
O autorovi
Lyza Danger Gardner je dev. Od roku 2007, kdy spoluzaložila mobilní webový startup Cloud Four se sídlem v Portlandu v Oregonu, se trápí a vzrušuje s …Více oLyza↬
- 23 min čtení
- Kódování,JavaScript,Techniky,Pracovníci služeb
- Uloženo pro offline čtení
- Sdílet na Twitteru, LinkedIn


Ve vznikajícím rozhraní API service worker, které se nyní dodává v některých populárních prohlížečích, není nouze o povzbuzování a nadšení. Existují kuchařky a příspěvky na blogu, úryvky kódu a nástroje. Zjistil jsem však, že když se chci důkladně naučit nový webový koncept, je často ideální vyhrnout si pověstné rukávy, ponořit se do toho a vytvořit něco od nuly.
Nárazy a modřiny, zádrhele a chyby, na které jsem tentokrát narazil, mají své výhody:
Service workers dělají spoustu různých věcí; existuje nespočet způsobů, jak využít jejich schopností. Rozhodl jsem se vytvořit jednoduchý service worker pro svůj (statický, nekomplikovaný) web, který zhruba odráží funkce, které poskytovalo zastaralé API Application Cache – tedy:
- zajistit fungování webu v režimu offline,
- zvýšit výkon online snížením síťových požadavků na určité prostředky,
- zajistit přizpůsobený offline fallback.
Před začátkem bych chtěl ocenit dva lidi, díky jejichž práci bylo možné tento článek vytvořit. Zaprvé jsem nesmírně zavázán Jeremymu Keithovi za implementaci servisních pracovníků na jeho vlastním webu, která posloužila jako výchozí bod pro můj vlastní kód. Inspiroval mě jeho nedávný příspěvek popisující jeho průběžné zkušenosti se service workery. Ve skutečnosti je moje práce tak silně odvozená, že bych o ní nenapsal, nebýt Jeremyho nabádání v dřívějším příspěvku:
Takže pokud se rozhodnete pohrát si se service workery, prosím, podělte se o své zkušenosti.
Druhé, všelijaké staré velké díky Jakeu Archibaldovi za jeho vynikající technickou recenzi a zpětnou vazbu. Vždy je příjemné, když vás jeden z tvůrců a evangelistů specifikace Service Worker dokáže uvést na pravou míru!
Co je Service Worker?
Service Worker je skript, který stojí mezi vaším webem a sítí a dává vám mimo jiné možnost zachytávat síťové požadavky a různými způsoby na ně reagovat.
Aby váš web nebo aplikace fungovaly, prohlížeč si načítá jejich prostředky – například stránky HTML, JavaScript, obrázky, písma. V minulosti byla jejich správa především výsadou prohlížeče. Pokud by prohlížeč nemohl přistupovat k síti, pravděpodobně byste viděli jeho zprávu „Hej, jste offline“. Existovaly techniky, kterými jste mohli podpořit lokální ukládání prostředků do mezipaměti, ale poslední slovo měl často prohlížeč.
To nebylo pro uživatele, kteří byli offline, příliš příjemné a vývojářům webu to ponechávalo jen malou kontrolu nad ukládáním prostředků do mezipaměti prohlížeče.
Přišla na řadu mezipaměť aplikací (neboli AppCache), jejíž příchod před několika lety vypadal slibně. Údajně umožňovala diktovat, jak se má zacházet s různými prostředky, aby web nebo aplikace mohly fungovat offline. Jednoduše vypadající syntaxe AppCache však popírala její základní zmatečnost a nedostatečnou flexibilitu.
Začínající rozhraní API Service Worker umí to, co AppCache, a ještě mnohem víc. Na první pohled však vypadá poněkud skličujícím způsobem. Specifikace jsou těžkým a abstraktním čtením a řada API je mu podřízena nebo s ním jinak souvisí: cache, fetch atd. Service workers zahrnují tolik funkcí: push notifikace a brzy i synchronizaci na pozadí. Ve srovnání s AppCache to vypadá… komplikovaně.
Když AppCache (která mimochodem zaniká) bylo snadné se naučit, ale příšerné každou chvíli poté (můj názor), service workers jsou spíše počáteční kognitivní investicí, ale jsou výkonné a užitečné, a pokud něco rozbijete, můžete se z problémů zpravidla dostat sami.
Několik základních konceptů service workerů
Service worker je soubor s nějakým JavaScriptem. V tomto souboru můžete psát JavaScript tak, jak ho znáte a máte rádi, přičemž je třeba mít na paměti několik důležitých věcí.
Skripty Service Worker běží ve vlákně prohlížeče odděleném od stránek, které ovládají. Existují způsoby komunikace mezi pracovními skripty a stránkami, které se však vykonávají v odděleném oboru. To znamená, že nebudete mít přístup například k DOM těchto stránek. Představuji si service worker jako něco jako běh v oddělené kartě od stránky, kterou ovlivňuje; není to vůbec přesné, ale je to užitečná hrubá metafora, abych se vyvaroval zmatků.
JavaScript v service workeru nesmí blokovat. Je třeba používat asynchronní rozhraní API. Například nelze použít localStorage v service workeru (localStorage je synchronní API). Humorné je, že i když jsem to věděl, podařilo se mi to porušit, jak uvidíme.
Registrace service workeru
Service worker uvedete v činnost tím, že ho zaregistrujete. Tato registrace se provádí mimo service worker, prostřednictvím jiné stránky nebo skriptu na vašem webu. Na mém webu je globální skript site.js součástí každé stránky HTML. Z něj registruji svůj service worker.
Při registraci service workeru mu také (volitelně) sdělíte, v jakém rozsahu se má uplatnit. Pracovníka služby můžete instruovat, aby zpracovával věci pouze pro část vašeho webu (například '/blog/'), nebo ho můžete zaregistrovat pro celý web ('/'), jako to dělám já.
Životní cyklus pracovníka služby a události
Pracovník služby vykonává většinu své práce tím, že naslouchá příslušným událostem a užitečným způsobem na ně reaguje. V různých bodech životního cyklu service workeru se spouštějí různé události.
Po registraci a stažení se service worker nainstaluje na pozadí. Váš servisní pracovník může naslouchat události install a provádět úkoly vhodné pro tuto fázi.
V našem případě chceme využít stavu install k předběžnému uložení několika prostředků, o kterých víme, že je budeme chtít mít později k dispozici offline.
Po dokončení fáze install je pak servisní pracovník aktivován. To znamená, že servisní pracovník má nyní kontrolu nad věcmi v rámci svého scope a může dělat své věci. Událost activate není pro nový service worker příliš zajímavá, ale uvidíme, jak je užitečná při aktualizaci service workeru novou verzí.
Přesný okamžik aktivace závisí na tom, zda se jedná o zcela nový service worker, nebo o aktualizovanou verzi již existujícího service workeru. Pokud prohlížeč nemá již zaregistrovanou předchozí verzi daného service workeru, dojde k aktivaci ihned po dokončení instalace.
Po dokončení instalace a aktivace k nim již nedojde, dokud nebude stažena a zaregistrována aktualizovaná verze service workeru.
Kromě instalace a aktivace se dnes budeme zabývat především událostí fetch, aby byl náš service worker užitečný. Existuje však i několik dalších užitečných událostí: například události synchronizace a události oznámení.
Pro zápočet navíc nebo zábavu ve volném čase si můžete přečíst více o rozhraních, která service workers implementují. Právě implementací těchto rozhraní získávají service workery většinu svých událostí a velkou část své rozšířené funkčnosti.
Interface API service workeru založené na slibech
Interface API service workeru hojně využívá Promises. Příslib představuje případný výsledek asynchronní operace, i když jeho skutečná hodnota bude známa až po dokončení operace někdy v budoucnu.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});Funkce getAnAnswer… vrací Promise, který (doufáme) bude nakonec splněn nebo přeložen na hledaný answer. Tento answer pak můžeme předat libovolně zřetězené obslužné funkci then, nebo v žalostném případě nedosažení cíle můžeme Promise odmítnout – často s uvedením důvodu – a o tyto situace se postarají obslužné funkce catch.
Slibů je více, ale pokusím se, aby zde byly příklady jednoduché (nebo alespoň komentované). Vyzývám vás, abyste si něco informativně přečetli, pokud jste v oblasti slibů nováčky.
Poznámka: V ukázkovém kódu pro servisní pracovníky používám některé funkce jazyka ECMAScript6 (nebo ES2015), protože prohlížeče, které podporují servisní pracovníky, tyto funkce také podporují. Konkrétně zde používám šipkové funkce a šablonové řetězce.
Další nezbytnosti servisních pracovníků
Také si všimněte, že servisní pracovníci vyžadují ke své činnosti protokol HTTPS. Z tohoto pravidla existuje důležitá a užitečná výjimka:
Zábavný fakt: Tento projekt mě donutil udělat něco, co jsem nějakou dobu odkládal: získat a nakonfigurovat SSL pro subdoménu www mého webu. To je něco, co bych lidem doporučil, aby zvážili, protože téměř všechny nové zábavné věci, které se v budoucnu dostanou do prohlížeče, budou vyžadovat použití SSL.
Všechny věci, které dáme dohromady, dnes fungují v prohlížeči Chrome (používám verzi 47). Každým dnem bude dodán Firefox 44, který podporuje pracovníky služeb. V článku Is Service Worker Ready? najdete podrobné informace o podpoře v různých prohlížečích.
Registrace, instalace a aktivace Service Workeru
Teď, když jsme se postarali o trochu teorie, můžeme začít sestavovat náš Service Worker.
Pro instalaci a aktivaci našeho service workeru chceme naslouchat událostem install a activate a jednat podle nich.
Můžeme začít s prázdným souborem pro náš service worker a přidat pár eventListeners. V serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registrace našeho service workeru
Nyní musíme říct stránkám na našem webu, aby používaly service worker.
Pamatujte, že tato registrace probíhá mimo service worker – v mém případě ze skriptu (/js/site.js), který je součástí každé stránky mého webu.
V mém site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Přednačítání statických prostředků během instalace
Chci použít fázi instalace k přednačítání některých prostředků na svém webu.
- Přednačítáním některých statických prostředků (obrázky, CSS, JavaScript), které používá mnoho stránek na mém webu, mohu zrychlit načítání tím, že je budu brát z mezipaměti, místo aby se při dalším načítání stránky načítaly ze sítě.
- Přednačítáním offline záložní stránky mohu zobrazit pěknou stránku, když nemohu splnit požadavek na stránku, protože uživatel je offline.
Kroky k tomu jsou následující:
- Příkazem
event.waitUntilřeknu událostiinstall, aby se zdržela a nedokončila se, dokud neudělám, co potřebuji. - Otevřu příslušný
cachea pomocíCache.addAlldo něj vložím statické prostředky. V řeči progresivních webových aplikací tvoří tato aktiva můj „obal aplikace“.
V /serviceWorker.js rozbalíme obslužný program install:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Obslužný program implementuje rozhraní CacheStorage, které v našem obslužném programu globálně zpřístupní vlastnost caches. Na caches existuje několik užitečných metod – například open a delete.
Na tomto místě můžete vidět Promises při práci: caches.open vrací Promise, který se resolvuje na objekt cache, jakmile úspěšně otevře static mezipaměť; addAll také vrací Promise, který se resolvuje, jakmile jsou všechny položky, které mu byly předány, uloženy do mezipaměti.
Řeknu event, aby počkal, dokud se Promise vrácený mou obslužnou funkcí úspěšně nevyřeší. Pak si můžeme být jisti, že se všechny tyto položky před uložením do mezipaměti roztřídí ještě před dokončením instalace.
Zmatky v konzoli
Zálohování logů
Nejspíš nejde o chybu, ale určitě o zmatek: Pokud console.log z pracovníků služeb, bude Chrome při dalších požadavcích na stránku tyto zprávy protokolu nadále znovu zobrazovat (místo aby je vymazal). To může způsobit, že to vypadá, jako by se události spouštěly příliš mnohokrát nebo jako by se kód spouštěl stále dokola.
Příklad přidejme příkaz log do naší obslužné rutiny install:
self.addEventListener('install', event => { // … as before console.log('installing');});
install při každém načtení stránky. Místo toho zobrazuje neaktuální protokoly. (Zobrazit velkou verzi)Chybová hláška, i když je vše v pořádku
Další podivnou věcí je, že po instalaci a aktivaci service workeru se při následném načtení libovolné stránky v jeho rozsahu v konzoli vždy objeví jedna chyba. Myslel jsem, že dělám něco špatně.

Co jsme zatím dokázali
Service worker zpracovává událost install a přednačítá některé statické prostředky. Pokud byste tento service worker použili a zaregistrovali, skutečně by přednačítal uvedená aktiva, ale ještě by je nedokázal využít offline.
Obsah serviceWorker.js je na GitHubu.
Obsluha načítání pomocí service workerů
Naše service workery zatím mají odfláknutou obsluhu install, ale nedělají nic navíc. Ke skutečnému kouzlu našeho servisního pracovníka dojde až po vyvolání událostí fetch.
Na načítání můžeme reagovat různými způsoby. Pomocí různých síťových strategií můžeme prohlížeči říci, aby se vždy pokusil načíst určité prostředky ze sítě (čímž se ujistí, že klíčový obsah je čerstvý), zatímco u statických prostředků upřednostní kopie v mezipaměti – tím skutečně zeštíhlíme užitečné zatížení našich stránek. Můžeme také poskytnout pěknou nouzovou možnost offline, pokud vše ostatní selže.
Kdykoli bude chtít prohlížeč načíst aktivum, které je v rozsahu tohoto service workeru, můžeme se o tom dozvědět, ano, přidáním eventListener do serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Znovu, každé načtení, které spadá do rozsahu tohoto service workeru (tj. cesty), vyvolá tuto událost – stránky HTML, skripty, obrázky, CSS, na co si vzpomenete. Můžeme selektivně upravit způsob, jakým prohlížeč reaguje na kterékoli z těchto načtení.
Měli bychom toto načtení zpracovat?
Při výskytu události fetch pro prostředek chci nejprve určit, zda má tento pracovník služby zasahovat do načítání daného prostředku. V opačném případě by neměl dělat nic a nechat prohlížeč, aby potvrdil své výchozí chování.
V serviceWorker.js skončíme se základní logikou takto:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});Funkce shouldHandleFetch vyhodnotí daný požadavek a určí, zda máme poskytnout odpověď, nebo nechat prohlížeč, aby potvrdil své výchozí zpracování.
Proč nepoužít sliby?“
Abych dodržel zálibu service workeru v slibech, vypadala první verze mé obsluhy události fetch takto:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Zní to logicky, ale dělal jsem několik začátečnických chyb se sliby. Přísahám, že i zpočátku jsem cítil zápach kódu, ale byl to Jake, kdo mě vyvedl z omylu. (Poučení: Jako vždy platí, že pokud kód cítíš špatně, pravděpodobně špatný je.)
Odmítnutí slibů by nemělo znamenat: „Dostal jsem odpověď, která se mi nelíbila“. Místo toho by odmítnutí mělo naznačovat: „A sakra, něco se pokazilo při pokusu o získání odpovědi“. To znamená, že odmítnutí by mělo být výjimečné.
Kritéria pro platné požadavky
Pravda, zpět k určení, zda je daný požadavek na načtení použitelný pro mého pracovníka služby. Moje kritéria pro konkrétní stránky jsou následující:
- Požadovaná adresa URL by měla představovat něco, co chci uložit do mezipaměti nebo na co chci odpovědět. Jeho cesta by měla odpovídat
Regular Expressionplatných cest. - Metoda HTTP požadavku by měla být
GET. - Požadavek by měl být na zdroj z mého původu (
lyza.com).
Pokud některý z testů criteria vyhodnotí false, neměli bychom tento požadavek zpracovat. V serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Zde uvedená kritéria jsou samozřejmě moje vlastní a na jednotlivých stránkách by se lišila. event.request je objekt Request, který obsahuje nejrůznější údaje, na které se můžete podívat, abyste posoudili, jak byste chtěli, aby se vaše obsluha načítání chovala.
Triviální poznámka: Pokud jste si všimli vpádu config, předávaného jako opts do obslužných funkcí, dobře jste si všimli. Vyřadil jsem některé opakovaně použitelné hodnoty podobné config a vytvořil objekt config v oboru nejvyšší úrovně servisního pracovníka:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Proč whitelist?
Možná vás zajímá, proč cachuji pouze věci s cestami, které odpovídají tomuto regulárnímu výrazu:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… místo toho, abych cachoval cokoli, co pochází z mého vlastního původu. Několik důvodů:
- Nechci cachovat samotného pracovníka služby.
- Když vyvíjím svůj web lokálně, některé generované požadavky se týkají věcí, které nechci cachovat. Například používám
browserSync, což v mém vývojovém prostředí vyvolá spoustu souvisejících požadavků. Tyto věci nechci ukládat do mezipaměti! Přišlo mi nepřehledné a náročné snažit se vymyslet, co všechno bych nechtěl kešovat (nemluvě o tom, že je trochu divné, že to musím rozepisovat v konfiguraci svého service workeru). Přístup založený na bílém seznamu se tedy zdál přirozenější.
Napsání obsluhy načítání
Nyní jsme připraveni předat použitelné fetch požadavky obsluze. Funkce onFetch musí určit:
- jaký druh prostředku je požadován,
- a jak mám tento požadavek splnit.
1. Jaký druh prostředku je požadován?“
Mohu se podívat na hlavičku HTTP Accept, abych získal nápovědu, jaký druh prostředku je požadován. To mi pomůže zjistit, jak s ním chci zacházet.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Abych si udržel pořádek, chci strkat různé druhy prostředků do různých mezipamětí. To mi umožní později tyto mezipaměti spravovat. Tyto klíče keší String jsou libovolné – můžete své keše nazývat, jak chcete; rozhraní API keší nemá názory.
2. Reagovat na událost Fetch
Další věc, kterou onFetch musí udělat, je respondTo událost fetch s inteligentním Response.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Pozor na asynchronizaci!“
V našem případě shouldHandleFetch nedělá nic asynchronního a ani onFetch až do bodu event.respondWith. Kdyby se předtím stalo něco asynchronního, měli bychom problém. Mezi vyvoláním události fetch a návratem řízení do prohlížeče musí být zavolána event.respondWith. Totéž platí pro event.waitUntil. V zásadě platí, že pokud zpracováváte nějakou událost, buď něco udělejte okamžitě (synchronně), nebo řekněte prohlížeči, aby vyčkal, dokud se vaše asynchronní věci nedokončí.
Obsah HTML:
Odpovídání na požadavky fetch zahrnuje implementaci vhodné síťové strategie. Podívejme se blíže na způsob, jakým odpovídáme na požadavky na obsah HTML (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}Způsob, jakým zde plníme požadavky na obsah, je strategie „network-first“. Protože obsah HTML je hlavním zájmem mého webu a často se mění, snažím se vždy získat čerstvé dokumenty HTML ze sítě.
Projdeme si to postupně.
1. Zkuste načíst ze sítě
fetch(request) .then(response => addToCache(cacheKey, request, response))Pokud je požadavek ze sítě úspěšný (tj. slib se vyřeší), pokračujte a uložte kopii dokumentu HTML do příslušné mezipaměti (content). Tomu se říká čtení z mezipaměti:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Odpovědi lze použít pouze jednou.
S objektem response, který máme, musíme udělat dvě věci:
- uložit jej do mezipaměti,
- odpovědět s ním na událost (tj. vrátit jej).
Objekty Response lze však použít pouze jednou. Jeho klonováním jsme schopni vytvořit kopii pro použití v mezipaměti:
var copy = response.clone();
Neukládejte do mezipaměti špatné odpovědi. Nedělejte stejnou chybu jako já. První verze mého kódu tuto podmínku neměla:
if (response.ok)Pěkná paráda skončit s 404 nebo jinými špatnými odpověďmi v cache! Do mezipaměti ukládejte pouze šťastné odpovědi.
2. Pokus o načtení z mezipaměti
Pokud se načtení aktiva ze sítě podaří, máme hotovo. Pokud se to však nepodaří, můžeme být offline nebo jinak ohroženi sítí. Zkuste načíst dříve uloženou kopii HTML z mezipaměti:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Tady je funkce fetchFromCache:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Poznámka: Neoznačujte, kterou mezipaměť chcete zkontrolovat pomocí caches.match; zkontrolujte je všechny najednou.
3. Zajistěte nouzové řešení offline
Pokud jsme se dostali až sem, ale v cache není nic, čím bychom mohli reagovat, vraťte pokud možno vhodné nouzové řešení offline. V případě stránek HTML je to stránka uložená v mezipaměti /offline/. Je to přiměřeně dobře naformátovaná stránka, která uživateli sdělí, že je offline a že nemůžeme splnit to, po čem touží.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))A zde je funkce offlineResponse:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}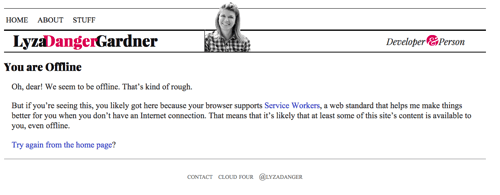
Další zdroje: Implementace strategie cache-first
Logika načítání jiných zdrojů než obsahu HTML používá strategii cache-first. Obrázky a další statický obsah na webu se mění jen zřídka; proto nejprve zkontrolujte mezipaměť a vyhněte se obcházení sítě.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Kroky zde jsou následující:
- pokusit se načíst prostředek z mezipaměti;
- pokud se to nepodaří, zkuste načíst ze sítě (s mezipamětí pro čtení);
- pokud se to nepodaří, poskytněte offline záložní prostředek, pokud je to možné.
Offline obrázek
Můžeme vrátit obrázek SVG s textem „Offline“ jako offline záložní zdroj doplněním funkce offlineResource:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}A provedeme příslušné aktualizace funkce config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};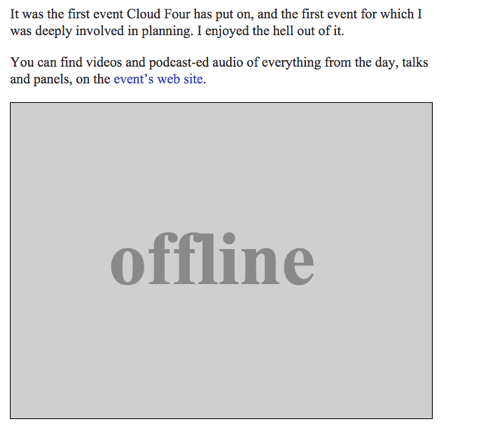
Pozor na sítě CDN
Pozor na sítě CDN, pokud omezujete zpracování načítání na svůj původ. Při konstrukci svého prvního servisního pracovníka jsem zapomněl, že můj poskytovatel hostingu rozdělil aktiva (obrázky a skripty) do své sítě CDN, takže již nebyla obsluhována z originu mého webu (lyza.com). Jejda! To nefungovalo. Nakonec jsem zakázal CDN pro dotčená aktiva (ale samozřejmě jsem tato aktiva optimalizoval!).
Dokončení první verze
První verze našeho servisního pracovníka je hotová. Máme obslužnou jednotku install a doplněnou obslužnou jednotku fetch, která může reagovat na použitelná načtení optimalizovanými odpověďmi a také poskytovat prostředky v mezipaměti a stránku offline, když je offline.
Při procházení webu budou uživatelé nadále vytvářet další položky v mezipaměti. V režimu offline budou moci pokračovat v procházení položek, které již mají uloženy v mezipaměti, nebo se jim zobrazí offline stránka (nebo obrázek), pokud požadovaný prostředek není dostupný v mezipaměti.
Úplný kód se zpracováním načítání (serviceWorker.js) je na GitHubu.
Verze a aktualizace Service Workeru
Pokud by se na našem webu už nikdy nic nezměnilo, mohli bychom říct, že máme hotovo. Servisní pracovníky je však třeba čas od času aktualizovat. Možná budu chtít přidat další cesty, které lze ukládat do mezipaměti. Možná budu chtít vyvinout způsob, jakým fungují moje offline zálohy. Možná je v mém service workeru něco mírně chybného, co chci opravit.“
Chci zdůraznit, že existují automatizované nástroje, díky kterým se správa service workerů stane součástí pracovního postupu, například Service Worker Precache od společnosti Google. Nemusíte tuto správu verzí spravovat ručně. Složitost mého webu je však natolik nízká, že pro správu změn service workeru používám lidskou strategii verzování. Ta se skládá z:
- jednoduchého řetězce verzí pro označení verzí,
- implementace obsluhy
activatepro úklid po starých verzích, - aktualizace obsluhy
installpro zrychlení aktualizovaných servisních pracovníkůactivate.
Klíče vyrovnávací paměti verzí
Mohu do svého objektu config přidat vlastnost version:
version: 'aether'To by se mělo změnit vždy, když chci nasadit aktualizovanou verzi svého servisního pracovníka. Používám jména řeckých božstev, protože jsou pro mě zajímavější než náhodné řetězce nebo čísla.
Poznámka: Provedl jsem několik změn v kódu, přidal jsem komfortní funkci (cacheName) pro generování prefixových klíčů keše. Je to styčné, takže to zde neuvádím, ale můžete si to prohlédnout v dokončeném kódu service workeru.
achilles.) (Zobrazit velkou verzi)Nepřejmenovávejte servisní pracovník
V jednu chvíli jsem si pohrával s konvencemi pojmenování názvu souboru servisního pracovníka. Nedělejte to. Pokud to uděláte, prohlížeč zaregistruje nový service worker, ale starý service worker zůstane také nainstalovaný. To je nepřehledný stav. Určitě existuje řešení, ale řekl bych, že service worker nepřejmenovávejte.
Nepoužívejte importScripts pro konfiguraci
Já jsem se vydal cestou, kdy jsem svůj objekt config umístil do externího souboru a pomocí self.importScripts() v souboru service workeru jsem tento skript natáhl. To se zdálo jako rozumný způsob, jak spravovat můj config mimo service worker, ale objevil se zádrhel.
Prohlížeč porovnává bajty souborů service worker, aby zjistil, zda byly aktualizovány – podle toho pozná, kdy má znovu spustit cyklus stahování a instalace. Změny externího config nezpůsobují žádné změny v samotném service workeru, což znamená, že změny config nezpůsobily aktualizaci service workeru. Whoops.
Přidání obsluhy aktivace
Účelem existence názvů mezipaměti specifických pro jednotlivé verze je, abychom mohli vyčistit mezipaměť z předchozích verzí. Pokud se při aktivaci objeví keše, které nemají předponu s řetězcem aktuální verze, budeme vědět, že by měly být odstraněny, protože jsou crufty.
Úklid starých keší
Můžeme použít funkci pro úklid po starých keších:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Zrychlení instalace a aktivace
Stáhne se aktualizovaný servisní pracovník, který bude install na pozadí. Nyní se jedná o čekajícího pracovníka. Ve výchozím nastavení se aktualizovaný service worker neaktivuje, dokud jsou načteny stránky, které stále používají starý service worker. Můžeme to však urychlit provedením malé změny v naší obslužné rutině install:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting způsobí, že activate proběhne okamžitě.
Nyní dokončíme obslužnou rutinu activate:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim způsobí, že se nový pracovník služby okamžitě projeví na všech otevřených stránkách v jeho rozsahu.

chrome://serviceworker-internals a zobrazit všechny pracovníky služby, které prohlížeč zaregistroval. (Zobrazit velkou verzi)
Ta-Da!
Máme nyní pracovníka služby se správou verzí! Aktualizovaný soubor serviceWorker.js se správou verzí si můžete prohlédnout na GitHubu.
Další čtení na SmashingMagu:
- Průvodce začátečníka progresivními webovými aplikacemi
- Vytvoření jednoduchého offline seznamu úkolů napříč prohlížeči
- Světový web, ne bohatý západní web
.