
About The Author
Lyza Danger Gardner jest dev. Od czasu współzałożenia w Portland w stanie Oregon mobilnego startupu Cloud Four w 2007 roku, torturuje i ekscytuje się …More aboutLyza↬
- 23 min read
- Coding,JavaScript,Techniques,Service Workers
- Saved for offline reading
- Share on Twitter, LinkedIn


Nie brakuje entuzjazmu i podekscytowania związanego z nowopowstałym API Service Worker, obecnie dostępnym w niektórych popularnych przeglądarkach. Istnieją książki kucharskie i posty na blogach, fragmenty kodu i narzędzia. Ale ja uważam, że kiedy chcę dokładnie poznać nową koncepcję sieciową, zakasanie rękawów, zanurzenie się i zbudowanie czegoś od zera jest często idealnym rozwiązaniem.
Wyboje i siniaki, wpadki i błędy, na które wpadłem tym razem, mają swoje zalety: Teraz rozumiem pracowników usług o wiele lepiej i przy odrobinie szczęścia mogę pomóc ci uniknąć niektórych z bólów głowy, które napotkałem podczas pracy z nowym API.
Pracownicy usług robią wiele różnych rzeczy; istnieją niezliczone sposoby na wykorzystanie ich mocy. Postanowiłem zbudować prostego pracownika serwisowego dla mojej (statycznej, nieskomplikowanej) witryny, który z grubsza odzwierciedla funkcje, które zapewniał przestarzały interfejs API Application Cache – czyli:
- sprawia, że witryna działa w trybie offline,
- zwiększa wydajność online poprzez redukcję żądań sieciowych dla niektórych zasobów,
- zapewnia niestandardowe doświadczenie awaryjne w trybie offline.
Przed rozpoczęciem, chciałbym podziękować dwóm osobom, których praca uczyniła to możliwym. Po pierwsze, jestem ogromnie wdzięczny Jeremy’emu Keithowi za implementację service workers na jego własnej stronie internetowej, która posłużyła jako punkt wyjścia dla mojego własnego kodu. Zainspirował mnie jego ostatni post opisujący jego bieżące doświadczenia z robotami usługowymi. W rzeczywistości moja praca jest tak mocno pochodna, że nie pisałbym o niej, gdyby nie napomnienie Jeremy’ego we wcześniejszym poście:
Więc jeśli zdecydujesz się pobawić z Service Workers, proszę, podziel się swoimi doświadczeniami.
Po drugie, wszelkiego rodzaju wielkie podziękowania dla Jake’a Archibalda za jego wspaniałą recenzję techniczną i informacje zwrotne. Zawsze miło, gdy jeden z twórców i ewangelistów specyfikacji Service Worker jest w stanie ustawić cię prosto!
Czym jest Service Worker?
Skrypt Service Worker to skrypt, który stoi pomiędzy twoją witryną a siecią, dając ci, między innymi, możliwość przechwytywania żądań sieciowych i odpowiadania na nie na różne sposoby.
Aby twoja witryna lub aplikacja działała, przeglądarka pobiera jej zasoby – takie jak strony HTML, JavaScript, obrazy, czcionki. W przeszłości, zarządzanie tym było głównie prerogatywą przeglądarki. Jeśli przeglądarka nie mogła uzyskać dostępu do sieci, prawdopodobnie zobaczyłbyś jej komunikat „Hej, jesteś offline”. Istniały techniki, których można było użyć, aby zachęcić do lokalnego buforowania zasobów, ale przeglądarka często miała ostatnie słowo.
To nie było takie wspaniałe doświadczenie dla użytkowników, którzy byli offline, a to pozostawiło twórców stron internetowych z niewielką kontrolą nad buforowaniem przeglądarki.
Cue Application Cache (lub AppCache), którego przybycie kilka lat temu wydawało się obiecujące. Pozwalał on dyktować, w jaki sposób różne zasoby powinny być obsługiwane, aby witryna lub aplikacja mogła działać w trybie offline. Jednak prosto wyglądająca składnia AppCache’a ukrywała jego zagmatwaną naturę i brak elastyczności.
Rozwijający się Service worker API może zrobić to, co AppCache zrobił, a nawet o wiele więcej. Ale na początku wygląda to trochę zniechęcająco. Specyfikacja jest ciężka i abstrakcyjna, a liczne API są jej podporządkowane lub w inny sposób powiązane: cache, fetch, itd. Service workers obejmują tak wiele funkcjonalności: powiadomienia push i, wkrótce, synchronizację w tle. W porównaniu z AppCache, wygląda to… skomplikowanie.
Whereas AppCache (który, nawiasem mówiąc, odchodzi) był łatwy do nauczenia się, ale okropny w każdej chwili po tym (moja opinia), pracownicy serwisowi są bardziej początkową inwestycją poznawczą, ale są potężni i użyteczni, i generalnie możesz wydostać się z kłopotów, jeśli zepsujesz rzeczy.
Some Basic Service Worker Concepts
A service worker jest plikiem z pewnym JavaScriptem w nim. W tym pliku możesz pisać JavaScript tak jak go znasz i kochasz, z kilkoma ważnymi rzeczami, o których należy pamiętać.
Skrypty robotów usługowych działają w oddzielnym wątku w przeglądarce od stron, które kontrolują. Istnieją sposoby komunikacji między robotami a stronami, ale wykonują się one w oddzielnym zakresie. Oznacza to, że nie będziesz miał dostępu do DOM tych stron, na przykład. Wizualizuję pracownika serwisowego jako działającego w oddzielnej zakładce od strony, na którą ma wpływ; nie jest to wcale dokładne, ale jest to pomocna metafora, która pozwala mi utrzymać się z dala od zamieszania.
JavaScript w pracowniku serwisowym nie może blokować. Musisz używać asynchronicznych interfejsów API. Na przykład nie można używać localStorage w service worker (localStorage jest synchronicznym API). Humorystycznie rzecz biorąc, nawet wiedząc o tym, udało mi się zaryzykować jego naruszenie, jak zobaczymy.
Registering a Service Worker
Uruchamiasz pracownika serwisowego poprzez jego rejestrację. Ta rejestracja jest wykonywana z zewnątrz service worker’a, przez inną stronę lub skrypt w twojej witrynie. Na mojej stronie internetowej, globalny skrypt site.js jest dołączony do każdej strony HTML. Stamtąd rejestruję mojego pracownika serwisu.
Kiedy rejestrujesz pracownika serwisu, (opcjonalnie) mówisz mu również, do jakiego zakresu powinien się zastosować. Możesz poinstruować pracownika serwisu tylko do obsługi rzeczy dla części twojej witryny (na przykład, '/blog/') lub możesz zarejestrować go dla całej witryny ('/'), tak jak ja to robię.
Cykl życia pracownika serwisu i zdarzenia
Pracownik serwisu wykonuje większość swojej pracy przez nasłuchiwanie odpowiednich zdarzeń i odpowiadanie na nie w użyteczny sposób. Różne zdarzenia są wywoływane w różnych punktach cyklu życia pracownika serwisowego.
Po zarejestrowaniu i pobraniu pracownika serwisowego, zostaje on zainstalowany w tle. Twój pracownik serwisowy może nasłuchiwać zdarzenia install i wykonywać zadania odpowiednie dla tego etapu.
W naszym przypadku chcemy wykorzystać stan install do wstępnego buforowania kilku zasobów, o których wiemy, że będą później dostępne offline.
Po zakończeniu etapu install pracownik serwisowy jest aktywowany. Oznacza to, że pracownik serwisu ma teraz kontrolę nad rzeczami w obrębie swojego scope i może robić swoje. Zdarzenie activate nie jest zbyt ekscytujące dla nowego pracownika serwisu, ale zobaczymy, jak jest przydatne podczas uaktualniania pracownika serwisu o nową wersję.
Dokładnie to, kiedy następuje aktywacja, zależy od tego, czy jest to zupełnie nowy pracownik serwisu, czy uaktualniona wersja wcześniej istniejącego pracownika serwisu. Jeśli przeglądarka nie ma już zarejestrowanej poprzedniej wersji danego pracownika serwisu, aktywacja nastąpi natychmiast po zakończeniu instalacji.
Po zakończeniu instalacji i aktywacji nie wystąpią one ponownie, dopóki nie zostanie pobrana i zarejestrowana zaktualizowana wersja pracownika serwisu.
Poza instalacją i aktywacją, aby uczynić naszego pracownika serwisu użytecznym, przyjrzymy się dziś przede wszystkim zdarzeniu fetch. Ale istnieje kilka użytecznych zdarzeń poza tym: zdarzenia synchronizacji i powiadomienia, na przykład.
Dla dodatkowego zaliczenia lub rozrywki możesz przeczytać więcej o interfejsach, które implementują pracownicy usług. To dzięki implementacji tych interfejsów pracownicy usług otrzymują większość swoich zdarzeń i wiele ze swojej rozszerzonej funkcjonalności.
Podstawowy interfejs API pracownika usług
Podstawowy interfejs API pracownika usług intensywnie korzysta z Promises. Obietnica reprezentuje ostateczny rezultat operacji asynchronicznej, nawet jeśli rzeczywista wartość nie będzie znana, dopóki operacja nie zostanie zakończona w przyszłości.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});Funkcja getAnAnswer… zwraca Promise, która (mamy nadzieję) zostanie ostatecznie spełniona przez, lub rozwiązana do answer, którego szukamy. Następnie, ten answer może być podany do dowolnego łańcucha then funkcji obsługi, lub, w smutnym przypadku nieosiągnięcia celu, Promise może być odrzucony – często z powodem – a catch funkcje obsługi mogą zająć się tymi sytuacjami.
W obietnicach jest więcej, ale postaram się utrzymać przykłady tutaj proste (lub przynajmniej skomentowane). Zachęcam do przeczytania kilku pouczających lektur, jeśli jesteś nowy w obietnicach.
Uwaga: Używam pewnych funkcji ECMAScript6 (lub ES2015) w przykładowym kodzie dla pracowników obsługi, ponieważ przeglądarki, które obsługują pracowników obsługi, również obsługują te funkcje. W szczególności używam tutaj funkcji strzałek i łańcuchów szablonów.
Inne potrzeby pracowników usług
Zauważ również, że pracownicy usług wymagają HTTPS do pracy. Istnieje ważny i przydatny wyjątek od tej reguły: Pracownicy usług działają dla localhost na niepewnych http, co jest ulgą, ponieważ ustawienie lokalnego SSL jest czasami żmudne.
Fun fact: Ten projekt zmusił mnie do zrobienia czegoś, co odkładałem na później przez jakiś czas: uzyskanie i skonfigurowanie SSL dla subdomeny www mojej witryny. Jest to coś, do czego zachęcam ludzi, aby rozważyli zrobienie tego, ponieważ prawie wszystkie nowe rzeczy, które trafiają do przeglądarki w przyszłości, będą wymagały użycia SSL.
Wszystkie rzeczy, które połączymy razem, działają dziś w Chrome (używam wersji 47). Lada dzień pojawi się Firefox 44, który obsługuje pracowników usług. Is Service Worker Ready? dostarcza szczegółowych informacji na temat wsparcia w różnych przeglądarkach.
Registering, Installing And Activating A Service Worker
Teraz, gdy zajęliśmy się już pewną teorią, możemy zacząć składać naszego pracownika serwisowego.
Aby zainstalować i aktywować naszego pracownika serwisu, chcemy nasłuchiwać zdarzeń install i activate i działać na nich.
Możemy zacząć od pustego pliku dla naszego pracownika serwisu i dodać kilka eventListeners. W serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registering Our Service Worker
Teraz musimy powiedzieć stronom w naszej witrynie, aby korzystały z service worker.
Pamiętaj, że ta rejestracja odbywa się spoza service worker – w moim przypadku z wnętrza skryptu (/js/site.js), który jest dołączony do każdej strony mojej witryny.
W moim site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-Cache Static Assets During Install
Chcę użyć etapu instalacji do wstępnego buforowania niektórych aktywów na mojej stronie internetowej.
- Przez wstępne buforowanie niektórych statycznych aktywów (obrazy, CSS, JavaScript), które są używane przez wiele stron w mojej witrynie, mogę przyspieszyć czasy ładowania przez pobranie ich z pamięci podręcznej, zamiast pobierania z sieci przy kolejnych załadowaniach strony.
- Przez wstępne buforowanie strony awaryjnej offline, mogę pokazać ładną stronę, gdy nie mogę spełnić żądania strony, ponieważ użytkownik jest offline.
Kroki, aby to zrobić, są następujące:
- Powiedz zdarzeniu
install, aby się wstrzymało i nie kończyło, dopóki nie zrobię tego, co muszę zrobić, używającevent.waitUntil. - Otwórz odpowiedni
cachei umieść w nim statyczne zasoby, używającCache.addAll. W języku progresywnych aplikacji internetowych te aktywa tworzą moją „powłokę aplikacji.”
W /serviceWorker.js rozwińmy install handler:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Pracownik serwisowy implementuje interfejs CacheStorage, co sprawia, że właściwość caches jest dostępna globalnie w naszym pracowniku serwisowym. Istnieje kilka użytecznych metod na caches – na przykład open i delete.
Możesz zobaczyć Promises w pracy tutaj: caches.open zwraca Promise rozwiązujący do obiektu cache, gdy tylko pomyślnie otworzy static cache; addAll zwraca również Promise, który rozwiązuje się, gdy wszystkie przekazane do niego elementy zostały schowane w cache.
Powiadam event, aby czekał, aż Promise zwrócony przez moją funkcję obsługi zostanie pomyślnie rozwiązany. Wtedy możemy być pewni, że wszystkie te elementy pre-cache zostaną posortowane przed zakończeniem instalacji.
Konsolowe pomyłki
Stale logowanie
Prawdopodobnie nie jest to błąd, ale na pewno pomyłka: Jeśli console.log z pracowników usług, Chrome będzie nadal ponownie wyświetlał (a nie usuwał) te komunikaty dziennika na kolejnych żądaniach stron. Może to sprawiać wrażenie, że zdarzenia są uruchamiane zbyt wiele razy lub że kod jest wykonywany w kółko.
Na przykład dodajmy instrukcję log do naszego install handler’a:
self.addEventListener('install', event => { // … as before console.log('installing');});
install przy każdym ładowaniu strony. Zamiast tego pokazuje nieaktualne logi. (Wyświetl dużą wersję)Błąd, gdy wszystko jest w porządku
Inną dziwną rzeczą jest to, że po zainstalowaniu i aktywowaniu pracownika serwisu, kolejne ładowania stron w jego zakresie zawsze powodują pojedynczy błąd w konsoli. Myślałem, że robię coś nie tak.

Co osiągnęliśmy do tej pory
Pracownik serwisowy obsługuje zdarzenie install i wstępnie buforuje niektóre statyczne zasoby. Gdybyś użył tego pracownika serwisu i zarejestrował go, rzeczywiście wstępnie buforowałby wskazane zasoby, ale nie byłby jeszcze w stanie skorzystać z nich w trybie offline.
Treść serviceWorker.js znajduje się na GitHub.
Obsługa pobierania za pomocą robotów serwisowych
Do tej pory nasz robot serwisowy ma dopracowany install handler, ale nie robi nic ponad to. Magia naszego service worker’a wydarzy się naprawdę, gdy fetchzdarzenia zostaną wywołane.
Możemy reagować na fetche na różne sposoby. Używając różnych strategii sieciowych, możemy powiedzieć przeglądarce, aby zawsze próbowała pobierać pewne zasoby z sieci (upewniając się, że kluczowa zawartość jest świeża), jednocześnie faworyzując kopie z pamięci podręcznej dla statycznych zasobów – naprawdę odchudzając nasz ładunek strony. Możemy również zapewnić miły fallback offline, jeśli wszystko inne zawiedzie.
Gdy przeglądarka chce pobrać zasób, który jest w zakresie tego pracownika usług, możemy o tym usłyszeć przez, tak, dodanie eventListener w serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Znowu, każdy fetch, który mieści się w zakresie tego pracownika usług (tj. ścieżka) wywoła to zdarzenie – strony HTML, skrypty, obrazy, CSS, możesz to nazwać. Możemy selektywnie sterować sposobem, w jaki przeglądarka reaguje na każdy z tych pobrań.
Should We Handle This Fetch?
Gdy wystąpi zdarzenie fetch dla zasobu, pierwszą rzeczą, którą chcę określić, jest to, czy ten pracownik serwisu powinien ingerować w pobieranie danego zasobu. W przeciwnym razie nie powinien nic robić i pozwolić przeglądarce na zapewnienie domyślnego zachowania.
Zakończymy z podstawową logiką taką jak ta w serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});Funkcja shouldHandleFetch ocenia dane żądanie, aby określić, czy powinniśmy udzielić odpowiedzi, czy pozwolić przeglądarce na zapewnienie domyślnej obsługi.
Why Not Use Promises?
Aby trzymać się upodobania Service Workera do obietnic, pierwsza wersja mojego fetch event handler’a wyglądała tak:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Wydaje się logiczne, ale popełniałem kilka podstawowych błędów z obietnicami. Przysięgam, że nawet na początku wyczuwałem zapach kodu, ale to Jake wyprostował mnie na błędach moich dróg. (Lekcja: Jak zawsze, jeśli kod wydaje się zły, to prawdopodobnie taki jest.)
Odrzucenia obietnic nie powinny być używane do wskazywania, „Dostałem odpowiedź, która mi się nie spodobała.” Zamiast tego odrzucenia powinny wskazywać, „Ah, crap, coś poszło nie tak podczas próby uzyskania odpowiedzi”. To znaczy, odrzucenia powinny być wyjątkowe.
Kryteria poprawnych żądań
Dobrze, wracając do określania, czy dane żądanie pobierania ma zastosowanie dla mojego pracownika serwisu. Moje kryteria specyficzne dla witryny są następujące:
- Żądany adres URL powinien reprezentować coś, co chcę buforować lub na co chcę odpowiedzieć. Jego ścieżka powinna pasować do
Regular Expressionprawidłowych ścieżek. - Metoda HTTP żądania powinna być
GET. - Żądanie powinno dotyczyć zasobu z mojego pochodzenia (
lyza.com).
Jeśli którykolwiek z testów criteria oceni false, nie powinniśmy obsługiwać tego żądania. W serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Oczywiście, kryteria tutaj są moje własne i różniłyby się w zależności od witryny. event.request jest obiektem Request, który ma wszystkie rodzaje danych, na które możesz spojrzeć, aby ocenić, jak chciałbyś, aby twój handler fetch zachowywał się.
Trywialna uwaga: Jeśli zauważyłeś wtargnięcie config, przekazanego jako opts do funkcji handler, dobrze zauważone. Wyodrębniłem niektóre wartości config podobne do config wielokrotnego użytku i utworzyłem obiekt config w zakresie najwyższego poziomu service worker:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Why Whitelist?
Możesz się zastanawiać, dlaczego buforuję tylko rzeczy ze ścieżkami, które pasują do tego wyrażenia regularnego:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… zamiast buforować wszystko, co pochodzi z mojego własnego źródła. Kilka powodów:
- Nie chcę buforować samego pracownika serwisu.
- Gdy tworzę moją stronę lokalnie, niektóre żądania generowane są dla rzeczy, których nie chcę buforować. Na przykład, używam
browserSync, który wywołuje kilka powiązanych żądań w moim środowisku programistycznym. Nie chcę buforować tych rzeczy! Próba wymyślenia wszystkiego, czego nie chciałbym buforować, wydawała się nieporządna i wymagająca (nie wspominając o tym, że trochę dziwnie jest mieć to wypisane w konfiguracji mojego service worker’a). Tak więc podejście oparte na białej liście wydawało się bardziej naturalne.
Writing The Fetch Handler
Teraz jesteśmy gotowi, aby przekazać odpowiednie fetch żądania do programu obsługi. Funkcja onFetch musi określić:
- jaki rodzaj zasobu jest żądany,
- i w jaki sposób powinienem spełnić to żądanie.
1. What Kind of Resource Is Being Requested?
Mogę spojrzeć na nagłówek HTTP Accept, aby uzyskać podpowiedź, jaki rodzaj zasobu jest wymagany. To pomaga mi dowiedzieć się, jak chcę sobie z tym poradzić.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Aby pozostać zorganizowanym, chcę umieścić różne rodzaje zasobów w różnych pamięciach podręcznych. Pozwoli mi to zarządzać tymi pamięciami podręcznymi później. Te klucze pamięci podręcznej Strings są arbitralne – możesz nazywać swoje pamięci podręczne, jak tylko chcesz; API pamięci podręcznej nie ma opinii.
2. Odpowiedz na Fetch
Następną rzeczą dla onFetch do zrobienia jest respondTo zdarzenie fetch z inteligentnym Response.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Careful With Async!
W naszym przypadku, shouldHandleFetch nie robi nic asynchronicznego, ani też onFetch aż do punktu event.respondWith. Gdyby coś asynchronicznego wydarzyło się przed tym, bylibyśmy w kłopocie. event.respondWith musi zostać wywołane pomiędzy wystrzeleniem zdarzenia fetch a powrotem sterowania do przeglądarki. To samo odnosi się do event.waitUntil. Zasadniczo, jeśli obsługujesz zdarzenie, albo zrób coś natychmiast (synchronicznie), albo powiedz przeglądarce, żeby się wstrzymała, aż twoje asynchroniczne rzeczy zostaną zrobione.
HTML Content: Implementing A Network-First Strategy
Odpowiadanie na żądania fetch wymaga wdrożenia odpowiedniej strategii sieciowej. Przyjrzyjmy się bliżej sposobowi, w jaki odpowiadamy na żądania dotyczące zawartości HTML (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}Sposób, w jaki spełniamy tutaj żądania dotyczące zawartości, to strategia network-first. Ponieważ zawartość HTML jest głównym przedmiotem zainteresowania mojej witryny i często się zmienia, zawsze staram się pobierać świeże dokumenty HTML z sieci.
Przejrzyjmy to krok po kroku.
1. Try Fetching From the Network
fetch(request) .then(response => addToCache(cacheKey, request, response))Jeśli żądanie sieciowe się powiedzie (tzn. obietnica zostanie rozwiązana), przejdź dalej i umieść kopię dokumentu HTML w odpowiedniej pamięci podręcznej (content). Nazywa się to buforowaniem przez odczyt:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Odpowiedzi mogą być użyte tylko raz.
Musimy zrobić dwie rzeczy z response, który mamy:
- buforować go,
- odpowiedzieć na zdarzenie za jego pomocą (tj. zwrócić go).
Ale obiekty Response mogą być użyte tylko raz. Klonując go, jesteśmy w stanie stworzyć kopię do użytku w cache’u:
var copy = response.clone();
Nie buforuj złych odpowiedzi. Nie popełnij tego samego błędu, który ja popełniłem. Pierwsza wersja mojego kodu nie miała tego warunku:
if (response.ok)Pretty awesome skończyć z 404 lub innymi złymi odpowiedziami w pamięci podręcznej! Tylko buforuj szczęśliwe odpowiedzi.
2. Try to Retrieve From Cache
Jeśli pobieranie zasobu z sieci się powiedzie, skończyliśmy. Jeśli jednak tak się nie stanie, możemy być offline lub w inny sposób zagrożeni przez sieć. Spróbuj pobrać wcześniej zbuforowaną kopię HTML z pamięci podręcznej:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Tutaj jest funkcja fetchFromCache:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Uwaga: Nie wskazuj, którą pamięć podręczną chcesz sprawdzić za pomocą caches.match; sprawdź je wszystkie naraz.
3. Provide an Offline Fallback
Jeśli dotarliśmy tak daleko, ale nie ma nic w cache’u, na co moglibyśmy odpowiedzieć, zwróć odpowiedni offline fallback, jeśli to możliwe. Dla stron HTML, jest to strona zbuforowana z /offline/. Jest to dość dobrze sformatowana strona, która mówi użytkownikowi, że jest offline i że nie możemy spełnić tego, czego szuka.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))A oto funkcja offlineResponse:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}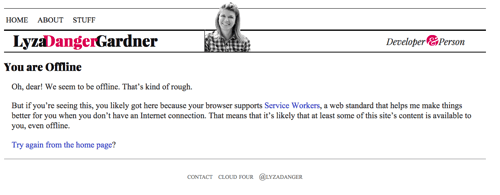
Inne zasoby: Implementing A Cache-First Strategy
Logika pobierania dla zasobów innych niż zawartość HTML wykorzystuje strategię cache-first. Obrazy i inne statyczne treści w witrynie rzadko się zmieniają, dlatego najpierw należy sprawdzić pamięć podręczną i uniknąć podróży przez sieć.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Kroki są następujące:
- próbuj pobrać zasób z pamięci podręcznej;
- jeśli to się nie powiedzie, spróbuj pobrać go z sieci (z buforowaniem przez odczyt);
- jeśli to się nie powiedzie, zapewnij zapasowy zasób offline, jeśli to możliwe.
Offline Image
Możemy zwrócić obraz SVG z tekstem „Offline” jako offline fallback, wykonując funkcję offlineResource:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}I zróbmy odpowiednie aktualizacje do config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};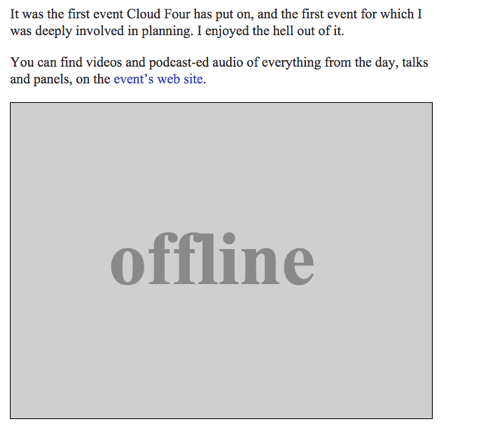
Uwaga na sieci CDN
Uwaga na sieci CDN, jeśli ograniczasz obsługę fetch do swojego źródła. Podczas konstruowania mojego pierwszego service worker’a zapomniałem, że mój dostawca hostingu wydzielił zasoby (obrazy i skrypty) do swojej sieci CDN, tak że nie były one już obsługiwane z miejsca pochodzenia mojej witryny (lyza.com). Ups! To nie zadziałało. Skończyło się na wyłączeniu CDN dla dotkniętych aktywów (ale optymalizując te aktywa, oczywiście!).
Ukończenie pierwszej wersji
Pierwsza wersja naszego pracownika serwisowego jest już gotowa. Mamy install handler i rozbudowany fetch handler, który może odpowiadać na stosowne pobrania ze zoptymalizowanymi odpowiedziami, jak również zapewniać buforowane zasoby i stronę offline, gdy jest offline.
Jak użytkownicy będą przeglądać witrynę, będą nadal budować więcej buforowanych elementów. W trybie offline będą mogli nadal przeglądać elementy, które już mają w pamięci podręcznej, lub zobaczą stronę offline (lub obraz), jeśli żądany zasób nie jest dostępny w pamięci podręcznej.
Pełny kod z obsługą fetch (serviceWorker.js) znajduje się na GitHubie.
Wersja i aktualizacja Service Workera
Gdyby nic już nigdy nie miało się zmienić na naszej stronie, moglibyśmy powiedzieć, że skończyliśmy. Jednak pracownicy serwisowi muszą być od czasu do czasu aktualizowani. Może będę chciał dodać więcej cache’owalnych ścieżek. Może będę chciał rozwinąć sposób w jaki działają moje fallbacki offline. Może jest coś nieco błędnego w moim service worker, co chcę naprawić.
Chcę podkreślić, że istnieją zautomatyzowane narzędzia do uczynienia zarządzania service worker częścią twojego przepływu pracy, takie jak Service Worker Precache od Google. Nie musisz zarządzać wersjonowaniem tego ręcznie. Jednak złożoność na mojej stronie jest na tyle niska, że używam ludzkiej strategii wersjonowania do zarządzania zmianami w moim robotniku serwisowym. Składa się to z:
- prostego łańcucha wersji, aby wskazać wersje,
- implementacja
activatehandler, aby posprzątać po starych wersjach, - aktualizacja
installhandler, aby zaktualizowani pracownicy usługactivateszybciej.
Versioning Cache Keys
Mogę dodać właściwość version do mojego config obiektu:
version: 'aether'To powinno się zmienić za każdym razem, gdy chcę wdrożyć zaktualizowaną wersję mojego pracownika serwisu. Używam imion greckich bóstw, ponieważ są one dla mnie bardziej interesujące niż losowe ciągi lub liczby.
Uwaga: Dokonałem pewnych zmian w kodzie, dodając funkcję wygody (cacheName) do generowania prefiksowanych kluczy pamięci podręcznej. Jest to styczne, więc nie uwzględniam go tutaj, ale możesz go zobaczyć w ukończonym kodzie pracownika usługi.
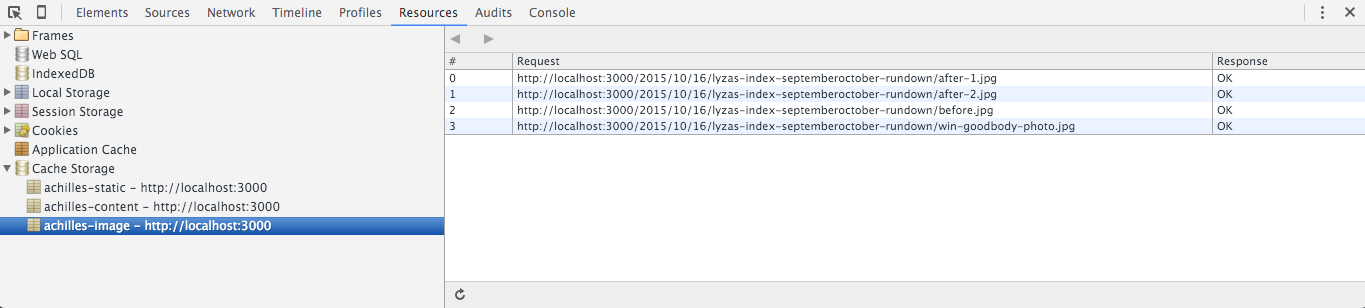
achilles.) (Zobacz dużą wersję)Nie zmieniaj nazwy swojego Service Workera
W pewnym momencie kombinowałem z konwencjami nazewnictwa dla nazwy pliku Service Workera. Nie rób tego. Jeśli to zrobisz, przeglądarka zarejestruje nowego pracownika serwisu, ale stary pracownik serwisu również pozostanie zainstalowany. Jest to nieporządany stan rzeczy. Jestem pewien, że jest jakieś obejście, ale powiedziałbym, żeby nie zmieniać nazwy swojego pracownika serwisu.
Don’t Use importScripts for config
Poszedłem ścieżką umieszczania mojego config obiektu w zewnętrznym pliku i używania self.importScripts() w pliku pracownika serwisu, aby wciągnąć ten skrypt. Wydawało się to rozsądnym sposobem zarządzania moim config poza robotem serwisowym, ale był pewien problem.
Przeglądarka porównuje bajtowo pliki robotów serwisowych, aby określić, czy zostały one zaktualizowane – w ten sposób wie, kiedy ponownie uruchomić cykl pobierania i instalacji. Zmiany w zewnętrznym pliku config nie powodują żadnych zmian w samym pracowniku serwisu, co oznacza, że zmiany w pliku config nie powodowały aktualizacji pracownika serwisu. Whoops.
Adding An Activate Handler
Celem posiadania nazw cache specyficznych dla wersji jest to, że możemy wyczyścić cache z poprzednich wersji. Jeśli podczas aktywacji pojawią się pamięci podręczne, które nie są poprzedzone ciągiem znaków bieżącej wersji, będziemy wiedzieć, że powinny zostać usunięte, ponieważ są „crufty”.
Czyszczenie starych pamięci podręcznych
Możemy użyć funkcji do posprzątania po starych pamięciach podręcznych:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Speeding Up Install and Activate
Zaktualizowany worker usługi zostanie pobrany i będzie install w tle. Jest to teraz robotnik w oczekiwaniu. Domyślnie, zaktualizowany robotnik serwisowy nie będzie aktywowany podczas ładowania stron, które nadal używają starego robotnika serwisowego. Możemy to jednak przyspieszyć, wprowadzając niewielką zmianę w naszym install handlerze:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting spowoduje, że activate wykona się natychmiast.
Teraz zakończ activate handler:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim sprawi, że nowy pracownik serwisu zacznie działać natychmiast na wszystkich otwartych stronach w jego zakresie.

chrome://serviceworker-internals w Chrome, aby zobaczyć wszystkich pracowników serwisu, których zarejestrowała przeglądarka. (Wyświetl dużą wersję)
Ta-Da!
Mamy teraz pracownika serwisu zarządzającego wersjami! Możesz zobaczyć zaktualizowany plik serviceWorker.js z zarządzaniem wersjami na GitHub.
Dalsza lektura na SmashingMag:
- A Beginner’s Guide To Progressive Web Apps
- Building A Simple Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web
.