Šifrování dat v klidovém stavu je pro každou moderní internetovou společnost nezbytností. Mnoho společností však své disky nešifruje, protože se obávají potenciálního snížení výkonu způsobeného režijními náklady na šifrování.
Šifrování dat v klidu je pro společnost Cloudflare s více než 200 datovými centry po celém světě životně důležité. V tomto příspěvku prozkoumáme výkonnost šifrování disků v systému Linux a vysvětlíme, jak jsme jej pro sebe a naše zákazníky zrychlili nejméně dvakrát!
Šifrování dat v klidu
Pokud jde o šifrování dat v klidu, existuje několik způsobů, jak jej v moderním operačním systému (OS) realizovat. Dostupné techniky jsou úzce spjaty s typickým zásobníkem úložišť OS. Zjednodušenou verzi zásobníku úložišť a řešení šifrování najdete na následujícím diagramu:
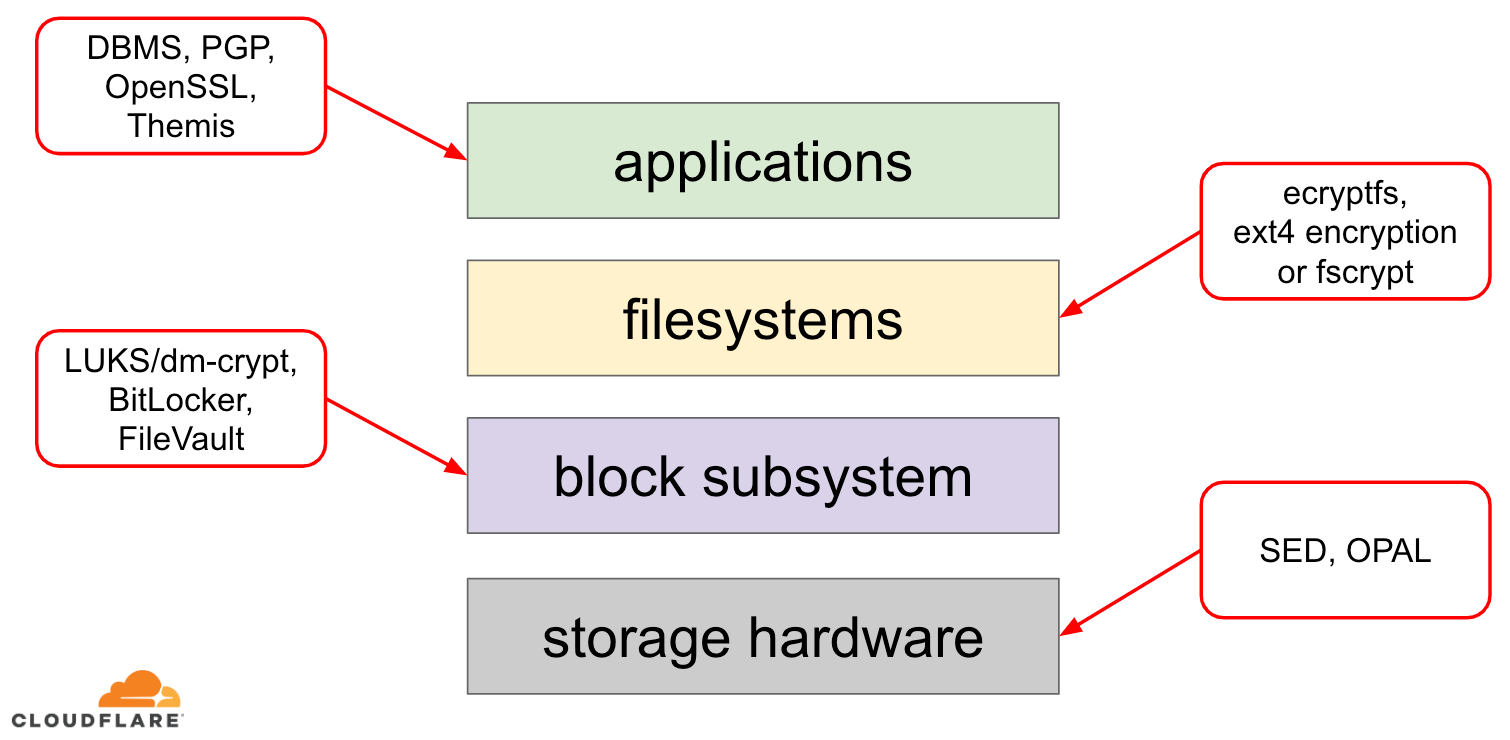
Na vrcholu zásobníku jsou aplikace, které čtou a zapisují data v souborech (nebo proudech). Souborový systém v jádře operačního systému sleduje, které bloky podkladového blokového zařízení patří ke kterým souborům, a převádí tato čtení a zápisy souborů na čtení a zápisy bloků, avšak hardwarová specifika podkladového úložného zařízení jsou od souborového systému abstrahována. Nakonec blokový subsystém skutečně předává čtení a zápisy bloků podkladovému hardwaru pomocí příslušných ovladačů zařízení.
Koncepce zásobníku úložišť je vlastně podobná známému síťovému modelu OSI, kde každá vrstva má více vysokoúrovňový pohled na informace a implementační detaily nižších vrstev jsou od horních vrstev abstrahovány. A podobně jako v modelu OSI lze použít šifrování na různých vrstvách (vzpomeňte si na TLS vs. IPsec nebo VPN).
Pro data v klidu můžeme použít šifrování buď na blokových vrstvách (buď v hardwaru, nebo v softwaru), nebo na úrovni souborů (buď přímo v aplikacích, nebo v souborovém systému).
Šifrování bloků vs. souborů
Obecně platí, že čím výše v zásobníku šifrování použijeme, tím větší flexibilitu máme. Při šifrování na úrovni aplikace mohou správci aplikace použít libovolný šifrovací kód na konkrétní data, která potřebují. Nevýhodou tohoto přístupu je, že jej vlastně musí implementovat sami a šifrování obecně není příliš přívětivé pro vývojáře: je třeba znát zákoutí konkrétního kryptografického algoritmu, správně generovat klíče, noncesy, IV atd. Šifrování na aplikační úrovni navíc nevyužívá ukládání do mezipaměti na úrovni operačního systému a zejména linuxové mezipaměti stránek: pokaždé, když aplikace potřebuje data použít, musí je buď znovu dešifrovat, čímž plýtvá cykly procesoru, nebo implementovat vlastní dešifrovanou „mezipaměť“, což do kódu vnáší další složitost.
Šifrování na úrovni souborového systému činí šifrování dat pro aplikace transparentním, protože souborový systém sám data před předáním blokovému subsystému zašifruje, takže soubory jsou šifrovány bez ohledu na to, zda má aplikace podporu šifrování nebo ne. Souborové systémy lze také nakonfigurovat tak, aby šifrovaly pouze určitý adresář nebo měly různé klíče pro různé soubory. Tato flexibilita je však za cenu složitější konfigurace. Šifrování souborového systému je také považováno za méně bezpečné než šifrování blokových zařízení, protože je šifrován pouze obsah souborů. Soubory mají také přidružená metadata, jako je velikost souboru, počet souborů, uspořádání stromu adresářů atd., která jsou pro potenciálního protivníka stále viditelná.
Šifrování až na blokové vrstvě (často označované jako šifrování disku nebo šifrování celého disku) také zprůhledňuje šifrování dat pro aplikace a dokonce i celé souborové systémy. Na rozdíl od šifrování na úrovni souborového systému šifruje všechna data na disku včetně metadat souborů a dokonce i volného místa. Je však méně flexibilní – celý disk lze zašifrovat pouze jedním klíčem, takže neexistuje žádná konfigurace pro jednotlivé adresáře, soubory nebo uživatele. Z hlediska šifrování nelze použít všechny kryptografické algoritmy, protože bloková vrstva již nemá vysokoúrovňový přehled o datech, takže musí zpracovávat každý blok samostatně. Většina běžných algoritmů vyžaduje ke svému zabezpečení nějaký druh řetězení bloků, takže nejsou použitelné pro diskové šifrování. Místo toho byly vyvinuty speciální režimy právě pro tento specifický případ použití.
Takže jakou vrstvu zvolit? Jako vždy záleží na… Šifrování na úrovni aplikací a souborového systému je obvykle preferovanou volbou pro klientské systémy z důvodu flexibility. Například každý uživatel na víceuživatelském počítači může chtít šifrovat svůj domovský adresář klíčem, který vlastní, a některé sdílené adresáře ponechat nešifrované. Naopak u serverových systémů, spravovaných společnostmi SaaS/PaaS/IaaS (včetně Cloudflare), je preferovanou volbou jednoduchost konfigurace a zabezpečení – při zapnutém šifrování celého disku jsou jakákoli data z jakékoli aplikace automaticky šifrována bez výjimek nebo přepisů. Domníváme se, že všechna data je třeba chránit bez třídění na „důležitá“ a „nedůležitá“, takže selektivní flexibilita, kterou poskytují vyšší vrstvy, není potřeba.
Hardwarové vs. softwarové šifrování disku
Při šifrování dat na blokové vrstvě je možné jej provádět přímo v hardwaru úložiště, pokud to hardware podporuje. Takový postup obvykle poskytuje lepší výkon při čtení/zápisu a spotřebovává méně prostředků hostitele. Protože je však většina hardwarového firmwaru proprietární, nedostává se mu od bezpečnostní komunity tolik pozornosti a recenzí. V minulosti to vedlo k chybám v některých implementacích hardwarového šifrování disků, které učinily celý model zabezpečení nepoužitelným. Například společnost Microsoft od té doby začala preferovat softwarové šifrování disků.
Nechtěli jsme vystavovat naše data a data našich zákazníků riziku používání potenciálně nezabezpečených řešení a pevně věříme v open-source. Proto se spoléháme pouze na softwarové šifrování disků v jádře Linuxu, které je otevřené a bylo prověřeno mnoha bezpečnostními odborníky po celém světě.
Výkon šifrování disků v Linuxu
Naším cílem je nejen ušetřit našim zákazníkům náklady na šířku pásma, ale také co nejrychleji doručovat obsah uživatelům internetu.
V jednu chvíli jsme si všimli, že naše disky nejsou tak rychlé, jak bychom si přáli. Několik profilů a také rychlý A/B test ukázaly na šifrování disků v systému Linux. Protože nešifrování dat (i když se má jednat o veřejnou internetovou mezipaměť) není udržitelnou variantou, rozhodli jsme se blíže podívat na výkonnost linuxového šifrování disků.
Mapovač zařízení a dm-crypt
Linux implementuje transparentní šifrování disků prostřednictvím modulu dm-crypt a dm-crypt sám je součástí jádra device mapper framework. Stručně řečeno, mapovač zařízení umožňuje předběžné/následné zpracování IO požadavků při jejich cestě mezi souborovým systémem a základním blokovým zařízením.
dm-crypt Konkrétně šifruje IO požadavky „zápis“ před jejich odesláním dále po zásobníku na skutečné blokové zařízení a dešifruje IO požadavky „čtení“ před jejich odesláním nahoru k ovladači souborového systému. Jednoduché a snadné! Nebo ne?
Nastavení benchmarkingu
Pro pořádek, čísla v tomto příspěvku byla získána spuštěním zadaných příkazů na nečinném serveru Cloudflare G9 mimo produkci. Nastavení by však mělo být snadno reprodukovatelné na jakémkoli moderním notebooku x86.
Obecně je benchmarkování čehokoli kolem zásobníku úložiště obtížné kvůli šumu vnášenému samotným hardwarem úložiště. Ne všechny disky jsou stejné, takže pro účely tohoto příspěvku použijeme nejrychlejší dostupné disky – tedy žádné disky.
Místo toho má Linux možnost emulovat disk přímo v paměti RAM. Protože paměť RAM je mnohem rychlejší než jakékoli trvalé úložiště, mělo by to do našich výsledků vnést jen malé zkreslení.
Následující příkaz vytvoří 4GB ramdisk:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Nyní na něm můžeme nastavit instanci dm-crypt, čímž umožníme šifrování disku. Nejprve musíme vygenerovat šifrovací klíč disku, „naformátovat“ disk a zadat heslo pro odemčení nově vygenerovaného klíče.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Ti, kdo znají LUKS/dm-crypt, si možná všimli, že jsme zde použili oddělenou hlavičku LUKS. Za normálních okolností ukládá systém LUKS šifrovací klíč disku zašifrovaný heslem na stejný disk jako data, ale protože chceme porovnat výkonnost čtení/zápisu mezi šifrovanými a nešifrovanými zařízeními, mohli bychom později při srovnávacím testu omylem šifrovaný klíč přepsat. Udržováním šifrovaného klíče v samostatném souboru se tomuto problému pro účely tohoto příspěvku vyhneme.
Nyní můžeme skutečně „odemknout“ šifrované zařízení pro naše testování:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0V tomto okamžiku můžeme nyní porovnat výkon šifrovaného a nešifrovaného ramdisku: pokud budeme číst/zapisovat data na /dev/ram0, budou uložena v prostém textu. Stejně tak pokud čteme/zapisujeme data na /dev/mapper/encrypted-ram0, budou cestou dešifrována/zašifrována pomocí dm-crypt a uložena v šifrovaném textu.
Je třeba poznamenat, že nad našimi blokovými zařízeními nevytváříme žádný souborový systém, abychom se vyhnuli zkreslení výsledků režií souborového systému.
Měření propustnosti
Pokud jde o testování/benchmarking úložišť, je obvyklým řešením Flexible I/O tester. Simulujme jednoduché sekvenční čtení/zápis s velikostí bloku 4K na ramdisku bez šifrování:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Výše uvedený příkaz poběží dlouho, takže ho po chvíli prostě zastavíme. Jak vidíme ze statistik, jsme schopni číst a zapisovat zhruba se stejnou propustností kolem 1126 MB/s. Zopakujme test se zašifrovaným ramdiskem:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecKdoví, to je pokles! Nyní dostáváme pouze ~147 MB/s, což je více než 7krát pomalejší! A to na zcela nečinném stroji!
Možná je šifrování jen pomalé
První věc, kterou jsme zvažovali, je zajistit, abychom používali co nejrychlejší šifrování. cryptsetup Umožňuje nám porovnat všechny dostupné implementace šifrování v systému a vybrat tu nejlepší:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/AZdá se, že aes-xts s 256bitovým klíčem pro šifrování dat je zde nejrychlejší. Ale kterou z nich vlastně používáme pro náš šifrovaný ramdisk?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Používáme skutečně aes-xts s 256bitovým klíčem pro šifrování dat (spočítejte všechny nuly příhodně maskované nástrojem dmsetup – pokud chcete vidět skutečné bajty, přidejte do výše uvedeného příkazu volbu --showkeys). Čísla se však nesčítají: cryptsetup benchmark nám výše říká, abychom se na výsledky nespoléhali, protože „Testy jsou přibližné, používají pouze paměť (bez IO úložiště)“, ale přesně tak jsme nastavili náš experiment s použitím ramdisku. V poněkud horším případě (za předpokladu, že čteme všechna data a pak je šifrujeme/dešifrujeme sekvenčně bez paralelizace) bychom měli výpočtem back-of-the-envelope získat přibližně (1126 * 1823) / (1126 + 1823) =~696 MB/s, což je stále dost daleko od skutečných 147 * 2 = 294 MB/s (celkem za čtení a zápis).
příznaky výkonu dm-crypt
Při čtení manuálové stránky cryptsetup jsme si všimli, že má dvě volby s předponou --perf-, které pravděpodobně souvisejí s laděním výkonu. První z nich je --perf-same_cpu_crypt s poněkud kryptickým popisem:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Povolíme tedy volbu
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Poznámka: podle poslední manuálové stránky existuje také příkaz cryptsetup refresh, kterým lze tyto volby povolit živě, aniž by bylo nutné šifrované zařízení „zavírat“ a „znovu otevírat“. Náš cryptsetup jej však zatím nepodporoval.
Ověření, zda byla volba skutečně povolena:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptAno, ve výstupu nyní vidíme same_cpu_crypt, což jsme chtěli. Zopakujme benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, nyní je to ~136 MB/s, což je o něco horší než předtím, takže nic dobrého. A co druhá možnost --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Možná jsme v „nějaké situaci“, takže ji vyzkoušíme:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusA nyní benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, což je o něco lepší, ale pořád nic moc…
Ptáme se komunity
Jako zoufalí jsme se rozhodli hledat podporu na internetu a napsali jsme naše zjištění do konference dm-crypt, ale reakce, kterou jsme dostali, nebyla příliš povzbudivá:
Pokud vás čísla znepokojují, pak je to z nepochopení na vaší straně. Pravděpodobně si neuvědomujete, že šifrování je těžkotonážní operace…
Rozhodli jsme se provést vědecký výzkum na toto téma zadáním „is encryption expensive“ do vyhledávače Google a jedním z nejlepších výsledků, který skutečně obsahuje smysluplná měření, je… náš vlastní příspěvek o nákladech na šifrování, ale v kontextu TLS! Je to fascinující čtení samo o sobě, ale podstata je následující: moderní šifrování na moderním hardwaru je velmi levné i v měřítku Cloudflare (provádí miliony šifrovaných požadavků HTTP za sekundu). Ve skutečnosti je tak levná, že Cloudflare byl prvním poskytovatelem, který nabídl SSL/TLS zdarma pro všechny.
Hloubání ve zdrojovém kódu
Při pokusu o použití výše popsaných vlastních možností dm-crypt nás zajímalo, proč vůbec existují a co je to vlastně za „offloading“. Původně jsme očekávali, že dm-crypt bude jednoduchý „proxy“, který pouze zašifruje/dešifruje data při jejich průchodu zásobníkem. Ukázalo se, že dm-crypt toho dělá víc než jen šifrování paměťových bufferů, a níže je uveden (zjednodušený) diagram cesty IO:

Když souborový systém vydá požadavek na zápis, dm-crypt ho nezpracuje okamžitě – místo toho ho zařadí do pracovní fronty s názvem „kcryptd“. Stručně řečeno, pracovní fronta jádra pouze naplánuje nějakou práci (v tomto případě šifrování), která bude provedena později, až to bude vhodnější. Když „ten čas“ nastane, dm-crypt odešle požadavek na Linux Crypto API pro skutečné šifrování. Moderní Linux Crypto API je však také asynchronní, takže v závislosti na tom, jakou konkrétní implementaci bude váš systém používat, nebude s největší pravděpodobností zpracován okamžitě, ale bude opět zařazen do fronty na „pozdější dobu“. Když Linux Crypto API konečně provede šifrování, může se dm-crypt pokusit roztřídit čekající požadavky na zápis tak, že jednotlivé požadavky zařadí do červeno-černého stromu. Pak samostatné vlákno jádra opět „někdy později“ skutečně vezme všechny IO požadavky ve stromu a pošle je dolů po zásobníku.
Nyní pro požadavky na čtení: tentokrát potřebujeme nejprve získat zašifrovaná data z hardwaru, ale dm-crypt se na data nezeptá jen ovladače, ale zařadí požadavek do jiné pracovní fronty s názvem „kcryptd_io“. V určitém okamžiku později, až budeme mít šifrovaná data skutečně k dispozici, naplánujeme jejich dešifrování pomocí již známé pracovní fronty „kcryptd“. „kcryptd“ odešle požadavek na Linux Crypto API, které může data dešifrovat i asynchronně.
Pro spravedlnost je třeba říci, že požadavek ne vždy prochází všemi těmito frontami, ale důležité zde je, že požadavky na zápis mohou být zařazeny do fronty dm-crypt až 4krát a požadavky na čtení až 3krát. V tuto chvíli nás zajímalo, zda toto dodatečné řazení do fronty může způsobit nějaké problémy s výkonem. Existuje například pěkná prezentace společnosti Google o vztahu mezi řazením do fronty a zpožděním na konci fronty. Jeden z klíčových poznatků z prezentace zní:
Významná část tail latence je způsobena queueing efekty
Takže, proč tam všechny ty fronty jsou a můžeme je odstranit?“
Archeologie systému Git
Nikdo nepíše složitější kód jen tak pro zábavu, zejména pro jádro OS. Takže všechny ty fronty tam musely být umístěny z nějakého důvodu. Naštěstí jsou zdrojové kódy linuxového jádra spravovány gitem, takže se můžeme pokusit dohledat změny a rozhodnutí kolem nich.
Pracovní fronta „kcryptd“ byla ve zdrojových kódech od počátku dostupné historie s následujícím komentářem:
Uvedeno proto, že by bylo velmi nerozumné provádět dešifrování v kontextu přerušení, takže bios vracející se z požadavků na čtení se řadí sem.
Takže to bylo jen pro čtení, ale i tak – proč se staráme o to, jestli je to v kontextu přerušení nebo ne, když linuxové Crypto API stejně bude pravděpodobně používat pro šifrování vyhrazené vlákno/kolej? No, v roce 2005 nebylo Crypto API asynchronní, takže to dávalo smysl.
V roce 2006 dm-crypt se začalo používat pracovní fronta „kcryptd“ nejen pro šifrování, ale i pro odesílání IO požadavků:
Tento patch je navržen tak, aby pomohl dm-crypt vyhovět novým omezením zavedeným následujícím patchem v -mm: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Zdá se, že cílem zde nebylo přidat více souběžnosti, ale spíše snížit využití zásobníku jádra, což opět dává smysl, protože jádro má společný zásobník pro celý kód, takže je to poměrně omezený zdroj. Stojí však za zmínku, že zásobník linuxového jádra byl v roce 2014 rozšířen pro platformy x86, takže by to již nemusel být problém.
První verze workqueue „kcryptd_io“ byla přidána v roce 2007 se záměrem zabránit:
hladovění způsobenému mnoha požadavky čekajícími na alokaci paměti…
Zpracování požadavků zde bylo úzkým hrdlem jediného workqueue, takže řešením bylo přidání dalšího. To dává smysl.
Nejsme rozhodně první, kdo zažívá snížení výkonu kvůli rozsáhlému řazení do fronty: v roce 2011 byla zavedena změna, která podmíněně vrátila část řazení do fronty pro požadavky na čtení:
Pokud je dostatek paměti, může kód přímo odeslat bio místo toho, aby tuto operaci řadil do fronty v samostatném vlákně.
Naneštěstí v té době nebyly zprávy o revizi linuxového jádra tak slovní jako dnes, takže nejsou k dispozici žádné údaje o výkonu.
V roce 2015 začal dm-crypt řadit zápisy v samostatném vlákně „dmcrypt_write“ před jejich odesláním na zásobník:
Na víceprocesorovém stroji končí požadavky na šifrování v jiném pořadí, než byly odeslány. V důsledku toho by se požadavky na zápis odesílaly v jiném pořadí, což by mohlo způsobit vážné snížení výkonu.
Dává to smysl, protože sekvenční přístup na disk býval mnohem rychlejší než náhodný a dm-crypt tento vzor porušoval. Ale to se týká hlavně točivých disků, které byly v roce 2015 ještě dominantní. U moderních rychlých SSD (včetně NVME SSD) to nemusí být tak důležité.
Další část zprávy o revizi stojí za zmínku:
…zejména umožňuje plánovačům IO jako CFQ efektivněji třídit…
Zmiňuje se o výkonnostních výhodách pro plánovač IO CFQ, ale plánovače v Linuxu se od té doby zlepšily natolik, že plánovač CFQ byl v roce 2018 z jádra odstraněn.
Tentýž patchset nahrazuje třídicí seznam červeno-černým stromem:
Teoreticky by měl třídění provádět základní plánovač disku, v praxi však plánovač disku přijímá a třídí pouze konečný počet požadavků. Aby bylo možné třídit všechny požadavky, musí dm-crypt implementovat vlastní třídění.
Režie spojená s tříděním na základě rbtree je považována za zanedbatelnou, takže se podmíněně nepoužívá.
Všechno to dává smysl, ale bylo by dobré mít nějaká záložní data.
Zajímavé je, že ve stejném souboru patchů vidíme zavedení nám známé volby „submit_from_crypt_cpus“:
Existují situace, kdy odlehčení biosu zápisu ze šifrovacích vláken na jedno vlákno výrazně snižuje výkon
Celkově vidíme, že každá změna byla rozumná a potřebná, nicméně věci se od té doby změnily:
- hardware se stal rychlejším a chytřejším
- Přehodnotilo se přidělování prostředků v Linuxu
- přehodnotily se propojené subsystémy Linuxu
A mnoho z výše uvedených návrhových rozhodnutí nemusí být pro moderní Linux použitelné.
„Vyčištění“
Na základě výše uvedeného výzkumu jsme se rozhodli pokusit se odstranit veškeré dodatečné řazení do front a asynchronní chování a vrátit se dm-crypt k původnímu účelu: jednoduše šifrovat/dešifrovat IO požadavky při jejich průchodu. Kvůli stabilitě a dalším srovnávacím testům jsme však nakonec neodstranili skutečný kód, ale přidali jsme další volbu dm-crypt, která obchází všechny fronty/vlákna, pokud je povolena. Tento příznak nám umožňuje přepínat mezi současným a novým chováním za běhu při plném produkčním zatížení, takže můžeme naše změny snadno vrátit, pokud bychom zaznamenali nějaké vedlejší účinky. Výsledný patch najdete v linuxovém repozitáři Cloudflare GitHub.
Synchronní linuxové kryptografické API
Z výše uvedeného diagramu si pamatujeme, že ne všechny fronty jsou implementovány v dm-crypt. Moderní Linux Crypto API může být také asynchronní a pro účely tohoto experimentu chceme fronty eliminovat i tam. Co však znamená „může být“? Operační systém může obsahovat různé implementace téhož algoritmu (například hardwarově akcelerovaný AES-NI na platformách x86 a obecnou implementaci AES v kódu C). Ve výchozím nastavení systém vybere tu „nejlepší“ na základě nakonfigurované priority algoritmu. dm-crypt umožňuje toto chování obejít a vyžádat si konkrétní implementaci šifry pomocí předpony capi:. Je zde však jeden problém. Zkontrolujme vlastně dostupné implementace AES-XTS (to je naše šifra pro šifrování disku, pamatujete?) v našem systému:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64Chceme explicitně vybrat synchronní šifru z výše uvedeného seznamu, abychom se vyhnuli efektům fronty ve vláknech, ale jediné dvě podporované jsou xts(ecb(aes-generic)) (obecná implementace C) a __xts-aes-aesni (hardwarově akcelerovaná implementace x86). Rozhodně chceme druhou jmenovanou, protože je mnohem rychlejší (jde nám o výkon), ale je podezřele označena jako interní (viz internal: yes). Pokud se podíváme do zdrojového kódu:
Označte šifru jako servisní implementaci použitelnou pouze jinou šifrou a nikdy ne běžným uživatelem jaderného kryptografického API
Tato šifra má být tedy použita pouze jiným obalovým kódem v kryptografickém API a ne mimo něj. V praxi to znamená, že volající Crypto API musí tento příznak explicitně zadat, když požaduje konkrétní implementaci šifry, ale dm-crypt to nedělá, protože podle návrhu není součástí linuxového Crypto API, spíše „vnějším“ uživatelem. Modul dm-crypt již opravujeme, takže bychom mohli rovnou přidat příslušný příznak. Zejména u AES-NI však existuje další problém: x86 FPU. Říkáte „plovoucí desetinná čárka“? Proč potřebujeme matematiku s plovoucí desetinnou čárkou k symetrickému šifrování, které by mělo být jen o bitových posunech a operacích XOR? Matematiku nepotřebujeme, ale instrukce AES-NI využívají některé registry procesoru, které jsou vyhrazeny pro FPU. Bohužel jádro Linuxu tyto registry z výkonnostních důvodů ne vždy zachovává v kontextu přerušení (ukládání/obnovování FPU je drahé). dm-crypt Může však dojít k provedení kódu v kontextu přerušení, takže riskujeme poškození dat nějakého jiného procesu a vracíme se k tvrzení „bylo by velmi nerozumné provádět dešifrování v kontextu přerušení“ v původním kódu.
Naším řešením výše uvedeného bylo vytvoření dalšího poněkud „inteligentního“ modulu Crypto API. Tento modul je synchronní a neprovádí vlastní šifrování, ale je pouze „směrovačem“ požadavků na šifrování:
- pokud můžeme použít FPU (a tedy AES-NI) v aktuálním kontextu provádění, prostě požadavek na šifrování přepošleme rychlejší, „interní“ implementaci
__xts-aes-aesni(a můžeme ji použít zde, protože nyní jsme součástí rozhraní Crypto API) - v opačném případě prostě předáme požadavek na šifrování pomalejší, obecné implementaci
xts(ecb(aes-generic))založené na jazyce C
Používáme celou řadu
Projdeme procesem použití všeho dohromady. Prvním krokem je pořízení patchů a překompilování jádra (nebo jen zkompilování dm-crypt a našich modulů xtsproxy).
Následujícím krokem bude restartování naší IO zátěže v samostatném terminálu, abychom se mohli ujistit, že můžeme jádro překonfigurovat za běhu pod zátěží:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...V hlavním terminálu se ujistěte, že je náš nový modul Crypto API načten a dostupný:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Překonfigurujte šifrovaný disk tak, aby používal náš nově načtený modul, a povolte náš opravený příznak dm-crypt (musíme použít nízkoúrovňový nástroj dmsetup, protože cryptsetup o našich úpravách zřejmě neví):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Právě jsme „načetli“ novou konfiguraci, ale aby se projevila, musíme šifrované zařízení pozastavit/obnovit:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0A nyní pozorujte výsledek. Můžeme se vrátit do druhého terminálu, kde běží úloha fio, a podívat se na výstup, ale aby to bylo hezčí, zde je snímek pozorované propustnosti čtení/zápisu v Grafana:
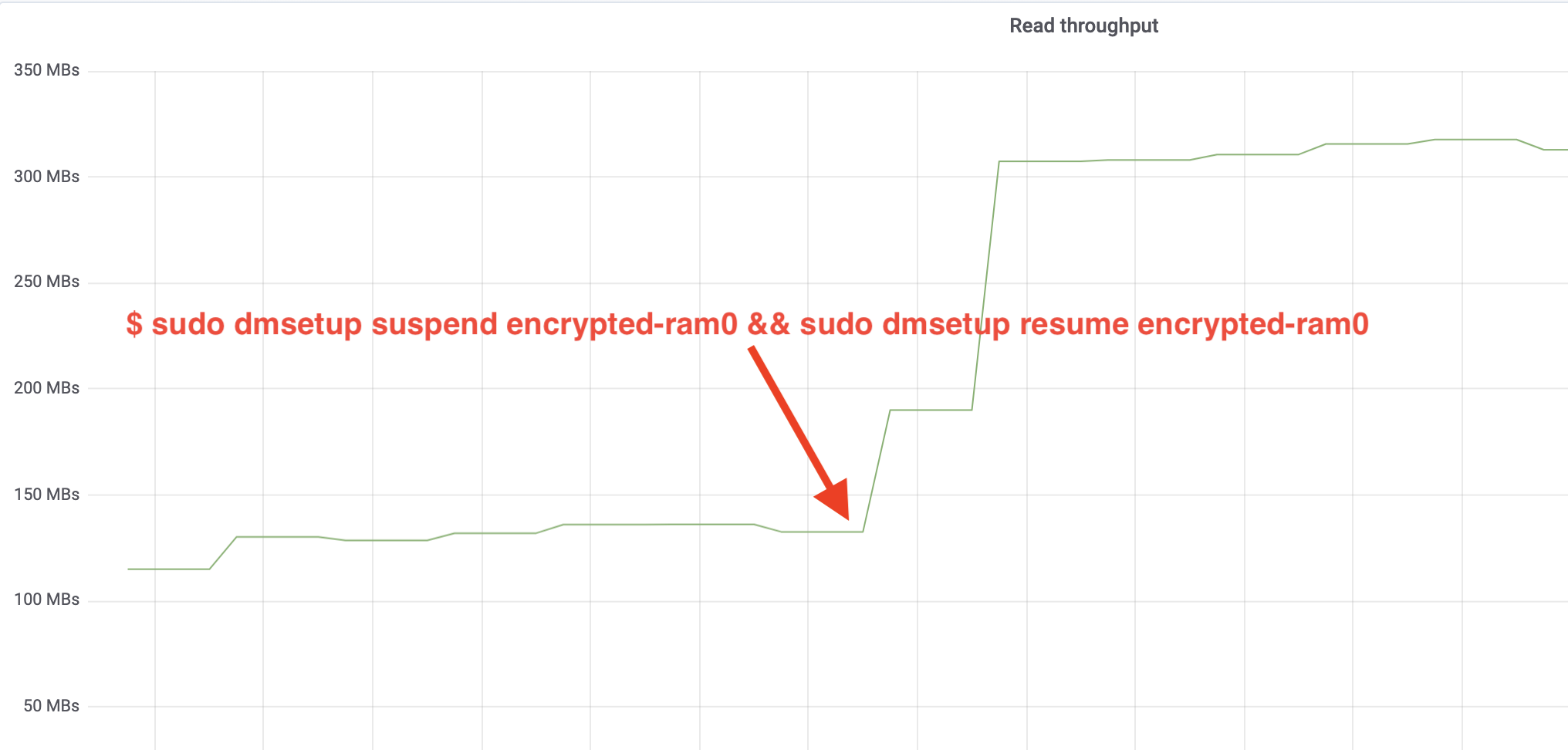
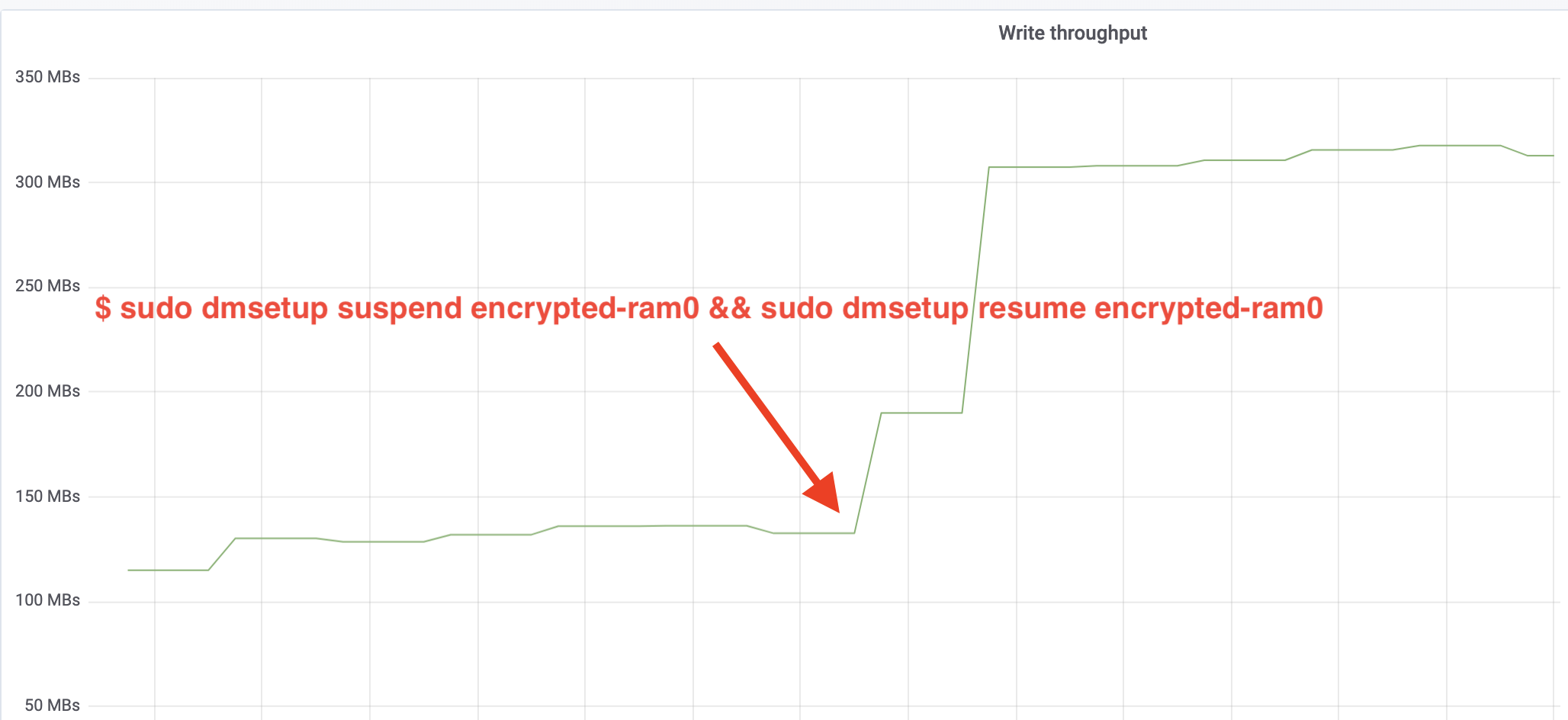
Páni, propustnost jsme více než zdvojnásobili! S celkovou propustností ~640 MB/s jsme nyní mnohem blíže očekávané hodnotě ~696 MB/s z výše uvedeného. A co latence IO? (Statistika await z reportovacího nástroje iostat):
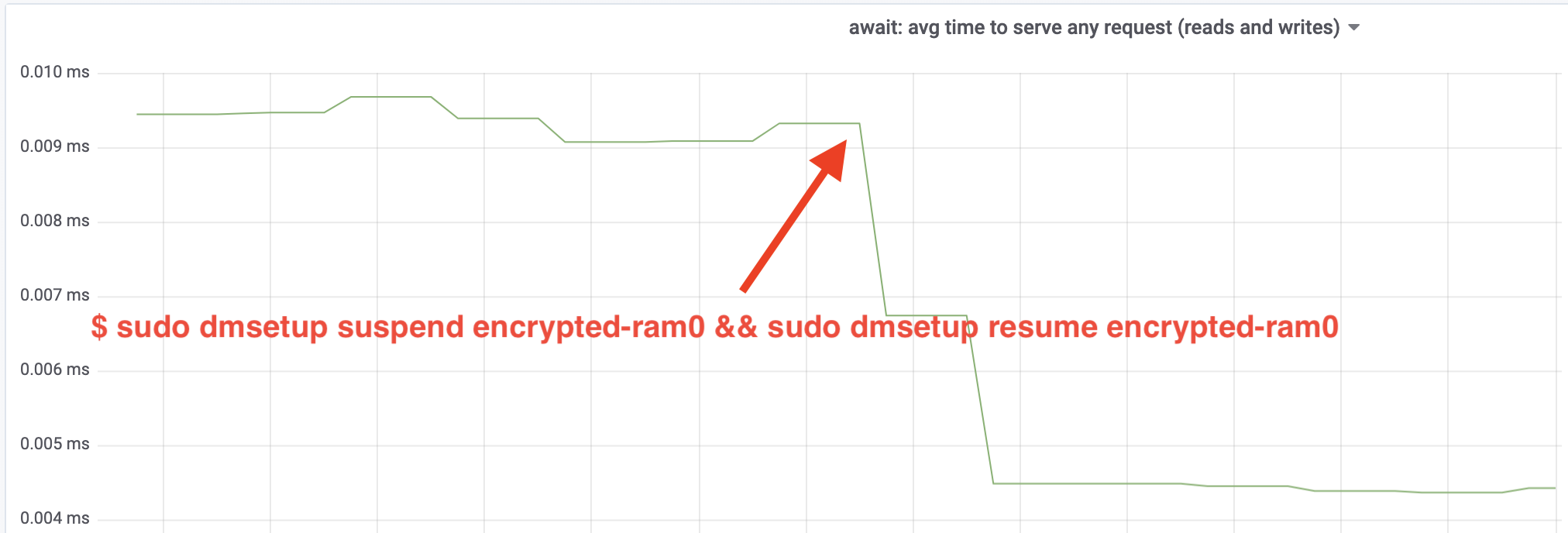
Také latence se snížila na polovinu!!!
Do produkce
Dosud jsme používali syntetické nastavení, ve kterém chyběly některé části plného produkčního zásobníku, jako jsou souborové systémy, skutečný hardware a hlavně produkční zátěž. Abychom se ujistili, že neoptimalizujeme vymyšlené věci, zde je snímek produkčního dopadu, který tyto změny přinášejí do části našeho zásobníku pro ukládání do mezipaměti:

Tento graf představuje třístranné srovnání nejhorších časů odezvy (99. percentil) pro zásah do mezipaměti v jednom z našich serverů. Zelená čára je ze serveru s nešifrovanými disky, který použijeme jako výchozí. Červená čára je ze serveru se šifrovanými disky s výchozí implementací šifrování disků v systému Linux a modrá čára je ze serveru se šifrovanými disky a zapnutými našimi optimalizacemi. Jak vidíme, výchozí implementace šifrování disků v systému Linux má v nejhorších scénářích významný dopad na latenci naší mezipaměti, zatímco opravená implementace je k nerozeznání od nepoužití šifrování vůbec. Jinými slovy, vylepšená implementace šifrování nemá na rychlost odezvy naší mezipaměti vůbec žádný vliv, takže ji v podstatě dostáváme zdarma! To je výhra!
Jsme teprve na začátku
Tento příspěvek ukazuje, jak může revize architektury zdvojnásobit výkon systému. Také jsme si znovu potvrdili, že moderní kryptografie není drahá a většinou neexistuje výmluva, proč nechránit svá data.
Chystáme se tuto práci předložit k zařazení do hlavního zdrojového stromu jádra, ale s největší pravděpodobností ne v současné podobě. Přestože výsledky vypadají povzbudivě, musíme mít na paměti, že Linux je vysoce přenosný operační systém: běží na výkonných serverech i na malých zařízeních internetu věcí s omezenými zdroji a také na mnoha dalších architekturách procesorů. Současná verze záplat pouze optimalizuje šifrování disků pro konkrétní pracovní zátěž na konkrétní architektuře, ale Linux potřebuje řešení, které poběží bez problémů všude.
Pokud si myslíte, že váš případ je podobný a chcete využít zlepšení výkonu již nyní, můžete si záplaty vzít a doufejme, že poskytnete zpětnou vazbu. Příznak runtime umožňuje snadno přepínat funkčnost za běhu a lze provést jednoduchý A/B test, aby se zjistilo, zda je to pro nějaký konkrétní případ nebo nastavení výhodné. Tyto opravy byly spuštěny v naší široké síti více než 200 datových center na pěti generacích hardwaru, takže je lze přiměřeně považovat za stabilní. Užijte si výkon i zabezpečení od společnosti Cloudflare pro všechny!

Aktualizace (11. října 2020)
Hlavní záplata z tohoto blogu (v mírně aktualizované podobě) byla začleněna do hlavní řady linuxového jádra a je k dispozici od verze 5.9 a dále. Hlavním rozdílem je, že mainline verze vystavuje dva příznaky místo jednoho, které poskytují možnost obejít pracovní fronty dm-crypt pro čtení a zápis nezávisle. Podrobnosti naleznete v oficiální dokumentaci k dm-crypt.