Úvod
Pokud analyzujete data pomocí vícenásobné regrese a některá z vašich nezávislých proměnných byla měřena na nominální nebo ordinální stupnici, musíte vědět, jak vytvořit fiktivní proměnné a interpretovat jejich výsledky. Je to proto, že nominální a ordinální nezávislé proměnné, obecněji známé jako kategoriální nezávislé proměnné, nelze přímo zadat do vícenásobné regresní analýzy. Místo toho je třeba je převést na dummy proměnné. Výjimkou jsou ordinální nezávislé proměnné, které se do vícenásobné regrese zadávají jako spojité nezávislé proměnné, které není třeba převádět na dummy proměnné. Proto si v této příručce ukážeme, jak vytvořit fiktivní proměnné, když máte kategoriální nezávislé proměnné.
Nejprve uvedeme příklad, na kterém si ukážeme, jak vytvořit fiktivní proměnné v programu SPSS Statistics, a poté vysvětlíme, jak nastavit data v oknech Variable View a Data View programu SPSS Statistics, abyste mohli vytvořit fiktivní proměnné. Pokud nejste obeznámeni s používáním fiktivních proměnných, doporučujeme vám, abyste si poté přečetli některé základní principy fiktivních proměnných a kódování fiktivních proměnných, včetně: (a) počtu fiktivních proměnných, které je třeba v analýze vytvořit, a (b) způsobu vytváření fiktivních proměnných a kódování fiktivních proměnných. V následující části Postup uvádíme jednoduchý tříkrokový postup Vytvořit dummy proměnné v programu SPSS Statistics, který lze použít k vytvoření dummy proměnných. Nakonec vysvětlíme výstup programu SPSS Statistics po spuštění procedury Create Dummy Variables, včetně toho, jak budou nyní vaše fiktivní proměnné nastaveny v oknech Variable View a Data View programu SPSS Statistics.
Poznámka: Pokud zjistíte, že postupy v této příručce nepokrývají typ fiktivních proměnných, které chcete vytvořit, kontaktujte nás. Možná budeme moci na stránky přidat dalšího průvodce, který vám pomůže.
SPSS Statistics
Příklad použitý v této příručce
V této příručce použijeme příklad 10 triatlonistů, kteří byli požádáni, aby vybrali svůj oblíbený sport ze tří sportů, které provozují při triatlonu: plavání, jízda na kole a běh. Jejich odpovědi byly zaznamenány do nominální nezávislé proměnné favourite_sport, která má tři kategorie: „plavání“, „cyklistika“ a „běh“. Tato nominální nezávislá proměnná, favourite_sport, měla být zahrnuta do vícenásobné regresní analýzy, která měla také řadu spojitých nezávislých proměnných. Protože tato nezávislá proměnná byla kategoriální (tj. nominální proměnné a ordinální proměnné lze obecně klasifikovat jako kategoriální proměnné), musely být před jejím zařazením do vícenásobné regresní analýzy vytvořeny dummy proměnné.
Důležité: Všimněte si, že favorite_sport je nominální proměnná, ale dummy proměnné můžete vytvořit i pro ordinální proměnnou. Kromě toho je postup vytváření dummy proměnných stejný bez ohledu na to, zda máte ordinální nebo nominální proměnnou, s výjimkou jedné malé změny, kterou musíte provést při nastavování dat a která je vysvětlena níže.
Poznámka 1: „Kategorie“ kategoriální nezávislé proměnné se také označují jako „skupiny“ nebo „úrovně“, ale termín „úrovně“ je obvykle vyhrazen pro kategorie, které mají pořadí (např. ordinální nezávislá proměnná „úroveň fyzické zdatnosti“ může mít tři úrovně: „nízká“, „střední“ a „vysoká“). Tyto tři termíny – „kategorie“, „skupiny“ a „úrovně“ – však lze používat zaměnitelně. V této příručce je budeme označovat jako kategorie, ale pokud chcete, můžete je označovat jako skupiny nebo úrovně.
Poznámka 2: Místo termínu „kategoriální nezávislé proměnné“ (tj. nezávislé proměnné, které jsou „ordinální“ nebo „nominální“) se někdy používá termín „faktory“. Tyto dva termíny – „kategoriální nezávislé proměnné“ a „faktory“ – však lze používat zaměnitelně. V této příručce je budeme označovat jako kategoriální nezávislé proměnné a také v programu SPSS Statistics se setkáte s tím, že je ve své proceduře vícenásobné regrese označuje jako nezávislé proměnné, nikoli faktory. Pokud však chcete, můžete je označovat jako faktory.
SPSS Statistics
Nastavení dat v programu SPSS Statistics
Při vytváření fiktivních proměnných začnete s jednou kategoriální nezávislou proměnnou (např. oblíbený_sport). Pro nastavení této kategoriální nezávislé proměnné má program SPSS Statistics k dispozici Zobrazení proměnné, kde definujete typy analyzované proměnné, a Zobrazení dat, kam zadáváte data pro tuto proměnnou. V této části si nejprve ukážeme, jak nastavit kategoriální nezávislou proměnnou v okně Variable View programu SPSS Statistics, a poté si ukážeme, jak zadat data do okna Data View. Uděláme to pomocí naší kategoriální nezávislé proměnné favourite_sport, která má tři kategorie: „
Zobrazení proměnné v aplikaci SPSS Statistics
Pro jednu kategoriální nezávislou proměnnou (např, favourite_sport) bude vaše okno Zobrazení proměnné vypadat jako níže uvedené:
Poznámka: Do okna Zobrazení proměnné v programu SPSS Statistics se dostanete kliknutím na záložku ![]() v levém dolním rohu programu SPSS Statistics.
v levém dolním rohu programu SPSS Statistics.
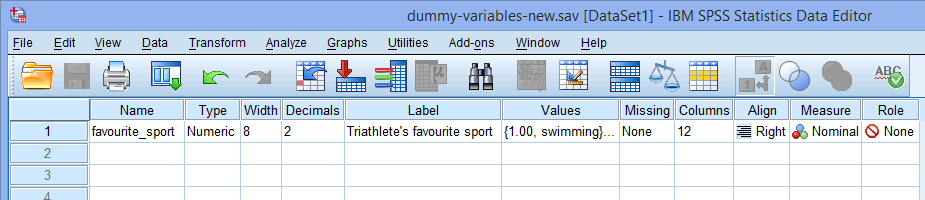
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Název vaší kategoriální nezávislé proměnné by měl být zadán do buňky pod sloupcem ![]() (např, „favourite_sport“ v řádku
(např, „favourite_sport“ v řádku ![]() , který představuje naši kategoriální nezávislou proměnnou favourite_sport. Existují určité „nepovolené“ znaky, které nelze do buňky
, který představuje naši kategoriální nezávislou proměnnou favourite_sport. Existují určité „nepovolené“ znaky, které nelze do buňky ![]() zadat. Pokud se vám tedy zobrazí chybové hlášení a budete chtít, abychom přidali průvodce programem SPSS Statistics, který vysvětlí, co jsou tyto nepovolené znaky, kontaktujte nás.
zadat. Pokud se vám tedy zobrazí chybové hlášení a budete chtít, abychom přidali průvodce programem SPSS Statistics, který vysvětlí, co jsou tyto nepovolené znaky, kontaktujte nás.
Poznámka: Pro vlastní přehlednost můžete ve sloupci ![]() uvést také označení svých proměnných. Například označení, které jsme zadali pro „favourite_sport“, bylo „Oblíbený sport triatlonisty“.
uvést také označení svých proměnných. Například označení, které jsme zadali pro „favourite_sport“, bylo „Oblíbený sport triatlonisty“.
Buňka pod sloupcem ![]() by měla obsahovat informace o kategoriích vaší kategorické nezávislé proměnné (např. pro favourite_sport „plavání“, „cyklistika“ a „běh“. Chcete-li tyto informace zadat, klikněte do buňky pod sloupcem
by měla obsahovat informace o kategoriích vaší kategorické nezávislé proměnné (např. pro favourite_sport „plavání“, „cyklistika“ a „běh“. Chcete-li tyto informace zadat, klikněte do buňky pod sloupcem ![]() pro vaši nezávislou proměnnou. V buňce se objeví tlačítko
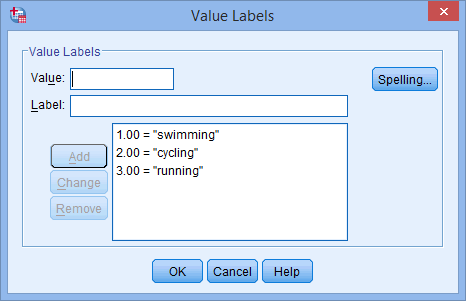
pro vaši nezávislou proměnnou. V buňce se objeví tlačítko ![]() . Klikněte na toto tlačítko a zobrazí se dialogové okno Označení hodnot. Nyní musíte každé kategorii vaší nezávislé proměnné přiřadit „hodnotu“, kterou zadáte do pole Value: (např. „1“), a také „popisek“, který zadáte do pole Label: (např. „plavání“). Po kliknutí na tlačítko
. Klikněte na toto tlačítko a zobrazí se dialogové okno Označení hodnot. Nyní musíte každé kategorii vaší nezávislé proměnné přiřadit „hodnotu“, kterou zadáte do pole Value: (např. „1“), a také „popisek“, který zadáte do pole Label: (např. „plavání“). Po kliknutí na tlačítko ![]() se v hlavním poli objeví kódování (např. „1,00=“plavání“ pro oblíbený_sport). Nastavení pro naši kategoriální nezávislou proměnnou je uvedeno v následujícím dialogovém okně Označení hodnot:
se v hlavním poli objeví kódování (např. „1,00=“plavání“ pro oblíbený_sport). Nastavení pro naši kategoriální nezávislou proměnnou je uvedeno v následujícím dialogovém okně Označení hodnot:
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Buňka pod sloupcem ![]() by měla zobrazovat
by měla zobrazovat ![]() , pokud máte nominální nezávislou proměnnou (např, favourite_sport, jako v našem příkladu) nebo
, pokud máte nominální nezávislou proměnnou (např, favourite_sport, jako v našem příkladu) nebo ![]() , pokud máte ordinální nezávislou proměnnou (např. představte si ordinální proměnnou jako „Body Mass Index“ (BMI), BMI), která má čtyři úrovně: „Podváha“, „Zdravá/normální hmotnost“, „Nadváha“ a „Obézní“). Nakonec by se v buňce pod sloupcem
, pokud máte ordinální nezávislou proměnnou (např. představte si ordinální proměnnou jako „Body Mass Index“ (BMI), BMI), která má čtyři úrovně: „Podváha“, „Zdravá/normální hmotnost“, „Nadváha“ a „Obézní“). Nakonec by se v buňce pod sloupcem ![]() mělo zobrazit
mělo zobrazit ![]() .
.
Poznámka: Doporučujeme změnit buňku pod sloupcem ![]() z
z ![]() na
na ![]() , ale tuto změnu nemusíte provádět. Doporučujeme vám to proto, že v programu SPSS Statistics existují určité analýzy, u nichž nastavení
, ale tuto změnu nemusíte provádět. Doporučujeme vám to proto, že v programu SPSS Statistics existují určité analýzy, u nichž nastavení ![]() vede k tomu, že se vaše proměnné automaticky přenesou do určitých polí dialogových oken, která používáte. Protože tyto proměnné možná nebudete chtít přenášet, doporučujeme změnit nastavení
vede k tomu, že se vaše proměnné automaticky přenesou do určitých polí dialogových oken, která používáte. Protože tyto proměnné možná nebudete chtít přenášet, doporučujeme změnit nastavení ![]() na
na ![]() , aby k tomu automaticky nedocházelo.
, aby k tomu automaticky nedocházelo.
V okně Variable View jste nyní úspěšně zadali všechny informace, které SPSS Statistics potřebuje vědět o vaší kategoriální nezávislé proměnné. V další části si ukážeme, jak zadat data do okna Zobrazení dat.
Zobrazení dat v programu SPSS Statistics
Na základě nastavení souboru pro vaši kategoriální nezávislou proměnnou ve výše uvedeném okně Zobrazení proměnné bude okno Zobrazení dat vypadat takto:
Poznámka: Do okna Zobrazení dat v programu SPSS Statistics se dostanete kliknutím na záložku ![]() v levém dolním rohu programu SPSS Statistics.
v levém dolním rohu programu SPSS Statistics.
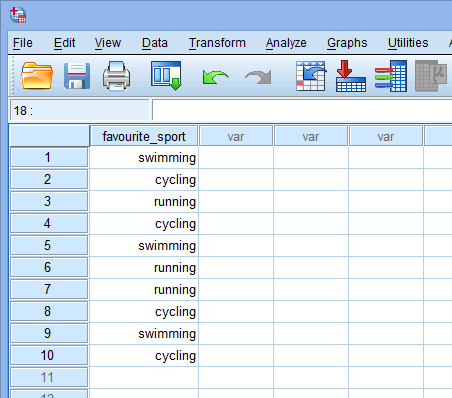
Publikováno s písemným svolením společnosti SPSS Statistics, IBM Corporation.
Vaše kategoriální nezávislá proměnná bude zobrazena v prvním sloupci, protože v tomto pořadí jsme proměnnou zadali do okna Variable View. V našem příkladu jsou odpovědi deseti triatlonistů uvedeny ve sloupci ![]() . Nyní stačí zadat údaje do buněk pod tímto prvním sloupcem. Nezapomeňte, že každý řádek představuje jeden případ (např. případem může být jeden účastník). V řádku
. Nyní stačí zadat údaje do buněk pod tímto prvním sloupcem. Nezapomeňte, že každý řádek představuje jeden případ (např. případem může být jeden účastník). V řádku ![]() našeho příkladu tedy první případ představoval triatlonistu, jehož oblíbeným sportem bylo „plavání“. Protože tyto buňky budou zpočátku prázdné, musíte do nich kliknout a zadat údaje. Všimněte si, že po kliknutí do buněk pod sloupcem
našeho příkladu tedy první případ představoval triatlonistu, jehož oblíbeným sportem bylo „plavání“. Protože tyto buňky budou zpočátku prázdné, musíte do nich kliknout a zadat údaje. Všimněte si, že po kliknutí do buněk pod sloupcem ![]() vám SPSS Statistics nabídne rozbalovací nabídku s již vyplněnými kategoriemi.
vám SPSS Statistics nabídne rozbalovací nabídku s již vyplněnými kategoriemi.
Teď, když jste nastavili svá data v oknech Variable View a Data View programu SPSS Statistics, doporučujeme přečíst si další část: V této části vysvětlíme základní principy fiktivních proměnných a fiktivního kódování. Pokud jste však již se základy dummy proměnných a dummy kódování obeznámeni, můžete tuto část přeskočit a přejít rovnou k části Postup, kde uvádíme postup Vytvořit dummy proměnné v aplikaci SPSS Statistics, který se používá k vytváření dummy proměnných.
SPSS Statistics
Pochopení fiktivních proměnných a kódování fiktivních proměnných
Jak jsme se zmínili v úvodu, pokud analyzujete svá data pomocí vícenásobné regrese a některá z vašich nezávislých proměnných byla měřena na nominální nebo ordinální stupnici, musíte vědět, jak vytvořit fiktivní proměnné a interpretovat jejich výsledky. Je to proto, že kategoriální nezávislé proměnné (tj. nominální a ordinální nezávislé proměnné) nelze přímo zadat do vícenásobné regrese. Místo toho je třeba je převést na dummy proměnné. Výjimkou jsou ordinální nezávislé proměnné, které se do vícenásobné regrese zadávají jako spojité nezávislé proměnné, které není třeba převádět na dummy proměnné. V následujících částech vysvětlíme: (a) počet fiktivních proměnných, které je třeba vytvořit, a b) způsob vytváření fiktivních proměnných a kódování fiktivních proměnných.
Počet fiktivních proměnných, které je třeba vytvořit
Počet fiktivních proměnných, které je třeba vytvořit, závisí na tom, kolik kategorií má vaše kategoriální nezávislá proměnná. Obecně platí, že vytvoříte o jednu fiktivní proměnnou méně, než je počet kategorií ve vaší kategoriální nezávislé proměnné. Máte-li například kategoriální nezávislou proměnnou se třemi kategoriemi (např. oblíbený_sport s těmito třemi kategoriemi: „plavání“, „cyklistika“ a „běh“), vytvoříte dvě fiktivní proměnné a jednu kategorii vyberete jako referenční kategorii (např. „plavání“ a „cyklistika“ se stanou fiktivními proměnnými a „běh“ se stane referenční kategorií). Více o referenčních kategoriích vysvětlíme za následující tabulkou, která uvádí několik příkladů kategoriálních nezávislých proměnných a počet fiktivních proměnných, které je třeba vytvořit:
| Název kategoriální nezávislé proměnné | Typ proměnné | Počet kategorií | Počet tzv. fiktivní proměnné | ||||
|---|---|---|---|---|---|---|---|
| 1 | Pohlaví | Nominální | Dvě (Muži &Ženy) |
Jedna=Muži „Ženy“ je referenční kategorie |
|||
| 2 | Výška | Ordinální | Dvě (Pod 180cm & 180cm a více) |
Jedna=Pod. 180cm „180cm a více“ je referenční kategorie |
|||
| 3 | Etnicita | Nominální | Tři (Afroameričané, Kavkazan & Hispánec) |
Dvě=Afroameričan & Kavkazan „Hispánec“ je referenční kategorie |
|||
| 4 | Úroveň fyzické aktivity | Ordinální | Tři (Nízká, Střední & Vysoká) |
Dvě=Nízká & Střední „Vysoká“ je referenční kategorie |
|||
| 5 | Profese | Nominální | Čtvrtá (Chirurg, Lékař, Zdravotní sestra & Terapeut) |
Tři=Chirurg, Lékař & Zdravotní sestra „Terapeut“ je referenční kategorie |
|||
| 6 | Úroveň souhlasu | Ordinální | Čtyři (Rozhodně souhlasím, Souhlasím, Nesouhlasím, Silně nesouhlasím) |
Tři=Silně souhlasím, Souhlasím & Nesouhlasím „Silně nesouhlasím“ je referenční kategorie |
|||
| 7 | Oblast | Nominální | Pět (Obchodní studia, Psychologie, Biologické vědy, Technické vědy & Právo) |
Čtyři=Obchodní studia, Psychologie, Biologické vědy & Technické vědy „Právo“ je referenční kategorie |
|||
| 8 | Věk | Odborný | Pět (Do 18 let, 19-30, 31-40, 41-50, 51-60) |
Čtyři=Mladší 18 let, 19-30, 31-40 & 41-50 „51-60“ je referenční kategorie |
|||
| Tabulka: Příklady kategoriálních nezávislých proměnných a jejich příslušných fiktivních proměnných | |||||||
Jak je uvedeno v tabulce výše, stačí vytvořit o jednu fiktivní proměnnou méně, než je počet kategorií ve vaší kategoriální nezávislé proměnné. Je to proto, že tento počet fiktivních proměnných musíte (a měli byste) převést do vícenásobné regrese pouze v případě, že máte kategoriální nezávislou proměnnou. Existují však dobré důvody, proč vytvořit fiktivní proměnnou pro každou kategorii kategoriální nezávislé proměnné: (a) je to flexibilnější a (b) umožňuje to provádět vícenásobná srovnání (viz poznámka níže). Jinými slovy, pokud má vaše kategoriální nezávislá proměnná tři kategorie, měli byste vytvořit tři dummy proměnné, nikoli pouze dvě.
Naštěstí procedura Create Dummy Variables v programu SPSS Statistics verze 22 a vyšší automaticky vytvoří dummy proměnnou pro každou kategorii vaší kategoriální nezávislé proměnné. To však neplatí pro postup Rekódování do různých proměnných v programu SPSS Statistics verze 21 nebo starší. Za normálních okolností tedy budete mít v programu SPSS Statistics vytvořeno následující nastavení v závislosti na tom, zda máte verzi 21 nebo starší, nebo verzi 22 a vyšší:
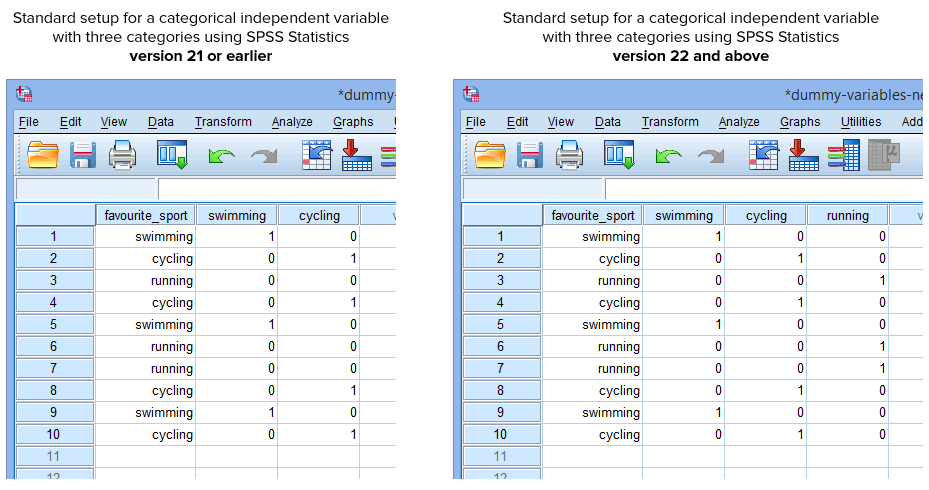
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Poznámka: Jak bylo uvedeno výše, vytvoření dummy proměnné pro každou kategorii kategoriální nezávislé proměnné je výhodné ze dvou důvodů: (a) je flexibilnější a (b) umožňuje provádět vícenásobná srovnání. Těchto výhod se stručně dotkneme níže:
Je flexibilnější:
Pokud jste vytvořili dummy proměnnou pro každou kategorii vaší kategoriální nezávislé proměnné, můžete pak považovat jakoukoli kategorii za referenční kategorii. V našem příkladu jsme za referenční kategorii považovali kategorii „běh“, což znamená, že bychom do rovnice vícenásobné regrese převedli kategorie „plavání“ a „jízda na kole“. Pokud bychom si však později výběr referenční kategorie rozmysleli, museli bychom postup s fiktivní proměnnou provést znovu (pokud nemáte program SPSS Statistics verze 22 nebo vyšší). Předpokládejme například, že nyní chceme za referenční kategorii považovat kategorii „cyklistika“. Nyní bychom mohli do rovnice vícenásobné regrese přenést dummy proměnné „plavání“ a „běh“, protože máme k dispozici také dummy proměnnou „běh“.
To umožňuje provádět vícenásobná srovnání:
Koeficient dummy proměnné představuje rozdíl mezi kategorií, kterou dummy proměnná reprezentuje, a referenční kategorií. Například při referenční kategorii „běh“ představuje koeficient dummy proměnné „plavání“ rozdíl v závislé proměnné mezi kategoriemi „plavání“ a „běh“. Při použití této metody nebudou možné všechny kombinace kategorií. Tento problém lze vyřešit použitím různých referenčních kategorií. To je možné, pokud všechny kategorie kategoriální proměnné mají dummy proměnnou.
Jak vytvořit dummy proměnné a dummy kódování
Pro úspěšné nastavení dummy proměnných ve vícenásobné regresi existují dva kroky: (1) vytvořte fiktivní proměnné, které představují kategorie vaší kategoriální nezávislé proměnné, a (2) zadejte do těchto fiktivních proměnných hodnoty – tzv. kódování fiktivních proměnných – které představují kategorie vaší kategoriální nezávislé proměnné. Tento postup vysvětlíme níže na příkladu, který jsme uvedli výše.
Vysvětlení: Dummy proměnné jsou jednoduše nové proměnné, které slouží jako „zástupné znaky“ pro určité kódovací schéma. Samy o sobě neobsahují vůbec žádné údaje. Místo toho je třeba k těmto fiktivním proměnným přidat údaje/hodnoty, aby mohly plnit svůj účel reprezentovat kategorie vaší kategoriální nezávislé proměnné. Existuje mnoho různých typů kódovacích schémat, která budou diktovat hodnoty, které se do fiktivních proměnných zadávají, ale my používáme velmi běžné kódovací schéma, které se nazývá fiktivní kódování nebo případně kódování indikátorů (N.B., nenechte se zmást, protože fiktivní proměnné a fiktivní kódování nejsou totéž). Dummy kódování funguje tak, že každá dummy proměnná slouží k identifikaci konkrétní kategorie kategoriální nezávislé proměnné s výjimkou referenční kategorie, kterou vysvětlíme níže.
Začněme tím, že vezmeme v úvahu naši příkladovou kategoriální nezávislou proměnnou, oblíbený_sport, která má tři kategorie: „plavání“, „jízda na kole“ a „běh“. Protože existují tři kategorie, je třeba mít dvě fiktivní proměnné reprezentující dvě z kategorií a referenční kategorii reprezentující třetí kategorii.
Poznámka: Z výše uvedené diskuse si pamatujte, že vícenásobná regrese vyžaduje, abyste převedli o jednu fiktivní proměnnou méně, než je počet kategorií ve vaší kategoriální nezávislé proměnné (tj. v našem příkladu dvě). Můžete však vytvořit dummy proměnnou pro každou kategorii kategoriální nezávislé proměnné pro účely větší flexibility a možnosti provádět vícenásobná srovnání. Nicméně v následující diskusi zdůrazníme pouze to, co je nutné pro vícenásobnou regresi, tj. vytvoření o jednu dummy proměnnou méně, než je počet kategorií ve vaší kategoriální nezávislé proměnné, přičemž kategorie, která není přímo zastoupena, se stane „referenční kategorií“.
Například nechť dummy proměnná č. 1 představuje kategorii „plavání“ a dummy proměnná č. 2 kategorii „cyklistika“. Tím nezůstane žádná dummy proměnná pro kategorii „běh“. Tato „chybějící“ kategorie je referenční kategorií a není potřeba. Kromě toho záleží pouze na vašem rozhodnutí, kterou kategorii chcete použít jako referenční kategorii. Stejně dobře jsme mohli jako referenční kategorii zvolit kategorii „plavání“ a ne kategorii „běh“. Jediný důvod, proč jsme to neudělali, je ten, že ve výchozím nastavení používá SPSS Statistics jako referenční kategorii poslední kategorii, kterou jste zakódovali v Zobrazení proměnné pro vaši kategoriální nezávislou proměnnou (viz poznámka níže).
Poznámka: Jak bylo vysvětleno v předchozí části Nastavení dat a jak je uvedeno níže v dialogovém okně Označení hodnot, třetí a poslední kategorií naší kategoriální nezávislé proměnné byl „běh“ (tj, 3=“běh“).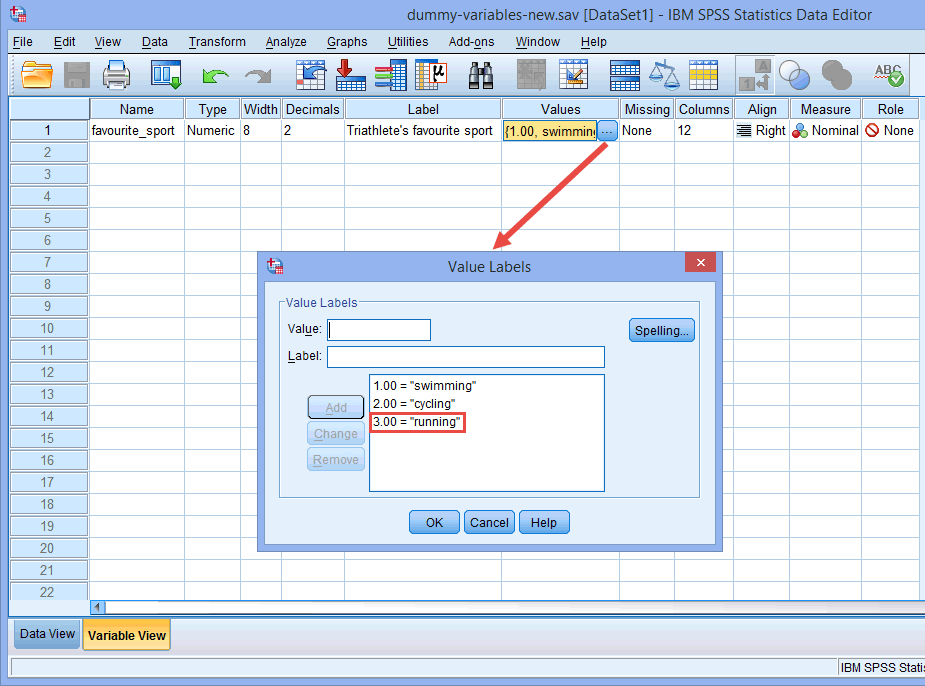
Neexistoval žádný teoretický ani statistický důvod, abychom z kategorie „běh“ udělali třetí a poslední kategorii, což z ní ve výchozím nastavení programu SPSS Statistics učinilo referenční kategorii. Jednoduše jsme to takto udělali, protože když se triatlonisté účastní triatlonu, nejprve plavou, pak podnikají cyklistický závod a nakonec doběhnou do cíle. Proto se zdálo logické kódovat naši kategoriální nezávislou proměnnou tímto způsobem. Mohli jsme ji však kódovat jako 1 = jízda na kole, 2 = běh a 3 = plavání; na tom by nic nezměnilo, až na to, že jako třetí a poslední kategorie by se „plavání“ stalo naší referenční kategorií ve výchozím nastavení programu SPSS Statistics.
Při vytváření fiktivních proměnných byste jim měli dát smysluplný název. Protože každá z našich fiktivních proměnných představuje kategorii naší kategoriální nezávislé proměnné, je zvykem označovat každou fiktivní proměnnou názvem kategorie, kterou představuje. Proto jsme dummy proměnnou č. 1 nazvali „plavání“, protože představuje kategorii plavání. Podobně jsme dummy proměnnou č. 2 nazvali „cyklistika“, protože představuje kategorii cyklistiky. Vytvořením těchto dvou fiktivních proměnných získáme v našem souboru dat v programu SPSS Statistics dva nové sloupce, jak je uvedeno níže:
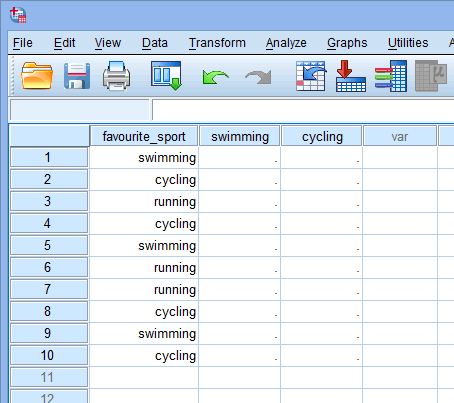
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Teď, když jsme vytvořili dvě fiktivní proměnné a dali jim vhodné názvy, musíme do těchto proměnných zadat hodnoty tak, aby každá fiktivní proměnná skutečně reprezentovala svou kategorii kategoriální nezávislé proměnné. Pomocí dummy kódování je to velmi jednoduché. Zadáte „1“, abyste reprezentovali každý případ (např. účastníka v souboru dat), který má danou kategorii, a zadáte „0“ (nulu), pokud danou kategorii nemá. Nejprve uvažujme fiktivní proměnnou „plavání“, jak je uvedeno níže:
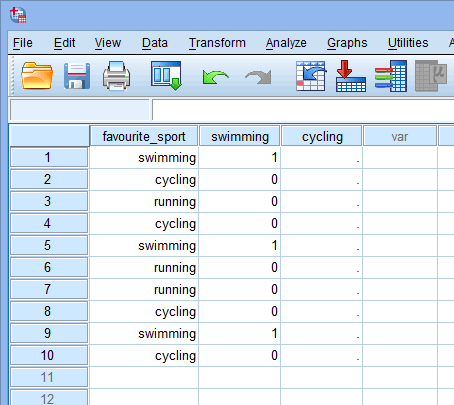
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
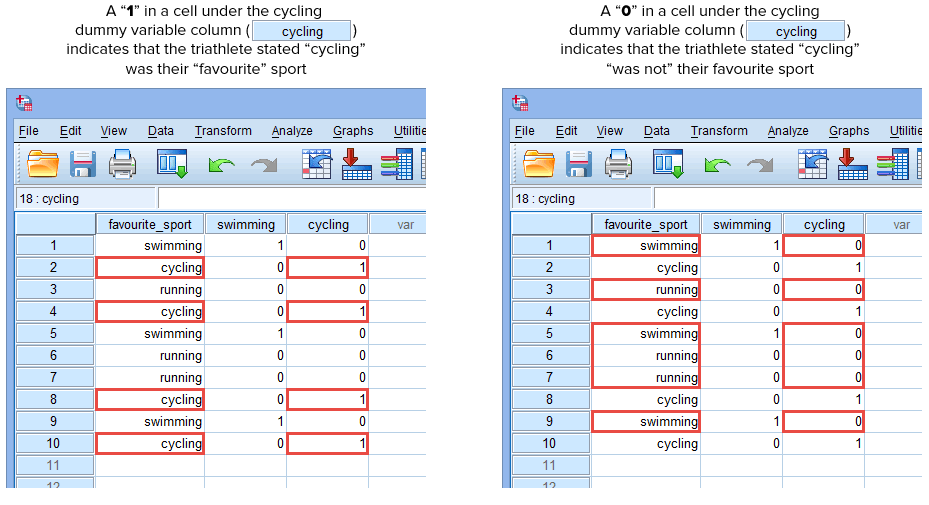
Pokud některý z triatlonistů uvedl, že „plavání“ je jeho „oblíbený“ sport, zadáme „1“ do buňky pod sloupcem fiktivní proměnné plavání (![]() ) pro toho triatlonistu, který uvedl, že plavání je jeho „oblíbený“ sport. Pokud by naopak některý z triatlonistů uvedl, že jeho „oblíbeným“ sportem je „cyklistika“ nebo „běh“, zadali bychom do buňky ve sloupci s fiktivní proměnnou plavání (
) pro toho triatlonistu, který uvedl, že plavání je jeho „oblíbený“ sport. Pokud by naopak některý z triatlonistů uvedl, že jeho „oblíbeným“ sportem je „cyklistika“ nebo „běh“, zadali bychom do buňky ve sloupci s fiktivní proměnnou plavání (![]() ) hodnotu „0“ pro toho triatlonistu, který uvedl, že plavání „není“ jeho oblíbeným sportem (tj. znamená to, že oblíbeným sportem tohoto triatlonisty je buď „cyklistika“, nebo „běh“). To je zvýrazněno níže pro všech 10 triatlonistů:
) hodnotu „0“ pro toho triatlonistu, který uvedl, že plavání „není“ jeho oblíbeným sportem (tj. znamená to, že oblíbeným sportem tohoto triatlonisty je buď „cyklistika“, nebo „běh“). To je zvýrazněno níže pro všech 10 triatlonistů:
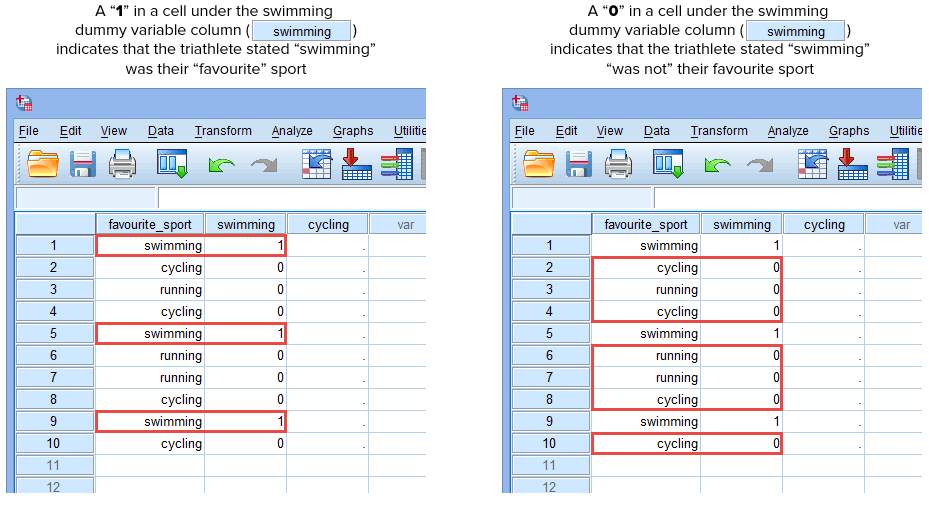
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Tento postup opakujeme pro druhou fiktivní proměnnou, „cyklistika“, jak je uvedeno níže:
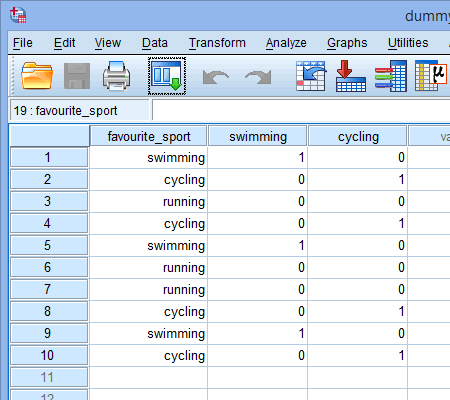
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Pokud některý z triatlonistů uvedl, že „cyklistika“ je jeho „oblíbený“ sport, zapíšeme „1“ do buňky pod sloupcem dummy proměnné cyklistika (![]() ) pro toho triatlonistu, který uvedl, že cyklistika je jeho „oblíbený“ sport. Pokud by naopak některý z triatlonistů uvedl, že jeho „oblíbeným“ sportem je „plavání“ nebo „běh“, zadali bychom do buňky ve sloupci s fiktivní proměnnou cyklistika (
) pro toho triatlonistu, který uvedl, že cyklistika je jeho „oblíbený“ sport. Pokud by naopak některý z triatlonistů uvedl, že jeho „oblíbeným“ sportem je „plavání“ nebo „běh“, zadali bychom do buňky ve sloupci s fiktivní proměnnou cyklistika (![]() ) hodnotu „0“ pro toho triatlonistu, který uvedl, že cyklistika „není“ jeho oblíbeným sportem (tj. znamená to, že oblíbeným sportem tohoto triatlonisty je buď „plavání“, nebo „běh“). Toto je zvýrazněno níže pro všech 10 triatlonistů:
) hodnotu „0“ pro toho triatlonistu, který uvedl, že cyklistika „není“ jeho oblíbeným sportem (tj. znamená to, že oblíbeným sportem tohoto triatlonisty je buď „plavání“, nebo „běh“). Toto je zvýrazněno níže pro všech 10 triatlonistů:
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Zadáním „1“ a „0“ do svých dummy proměnných tímto způsobem vytvoříte sadu dummy proměnných, které můžete zadat do vícenásobné regresní analýzy. V následující části Postup vám ukážeme, jak tyto fiktivní proměnné vytvořit pomocí procedury Vytvořit fiktivní proměnné.
SPSS Statistics
Postup v aplikaci SPSS Statistics pro vytvoření fiktivních proměnných
V aplikaci SPSS Statistics existují dvě procedury pro vytvoření fiktivních proměnných: procedura Vytvořit fiktivní proměnné a procedura Překódovat do jiných proměnných. V této příručce vám ukážeme, jak používat proceduru Create Dummy Variables, což je jednoduchý postup o 3 krocích. Je však k dispozici pouze v případě, že máte aplikaci SPSS Statistics verze 22 nebo novější, přičemž verze 26 (a předplacená verze aplikace SPSS Statistics) je nejnovější verzí aplikace SPSS Statistics. Pokud si nejste jisti, kterou verzi SPSS Statistics používáte, podívejte se do našeho průvodce: Zjistěte, jaká je vaše verze programu SPSS Statistics. Pokud máte SPSS Statistics verze 21 nebo starší nebo máte zájem o vícenásobná srovnání při provádění vícenásobné regresní analýzy, přečtěte si níže uvedenou poznámku:
Poznámka: Pokud máte SPSS Statistics verze 21 nebo starší, nemůžete použít postup Create Dummy Variables. Procedura Překódování do různých proměnných vám proto umožní alespoň vytvořit fiktivní proměnné v programu SPSS Statistics. I když můžete k vytvoření fiktivních proměnných použít také proceduru Recode into Different Variables, pokud máte SPSS Statistics verze 22 nebo novější, v této příručce uvádíme proceduru Create Dummy Variables, protože je určena k vytváření fiktivních proměnných a její použití je mnohem jednodušší a rychlejší. Například k vytvoření fiktivních proměnných pro příklad použitý v této příručce jsou zapotřebí pouze 3 kroky ve srovnání s 28 kroky pro stejný příklad při použití postupu Rekódování do různých proměnných.
Pokud tedy máte SPSS Statistics verze 21 nebo starší, náš rozšířený průvodce Vytváření fiktivních proměnných v části pro členy na Laerd Statistics obsahuje stránku věnovanou tomu, jak provést tento 28krokový postup Rekódování do různých proměnných. Přístup k tomuto rozšířenému průvodci získáte, pokud se přihlásíte k odběru Laerd Statistics. Případně můžete jednoduše použít níže uvedený postup Vytvoření fiktivních proměnných.
Chcete-li vytvořit fiktivní proměnné, když máte SPSS Statistics verze 22 nebo novější, postupujte podle níže uvedeného tříkrokového postupu Vytvoření fiktivních proměnných:
- Klikněte na Transformovat > Vytvořit fiktivní proměnné v hlavní nabídce, jak je uvedeno níže:

Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Zobrazí se dialogové okno Create Dummy Variables, jak je znázorněno níže:
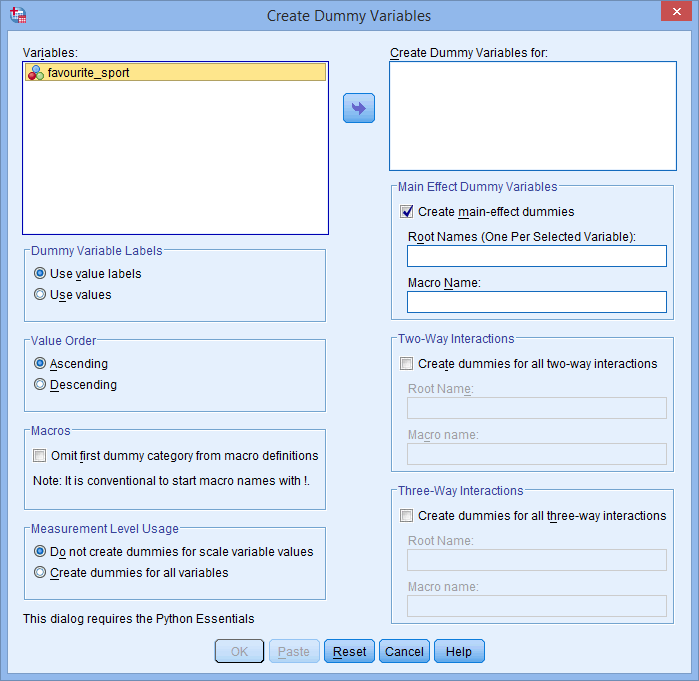
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
- Přeneste kategoriální nezávislou proměnnou favorite_sport do pole Create Dummy Variables for: jejím výběrem (kliknutím na ni) a poté kliknutím na tlačítko
 . Do pole Root Names (One Per Selected Variable): v oblasti -Main Effect Dummy Variables- zadejte také „kořenový“ název, který může reprezentovat všechny nové dummy proměnné. Zadali jsme kořenový název „fs“ jako zkratku pro naši kategoriální nezávislou proměnnou „favourite_sport“, jak je uvedeno níže:
. Do pole Root Names (One Per Selected Variable): v oblasti -Main Effect Dummy Variables- zadejte také „kořenový“ název, který může reprezentovat všechny nové dummy proměnné. Zadali jsme kořenový název „fs“ jako zkratku pro naši kategoriální nezávislou proměnnou „favourite_sport“, jak je uvedeno níže:
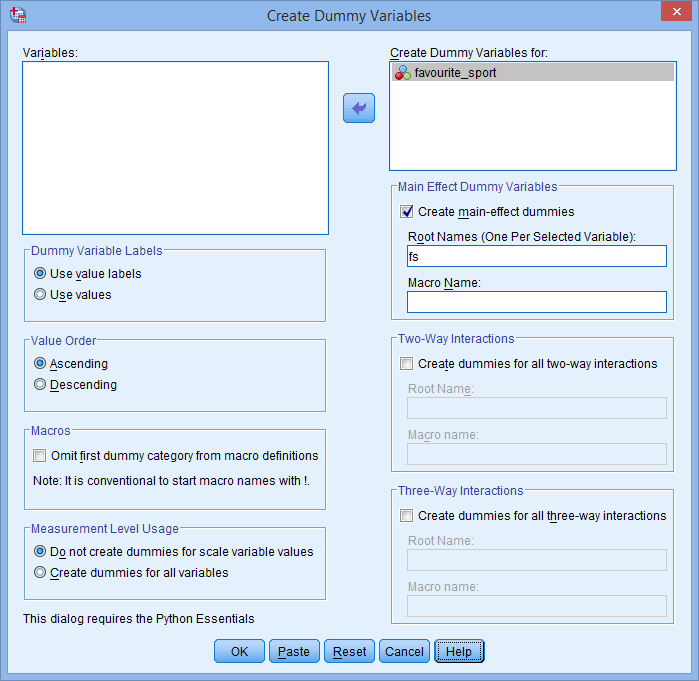
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Poznámka: SPSS Statistics přidá pořadové číslo (tj. 1, 2, 3, 4 atd.) na konec kořenového názvu, který zvolíte pro reprezentaci vaší kategoriální nezávislé proměnné. Pořadové číslo se vytvoří pro každou z fiktivních proměnných, které chcete vytvořit (např. pokud máte dvě fiktivní proměnné, na konec kořenového názvu se přidá 1 a 2, ale pokud byste měli šest fiktivních proměnných, na konec kořenového názvu by se přidalo 1, 2, 3, 4, 5 a 6). To je znázorněno pro náš příklad v okně Zobrazení proměnné níže:
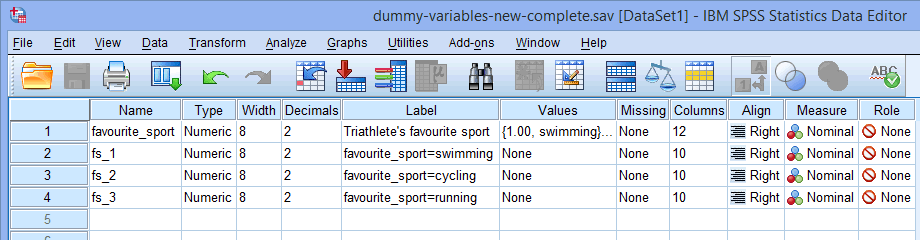
Protože naše kategoriální nezávislá proměnná, favourite_sport, měla tři kategorie (tj. plavání, jízda na kole a běh), procedura Vytvořit dummy proměnné vytvoří tři dummy proměnné (tj. jednu pro plavání, jednu pro jízdu na kole a jednu pro běh). Tyto tři fiktivní proměnné jsou zvýrazněny ve sloupci výše: „fs_1“ (pro plavání), „fs_2“ (pro cyklistiku) a „fs_3“ (pro běh). Později je můžete přejmenovat tak, aby dávaly větší smysl. Zdůrazňujeme to jen proto, abyste věděli, jak funguje výše uvedené pole Kořenové názvy (jeden na vybranou proměnnou):
výše: „fs_1“ (pro plavání), „fs_2“ (pro cyklistiku) a „fs_3“ (pro běh). Později je můžete přejmenovat tak, aby dávaly větší smysl. Zdůrazňujeme to jen proto, abyste věděli, jak funguje výše uvedené pole Kořenové názvy (jeden na vybranou proměnnou):
Také kořenový název, který zadáte do pole Kořenové názvy (jeden na vybranou proměnnou):, nesmí být stejný jako název vaší kategoriální nezávislé proměnné, jak je uvedeno níže (tj, kde jsme zadali kořenový název „favourite_sport“, abychom ilustrovali, jak bychom nemohli nazvat náš kořenový název):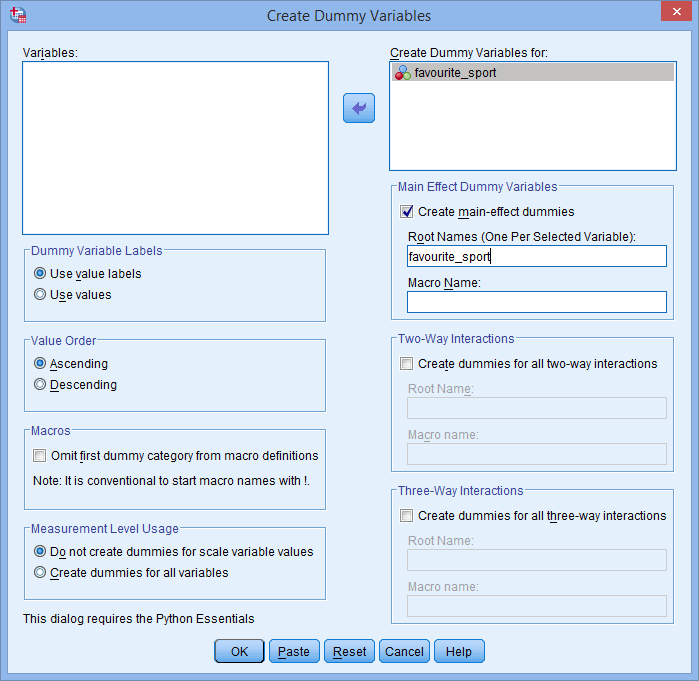
Pokud je zadaný kořenový název stejný jako název vaší kategoriální nezávislé proměnné, jak je uvedeno výše, po kliknutí na tlačítko se zobrazí následující upozornění:
se zobrazí následující upozornění:
- Klikněte na tlačítko .
Po provedení výše uvedeného tříkrokového postupu Vytvořit dummy proměnnou budete mít vytvořeny dummy proměnné pro vaši kategoriální nezávislou proměnnou. V další části zvýrazněte výstup, který se vytvoří v zobrazení proměnných a dat v programu SPSS Statistics po provedení tohoto postupu Vytvořit dummy proměnné.
SPSS Statistics
Výstup a nastavení dat v programu SPSS Statistics po vytvoření dummy proměnných
Po vytvoření vašich dummy proměnných vytvoří program SPSS Statistics následující tabulku Vytvoření proměnných jeho IBM SPSS Statistics Viewer:
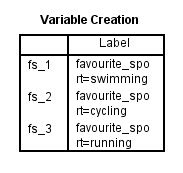
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Tabulka Vytvoření proměnné potvrzuje, že jste úspěšně vytvořili fiktivní proměnné. Mělo by zde být tolik řádků, kolik je nových fiktivních proměnných. Protože jsme vytvořili tři fiktivní proměnné, jsou v tabulce tři řádky „fs_1“, „fs_2“ a „fs_3“, které odrážejí kořenový název a pořadové číslování zadané v kroku 2 postupu Vytvoření fiktivních proměnných v předchozí části. Pro každou z těchto fiktivních proměnných je v tabulce uvedeno označení, aby bylo zřejmé, kterou kategorii kategoriální nezávislé proměnné každá fiktivní proměnná představuje. Například pro „fs_1“ je uvedeno označení „favourite_sport=swimming“, což znamená, že „fs_1“ je dummy proměnná pro kategorii „plavání“ kategoriální nezávislé proměnné favourite_sport.
Dále přejděte do okna Variable View programu SPSS Statistics kliknutím na kartu ![]() . Budou přidány tři fiktivní proměnné, jak je uvedeno níže (tj. fiktivní proměnné „fs_1“, „fs_2“ a „fs_3“ ve sloupci
. Budou přidány tři fiktivní proměnné, jak je uvedeno níže (tj. fiktivní proměnné „fs_1“, „fs_2“ a „fs_3“ ve sloupci ![]() ):
):
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Poznámka: Názvy fiktivních proměnných ve sloupci ![]() můžete změnit, aby bylo jasnější, o co se jedná. Například jsme změnili „fs_1“ na „plavání“, „fs_2“ na „jízda na kole“ a „fs_3“ na „běh“, jak je uvedeno níže:
můžete změnit, aby bylo jasnější, o co se jedná. Například jsme změnili „fs_1“ na „plavání“, „fs_2“ na „jízda na kole“ a „fs_3“ na „běh“, jak je uvedeno níže:
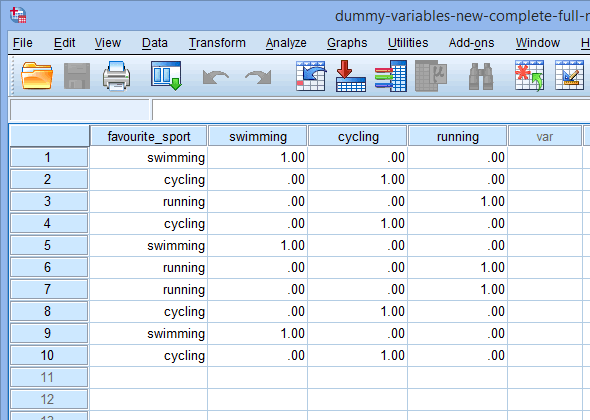
Nakonec přejděte do okna Data View programu SPSS Statistics kliknutím na kartu ![]() . Pod každou z vytvořených fiktivních proměnných se zobrazí kódování fiktivních proměnných. Například v řádcích pod sloupcem „fs_1“ je kategorie „plavání“ kódována jako „1,00“, zatímco kategorie „cyklistika“ a „běh“ jsou kódovány jako „,00“, jak je uvedeno níže. Pokud si nejste jisti, proč jsou tyto fiktivní proměnné takto kódovány, viz oddíl:
. Pod každou z vytvořených fiktivních proměnných se zobrazí kódování fiktivních proměnných. Například v řádcích pod sloupcem „fs_1“ je kategorie „plavání“ kódována jako „1,00“, zatímco kategorie „cyklistika“ a „běh“ jsou kódovány jako „,00“, jak je uvedeno níže. Pokud si nejste jisti, proč jsou tyto fiktivní proměnné takto kódovány, viz oddíl:
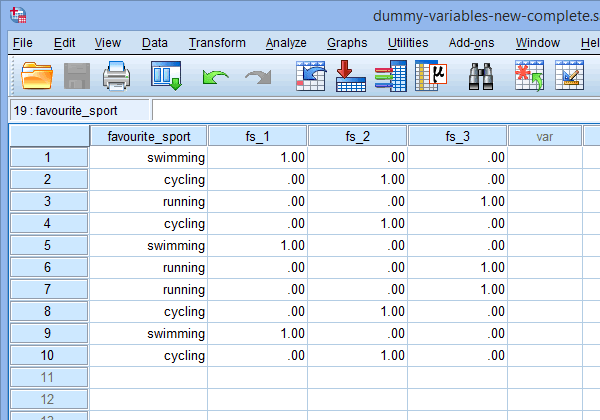
Publikováno s písemným svolením SPSS Statistics, IBM Corporation.
Poznámka 1: Vzhledem k výchozímu nastavení SPSS Statistics budou vaše fiktivní proměnné kódovány „1,00“ nebo „,00“ místo „1“, resp. „0“. Jsou totožné. Často se však setkáte s kódováním fiktivních proměnných zapsaným v podobě 1 a 0, nikoli včetně desetinných míst.
Poznámka 2: Pokud jste změnili názvy fiktivních proměnných ve výše uvedeném sloupci ![]() okna Variable View (Zobrazení proměnných), budou tyto názvy změněny i ve sloupcích okna Data View (Zobrazení dat), jak je uvedeno níže (např. nadpis sloupce
okna Variable View (Zobrazení proměnných), budou tyto názvy změněny i ve sloupcích okna Data View (Zobrazení dat), jak je uvedeno níže (např. nadpis sloupce ![]() se nyní jmenuje
se nyní jmenuje ![]() ):
):
.