
>
Sobre o Autor
Lyza Danger Gardner é um dev. Desde que co-fundou a Portland, a Cloud Four em 2007, uma rede móvel baseada no Oregon, ela tem torturado e se entusiasmado com a …Mais aboutLyza↬
- 23 min read
- Codificação,JavaScript,Técnicas,Trabalhadores de Serviço
- Salvado para leitura offline
- Partilhar no Twitter, LinkedIn


Não há falta de boosterismo ou excitação sobre a API do novato prestador de serviços, agora enviando em alguns browsers populares. Existem livros de receitas e posts em blogs, trechos de código e ferramentas. Mas eu acho que quando eu quero aprender um novo conceito na web, arregaçar minhas mangas proverbiais, mergulhar e construir algo do zero é muitas vezes ideal.
Os solavancos e hematomas, gotchas e bugs que encontrei desta vez têm benefícios: Agora eu entendo muito melhor os trabalhadores de serviço, e com alguma sorte eu posso ajudá-lo a evitar algumas das dores de cabeça que encontrei ao trabalhar com a nova API.
Os trabalhadores de serviço fazem muitas coisas diferentes; há uma infinidade de maneiras de aproveitar seus poderes. Eu decidi construir um simples servidor de serviços para o meu website (estático, descomplicado) que espelha aproximadamente os recursos que a obsoleta API do Cache de Aplicações costumava fornecer – ou seja:
- tornar a função do website offline,
- aumentar a performance online reduzindo as requisições de rede para certos ativos,
- prover uma experiência personalizada offline de recuperação de falhas.
Antes de começar, gostaria de agradecer a duas pessoas cujo trabalho tornou isto possível. Primeiro, estou imensamente grato ao Jeremy Keith pela implementação de trabalhadores de serviço em seu próprio site, que serviu como ponto de partida para meu próprio código. Fiquei inspirado pelo seu recente cargo, descrevendo as suas experiências de trabalhador de serviço em curso. Na verdade, meu trabalho é tão fortemente derivado que eu não teria escrito sobre ele, exceto pela exortação de Jeremy em um post anterior:
Então, se você decidir brincar com os trabalhadores de serviço, por favor, por favor, compartilhe sua experiência.
Segundamente, todos os tipos de grandes agradecimentos ao Jake Archibald por sua excelente revisão técnica e feedback. Sempre bom quando um dos criadores e evangelistas da especificação do obreiro de serviço é capaz de colocá-lo em ordem!
O que é um obreiro de serviço?
Um obreiro de serviço é um script que fica entre seu website e a rede, dando-lhe, entre outras coisas, a capacidade de interceptar solicitações da rede e responder a elas de diferentes maneiras.
Para que seu website ou aplicativo funcione, o navegador vai buscar seus recursos – como páginas HTML, JavaScript, imagens, fontes. No passado, a gestão disto era principalmente uma prerrogativa do navegador. Se o navegador não conseguisse acessar a rede, você provavelmente veria sua mensagem “Ei, você está offline”. Havia técnicas que você poderia usar para incentivar o cache local de ativos, mas o navegador frequentemente tinha a última palavra a dizer.
Esta não foi uma experiência tão boa para usuários que estavam offline, e deixou os desenvolvedores web com pouco controle sobre o cache do navegador.
Cue Application Cache (ou AppCache), cuja chegada há vários anos parecia promissora. Ele aparentemente permite que você dite como diferentes ativos devem ser tratados, para que seu site ou aplicativo possa funcionar offline. No entanto, a sintaxe simples do AppCache desmentiu sua natureza confusa e falta de flexibilidade.
A API do novato funcionário de serviço pode fazer o que o AppCache fez, e muito mais. Mas parece um pouco assustador no início. As especificações fazem uma leitura pesada e abstrata, e numerosas APIs são subservientes a ela ou de outra forma relacionadas: cache, fetch, etc. Os trabalhadores de serviço englobam tanta funcionalidade: notificações push e, em breve, sincronização de fundo. Comparado ao AppCache, ele parece… complicado.
Whereas AppCache (que, a propósito, está indo embora) foi fácil de aprender mas terrível para cada momento depois disso (minha opinião), trabalhadores de serviço são mais um investimento cognitivo inicial, mas eles são poderosos e úteis, e você geralmente pode se livrar de problemas se você quebrar coisas.
alguns Conceitos Básicos de Trabalhadores de Serviço
Um trabalhador de serviço é um arquivo com algum JavaScript nele. Nesse arquivo você pode escrever JavaScript como você sabe e adora, com algumas coisas importantes para ter em mente.
Service worker scripts executados em uma thread separada no navegador das páginas que eles controlam. Existem formas de comunicação entre os trabalhadores e as páginas, mas eles executam em um escopo separado. Isso significa que você não terá acesso ao DOM dessas páginas, por exemplo. Eu visualizo um servidor como se estivesse rodando em uma aba separada da página que ele afeta; isso não é nada preciso, mas é uma metáfora aproximada útil para me manter longe de confusões.
JavaScript em um servidor não deve bloquear. Você precisa usar APIs assíncronas. Por exemplo, você não pode usar localStorage em um prestador de serviços (localStorage é uma API síncrona). Humorosamente, mesmo sabendo disso, eu consegui correr o risco de violá-la, como veremos.
Registar um service worker
Você faz um service worker ter efeito ao registrá-lo. Esse registro é feito de fora do prestador de serviços, por outra página ou script em seu site. No meu site, um script global site.js está incluído em cada página HTML. Eu registo o meu service worker a partir daí.
Quando você regista um service worker, você (opcionalmente) também lhe diz a que âmbito ele se deve aplicar. Você pode instruir um funcionário de serviço apenas para lidar com coisas para parte do seu website (por exemplo, '/blog/') ou você pode registrá-lo para todo o seu website ('/') como eu faço.
Ciclo de vida e eventos do funcionário de serviço
Um funcionário de serviço faz a maior parte do seu trabalho escutando eventos relevantes e respondendo a eles de maneiras úteis. Diferentes eventos são acionados em diferentes pontos do ciclo de vida de um prestador de serviços.
Após o prestador de serviços ter sido registrado e baixado, ele é instalado em segundo plano. Seu prestador de serviços pode ouvir o evento install e executar tarefas apropriadas para esta etapa.
No nosso caso, queremos aproveitar o estado install para pré-cache de um monte de ativos que sabemos que queremos disponíveis offline mais tarde.
Após a etapa install estar concluída, o prestador de serviços é então ativado. Isso significa que o funcionário de serviço está agora no controle das coisas dentro do seu scope e pode fazer a sua coisa. O evento activate não é muito empolgante para um novo prestador de serviços, mas veremos como ele é útil ao atualizar um prestador de serviços com uma nova versão.
Exatamente quando a ativação ocorre, depende se este é um novo prestador de serviços ou uma versão atualizada de um prestador de serviços pré-existente. Se o navegador não tiver uma versão anterior de um determinado funcionário de serviço já registrado, a ativação ocorrerá imediatamente após a conclusão da instalação.
Após a conclusão da instalação e ativação, elas não ocorrerão novamente até que uma versão atualizada do funcionário de serviço seja baixada e registrada.
Além da instalação e ativação, estaremos olhando principalmente para o evento fetch hoje para tornar o nosso funcionário de serviço útil. Mas há vários eventos úteis além disso: eventos de sincronização e eventos de notificação, por exemplo.
Para crédito extra ou diversão de lazer, você pode ler mais sobre as interfaces que os funcionários do serviço implementam. É implementando essas interfaces que os trabalhadores de serviços obtêm a maior parte de seus eventos e grande parte de suas funcionalidades estendidas.
A API do trabalhador de serviços Promise-Based API
A API do trabalhador de serviços faz uso pesado de Promises. Uma promessa representa o resultado final de uma operação assíncrona, mesmo que o valor real não seja conhecido até que a operação termine algum tempo no futuro.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});A função getAnAnswer… retorna um Promise que (esperamos) será eventualmente cumprido por, ou resolvido por, o answer que estamos procurando. Então, aquele answer pode ser alimentado a qualquer função de manuseamento encadeada then, ou, no caso lamentável de não conseguir atingir o seu objectivo, o Promise pode ser rejeitado – muitas vezes com uma razão – e catch as funções de manuseamento podem tratar destas situações.
Há mais promessas, mas tentarei manter os exemplos aqui em aberto (ou pelo menos comentados). Peço que você faça uma leitura informativa se você é novo em promessas.
Nota: Eu uso certos recursos do ECMAScript6 (ou ES2015) no código de exemplo para trabalhadores de serviços porque os navegadores que suportam trabalhadores de serviços também suportam esses recursos. Especificamente aqui, estou usando funções de seta e strings de modelos.
Outros Necessities dos trabalhadores de serviços
Além disso, note que os trabalhadores de serviços requerem HTTPS para funcionar. Há uma exceção importante e útil a esta regra: Trabalhadores de serviços trabalham para localhost em insegurança http, o que é um alívio porque configurar SSL local é às vezes um slog.
Fun fact: Este projeto me forçou a fazer algo que eu estava adiando por um tempo: obter e configurar SSL para o subdomínio www do meu site. Isto é algo que eu peço às pessoas que considerem fazer, porque praticamente todas as coisas novas e divertidas que irão bater no navegador no futuro irão requerer o uso do SSL.
Todas as coisas que iremos montar hoje funcionam no Chrome (eu uso a versão 47). A qualquer dia agora, o Firefox 44 será enviado, e suporta trabalhadores de serviço. O Service Worker Ready? fornece informações granulares sobre suporte em diferentes navegadores.
Registar, Instalar e Ativar um Service Worker
Agora que já cuidamos de alguma teoria, podemos começar a montar o nosso service worker.
Para instalar e ativar nosso prestador de serviços, queremos ouvir install e activate eventos e agir sobre eles.
Podemos começar com um arquivo vazio para nosso prestador de serviços e adicionar um par de eventListeners. Em serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Registar o nosso prestador de serviços
Agora precisamos dizer às páginas do nosso site para usar o prestador de serviços.
Lembrar, esse registro acontece de fora do prestador de serviços – no meu caso, de dentro de um script (/js/site.js) que está incluído em todas as páginas do meu site.
Na minha site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Pré-Caching Static Assets During Install
Desejo usar a fase de instalação para pré-cache de alguns assets no meu website.
- Pré-cache de alguns ativos estáticos (imagens, CSS, JavaScript) que são usados por muitas páginas do meu site, eu posso acelerar o tempo de carregamento pegando esses ativos fora do cache, ao invés de buscar na rede em carregamentos de páginas subseqüentes.
- Pré-cache de uma página fallback offline, eu posso mostrar uma página legal quando eu não consigo atender a um pedido de página porque o usuário está offline.
Os passos para fazer isso são:
- Diga o evento
installpara esperar e não completar até que eu tenha feito o que eu preciso fazer usandoevent.waitUntil. - Abrir o apropriado
cache, e colar os ativos estáticos nele usandoCache.addAll. Em linguagem progressiva de aplicação web, esses recursos compõem a minha “shell de aplicação”
Em /serviceWorker.js, vamos expandir o install handler:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});O trabalhador de serviço implementa a interface CacheStorage, o que torna a propriedade caches disponível globalmente no nosso trabalhador de serviço. Existem vários métodos úteis em caches – por exemplo, open e delete.
Você pode ver Promises a trabalhar aqui: caches.open retorna um Promise resolvendo para um objecto cache uma vez que tenha aberto com sucesso a static cache; addAll também retorna um Promise que resolve quando todos os itens passados para ele tiverem sido guardados na cache.
Eu digo ao event para esperar até que o Promise devolvido pela função do meu manipulador seja resolvido com sucesso. Então podemos ter a certeza que todos esses itens pré-cache são classificados antes da instalação estar completa.
Console Confusions
Stale Logging
Possivelmente não é um bug, mas certamente uma confusão: Se você console.log dos funcionários do serviço, o Chrome continuará a exibir novamente (ao invés de limpar) as mensagens de log nas solicitações de página subsequentes. Isto pode fazer parecer que os eventos estão a disparar demasiadas vezes ou que o código está a ser executado vezes sem conta.
Por exemplo, vamos adicionar uma declaração log ao nosso install handler:
self.addEventListener('install', event => { // … as before console.log('installing');});
install em cada carregamento de página. Ao invés disso, ele está mostrando logs obsoletos. (Ver versão grande)Um erro quando as coisas estão OK
Outra coisa estranha é que uma vez que um funcionário de serviço é instalado e ativado, carregamentos subsequentes de página para qualquer página dentro de seu escopo sempre causarão um único erro no console. Eu pensei que estava fazendo algo errado.

O que realizamos até agora
O funcionário de serviço lida com o evento install e pré-cache alguns ativos estáticos. Se você usasse esse prestador de serviços e o registrasse, ele realmente pré-cache os recursos indicados, mas ainda não seria capaz de aproveitá-los offline.
O conteúdo de serviceWorker.js está no GitHub.
Lidar com os prestadores de serviços
Até agora, nosso prestador de serviços tem um prestador de serviços install mas não faz nada além disso. A magia do nosso prestador de serviços vai realmente acontecer quando fetch eventos forem acionados.
Podemos responder a buscas de diferentes maneiras. Ao usar diferentes estratégias de rede, podemos dizer ao navegador para sempre tentar pegar certos ativos da rede (certificando-se de que o conteúdo chave esteja fresco), enquanto favorecemos cópias em cache para ativos estáticos – realmente emagrecendo a carga útil da nossa página. Nós também podemos fornecer um bom fallback offline se tudo mais falhar.
Quando um browser quer ir buscar um activo que está dentro do escopo deste funcionário de serviço, nós podemos ouvir sobre isso, sim, adicionando um eventListener em serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});Again, cada fetch que se enquadra dentro do escopo deste funcionário de serviço (i.e. caminho) irá desencadear este evento – páginas HTML, scripts, imagens, CSS, o que você quiser. Podemos tratar selectivamente da forma como o browser responde a qualquer um destes fetch.
Devíamos tratar deste fetch?
Quando um evento fetch ocorre para um ativo, a primeira coisa que quero determinar é se esse prestador de serviços deve interferir com a busca do recurso em questão. Caso contrário, ele não deve fazer nada e deixar o navegador afirmar seu comportamento padrão.
Lógica básica como esta em serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});A função shouldHandleFetch avalia uma determinada requisição para determinar se devemos fornecer uma resposta ou deixar o navegador afirmar seu comportamento padrão.
Por que não usar promessas?
Para manter a predileção dos trabalhadores de serviço pelas promessas, a primeira versão do meu fetch manipulador de eventos parecia assim:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Parece lógico, mas eu estava cometendo um par de erros de novato com promessas. Eu juro que senti um cheiro de código mesmo inicialmente, mas foi o Jake que me esclareceu sobre os erros dos meus caminhos. (Lição: Como sempre, se o código parece errado, provavelmente é.)
Rejeições de promessa não devem ser usadas para indicar, “Eu recebi uma resposta que não gostei”. Em vez disso, as rejeições devem indicar: “Ah, merda, alguma coisa correu mal ao tentar obter a resposta”. Ou seja, as rejeições devem ser excepcionais.
Critérios para Pedidos Válidos
Direito, de volta para determinar se um determinado pedido de fetch é aplicável ao meu prestador de serviços. Os critérios específicos do meu site são os seguintes:
- A URL solicitada deve representar algo que eu quero guardar ou responder. Seu caminho deve corresponder a um
Regular Expressionde caminhos válidos. - O método HTTP da requisição deve ser
GET. - A requisição deve ser para um recurso da minha origem (
lyza.com).
Se algum dos testes criteria avaliar para false, nós não devemos lidar com esta requisição. Em serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Obviamente, os critérios aqui são os meus próprios e variariam de site para site. event.request é um objecto Request que tem todo o tipo de dados que pode ver para avaliar como gostaria que o seu manipulador de fetch se comportasse.
Nota trivial: Se reparou na incursão de config, passou como opts para as funções do manipulador, bem manchadas. Eu fatorei alguns valores reutilizáveis configcomo valores e criei um objeto config no escopo de nível superior do prestador de serviços:
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Por que Whitelist?
Você pode estar se perguntando porque eu estou apenas caching coisas com caminhos que combinam com esta expressão regular:
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… em vez de caching qualquer coisa vinda da minha própria origem. Um par de razões:
- Não quero fazer cache do próprio funcionário do serviço.
- Quando estou desenvolvendo meu site localmente, alguns pedidos gerados são para coisas que eu não quero fazer cache. Por exemplo, eu uso
browserSync, o que dá início a um monte de requisições relacionadas no meu ambiente de desenvolvimento. Eu não quero fazer cache dessas coisas! Parecia confuso e desafiador tentar pensar em tudo que eu não gostaria de fazer cache (para não mencionar, um pouco estranho ter que soletrar na configuração do meu servidor de serviço). Então, uma abordagem de lista branca pareceu mais natural.
Escrever o Fetch Handler
Agora estamos prontos para passar os pedidos aplicáveis fetch para um handler. A função onFetch precisa determinar:
- que tipo de recurso está sendo solicitado,
- e como devo atender a este pedido.
1. Que tipo de recurso está sendo requisitado,
Eu posso olhar o cabeçalho HTTP Accept para obter uma dica sobre que tipo de recurso está sendo requisitado. Isso me ajuda a descobrir como eu quero lidar com isso.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Para me manter organizado, eu quero colar diferentes tipos de recursos em diferentes caches. Isto permitir-me-á gerir esses caches mais tarde. Estas chaves de cache Strings são arbitrárias – você pode chamar as suas caches como quiser; a API da cache não tem opiniões.
2. Responda ao Fetch
A próxima coisa para onFetch fazer é respondTo o evento fetch com um inteligente Response.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Cuidado com Async!
No nosso caso, shouldHandleFetch não faz nada assíncrono, e nem onFetch até ao ponto de event.respondWith. Se algo assíncrono tivesse acontecido antes disso, estaríamos em apuros. event.respondWith deve ser chamado entre o fetch disparo de evento e controle retornando ao navegador. O mesmo vale para event.waitUntil. Basicamente, se você estiver manipulando um evento, ou faça algo imediatamente (de forma síncrona) ou diga ao navegador para aguentar até que o seu material assíncrono seja feito.
HTML Content: Implementar uma estratégia de rede
Responder a fetch pedidos envolve a implementação de uma estratégia de rede apropriada. Vamos olhar mais de perto a forma como estamos respondendo às solicitações de conteúdo HTML (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}A forma como atendemos às solicitações de conteúdo aqui é uma estratégia de Network-First. Como o conteúdo HTML é a principal preocupação do meu site e ele muda frequentemente, eu sempre tento obter novos documentos HTML da rede.
Passemos por aqui.
1. Tente obter da rede
fetch(request) .then(response => addToCache(cacheKey, request, response))Se a solicitação da rede for bem sucedida (ou seja, a promessa resolve), vá em frente e guarde uma cópia do documento HTML no cache apropriado (content). Isto é chamado de cache de leitura:
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Responses podem ser usados apenas uma vez.
Precisamos fazer duas coisas com o response temos:
- cache,
- responder ao evento com ele (ou seja, devolvê-lo).
Mas Response objetos podem ser usados apenas uma vez. Ao cloná-lo, somos capazes de criar uma cópia para uso do cache:
var copy = response.clone();
Não faça o cache com respostas ruins. Não cometa o mesmo erro que eu cometi. A primeira versão do meu código não tinha este condicional:
if (response.ok)Pretty awesome para acabar com 404 ou outras respostas ruins no cache! Apenas respostas felizes na cache.
2. Tente recuperar da cache
Se a recuperação do activo da rede for bem sucedida, estamos feitos. Entretanto, se não conseguir, podemos estar offline ou de outra forma comprometidos com a rede. Tente recuperar uma cópia previamente em cache do HTML:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Aqui está a função fetchFromCache:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Nota: Não indique com que cache você deseja verificar com caches.match; verifique todos de uma só vez.
3. Forneça um Fallback Offline
Se chegamos até aqui mas não há nada na cache com que possamos responder, devolva um fallback offline apropriado, se possível. Para páginas HTML, esta é a página armazenada em cache a partir de /offline/. É uma página razoavelmente bem formatada que diz ao utilizador que estão offline e que não podemos preencher o que eles querem.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))E aqui está a função offlineResponse:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}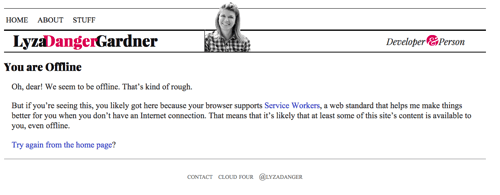
Outros Recursos: Implementing A Cache-First Strategy
The fetch logic for resources other than HTML content uses a cache-first strategy. Imagens e outros conteúdos estáticos no site raramente mudam; então, verifique o cache primeiro e evite a ida e volta da rede.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Os passos aqui são:
- try para recuperar o recurso do cache;
- se isso falhar, tente recuperar da rede (com cache de leitura);
- se isso falhar, forneça um recurso offline de fallback, se possível.
Offline Image
Podemos retornar uma imagem SVG com o texto “Offline” como um fallback offline completando a função offlineResource:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}E vamos fazer as atualizações relevantes para config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};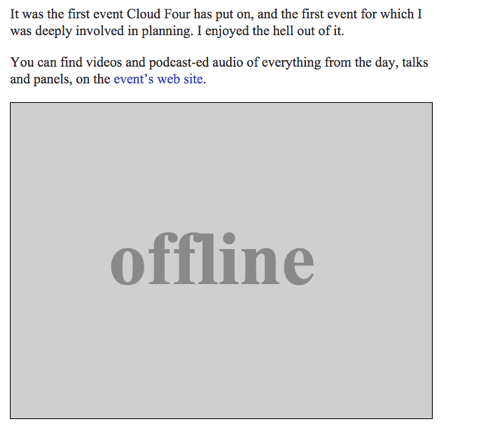
Watch Out para CDNs
Watch Out para CDNs se você estiver restringindo o manuseio de fetch à sua origem. Quando construí o meu primeiro serviço, esqueci-me que o meu fornecedor de alojamento tinha deitado bens (imagens e scripts) no seu CDN, para que não fossem mais servidos a partir da origem do meu site (lyza.com). Whoops! Isso não funcionou. Acabei desabilitando o CDN para os ativos afetados (mas otimizando esses ativos, claro!).
Completando a primeira versão
A primeira versão do nosso prestador de serviços agora está pronta. Temos um handler install e um fleshed-out fetch handler que pode responder aos fetches aplicáveis com respostas otimizadas, bem como fornecer recursos em cache e uma página offline quando offline.
Quando os usuários navegarem no site, eles continuarão a construir mais itens em cache. Quando offline, eles poderão continuar a navegar pelos itens que já têm em cache, ou verão uma página offline (ou imagem) se o recurso solicitado não estiver disponível em cache.
O código completo com o manuseio do fetch (serviceWorker.js) está no GitHub.
Versão e Atualização do Assistente de Serviço
Se nada fosse mudar no nosso site novamente, poderíamos dizer que terminamos. No entanto, os trabalhadores de serviço precisam ser atualizados de tempos em tempos. Talvez eu queira adicionar mais caminhos com cache. Talvez eu queira evoluir a forma como os meus fallbacks offline funcionam. Talvez haja algo ligeiramente buggy no meu operário de serviço que eu queira corrigir.
Eu quero enfatizar que existem ferramentas automatizadas para tornar o gerenciamento do operário de serviço parte do seu fluxo de trabalho, como o Service Worker Precache do Google. Você não precisa gerenciar a versão à mão. No entanto, a complexidade do meu site é suficientemente baixa para que eu use uma estratégia de gerenciamento de versões humanas para gerenciar as mudanças para o meu técnico de serviços. Isso consiste em:
- uma seqüência de versões simples para indicar versões,
- implementação de um manipulador para limpar após versões antigas,
- atualização do manipulador
installpara tornar os trabalhadores de serviços atualizadosactivatemais rápido.
Chaves de Cache de Versão
Posso adicionar uma propriedade version ao meu config objeto:
version: 'aether'Isso deve mudar a qualquer momento que eu quiser implantar uma versão atualizada do meu prestador de serviços. Eu uso os nomes de deidades gregas porque eles são mais interessantes para mim do que strings ou números aleatórios.
Note: Eu fiz algumas alterações no código, adicionando uma função de conveniência (cacheName) para gerar chaves de cache prefixadas. É tangencial, por isso não a estou a incluir aqui, mas pode vê-la no código completo do funcionário do serviço.
achilles.) (Ver versão grande)Não renomeie o nome do seu funcionário de serviço
A dada altura, eu estava a fazer uma pesquisa sobre convenções de nomes para o nome do ficheiro do funcionário de serviço. Não faça isso. Se você fizer isso, o navegador registrará o novo funcionário de serviço, mas o antigo funcionário de serviço também ficará instalado. Isto é uma situação complicada. Tenho certeza que há uma solução, mas eu diria para não renomear o seu service worker.
Não use importScripts para config
Fui por um caminho de colocar meu objeto config em um arquivo externo e usar self.importScripts() no arquivo do service worker para puxar esse script para dentro. Isso pareceu uma maneira razoável de gerenciar meu config fora do service worker, mas houve um problema.
O browser byte-compare os arquivos do service worker para determinar se eles foram atualizados – é assim que ele sabe quando acionar novamente um ciclo de download e instalação. Alterações no externo config não causam quaisquer alterações ao service worker em si, o que significa que as alterações no config não estavam a causar a actualização do service worker. Whoops.
Adicionando um manipulador de ativação
O propósito de ter nomes de cache específicos de versões é para que possamos limpar os caches das versões anteriores. Se houver caches durante a ativação que não estejam prefixados com a string da versão atual, saberemos que eles devem ser excluídos porque são crufty.
Limpar Caches Antigos
Podemos usar uma função para limpar depois de caches antigos:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Velocidade Instalar e Ativar
Um funcionário de serviço atualizado será baixado e irá install em segundo plano. Agora é um operário em espera. Por padrão, o trabalhador de serviço atualizado não será ativado enquanto qualquer página que ainda esteja usando o antigo trabalhador de serviço estiver sendo carregada. No entanto, podemos acelerar isso fazendo uma pequena alteração no nosso install handler:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting fará com que activate aconteça imediatamente.
Agora, termine o activate handler:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim fará com que o novo prestador de serviços tenha efeito imediato em qualquer página aberta em seu escopo.

chrome://serviceworker-internals no Chrome para ver todos os prestadores de serviços que o navegador tenha registrado. (Ver versão grande)
Ta-Da!
Agora temos um funcionário de serviço gerido por versão! Você pode ver o arquivo atualizado serviceWorker.js com gerenciamento de versão no GitHub.
Leitura adicional no SmashingMag:
- Um Guia para Iniciantes em Aplicações Web Progressivas
- Construindo um simples Cross-Browser Offline To-Do List
- World Wide Web, Not Wealthy Western Web