
Om forfatteren
Lyza Danger Gardner er en dev. Siden hun var med til at stifte Portland, Oregon-baserede mobile webstartup Cloud Four i 2007, har hun pint og begejstret sig selv med …Mere omLyza↬
- 23 min læsning
- Coding,JavaScript,Teknikker,Service Workers
- Sparet til offline læsning
- Del på Twitter, LinkedIn


Der er ingen mangel på opmuntring eller begejstring over den spæde service worker API, der nu leveres i nogle populære browsere. Der findes kogebøger og blogindlæg, kodestumper og værktøjer. Men jeg finder ud af, at når jeg vil lære et nyt webkoncept grundigt, er det ofte ideelt at smøge ærmerne op, kaste mig ud i det og bygge noget fra bunden.
De ujævnheder, problemer og fejl, som jeg stødte på denne gang, har fordele: Nu forstår jeg service workers meget bedre, og med lidt held kan jeg hjælpe dig med at undgå nogle af de hovedpiner, jeg stødte på, da jeg arbejdede med det nye API.
Service workers gør mange forskellige ting; der er et utal af måder at udnytte deres kræfter på. Jeg besluttede at bygge en simpel service worker til mit (statiske, ukomplicerede) websted, der nogenlunde afspejler de funktioner, som det forældede Application Cache API plejede at give – det vil sige:
- gøre webstedet funktionsdygtigt offline,
- øge online-ydelsen ved at reducere netværksanmodninger for visse aktiver,
- tilvejebringe en tilpasset offline-fallback-oplevelse.
Hvor jeg begynder, vil jeg gerne takke to personer, hvis arbejde har gjort dette muligt. For det første er jeg Jeremy Keith enormt taknemmelig for implementeringen af service workers på hans eget websted, som har tjent som udgangspunkt for min egen kode. Jeg blev inspireret af hans nylige indlæg, der beskriver hans igangværende erfaringer med service workers. Faktisk er mit arbejde så stærkt afledt, at jeg ikke ville have skrevet om det uden Jeremys formaning i et tidligere indlæg:
Så hvis du beslutter dig for at lege med Service Workers, så vær sød, vær sød at dele dine erfaringer.
For det andet, alle mulige store gamle tak til Jake Archibald for hans fremragende tekniske gennemgang og feedback. Det er altid rart, når en af service worker-specifikationens skabere og evangelister er i stand til at sætte dig på plads!
Hvad er en service worker?
En service worker er et script, der står mellem dit websted og netværket og giver dig bl.a. mulighed for at opfange netværksanmodninger og reagere på dem på forskellige måder.
For at dit websted eller din app kan fungere, henter browseren sine aktiver – såsom HTML-sider, JavaScript, billeder, skrifttyper. Tidligere var det hovedsageligt browserens opgave at administrere dette. Hvis browseren ikke kunne få adgang til netværket, ville du sandsynligvis se meddelelsen “Hey, you’re offline”. Der var teknikker, man kunne bruge til at fremme lokal caching af aktiver, men browseren havde ofte det sidste ord.
Det var ikke nogen god oplevelse for brugere, der var offline, og det gav webudviklere meget lidt kontrol over browsercachelagring.
Det var Application Cache (eller AppCache), hvis ankomst for flere år siden virkede lovende. Den lod dig angiveligt diktere, hvordan forskellige aktiver skulle håndteres, så dit websted eller din app kunne fungere offline. Men AppCaches enkle syntaks afslørede dens underliggende forvirrende karakter og mangel på fleksibilitet.
Den nye API for service workers kan gøre det, som AppCache gjorde, og meget mere. Men det ser lidt skræmmende ud i starten. Specifikationerne er tung og abstrakt læsning, og adskillige API’er er underordnet eller på anden måde relateret til den: cache, fetch osv. Service workers omfatter så mange funktioner: push-notifikationer og snart også baggrundssynkronisering. Sammenlignet med AppCache ser det … kompliceret ud.
Mens AppCache (som i øvrigt er på vej væk) var let at lære, men forfærdelig i hvert eneste øjeblik derefter (min mening), er service workers mere en indledende kognitiv investering, men de er kraftfulde og nyttige, og du kan generelt få dig selv ud af problemerne, hvis du ødelægger ting.
Somme grundlæggende service worker-begreber
En service worker er en fil med noget JavaScript i den. I den fil kan du skrive JavaScript, som du kender og elsker det, med nogle få vigtige ting, du skal huske på.
Service worker-scripts kører i en separat tråd i browseren i forhold til de sider, de styrer. Der er måder at kommunikere mellem workers og sider på, men de afvikles i et separat scope. Det betyder, at du f.eks. ikke har adgang til DOM’en på disse sider. Jeg visualiserer en service worker som en slags, der kører i en separat fane fra den side, den påvirker; det er slet ikke korrekt, men det er en nyttig grov metafor til at holde mig selv ude af forvirring.
JavaScript i en service worker må ikke blokere. Du er nødt til at bruge asynkrone API’er. Du kan f.eks. ikke bruge localStorage i en service worker (localStorage er et synkront API). Humoristisk nok lykkedes det mig, selv om jeg vidste dette, at løbe risikoen for at overtræde det, som vi skal se.
Registrering af en service worker
Du får en service worker til at træde i kraft ved at registrere den. Denne registrering foretages uden for servicearbejderen, af en anden side eller et andet script på dit websted. På mit websted er der et globalt site.js-script på hver HTML-side. Jeg registrerer min service worker derfra.
Når du registrerer en service worker, fortæller du den (valgfrit) også, hvilket anvendelsesområde den skal anvende sig selv på. Du kan give en service worker besked om kun at håndtere ting for en del af dit websted (f.eks. '/blog/'), eller du kan registrere den for hele dit websted ('/'), som jeg gør.
Service Worker Lifecycle And Events
En service worker udfører hovedparten af sit arbejde ved at lytte efter relevante hændelser og reagere på dem på nyttige måder. Forskellige hændelser udløses på forskellige punkter i en service workers livscyklus.
Når serviceworkeren er blevet registreret og downloadet, bliver den installeret i baggrunden. Din service worker kan lytte efter install-hændelsen og udføre opgaver, der passer til denne fase.
I vores tilfælde ønsker vi at udnytte install-tilstanden til at pre-cache en masse aktiver, som vi ved, at vi vil have tilgængelige offline senere.
Når install-fasen er afsluttet, aktiveres serviceworkeren derefter. Det betyder, at servicearbejderen nu har kontrol over tingene inden for sin scope og kan gøre sin ting. activate-hændelsen er ikke særlig spændende for en ny service worker, men vi vil se, hvordan den er nyttig, når en service worker opdateres med en ny version.
Det nøjagtige tidspunkt for aktivering afhænger af, om der er tale om en helt ny service worker eller en opdateret version af en allerede eksisterende service worker. Hvis browseren ikke allerede har en tidligere version af en given service worker registreret, sker aktiveringen straks efter installationen er afsluttet.
Når installationen og aktiveringen er afsluttet, sker de ikke igen, før en opdateret version af serviceworkeren er hentet og registreret.
Bortset fra installation og aktivering kigger vi i dag primært på fetch-hændelsen for at gøre vores service worker nyttig. Men der er flere nyttige hændelser ud over det: f.eks. synkroniseringshændelser og notifikationshændelser.
For ekstra point eller for sjov i fritiden kan du læse mere om de grænseflader, som service workers implementerer. Det er ved at implementere disse grænseflader, at service workers får hovedparten af deres hændelser og en stor del af deres udvidede funktionalitet.
The Service Worker’s Promise-Based API
The service worker’s API gør stor brug af Promises. Et løfte repræsenterer det endelige resultat af en asynkron operation, selv om den faktiske værdi ikke vil være kendt, før operationen er afsluttet et stykke ude i fremtiden.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');}); getAnAnswer…Funktionen getAnAnswer… returnerer et Promise, der (håber vi) i sidste ende vil blive opfyldt af, eller opløses til, det answer, vi leder efter. Derefter kan denne answer føres til enhver kæde af then-handlerfunktioner, eller, i det kedelige tilfælde, at den ikke når sit mål, kan Promise afvises – ofte med en grund – og catch-handlerfunktioner kan tage sig af disse situationer.
Der er mere at love, men jeg vil forsøge at holde eksemplerne her ligetil (eller i det mindste kommenteret). Jeg opfordrer dig til at lave noget informativ læsning, hvis du er ny med promises.
Bemærk: Jeg bruger visse ECMAScript6- (eller ES2015-) funktioner i eksempelkoden til service workers, fordi browsere, der understøtter service workers, også understøtter disse funktioner. Specifikt her bruger jeg pilefunktioner og skabelonstrenge.
Andre service worker-nødvendigheder
Og bemærk også, at service workers kræver HTTPS for at fungere. Der er en vigtig og nyttig undtagelse fra denne regel: Service workers fungerer for localhost på usikre http, hvilket er en lettelse, fordi det nogle gange er en stor mundfuld at opsætte lokal SSL.
Sjovt faktum: Dette projekt tvang mig til at gøre noget, jeg havde udskudt i et stykke tid: at få og konfigurere SSL til www-subdomænet på mit websted. Det er noget, jeg opfordrer folk til at overveje at gøre, fordi stort set alle de sjove nye ting, der rammer browseren i fremtiden, vil kræve, at der anvendes SSL.
Alle de ting, vi sætter sammen, virker i dag i Chrome (jeg bruger version 47). Når som helst nu kommer Firefox 44 på markedet, og den understøtter service workers. Is Service Worker Ready? indeholder granulære oplysninger om understøttelse i forskellige browsere.
Registrering, installation og aktivering af en service worker
Nu, hvor vi har taget os af noget teori, kan vi begynde at sammensætte vores service worker.
For at installere og aktivere vores service worker vil vi lytte efter install– og activate-hændelser og handle på dem.
Vi kan starte med en tom fil til vores service worker og tilføje et par eventListeners. I serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registrering af vores service worker
Nu skal vi fortælle siderne på vores websted, at de skal bruge serviceworkeren.
Husk, at denne registrering sker uden for serviceworkeren – i mit tilfælde fra et script (/js/site.js), som er inkluderet på hver side på mit websted.
I min site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-Caching af statiske aktiver under installationen
Jeg ønsker at bruge installationsfasen til at pre-cache nogle aktiver på mit websted.
- Gennem pre-caching af nogle statiske aktiver (billeder, CSS, JavaScript), der bruges af mange sider på mit websted, kan jeg fremskynde indlæsningstiderne ved at hente disse fra cachen i stedet for at hente dem fra netværket ved efterfølgende sideindlæsninger.
- Gennem pre-caching af en offline fallback-side kan jeg vise en pæn side, når jeg ikke kan opfylde en sideanmodning, fordi brugeren er offline.
Trinene for at gøre dette er:
- Fortæl
install-hændelsen at hænge på og ikke afslutte, før jeg har gjort, hvad jeg skal gøre, ved hjælp afevent.waitUntil. - Åbn den relevante
cache, og sæt de statiske aktiver i den ved hjælp afCache.addAll. I progressiv webapp-sprog udgør disse aktiver min “applikationsskal”.”
I /serviceWorker.js skal vi udvide install-handleren:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Tjenestearbejderen implementerer CacheStorage-grænsefladen, hvilket gør caches-egenskaben tilgængelig globalt i vores tjenestearbejder. Der er flere nyttige metoder på caches – f.eks. open og delete.
Du kan se Promises på arbejde her: caches.open returnerer en Promise, der opløses til et cache-objekt, når den har åbnet static-cachen med succes; addAll returnerer også en Promise, der opløses, når alle de elementer, der er overgivet til den, er blevet gemt i cachen.
Jeg fortæller event, at den skal vente, indtil den Promise, der returneres af min behandlerfunktion, er blevet opløst med succes. Så kan vi være sikre på, at alle disse præ-cache-elementer bliver sorteret, inden installationen er afsluttet.
Konsolforvirring
Stor logning
Måske ikke en fejl, men helt sikkert en forvirring: Hvis du console.log fra servicemedarbejdere, fortsætter Chrome med at vise disse logmeddelelser igen (i stedet for at slette dem) ved efterfølgende sideanmodninger. Det kan få det til at se ud som om, at begivenhederne udløses for mange gange, eller som om kode udføres igen og igen.
Lad os f.eks. tilføje en log-anvisning til vores install-handler:
self.addEventListener('install', event => { // … as before console.log('installing');});
install-hændelsen ved hver sideindlæsning. I stedet viser den forældede logfiler. (Se den store version)En fejl, når tingene er i orden
En anden mærkelig ting er, at når en service worker er installeret og aktiveret, vil efterfølgende sideindlæsninger for enhver side inden for dens anvendelsesområde altid forårsage en enkelt fejl i konsollen. Jeg troede, at jeg gjorde noget forkert.

Hvad vi har opnået indtil videre
Tjenestearbejderen håndterer install-hændelsen og pre-cacher nogle statiske aktiver. Hvis du skulle bruge denne service worker og registrere den, ville den faktisk pre-cache de angivne aktiver, men den ville endnu ikke kunne udnytte dem offline.
Indholdet af serviceWorker.js findes på GitHub.
Fetch-håndtering med service workers
Så vidt har vores service worker en udbygget install-håndtering, men den gør ikke noget ud over det. Magien i vores service worker kommer virkelig til at ske, når fetch-hændelser udløses.
Vi kan reagere på hentninger på forskellige måder. Ved at bruge forskellige netværksstrategier kan vi fortælle browseren, at den altid skal forsøge at hente visse aktiver fra netværket (hvilket sikrer, at nøgleindholdet er friskt), mens vi favoriserer cachelagrede kopier for statiske aktiver – hvilket virkelig slanker vores siders nyttelast. Vi kan også give en god offline-fallback, hvis alt andet fejler.
Når en browser ønsker at hente et aktiv, der er inden for denne servicearbejders rækkevidde, kan vi høre om det ved, ja, at tilføje en eventListener i serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Alle hentninger, der falder inden for denne servicearbejders rækkevidde (dvs. sti), vil udløse denne hændelse – HTML-sider, scripts, billeder, CSS, you name it. Vi kan selektivt håndtere den måde, som browseren reagerer på en af disse hentninger.
Bør vi håndtere denne hentning?
Når der opstår en fetch hændelse for et aktiv, er det første, jeg ønsker at afgøre, om denne servicemedarbejder skal blande sig i hentningen af den givne ressource. Ellers skal den ikke gøre noget og lade browseren hævde sin standardadfærd.
Vi ender med en grundlæggende logik som denne i serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }}); shouldHandleFetchfunktionen vurderer en given anmodning for at afgøre, om vi skal give et svar eller lade browseren hævde sin standardhåndtering.
Hvorfor ikke bruge løfter?
For at holde mig til service workers forkærlighed for løfter, så den første version af min fetch hændelseshåndtering sådan ud:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Det virker logisk, men jeg begik et par begynderfejl med løfter. Jeg sværger, at jeg fornemmede en kodelugt allerede i starten, men det var Jake, der fik mig på rette spor. (Lektion: Som altid, hvis kode føles forkert, er det sandsynligvis forkert.)
Afvisninger af løfter bør ikke bruges til at indikere: “Jeg fik et svar, som jeg ikke kunne lide”. I stedet bør afvisninger indikere, “Ah, pis, noget gik galt i forsøget på at få svaret”. Det vil sige, at afvisninger bør være ekstraordinære.
Kriterier for gyldige anmodninger
Okay, tilbage til at bestemme, om en given hentningsanmodning er anvendelig for min servicemedarbejder. Mine webstedsspecifikke kriterier er som følger:
- Den anmodede URL skal repræsentere noget, som jeg ønsker at cache eller reagere på. Dens sti skal matche en
Regular Expressionaf gyldige stier. - Anmodningens HTTP-metode skal være
GET. - Anmodningen skal vedrøre en ressource fra min oprindelse (
lyza.com).
Hvis nogen af criteria-testene evaluerer til false, skal vi ikke håndtere denne anmodning. I serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Kriterierne her er naturligvis mine egne og vil variere fra sted til sted. event.request er et Request-objekt, der har alle mulige data, som du kan se på for at vurdere, hvordan du ønsker, at din hentningshåndtering skal opføre sig.
Triviel bemærkning: Hvis du har bemærket indbruddet af config, der overføres som opts til håndteringsfunktioner, er det godt opdaget. Jeg har fjernet nogle genanvendelige config-lignende værdier og oprettet et config-objekt i servicemedarbejderens topniveauområde:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Hvorfor whitelist?
Du undrer dig måske over, hvorfor jeg kun cachelagrerer ting med stier, der matcher dette regulære udtryk:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… i stedet for at cachelagre alt, der kommer fra min egen oprindelse. Et par grunde:
- Jeg ønsker ikke at cache selve servicemedarbejderen.
- Når jeg udvikler mit websted lokalt, genereres der nogle anmodninger til ting, som jeg ikke ønsker at cache. Jeg bruger f.eks.
browserSync, hvilket udløser en masse relaterede anmodninger i mit udviklingsmiljø. Jeg ønsker ikke at cache disse ting! Det virkede rodet og udfordrende at forsøge at tænke på alt det, jeg ikke ønsker at cache (for ikke at nævne, at det var lidt mærkeligt at skulle stave det i min servicearbejders konfiguration). Så en whitelist-tilgang virkede mere naturlig.
Skrivning af Fetch Handler
Nu er vi klar til at sende gældende fetch anmodninger videre til en handler. onFetch funktionen skal bestemme:
- hvilken slags ressource der anmodes om,
- og hvordan jeg skal opfylde denne anmodning.
1. Hvilken slags ressource anmodes der om?
Jeg kan se på HTTP Accept-headeren for at få et hint om, hvilken slags aktiv der anmodes om. Det hjælper mig med at finde ud af, hvordan jeg vil håndtere det.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}For at holde mig organiseret ønsker jeg at placere forskellige typer ressourcer i forskellige caches. Dette vil gøre det muligt for mig at administrere disse caches senere. Disse cache-nøgler String er vilkårlige – du kan kalde dine caches hvad du vil; cache-API’en har ingen meninger.
2. Svar på Fetch
Det næste, onFetch skal gøre, er at respondTo fetch-hændelsen med en intelligent Response.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Skynd dig med asynkronitet!
I vores tilfælde gør shouldHandleFetch ikke noget asynkront, og det gør onFetch heller ikke op til event.respondWith. Hvis der var sket noget asynkront før det, ville vi være i problemer. event.respondWith skal kaldes mellem det tidspunkt, hvor fetch-hændelsen udløses, og kontrollen vender tilbage til browseren. Det samme gælder for event.waitUntil. Grundlæggende gælder det, at hvis du håndterer en hændelse, skal du enten gøre noget med det samme (synkront) eller fortælle browseren, at den skal vente, indtil dine asynkrone ting er færdige.
HTML Content: Implementering af en netværksførst-strategi
Svar på fetch-anmodninger indebærer implementering af en passende netværksstrategi. Lad os se nærmere på den måde, vi reagerer på anmodninger om HTML-indhold (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}Den måde, vi opfylder anmodninger om indhold på her, er en netværksførste strategi. Da HTML-indhold er kernen i mit websted, og det ændrer sig ofte, forsøger jeg altid at få friske HTML-dokumenter fra netværket.
Lad os gennemgå dette trinvis.
1. Prøv at hente fra netværket
fetch(request) .then(response => addToCache(cacheKey, request, response))Hvis netværksanmodningen lykkes (dvs. løftet bliver løst), skal du gå videre og gemme en kopi af HTML-dokumentet i den relevante cache (content). Dette kaldes read-through caching:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Svar må kun bruges én gang.
Vi skal gøre to ting med det response, vi har:
- cache det,
- svar på hændelsen med det (dvs. returnere det).
Men Response-objekter må kun bruges én gang. Ved at klone det kan vi oprette en kopi til brug for cachen:
var copy = response.clone();
Lad være med at cache dårlige svar. Du må ikke begå den samme fejl som mig. Den første version af min kode havde ikke denne betingelse:
if (response.ok)Temmelig fedt at ende op med 404 eller andre dårlige svar i cachen! Kun cachelagre svar, der er glade.
2. Prøv at hente fra cachen
Hvis det lykkes at hente aktivet fra netværket, er vi færdige. Men hvis det ikke lykkes, er vi måske offline eller på anden måde netværkskompromitteret. Prøv at hente en tidligere cachet kopi af HTML-filen fra cache:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Her er fetchFromCache-funktionen:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Bemærk: Du skal ikke angive hvilken cache du vil kontrollere med caches.match; kontroller dem alle på én gang.
3. Giv en offline fallback
Hvis vi er nået så langt, men der ikke er noget i cachen, vi kan svare med, skal du returnere en passende offline fallback, hvis det er muligt. For HTML-sider er dette den side, der er gemt i cachen fra /offline/. Det er en rimeligt velformateret side, der fortæller brugeren, at de er offline, og at vi ikke kan opfylde det, de er ude efter.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))Og her er offlineResponse-funktionen:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}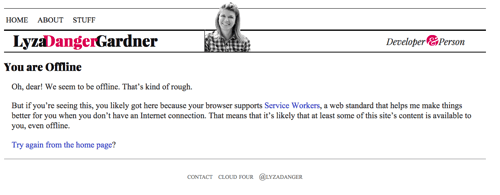
Andre ressourcer: Implementering af en Cache-First-strategi
Hentningslogikken for andre ressourcer end HTML-indhold bruger en cache-First-strategi. Billeder og andet statisk indhold på webstedet ændres sjældent; tjek derfor først cachen og undgå netværksrundrejsen.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Trinene her er:
- prøv at hente aktivet fra cache;
- hvis det mislykkes, prøv at hente fra netværket (med read-through caching);
- hvis det mislykkes, giv om muligt en offline fallback-ressource.
Offline-billede
Vi kan returnere et SVG-billede med teksten “Offline” som offline fallback ved at færdiggøre offlineResource-funktionen:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}Og lad os foretage de relevante opdateringer til config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};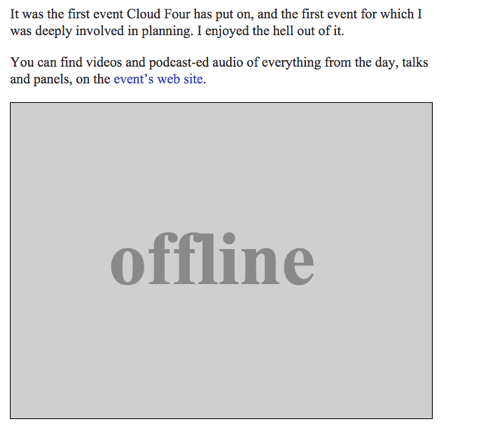
Hold øje med CDN’er
Hold øje med CDN’er, hvis du begrænser hentningshåndteringen til din oprindelse. Da jeg konstruerede min første service worker, glemte jeg, at min hostingudbyder shardede aktiver (billeder og scripts) på sit CDN, så de ikke længere blev serveret fra min hjemmesides oprindelse (lyza.com). Whoops! Det virkede ikke. Jeg endte med at deaktivere CDN’en for de berørte aktiver (men optimerede selvfølgelig disse aktiver!).
Færdiggørelse af den første version
Den første version af vores servicemedarbejder er nu færdig. Vi har en install-handler og en udbygget fetch-handler, der kan reagere på relevante hentninger med optimerede svar samt levere ressourcer i cachen og en offline-side, når de er offline.
Når brugerne gennemser webstedet, vil de fortsætte med at opbygge flere cachede elementer. Når de er offline, vil de kunne fortsætte med at gennemse de elementer, de allerede har fået cachet, eller de vil se en offline-side (eller et billede), hvis den ønskede ressource ikke er tilgængelig i cachen.
Den fulde kode med fetch-håndtering (serviceWorker.js) findes på GitHub.
Versionering og opdatering af serviceworkeren
Hvis intet nogensinde skulle ændres på vores websted igen, kunne vi sige, at vi er færdige. Service workers skal dog opdateres fra tid til anden. Måske vil jeg tilføje flere stier, der kan cachelagres. Måske vil jeg udvikle den måde, som mine offline fallbacks fungerer på. Måske er der noget lidt buggy i min service worker, som jeg vil rette.
Jeg vil gerne understrege, at der findes automatiserede værktøjer til at gøre administration af service workers til en del af din arbejdsgang, f.eks. Service Worker Precache fra Google. Du behøver ikke at administrere versionering af dette i hånden. Kompleksiteten på mit websted er dog lav nok til, at jeg bruger en menneskelig versioneringsstrategi til at administrere ændringer i min service worker. Dette består af:
- en simpel versionsstreng til at angive versioner,
- implementering af en
activatehandler til at rydde op efter gamle versioner, - opdatering af
installhåndteringen for at gøre opdaterede service workersactivatehurtigere.
Versionering af cache-nøgler
Jeg kan tilføje en version egenskab til mit config objekt:
version: 'aether'Dette skal ændres, hver gang jeg ønsker at distribuere en opdateret version af min service worker. Jeg bruger navnene på græske guder, fordi de er mere interessante for mig end tilfældige strenge eller tal.
Bemærk: Jeg har foretaget nogle ændringer i koden og tilføjet en bekvemmelighedsfunktion (cacheName) til at generere cache-nøgler med præfiksering. Det er tangentielt, så jeg medtager det ikke her, men du kan se det i den færdige service worker-kode.
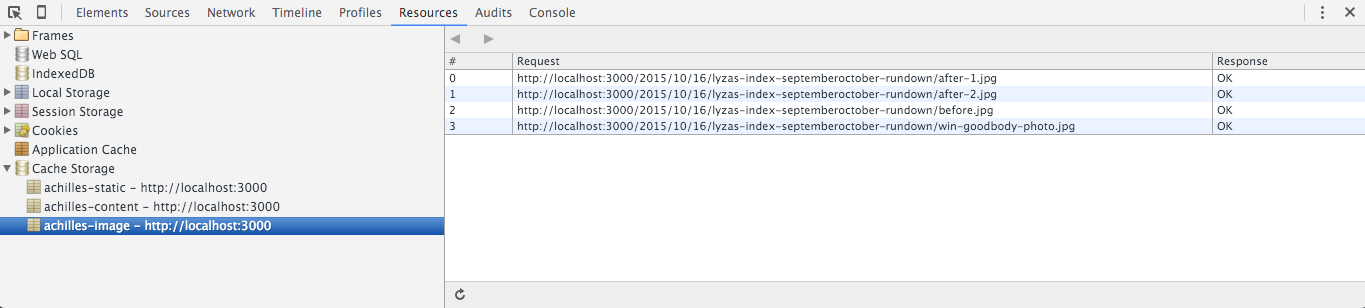
achilles.) (Se stor version)Du må ikke omdøbe din service worker
På et tidspunkt fjollede jeg rundt med navngivningskonventioner for service workerens filnavn. Lad være med at gøre dette. Hvis du gør det, vil browseren registrere den nye servicemedarbejder, men den gamle servicemedarbejder vil også forblive installeret. Det er en uoverskuelig situation. Jeg er sikker på, at der findes en løsning, men jeg vil sige, at du ikke skal omdøbe din service worker.
Brug ikke importScripts til config
Jeg gik en vej, hvor jeg lagde mit config-objekt i en ekstern fil og brugte self.importScripts() i service worker-filen til at trække dette script ind. Det virkede som en fornuftig måde at administrere min config på uden for servicemedarbejderen, men der var en hage.
Browseren byte- sammenligner servicemedarbejderfiler for at fastslå, om de er blevet opdateret – det er sådan, den ved, hvornår den skal udløse en download- og installationscyklus igen. Ændringer i den eksterne config medfører ingen ændringer i selve servicearbejderen, hvilket betyder, at ændringer i config ikke fik servicearbejderen til at blive opdateret. Hovsa.
Tilføjelse af en aktiveringshåndtering
Formålet med at have versionsspecifikke cachenavne er, at vi kan rydde op i cachenavne fra tidligere versioner. Hvis der er caches rundt omkring under aktivering, som ikke er præfikseret med den aktuelle versionsstreng, ved vi, at de skal slettes, fordi de er uoverskuelige.
Sanering af gamle caches
Vi kan bruge en funktion til at rydde op efter gamle caches:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Speeding Up Install and Activate
En opdateret servicemedarbejder bliver hentet og vil install i baggrunden. Det er nu en arbejdstager i vente. Som standard vil den opdaterede servicemedarbejder ikke blive aktiveret, mens der indlæses sider, som stadig bruger den gamle servicemedarbejder. Vi kan dog fremskynde dette ved at foretage en lille ændring i vores install-handler:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting vil få activate til at ske med det samme.
Færdiggør nu activate-handleren:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim vil få den nye servicemedarbejder til at træde i kraft med det samme på alle åbne sider i dens anvendelsesområde.

chrome://serviceworker-internals i Chrome for at se alle de servicemedarbejdere, som browseren har registreret. (Se stor version)
Ta-Da!
Vi har nu en versionsstyret servicemedarbejder! Du kan se den opdaterede serviceWorker.js fil med versionsstyring på GitHub.
Yderligere læsning på SmashingMag:
- A Beginner’s Guide To Progressive Web Apps
- Building A Simple Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web