
Acerca de la autora
Lyza Danger Gardner es una dev. Desde que cofundó la startup de web móvil Cloud Four, con sede en Portland, Oregón, en 2007, se ha torturado y emocionado con la …More aboutLyza↬
- 23 min read
- Coding,JavaScript,Techniques,Service Workers
- Saved for offline reading
- Share on Twitter, LinkedIn


No hay escasez de promoción o entusiasmo acerca de la incipiente API de trabajadores de servicios, que ya está disponible en algunos navegadores populares. Hay libros de cocina y entradas de blog, fragmentos de código y herramientas. Pero me parece que cuando quiero aprender un nuevo concepto web a fondo, arremangarse, sumergirse y construir algo desde cero es a menudo ideal.
Los golpes y moretones, gotas y errores que me encontré esta vez tienen beneficios: Ahora entiendo los trabajadores de servicio mucho mejor, y con un poco de suerte puedo ayudarte a evitar algunos de los dolores de cabeza que encontré al trabajar con la nueva API.
Los trabajadores de servicio hacen un montón de cosas diferentes; hay innumerables maneras de aprovechar sus poderes. Decidí construir un simple service worker para mi sitio web (estático, sin complicaciones) que refleja aproximadamente las características que la obsoleta Application Cache API solía proporcionar – es decir:
- hacer que el sitio web funcione fuera de línea,
- aumentar el rendimiento en línea mediante la reducción de las solicitudes de red para ciertos activos,
- proporcionar una experiencia personalizada de retroceso fuera de línea.
Antes de empezar, me gustaría dar las gracias a dos personas cuyo trabajo ha hecho esto posible. En primer lugar, estoy en deuda con Jeremy Keith por la implementación de trabajadores de servicio en su propio sitio web, que sirvió como punto de partida para mi propio código. Me inspiré en su reciente publicación, en la que describe sus experiencias con los trabajadores de servicio. De hecho, mi trabajo es tan fuertemente derivado que no habría escrito sobre él si no fuera por la exhortación de Jeremy en un post anterior:
Así que si decides jugar con los Service Workers, por favor, por favor, comparte tu experiencia.
En segundo lugar, todo tipo de grandes agradecimientos a Jake Archibald por su excelente revisión técnica y comentarios. Siempre es agradable cuando uno de los creadores y evangelistas de la especificación del trabajador de servicio es capaz de ponerlo en claro.
¿Qué es un trabajador de servicio?
Un trabajador de servicio es una secuencia de comandos que se interpone entre su sitio web y la red, dándole, entre otras cosas, la capacidad de interceptar las solicitudes de la red y responder a ellas de diferentes maneras.
Para que su sitio web o aplicación funcione, el navegador obtiene sus activos – tales como páginas HTML, JavaScript, imágenes, fuentes. En el pasado, la gestión de esto era principalmente una prerrogativa del navegador. Si el navegador no podía acceder a la red, probablemente verías su mensaje «Oye, estás desconectado». Había técnicas que se podían utilizar para fomentar el almacenamiento en caché local de los activos, pero el navegador a menudo tenía la última palabra.
Esto no era una gran experiencia para los usuarios que estaban desconectados, y dejaba a los desarrolladores web con poco control sobre el almacenamiento en caché del navegador.
Cue Application Cache (o AppCache), cuya llegada hace varios años parecía prometedora. Aparentemente, permitía dictar cómo debían manejarse los distintos activos, de modo que el sitio web o la aplicación pudieran funcionar sin conexión. Sin embargo, la sencilla sintaxis de AppCache oculta su naturaleza confusa y su falta de flexibilidad.
La incipiente API de trabajadores de servicios puede hacer lo mismo que AppCache, y mucho más. Pero parece un poco desalentador al principio. Las especificaciones hacen una lectura pesada y abstracta, y numerosas APIs están subordinadas a ella o relacionadas de alguna manera: cache, fetch, etc. Los service workers abarcan muchas funcionalidades: notificaciones push y, pronto, sincronización en segundo plano. Comparado con AppCache, parece… complicado.
Mientras que AppCache (que, por cierto, va a desaparecer) era fácil de aprender pero terrible para cada momento posterior (mi opinión), los service workers suponen más una inversión cognitiva inicial, pero son potentes y útiles, y generalmente puedes salir de los problemas si rompes cosas.
Algunos conceptos básicos de los service workers
Un service worker es un archivo con algo de JavaScript en él. En ese archivo puedes escribir JavaScript como lo conoces y te encanta, con algunas cosas importantes a tener en cuenta.
Los scripts de los service workers se ejecutan en un hilo separado en el navegador de las páginas que controlan. Hay maneras de comunicarse entre los trabajadores y las páginas, pero se ejecutan en un ámbito separado. Eso significa que no tendrán acceso al DOM de esas páginas, por ejemplo. Yo visualizo un service worker como una especie de ejecución en una pestaña separada de la página a la que afecta; esto no es del todo exacto, pero es una metáfora aproximada útil para no confundirme.
El javaScript en un service worker no debe bloquearse. Debe utilizar APIs asíncronas. Por ejemplo, no puedes usar localStorage en un service worker (localStorage es una API sincrónica). Humorísticamente, aún sabiendo esto, me las arreglé para correr el riesgo de violarlo, como veremos.
Registrar un Service Worker
Haces que un service worker tenga efecto registrándolo. Este registro se hace desde fuera del service worker, por otra página o script de tu sitio web. En mi sitio web, se incluye un script global site.js en cada página HTML. Yo registro mi service worker desde allí.
Cuando registras un service worker, (opcionalmente) también le dices a qué ámbito debe aplicarse. Puedes instruir a un service worker sólo para que maneje cosas para una parte de tu sitio web (por ejemplo, '/blog/') o puedes registrarlo para todo tu sitio web ('/') como hago yo.
Ciclo de vida del service worker y eventos
Un service worker hace la mayor parte de su trabajo escuchando eventos relevantes y respondiendo a ellos de forma útil. Diferentes eventos se desencadenan en diferentes puntos en el ciclo de vida de un trabajador de servicio.
Una vez que el trabajador de servicio se ha registrado y descargado, se instala en el fondo. Tu service worker puede escuchar el evento install y realizar las tareas apropiadas para esta etapa.
En nuestro caso, queremos aprovechar el estado install para pre-cachear un montón de activos que sabemos que querremos que estén disponibles fuera de línea más tarde.
Después de que la etapa install haya terminado, el service worker se activa. Eso significa que el trabajador de servicio está ahora en control de las cosas dentro de su scope y puede hacer lo suyo. El evento activate no es demasiado emocionante para un nuevo service worker, pero veremos cómo es útil cuando se actualiza un service worker con una nueva versión.
El momento exacto en el que se produce la activación depende de si se trata de un service worker completamente nuevo o de una versión actualizada de un service worker preexistente. Si el navegador no tiene una versión anterior de un trabajador de servicio dado ya registrado, la activación se producirá inmediatamente después de que la instalación se complete.
Una vez que la instalación y la activación se han completado, no se producirán de nuevo hasta que una versión actualizada del trabajador de servicio se descargue y se registre.
Más allá de la instalación y la activación, hoy vamos a ver principalmente el evento fetch para que nuestro trabajador de servicio sea útil. Pero hay varios eventos útiles más allá de eso: eventos de sincronización y eventos de notificación, por ejemplo.
Para un crédito extra o para divertirse, puedes leer más sobre las interfaces que implementan los service workers. Es mediante la implementación de estas interfaces que los service workers obtienen la mayor parte de sus eventos y gran parte de su funcionalidad extendida.
La API basada en promesas del service worker
La API del service worker hace un uso intensivo de Promises. Una promesa representa el resultado eventual de una operación asíncrona, incluso si el valor real no se conocerá hasta que la operación se complete en algún momento en el futuro.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});La función getAnAnswer… devuelve un Promise que (esperamos) finalmente se cumplirá con, o se resolverá a, el answer que estamos buscando. Entonces, ese answer puede ser alimentado a cualquier función manejadora then encadenada, o, en el lamentable caso de que no logre su objetivo, el Promise puede ser rechazado – a menudo con una razón – y las funciones manejadoras catch pueden hacerse cargo de estas situaciones.
Hay más cosas que prometer, pero trataré de mantener los ejemplos aquí sencillos (o al menos comentados). Te insto a que hagas alguna lectura informativa si eres nuevo en las promesas.
Nota: Utilizo ciertas características de ECMAScript6 (o ES2015) en el código de ejemplo para los service workers porque los navegadores que soportan service workers también soportan estas características. Específicamente aquí, estoy usando funciones de flecha y cadenas de plantilla.
Otras necesidades de los service workers
También, ten en cuenta que los service workers requieren HTTPS para funcionar. Hay una importante y útil excepción a esta regla: Los trabajadores de servicio funcionan para localhost en el inseguro http, lo que es un alivio porque la configuración de SSL local es a veces un trabajo pesado.
Dato divertido: Este proyecto me obligó a hacer algo que había estado posponiendo por un tiempo: obtener y configurar SSL para el subdominio www de mi sitio web. Esto es algo que insto a la gente a que considere hacerlo porque casi todas las cosas nuevas y divertidas que lleguen al navegador en el futuro requerirán que se use SSL.
Todo lo que vamos a poner junto funciona hoy en Chrome (yo uso la versión 47). Cualquier día de estos, Firefox 44 se lanzará, y soporta service workers. Is Service Worker Ready? proporciona información granular sobre el soporte en diferentes navegadores.
Registro, instalación y activación de un Service Worker
Ahora que nos hemos ocupado de algo de teoría, podemos empezar a montar nuestro service worker.
Para instalar y activar nuestro service worker, queremos escuchar los eventos install y activate y actuar sobre ellos.
Podemos empezar con un archivo vacío para nuestro service worker y añadir un par de eventListeners. En serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registrando nuestro service worker
Ahora tenemos que decirle a las páginas de nuestro sitio web que usen el service worker.
Recuerda que este registro ocurre desde fuera del service worker – en mi caso, desde dentro de un script (/js/site.js) que se incluye en cada página de mi sitio web.
En mi site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-cachear activos estáticos durante la instalación
Quiero utilizar la etapa de instalación para pre-cachear algunos activos en mi sitio web.
- Al almacenar en caché algunos activos estáticos (imágenes, CSS, JavaScript) que son utilizados por muchas páginas en mi sitio web, puedo acelerar los tiempos de carga mediante la captura de estos de la caché, en lugar de obtener de la red en las cargas de la página posterior.
- Al almacenar en caché una página de reserva fuera de línea, puedo mostrar una página agradable cuando no puedo cumplir con una solicitud de página porque el usuario está fuera de línea.
Los pasos para hacer esto son:
- Dile al evento
installque aguante y que no se complete hasta que haya hecho lo que necesito usandoevent.waitUntil. - Abre el
cacheapropiado, y mete los activos estáticos en él usandoCache.addAll. En el lenguaje de las aplicaciones web progresivas, estos activos conforman mi «shell de la aplicación».
En /serviceWorker.js, vamos a ampliar el manejador install:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});El service worker implementa la interfaz CacheStorage, que hace que la propiedad caches esté disponible globalmente en nuestro service worker. Hay varios métodos útiles en caches – por ejemplo, open y delete.
Puedes ver Promises en funcionamiento aquí: caches.open devuelve un Promise que resuelve a un objeto cache una vez que ha abierto con éxito la caché de static; addAll también devuelve un Promise que resuelve cuando todos los elementos que se le han pasado se han almacenado en la caché.
Le digo al event que espere hasta que el Promise devuelto por mi función manejadora se resuelva con éxito. Entonces podemos estar seguros de que todos esos elementos previos a la caché se resuelven antes de que se complete la instalación.
Confusiones en la consola
Registro de datos
Posiblemente no sea un error, pero sí una confusión: Si console.logdesde los trabajadores de servicio, Chrome seguirá volviendo a mostrar (en lugar de borrar) esos mensajes de registro en las siguientes peticiones de página. Esto puede hacer que parezca que los eventos se disparan demasiadas veces o que el código se ejecuta una y otra vez.
Por ejemplo, añadamos una sentencia log a nuestro manejador install:
self.addEventListener('install', event => { // … as before console.log('installing');});
install en cada carga de página. En su lugar, está mostrando registros antiguos. (Ver versión grande)Un error cuando las cosas están bien
Otra cosa extraña es que una vez que un trabajador de servicio se instala y se activa, las cargas de página posteriores para cualquier página dentro de su ámbito siempre causará un único error en la consola. Pensé que estaba haciendo algo mal.

Lo que hemos logrado hasta ahora
El service worker maneja el evento install y pre-cachea algunos activos estáticos. Si utilizas este service worker y lo registras, efectivamente pre-cacheará los activos indicados pero no podrá aprovecharlos aún sin conexión.
El contenido de serviceWorker.jsestá en GitHub.
Manejo de Fetch con Service Workers
Hasta ahora, nuestro service worker tiene un handler install muy completo pero no hace nada más allá de eso. La magia de nuestro service worker va a ocurrir realmente cuando se disparen los eventos fetch.
Podemos responder a los fetches de diferentes maneras. Mediante el uso de diferentes estrategias de red, podemos decirle al navegador que siempre trate de obtener ciertos activos de la red (asegurándose de que el contenido clave es fresco), mientras que favorece las copias en caché para los activos estáticos – realmente adelgazando nuestras cargas útiles de la página. También podemos proporcionar un buen recurso fuera de línea si todo lo demás falla.
Cada vez que un navegador quiere obtener un activo que está dentro del ámbito de este trabajador de servicio, podemos escuchar sobre él por, sí, la adición de un eventListener en serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});De nuevo, cada obtención que cae dentro del ámbito de este trabajador de servicio (es decir, la ruta) activará este evento – páginas HTML, scripts, imágenes, CSS, lo que sea. Podemos manejar selectivamente la forma en que el navegador responde a cualquiera de estas búsquedas.
¿Deberíamos manejar esta búsqueda?
Cuando se produce un evento fetch para un activo, lo primero que quiero determinar es si este service worker debe interferir con la obtención del recurso dado. De lo contrario, debe no hacer nada y dejar que el navegador afirme su comportamiento por defecto.
Terminaremos con una lógica básica como esta en serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});La función shouldHandleFetch evalúa una solicitud dada para determinar si debemos proporcionar una respuesta o dejar que el navegador afirme su manejo por defecto.
¿Por qué no usar promesas?
Para seguir con la predilección del service worker por las promesas, la primera versión de mi manejador de eventos fetch tenía este aspecto:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Parece lógico, pero estaba cometiendo un par de errores de novato con las promesas. Juro que incluso al principio percibí un olor a código, pero fue Jake quien me puso al corriente de mis errores. (Lección: Como siempre, si el código se siente mal, probablemente lo es.)
Los rechazos de promesas no deben ser utilizados para indicar, «Tengo una respuesta que no me gustó». En su lugar, los rechazos deberían indicar, «Ah, mierda, algo salió mal al intentar obtener la respuesta». Es decir, los rechazos deberían ser excepcionales.
Criterios para las solicitudes válidas
De acuerdo, volvamos a determinar si una determinada solicitud de fetch es aplicable para mi service worker. Los criterios específicos de mi sitio son los siguientes:
- La URL solicitada debe representar algo que quiero almacenar en caché o responder. Su ruta debe coincidir con una
Regular Expressionde rutas válidas. - El método HTTP de la solicitud debe ser
GET. - La solicitud debe ser para un recurso de mi origen (
lyza.com).
Si alguna de las pruebas criteria evalúa a false, no debemos manejar esta solicitud. En serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Por supuesto, los criterios aquí son los míos y variarían de un sitio a otro. event.request es un objeto Request que tiene todo tipo de datos que puedes mirar para evaluar cómo te gustaría que se comportara tu fetch handler.
Nota trivial: Si te has dado cuenta de la incursión de config, pasada como opts a las funciones del handler, bien visto. He eliminado algunos valores reutilizables del tipo config y he creado un objeto config en el ámbito de nivel superior del service worker:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};¿Por qué la lista blanca?
Tal vez te preguntes por qué sólo estoy almacenando en caché cosas con rutas que coinciden con esta expresión regular:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… en lugar de almacenar en caché cualquier cosa que provenga de mi propio origen. Un par de razones:
- No quiero almacenar en caché el propio service worker.
- Cuando estoy desarrollando mi sitio web localmente, algunas peticiones generadas son para cosas que no quiero almacenar en caché. Por ejemplo, uso
browserSync, que lanza un montón de peticiones relacionadas en mi entorno de desarrollo. No quiero almacenar en caché esas cosas. Parecía complicado y desafiante tratar de pensar en todo lo que no quiero almacenar en caché (por no mencionar que es un poco raro tener que explicarlo en la configuración de mi trabajador de servicio). Así que, un enfoque de lista blanca parecía más natural.
Escribiendo el Fetch Handler
Ahora estamos listos para pasar las solicitudes aplicables fetch a un handler. La función onFetch necesita determinar:
- qué tipo de recurso se está solicitando,
- y cómo debería cumplir esta solicitud.
1. ¿Qué tipo de recurso se solicita?
Puedo mirar la cabecera HTTP Accept para obtener una pista sobre el tipo de recurso que se solicita. Esto me ayuda a averiguar cómo quiero manejarlo.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Para mantenerme organizado, quiero meter diferentes tipos de recursos en diferentes cachés. Esto me permitirá gestionar esas cachés más tarde. Estas claves de caché Stringson arbitrarias – puedes llamar a tus cachés como quieras; la API de caché no tiene opiniones.
2. Responder al Fetch
Lo siguiente que debe hacer onFetch es respondToel evento fetch con un Response inteligente.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}¡Cuidado con lo asíncrono!
En nuestro caso, shouldHandleFetch no hace nada asíncrono, y tampoco lo hace onFetch hasta el punto de event.respondWith. Si algo asíncrono hubiera ocurrido antes de eso, estaríamos en problemas. event.respondWith debe ser llamado entre el disparo del evento fetch y el retorno del control al navegador. Lo mismo ocurre con event.waitUntil. Básicamente, si estás manejando un evento, haz algo inmediatamente (sincrónicamente) o dile al navegador que espere hasta que tus cosas asíncronas estén hechas.
Contenido HTML: Implementación de una estrategia de red
Responder a las peticiones de fetch implica implementar una estrategia de red adecuada. Veamos más de cerca la forma en que estamos respondiendo a las solicitudes de contenido HTML (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}La forma en que satisfacemos las solicitudes de contenido aquí es una estrategia que da prioridad a la red. Debido a que el contenido HTML es la principal preocupación de mi sitio web y cambia a menudo, siempre trato de obtener documentos HTML frescos de la red.
Vamos a pasar por esto.
1. Intente obtener el documento de la red
fetch(request) .then(response => addToCache(cacheKey, request, response))Si la solicitud de la red tiene éxito (es decir, la promesa se resuelve), siga adelante y guarde una copia del documento HTML en la caché apropiada (content). A esto se le llama caché de lectura:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Las respuestas sólo pueden usarse una vez.
Necesitamos hacer dos cosas con el response que tenemos:
- Cachéalo,
- Responde al evento con él (es decir, devuélvelo).
Pero los objetos Responsesólo pueden usarse una vez. Al clonarlo, podemos crear una copia para el uso de la caché:
var copy = response.clone();
No almacenes en la caché las malas respuestas. No cometas el mismo error que yo. La primera versión de mi código no tenía esta condicional:
if (response.ok)¡Es muy impresionante acabar con 404 u otras respuestas malas en la caché! Sólo las respuestas felices de la caché.
2. Intentar recuperar de la caché
Si recuperar el activo de la red tiene éxito, hemos terminado. Sin embargo, si no lo hace, es posible que estemos fuera de línea o que la red esté comprometida. Intente recuperar una copia del HTML previamente almacenada en la caché:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Aquí está la función fetchFromCache:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Nota: No indique qué caché desea comprobar con caches.match; compruébelas todas a la vez.
3. Proporcionar un Offline Fallback
Si hemos llegado hasta aquí pero no hay nada en la caché con lo que podamos responder, devuelva un Offline Fallback apropiado, si es posible. En el caso de las páginas HTML, se trata de la página cacheada de /offline/. Es una página razonablemente bien formateada que le dice al usuario que está fuera de línea y que no podemos cumplir lo que busca.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))Y aquí está la función offlineResponse:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}
Otros recursos: Implementación de una estrategia de caché primero
La lógica de obtención de recursos que no sean contenido HTML utiliza una estrategia de caché primero. Las imágenes y otros contenidos estáticos del sitio web rara vez cambian; por lo tanto, compruebe primero la caché y evite el viaje de ida y vuelta a la red.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Los pasos a seguir son:
- intentar recuperar el recurso de la caché;
- si eso falla, intente recuperarlo de la red (con caché de lectura);
- si eso falla, proporcione un recurso de reserva sin conexión, si es posible.
Imagen sin conexión
Podemos devolver una imagen SVG con el texto «Offline» como recurso de reserva sin conexión completando la función offlineResource:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}Y hagamos las actualizaciones pertinentes en config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};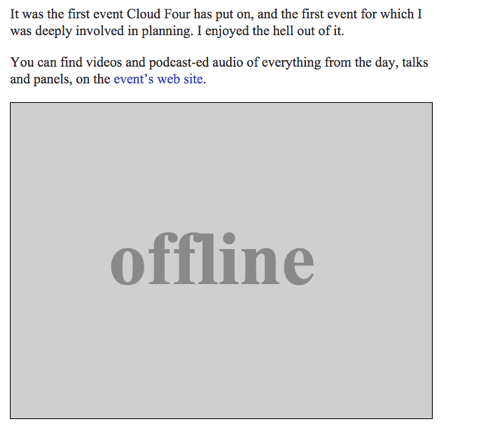
Cuidado con las CDNs
Cuidado con las CDNs si estás restringiendo el manejo de fetch a tu origen. Cuando construí mi primer trabajador de servicio, me olvidé de que mi proveedor de alojamiento sharded activos (imágenes y secuencias de comandos) en su CDN, por lo que ya no fueron servidos desde el origen de mi sitio web (lyza.com). ¡Ups! Eso no funcionó. Terminé deshabilitando el CDN para los activos afectados (pero optimizando esos activos, por supuesto).
Completando la primera versión
La primera versión de nuestro service worker ya está hecha. Tenemos un manejador install y un manejador fetch más completo que puede responder a las búsquedas aplicables con respuestas optimizadas, así como proporcionar recursos en caché y una página sin conexión cuando se desconecta.
A medida que los usuarios navegan por el sitio web, seguirán acumulando más elementos en caché. Cuando estén desconectados, podrán seguir navegando por los elementos que ya tienen almacenados en la caché, o verán una página sin conexión (o una imagen) si el recurso solicitado no está disponible en la caché.
El código completo con el manejo de fetch (serviceWorker.js) está en GitHub.
Versión y actualización del Service Worker
Si nunca más fuera a cambiar nada en nuestra web, podríamos decir que hemos terminado. Sin embargo, los service workers necesitan ser actualizados de vez en cuando. Tal vez quiera añadir más rutas que se puedan almacenar en caché. Tal vez quiera evolucionar la forma en que funcionan mis fallbacks offline. Tal vez hay algo ligeramente buggy en mi trabajador de servicio que quiero arreglar.
Quiero destacar que hay herramientas automatizadas para hacer que la gestión del trabajador de servicio sea parte de su flujo de trabajo, como Service Worker Precache de Google. No necesitas gestionar el versionado de esto a mano. Sin embargo, la complejidad en mi sitio web es lo suficientemente baja como para utilizar una estrategia de versionado humano para gestionar los cambios en mi service worker. Esto consiste en:
- una simple cadena de versión para indicar las versiones,
- implementación de un manejador
activatepara limpiar después de las versiones antiguas, - actualización del manejador
installpara que los service workers actualizadosactivatesean más rápidos.
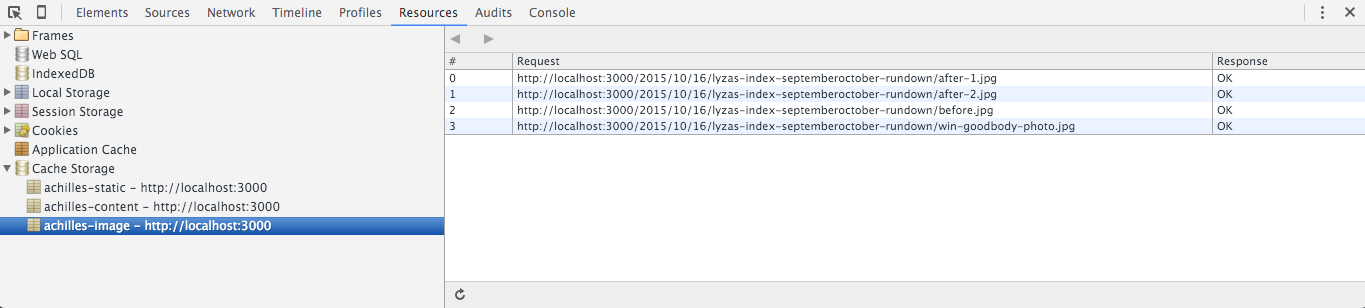
Claves de caché de versión
Puedo añadir una propiedad version a mi objeto config:
version: 'aether'Esto debería cambiar cada vez que quiera desplegar una versión actualizada de mi service worker. Utilizo los nombres de las deidades griegas porque me resultan más interesantes que las cadenas o los números aleatorios.
Nota: He realizado algunos cambios en el código, añadiendo una función de conveniencia (cacheName) para generar claves de caché prefijadas. Es tangencial, así que no la incluyo aquí, pero puedes verla en el código del service worker completado.
achilles.) (Ver versión grande)No cambies el nombre de tu Service Worker
En un momento dado, estuve jugando con las convenciones de nomenclatura para el nombre del archivo del service worker. No haga esto. Si lo hace, el navegador registrará el nuevo trabajador de servicio, pero el viejo trabajador de servicio permanecerá instalado, también. Esta es una situación complicada. Estoy seguro de que hay una solución, pero yo diría que no cambie el nombre de su trabajador de servicio.
No utilice importScripts para config
Yo fui por un camino de poner mi objeto config en un archivo externo y el uso de self.importScripts() en el archivo de trabajador de servicio para tirar de ese script. Eso parecía una manera razonable de gestionar mi config fuera del trabajador de servicio, pero había un obstáculo.
El navegador compara los archivos del trabajador de servicio para determinar si han sido actualizados – así es como sabe cuándo volver a desencadenar un ciclo de descarga e instalación. Los cambios en el config externo no causan ningún cambio en el propio trabajador de servicio, lo que significa que los cambios en el config no estaban causando la actualización del trabajador de servicio. Whoops.
Añadir un manejador de activación
El propósito de tener nombres de caché específicos de la versión es para que podamos limpiar las cachés de las versiones anteriores. Si hay cachés durante la activación que no están prefijados con la cadena de la versión actual, sabremos que deben ser eliminados porque son crufty.
Limpiar cachés antiguos
Podemos utilizar una función para limpiar después de cachés antiguos:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Acelerar la instalación y activación
Un trabajador de servicio actualizado se descargará y se installen el fondo. Ahora es un trabajador en espera. Por defecto, el service worker actualizado no se activará mientras se cargan las páginas que aún utilizan el service worker antiguo. Sin embargo, podemos acelerar esto haciendo un pequeño cambio en nuestro manejador install:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting hará que activate ocurra inmediatamente.
Ahora, termina el manejador activate:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim hará que el nuevo service worker tenga efecto inmediatamente en cualquier página abierta en su ámbito.

chrome://serviceworker-internals en Chrome para ver todos los service workers que el navegador ha registrado. (Ver versión grande)
¡Ta-Da!
¡Ahora tenemos un trabajador de servicios con gestión de versiones! Puedes ver el archivo actualizado serviceWorker.jscon gestión de versiones en GitHub.
Más lecturas en SmashingMag:
- Guía para principiantes de las aplicaciones web progresivas
- Construcción de una sencilla lista de tareas offline entre navegadores
- World Wide Web, Not Wealthy Western Web