
Předtím, než jsem se vydal na tuto cestu snahy naučit se informatiku, existovaly určité termíny a fráze, které mě nutily utíkat opačným směrem.
Ale místo abych utíkal, předstíral jsem jejich znalost, přikyvoval jsem v rozhovorech a předstíral, že vím, na co někdo odkazuje, i když pravda byla taková, že jsem neměl tušení a vlastně jsem přestal úplně poslouchat, když jsem slyšel That Super Scary Computer Science Term™. V průběhu tohoto seriálu se mi podařilo pokrýt spoustu témat a mnoho z těchto termínů se ve skutečnosti stalo mnohem méně děsivými!“
Je tu však jeden velký, kterému jsem se nějakou dobu vyhýbal. Až dosud, kdykoli jsem tento termín slyšel, cítil jsem se ochromen. Objevoval se v náhodných rozhovorech na setkáních a někdy i na konferencích. Pokaždé se mi vybaví stroje, které se točí, a počítače chrlící řetězce kódu, které jsou nerozluštitelné, až na to, že všichni ostatní kolem mě je vlastně umí rozluštit, takže jsem to vlastně jen já, kdo neví, co se děje (jéje, jak se to stalo?!).
Snad nejsem jediný, kdo se tak cítil. Ale asi bych vám měl říct, co je to vlastně za pojem, ne? No, připravte se, protože mám na mysli stále neuchopitelný a zdánlivě matoucí abstraktní syntaktický strom, zkráceně AST. Po mnoha letech zastrašování jsem nadšený, že se konečně přestávám tohoto termínu bát a skutečně chápu, co to proboha je.
Je čas postavit se kořenům abstraktního syntaktického stromu čelem – a srovnat naši hru na parsování!
Každé dobré pátrání začíná pevným základem a naše mise demystifikovat tuto strukturu by měla začít úplně stejně: samozřejmě definicí!
Abstraktní syntaktický strom (obvykle označovaný jen jako AST) není ve skutečnosti nic jiného než zjednodušená, zhuštěná verze stromu parsování. V kontextu návrhu překladače se termín „AST“ používá zaměnitelně se syntaktickým stromem.

O syntaktických stromech (a jejich konstrukci) často uvažujeme v porovnání s jejich protějšky v podobě parsovacích stromů, které již dobře známe. Víme, že parsovací stromy jsou stromové datové struktury, které obsahují gramatickou strukturu našeho kódu; jinými slovy, obsahují všechny syntaktické informace, které se objevují ve „větě“ kódu a jsou odvozeny přímo z gramatiky samotného programovacího jazyka.
Abstraktní syntaktický strom naproti tomu ignoruje značné množství syntaktických informací, které by jinak parsovací strom obsahoval.
Naproti tomu AST obsahuje pouze informace související s analýzou zdrojového textu a vynechává jakýkoli další dodatečný obsah, který se používá při rozboru textu.
Toto rozlišení začne dávat mnohem větší smysl, pokud se zaměříme na „abstraktnost“ AST.
Připomeneme si, že parsovací strom je ilustrovaná, obrázková verze gramatické struktury věty. Jinými slovy můžeme říci, že parsovací strom přesně znázorňuje, jak výraz, věta nebo text vypadá. Je to v podstatě přímý překlad samotného textu; vezmeme větu a každý její kousek – od interpunkce přes výrazy až po tokeny – převedeme do stromové datové struktury. Odhaluje konkrétní syntax textu, proto se také označuje jako konkrétní syntaktický strom neboli CST. Termín konkrétní používáme k popisu této struktury proto, že se jedná o gramatickou kopii našeho kódu, token po tokenu, ve stromovém formátu.
Ale co dělá něco konkrétním oproti abstraktnímu? Inu, abstraktní syntaktický strom nám neukazuje, jak přesně výraz vypadá, tak jako to dělá parsovací strom.

Abstraktní syntaktický strom nám spíše ukazuje „důležité“ části – věci, na kterých nám opravdu záleží a které dávají smysl samotné „větě“ našeho kódu. Syntaktické stromy nám ukazují významné části výrazu neboli abstrahovanou syntaxi našeho zdrojového textu. Ve srovnání s konkrétními syntaktickými stromy jsou tedy tyto struktury abstraktní reprezentací našeho kódu (a v některých ohledech méně přesnou), a právě proto dostaly své jméno.
Teď, když jsme pochopili rozdíl mezi těmito dvěma datovými strukturami a různé způsoby, jakými mohou reprezentovat náš kód, stojí za to položit si otázku: Kam se abstraktní syntaktický strom v překladači hodí? Nejprve si připomeňme vše, co víme o procesu kompilace, jak ho známe doposud.

Řekněme, že máme super krátký a sladký zdrojový text, který vypadá takto: 5 + (1 x 12).
Připomeňme si, že první, co se v procesu kompilace stane, je skenování textu, což je práce prováděná skenerem, jejímž výsledkem je rozdělení textu na co nejmenší části, které se nazývají lexémy. Tato část bude jazykově agnostická a my skončíme s rozebranou verzí našeho zdrojového textu.
Poté jsou právě tyto lexémy předány lexeru/tokenizéru, který tyto malé reprezentace našeho zdrojového textu změní na tokeny, které budou specifické pro náš jazyk. Naše tokeny budou vypadat nějak takto: . Společné úsilí skeneru a tokenizéru tvoří lexikální analýzu kompilace.
Poté, co byl náš vstup tokenizován, jsou jeho výsledné tokeny předány našemu parseru, který pak vezme zdrojový text a sestaví z něj strom rozboru. Následující obrázek je ukázkou toho, jak vypadá náš tokenizovaný kód ve formátu stromu parsování.
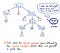
Práce spočívající v přeměně tokenů na strom parsování se také nazývá parsování a je známa jako fáze syntaktické analýzy. Fáze syntaktické analýzy je přímo závislá na fázi lexikální analýzy; lexikální analýza tedy musí být v procesu kompilace vždy na prvním místě, protože parser našeho překladače může svou práci vykonat až poté, co svou práci vykoná tokenizér!
Můžeme si části kompilátoru představit jako dobré přátele, kteří jsou na sobě navzájem závislí, aby zajistili správnou transformaci našeho kódu z textu nebo souboru do parsovacího stromu.
Ale zpět k naší původní otázce: kam do této skupiny přátel patří abstraktní syntaktický strom? No, abychom mohli odpovědět na tuto otázku, pomůže nám v první řadě pochopit, proč vůbec potřebujeme AST.
Kondenzace jednoho stromu do druhého
Dobře, takže teď máme dva stromy, které musíme mít v hlavě srovnané. Už jsme měli strom parsování, a jak je tu další datová struktura, kterou se musíme naučit! A podle všeho je tato datová struktura AST jen zjednodušeným parsovacím stromem. K čemu ji tedy potřebujeme? Jaký to má vůbec smysl?“
No, pojďme se podívat na náš parsovací strom, ano?“
Již víme, že parsovací stromy reprezentují náš program po jeho nejzřetelnějších částech; ostatně právě proto mají skener a tokenizér tak důležitou úlohu rozložit náš výraz na jeho nejmenší části!“
Co to vlastně znamená reprezentovat program po jeho nejzřetelnějších částech?
Jak se ukazuje, někdy nám vlastně všechny odlišné části programu nejsou vždycky až tak užitečné.
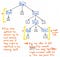
Podívejme se na zde uvedený obrázek, který představuje náš původní výraz 5 + (1 x 12) ve formátu stromu parsování. Pokud se na tento strom podíváme kritickým okem, zjistíme, že existuje několik případů, kdy má jeden uzel přesně jednoho potomka, které se také označují jako uzly s jedním následníkem, protože z nich vychází pouze jeden podřízený uzel (neboli jeden „následník“).
V případě našeho příkladu stromu parsování mají uzly s jedním následníkem rodičovský uzel Expression nebo Exp, které mají jediného následníka nějaké hodnoty, například 5, 1 nebo 12. Nadřazené uzly Exp nám zde však ve skutečnosti nic hodnotného nepřidávají, nebo ano? Vidíme, že obsahují podřízené uzly token/terminál, ale rodičovský uzel „výraz“ nás ve skutečnosti nezajímá; jediné, co chceme vědět, je, co je to výraz?“
Rodičovský uzel nám po rozboru našeho stromu neposkytuje vůbec žádné další informace. Místo toho nás ve skutečnosti zajímá jediný podřízený uzel s jedním následníkem. To je totiž uzel, který nám poskytuje důležitou informaci, tu část, která je pro nás podstatná: samotné číslo a hodnotu! Vzhledem k tomu, že tyto rodičovské uzly jsou pro nás tak trochu zbytečné, je zřejmé, že tento parsovací strom je tak trochu slovíčkaření.
Všechny tyto uzly s jedním následníkem jsou pro nás docela zbytečné a vůbec nám nepomáhají. Zbavme se jich tedy!“
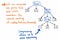
Pokud komprimujeme jednovětné uzly v našem stromu parsování, získáme ve výsledku komprimovanější verzi přesně stejné struktury. Při pohledu na výše uvedený obrázek uvidíme, že stále zachováváme přesně stejné vnoření jako dříve a naše uzly/tokeny/terminály se ve stromu stále objevují na správném místě. Ale podařilo se nám ho trochu zeštíhlit.
A můžeme také ořezat další části našeho stromu. Pokud se například podíváme na náš strom parsování v současné podobě, uvidíme, že se v něm nachází zrcadlová struktura. Podvýraz (1 x 12) je vnořen do závorek (), které jsou samy o sobě tokeny.
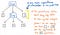
Tyto závorky nám však ve skutečnosti nepomohou, jakmile máme náš strom hotový. Už víme, že 1 a 12 jsou argumenty, které budou předány operaci násobení x, takže závorky nám v tuto chvíli zase tolik neřeknou. Ve skutečnosti bychom mohli náš strom parsování ještě více zkomprimovat a zbavit se těchto nadbytečných listových uzlů.
Pokud náš strom parsování zkomprimujeme a zjednodušíme a zbavíme se nadbytečného syntaktického „prachu“, dostaneme strukturu, která v tomto okamžiku vypadá viditelně jinak. Touto strukturou je ve skutečnosti náš nový a tolik očekávaný přítel: abstraktní syntaktický strom.

Výše uvedený obrázek ilustruje přesně stejný výraz jako náš parsovací strom: 5 + (1 x 12). Rozdíl je v tom, že abstrahoval výraz od konkrétní syntaxe. V tomto stromu již nevidíme žádné závorky (), protože nejsou nutné. Stejně tak nevidíme neterminály jako Exp, protože jsme již zjistili, co je „výraz“, a jsme schopni vytáhnout hodnotu, která je pro nás skutečně důležitá – například číslo 5.
To je přesně ten rozlišující faktor mezi AST a CST. Víme, že abstraktní syntaktický strom ignoruje značné množství syntaktických informací, které obsahuje parsovací strom, a vynechává „obsah navíc“, který se používá při parsování. Nyní však můžeme přesně vidět, jak k tomu dochází!“

Teď, když jsme si zhustili vlastní parsovací strom, budeme mnohem lépe vnímat některé zákonitosti, které odlišují AST od CST.
Existuje několik způsobů, kterými se abstraktní syntaktický strom vizuálně liší od parsovacího stromu:
- AST nikdy nebude obsahovat syntaktické detaily, jako jsou čárky, závorky a středníky (samozřejmě v závislosti na jazyce).
- AST bude mít sbalené verze toho, co by jinak vypadalo jako jednovětné uzly; nikdy nebude obsahovat „řetězce“ uzlů s jedním potomkem.
- Nakonec se všechny operátorové tokeny (jako
+,-,xa/) stanou vnitřními (rodičovskými) uzly stromu, nikoli listy, které končí v parsovacím stromu.
Vizuálně bude AST vždy vypadat kompaktněji než parsovací strom, protože je to z definice komprimovaná verze parsovacího stromu s méně syntaktickými detaily.
Je tedy logické, že pokud je AST zhuštěnou verzí parsovacího stromu, můžeme abstraktní syntaktický strom skutečně vytvořit pouze tehdy, pokud máme věci, kterými můžeme parsovací strom začít sestavovat!“
Takto skutečně zapadá abstraktní syntaktický strom do širšího procesu kompilace. AST má přímou vazbu na parsovací stromy, o kterých jsme se již učili, a zároveň spoléhá na to, že lexer odvede svou práci ještě předtím, než AST vůbec vytvoříme.

Abstraktní syntaktický strom se vytváří jako konečný výsledek fáze syntaktické analýzy. Parser, který je při syntaktické analýze v popředí jako hlavní „postava“, může, ale nemusí vždy vytvářet parsovací strom neboli CST. V závislosti na samotném překladači a na tom, jak byl navržen, může parser rovnou přejít ke konstrukci syntaktického stromu neboli AST. Parser však vždy vygeneruje AST jako svůj výstup, bez ohledu na to, zda mezitím vytvoří parsovací strom nebo kolik průchodů k tomu může potřebovat.
Anatomie AST
Teď, když víme, že abstraktní syntaktický strom je důležitý (ale ne nutně zastrašující!), můžeme ho začít pitvat trochu víc. Zajímavý aspekt toho, jak je AST konstruován, souvisí s uzly tohoto stromu.
Následující obrázek je ukázkou anatomie jednoho uzlu v rámci abstraktního syntaktického stromu.
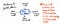
Všimneme si, že tento uzel je podobný ostatním, které jsme viděli dříve, protože obsahuje nějaká data (a token a jeho value). Obsahuje však také několik velmi specifických ukazatelů. Každý uzel v AST obsahuje odkazy na svůj další sourozenecký uzel a také na svůj první podřízený uzel.
Například z našeho jednoduchého výrazu 5 + (1 x 12) lze sestavit vizualizovanou ilustraci AST, jako je ta níže.

Můžeme si představit, že čtení, procházení nebo „interpretace“ tohoto AST může začít od spodních úrovní stromu, postupovat zpět nahoru a na konci vytvořit hodnotu nebo návratovou result
Může nám také pomoci vidět kódovanou verzi výstupu parseru, která nám pomůže doplnit vizualizace. Můžeme se opřít o různé nástroje a použít již existující parsery, abychom viděli rychlý příklad toho, jak by náš výraz mohl vypadat při průchodu parserem. Níže je uveden příklad našeho zdrojového textu 5 + (1 * 12), prohnaného parserem Esprima, parserem ECMAScript, a jeho výsledný abstraktní syntaktický strom, následovaný seznamem jeho jednotlivých tokenů.
V tomto formátu můžeme vidět vnoření stromu, pokud se podíváme na vnořené objekty. Všimneme si, že hodnoty obsahující 1 a 12 jsou left a right potomky nadřazené operace *. Uvidíme také, že operace násobení (*) tvoří pravý podstrom celého vlastního výrazu, proto je vnořena do většího objektu BinaryExpression pod klíčem "right". Podobně hodnota 5 je jediným potomkem "left" většího objektu BinaryExpression.

Nejzajímavějším aspektem abstraktního syntaktického stromu je však skutečnost, že i když jsou tak kompaktní a přehledné, není vždy snadné se o jejich konstrukci pokusit. Ve skutečnosti může být sestavení AST docela složité, v závislosti na jazyce, se kterým parser pracuje!
Většina parserů obvykle buď zkonstruuje parsovací strom (CST) a pak jej převede do formátu AST, protože to může být někdy jednodušší – i když to znamená více kroků a obecně řečeno více průchodů zdrojovým textem. Sestavení CST je ve skutečnosti docela snadné, jakmile parser zná gramatiku jazyka, který se snaží analyzovat. Nemusí složitě zjišťovat, zda je token „významný“, nebo ne; místo toho prostě vezme přesně to, co vidí, v konkrétním pořadí, v jakém to vidí, a vyplivne to všechno do stromu.
Na druhou stranu existují parsery, které se to všechno pokusí udělat jako jednokrokový proces a rovnou přejdou ke konstrukci abstraktního syntaktického stromu.
Přímé sestavení AST může být složité, protože parser musí nejen najít tokeny a správně je reprezentovat, ale také rozhodnout, které tokeny jsou pro nás důležité a které ne.
Při návrhu překladače je AST nakonec superdůležitý z více než jednoho důvodu. Ano, jeho konstrukce může být složitá (a pravděpodobně se dá snadno pokazit), ale také je to poslední a konečný výsledek kombinované fáze lexikální a syntaktické analýzy! Fáze lexikální a syntaktické analýzy se často společně nazývají fází analýzy nebo front-endem překladače.

O abstraktním syntaktickém stromu můžeme uvažovat jako o „konečném projektu“ front-endu překladače. Je to nejdůležitější část, protože je to poslední věc, kterou se front-end musí předvést. Odborně se mu říká reprezentace mezikódu neboli IR, protože se stává datovou strukturou, kterou nakonec překladač používá k reprezentaci zdrojového textu.
Abstraktní syntaktický strom je nejběžnější formou IR, ale také, někdy nejvíce nepochopenou. Ale teď, když mu rozumíme o něco lépe, můžeme začít měnit své vnímání této děsivé struktury! Doufejme, že je pro nás nyní o něco méně zastrašující.
Zdroje
O AST existuje celá řada zdrojů, a to v různých jazycích. Vyznat se v tom, kde začít, může být složité, zejména pokud se chcete naučit více. Níže uvádíme několik zdrojů vhodných pro začátečníky, které se zabývají mnohem podrobněji, aniž by byly příliš náročné. Šťastnou cestu!!!
- AST vs. strom parsování, profesor Charles N. Fischer
- Jaký je rozdíl mezi stromy parsování a abstraktními syntaktickými stromy? StackOverflow
- Abstraktní vs. konkrétní syntaktické stromy, Eli Bendersky
- Abstraktní syntaktické stromy, profesor Stephen A. Edwards
- Abstraktní syntaktické stromy & Parsing shora dolů, profesor Konstantinos (Kostis) Sagonas
- Lexikální a syntaktická analýza programovacích jazyků, Chris Northwood
- AST Explorer, Felix Kling