
À propos de l’auteur
Lyza Danger Gardner est une dev. Depuis qu’elle a cofondé Cloud Four, une startup de Portland (Oregon) spécialisée dans le web mobile, en 2007, elle s’est torturée et a …En savoir plus surLyza↬
- 23 min de lecture
- Codage,JavaScript,Techniques,Service Workers
- Enregistré pour une lecture hors ligne
- Partager sur Twitter, LinkedIn


Il n’y a pas de pénurie de boosterisme ou d’excitation au sujet de l’API de travailleur de service naissante, maintenant expédiée dans certains navigateurs populaires. Il y a des livres de recettes et des articles de blog, des bouts de code et des outils. Mais je trouve que lorsque je veux apprendre un nouveau concept web en profondeur, retrousser mes manches proverbiales, plonger et construire quelque chose à partir de zéro est souvent idéal.
Les bosses et les bleus, les gotchas et les bugs que j’ai rencontrés cette fois ont des avantages : Maintenant, je comprends beaucoup mieux les travailleurs de service, et avec un peu de chance, je peux vous aider à éviter certains des maux de tête que j’ai rencontrés en travaillant avec la nouvelle API.
Les travailleurs de service font beaucoup de choses différentes ; il existe une myriade de façons d’exploiter leurs pouvoirs. J’ai décidé de construire un travailleur de service simple pour mon site Web (statique, non compliqué) qui reflète grossièrement les fonctionnalités que l’API obsolète Application Cache fournissait – à savoir :
- faire fonctionner le site Web hors ligne,
- augmenter les performances en ligne en réduisant les demandes de réseau pour certains actifs,
- fournir une expérience de repli hors ligne personnalisée.
Avant de commencer, je voudrais remercier deux personnes dont le travail a rendu cela possible. Tout d’abord, je suis extrêmement redevable à Jeremy Keith pour la mise en œuvre des travailleurs de service sur son propre site Web, qui a servi de point de départ pour mon propre code. J’ai été inspiré par son récent billet décrivant ses expériences en cours sur les travailleurs de service. En fait, mon travail est si fortement dérivé que je n’aurais pas écrit à ce sujet si ce n’est pour l’exhortation de Jeremy dans un post précédent :
Donc si vous décidez de jouer avec les travailleurs de service, s’il vous plaît, s’il vous plaît, partagez votre expérience.
Deuxièmement, toutes sortes de grands vieux remerciements à Jake Archibald pour son excellente revue technique et ses commentaires. C’est toujours agréable quand l’un des créateurs et des évangélistes de la spécification du travailleur de service est capable de vous remettre à l’endroit !
Qu’est-ce qu’un travailleur de service ?
Un travailleur de service est un script qui se tient entre votre site Web et le réseau, vous donnant, entre autres, la possibilité d’intercepter les requêtes du réseau et d’y répondre de différentes manières.
Pour que votre site Web ou votre application fonctionne, le navigateur va chercher ses actifs – tels que les pages HTML, JavaScript, les images, les polices. Par le passé, la gestion de ces éléments était principalement l’apanage du navigateur. Si le navigateur ne pouvait pas accéder au réseau, vous verriez probablement son message « Hey, you’re offline ». Il y avait des techniques que vous pouviez utiliser pour encourager la mise en cache locale des actifs, mais le navigateur avait souvent le dernier mot.
Ce n’était pas une si bonne expérience pour les utilisateurs qui étaient hors ligne, et cela laissait les développeurs web avec peu de contrôle sur la mise en cache du navigateur.
Cue Application Cache (ou AppCache), dont l’arrivée il y a plusieurs années semblait prometteuse. Il vous permettait ostensiblement de dicter la façon dont les différents actifs devaient être traités, afin que votre site Web ou votre application puisse fonctionner hors ligne. Pourtant, la syntaxe d’apparence simple d’AppCache démentait sa nature déroutante sous-jacente et son manque de flexibilité.
L’API de travailleur de service naissante peut faire ce qu’AppCache faisait, et bien plus encore. Mais elle semble un peu intimidante au début. Les spécifications font une lecture lourde et abstraite, et de nombreuses API lui sont subordonnées ou autrement liées : cache, fetch, etc. Les travailleurs de service englobent tant de fonctionnalités : les notifications push et, bientôt, la synchronisation en arrière-plan. Comparé à AppCache, cela semble… compliqué.
Alors qu’AppCache (qui, soit dit en passant, disparaît) était facile à apprendre mais terrible pour chaque moment après cela (mon avis), les travailleurs de service sont plus un investissement cognitif initial, mais ils sont puissants et utiles, et vous pouvez généralement vous sortir des problèmes si vous cassez des choses.
Quelques concepts de base sur les travailleurs de service
Un travailleur de service est un fichier avec un peu de JavaScript dedans. Dans ce fichier, vous pouvez écrire du JavaScript comme vous le connaissez et l’aimez, avec quelques choses importantes à garder à l’esprit.
Les scripts de travailleurs de service s’exécutent dans un thread séparé dans le navigateur des pages qu’ils contrôlent. Il existe des moyens de communiquer entre les travailleurs et les pages, mais ils s’exécutent dans une portée séparée. Cela signifie que vous n’aurez pas accès au DOM de ces pages, par exemple. Je visualise un travailleur de service comme une sorte d’exécution dans un onglet séparé de la page qu’il affecte ; ce n’est pas du tout exact, mais c’est une métaphore grossière utile pour me garder hors de la confusion.
JavaScript dans un travailleur de service ne doit pas bloquer. Vous devez utiliser des API asynchrones. Par exemple, vous ne pouvez pas utiliser localStorage dans un travailleur de service (localStorage est une API synchrone). De façon assez humoristique, même en sachant cela, j’ai réussi à courir le risque de le violer, comme nous allons le voir.
Enregistrer un Service Worker
Vous faites prendre effet à un Service Worker en l’enregistrant. Cet enregistrement se fait depuis l’extérieur du service worker, par une autre page ou un script de votre site web. Sur mon site web, un script global site.js est inclus sur chaque page HTML. J’enregistre mon travailleur de service à partir de là.
Lorsque vous enregistrez un travailleur de service, vous lui indiquez (facultativement) également à quelle portée il doit s’appliquer. Vous pouvez instruire un travailleur de service seulement pour gérer des choses pour une partie de votre site Web (par exemple, '/blog/') ou vous pouvez l’enregistrer pour tout votre site Web ('/') comme je le fais.
Cycle de vie du travailleur de service et événements
Un travailleur de service fait la majeure partie de son travail en écoutant les événements pertinents et en y répondant de manière utile. Différents événements sont déclenchés à différents moments du cycle de vie d’un travailleur de service.
Une fois que le travailleur de service a été enregistré et téléchargé, il est installé en arrière-plan. Votre travailleur de service peut écouter l’événement install et effectuer les tâches appropriées pour cette étape.
Dans notre cas, nous voulons profiter de l’état install pour pré-cacher un tas d’actifs que nous savons que nous voudrons disponibles hors ligne plus tard.
Après que l’étape install soit terminée, le travailleur de service est alors activé. Cela signifie que le travailleur de service est maintenant en contrôle des choses dans son scope et peut faire son truc. L’événement activate n’est pas trop excitant pour un nouveau travailleur de service, mais nous verrons comment il est utile lors de la mise à jour d’un travailleur de service avec une nouvelle version.
Le moment exact de l’activation dépend du fait qu’il s’agisse d’un tout nouveau travailleur de service ou d’une version mise à jour d’un travailleur de service préexistant. Si le navigateur n’a pas de version précédente d’un travailleur de service donné déjà enregistrée, l’activation se produira immédiatement après la fin de l’installation.
Une fois l’installation et l’activation terminées, elles ne se produiront plus jusqu’à ce qu’une version mise à jour du travailleur de service soit téléchargée et enregistrée.
A part l’installation et l’activation, nous regarderons principalement l’événement fetch aujourd’hui pour rendre notre travailleur de service utile. Mais il y a plusieurs événements utiles au-delà de cela : les événements de synchronisation et les événements de notification, par exemple.
Pour un crédit supplémentaire ou un plaisir de loisir, vous pouvez lire plus sur les interfaces que les travailleurs de service mettent en œuvre. C’est en implémentant ces interfaces que les travailleurs de service obtiennent la majeure partie de leurs événements et une grande partie de leurs fonctionnalités étendues.
L’API basée sur les promesses du travailleur de service
L’API du travailleur de service fait un usage intensif de Promises. Une promesse représente le résultat éventuel d’une opération asynchrone, même si la valeur réelle ne sera pas connue avant que l’opération ne se termine quelque temps dans le futur.
getAnAnswerToADifficultQuestionSomewhereFarAway() .then(answer => { console.log('I got the ${answer}!'); }) .catch(reason => { console.log('I tried to figure it out but couldn't because ${reason}');});La fonction getAnAnswer… renvoie une Promise qui (nous l’espérons) sera finalement remplie par, ou résolue en, la answer que nous recherchons. Ensuite, ce answer peut être alimenté à n’importe quelle chaîne de fonctions de traitement then, ou, dans le cas désolé de l’échec de son objectif, le Promise peut être rejeté – souvent avec une raison – et les fonctions de traitement catch peuvent prendre en charge ces situations.
Il y a plus de promesses, mais je vais essayer de garder les exemples ici simples (ou au moins commentés). Je vous invite à faire quelques lectures informatives si vous êtes nouveau dans les promesses.
Note : J’utilise certaines fonctionnalités ECMAScript6 (ou ES2015) dans le code d’exemple pour les travailleurs de service parce que les navigateurs qui prennent en charge les travailleurs de service prennent également en charge ces fonctionnalités. Plus précisément ici, j’utilise des fonctions de flèche et des chaînes de modèle.
Autres nécessités des travailleurs de services
Notez également que les travailleurs de services nécessitent HTTPS pour fonctionner. Il existe une exception importante et utile à cette règle : Les travailleurs de service fonctionnent pour localhost sur http non sécurisé, ce qui est un soulagement parce que la mise en place de SSL local est parfois un slog.
Fun fact : Ce projet m’a forcé à faire quelque chose que j’avais mis de côté pendant un certain temps : obtenir et configurer SSL pour le sous-domaine www de mon site Web. C’est quelque chose que j’exhorte les gens à envisager de faire parce que presque toutes les nouvelles choses amusantes qui frappent le navigateur à l’avenir nécessiteront l’utilisation de SSL.
Toutes les choses que nous allons mettre ensemble fonctionnent aujourd’hui dans Chrome (j’utilise la version 47). D’un jour à l’autre, Firefox 44 sera expédié, et il prend en charge les travailleurs de service. Is Service Worker Ready ? fournit des informations granulaires sur le support dans les différents navigateurs.
Registering, Installing And Activating A Service Worker
Maintenant que nous avons pris soin de la théorie, nous pouvons commencer à mettre en place notre service worker.
Pour installer et activer notre travailleur de service, nous voulons écouter les événements install et activate et agir sur eux.
Nous pouvons commencer avec un fichier vide pour notre travailleur de service et ajouter un couple de eventListeners. Dans serviceWorker.js:
self.addEventListener('install', event => { // Do install stuff});self.addEventListener('activate', event => { // Do activate stuff: This will come later on.});Enregistrement de notre travailleur de service
Maintenant, nous devons dire aux pages de notre site Web d’utiliser le travailleur de service.
Rappellez-vous, cet enregistrement se produit à l’extérieur du travailleur de service – dans mon cas, à l’intérieur d’un script (/js/site.js) qui est inclus sur chaque page de mon site Web.
Dans mon site.js:
if ('serviceWorker' in navigator) { navigator.serviceWorker.register('/serviceWorker.js', { scope: '/' });}Mise en cache préalable des actifs statiques pendant l’installation
Je veux utiliser l’étape d’installation pour mettre en cache préalable certains actifs sur mon site web.
- En pré-cachant certains actifs statiques (images, CSS, JavaScript) qui sont utilisés par de nombreuses pages de mon site Web, je peux accélérer les temps de chargement en les récupérant dans le cache, au lieu de les récupérer sur le réseau lors des chargements de pages ultérieurs.
- En pré-cachant une page de repli hors ligne, je peux afficher une belle page lorsque je ne peux pas répondre à une demande de page parce que l’utilisateur est hors ligne.
Les étapes pour faire cela sont :
- Dire à l’événement
installde s’accrocher et de ne pas terminer jusqu’à ce que j’aie fait ce que je dois faire en utilisantevent.waitUntil. - Ouvrir le
cacheapproprié, et y coller les actifs statiques en utilisantCache.addAll. En langage d’application web progressive, ces actifs constituent mon « shell d’application ».
Dans /serviceWorker.js, développons le gestionnaire install:
self.addEventListener('install', event => { function onInstall () { return caches.open('static') .then(cache => cache.addAll() ); } event.waitUntil(onInstall(event));});Le travailleur de service implémente l’interface CacheStorage, ce qui rend la propriété caches disponible globalement dans notre travailleur de service. Il y a plusieurs méthodes utiles sur caches – par exemple, open et delete.
Vous pouvez voir Promises au travail ici : caches.open renvoie un Promise se résolvant à un objet cache une fois qu’il a ouvert avec succès le cache static ; addAll renvoie également un Promise qui se résout lorsque tous les éléments qui lui sont passés ont été rangés dans le cache.
Je dis au event d’attendre jusqu’à ce que le Promise renvoyé par ma fonction handler soit résolu avec succès. Ensuite, nous pouvons être sûrs que tous ces éléments de pré-cache sont triés avant que l’installation ne soit terminée.
Confusions de console
Journalage stale
Possiblement pas un bogue, mais certainement une confusion : Si vous console.log des travailleurs de service, Chrome continuera à réafficher (plutôt que d’effacer) ces messages de journal sur les demandes de page suivantes. Cela peut donner l’impression que les événements se déclenchent trop souvent ou que le code s’exécute encore et encore.
Par exemple, ajoutons une déclaration log à notre gestionnaire install:
self.addEventListener('install', event => { // … as before console.log('installing');});
install à chaque chargement de page. Au lieu de cela, il affiche des journaux périmés. (Voir la grande version)Une erreur quand tout va bien
Une autre chose étrange est qu’une fois qu’un travailleur de service est installé et activé, les chargements de page ultérieurs pour toute page dans sa portée provoquent toujours une seule erreur dans la console. Je pensais que je faisais quelque chose de mal.

Ce que nous avons accompli jusqu’à présent
Le travailleur de service gère l’événement install et pré-cache certains actifs statiques. Si vous deviez utiliser ce travailleur de service et l’enregistrer, il pré-cacherait en effet les actifs indiqués mais ne serait pas encore capable d’en tirer parti hors ligne.
Le contenu de serviceWorker.js est sur GitHub.
Gestion de la récupération avec les travailleurs de service
Jusqu’ici, notre travailleur de service a un gestionnaire install étoffé mais ne fait rien au-delà. La magie de notre travailleur de service va vraiment se produire lorsque les événements fetch sont déclenchés.
Nous pouvons répondre aux fetches de différentes manières. En utilisant différentes stratégies de réseau, nous pouvons dire au navigateur de toujours essayer de récupérer certains actifs depuis le réseau (en s’assurant que le contenu clé est frais), tout en favorisant les copies en cache pour les actifs statiques – en réduisant vraiment la charge utile de nos pages. Nous pouvons également fournir une belle solution de repli hors ligne si tout le reste échoue.
Quand un navigateur veut récupérer un actif qui est dans la portée de ce travailleur de service, nous pouvons en être informés par, ouais, l’ajout d’un eventListener dans serviceWorker.js:
self.addEventListener('fetch', event => { // … Perhaps respond to this fetch in a useful way?});De nouveau, chaque récupération qui tombe dans la portée de ce travailleur de service (c’est-à-dire le chemin) déclenchera cet événement – pages HTML, scripts, images, CSS, vous le nommez. Nous pouvons gérer de manière sélective la façon dont le navigateur répond à l’une de ces récupérations.
Devons-nous gérer cette récupération ?
Lorsqu’un événement fetch se produit pour un actif, la première chose que je veux déterminer est si ce travailleur de service doit interférer avec la récupération de la ressource donnée. Sinon, il devrait ne rien faire et laisser le navigateur affirmer son comportement par défaut.
Nous nous retrouverons avec une logique de base comme celle-ci dans serviceWorker.js:
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { // Should we handle this fetch? } function onFetch (event, opts) { // … TBD: Respond to the fetch } if (shouldHandleFetch(event, config)) { onFetch(event, config); }});La fonction shouldHandleFetch évalue une requête donnée pour déterminer si nous devons fournir une réponse ou laisser le navigateur affirmer son traitement par défaut.
Pourquoi ne pas utiliser les promesses ?
Pour rester dans la prédilection du service worker pour les promesses, la première version de mon gestionnaire d’événements fetch ressemblait à ceci :
self.addEventListener('fetch', event => { function shouldHandleFetch (event, opts) { } function onFetch (event, opts) { } shouldHandleFetch(event, config) .then(onFetch(event, config)) .catch(…);});Cela semble logique, mais je faisais quelques erreurs de débutant avec les promesses. Je jure que j’ai senti une odeur de code même au début, mais c’est Jake qui m’a remis à l’ordre sur les erreurs de mes manières. (Leçon : comme toujours, si le code sent mauvais, c’est probablement le cas.)
Les rejets de promesses ne devraient pas être utilisés pour indiquer, « J’ai obtenu une réponse que je n’ai pas aimée. » Au lieu de cela, les rejets devraient indiquer, « Ah, merde, quelque chose a mal tourné en essayant d’obtenir la réponse. » C’est-à-dire que les rejets devraient être exceptionnels.
Critères pour les demandes valides
D’accord, revenons à déterminer si une demande de récupération donnée est applicable pour mon travailleur de service. Mes critères spécifiques au site sont les suivants :
- L’URL demandée doit représenter quelque chose que je veux mettre en cache ou auquel je veux répondre. Son chemin doit correspondre à un
Regular Expressionde chemins valides. - La méthode HTTP de la requête doit être
GET. - La requête doit concerner une ressource de mon origine (
lyza.com).
Si l’un des tests criteria évalue à false, nous ne devons pas traiter cette requête. Dans serviceWorker.js:
function shouldHandleFetch (event, opts) { var request = event.request; var url = new URL(request.url); var criteria = { matchesPathPattern: !!(opts.cachePathPattern.exec(url.pathname), isGETRequest : request.method === 'GET', isFromMyOrigin : url.origin === self.location.origin }; // Create a new array with just the keys from criteria that have // failing (i.e. false) values. var failingCriteria = Object.keys(criteria) .filter(criteriaKey => !criteria); // If that failing array has any length, one or more tests failed. return !failingCriteria.length;}Bien sûr, les critères ici sont les miens et varieraient d’un site à l’autre. event.request est un objet Request qui a toutes sortes de données que vous pouvez regarder pour évaluer comment vous aimeriez que votre gestionnaire de récupération se comporte.
Note triviale : Si vous avez remarqué l’incursion de config, passé comme opts aux fonctions de gestionnaire, bien repéré. J’ai pris en compte certaines valeurs réutilisables de type config et créé un objet config dans la portée de haut niveau du travailleur de service :
var config = { staticCacheItems: , cachePathPattern: /^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/};Pourquoi une liste blanche ?
Vous vous demandez peut-être pourquoi je ne mets en cache que les choses dont les chemins correspondent à cette expression régulière :
/^\/(?:(20{2}|about|blog|css|images|js)\/(.+)?)?$/
… au lieu de mettre en cache tout ce qui provient de ma propre origine. Quelques raisons:
- Je ne veux pas mettre en cache le travailleur de service lui-même.
- Lorsque je développe mon site web localement, certaines requêtes générées sont pour des choses que je ne veux pas mettre en cache. Par exemple, j’utilise
browserSync, qui déclenche un tas de requêtes connexes dans mon environnement de développement. Je ne veux pas mettre ces choses en cache ! Il semblait désordonné et difficile d’essayer de penser à tout ce que je ne voudrais pas mettre en cache (sans parler du fait qu’il était un peu bizarre de devoir l’expliciter dans la configuration de mon travailleur de service). Donc, une approche de liste blanche semblait plus naturelle.
Écrire le gestionnaire de récupération
Maintenant, nous sommes prêts à transmettre les demandes fetch applicables à un gestionnaire. La fonction onFetch doit déterminer :
- quel type de ressource est demandé,
- et comment je dois répondre à cette demande.
1. Quel type de ressource est demandé ?
Je peux regarder l’en-tête HTTP Accept pour avoir un indice sur le type d’actif demandé. Cela m’aide à déterminer comment je veux le traiter.
function onFetch (event, opts) { var request = event.request; var acceptHeader = request.headers.get('Accept'); var resourceType = 'static'; var cacheKey; if (acceptHeader.indexOf('text/html') !== -1) { resourceType = 'content'; } else if (acceptHeader.indexOf('image') !== -1) { resourceType = 'image'; } // {String} cacheKey = resourceType; // … now do something}Pour rester organisé, je veux coller différents types de ressources dans différents caches. Cela me permettra de gérer ces caches plus tard. Ces clés de cache Stringsont arbitraires – vous pouvez appeler vos caches comme vous le souhaitez ; l’API de cache n’a pas d’avis.
2. Répondre au Fetch
La prochaine chose à faire pour onFetch est de respondTol’événement fetch avec un Response intelligent.
function onFetch (event, opts) { // 1. Determine what kind of asset this is… (above). if (resourceType === 'content') { // Use a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) ); } else { // Use a cache-first strategy. event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)) ); }}Attention à l’asynchrone!
Dans notre cas, shouldHandleFetch ne fait rien d’asynchrone, et onFetch non plus jusqu’au point de event.respondWith. Si quelque chose d’asynchrone s’était produit avant cela, nous aurions des problèmes. event.respondWith doit être appelé entre le déclenchement de l’événement fetch et le retour du contrôle au navigateur. Il en va de même pour event.waitUntil. En gros, si vous traitez un événement, faites quelque chose immédiatement (de manière synchrone) ou dites au navigateur de patienter jusqu’à ce que votre truc asynchrone soit fait.
Contenu HTML : Mise en œuvre d’une stratégie axée sur le réseau
Répondre aux demandes fetch implique la mise en œuvre d’une stratégie réseau appropriée. Examinons de plus près la façon dont nous répondons aux demandes de contenu HTML (resourceType === 'content').
if (resourceType === 'content') { // Respond with a network-first strategy. event.respondWith( fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts)) );}La façon dont nous répondons aux demandes de contenu ici est une stratégie de réseau d’abord. Parce que le contenu HTML est la préoccupation centrale de mon site Web et qu’il change souvent, j’essaie toujours d’obtenir des documents HTML frais à partir du réseau.
Démarrons par étape.
1. Essayez de récupérer à partir du réseau
fetch(request) .then(response => addToCache(cacheKey, request, response))Si la requête réseau est réussie (c’est-à-dire que la promesse se résout), allez-y et stockez une copie du document HTML dans le cache approprié (content). C’est ce qu’on appelle la mise en cache en lecture directe :
function addToCache (cacheKey, request, response) { if (response.ok) { var copy = response.clone(); caches.open(cacheKey).then( cache => { cache.put(request, copy); }); return response; }}Les réponses ne peuvent être utilisées qu’une seule fois.
Nous devons faire deux choses avec le response que nous avons :
- le mettre en cache,
- répondre à l’événement avec lui (c’est-à-dire le retourner).
Mais les objets Response ne peuvent être utilisés qu’une seule fois. En le clonant, nous sommes en mesure de créer une copie pour l’utilisation du cache:
var copy = response.clone();
Ne mettez pas en cache les mauvaises réponses. Ne faites pas la même erreur que moi. La première version de mon code n’avait pas cette conditionnelle:
if (response.ok)Pretty awesome de se retrouver avec 404 ou d’autres mauvaises réponses dans le cache ! Ne mettez en cache que les réponses heureuses.
2. Essayer de récupérer depuis le cache
Si la récupération de l’actif depuis le réseau réussit, nous avons terminé. Cependant, si cela ne réussit pas, nous pourrions être hors ligne ou autrement compromis par le réseau. Essayez de récupérer une copie précédemment mise en cache du HTML à partir du cache:
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event))Voici la fonction fetchFromCache:
function fetchFromCache (event) { return caches.match(event.request).then(response => { if (!response) { // A synchronous error that will kick off the catch handler throw Error('${event.request.url} not found in cache'); } return response; });}Note : N’indiquez pas quel cache vous souhaitez vérifier avec caches.match ; vérifiez-les tous en même temps.
3. fournir un repli hors ligne
Si nous sommes arrivés jusqu’ici mais qu’il n’y a rien dans le cache avec lequel nous pouvons répondre, renvoyez un repli hors ligne approprié, si possible. Pour les pages HTML, il s’agit de la page mise en cache à partir de /offline/. C’est une page raisonnablement bien formatée qui indique à l’utilisateur qu’il est hors ligne et que nous ne pouvons pas répondre à ce qu’il recherche.
fetch(request) .then(response => addToCache(cacheKey, request, response)) .catch(() => fetchFromCache(event)) .catch(() => offlineResponse(opts))Et voici la fonction offlineResponse:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { return new Response(opts.offlineImage, { headers: { 'Content-Type': 'image/svg+xml' } } ); } else if (resourceType === 'content') { return caches.match(opts.offlinePage); } return undefined;}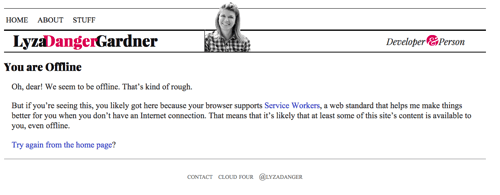
Autres ressources : Mise en œuvre d’une stratégie de cache en premier
La logique de récupération des ressources autres que le contenu HTML utilise une stratégie de cache en premier. Les images et autres contenus statiques sur le site Web changent rarement ; ainsi, vérifiez d’abord le cache et évitez les allers-retours sur le réseau.
event.respondWith( fetchFromCache(event) .catch(() => fetch(request)) .then(response => addToCache(cacheKey, request, response)) .catch(() => offlineResponse(resourceType, opts)));Les étapes ici sont :
- essayer de récupérer l’actif à partir du cache ;
- si cela échoue, essayer de récupérer à partir du réseau (avec une mise en cache en lecture directe) ;
- si cela échoue, fournir une ressource de repli hors ligne, si possible.
Image hors ligne
Nous pouvons retourner une image SVG avec le texte « Offline » comme ressource de repli hors ligne en complétant la fonction offlineResource:
function offlineResponse (resourceType, opts) { if (resourceType === 'image') { // … return an offline image } else if (resourceType === 'content') { return caches.match('/offline/'); } return undefined;}Et faisons les mises à jour pertinentes de config:
var config = { // … offlineImage: '<svg role="img" aria-labelledby="offline-title"' + 'viewBox="0 0 400 300" xmlns="http://www.w3.org/2000/svg">' + '<title>Offline</title>' + '<g fill="none" fill-rule="evenodd"><path fill=>"#D8D8D8" d="M0 0h400v300H0z"/>' + '<text fill="#9B9B9B" font-family="Times New Roman,Times,serif" font-size="72" font-weight="bold">' + '<tspan x="93" y="172">offline</tspan></text></g></svg>', offlinePage: '/offline/'};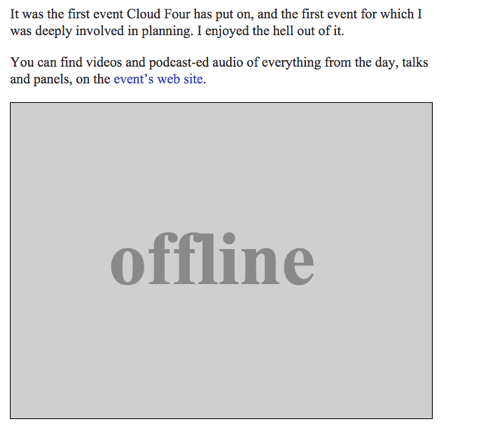
Veillez aux CDN
Veillez aux CDN si vous limitez la gestion des récupérations à votre origine. En construisant mon premier service worker, j’ai oublié que mon hébergeur shardait des actifs (images et scripts) sur son CDN, de sorte qu’ils n’étaient plus servis depuis l’origine de mon site web (lyza.com). Oups ! Cela n’a pas fonctionné. J’ai fini par désactiver le CDN pour les actifs concernés (mais en optimisant ces actifs, bien sûr !).
Compléter la première version
La première version de notre travailleur de service est maintenant terminée. Nous disposons d’un gestionnaire install et d’un gestionnaire fetch étoffé qui peut répondre aux fetches applicables avec des réponses optimisées, ainsi que fournir des ressources en cache et une page hors ligne lorsqu’ils sont hors ligne.
A mesure que les utilisateurs naviguent sur le site Web, ils continueront à accumuler plus d’éléments en cache. Lorsqu’ils sont hors ligne, ils pourront continuer à parcourir les éléments qu’ils ont déjà mis en cache, ou ils verront une page hors ligne (ou une image) si la ressource demandée n’est pas disponible dans le cache.
Le code complet avec la gestion du fetch (serviceWorker.js) est sur GitHub.
Version et mise à jour du Service Worker
Si plus rien ne devait changer sur notre site web, nous pourrions dire que nous avons terminé. Cependant, les travailleurs de service ont besoin d’être mis à jour de temps en temps. Peut-être que je voudrai ajouter plus de chemins pouvant être mis en cache. Peut-être que je veux faire évoluer la façon dont mes solutions de repli hors ligne fonctionnent. Peut-être y a-t-il quelque chose de légèrement bogué dans mon travailleur de service que je veux corriger.
Je tiens à souligner qu’il existe des outils automatisés pour intégrer la gestion des travailleurs de service dans votre flux de travail, comme Service Worker Precache de Google. Vous n’avez pas besoin de gérer le versionnement de ceci à la main. Cependant, la complexité de mon site Web est suffisamment faible pour que j’utilise une stratégie de versionnement humaine pour gérer les modifications de mon travailleur de service. Cela consiste en:
- une simple chaîne de version pour indiquer les versions,
- implémentation d’un gestionnaire
activatepour nettoyer après les anciennes versions, - mise à jour du gestionnaire
installpour rendre les travailleurs de service mis à jouractivateplus rapides.
Version des clés de cache
Je peux ajouter une propriété version à mon objet config:
version: 'aether'Ceci devrait changer chaque fois que je veux déployer une version mise à jour de mon travailleur de service. J’utilise les noms des divinités grecques parce qu’ils sont plus intéressants pour moi que des chaînes ou des nombres aléatoires.
Note : J’ai apporté quelques modifications au code, en ajoutant une fonction de commodité (cacheName) pour générer des clés de cache préfixées. C’est tangentiel, donc je ne l’inclus pas ici, mais vous pouvez le voir dans le code du travailleur de service complété.
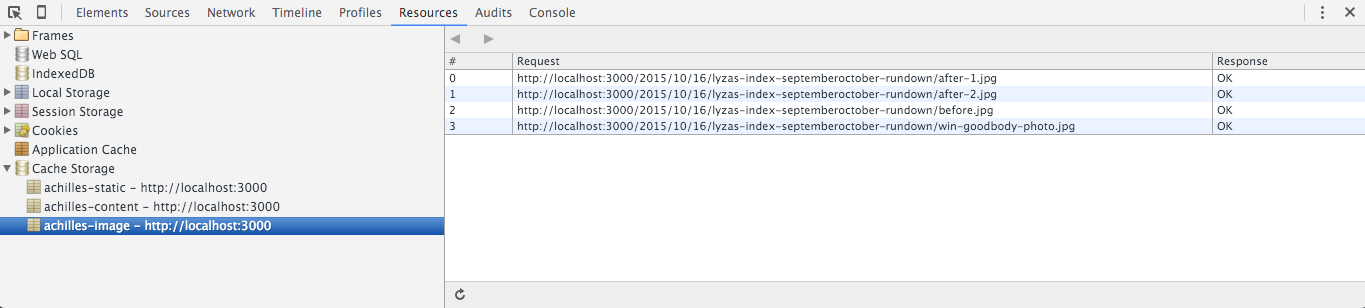
achilles.) (View large version)Ne renommez pas votre Service Worker
À un moment donné, j’ai bricolé des conventions de nommage pour le nom de fichier du Service Worker. Ne faites pas cela. Si vous le faites, le navigateur enregistrera le nouveau travailleur de service, mais l’ancien travailleur de service restera installé, aussi. C’est une situation désordonnée. Je suis sûr qu’il y a une solution de contournement, mais je dirais de ne pas renommer votre travailleur de service.
Ne pas utiliser importScripts pour config
J’ai suivi une voie consistant à mettre mon objet config dans un fichier externe et à utiliser self.importScripts() dans le fichier du travailleur de service pour tirer ce script. Cela semblait être un moyen raisonnable de gérer mon config en dehors du travailleur de service, mais il y avait un hic.
Le navigateur compare les octets des fichiers du travailleur de service pour déterminer s’ils ont été mis à jour – c’est ainsi qu’il sait quand redéclencher un cycle de téléchargement et d’installation. Les modifications apportées au config externe ne provoquent aucune modification du travailleur de service lui-même, ce qui signifie que les modifications apportées au config ne provoquaient pas la mise à jour du travailleur de service. Oups.
Ajout d’un gestionnaire d’activation
Le but d’avoir des noms de cache spécifiques à une version est que nous puissions nettoyer les caches des versions précédentes. S’il y a des caches autour pendant l’activation qui ne sont pas préfixés avec la chaîne de la version actuelle, nous saurons qu’ils devraient être supprimés parce qu’ils sont crufty.
Nettoyage des anciens caches
Nous pouvons utiliser une fonction pour nettoyer après les anciens caches:
function onActivate (event, opts) { return caches.keys() .then(cacheKeys => { var oldCacheKeys = cacheKeys.filter(key => key.indexOf(opts.version) !== 0 ); var deletePromises = oldCacheKeys.map(oldKey => caches.delete(oldKey)); return Promise.all(deletePromises); });}Accélération de l’installation et de l’activation
Un worker de service mis à jour sera téléchargé et sera installen arrière-plan. C’est maintenant un travailleur en attente. Par défaut, le travailleur de service mis à jour ne sera pas activé pendant le chargement des pages qui utilisent encore l’ancien travailleur de service. Cependant, nous pouvons accélérer cela en apportant une petite modification à notre gestionnaire install:
self.addEventListener('install', event => { // … as before event.waitUntil( onInstall(event, config) .then( () => self.skipWaiting() ) );});skipWaiting fera en sorte que activate se produise immédiatement.
Maintenant, terminez le gestionnaire activate:
self.addEventListener('activate', event => { function onActivate (event, opts) { // … as above } event.waitUntil( onActivate(event, config) .then( () => self.clients.claim() ) );});self.clients.claim fera en sorte que le nouveau travailleur de service prenne effet immédiatement sur toutes les pages ouvertes dans sa portée.

chrome://serviceworker-internals dans Chrome pour voir tous les travailleurs de service que le navigateur a enregistrés. (Voir la grande version)
Ta-Da!
Nous avons maintenant un travailleur de service géré par version ! Vous pouvez voir le fichier serviceWorker.js mis à jour avec la gestion des versions sur GitHub.
Lectures complémentaires sur SmashingMag:
- Guide du débutant pour les applications Web progressives
- Construire une liste de choses à faire hors ligne simple et croisée
- World Wide Web, not Wealthy Western Web
.