
Over de auteur
Lyza Danger Gardner is een ontwikkelaar. Sinds ze in 2007 de Portland, Oregon-based mobile web startup Cloud Four oprichtte, heeft ze zichzelf gekweld en opgewonden met …Meer overLyza↬
- 23 min lezen
- Codering,JavaScript,Technieken,Service Workers
- Opgeslagen voor offline lezen
- Delen op Twitter, LinkedIn


Er is geen gebrek aan enthousiasme of opwinding over de prille service worker API, die nu in een aantal populaire browsers wordt geleverd. Er zijn kookboeken en blog posts, code snippets en tools. Maar ik vind dat wanneer ik een nieuw webconcept grondig wil leren, het vaak ideaal is om mijn spreekwoordelijke mouwen op te stropen, erin te duiken en iets van de grond af op te bouwen.
De hobbels en blauwe plekken, gotchas en bugs die ik deze keer tegenkwam, hebben voordelen: Nu begrijp ik service workers een stuk beter, en met een beetje geluk kan ik je helpen een aantal van de hoofdbrekens te vermijden die ik tegenkwam bij het werken met de nieuwe API.
Service workers doen veel verschillende dingen; er zijn talloze manieren om hun krachten te benutten. Ik besloot een eenvoudige servicewerker te bouwen voor mijn (statische, ongecompliceerde) website die ruwweg de functies weerspiegelt die de verouderde Application Cache API vroeger bood – dat wil zeggen:
- de website offline laten functioneren,
- de online prestaties verbeteren door netwerkverzoeken voor bepaalde activa te verminderen,
- een aangepaste offline fallback-ervaring bieden.
Voordat ik begin, wil ik twee mensen bedanken wiens werk dit mogelijk heeft gemaakt. Ten eerste ben ik Jeremy Keith veel dank verschuldigd voor de implementatie van service workers op zijn eigen website, die als uitgangspunt diende voor mijn eigen code. Ik was geïnspireerd door zijn recente post waarin hij zijn ervaringen met service workers beschreef. In feite is mijn werk zo sterk afgeleid dat ik er niet over zou hebben geschreven, behalve Jeremy’s aansporing in een eerdere post:
Dus als je besluit te gaan spelen met Service Workers, deel dan alsjeblieft je ervaringen.
Tweede, heel veel dank aan Jake Archibald voor zijn uitstekende technische review en feedback. Altijd leuk als een van de makers en evangelisten van de service worker specificatie in staat is om je recht te zetten!
Wat is een service worker?
Een service worker is een script dat tussen je website en het netwerk staat, waardoor je onder andere de mogelijkheid hebt om netwerkverzoeken te onderscheppen en er op verschillende manieren op te reageren.
Om je website of app te laten werken, haalt de browser zijn assets op – zoals HTML-pagina’s, JavaScript, afbeeldingen, lettertypes. In het verleden was het beheer hiervan voornamelijk het prerogatief van de browser. Als de browser geen toegang kreeg tot het netwerk, zag je waarschijnlijk het bericht “Hé, je bent offline”. Er waren technieken die je kon gebruiken om het lokaal cachen van assets aan te moedigen, maar de browser had vaak het laatste woord.
Dit was niet zo’n geweldige ervaring voor gebruikers die offline waren, en het liet webontwikkelaars met weinig controle over browser caching.
Cue Application Cache (of AppCache), waarvan de komst enkele jaren geleden veelbelovend leek. Het leek erop dat je kon dicteren hoe verschillende onderdelen moesten worden behandeld, zodat je website of app offline kon werken. Maar AppCache’s eenvoudig ogende syntaxis verraadde zijn onderliggende verwarrende aard en gebrek aan flexibiliteit.
De jonge service worker API kan doen wat AppCache deed, en een heleboel meer. Maar het ziet er een beetje ontmoedigend uit op het eerste gezicht. De specificaties zijn zwaar en abstract, en talloze API’s zijn eraan ondergeschikt of anderszins verwant: cache, fetch, enz. Service workers omvatten zo veel functionaliteit: push notificaties en, binnenkort, synchronisatie op de achtergrond. Vergeleken met AppCache, het ziet er … ingewikkeld.
Waar AppCache (die, door de manier, gaat weg) was gemakkelijk te leren, maar verschrikkelijk voor elk moment daarna (mijn mening), service workers zijn meer van een initiële cognitieve investering, maar ze zijn krachtig en nuttig, en je kunt over het algemeen jezelf uit de problemen als je dingen kapot.
Enkele basis Service Worker Concepten
Een service worker is een bestand met wat JavaScript in het. In dat bestand kun je JavaScript schrijven zoals je dat kent en liefhebt, met een paar belangrijke dingen om in gedachten te houden.
Service worker scripts draaien in een aparte thread in de browser van de pagina’s die ze besturen. Er zijn manieren om te communiceren tussen werkers en pagina’s, maar ze worden uitgevoerd in een aparte scope. Dat betekent dat je geen toegang hebt tot de DOM van die pagina’s, bijvoorbeeld. Ik visualiseer een service worker als een soort van draaiend in een aparte tab van de pagina die het beïnvloedt; dit is helemaal niet nauwkeurig, maar het is een handige ruwe metafoor om mezelf uit de verwarring te houden.
JavaScript in een service worker mag niet blokkeren. U moet asynchrone API’s gebruiken. U kunt bijvoorbeeld localStorage niet gebruiken in een service worker (localStorage is een synchrone API). Humoristisch genoeg, zelfs dit wetende, slaagde ik erin het risico te lopen dit te overtreden, zoals we zullen zien.
Registreren van een Service Worker
Je laat een service worker in werking treden door hem te registreren. Deze registratie wordt gedaan van buiten de service worker, door een andere pagina of script op je website. Op mijn website is op elke HTML-pagina een globaal site.js-script opgenomen. Ik registreer mijn service worker van daaruit.
Wanneer je een service worker registreert, vertel je hem (optioneel) ook op welk bereik hij zich moet richten. U kunt een service worker instrueren om alleen dingen af te handelen voor een deel van uw website (bijvoorbeeld '/blog/') of u kunt hem registreren voor uw hele website ('/') zoals ik doe.
Service Worker Lifecycle And Events
Een service worker doet het grootste deel van zijn werk door te luisteren naar relevante gebeurtenissen en daarop te reageren op een nuttige manier. Verschillende gebeurtenissen worden geactiveerd op verschillende punten in de levenscyclus van een service worker.
Als de service worker is geregistreerd en gedownload, wordt deze op de achtergrond geïnstalleerd. Uw service worker kan luisteren naar de install gebeurtenis en taken uitvoeren die geschikt zijn voor deze fase.
In ons geval willen we profiteren van de install staat om pre-cache een bos van activa die we weten dat we zullen willen offline beschikbaar later.
Nadat de install fase is voltooid, wordt de service worker vervolgens geactiveerd. Dat betekent dat de service worker nu de controle heeft over de dingen binnen zijn scope en zijn ding kan doen. Het activate event is niet al te spannend voor een nieuwe service worker, maar we zullen zien hoe nuttig het is bij het updaten van een service worker met een nieuwe versie.
Het precieze tijdstip waarop activering plaatsvindt, hangt af van de vraag of dit een gloednieuwe service worker is of een bijgewerkte versie van een reeds bestaande service worker. Als de browser geen eerdere versie van een bepaalde service worker al heeft geregistreerd, zal activering onmiddellijk gebeuren nadat de installatie is voltooid.
Als de installatie en activering zijn voltooid, zullen ze niet meer voorkomen totdat een bijgewerkte versie van de service worker is gedownload en geregistreerd.
Naast installatie en activering, zullen we vandaag vooral kijken naar het fetch-gebeurtenis om onze service worker nuttig te maken. Maar er zijn verschillende nuttige gebeurtenissen buiten dat: sync gebeurtenissen en kennisgeving gebeurtenissen, bijvoorbeeld.
Voor extra krediet of vrije tijd plezier, kunt u meer lezen over de interfaces die service workers implementeren. Het is door het implementeren van deze interfaces dat service workers het grootste deel van hun gebeurtenissen en veel van hun uitgebreide functionaliteit krijgen.
The Service Worker’s Promise-Based API
The service worker API maakt zwaar gebruik van Promises. Een belofte vertegenwoordigt het uiteindelijke resultaat van een asynchrone bewerking, zelfs als de werkelijke waarde niet bekend zal zijn totdat de bewerking enige tijd in de toekomst is voltooid.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});De getAnAnswer… functie retourneert een Promise die (we hopen) uiteindelijk zal worden vervuld door, of oplossen naar, de answer waarnaar we op zoek zijn. Dan kan die answer worden toegevoerd aan een keten van then handler functies, of, in het droevige geval dat het doel niet wordt bereikt, kan de Promise worden afgewezen – vaak met een reden – en catch handler functies kunnen voor deze situaties zorgen.
Er is meer te beloven, maar ik zal proberen de voorbeelden hier eenvoudig te houden (of op zijn minst becommentarieerd). Ik dring erop aan dat je wat informatieve lectuur doet als je nieuw bent met promises.
Note: Ik gebruik bepaalde ECMAScript6 (of ES2015) functies in de voorbeeldcode voor service workers omdat browsers die service workers ondersteunen, deze functies ook ondersteunen. Specifiek hier, gebruik ik pijl functies en sjabloon strings.
Andere Service Worker benodigdheden
Ook, merk op dat service workers HTTPS nodig hebben om te werken. Er is een belangrijke en nuttige uitzondering op deze regel: Service workers werken voor localhost op onveilige http, wat een opluchting is omdat het opzetten van lokale SSL soms een ploeterpartij is.
Fun fact: Dit project dwong me om iets te doen dat ik al een tijdje had uitgesteld: het verkrijgen en configureren van SSL voor het www subdomein van mijn website. Dit is iets wat ik mensen dringend wil aanraden om te overwegen, omdat vrijwel alle leuke nieuwe dingen die in de toekomst in de browser komen, SSL vereisen.
Alle dingen die we zullen samenstellen, werken vandaag in Chrome (ik gebruik versie 47). Firefox 44 kan elk moment uitkomen, en het ondersteunt service workers. Is Service Worker Ready? biedt gedetailleerde informatie over ondersteuning in verschillende browsers.
Registreren, Installeren en Activeren van een Service Worker
Nu we hebben gezorgd voor een aantal theorie, kunnen we beginnen met het samenstellen van onze service worker.
Om onze service worker te installeren en te activeren, willen we luisteren naar install en activate events en daarop acteren.
We kunnen beginnen met een leeg bestand voor onze service worker en een paar eventListeners toevoegen. In serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registratie van onze service worker
Nu moeten we de pagina’s op onze website vertellen om de service worker te gebruiken.
Bedenk dat deze registratie gebeurt van buiten de service worker – in mijn geval, van binnen een script (/js/site.js) dat op elke pagina van mijn website is opgenomen.
In mijn site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-Caching Static Assets During Install
Ik wil de install-fase gebruiken om sommige assets op mijn website te pre-cachen.
- Door sommige statische elementen (afbeeldingen, CSS, JavaScript) die door veel pagina’s op mijn website worden gebruikt vooraf te cachen, kan ik de laadtijd versnellen door ze uit de cache te halen, in plaats van ze bij een volgende paginalading uit het netwerk op te halen.
- Door een offline fallback pagina vooraf te cachen, kan ik een mooie pagina laten zien als ik niet aan een paginaverzoek kan voldoen omdat de gebruiker offline is.
De stappen om dit te doen zijn:
- Tell de
installevent te hangen en niet te voltooien totdat ik heb gedaan wat ik moet doen door gebruik te maken vanevent.waitUntil. - Open de juiste
cache, en plak de statische activa in het door gebruik te maken vanCache.addAll. In progressive web app jargon, vormen deze assets mijn “applicatie schil.”
In /serviceWorker.js, laten we de install handler uitbreiden:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});De service worker implementeert de CacheStorage interface, die de caches eigenschap globaal beschikbaar maakt in onze service worker. Er zijn verschillende nuttige methoden op caches – bijvoorbeeld open en delete.
U kunt Promises hier aan het werk zien: caches.open retourneert een Promise die resolveert naar een cache object zodra het met succes de static cache heeft geopend; addAll retourneert ook een Promise die resolveert wanneer alle items die eraan zijn doorgegeven in de cache zijn gestouwd.
Ik vertel de event om te wachten totdat de Promise geretourneerd door mijn handler-functie met succes is resolved. Dan kunnen we er zeker van zijn dat al die pre-cache items worden gesorteerd voordat de installatie is voltooid.
Console Confusions
Stale Logging
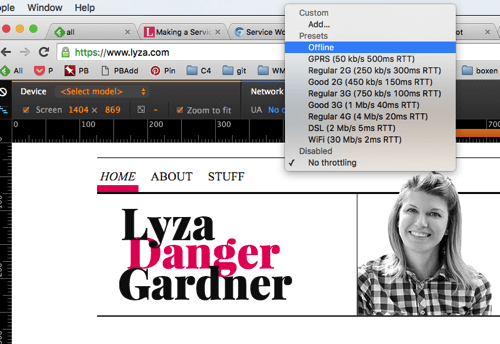
Misschien geen bug, maar zeker een verwarring: Als u console.log uit service workers haalt, blijft Chrome die logberichten opnieuw weergeven (in plaats van ze te wissen) bij volgende paginaverzoeken. Hierdoor kan het lijken alsof events te vaak worden uitgevoerd of alsof code steeds opnieuw wordt uitgevoerd.
Schrijven we bijvoorbeeld een log-instructie toe aan onze install-handler:
self.addEventListener('install', event => { // … as before console.log('installing');});
install-gebeurtenis niet echt af bij elke pagina die wordt geladen. In plaats daarvan worden oude logboeken weergegeven. (Grote versie weergeven)Een foutmelding wanneer alles in orde is
Een ander vreemd iets is dat wanneer een service worker eenmaal is geïnstalleerd en geactiveerd, de volgende pagina’s die worden geladen voor pagina’s die binnen het bereik vallen, altijd een enkele foutmelding in de console veroorzaken. Ik dacht dat ik iets verkeerd deed.

Wat we tot nu toe hebben bereikt
De service worker handelt de install-gebeurtenis af en slaat een aantal statische elementen op in de cache. Als je deze service worker zou gebruiken en hem zou registreren, zou hij inderdaad de aangegeven assets pre-cachen, maar nog niet in staat zijn om er offline voordeel uit te halen.
De inhoud van serviceWorker.js staat op GitHub.
Fetch Handling With Service Workers
Tot nu toe heeft onze service worker een uitgewerkte install handler, maar doet niets anders dan dat. De magie van onze service worker gaat echt gebeuren wanneer fetch gebeurtenissen worden getriggerd.
We kunnen op verschillende manieren reageren op fetches. Door het gebruik van verschillende netwerk strategieën, kunnen we de browser vertellen om altijd te proberen om bepaalde middelen op te halen uit het netwerk (ervoor te zorgen dat de belangrijkste inhoud vers is), terwijl de voorkeur aan gecachede kopieën voor statische activa – echt afslanken onze pagina payloads. We kunnen ook een mooie offline fallback bieden als al het andere faalt.
Wanneer een browser een asset wil ophalen die binnen het bereik van deze service worker valt, kunnen we dat horen door, jawel, een eventListener toe te voegen in serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Alweer, elke fetch die binnen het bereik van deze service worker valt (d.w.z. het pad) zal dit event triggeren – HTML pagina’s, scripts, afbeeldingen, CSS, noem maar op. We kunnen selectief omgaan met de manier waarop de browser reageert op elk van deze fetches.
Hoe moeten we deze fetch afhandelen?
Wanneer een fetch event optreedt voor een asset, is het eerste wat ik wil bepalen of deze service worker zich moet bemoeien met het ophalen van de gegeven resource. Zo niet, dan moet hij niets doen en de browser zijn standaard gedrag laten bevestigen.
We eindigen met basis logica zoals deze in serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});De shouldHandleFetch functie beoordeelt een gegeven verzoek om te bepalen of we een antwoord moeten geven of dat we de browser zijn standaard gedrag moeten laten bevestigen.
Waarom geen beloftes gebruiken?
Om me aan te passen aan de voorliefde van de service worker voor beloftes, zag de eerste versie van mijn fetch event handler er als volgt uit:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Lijkt logisch, maar ik maakte een paar beginnersfouten met beloftes. Ik zweer dat ik een code geur voelde, zelfs in het begin, maar het was Jake die me op mijn fouten wees. (Les: Zoals altijd, als code verkeerd aanvoelt, is het dat waarschijnlijk ook.)
Weigeringen van beloftes moeten niet worden gebruikt om aan te geven: “Ik heb een antwoord gekregen dat ik niet leuk vond.” In plaats daarvan moeten afwijzingen aangeven: “Ah, verdorie, er is iets misgegaan bij het proberen te krijgen van het antwoord.” Dat wil zeggen, afwijzingen moeten uitzonderlijk zijn.
Criteria voor geldige verzoeken
Nou, terug naar het bepalen of een gegeven fetch-verzoek van toepassing is op mijn servicewerker. Mijn site-specifieke criteria zijn als volgt:
- De aangevraagde URL moet iets voorstellen dat ik wil cachen of waarop ik wil reageren. Het pad moet overeenkomen met een
Regular Expressionvan geldige paden. - De HTTP-methode van het verzoek moet
GETzijn. - Het verzoek moet zijn voor een bron van mijn oorsprong (
lyza.com).
Als een van de criteria-tests evalueert tot false, moeten we dit verzoek niet behandelen. In serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}De criteria hier zijn natuurlijk mijn eigen en zouden variëren van site tot site. event.request is een Request-object dat allerlei gegevens bevat waarnaar je kunt kijken om te beoordelen hoe je wilt dat je fetch handler zich gedraagt.
Triviale opmerking: Als je de inval van config hebt opgemerkt, doorgegeven als opts aan handler functies, goed gezien. Ik heb een aantal herbruikbare config-achtige waarden eruit gehaald en een config-object gemaakt in de top-level scope van de service worker:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Waarom whitelist?
Je vraagt je misschien af waarom ik alleen dingen cach met paden die overeenkomen met deze reguliere expressie:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… in plaats van alles te cachen dat afkomstig is van mijn eigen bron. Een paar redenen:
- Ik wil de service worker zelf niet cachen.
- Wanneer ik mijn website lokaal ontwikkel, zijn sommige verzoeken die gegenereerd worden voor dingen die ik niet wil cachen. Ik gebruik bijvoorbeeld
browserSync, wat een heleboel gerelateerde verzoeken in mijn ontwikkelomgeving genereert. Ik wil dat spul niet cachen! Het leek rommelig en uitdagend om alles te bedenken wat ik niet wil cachen (om nog maar te zwijgen van het feit dat het een beetje vreemd is om het in de configuratie van mijn service worker te moeten spellen). Dus een whitelist aanpak leek meer natuurlijk.
Het schrijven van de Fetch Handler
Nu zijn we klaar om van toepassing zijnde fetch verzoeken door te geven aan een handler. De onFetch functie moet bepalen:
- wat voor soort bron er wordt opgevraagd,
- en hoe ik aan dit verzoek moet voldoen.
1.
Ik kan naar de HTTP Accept header kijken om een hint te krijgen over wat voor soort bron er wordt aangevraagd. Dit helpt me om uit te vinden hoe ik het wil behandelen.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Om georganiseerd te blijven, wil ik verschillende soorten bronnen in verschillende caches stoppen. Zo kan ik die caches later beheren. Deze cache sleutel Strings zijn willekeurig – u kunt uw caches noemen zoals u wilt; de cache API heeft geen meningen.
2. Reageer op de Fetch
Het volgende voor onFetch om te doen is om respondTo de fetch gebeurtenis met een intelligente Response.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Voorzichtig met Async!
In ons geval doet shouldHandleFetch niets asynchroon, en onFetch ook niet tot het punt van event.respondWith. Als daarvoor iets asynchroon was gebeurd, zouden we in de problemen zitten. event.respondWith moet worden aangeroepen tussen de gebeurtenis fetch en de terugkeer van de controle naar de browser. Hetzelfde geldt voor event.waitUntil. Als je een event afhandelt, doe je iets onmiddellijk (synchroon) of vertel je de browser dat hij moet wachten tot je asynchrone dingen gedaan zijn.
HTML-inhoud: Implementing A Network-First Strategy
Het beantwoorden van fetch-verzoeken impliceert het implementeren van een geschikte netwerkstrategie. Laten we eens nader kijken naar de manier waarop we reageren op verzoeken om HTML-inhoud (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}De manier waarop we hier verzoeken om inhoud afhandelen is een netwerk-eerst-strategie. Omdat HTML-inhoud de kern van mijn website is en vaak verandert, probeer ik altijd verse HTML-documenten van het netwerk te halen.
Laten we hier eens doorheen stappen.
1. Probeer op te halen van het netwerk
fetch(request) .then(response => addToCache(cacheKey, request, response))Als het netwerkverzoek succesvol is (d.w.z. de belofte wordt opgelost), ga je gang en bewaar een kopie van het HTML-document in de daarvoor bestemde cache (content). Dit heet read-through caching:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Responses mogen slechts eenmaal worden gebruikt.
We moeten twee dingen doen met de response die we hebben:
- cache het,
- beantwoord de gebeurtenis ermee (d.w.z. retourneer het).
Maar Response-objecten mogen slechts eenmaal worden gebruikt. Door het te klonen, kunnen we een kopie maken voor gebruik in de cache:
var copy = response.clone();
Gebruik geen slechte reacties in de cache. Maak niet dezelfde fout als ik heb gemaakt. De eerste versie van mijn code had deze voorwaarde niet:
if (response.ok)Geweldig om te eindigen met 404 of andere slechte reacties in de cache! Alleen goede reacties in de cache.
2. Probeer op te halen uit de cache
Als het lukt om de asset op te halen uit het netwerk, zijn we klaar. Maar als dat niet lukt, zijn we misschien offline of hebben we op een andere manier netwerkproblemen. Probeer een eerder opgeslagen kopie van de HTML uit de cache te halen:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Hier is de fetchFromCache functie:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Note: Geef niet aan welke cache je wilt controleren met caches.match; controleer ze allemaal tegelijk.
3. Zorg voor een Offline Fallback
Als we zover zijn gekomen, maar er is niets in de cache waarmee we kunnen reageren, geef dan een passende Offline Fallback terug, indien mogelijk. Voor HTML pagina’s is dit de pagina in de cache van /offline/. Het is een redelijk goed opgemaakte pagina die de gebruiker vertelt dat hij offline is en dat we niet kunnen voldoen aan wat hij zoekt.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))En hier is de offlineResponse functie:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}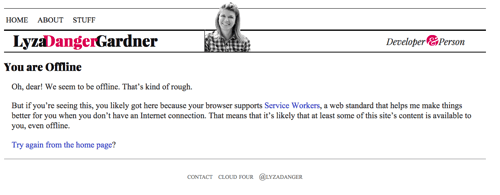
Andere bronnen: Implementing A Cache-First Strategy
De fetch-logica voor andere bronnen dan HTML-inhoud maakt gebruik van een cache-first-strategie. Afbeeldingen en andere statische inhoud op de website veranderen zelden; controleer dus eerst de cache en vermijd de netwerkroundtrip.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));De stappen hier zijn:
- probeer de asset uit de cache op te halen;
- als dat niet lukt, probeer dan op te halen uit het netwerk (met read-through caching);
- als dat niet lukt, zorg dan voor een offline fallback-resource, indien mogelijk.
Offline-afbeelding
We kunnen een SVG-afbeelding met de tekst “Offline” als offline fallback teruggeven door de offlineResource-functie in te vullen:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}En laten we de relevante updates in config aanbrengen:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};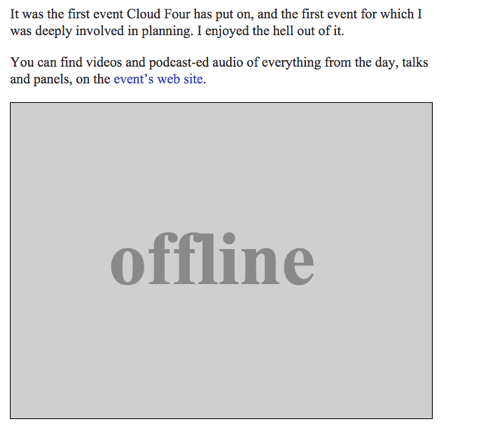
Watch out for CDNs
Watch out for CDNs als je de fetch handling beperkt tot je origin. Toen ik mijn eerste serviceworker bouwde, vergat ik dat mijn hostingprovider assets (afbeeldingen en scripts) naar zijn CDN shardde, zodat ze niet langer werden geserveerd vanaf de origin van mijn website (lyza.com). Oeps! Dat werkte niet. Ik heb uiteindelijk het CDN uitgeschakeld voor de betreffende assets (maar die assets wel geoptimaliseerd, natuurlijk!).
Voltooiing van de eerste versie
De eerste versie van onze service worker is nu klaar. We hebben een install handler en een uitgebreide fetch handler, die kan reageren op toepasselijke fetches met geoptimaliseerde reacties, evenals het verstrekken van cached resources en een offline pagina wanneer offline.
Als gebruikers surfen op de website, zullen ze blijven opbouwen van meer cached items.
De volledige code met fetch-handling (serviceWorker.js) staat op GitHub.
Versioneren en bijwerken van de serviceworker
Als er nooit meer iets zou veranderen op onze website, zouden we kunnen zeggen dat we klaar zijn. Maar, service workers moeten van tijd tot tijd worden bijgewerkt. Misschien wil ik meer cache-bare paden toevoegen. Misschien wil ik de manier waarop mijn offline fallbacks werken evolueren. Misschien is er iets licht buggy in mijn service worker dat ik wil repareren.
Ik wil benadrukken dat er geautomatiseerde tools zijn om service-worker management onderdeel te maken van je workflow, zoals Service Worker Precache van Google. Je hoeft het versiebeheer niet met de hand te doen. Echter, de complexiteit op mijn website is laag genoeg dat ik een menselijke versiebeheer strategie gebruik om veranderingen aan mijn service worker te beheren. Dit bestaat uit:
- een eenvoudige versie string om versies aan te geven,
- implementatie van een
activatehandler om op te ruimen na oude versies, - updating van de
installhandler om bijgewerkte service workersactivatesneller te maken.
Versioning Cache Keys
Ik kan een version eigenschap aan mijn config object toevoegen:
version: 'aether'Dit moet veranderen elke keer als ik een bijgewerkte versie van mijn service worker wil uitrollen. Ik gebruik de namen van Griekse goden omdat ze interessanter voor me zijn dan willekeurige strings of getallen.
Note: Ik heb wat wijzigingen aangebracht in de code, en een handige functie (cacheName) toegevoegd om vooraf bepaalde cache sleutels te genereren. Deze functie is niet relevant, dus ik laat hem hier buiten beschouwing, maar je kunt hem zien in de voltooide code van de servicewerker.
achilles.) (Bekijk de grote versie)Benoem uw servicewerker niet
Op een gegeven moment was ik aan het rommelen met naamgevingsconventies voor de bestandsnaam van de servicewerker. Doe dit niet. Als je dat wel doet, zal de browser de nieuwe service worker registreren, maar de oude service worker zal ook geïnstalleerd blijven. Dit is een rommelige situatie. Ik weet zeker dat er een workaround is, maar ik zou zeggen: hernoem je service worker niet.
Gebruik geen importScripts voor config
Ik heb mijn config object in een extern bestand gezet en heb self.importScripts() in het service worker bestand gebruikt om dat script binnen te halen. Dat leek een redelijke manier om mijn config buiten de service worker te beheren, maar er was een kink in de kabel.
De browser byte-vergelijkt service worker-bestanden om te bepalen of ze zijn bijgewerkt – dat is hoe het weet wanneer het een download-en-installatiecyclus opnieuw moet triggeren. Veranderingen in de externe config veroorzaken geen veranderingen in de service worker zelf, wat betekent dat veranderingen in de config er niet toe leidden dat de service worker werd geupdate. Whoops.
Adding An Activate Handler
Het doel van het hebben van versie-specifieke cache namen is zodat we caches van vorige versies kunnen opruimen. Als er tijdens de activatie caches zijn die niet de huidige versiestring hebben, weten we dat ze verwijderd moeten worden omdat ze crufty zijn.
Opruimen van oude caches
We kunnen een functie gebruiken om op te ruimen na oude caches:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Versnellen van Installeren en Activeren
Een bijgewerkte service worker wordt gedownload en zal install in de achtergrond draaien. Het is nu een werker in afwachting. Standaard zal de bijgewerkte service worker niet activeren terwijl pagina’s worden geladen die nog gebruik maken van de oude service worker. We kunnen dat echter versnellen door een kleine wijziging aan te brengen in onze install handler:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting zal ervoor zorgen dat activate onmiddellijk gebeurt.
Nu, maak de activate handler af:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim zorgt ervoor dat de nieuwe service worker onmiddellijk van kracht wordt op alle open pagina’s in zijn bereik.

chrome://serviceworker-internals in Chrome gebruiken om alle service workers te zien die de browser heeft geregistreerd. (Grote versie weergeven)
Ta-Da!
We hebben nu een versiebeheerde servicewerker! U kunt het bijgewerkte serviceWorker.js-bestand met versiebeheer bekijken op GitHub.
Verder lezen op SmashingMag:
- A Beginner’s Guide To Progressive Web Apps
- Building A Simple Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web