Ah, merda, qualcosa è andato storto nel tentativo di ottenere la risposta”. Cioè, i rifiuti dovrebbero essere eccezionali.
Criteri per le richieste valide
Va bene, torniamo a determinare se una data richiesta di fetch è applicabile al mio lavoratore di servizio. I miei criteri specifici per il sito sono i seguenti:
- L’URL richiesto dovrebbe rappresentare qualcosa che voglio mettere in cache o a cui voglio rispondere. Il suo percorso dovrebbe corrispondere a un
Regular Expressiondi percorsi validi. - Il metodo HTTP della richiesta dovrebbe essere
GET. - La richiesta dovrebbe essere per una risorsa dalla mia origine (
lyza.com).
Se uno dei test criteria valuta false, non dovremmo gestire questa richiesta. In serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Ovviamente, i criteri qui sono miei e varierebbero da sito a sito. event.request è un oggetto Request che ha tutti i tipi di dati che puoi guardare per valutare come vorresti che il tuo gestore di fetch si comportasse.
Nota banale: se hai notato l’incursione di config, passato come opts alle funzioni del gestore, ben fatto. Ho eliminato alcuni valori riutilizzabili simili a config e ho creato un oggetto config nello scope di primo livello del service worker:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Perché Whitelist?
Vi starete chiedendo perché sto memorizzando nella cache solo cose con percorsi che corrispondono a questa espressione regolare:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… invece di memorizzare nella cache tutto ciò che proviene dalla mia stessa origine. Un paio di ragioni:
- Non voglio mettere nella cache il service worker stesso.
- Quando sto sviluppando il mio sito in locale, alcune richieste generate sono per cose che non voglio mettere nella cache. Per esempio, uso
browserSync, che fa partire un mucchio di richieste correlate nel mio ambiente di sviluppo. Non voglio mettere in cache quella roba! Sembrava disordinato e impegnativo cercare di pensare a tutto ciò che non avrei voluto mettere in cache (per non parlare del fatto che era un po’ strano doverlo specificare nella configurazione del mio service worker). Quindi, l’approccio della whitelist sembrava più naturale.
Scrivere il gestore del fetch
Ora siamo pronti a passare le richieste fetch applicabili a un gestore. La funzione onFetch deve determinare:
- che tipo di risorsa è richiesta,
- e come dovrei soddisfare questa richiesta.
1. Che tipo di risorsa viene richiesta?
Posso guardare l’intestazione HTTP Accept per avere un indizio su che tipo di risorsa viene richiesta. Questo mi aiuta a capire come voglio gestirla.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Per essere organizzato, voglio mettere diversi tipi di risorse in diverse cache. Questo mi permetterà di gestire quelle cache in seguito. Queste chiavi di cache Stringsono arbitrarie – puoi chiamare le tue cache come vuoi; l’API della cache non ha opinioni.
2. Rispondere al Fetch
La prossima cosa da fare per onFetch è respondTo l’evento fetch con un Response intelligente.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Careful With Async!
Nel nostro caso, shouldHandleFetch non fa nulla di asincrono, e nemmeno onFetch fino al punto di event.respondWith. Se qualcosa di asincrono fosse successo prima, saremmo nei guai. event.respondWith deve essere chiamato tra lo sparo dell’evento fetch e il ritorno del controllo al browser. Lo stesso vale per event.waitUntil. Fondamentalmente, se stai gestendo un evento, o fai qualcosa immediatamente (in modo sincrono) o dici al browser di aspettare fino a quando la tua roba asincrona non è finita.
HTML Content: Implementare una strategia Network-First
Rispondere alle richieste fetch comporta l’implementazione di una strategia di rete appropriata. Guardiamo più da vicino il modo in cui stiamo rispondendo alle richieste di contenuto HTML (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}Il modo in cui soddisfiamo le richieste di contenuto qui è una strategia network-first. Poiché il contenuto HTML è l’interesse principale del mio sito web e cambia spesso, cerco sempre di ottenere documenti HTML freschi dalla rete.
Passiamo attraverso questo.
1. Prova a recuperare dalla rete
fetch(request) .then(response => addToCache(cacheKey, request, response))Se la richiesta di rete ha successo (cioè la promessa si risolve), vai avanti e metti una copia del documento HTML nella cache appropriata (content). Questo è chiamato read-through caching:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Le risposte possono essere usate solo una volta.
Abbiamo bisogno di fare due cose con il response che abbiamo:
- cache,
- rispondere all’evento con esso (cioè restituirlo).
Ma gli oggetti Response possono essere usati solo una volta. Clonandolo, siamo in grado di creare una copia per l’uso della cache:
var copy = response.clone();
Non mettere in cache le risposte negative. Non fate lo stesso errore che ho fatto io. La prima versione del mio codice non aveva questa condizione:
if (response.ok)Pratico finire con 404 o altre cattive risposte nella cache! Solo risposte felici nella cache.
2. Prova a recuperare dalla cache
Se il recupero della risorsa dalla rete ha successo, abbiamo finito. Tuttavia, se non ci riesce, potremmo essere offline o comunque compromessi dalla rete. Prova a recuperare una copia precedentemente memorizzata nella cache dell’HTML:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Ecco la funzione fetchFromCache:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Nota: Non indicare quale cache vuoi controllare con caches.match; controllale tutte insieme.
3. Fornire un fallback offline
Se siamo arrivati fin qui ma non c’è niente nella cache con cui possiamo rispondere, restituisci un fallback offline appropriato, se possibile. Per le pagine HTML, questa è la pagina in cache da /offline/. È una pagina ragionevolmente ben formattata che dice all’utente che è offline e che non possiamo soddisfare ciò che sta cercando.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) Ed ecco la funzione offlineResponse:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}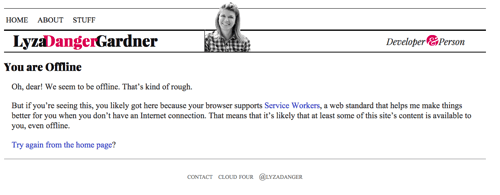
Altre risorse: Implementare una strategia Cache-First
La logica di fetch per risorse diverse dal contenuto HTML usa una strategia cache-first. Le immagini e altri contenuti statici sul sito web cambiano raramente; quindi, controlla prima la cache ed evita il viaggio in rete.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));I passi sono:
- prova a recuperare la risorsa dalla cache;
- se questo fallisce, prova a recuperare dalla rete (con la cache read-through);
- se questo fallisce, fornisci una risorsa fallback offline, se possibile.
Immagine offline
Possiamo restituire un’immagine SVG con il testo “Offline” come fallback offline completando la funzione offlineResource:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}E facciamo i relativi aggiornamenti a config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};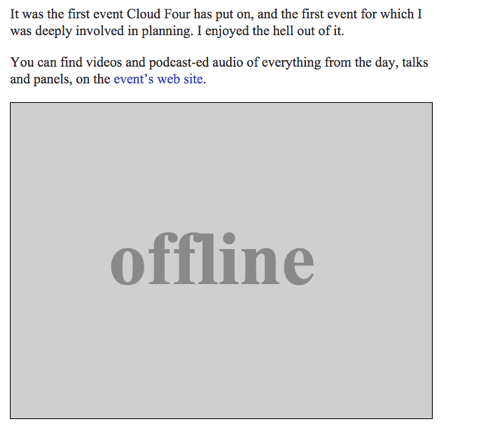
Watch Out for CDNs
Watch out for CDNs if you are restricting fetch handling to your origin. Quando ho costruito il mio primo service worker, ho dimenticato che il mio fornitore di hosting aveva shardato le risorse (immagini e script) sul suo CDN, così che non erano più servite dall’origine del mio sito (lyza.com). Ops! Non ha funzionato. Ho finito per disabilitare il CDN per le risorse interessate (ma ottimizzando quelle risorse, ovviamente!).
Completamento della prima versione
La prima versione del nostro service worker è ora fatta. Abbiamo un gestore install e un gestore fetch più completo che può rispondere alle ricerche applicabili con risposte ottimizzate, così come fornire risorse nella cache e una pagina offline quando non è in linea.
Quando gli utenti navigano nel sito web, continueranno a costruire più elementi nella cache. Quando sono offline, saranno in grado di continuare a sfogliare gli elementi che hanno già nella cache, o vedranno una pagina offline (o un’immagine) se la risorsa richiesta non è disponibile nella cache.
Il codice completo con la gestione del fetch (serviceWorker.js) è su GitHub.
Versioning And Updating The Service Worker
Se nulla dovesse più cambiare sul nostro sito web, potremmo dire che abbiamo finito. Tuttavia, i service worker devono essere aggiornati di tanto in tanto. Forse voglio aggiungere altri percorsi memorizzabili nella cache. Forse voglio evolvere il modo in cui funzionano i miei fallback offline. Forse c’è qualcosa di leggermente buggato nel mio service worker che voglio correggere.
Voglio sottolineare che ci sono strumenti automatici per rendere la gestione dei service worker parte del tuo flusso di lavoro, come Service Worker Precache di Google. Non è necessario gestire il versioning a mano. Tuttavia, la complessità del mio sito web è abbastanza bassa che uso una strategia di versioning umano per gestire le modifiche al mio service worker. Questo consiste in:
- una semplice stringa di versione per indicare le versioni,
- implementazione di un
activategestore per ripulire dopo le vecchie versioni, - aggiornamento del
installgestore per rendere i service worker aggiornatiactivatepiù veloci.
Versioning Cache Keys
Posso aggiungere una proprietà version al mio oggetto config:
version: 'aether'Questo dovrebbe cambiare ogni volta che voglio distribuire una versione aggiornata del mio service worker. Uso i nomi delle divinità greche perché per me sono più interessanti delle stringhe casuali o dei numeri.
Nota: Ho fatto alcune modifiche al codice, aggiungendo una funzione di convenienza (cacheName) per generare chiavi di cache prefissate. È tangenziale, quindi non la includo qui, ma potete vederla nel codice del service worker completato.
achilles.) (Visualizza versione grande)Non rinominare il tuo service worker
A un certo punto, stavo giocando con le convenzioni di denominazione del nome del file del service worker. Non farlo. Se lo fai, il browser registrerà il nuovo service worker, ma anche il vecchio service worker rimarrà installato. Questo è uno stato di cose incasinato. Sono sicuro che c’è una soluzione, ma ti direi di non rinominare il tuo service worker.
Non usare importScripts per la configurazione
Ho seguito la strada di mettere il mio oggetto config in un file esterno e usare self.importScripts() nel file del service worker per inserire quello script. Questo sembrava un modo ragionevole per gestire il mio config al di fuori del service worker, ma c’era un intoppo.
Il browser confronta i file del service worker per determinare se sono stati aggiornati – questo è il modo in cui sa quando riavviare un ciclo di download e installazione. I cambiamenti al config esterno non causano alcun cambiamento al service worker stesso, il che significa che i cambiamenti al config non stavano causando l’aggiornamento del service worker. Whoops.
Aggiungimento di un gestore di attivazione
Lo scopo di avere nomi di cache specifici per la versione è quello di poter pulire le cache delle versioni precedenti. Se ci sono cache in giro durante l’attivazione che non sono prefissate con la stringa della versione corrente, sapremo che dovrebbero essere eliminate perché sono crufty.
Pulizia delle vecchie cache
Possiamo usare una funzione per ripulire dopo le vecchie cache:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Speaking Up Install and Activate
Un service worker aggiornato verrà scaricato e sarà install in background. Ora è un lavoratore in attesa. Per impostazione predefinita, il service worker aggiornato non si attiverà mentre vengono caricate le pagine che stanno ancora usando il vecchio service worker. Tuttavia, possiamo velocizzare la cosa facendo una piccola modifica al nostro gestore install:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting farà sì che activate avvenga immediatamente.
Ora, finisci il gestore activate:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim farà sì che il nuovo service worker abbia effetto immediatamente su qualsiasi pagina aperta nel suo ambito.

chrome://serviceworker-internals in Chrome per vedere tutti i service worker che il browser ha registrato. (Visualizza versione grande)
Ta-Da!
Ora abbiamo un service worker gestito dalla versione! Puoi vedere il file serviceWorker.js aggiornato con la gestione delle versioni su GitHub.
Altre letture su SmashingMag:
- A Beginner’s Guide To Progressive Web Apps
- Building A Simple Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web