
Cu privire la autor
Lyza Danger Gardner este un dev. De când a cofondat, în 2007, Cloud Four, startup-ul web mobil din Portland, Oregon, s-a torturat și s-a entuziasmat cu …Mai multe despreLyza↬
- 23 min read
- Codare,JavaScript,Tehnici,Service Workers
- Salvat pentru citire offline
- Share on Twitter, LinkedIn


Nu lipsește nici un impuls sau entuziasm în legătură cu API-ul de lucrător de servicii începător, livrat acum în unele browsere populare. Există cărți de bucate și articole de blog, fragmente de cod și instrumente. Dar am descoperit că atunci când vreau să învăț un nou concept web în profunzime, să îmi suflec mânecile proverbiale, să mă scufund și să construiesc ceva de la zero este de multe ori ideal.
Bucăturile și vânătăile, problemele și bug-urile pe care le-am întâlnit de data aceasta au beneficii: Acum înțeleg mult mai bine lucrătorii de servicii și, cu puțin noroc, vă pot ajuta să evitați unele dintre durerile de cap pe care le-am întâlnit atunci când am lucrat cu noul API.
Lucrătorii de servicii fac o mulțime de lucruri diferite; există nenumărate moduri de a le exploata puterile. Am decis să construiesc un lucrător de servicii simplu pentru site-ul meu (static, necomplicat) care reflectă aproximativ caracteristicile pe care API-ul învechit Application Cache obișnuia să le ofere – și anume:
- face ca site-ul să funcționeze offline,
- crește performanța online prin reducerea solicitărilor de rețea pentru anumite active,
- oferă o experiență de rezervă offline personalizată.
Înainte de a începe, aș dori să recunosc două persoane a căror muncă a făcut posibil acest lucru. În primul rând, îi sunt enorm de îndatorat lui Jeremy Keith pentru implementarea service workers pe propriul său site web, care a servit ca punct de plecare pentru propriul meu cod. Am fost inspirat de recenta sa postare care descrie experiențele sale continue cu lucrătorii de servicii. De fapt, munca mea este atât de puternic derivată încât nu aș fi scris despre ea dacă nu ar fi existat îndemnul lui Jeremy într-o postare anterioară:
Așa că, dacă vă decideți să vă jucați cu Service Workers, vă rog, vă rog să vă împărtășiți experiența.
În al doilea rând, tot felul de mulțumiri vechi și mari lui Jake Archibald pentru revizuirea tehnică excelentă și feedback-ul său. Întotdeauna este plăcut când unul dintre creatorii și evangheliștii specificației service worker este capabil să te pună la punct!
Ce este un service worker?
Un service worker este un script care stă între site-ul dvs. web și rețea, oferindu-vă, printre altele, capacitatea de a intercepta cererile de rețea și de a răspunde la ele în diferite moduri.
Pentru ca site-ul web sau aplicația dvs. să funcționeze, browserul își recuperează resursele – cum ar fi pagini HTML, JavaScript, imagini, fonturi. În trecut, gestionarea acestora era în principal prerogativa browserului. Dacă browserul nu putea accesa rețeaua, probabil că ați fi văzut mesajul său „Hei, ești offline”. Existau tehnici pe care le puteați utiliza pentru a încuraja memoria cache locală a activelor, dar browserul avea adesea ultimul cuvânt de spus.
Aceasta nu era o experiență atât de grozavă pentru utilizatorii care erau offline și îi lăsa pe dezvoltatorii web cu puțin control asupra memoriei cache a browserului.
Apoi Application Cache (sau AppCache), a cărui sosire cu câțiva ani în urmă părea promițătoare. În aparență, vă permitea să dictați cum ar trebui să fie gestionate diferite active, astfel încât site-ul sau aplicația dvs. să poată funcționa offline. Cu toate acestea, sintaxa AppCache, care părea simplă, ascundea natura sa confuză și lipsa de flexibilitate subiacentă.
Apif-ul nou-înființat al lucrătorului de servicii poate face ceea ce făcea AppCache și mult mai mult. Dar pare puțin descurajantă la început. Specificațiile fac o lectură grea și abstractă, iar numeroase API-uri îi sunt subordonate sau sunt legate în alt mod: cache, fetch, etc. Service workers înglobează atât de multe funcționalități: notificări push și, în curând, sincronizare în fundal. În comparație cu AppCache, pare… complicat.
În timp ce AppCache (care, apropo, va dispărea) a fost ușor de învățat, dar teribil pentru fiecare clipă de după aceea (părerea mea), lucrătorii de servicii reprezintă mai mult o investiție cognitivă inițială, dar sunt puternici și utili și, în general, vă puteți scoate singuri din necazuri dacă stricați lucrurile.
Câteva concepte de bază despre lucrătorii de servicii
Un lucrător de servicii este un fișier cu ceva JavaScript în el. În acel fișier puteți scrie JavaScript așa cum îl cunoașteți și îl iubiți, cu câteva lucruri importante de care trebuie să țineți cont.
Scripturile service worker rulează într-un fir separat în browser de paginile pe care le controlează. Există modalități de a comunica între workers și pagini, dar acestea se execută într-un domeniu separat. Asta înseamnă că nu veți avea acces la DOM-ul acelor pagini, de exemplu. Eu vizualizez un lucrător de servicii ca un fel de execuție într-o filă separată de pagina pe care o afectează; acest lucru nu este deloc exact, dar este o metaforă aproximativă utilă pentru a mă feri de confuzii.
JavaScript într-un lucrător de servicii nu trebuie să blocheze. Trebuie să folosiți API-uri asincrone. De exemplu, nu puteți utiliza localStorage într-un lucrător de servicii (localStorage este o API sincronă). În mod destul de amuzant, chiar știind acest lucru, am reușit să risc să îl încalc, după cum vom vedea.
Înregistrarea unui lucrător de servicii
Faceți ca un lucrător de servicii să intre în vigoare prin înregistrarea lui. Această înregistrare se face din afara lucrătorului de servicii, de către o altă pagină sau un alt script de pe site-ul dumneavoastră. Pe site-ul meu web, un script global site.js este inclus pe fiecare pagină HTML. Îmi înregistrez lucrătorul de servicii de acolo.
Când înregistrați un lucrător de servicii, îi spuneți (opțional) și la ce domeniu de aplicare trebuie să se aplice. Puteți instrui un lucrător de servicii să se ocupe doar de lucruri pentru o parte din site-ul dumneavoastră (de exemplu, '/blog/') sau îl puteți înregistra pentru întregul site ('/'), așa cum fac eu.
Service Worker Lifecycle And Events
Un lucrător de servicii își face cea mai mare parte din muncă ascultând evenimente relevante și răspunzând la ele în moduri utile. Diferite evenimente sunt declanșate în diferite puncte din ciclul de viață al unui lucrător de servicii.
După ce lucrătorul de servicii a fost înregistrat și descărcat, acesta se instalează în fundal. Lucrătorul dvs. de servicii poate asculta evenimentul install și poate efectua sarcini adecvate pentru această etapă.
În cazul nostru, dorim să profităm de starea install pentru a pre-cacheta o serie de active despre care știm că le vom dori disponibile offline mai târziu.
După ce etapa install este terminată, lucrătorul de servicii este apoi activat. Asta înseamnă că lucrătorul de servicii deține acum controlul asupra lucrurilor din cadrul scope său și își poate face treaba. Evenimentul activate nu este prea interesant pentru un nou lucrător de servicii, dar vom vedea cum este util atunci când actualizăm un lucrător de servicii cu o nouă versiune.
Exact când are loc activarea depinde de faptul că este vorba de un lucrător de servicii complet nou sau de o versiune actualizată a unui lucrător de servicii preexistent. Dacă browserul nu are deja înregistrată o versiune anterioară a unui anumit lucrător de servicii, activarea va avea loc imediat după ce instalarea este finalizată.
După ce instalarea și activarea sunt finalizate, acestea nu vor mai avea loc din nou până când o versiune actualizată a lucrătorului de servicii nu este descărcată și înregistrată.
Dincolo de instalare și activare, astăzi ne vom uita în principal la evenimentul fetch pentru a face util lucrătorul nostru de servicii. Dar există mai multe evenimente utile dincolo de acesta: evenimente de sincronizare și evenimente de notificare, de exemplu.
Pentru credite suplimentare sau distracție în timpul liber, puteți citi mai multe despre interfețele pe care lucrătorii de servicii le implementează. Prin implementarea acestor interfețe, lucrătorii de servicii obțin cea mai mare parte a evenimentelor lor și o mare parte din funcționalitatea lor extinsă.
Apif-ul bazat pe promisiuni al lucrătorului de servicii
Apif-ul lucrătorului de servicii utilizează intensiv Promises. O promisiune reprezintă eventualul rezultat al unei operații asincrone, chiar dacă valoarea reală nu va fi cunoscută până când operația nu se va finaliza undeva în viitor.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});Funcția getAnAnswer… returnează o Promise care (sperăm) va fi în cele din urmă îndeplinită de, sau se va rezolva la, answer pe care o căutăm. Apoi, acel answer poate fi alimentat către orice funcție de manipulare then înlănțuită sau, în cazul regretabil al eșecului de a-și atinge obiectivul, Promise poate fi respins – adesea cu un motiv – iar funcțiile de manipulare catch se pot ocupa de aceste situații.
Există mai multe promisiuni, dar voi încerca să păstrez exemplele de aici simple (sau cel puțin comentate). Vă îndemn să faceți niște lecturi informative dacă sunteți nou în domeniul promisiunilor.
Nota: Folosesc anumite caracteristici ECMAScript6 (sau ES2015) în codul de exemplu pentru lucrătorii de servicii deoarece browserele care suportă lucrătorii de servicii suportă, de asemenea, aceste caracteristici. În mod specific aici, folosesc funcții săgeată și șiruri de șabloane.
Alte necesități ale lucrătorilor de servicii
De asemenea, rețineți că lucrătorii de servicii necesită HTTPS pentru a funcționa. Există o excepție importantă și utilă de la această regulă: Lucrătorii de servicii funcționează pentru localhost pe http nesigur, ceea ce este o ușurare, deoarece configurarea SSL-ului local este uneori o bătaie de cap.
Fapt amuzant: Acest proiect m-a forțat să fac ceva ce am amânat de ceva timp: să obțin și să configurez SSL pentru subdomeniul www al site-ului meu web. Acesta este un lucru pe care îi îndemn pe oameni să se gândească să-l facă, deoarece cam toate lucrurile noi și amuzante care vor ajunge în browser în viitor vor necesita utilizarea SSL.
Toate lucrurile pe care le vom pune împreună funcționează astăzi în Chrome (eu folosesc versiunea 47). În orice zi, Firefox 44 va fi livrat, iar acesta suportă service workers. Is Service Worker Ready? oferă informații granulare despre suportul în diferite browsere.
Înregistrarea, instalarea și activarea unui lucrător de servicii
Acum că ne-am ocupat de unele aspecte teoretice, putem începe să ne asamblăm lucrătorul de servicii.
Pentru a instala și activa lucrătorul nostru de servicii, dorim să ascultăm evenimentele install și activate și să acționăm în funcție de ele.
Potem începe cu un fișier gol pentru lucrătorul nostru de servicii și să adăugăm câteva eventListeners. În serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Înregistrarea lucrătorului nostru de servicii
Acum trebuie să le spunem paginilor de pe site-ul nostru web să folosească lucrătorul de servicii.
Amintiți-vă că această înregistrare are loc din afara lucrătorului de servicii – în cazul meu, din interiorul unui script (/js/site.js) care este inclus pe fiecare pagină a site-ului meu web.
În site.js meu site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-cachetarea activelor statice în timpul instalării
Vreau să folosesc etapa de instalare pentru a pre-cacheta unele active de pe site-ul meu.
- Prin precavarea unor active statice (imagini, CSS, JavaScript) care sunt utilizate de mai multe pagini de pe site-ul meu web, pot accelera timpii de încărcare prin preluarea acestora din cache, în loc să le extrag din rețea la încărcările ulterioare ale paginilor.
- Prin precavarea unei pagini de rezervă offline, pot afișa o pagină frumoasă atunci când nu pot îndeplini o cerere de pagină deoarece utilizatorul este offline.
Pasii pentru a face acest lucru sunt:
- Spuneți-i evenimentului
installsă stea în așteptare și să nu se finalizeze până când nu am făcut ceea ce trebuie să fac, folosindevent.waitUntil. - Deschideți
cachecorespunzător, și băgați activele statice în el folosindCache.addAll. În limbajul aplicațiilor web progresive, aceste active alcătuiesc „cochilia aplicației mele.”
În /serviceWorker.js, să extindem gestionarul install:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Lucrătorul de servicii implementează interfața CacheStorage, ceea ce face ca proprietatea caches să fie disponibilă la nivel global în lucrătorul nostru de servicii. Există mai multe metode utile pe caches – de exemplu, open și delete.
Puteți vedea Promises la lucru aici: caches.open returnează un Promise care se rezolvă la un obiect cache odată ce a deschis cu succes cache-ul static; addAll returnează, de asemenea, un Promise care se rezolvă atunci când toate elementele care i-au fost transmise au fost depozitate în cache.
Îi spun lui event să aștepte până când Promise returnat de funcția mea de manipulare este rezolvat cu succes. Atunci putem fi siguri că toate acele elemente din pre-cache sunt sortate înainte ca instalarea să fie finalizată.
Confuzii în consolă
Stale Logging
Posibil să nu fie un bug, dar cu siguranță o confuzie: Dacă console.log de la service workers, Chrome va continua să afișeze din nou (în loc să șteargă) acele mesaje de jurnal la solicitările de pagină ulterioare. Acest lucru poate face ca evenimentele să pară că se declanșează de prea multe ori sau ca și cum codul se execută la nesfârșit.
De exemplu, să adăugăm o instrucțiune log la gestionarul nostru install:
self.addEventListener('install', event => { // … as before console.log('installing');});
install la fiecare încărcare a paginii. În schimb, afișează jurnalele vechi. (Vizualizați versiunea mare)O eroare când lucrurile sunt în regulă
Un alt lucru ciudat este că, odată ce un lucrător de servicii este instalat și activat, încărcările ulterioare ale oricărei pagini din domeniul său de aplicare vor provoca întotdeauna o singură eroare în consolă. Am crezut că fac ceva greșit.

Ce am realizat până acum
Lucrătorul de servicii gestionează evenimentul install și pre-stochează unele active statice. Dacă ar fi să folosiți acest lucrător de servicii și să-l înregistrați, acesta ar pre-cacheta într-adevăr activele indicate, dar nu ar putea încă să profite de ele offline.
Contenutul lui serviceWorker.js se află pe GitHub.
Fetch Handling With Service Workers
Până acum, lucrătorul nostru de servicii are un handler install bine pus la punct, dar nu face nimic mai mult decât atât. Magia lucrătorului nostru de servicii se va întâmpla cu adevărat atunci când evenimentele fetch sunt declanșate.
Putem răspunde la preluări în diferite moduri. Utilizând diferite strategii de rețea, putem spune browserului să încerce întotdeauna să recupereze anumite active din rețea (asigurându-ne că conținutul cheie este proaspăt), în timp ce favorizăm copiile din cache pentru activele statice – reducând cu adevărat sarcinile utile ale paginilor noastre. Putem, de asemenea, să furnizăm o soluție de rezervă offline plăcută dacă toate celelalte eșuează.
De fiecare dată când un browser dorește să recupereze un activ care se află în domeniul de aplicare al acestui lucrător de servicii, putem afla despre acest lucru prin, da, adăugarea unui eventListener în serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Din nou, fiecare recuperare care se încadrează în domeniul de aplicare al acestui lucrător de servicii (adică calea) va declanșa acest eveniment – pagini HTML, scripturi, imagini, CSS, orice doriți. Putem gestiona în mod selectiv modul în care browserul răspunde la oricare dintre aceste preluări.
Ar trebui să gestionăm această preluare?
Când apare un eveniment fetch pentru o resursă, primul lucru pe care vreau să-l determin este dacă acest lucrător de servicii ar trebui să interfereze cu preluarea resursei date. În caz contrar, nu ar trebui să facă nimic și să lase browserul să își afirme comportamentul implicit.
Vom sfârși cu o logică de bază ca aceasta în serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});Funcția shouldHandleFetch evaluează o cerere dată pentru a determina dacă ar trebui să oferim un răspuns sau să lăsăm browserul să își afirme manipularea implicită.
De ce să nu folosim promisiuni?
Pentru a păstra predilecția service worker pentru promisiuni, prima versiune a gestionarului meu de evenimente fetch arăta astfel:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Pare logic, dar făceam câteva greșeli de începător cu promisiunile. Jur că am simțit un miros de cod chiar la început, dar Jake a fost cel care m-a pus la punct cu privire la erorile mele. (Lecție: Ca întotdeauna, dacă codul pare greșit, probabil că este.)
Respingerea promisiunilor nu ar trebui să fie folosită pentru a indica: „Am primit un răspuns care nu mi-a plăcut”. În schimb, respingerile ar trebui să indice: „Ah, la naiba, ceva a mers prost în încercarea de a obține răspunsul”. Adică, respingerile ar trebui să fie excepționale.
Criterii pentru cereri valide
Direct, înapoi la a determina dacă o anumită cerere de preluare este aplicabilă pentru lucrătorul meu de servicii. Criteriile mele specifice site-ului sunt următoarele:
- Url-ul solicitat ar trebui să reprezinte ceva la care vreau să stochez sau să răspund. Calea sa ar trebui să se potrivească cu o
Regular Expressionde căi valide. - Metoda HTTP a cererii ar trebui să fie
GET. - Cererea ar trebui să fie pentru o resursă de la originea mea (
lyza.com).
Dacă oricare dintre testele criteria se evaluează la false, nu ar trebui să gestionăm această cerere. În serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Desigur, criteriile de aici sunt ale mele și ar varia de la un site la altul. event.request este un obiect Request care are tot felul de date la care vă puteți uita pentru a evalua modul în care ați dori ca gestionarul de preluare să se comporte.
Nota trivială: Dacă ați observat incursiunea lui config, transmis ca opts către funcțiile de gestionare, bine văzut. Am eliminat unele valori de tip config reutilizabile și am creat un obiect config în domeniul de aplicare de nivel superior al lucrătorului de servicii:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};De ce Whitelist?
S-ar putea să vă întrebați de ce pun în cache doar lucruri cu căi care se potrivesc cu această expresie regulată:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… în loc să pun în cache tot ce vine de la propria mea origine. Câteva motive:
- Nu vreau să pun în cache lucrătorul de servicii în sine.
- Când îmi dezvolt site-ul local, unele cereri generate sunt pentru lucruri pe care nu vreau să le pun în cache. De exemplu, folosesc
browserSync, care declanșează o mulțime de cereri conexe în mediul meu de dezvoltare. Nu vreau să pun în cache aceste lucruri! Mi s-a părut dezordonat și provocator să încerc să mă gândesc la tot ceea ce nu aș vrea să pun în cache (ca să nu mai vorbim de faptul că este puțin ciudat să trebuiască să precizez acest lucru în configurația lucrătorului meu de servicii). Așadar, o abordare de tip listă albă părea mai naturală.
Scrierea gestionarului Fetch Handler
Acum suntem gata să transmitem cererile fetch aplicabile către un gestionar. Funcția onFetch trebuie să determine:
- ce fel de resursă este solicitată,
- și cum ar trebui să îndeplinesc această cerere.
1. Ce fel de resursă este solicitată?
Pot să mă uit la antetul HTTP Accept pentru a obține un indiciu despre ce fel de resursă este solicitată. Acest lucru mă ajută să-mi dau seama cum vreau să o gestionez.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Pentru a rămâne organizat, vreau să bag diferite tipuri de resurse în diferite cache-uri. Acest lucru îmi va permite să gestionez aceste cache-uri mai târziu. Aceste chei de cache Stringsunt arbitrare – puteți numi cache-urile dvs. cum doriți; API-ul cache nu are opinii.
2. Răspundeți la Fetch
Următorul lucru pe care trebuie să-l facă onFetch este să respondTo evenimentul fetch cu un Response inteligent.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Atenție cu asincronizarea!
În cazul nostru, shouldHandleFetch nu face nimic asincron și nici onFetch nu face nimic asincron și nici onFetch până în punctul event.respondWith. Dacă s-ar fi întâmplat ceva asincron înainte de asta, am fi avut probleme. event.respondWith trebuie să fie apelat între declanșarea evenimentului fetch și revenirea controlului în browser. Același lucru este valabil și pentru event.waitUntil. Practic, dacă gestionați un eveniment, fie faceți ceva imediat (sincron), fie spuneți-i browserului să aștepte până când se termină lucrul asincron.
Conținut HTML: Implementarea unei strategii bazate mai întâi pe rețea
Răspunsul la solicitările fetch implică implementarea unei strategii de rețea adecvate. Să ne uităm mai atent la modul în care răspundem la solicitările de conținut HTML (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}Modul în care îndeplinim solicitările de conținut aici este o strategie network-first. Deoarece conținutul HTML este preocuparea de bază a site-ului meu și se schimbă des, încerc întotdeauna să obțin documente HTML proaspete din rețea.
Să trecem prin asta.
1. Încercați să preluați din rețea
fetch(request) .then(response => addToCache(cacheKey, request, response))Dacă solicitarea din rețea are succes (adică promisiunea se rezolvă), mergeți mai departe și ascundeți o copie a documentului HTML în memoria cache corespunzătoare (content). Aceasta se numește „read-through caching”:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Răspunsurile pot fi folosite o singură dată.
Trebuie să facem două lucruri cu response pe care îl avem:
- să-l punem în cache,
- să răspundem la eveniment cu el (adică să-l returnăm).
Dar obiectele Response pot fi folosite o singură dată. Prin clonarea lui, putem crea o copie pentru utilizarea cache-ului:
var copy = response.clone();
Nu puneți în cache răspunsurile proaste. Nu faceți aceeași greșeală pe care am făcut-o eu. Prima versiune a codului meu nu avea această condiționalitate:
if (response.ok)Prea grozav să te trezești cu 404 sau alte răspunsuri proaste în memoria cache! Puneți în cache doar răspunsurile fericite.
2. Try to Retrieve From Cache
Dacă recuperarea activului din rețea reușește, am terminat. Cu toate acestea, dacă nu reușește, este posibil să fim offline sau să avem o rețea compromisă în alt mod. Încercați să recuperați din cache o copie anterioară a HTML-ului din cache:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Iată funcția fetchFromCache:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Nota: Nu indicați ce cache doriți să verificați cu caches.match; verificați-le pe toate deodată.
3. Furnizați o soluție de rezervă offline
Dacă am ajuns până aici, dar nu există nimic în memoria cache cu care să putem răspunde, returnați o soluție de rezervă offline corespunzătoare, dacă este posibil. Pentru paginile HTML, aceasta este pagina memorată în memoria cache din /offline/. Este o pagină rezonabil de bine formatată care îi spune utilizatorului că este offline și că nu putem îndeplini ceea ce caută.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))Și iată funcția offlineResponse:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}
Alte resurse: Implementarea unei strategii Cache-First
Logica de preluare pentru alte resurse decât conținutul HTML utilizează o strategie cache-first. Imaginile și alte conținuturi statice de pe site-ul web se schimbă rareori; deci, verificați mai întâi memoria cache și evitați călătoria dus-întors în rețea.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Pasii de aici sunt:
- încercați să preluați resursa din memoria cache;
- dacă nu reușește, încercați să preluați din rețea (cu memoria cache de tip read-through);
- dacă nu reușește, furnizați o resursă de rezervă offline, dacă este posibil.
Imagine offline
Potem returna o imagine SVG cu textul „Offline” ca resursă de rezervă offline prin completarea funcției offlineResource:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}Și să facem actualizările relevante la config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};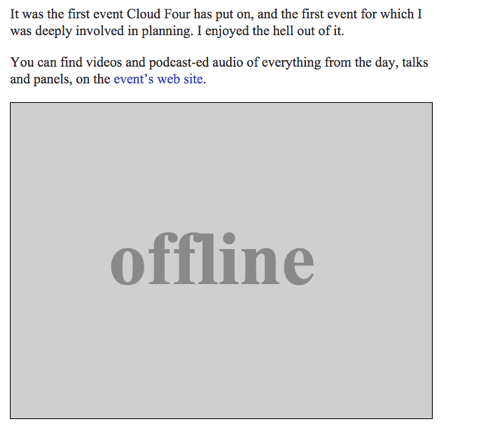
Atenție la CDN-uri
Atenție la CDN-uri dacă restricționați manipularea fetch la originea dvs. Când am construit primul meu lucrător de servicii, am uitat că furnizorul meu de găzduire a împărțit activele (imagini și scripturi) pe CDN-ul său, astfel încât acestea nu mai erau servite de la originea site-ului meu (lyza.com). Ups! Asta nu a funcționat. Am sfârșit prin a dezactiva CDN-ul pentru activele afectate (dar optimizând acele active, bineînțeles!).
Completarea primei versiuni
Prima versiune a lucrătorului nostru de servicii este acum gata. Avem un manipulator install și un manipulator fetch completat, care poate răspunde la preluările aplicabile cu răspunsuri optimizate, precum și să ofere resurse în cache și o pagină offline atunci când este offline.
Pe măsură ce utilizatorii navighează pe site, vor continua să acumuleze mai multe elemente în cache. Atunci când sunt offline, ei vor putea continua să navigheze printre elementele pe care le au deja în cache sau vor vedea o pagină offline (sau o imagine) dacă resursa solicitată nu este disponibilă în cache.
Codul complet cu manipularea fetch (serviceWorker.js) se află pe GitHub.
Versionarea și actualizarea lucrătorului de servicii
Dacă nimic nu se va mai schimba vreodată pe site-ul nostru, am putea spune că am terminat. Cu toate acestea, lucrătorii de servicii trebuie să fie actualizați din când în când. Poate că voi dori să adaug mai multe căi care pot fi stocate în memoria cache. Poate că vreau să evoluez modul în care funcționează fallback-urile mele offline. Poate că există ceva ușor eronat în lucrătorul meu de servicii pe care vreau să-l repar.
Vreau să subliniez că există instrumente automate pentru a face ca gestionarea lucrătorilor de servicii să facă parte din fluxul dvs. de lucru, cum ar fi Service Worker Precache de la Google. Nu trebuie să gestionați manual versiunile acestui lucru. Cu toate acestea, complexitatea de pe site-ul meu este suficient de redusă pentru ca eu să folosesc o strategie de versionare umană pentru a gestiona modificările aduse lucrătorului de servicii. Aceasta constă în:
- un simplu șir de versiuni pentru a indica versiunile,
- implementarea unui manipulator
activatepentru a curăța după versiunile vechi, - actualizarea manipulatorului
installpentru a face ca lucrătorii de servicii actualizațiactivatemai rapid.
Versionarea cheilor cache
Pot adăuga o proprietate version la obiectul meu config:
version: 'aether'Aceasta ar trebui să se schimbe de fiecare dată când vreau să implementez o versiune actualizată a lucrătorului meu de servicii. Folosesc numele zeităților grecești pentru că sunt mai interesante pentru mine decât șirurile de caractere sau numerele aleatorii.
Nota: Am făcut câteva modificări în cod, adăugând o funcție de comoditate (cacheName) pentru a genera chei cache prefixate. Este tangențială, așa că nu o includ aici, dar o puteți vedea în codul completat al lucrătorului de servicii.
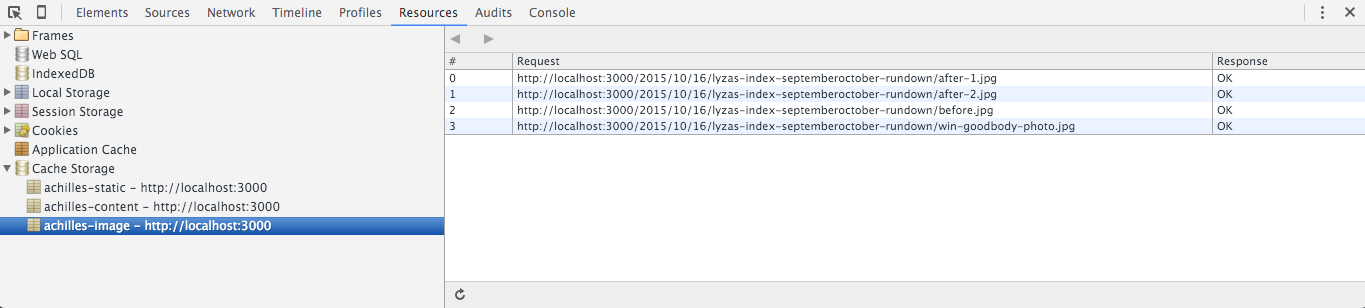
achilles.) (View large version)Don’t Rename Your Service Worker
La un moment dat, mă jucam cu convențiile de denumire pentru numele de fișier al lucrătorului de servicii. Nu faceți acest lucru. Dacă o faceți, browserul va înregistra noul lucrător de servicii, dar și vechiul lucrător de servicii va rămâne instalat. Aceasta este o stare de lucruri dezordonată. Sunt sigur că există o soluție, dar aș spune să nu vă redenumiți lucrătorul de servicii.
Don’t Use importScripts for config
Am mers pe o cale de a pune obiectul meu config într-un fișier extern și de a folosi self.importScripts() în fișierul lucrătorului de servicii pentru a trage acel script înăuntru. Aceasta părea o modalitate rezonabilă de a-mi gestiona config în afara lucrătorului de servicii, dar a existat o piedică.
Furnizorul compară byte cu byte fișierele lucrătorului de servicii pentru a determina dacă au fost actualizate – așa știe când trebuie să declanșeze din nou un ciclu de descărcare și instalare. Modificările aduse la config extern nu cauzează nicio modificare a lucrătorului de servicii în sine, ceea ce înseamnă că modificările aduse la config nu au determinat actualizarea lucrătorului de servicii. Whoops.
Adaugarea unui gestionar de activare
Scopul de a avea nume de cache specifice versiunilor este pentru a putea curăța cache-urile din versiunile anterioare. Dacă în timpul activării există cache-uri în jur care nu sunt prefixate cu șirul de caractere al versiunii curente, vom ști că ar trebui șterse pentru că sunt grețoase.
Curățarea cache-urilor vechi
Potem folosi o funcție pentru a curăța după cache-uri vechi:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Acelerarea instalării și activării
Un lucrător de servicii actualizat va fi descărcat și va install în fundal. Acum este un lucrător în așteptare. În mod implicit, lucrătorul de servicii actualizat nu se va activa în timp ce sunt încărcate paginile care folosesc încă vechiul lucrător de servicii. Cu toate acestea, putem accelera acest lucru prin efectuarea unei mici modificări la gestionarul nostru install:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting va face ca activate să se întâmple imediat.
Acum, terminați handlerul activate:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim va face ca noul lucrător de servicii să aibă efect imediat pe toate paginile deschise în domeniul său de aplicare.

chrome://serviceworker-internals în Chrome pentru a vedea toți lucrătorii de servicii pe care browserul i-a înregistrat. (Vizualizați versiunea mare)
Ta-Da!
Acum avem un lucrător de servicii gestionat prin versiune! Puteți vedea fișierul serviceWorker.js actualizat cu gestionarea versiunilor pe GitHub.
Lecturi suplimentare pe SmashingMag:
- A Beginner’s Guide To Progressive Web Apps
- Building A Simple Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web
.