
Über die Autorin
Lyza Danger Gardner ist eine Entwicklerin. Seit sie 2007 das mobile Web-Startup Cloud Four in Portland, Oregon, mitbegründet hat, quält und begeistert sie sich mit …Mehr überLyza↬
- 23 min read
- Coding,JavaScript,Techniques,Service Workers
- Saved for offline reading
- Share on Twitter, LinkedIn


Es gibt keinen Mangel an Aufmunterung oder Aufregung über die junge Service Worker API, die jetzt in einigen populären Browsern verfügbar ist. Es gibt Kochbücher und Blogeinträge, Codeschnipsel und Tools. Aber wenn ich ein neues Webkonzept gründlich erlernen will, ist es oft ideal, die sprichwörtlichen Ärmel hochzukrempeln, einzutauchen und etwas von Grund auf neu zu entwickeln.
Die Beulen und blauen Flecken, Probleme und Fehler, auf die ich dieses Mal gestoßen bin, haben Vorteile: Jetzt verstehe ich Service Worker viel besser, und mit etwas Glück kann ich Ihnen helfen, einige der Kopfschmerzen zu vermeiden, auf die ich bei der Arbeit mit der neuen API gestoßen bin.
Service Worker können viele verschiedene Dinge tun; es gibt unzählige Möglichkeiten, sich ihre Fähigkeiten zunutze zu machen. Ich habe mich entschlossen, einen einfachen Service Worker für meine (statische, unkomplizierte) Website zu erstellen, der in etwa die Funktionen widerspiegelt, die die veraltete Application Cache API bot, nämlich:
- die Website offline funktionieren zu lassen,
- die Online-Leistung zu erhöhen, indem Netzwerkanforderungen für bestimmte Assets reduziert werden,
- ein individuelles Offline-Fallback-Erlebnis zu bieten.
Bevor ich beginne, möchte ich mich bei zwei Personen bedanken, deren Arbeit dies möglich gemacht hat. Erstens bin ich Jeremy Keith zu großem Dank verpflichtet für die Implementierung von Service Workern auf seiner eigenen Website, die mir als Ausgangspunkt für meinen eigenen Code diente. Ich wurde von seinem jüngsten Beitrag inspiriert, in dem er seine Erfahrungen mit Service Workern beschreibt. Tatsächlich ist meine Arbeit so stark abgeleitet, dass ich nicht darüber geschrieben hätte, wäre da nicht Jeremys Ermahnung in einem früheren Beitrag gewesen:
Wenn Sie sich also entscheiden, mit Service Workern herumzuspielen, teilen Sie bitte, bitte Ihre Erfahrungen mit.
Zweitens, ein großes Dankeschön an Jake Archibald für seine ausgezeichnete technische Überprüfung und sein Feedback. Es ist immer schön, wenn einer der Schöpfer und Verfechter der Service-Worker-Spezifikation in der Lage ist, die Dinge richtig zu stellen!
Was ist ein Service-Worker?
Ein Service-Worker ist ein Skript, das zwischen Ihrer Website und dem Netzwerk steht und Ihnen unter anderem die Möglichkeit gibt, Netzwerkanfragen abzufangen und auf verschiedene Weise darauf zu reagieren.
Damit Ihre Website oder App funktioniert, holt der Browser seine Assets – wie HTML-Seiten, JavaScript, Bilder, Schriftarten. In der Vergangenheit war die Verwaltung dieser Daten hauptsächlich Sache des Browsers. Wenn der Browser nicht auf das Netzwerk zugreifen konnte, wurde wahrscheinlich die Meldung „Hey, du bist offline“ angezeigt. Es gab Techniken, mit denen man die lokale Zwischenspeicherung von Inhalten fördern konnte, aber der Browser hatte oft das letzte Wort.
Das war keine gute Erfahrung für Benutzer, die offline waren, und ließ Webentwicklern nur wenig Kontrolle über die Browser-Zwischenspeicherung.
Stichwort Application Cache (oder AppCache), dessen Ankunft vor einigen Jahren vielversprechend schien. Angeblich konnten Sie damit festlegen, wie verschiedene Assets behandelt werden sollten, damit Ihre Website oder Anwendung auch offline funktionieren konnte. Doch die einfach aussehende Syntax von AppCache täuschte über seine verwirrende Natur und mangelnde Flexibilität hinweg.
Die noch junge Service Worker API kann das, was AppCache konnte, und noch viel mehr. Auf den ersten Blick wirkt sie jedoch etwas entmutigend. Die Spezifikationen sind schwer und abstrakt zu lesen, und zahlreiche APIs sind ihr untergeordnet oder anderweitig mit ihr verbunden: cache, fetch, usw. Service Worker umfassen so viele Funktionen: Push-Benachrichtigungen und bald auch Hintergrundsynchronisierung. Im Vergleich zu AppCache sieht es… kompliziert aus.
Während AppCache (das übrigens nicht mehr weiterentwickelt wird) leicht zu erlernen, aber für jeden einzelnen Moment danach schrecklich war (meine Meinung), sind Service Worker eher eine anfängliche kognitive Investition, aber sie sind mächtig und nützlich, und man kann sich in der Regel selbst aus Schwierigkeiten befreien, wenn man Dinge kaputt macht.
Ein paar grundlegende Service Worker Konzepte
Ein Service Worker ist eine Datei mit etwas JavaScript darin. In dieser Datei können Sie JavaScript schreiben, wie Sie es kennen und lieben, wobei einige wichtige Dinge zu beachten sind.
Service-Worker-Skripte laufen in einem separaten Thread im Browser von den Seiten, die sie steuern. Es gibt Möglichkeiten, zwischen Workern und Seiten zu kommunizieren, aber sie werden in einem separaten Bereich ausgeführt. Das bedeutet, dass Sie z. B. keinen Zugriff auf das DOM dieser Seiten haben. Ich stelle mir einen Service-Worker so vor, als würde er in einem separaten Tab von der Seite laufen, die er steuert; das ist nicht ganz korrekt, aber es ist eine hilfreiche grobe Metapher, um mich nicht zu verwirren.
JavaScript in einem Service-Worker darf nicht blockieren. Sie müssen asynchrone APIs verwenden. Zum Beispiel können Sie localStorage nicht in einem Service Worker verwenden (localStorage ist eine synchrone API). Lustigerweise bin ich trotz dieses Wissens in die Gefahr geraten, dagegen zu verstoßen, wie wir sehen werden.
Registrierung eines Service Workers
Sie setzen einen Service Worker in Kraft, indem Sie ihn registrieren. Diese Registrierung erfolgt von außerhalb des Service Workers, durch eine andere Seite oder ein Skript auf Ihrer Website. Auf meiner Website ist ein globales site.js-Skript auf jeder HTML-Seite enthalten. Von dort aus registriere ich meinen Service-Worker.
Wenn Sie einen Service-Worker registrieren, teilen Sie ihm (optional) auch mit, für welchen Bereich er sich einsetzen soll. Sie können einen Service Worker anweisen, nur einen Teil Ihrer Website zu bearbeiten (z.B. '/blog/'), oder Sie können ihn für Ihre gesamte Website registrieren ('/'), so wie ich es tue.
Lebenszyklus und Ereignisse von Service Workern
Ein Service Worker erledigt den Großteil seiner Arbeit, indem er auf relevante Ereignisse wartet und auf sinnvolle Weise auf sie antwortet. Verschiedene Ereignisse werden an verschiedenen Punkten im Lebenszyklus eines Service Workers ausgelöst.
Nachdem der Service Worker registriert und heruntergeladen wurde, wird er im Hintergrund installiert. Ihr Service Worker kann auf das install-Ereignis warten und Aufgaben ausführen, die für diese Phase geeignet sind.
In unserem Fall wollen wir den install-Zustand nutzen, um eine Reihe von Assets zwischenzuspeichern, von denen wir wissen, dass sie später offline verfügbar sein sollen.
Nach Abschluss der install-Phase wird der Service Worker dann aktiviert. Das bedeutet, dass der Service Worker nun die Kontrolle über die Dinge innerhalb seines scope hat und sein Ding machen kann. Das activate-Ereignis ist für einen neuen Service-Worker nicht sonderlich aufregend, aber wir werden sehen, wie nützlich es ist, wenn ein Service-Worker mit einer neuen Version aktualisiert wird.
Der genaue Zeitpunkt der Aktivierung hängt davon ab, ob es sich um einen brandneuen Service-Worker oder eine aktualisierte Version eines bereits existierenden Service-Workers handelt. Wenn der Browser noch keine frühere Version eines bestimmten Service Workers registriert hat, erfolgt die Aktivierung sofort nach Abschluss der Installation.
Nach Abschluss der Installation und der Aktivierung werden sie erst wieder auftreten, wenn eine aktualisierte Version des Service Workers heruntergeladen und registriert wurde.
Neben der Installation und der Aktivierung werden wir uns heute hauptsächlich mit dem Ereignis fetch beschäftigen, um unseren Service Worker nützlich zu machen. Aber es gibt noch weitere nützliche Ereignisse: Synchronisierungsereignisse und Benachrichtigungsereignisse, zum Beispiel.
Für zusätzliche Aufgaben oder als Freizeitspaß können Sie mehr über die Schnittstellen lesen, die Service Worker implementieren. Durch die Implementierung dieser Schnittstellen erhalten Service Worker den Großteil ihrer Ereignisse und einen Großteil ihrer erweiterten Funktionalität.
Die auf Versprechen basierende API des Service Workers
Die API des Service Workers macht intensiven Gebrauch von Promises. Ein Versprechen repräsentiert das letztendliche Ergebnis einer asynchronen Operation, auch wenn der tatsächliche Wert nicht bekannt ist, bis die Operation irgendwann in der Zukunft abgeschlossen ist.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});Die getAnAnswer…-Funktion gibt ein Promise zurück, das (hoffentlich) irgendwann von dem gesuchten answer erfüllt oder aufgelöst wird. Dann kann dieses answer an beliebige verkettete then Handler-Funktionen weitergegeben werden, oder, im bedauerlichen Fall, dass das Ziel nicht erreicht wird, kann das Promise zurückgewiesen werden – oft mit einer Begründung – und catch Handler-Funktionen können sich um diese Situationen kümmern.
Es gibt noch mehr zu versprechen, aber ich werde versuchen, die Beispiele hier einfach zu halten (oder zumindest zu kommentieren). Ich empfehle Ihnen dringend, einige informative Lektüre, wenn Sie neu zu Versprechen sind.
Hinweis: Ich verwende bestimmte ECMAScript6 (oder ES2015) Funktionen in den Beispielcode für Service-Worker, weil Browser, die Service-Worker unterstützen auch diese Funktionen unterstützen. Speziell hier verwende ich Pfeilfunktionen und Template-Strings.
Andere Service-Worker-Notwendigkeiten
Auch ist zu beachten, dass Service-Worker HTTPS benötigen, um zu funktionieren. Es gibt eine wichtige und nützliche Ausnahme von dieser Regel: Service Worker funktionieren für localhost auf dem unsicheren http, was eine Erleichterung ist, weil das Einrichten von lokalem SSL manchmal eine Plackerei ist.
Spaßfakt: Dieses Projekt zwang mich, etwas zu tun, was ich schon eine Weile vor mir hergeschoben hatte: SSL für die www-Subdomain meiner Website zu besorgen und zu konfigurieren. Das ist etwas, was ich den Leuten dringend ans Herz legen möchte, denn so ziemlich alle neuen Dinge, die in Zukunft in den Browsern auftauchen werden, erfordern die Verwendung von SSL.
Alles, was wir zusammenstellen werden, funktioniert heute in Chrome (ich benutze Version 47). In den nächsten Tagen wird Firefox 44 ausgeliefert, der Service Worker unterstützt. Is Service Worker Ready? bietet detaillierte Informationen über die Unterstützung in verschiedenen Browsern.
Registrieren, Installieren und Aktivieren eines Service Workers
Nun, da wir uns um einige theoretische Dinge gekümmert haben, können wir damit beginnen, unseren Service Worker zusammenzustellen.
Um unseren Service Worker zu installieren und zu aktivieren, wollen wir auf install– und activate-Ereignisse hören und auf sie reagieren.
Wir können mit einer leeren Datei für unseren Service Worker beginnen und ein paar eventListeners hinzufügen. In serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registrierung unseres Service Workers
Jetzt müssen wir den Seiten auf unserer Website mitteilen, dass sie den Service Worker verwenden sollen.
Denken Sie daran, dass diese Registrierung von außerhalb des Service Workers erfolgt – in meinem Fall von einem Skript (/js/site.js), das auf jeder Seite meiner Website enthalten ist.
In meinem site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-Caching statischer Assets während der Installation
Ich möchte die Installationsphase nutzen, um einige Assets auf meiner Website vorzupuffern.
- Indem ich einige statische Assets (Bilder, CSS, JavaScript), die von vielen Seiten auf meiner Website verwendet werden, im Voraus zwischenspeichere, kann ich die Ladezeiten beschleunigen, indem ich diese aus dem Cache abrufe, anstatt sie bei späteren Seitenladungen aus dem Netzwerk zu holen.
- Indem ich eine Offline-Fallback-Seite im Voraus zwischenspeichere, kann ich eine schöne Seite anzeigen, wenn ich eine Seitenanforderung nicht erfüllen kann, weil der Benutzer offline ist.
Die Schritte dazu sind:
- Sagen Sie dem
install-Ereignis, dass es warten soll, bis ich das getan habe, was ich tun muss, indem ichevent.waitUntilverwende. - Öffnen Sie das entsprechende
cache, und fügen Sie die statischen Assets darin ein, indem SieCache.addAllverwenden. In der progressiven Web-App-Sprache bilden diese Assets meine „Anwendungs-Shell“.
Erweitern wir in /serviceWorker.js den install-Handler:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Der Service Worker implementiert die CacheStorage-Schnittstelle, die die caches-Eigenschaft global in unserem Service Worker verfügbar macht. Es gibt mehrere nützliche Methoden für caches – zum Beispiel open und delete.
Hier können Sie Promises bei der Arbeit sehen: caches.open gibt ein Promise zurück, das sich in ein cache-Objekt auflöst, sobald es den static-Cache erfolgreich geöffnet hat; addAll gibt auch ein Promise zurück, das sich auflöst, wenn alle an es übergebenen Elemente im Cache abgelegt wurden.
Ich sage dem event, dass er warten soll, bis das von meiner Handler-Funktion zurückgegebene Promise erfolgreich aufgelöst wurde. Dann können wir sicher sein, dass alle diese Pre-Cache-Elemente sortiert werden, bevor die Installation abgeschlossen ist.
Konsolen-Verwirrungen
Stale Logging
Wahrscheinlich kein Fehler, aber sicherlich eine Verwirrung: Wenn Sie console.log von Service-Workern aus starten, zeigt Chrome diese Protokollmeldungen bei nachfolgenden Seitenanfragen weiterhin an (anstatt sie zu löschen). Dies kann den Anschein erwecken, dass Ereignisse zu oft ausgelöst werden oder dass Code immer wieder ausgeführt wird.
Fügen wir zum Beispiel eine log-Anweisung zu unserem install-Handler hinzu:
self.addEventListener('install', event => { // … as before console.log('installing');});
install-Ereignis nicht wirklich bei jedem Seitenaufruf aus. Stattdessen zeigt es veraltete Protokolle an. (Große Version anzeigen)Ein Fehler, wenn alles in Ordnung ist
Eine weitere merkwürdige Sache ist, dass, sobald ein Service Worker installiert und aktiviert ist, nachfolgende Seitenaufrufe für jede Seite innerhalb seines Bereichs immer einen einzelnen Fehler in der Konsole verursachen. Ich dachte, ich mache etwas falsch.

Was wir bisher erreicht haben
Der Service Worker behandelt das install-Ereignis und speichert einige statische Elemente im Voraus. Wenn Sie diesen Service Worker verwenden und registrieren würden, würde er tatsächlich die angegebenen Assets vorcachen, wäre aber noch nicht in der Lage, sie offline zu nutzen.
Der Inhalt von serviceWorker.js befindet sich auf GitHub.
Fetch Handling With Service Workers
Bis jetzt hat unser Service Worker einen ausgefeilten install-Handler, tut aber nichts darüber hinaus. Die eigentliche Magie unseres Service Workers kommt zum Tragen, wenn fetch Ereignisse ausgelöst werden.
Wir können auf verschiedene Weise auf Abrufe reagieren. Durch die Verwendung verschiedener Netzwerkstrategien können wir dem Browser mitteilen, dass er immer versuchen soll, bestimmte Inhalte aus dem Netzwerk zu holen (um sicherzustellen, dass die wichtigsten Inhalte frisch sind), während wir bei statischen Inhalten zwischengespeicherte Kopien bevorzugen – was unsere Seiten-Nutzlasten wirklich verschlankt. Wir können auch einen netten Offline-Fallback bereitstellen, wenn alles andere fehlschlägt.
Wann immer ein Browser ein Asset abrufen will, das innerhalb des Bereichs dieses Service Workers liegt, können wir davon erfahren, indem wir ein eventListener in serviceWorker.js hinzufügen:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Auch jeder Abruf, der in den Bereich dieses Service Workers (d.h. Pfad) fällt, wird dieses Ereignis auslösen – HTML-Seiten, Skripte, Bilder, CSS, was immer. Wir können die Art und Weise, wie der Browser auf jeden dieser Abrufe reagiert, selektiv behandeln.
Sollten wir diesen Abruf behandeln?
Wenn ein fetch-Ereignis für ein Asset auftritt, möchte ich als erstes bestimmen, ob dieser Service Worker in den Abruf der gegebenen Ressource eingreifen soll. Andernfalls sollte er nichts tun und den Browser sein Standardverhalten durchsetzen lassen.
Wir werden mit einer grundlegenden Logik wie dieser in serviceWorker.js enden:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});Die shouldHandleFetchFunktion bewertet eine gegebene Anfrage, um zu bestimmen, ob wir eine Antwort bereitstellen oder den Browser seine Standardbehandlung durchsetzen lassen sollten.
Warum keine Versprechen verwenden?
Um der Vorliebe des Service Workers für Versprechen gerecht zu werden, sah die erste Version meines fetch Event-Handlers so aus:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Sieht logisch aus, aber ich machte ein paar Anfängerfehler mit Versprechen. Ich schwöre, dass ich sogar anfangs einen Codegeruch wahrgenommen habe, aber es war Jake, der mich auf meine Fehler aufmerksam gemacht hat. (Lektion: Wie immer gilt: Wenn sich Code falsch anfühlt, ist er es wahrscheinlich auch.)
Versprechen sollten nicht zurückgewiesen werden, um anzuzeigen: „Ich habe eine Antwort erhalten, die mir nicht gefällt.“ Stattdessen sollten Ablehnungen anzeigen: „Ah, Mist, irgendetwas ist beim Versuch, die Antwort zu bekommen, schief gelaufen.“ Das heißt, Ablehnungen sollten außergewöhnlich sein.
Kriterien für gültige Anfragen
Richtig, zurück zur Bestimmung, ob eine bestimmte Abrufanfrage für meinen Service Worker geeignet ist. Meine Site-spezifischen Kriterien lauten wie folgt:
- Die angeforderte URL sollte etwas darstellen, das ich zwischenspeichern oder auf das ich reagieren möchte. Der Pfad sollte mit einem
Regular Expressionder gültigen Pfade übereinstimmen. - Die HTTP-Methode der Anfrage sollte
GETsein. - Die Anfrage sollte für eine Ressource von meinem Ursprung (
lyza.com) sein.
Wenn einer der criteria-Tests zu false führt, sollten wir diese Anfrage nicht bearbeiten. In serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Natürlich sind die Kriterien hier meine eigenen und würden von Standort zu Standort variieren. event.request ist ein Request-Objekt, das alle Arten von Daten enthält, die Sie sich ansehen können, um zu beurteilen, wie Sie möchten, dass sich Ihr Fetch-Handler verhält.
Trivialer Hinweis: Wenn Sie den Einfall von config bemerkt haben, der als opts an Handler-Funktionen übergeben wird, gut erkannt. Ich habe einige wiederverwendbare config-ähnliche Werte ausgeklammert und ein config-Objekt im Top-Level-Bereich des Service Workers erstellt:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Warum Whitelist?
Sie fragen sich vielleicht, warum ich nur Dinge mit Pfaden zwischenspeichere, die mit diesem regulären Ausdruck übereinstimmen:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… statt alles zu zwischenspeichern, was von meinem eigenen Ursprung kommt. Hierfür gibt es mehrere Gründe:
- Ich möchte den Service Worker selbst nicht zwischenspeichern.
- Wenn ich meine Website lokal entwickle, werden einige Anfragen für Dinge generiert, die ich nicht zwischenspeichern möchte. Ich verwende z. B.
browserSync, was in meiner Entwicklungsumgebung eine Reihe von verwandten Anfragen auslöst. Ich möchte diese Dinge nicht zwischenspeichern! Es erschien mir unübersichtlich und schwierig, an alles zu denken, was ich nicht zwischenspeichern möchte (ganz zu schweigen davon, dass es etwas seltsam wäre, dies in der Konfiguration meines Service Workers zu vermerken). Daher erschien mir der Ansatz einer Whitelist natürlicher.
Schreiben des Fetch Handlers
Jetzt sind wir bereit, anwendbare fetch Anfragen an einen Handler weiterzugeben. Die onFetch Funktion muss feststellen:
- welche Art von Ressource angefordert wird,
- und wie ich diese Anforderung erfüllen soll.
1. Welche Art von Ressource wird angefordert?
Ich kann mir den HTTP Accept-Header ansehen, um einen Hinweis darauf zu erhalten, welche Art von Asset angefordert wird. Das hilft mir, herauszufinden, wie ich damit umgehen will.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Um organisiert zu bleiben, möchte ich verschiedene Arten von Ressourcen in verschiedene Caches stecken. So kann ich diese Caches später verwalten. Diese Cache-Schlüssel String sind willkürlich – du kannst deine Caches nennen, wie du willst; die Cache-API hat keine Meinungen.
2. Reagiere auf das Fetch
Das nächste, was onFetch zu tun hat, ist respondTo das fetch-Ereignis mit einem intelligenten Response.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Vorsicht mit Async!
In unserem Fall tut shouldHandleFetch nichts Asynchrones, und auch onFetch tut nichts bis zum Punkt event.respondWith. Wenn davor etwas Asynchrones passiert wäre, hätten wir ein Problem. event.respondWith muss zwischen dem Auslösen des Ereignisses fetch und der Rückgabe der Kontrolle an den Browser aufgerufen werden. Dasselbe gilt für event.waitUntil. Grundsätzlich gilt: Wenn Sie ein Ereignis behandeln, tun Sie entweder sofort etwas (synchron) oder sagen Sie dem Browser, dass er warten soll, bis Ihre asynchronen Aufgaben erledigt sind.
HTML Content: Implementing A Network-First Strategy
Die Beantwortung von fetch-Anfragen beinhaltet die Implementierung einer geeigneten Netzwerkstrategie. Schauen wir uns genauer an, wie wir auf Anfragen nach HTML-Inhalten (resourceType === 'content') reagieren.
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}Die Art und Weise, wie wir hier Anfragen nach Inhalten erfüllen, ist eine netzwerkorientierte Strategie. Da der HTML-Inhalt das Kernstück meiner Website ist und sich häufig ändert, versuche ich immer, frische HTML-Dokumente aus dem Netzwerk zu beziehen.
Lassen Sie uns diesen Schritt durchgehen.
1. Versuchen Sie, das Dokument aus dem Netzwerk zu holen
fetch(request) .then(response => addToCache(cacheKey, request, response))Wenn die Netzwerkanfrage erfolgreich ist (d.h. das Versprechen wird aufgelöst), legen Sie eine Kopie des HTML-Dokuments im entsprechenden Cache (content) ab. Dies nennt man Read-Through-Caching:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Antworten dürfen nur einmal verwendet werden.
Wir müssen zwei Dinge mit dem response tun, das wir haben:
- es zwischenspeichern,
- auf das Ereignis mit ihm reagieren (d.h. es zurückgeben).
Aber ResponseObjekte dürfen nur einmal verwendet werden. Indem wir es klonen, können wir eine Kopie für den Cache erstellen:
var copy = response.clone();
Don’t cache bad responses. Machen Sie nicht den gleichen Fehler wie ich. Die erste Version meines Codes enthielt diese Bedingung nicht:
if (response.ok)Es ist ziemlich gefährlich, 404 oder andere schlechte Antworten im Cache zu haben! Nur gute Antworten in den Cache stellen.
2. Abrufversuch aus dem Cache
Wenn der Abruf des Assets aus dem Netzwerk gelingt, sind wir fertig. Wenn dies jedoch nicht der Fall ist, sind wir möglicherweise offline oder das Netzwerk ist anderweitig beeinträchtigt. Versuchen Sie, eine zuvor zwischengespeicherte Kopie der HTML-Datei aus dem Cache abzurufen:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Hier ist die fetchFromCache-Funktion:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Hinweis: Geben Sie nicht an, welchen Cache Sie mit caches.match prüfen wollen; prüfen Sie alle auf einmal.
3. einen Offline-Fallback bereitstellen
Wenn wir so weit gekommen sind, aber nichts im Cache ist, mit dem wir antworten können, geben Sie einen geeigneten Offline-Fallback zurück, wenn möglich. Bei HTML-Seiten ist dies die im Cache gespeicherte Seite von /offline/. Es handelt sich um eine einigermaßen gut formatierte Seite, die dem Benutzer mitteilt, dass er offline ist und dass wir seine Wünsche nicht erfüllen können.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))Und hier ist die offlineResponse-Funktion:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}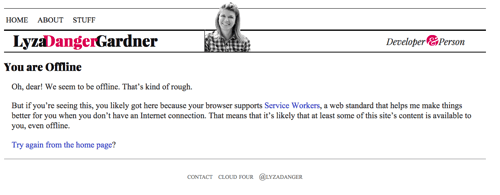
Weitere Ressourcen: Implementieren einer Cache-First-Strategie
Die Abruflogik für andere Ressourcen als HTML-Inhalte verwendet eine Cache-First-Strategie. Bilder und andere statische Inhalte auf der Website ändern sich nur selten; prüfen Sie daher zuerst den Cache und vermeiden Sie den Netzwerk-Roundtrip.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Die Schritte sind hier:
- Versuchen Sie, das Asset aus dem Cache abzurufen;
- wenn das fehlschlägt, versuchen Sie, es aus dem Netzwerk abzurufen (mit Read-Through-Caching);
- wenn das fehlschlägt, stellen Sie eine Offline-Fallback-Ressource bereit, wenn möglich.
Offline-Bild
Wir können ein SVG-Bild mit dem Text „Offline“ als Offline-Fallback zurückgeben, indem wir die offlineResource-Funktion vervollständigen:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}Und lassen Sie uns die entsprechenden Aktualisierungen an config vornehmen:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};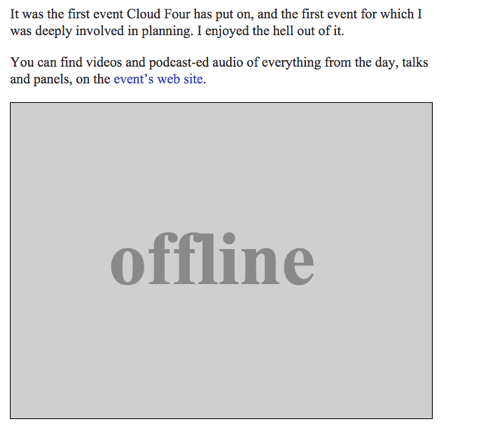
Auf CDNs achten
Auf CDNs achten, wenn Sie die Abrufverarbeitung auf Ihren Ursprung beschränken. Beim Aufbau meines ersten Service Workers vergaß ich, dass mein Hosting-Provider Assets (Bilder und Skripte) in sein CDN verlagert hatte, so dass sie nicht mehr vom Ursprung meiner Website (lyza.com) abgerufen werden konnten. Huch! Das hat nicht funktioniert. Am Ende habe ich das CDN für die betroffenen Assets deaktiviert (aber diese Assets natürlich optimiert!).
Fertigstellung der ersten Version
Die erste Version unseres Service Workers ist nun fertig. Wir haben einen install-Handler und einen ausgefeilten fetch-Handler, der auf anwendbare Abrufe mit optimierten Antworten reagieren sowie zwischengespeicherte Ressourcen und eine Offline-Seite bereitstellen kann, wenn sie offline sind.
Während die Benutzer die Website durchsuchen, werden sie immer mehr zwischengespeicherte Elemente aufbauen. Wenn sie offline sind, können sie weiterhin Elemente durchsuchen, die sie bereits im Cache gespeichert haben, oder sie sehen eine Offline-Seite (oder ein Bild), wenn die angeforderte Ressource nicht im Cache verfügbar ist.
Der vollständige Code mit Fetch-Handling (serviceWorker.js) befindet sich auf GitHub.
Versionierung und Aktualisierung des Service Workers
Wenn sich nie wieder etwas an unserer Website ändern würde, könnten wir sagen, dass wir fertig sind. Aber Service Worker müssen von Zeit zu Zeit aktualisiert werden. Vielleicht möchte ich mehr Pfade hinzufügen, die zwischengespeichert werden können. Vielleicht möchte ich die Art und Weise, wie meine Offline-Fallbacks funktionieren, weiterentwickeln. Vielleicht gibt es einen kleinen Fehler in meinem Service Worker, den ich beheben möchte.
Ich möchte betonen, dass es automatisierte Tools gibt, die die Verwaltung von Service Workern zu einem Teil Ihres Arbeitsablaufs machen, wie Service Worker Precache von Google. Sie müssen diese Versionierung nicht von Hand verwalten. Die Komplexität meiner Website ist jedoch so gering, dass ich eine menschliche Versionierungsstrategie verwende, um Änderungen an meinem Service Worker zu verwalten. Diese besteht aus:
- einem einfachen Versionsstring zur Angabe von Versionen,
- Implementierung eines
activateHandlers zum Aufräumen nach alten Versionen, - Aktualisierung des
installHandlers, um aktualisierte Service Workeractivateschneller zu machen.
Versioning Cache Keys
Ich kann eine version Eigenschaft zu meinem config Objekt hinzufügen:
version: 'aether'Dies sollte sich jedes Mal ändern, wenn ich eine aktualisierte Version meines Service Workers bereitstellen möchte. Ich verwende die Namen griechischer Gottheiten, weil sie für mich interessanter sind als zufällige Zeichenketten oder Zahlen.
Anmerkung: Ich habe einige Änderungen am Code vorgenommen und eine Komfortfunktion (cacheName) hinzugefügt, um Cache-Schlüssel mit Präfix zu erzeugen. Sie ist tangential und wird daher hier nicht aufgeführt, aber Sie können sie im fertigen Code des Service Workers sehen.
achilles.) (Große Version anzeigen)Don’t Rename Your Service Worker
Einen Moment lang habe ich mit den Namenskonventionen für den Dateinamen des Service Workers herumgespielt. Tun Sie das nicht. Wenn Sie das tun, registriert der Browser den neuen Service Worker, aber der alte Service Worker bleibt ebenfalls installiert. Das ist eine chaotische Situation. Ich bin mir sicher, dass es einen Workaround gibt, aber ich würde sagen, benennen Sie Ihren Service Worker nicht um.
Verwenden Sie keine importScripts für config
Ich bin den Weg gegangen, mein config Objekt in eine externe Datei zu packen und self.importScripts() in der Service Worker Datei zu verwenden, um das Skript hineinzuziehen. Das schien ein vernünftiger Weg zu sein, um meine config außerhalb des Service Workers zu verwalten, aber es gab ein Problem.
Der Browser vergleicht die Service Worker-Dateien mit Bytes, um festzustellen, ob sie aktualisiert wurden – so weiß er, wann er einen Download- und Installationszyklus erneut auslösen muss. Änderungen an der externen config verursachen keine Änderungen am Service-Worker selbst, was bedeutet, dass Änderungen an der config nicht zur Aktualisierung des Service-Workers geführt haben. Ups.
Hinzufügen eines Aktivierungs-Handlers
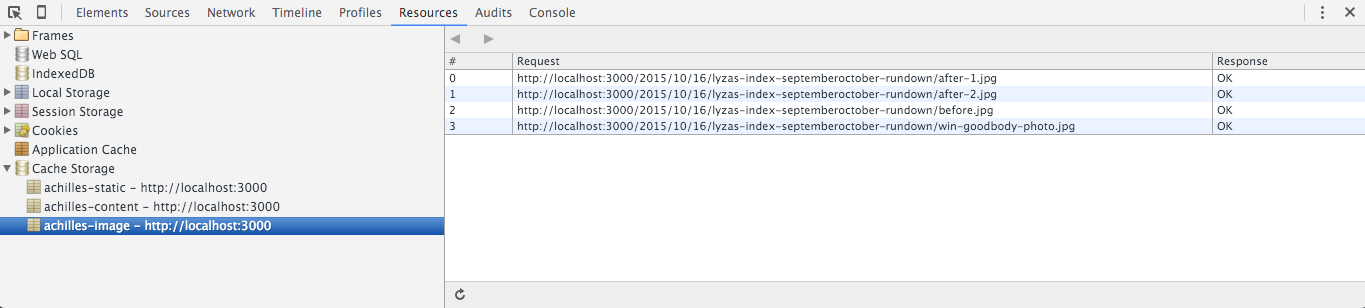
Der Zweck der versionsspezifischen Cache-Namen ist, dass wir Caches von früheren Versionen bereinigen können. Wenn es während der Aktivierung Caches gibt, die nicht mit der aktuellen Versionszeichenkette versehen sind, wissen wir, dass sie gelöscht werden sollten, weil sie muffig sind.
Aufräumen alter Caches
Wir können eine Funktion verwenden, um nach alten Caches aufzuräumen:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Beschleunigung von Installation und Aktivierung
Ein aktualisierter Service Worker wird heruntergeladen und install im Hintergrund ausgeführt. Er ist jetzt ein Worker im Wartezustand. Standardmäßig wird der aktualisierte Service Worker nicht aktiviert, während Seiten geladen werden, die noch den alten Service Worker verwenden. Wir können dies jedoch beschleunigen, indem wir eine kleine Änderung an unserem install-Handler vornehmen:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting bewirkt, dass activate sofort ausgeführt wird.
Beenden Sie nun den activate-Handler:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim bewirkt, dass der neue Service Worker sofort auf allen geöffneten Seiten in seinem Bereich wirksam wird.

chrome://serviceworker-internals in Chrome verwenden, um alle Service Worker zu sehen, die der Browser registriert hat. (Große Version anzeigen)
Ta-Da!
Wir haben jetzt einen versionsverwalteten Service Worker! Sie können die aktualisierte serviceWorker.js Datei mit Versionsverwaltung auf GitHub sehen.
Weitere Lektüre auf SmashingMag:
- A Beginner’s Guide To Progressive Web Apps
- Building A Simple Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web