
Om författaren
Lyza Danger Gardner är en dev. Sedan hon var med och grundade det mobila webbföretaget Cloud Four i Portland, Oregon, 2007 har hon plågat och roat sig själv med …Mer omLyza↬
- 23 min read
- Kodning,JavaScript,Tekniker,Service Workers
- Sparad för läsning offline
- Dela på Twitter, LinkedIn


Det råder ingen brist på uppmuntran eller entusiasm över det nya API:t Service Worker, som nu levereras i några populära webbläsare. Det finns kokböcker och blogginlägg, kodutdrag och verktyg. Men när jag vill lära mig ett nytt webbkoncept på djupet är det ofta bäst att kavla upp mina ärmar, dyka in och bygga något från grunden.
De stötar, problem och buggar som jag stötte på den här gången har fördelar: Nu förstår jag service workers mycket bättre, och med lite tur kan jag hjälpa dig att undvika några av de huvudvärksproblem som jag stötte på när jag arbetade med det nya API:t.
Service workers gör många olika saker och det finns otaliga sätt att utnyttja deras krafter. Jag bestämde mig för att bygga en enkel serviceworker för min (statiska, okomplicerade) webbplats som i stort sett speglar de funktioner som det föråldrade API:et Application Cache brukade erbjuda – det vill säga:
- göra att webbplatsen fungerar offline,
- öka prestandan online genom att minska nätverksförfrågningar för vissa tillgångar,
- tillhandahålla en anpassad offline fallback-upplevelse.
Innan jag börjar vill jag tacka två personer vars arbete gjort detta möjligt. För det första är jag Jeremy Keith enormt tacksam för genomförandet av service workers på hans egen webbplats, som tjänade som utgångspunkt för min egen kod. Jag inspirerades av hans senaste inlägg där han beskrev sina pågående erfarenheter av service workers. Faktum är att mitt arbete är så starkt avlett att jag inte skulle ha skrivit om det om det inte vore för Jeremys uppmaning i ett tidigare inlägg:
Så om du bestämmer dig för att leka med Service Workers, var snäll, var snäll och dela med dig av dina erfarenheter.
För det andra vill jag rikta ett stort tack till Jake Archibald för hans utmärkta tekniska granskning och återkoppling. Det är alltid trevligt när en av serviceworker-specifikationens skapare och evangelister kan ge dig rätt!
Vad är en serviceworker?
En serviceworker är ett skript som står mellan din webbplats och nätverket, vilket bland annat ger dig möjlighet att avlyssna nätverksförfrågningar och svara på dem på olika sätt.
För att din webbplats eller app ska fungera hämtar webbläsaren sina tillgångar – t.ex. HTML-sidor, JavaScript, bilder, typsnitt. Tidigare var det främst webbläsaren som skötte detta. Om webbläsaren inte kunde få tillgång till nätverket skulle du förmodligen få se meddelandet ”Hej, du är offline”. Det fanns tekniker som man kunde använda för att uppmuntra lokal cachelagring av tillgångar, men webbläsaren hade ofta sista ordet.
Detta var inte en så bra upplevelse för användare som var offline, och det lämnade webbutvecklare med liten kontroll över webbläsarens cachelagring.
Så kom Application Cache (eller AppCache), vars ankomst för flera år sedan verkade lovande. Den skulle tydligen låta dig diktera hur olika tillgångar skulle hanteras, så att din webbplats eller app skulle kunna fungera offline. Men AppCaches enkla syntax motsvarade dess underliggande förvirrande karaktär och brist på flexibilitet.
Det nya API:et för service workers kan göra det som AppCache gjorde, och mycket mer. Men det ser lite skrämmande ut i början. Specifikationerna är tunga och abstrakta att läsa, och många API:er är underordnade eller på annat sätt relaterade till den: cache, fetch osv. Service workers omfattar så mycket funktionalitet: push-notiser och snart även bakgrundssynkronisering. Jämfört med AppCache ser det… komplicerat ut.
Varemot AppCache (som förresten är på väg bort) var lätt att lära sig men fruktansvärt för varje ögonblick därefter (min åsikt), är service workers mer av en initial kognitiv investering, men de är kraftfulla och användbara, och du kan i allmänhet ta dig ur trubbel om du förstör saker och ting.
Några grundläggande begrepp för service workers
En service worker är en fil med lite JavaScript i den. I den filen kan du skriva JavaScript som du känner till och älskar det, med några viktiga saker att tänka på.
Service worker-skript körs i en separat tråd i webbläsaren från de sidor de styr. Det finns sätt att kommunicera mellan workers och sidor, men de körs i ett separat scope. Det innebär att du till exempel inte har tillgång till DOM för dessa sidor. Jag visualiserar en service worker som att den liksom körs i en separat flik från den sida den påverkar; detta är inte alls korrekt, men det är en hjälpsam grov metafor för att hålla mig utanför förvirring.
JavaScript i en service worker får inte blockera. Du måste använda asynkrona API:er. Du kan till exempel inte använda localStorage i en service worker (localStorage är ett synkront API). Humoristiskt nog lyckades jag, trots att jag visste detta, löpa risken att bryta mot det, vilket vi kommer att se.
Registrering av en serviceworker
Du får en serviceworker att träda i kraft genom att registrera den. Denna registrering görs utanför servicearbetaren, av en annan sida eller ett annat skript på din webbplats. På min webbplats finns ett globalt site.js-skript på varje HTML-sida. Jag registrerar min service worker därifrån.
När du registrerar en service worker talar du (frivilligt) också om för den vilket tillämpningsområde den ska tillämpa sig på. Du kan instruera en service worker att bara hantera saker för en del av din webbplats (till exempel '/blog/') eller så kan du registrera den för hela din webbplats ('/') som jag gör.
Service Worker Lifecycle And Events
En service worker gör huvuddelen av sitt arbete genom att lyssna efter relevanta händelser och svara på dem på användbara sätt. Olika händelser utlöses vid olika punkter i en servicearbetares livscykel.
När servicearbetaren har registrerats och laddats ner installeras den i bakgrunden. Din service worker kan lyssna på install-händelsen och utföra uppgifter som är lämpliga för detta steg.
I vårt fall vill vi dra nytta av install-tillståndet för att pre-cacha ett gäng tillgångar som vi vet att vi kommer att vilja ha tillgängliga offline senare.
När install-steget är avslutat aktiveras serviceworkaren sedan. Det innebär att servicearbetaren nu har kontroll över saker och ting inom sin scope och kan göra sin sak. Händelsen activate är inte särskilt spännande för en ny service worker, men vi kommer att se hur den är användbar när man uppdaterar en service worker med en ny version.
Exakt när aktiveringen sker beror på om det är en helt ny service worker eller en uppdaterad version av en redan existerande service worker. Om webbläsaren inte har en tidigare version av en viss service worker redan registrerad kommer aktiveringen att ske omedelbart efter att installationen är klar.
När installationen och aktiveringen är klar kommer de inte att inträffa igen förrän en uppdaterad version av serviceworkaren har laddats ner och registrerats.
Bortom installation och aktivering kommer vi i dag främst att titta på fetch-händelsen för att göra vår service worker användbar. Men det finns flera användbara händelser utöver det: synkroniseringshändelser och notifieringshändelser, till exempel.
För extrapoäng eller för att ha roligt på fritiden kan du läsa mer om de gränssnitt som service workers implementerar. Det är genom att implementera dessa gränssnitt som service workers får huvuddelen av sina händelser och mycket av sin utökade funktionalitet.
The Service Worker’s Promise-Based API
The service worker API gör stor användning av Promises. Ett löfte representerar det slutliga resultatet av en asynkron operation, även om det faktiska värdet inte kommer att vara känt förrän operationen avslutas någon gång i framtiden.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});Funktionen getAnAnswer… returnerar ett Promise som (vi hoppas) så småningom kommer att uppfyllas av, eller lösas upp till, det answer vi letar efter. Därefter kan den answer matas till alla kedjade then handlingsfunktioner, eller, i det tråkiga fallet att målet inte uppnås, kan Promise avvisas – ofta med en anledning – och catch handlingsfunktioner kan ta hand om dessa situationer.
Det finns mer att lova, men jag ska försöka hålla exemplen här enkla (eller åtminstone kommenterade). Jag uppmanar dig att göra lite informativ läsning om du är nybörjare på promises.
Anmärkningar: Jag använder vissa ECMAScript6- (eller ES2015-) funktioner i exempelkoden för service workers eftersom webbläsare som har stöd för service workers också har stöd för dessa funktioner. Här använder jag särskilt pilfunktioner och mallsträngar.
Other Service Worker Necessities
Notera också att service workers kräver HTTPS för att fungera. Det finns ett viktigt och användbart undantag från denna regel: Service workers fungerar för localhost på osäkra http, vilket är en lättnad eftersom det ibland är en besvärlig uppgift att konfigurera lokalt SSL.
Skoj: Det här projektet tvingade mig att göra något som jag hade skjutit upp ett tag: att skaffa och konfigurera SSL för www-subdomänen på min webbplats. Detta är något som jag uppmanar folk att överväga att göra eftersom i stort sett alla nya roliga saker som kommer att finnas i webbläsaren i framtiden kommer att kräva att SSL används.
Alla saker som vi kommer att sätta ihop fungerar idag i Chrome (jag använder version 47). När som helst nu kommer Firefox 44 att levereras, och den har stöd för service workers. Is Service Worker Ready? ger detaljerad information om stöd i olika webbläsare.
Registering, Installing And Activating A Service Worker
Nu när vi har tagit hand om lite teori kan vi börja sätta ihop vår serviceworker.
För att installera och aktivera vår service worker vill vi lyssna på install och activate händelser och agera på dem.
Vi kan börja med en tom fil för vår service worker och lägga till ett par eventListeners. I serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registering Our Service Worker
Nu måste vi tala om för sidorna på vår webbplats att de ska använda servicearbetaren.
Håll dig i minnet att den här registreringen sker utanför servicearbetaren – i mitt fall från ett skript (/js/site.js) som finns med på varje sida på min webbplats.
I min site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pre-Caching Static Assets During Install
Jag vill använda installationsfasen för att pre-cacha vissa tillgångar på min webbplats.
- Genom att förlagra vissa statiska tillgångar (bilder, CSS, JavaScript) som används av många sidor på min webbplats kan jag snabba upp laddningstiderna genom att hämta dessa från cacheminnet, i stället för att hämta dem från nätverket vid efterföljande sidinläsningar.
- Genom att förlagra en offline-fallback-sida kan jag visa en trevlig sida när jag inte kan uppfylla en sidförfrågan eftersom användaren är offline.
Stråken för att göra detta är:
- Säg till
install-händelsen att vänta och inte slutföra förrän jag har gjort det jag behöver göra med hjälp avevent.waitUntil. - Öppna lämplig
cache, och sätt in de statiska tillgångarna i den med hjälp avCache.addAll. I progressiv webbapplikationsspråk utgör dessa tillgångar mitt ”applikationsskal”.”
I /serviceWorker.js expanderar vi install-hanteraren:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Servicemedarbetaren implementerar CacheStorage-gränssnittet, vilket gör caches-egenskapen tillgänglig globalt i vår servicemedarbetare. Det finns flera användbara metoder på caches – till exempel open och delete.
Du kan se Promises i arbete här: caches.open returnerar en Promise som löser upp ett cache-objekt när den framgångsrikt har öppnat static-cachen; addAll returnerar också en Promise som löser upp när alla objekt som överlämnats till den har gömts i cachen.
Jag säger till event att vänta tills Promise som returneras av min handläggarfunktion har lösts upp framgångsrikt. Då kan vi vara säkra på att alla dessa för-cache-objekt sorteras innan installationen är klar.
Konsolförvirring
Stale Logging
Möjligen inte ett fel, men säkert en förvirring: Om du console.log från servicearbetare fortsätter Chrome att visa loggmeddelandena på nytt (i stället för att radera dem) vid efterföljande sidförfrågningar. Detta kan få det att se ut som om händelser utlöses för många gånger eller som om kod körs om och om igen.
Till exempel, låt oss lägga till ett log-meddelande till vår install-hanterare:
self.addEventListener('install', event => { // … as before console.log('installing');});
install-händelsen vid varje sidladdning. Istället visas föråldrade loggar. (Visa stor version)Ett fel när allt är okej
En annan märklig sak är att när en serviceworker väl har installerats och aktiverats kommer efterföljande sidinläsningar för alla sidor inom dess räckvidd alltid att orsaka ett enda fel i konsolen. Jag trodde att jag gjorde något fel.

Vad vi har åstadkommit hittills
Servicemedarbetaren hanterar install-händelsen och förlagrar några statiska tillgångar. Om du skulle använda den här servicearbetaren och registrera den skulle den faktiskt pre-cacha de angivna tillgångarna, men skulle ännu inte kunna dra nytta av dem offline.
Innehållet i serviceWorker.js finns på GitHub.
Fetch-hantering med servicearbetare
So långt har vår servicearbetare en utbyggd install-hanterare, men gör ingenting utöver det. Magin i vår serviceworker kommer verkligen att ske när fetch-händelser utlöses.
Vi kan reagera på hämtningar på olika sätt. Genom att använda olika nätverksstrategier kan vi tala om för webbläsaren att alltid försöka hämta vissa tillgångar från nätverket (vilket säkerställer att nyckelinnehållet är färskt), samtidigt som vi föredrar cachelagda kopior för statiska tillgångar – vilket verkligen bantar ner sidans nyttolast. Vi kan också tillhandahålla en trevlig offline-fallback om allt annat misslyckas.
När en webbläsare vill hämta en tillgång som ligger inom räckvidden för den här servicearbetaren kan vi höra om det genom att, ja, lägga till en eventListener i serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Och, varje hämtning som ligger inom räckvidden för den här servicearbetarens räckvidd (dvs. sökvägen) utlöser den här händelsen – HTML-sidor, skript, bilder, CSS, du kan nämna det. Vi kan selektivt hantera hur webbläsaren svarar på någon av dessa hämningar.
Ska vi hantera den här hämningen?
När en fetch-händelse inträffar för en resurs är det första jag vill avgöra om den här servicearbetaren ska störa hämtningen av den givna resursen. I annat fall ska den inte göra någonting och låta webbläsaren hävda sitt standardbeteende.
Vi kommer att sluta med grundläggande logik som denna i serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});Funktionen shouldHandleFetch bedömer en given begäran för att avgöra om vi ska ge ett svar eller låta webbläsaren hävda sin standardhantering.
Varför inte använda löften?
För att hålla mig till servicearbetarens förkärlek för löften såg den första versionen av min fetchhändelsehanterare ut så här:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Det verkar logiskt, men jag gjorde ett par nybörjarmisstag med löften. Jag svär på att jag kände en kodlukt redan från början, men det var Jake som visade mig mina misstag. (Lektion: Som alltid, om koden känns fel är den förmodligen det.)
Löfteavslag bör inte användas för att indikera: ”Jag fick ett svar som jag inte gillade”. Istället bör avvisningar indikera, ”Ah, skit, något gick fel när jag försökte få svaret”. Det vill säga, avslag ska vara exceptionella.
Kriterier för giltiga förfrågningar
Okej, tillbaka till att avgöra om en viss hämtningsförfrågan är tillämplig för min servicearbetare. Mina platsspecifika kriterier är följande:
- Den begärda URL:n ska representera något som jag vill cacha eller svara på. Dess sökväg ska matcha en
Regular Expressionav giltiga sökvägar. - Förfrågningens HTTP-metod ska vara
GET. - Förfrågan ska gälla en resurs från mitt ursprung (
lyza.com).
Om något av criteria-testerna utvärderar till false, ska vi inte hantera den här begäran. I serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Kriterierna här är naturligtvis mina egna och skulle variera från plats till plats. event.request är ett Request-objekt som har alla typer av data som du kan titta på för att bedöma hur du vill att din fetch-hanterare ska bete sig.
Triviell anmärkning: Om du har lagt märke till config, som överlämnats som opts till hanterarfunktioner, så är det bra upptäckt. Jag tog bort några återanvändbara config-liknande värden och skapade ett config-objekt i toppnivåns scope för servicearbetaren:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Varför Whitelist?
Du kanske undrar varför jag bara cachelagrar saker med sökvägar som matchar det här reguljära uttrycket:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… i stället för att cachelagra allt som kommer från mitt eget ursprung. Ett par anledningar:
- Jag vill inte cacha själva servicearbetaren.
- När jag utvecklar min webbplats lokalt genereras vissa förfrågningar för saker som jag inte vill cacha. Jag använder till exempel
browserSync, vilket startar en massa relaterade begäranden i min utvecklingsmiljö. Jag vill inte cacha dessa saker! Det verkade rörigt och utmanande att försöka tänka på allt jag inte vill cachelagra (för att inte tala om att det var lite konstigt att behöva stava ut det i min servicearbetares konfiguration). Så en whitelist-strategi verkade mer naturlig.
Skrivning av Fetch Handler
Nu är vi redo att skicka tillämpliga fetch-förfrågningar vidare till en handläggare. onFetch-funktionen måste avgöra:
- vilken typ av resurs som begärs,
- och hur jag ska uppfylla denna begäran.
1. Vilken typ av resurs begärs?
Jag kan titta på HTTP Accept-huvudet för att få en antydan om vilken typ av resurs som begärs. Detta hjälper mig att räkna ut hur jag vill hantera det.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}För att hålla mig organiserad vill jag stoppa olika typer av resurser i olika cacher. På så sätt kan jag hantera dessa cacher senare. Dessa cache key Strings är godtyckliga – du kan kalla dina cacher vad du vill; cache API:et har inga åsikter.
2. Svara på Fetch
Nästa sak för onFetch att göra är att respondTo händelsen fetch med en intelligent Response.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Försiktigt med asynk!
I vårt fall gör shouldHandleFetch ingenting asynkront, och inte heller onFetch fram till event.respondWith. Om något asynkront hade hänt innan dess skulle vi ha problem. event.respondWith måste anropas mellan det att fetch-händelsen utlöses och kontrollen återgår till webbläsaren. Samma sak gäller för event.waitUntil. I grund och botten, om du hanterar en händelse, ska du antingen göra något omedelbart (synkront) eller tala om för webbläsaren att vänta tills dina asynkrona saker är gjorda.
HTML-innehåll:
Att svara på fetch-förfrågningar innebär att man måste implementera en lämplig nätverksstrategi. Låt oss titta närmare på hur vi svarar på förfrågningar om HTML-innehåll (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}Det sätt på vilket vi uppfyller förfrågningar om innehåll här är en strategi för nätverk först. Eftersom HTML-innehåll är kärnan i min webbplats och det ändras ofta, försöker jag alltid få färska HTML-dokument från nätverket.
Vi går igenom detta stegvis.
1. Försök hämta från nätverket
fetch(request) .then(response => addToCache(cacheKey, request, response))Om nätverksförfrågan är framgångsrik (dvs. löftet löses upp), gå vidare och förvara en kopia av HTML-dokumentet i lämplig cache (content). Detta kallas read-through caching:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Svar får endast användas en gång.
Vi måste göra två saker med response vi har:
- cacha det,
- respondera på händelsen med det (dvs. returnera det).
Men Response-objekt får endast användas en gång. Genom att klona det kan vi skapa en kopia för användning i cachen:
var copy = response.clone();
Du får inte cacha dåliga svar. Gör inte samma misstag som jag gjorde. Den första versionen av min kod hade inte det här villkoret:
if (response.ok)Ganska häftigt att hamna med 404 eller andra dåliga svar i cachen! Cacha bara lyckliga svar.
2. Försök hämta från cacheminnet
Om det lyckas att hämta tillgången från nätverket är vi klara. Men om det inte gör det kan vi vara offline eller på annat sätt ha äventyrat nätverket. Försök att hämta en tidigare cachad kopia av HTML-filen från cache:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Här är fetchFromCache-funktionen:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Notera: Ange inte vilken cache du vill kontrollera med caches.match; kontrollera alla på en gång.
3. Ge en offline-fallback
Om vi har kommit så här långt men det inte finns något i cachen som vi kan svara med, returnera en lämplig offline-fallback, om möjligt. För HTML-sidor är detta den sida som finns i cacheminnet från /offline/. Det är en någorlunda välformaterad sida som talar om för användaren att de är offline och att vi inte kan uppfylla det de söker.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))Och här är offlineResponse-funktionen:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}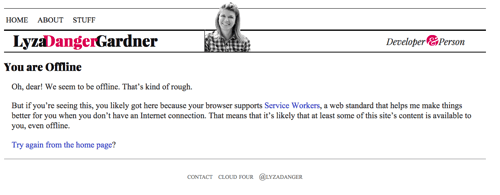
Övriga resurser: Implementing A Cache-First Strategy
Hämtningslogiken för andra resurser än HTML-innehåll använder en cache-first-strategi. Bilder och annat statiskt innehåll på webbplatsen ändras sällan, så kontrollera först i cacheminnet och undvik att gå runt i nätverket.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Stråken här är:
- försök att hämta resursen från cacheminnet;
- om det misslyckas, försök att hämta den från nätverket (med read-through-cachelagring);
- om det misslyckas, tillhandahåll en offline-utfallsresurs, om det är möjligt.
Offline Image
Vi kan returnera en SVG-bild med texten ”Offline” som offline-fallback genom att komplettera offlineResource-funktionen:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}Och låt oss göra de relevanta uppdateringarna av config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};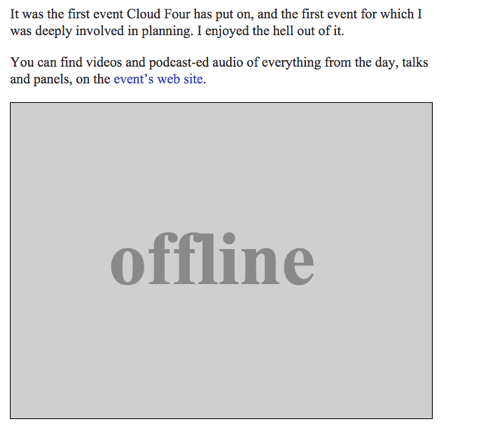
Var försiktig med CDN:er
Var försiktig med CDN:er om du begränsar hämtningshanteringen till ditt ursprung. När jag konstruerade min första serviceworker glömde jag att min webbhotellleverantör hade lagt tillgångar (bilder och skript) på sitt CDN, så att de inte längre serverades från min webbplats ursprung (lyza.com). Hoppsan! Det fungerade inte. Det slutade med att jag inaktiverade CDN för de drabbade tillgångarna (men optimerade dessa tillgångar, förstås!).
Färdigställande av den första versionen
Den första versionen av vår tjänstearbetare är nu klar. Vi har en install-hanterare och en utbyggd fetch-hanterare som kan svara på tillämpliga hämtningar med optimerade svar, samt tillhandahålla cachelagda resurser och en offlinesida när de är offline.
När användarna surfar på webbplatsen kommer de att fortsätta att bygga upp fler cachelagda objekt. När de är offline kan de fortsätta att bläddra i objekt som de redan har cachelagrat, eller så visas en offline-sida (eller bild) om den begärda resursen inte finns tillgänglig i cacheminnet.
Den fullständiga koden med fetchhantering (serviceWorker.js) finns på GitHub.
Versionering och uppdatering av Service Worker
Om ingenting någonsin skulle förändras på vår webbplats igen skulle vi kunna säga att vi är klara. Service workers behöver dock uppdateras från tid till annan. Kanske vill jag lägga till fler sökvägar som kan lagras i cache. Kanske vill jag utveckla hur mina offline fallbacks fungerar. Kanske finns det något litet buggigt i min serviceworker som jag vill rätta till.
Jag vill betona att det finns automatiserade verktyg för att göra serviceworkerhantering till en del av ditt arbetsflöde, till exempel Service Worker Precache från Google. Du behöver inte hantera versionshantering för hand. Komplexiteten på min webbplats är dock tillräckligt låg för att jag använder en mänsklig versioneringsstrategi för att hantera ändringar i min serviceworker. Denna består av:
- en enkel versionssträng för att ange versioner,
- implementering av en
activatehanterare för att städa upp efter gamla versioner, - uppdatering av
installhanteraren för att göra uppdaterade service workersactivatesnabbare.
Versioning Cache Keys
Jag kan lägga till en version egenskap till mitt config objekt:
version: 'aether'Detta bör ändras varje gång jag vill distribuera en uppdaterad version av min service worker. Jag använder namnen på grekiska gudomar eftersom de är mer intressanta för mig än slumpmässiga strängar eller siffror.
Anmärkningar: Jag har gjort några ändringar i koden och lagt till en bekvämlighetsfunktion (cacheName) för att generera cache-nycklar med prefix. Den är tangentiell, så jag tar inte med den här, men du kan se den i den färdiga koden för servicearbetaren.
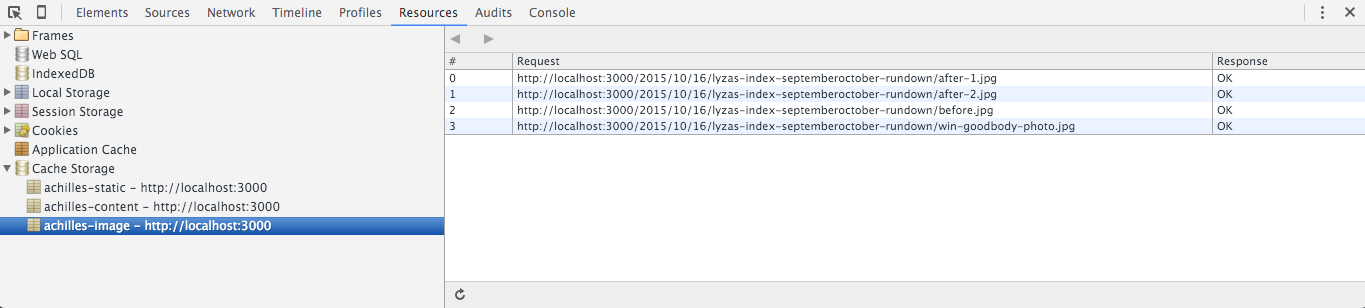
achilles.) (Visa stor version)Byt inte namn på din serviceworker
Vid ett tillfälle höll jag på att leka med namnkonventioner för servicearbetarens filnamn. Gör inte så här. Om du gör det kommer webbläsaren att registrera den nya servicearbetaren, men den gamla servicearbetaren kommer också att förbli installerad. Detta är ett rörigt tillstånd. Det finns säkert en lösning, men jag skulle säga att du inte ska byta namn på din service worker.
Använd inte importScripts för config
Jag gick en väg som gick ut på att lägga mitt config-objekt i en extern fil och använda self.importScripts() i serviceworkerfilen för att dra in det skriptet. Det verkade vara ett rimligt sätt att hantera min config utanför servicearbetaren, men det fanns ett problem.
Browsern gör en byte-jämförelse av servicearbetarfilerna för att avgöra om de har uppdaterats – det är så den vet när den ska återaktivera en nedladdnings- och installationscykel. Ändringar i den externa config orsakar inga ändringar i själva servicearbetaren, vilket innebär att ändringar i config inte orsakade någon uppdatering av servicearbetaren. Whoops.
Adding An Activate Handler
Syftet med att ha versionsspecifika cache-namn är att vi ska kunna rensa upp cacher från tidigare versioner. Om det finns cacher som finns under aktiveringen och som inte har prefix med strängen för den aktuella versionen, vet vi att de bör raderas eftersom de är krystade.
Rensning av gamla cacher
Vi kan använda en funktion för att städa upp efter gamla cacher:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Snabbare installation och aktivering
En uppdaterad serviceworker kommer att laddas ner och kommer install att ske i bakgrunden. Det är nu en arbetare som väntar. Som standard kommer den uppdaterade servicearbetaren inte att aktiveras medan sidor laddas som fortfarande använder den gamla servicearbetaren. Vi kan dock påskynda detta genom att göra en liten ändring i vår install-hanterare:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting kommer att leda till att activate sker omedelbart.
Färdigställ nu activate-hanteraren:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim gör att den nya servicearbetaren träder i kraft omedelbart på alla öppna sidor i dess räckvidd.

chrome://serviceworker-internals i Chrome för att se alla de servicearbetare som webbläsaren har registrerat. (Visa stor version)
Ta-Da!
Vi har nu en versionshanterad servicearbetare! Du kan se den uppdaterade serviceWorker.js-filen med versionshantering på GitHub.
Ytterligare läsning på SmashingMag:
- A Beginner’s Guide To Progressive Web Apps
- Building A Simple Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web