Posted on August 27, 2015
Recurrent Neural Networks
Člověk nezačíná své myšlení od nuly každou sekundu. Když čtete tuto esej, chápete každé slovo na základě porozumění předchozím slovům. Nezahazujete vše a nezačínáte přemýšlet znovu od nuly. Vaše myšlenky mají trvalost.
Tradiční neuronové sítě toto nedokážou a zdá se, že je to zásadní nedostatek. Představte si například, že chcete klasifikovat, jaký druh události se odehrává v každém bodě filmu. Není jasné, jak by tradiční neuronová síť mohla využít své úvahy o předchozích událostech ve filmu k informování o těch pozdějších.
Rekurentní neuronové sítě tento problém řeší. Jsou to sítě se smyčkami, které umožňují, aby informace přetrvávaly.

V uvedeném diagramu se část neuronové sítě, \(A\), dívá na nějaký vstup \(x_t\) a na výstupu má hodnotu \(h_t\). Smyčka umožňuje předávat informace z jednoho kroku sítě do dalšího.
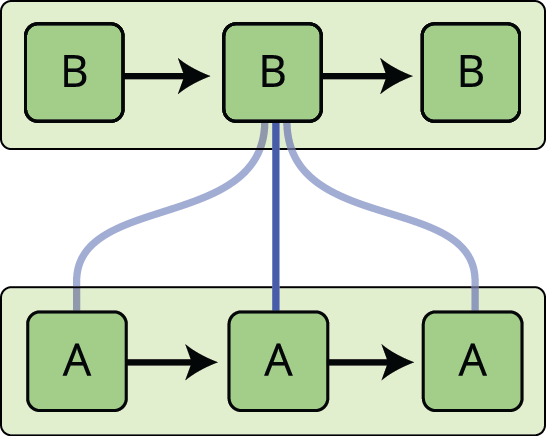
Tyto smyčky způsobují, že rekurentní neuronové sítě vypadají poněkud záhadně. Když se však trochu více zamyslíte, ukáže se, že se od běžné neuronové sítě zas tak moc neliší. Rekurentní neuronovou síť si lze představit jako několik kopií téže sítě, z nichž každá předává zprávu následníkovi. Uvažujte, co se stane, když rozvineme smyčku:

Tento řetězový charakter ukazuje, že rekurentní neuronové sítě jsou úzce spjaty se sekvencemi a seznamy. Jsou přirozenou architekturou neuronové sítě, která se pro taková data používá.
A rozhodně se používají! V posledních několika letech bylo dosaženo neuvěřitelných úspěchů při aplikaci RNN na nejrůznější problémy: rozpoznávání řeči, modelování jazyka, překlad, tvorba titulků k obrázkům… Seznam by mohl pokračovat. Diskusi o úžasných výkonech, kterých lze s RNN dosáhnout, přenechám vynikajícímu příspěvku Andreje Karpathyho na blogu The Unreasonable Effectiveness of Recurrent Neural Networks. Ale jsou opravdu úžasné.
Důležité pro tyto úspěchy je použití „LSTM“, velmi speciálního druhu rekurentní neuronové sítě, která pro mnoho úloh funguje mnohem mnohem lépe než standardní verze. Téměř všech zajímavých výsledků založených na rekurentních neuronových sítích bylo dosaženo právě s nimi. Právě těmito LSTM se bude zabývat tento esej.
Problém dlouhodobých závislostí
Jedním z lákadel RNN je myšlenka, že by mohly být schopny propojit předchozí informace s aktuální úlohou, například pomocí předchozích snímků videa by mohly informovat o pochopení současného snímku. Pokud by to RNN dokázaly, byly by nesmírně užitečné. Ale dokážou to? Záleží na tom.
Někdy nám k provedení současného úkolu stačí podívat se na nedávné informace. Uvažujme například jazykový model, který se snaží předpovědět další slovo na základě předchozích. Pokud se snažíme předpovědět poslední slovo ve větě „mraky jsou na obloze“, nepotřebujeme žádný další kontext – je zcela zřejmé, že dalším slovem bude obloha. V takových případech, kdy je mezera mezi příslušnou informací a místem, kde ji potřebujeme, malá, se RNN mohou naučit používat minulé informace.

Existují však i případy, kdy potřebujeme více kontextu. Uvažujme, že se snažíme předpovědět poslední slovo v textu „Vyrostl jsem ve Francii… Mluvím plynně francouzsky“. Poslední informace naznačují, že následující slovo je pravděpodobně název nějakého jazyka, ale pokud chceme zúžit, o jaký jazyk se jedná, potřebujeme kontext Francie, a to z větší dálky. Je docela dobře možné, že mezera mezi relevantní informací a místem, kde ji potřebujeme, bude velmi velká.
Naneštěstí, jak tato mezera roste, RNN se nedokážou naučit spojovat informace.

Teoreticky jsou RNN naprosto schopné zvládnout takové „dlouhodobé závislosti“. Člověk by pro ně mohl pečlivě vybírat parametry pro řešení problémů typu hračka. Bohužel se zdá, že v praxi se je RNN naučit nedokážou. Tento problém podrobně zkoumali Hochreiter (1991) a Bengio a další (1994), kteří našli několik docela zásadních důvodů, proč by to mohlo být obtížné.
Naštěstí sítě LSTM tento problém nemají!
Sítě LSTM
Sítě s dlouhou krátkodobou pamětí – obvykle se jim říká jen „LSTM“ – jsou speciálním druhem RNN, které se dokáží naučit dlouhodobé závislosti. Zavedl je Hochreiter &Schmidhuber (1997) a v následujících pracích je mnoho lidí zdokonalilo a zpopularizovalo.1 Fungují nesmírně dobře na velkém množství problémů a jsou nyní široce používány.
LSTM jsou výslovně navrženy tak, aby se vyhnuly problému dlouhodobých závislostí. Zapamatování informací na dlouhou dobu je prakticky jejich výchozí chování, nikoli něco, co se snaží naučit!“
Všechny rekurentní neuronové sítě mají podobu řetězce opakujících se modulů neuronové sítě. Ve standardních RNN bude mít tento opakující se modul velmi jednoduchou strukturu, například jednu tanh vrstvu.

LSTM mají také tuto strukturu podobnou řetězci, ale opakující se modul má jinou strukturu. Místo jedné vrstvy neuronové sítě jsou zde čtyři vrstvy, které se vzájemně ovlivňují velmi zvláštním způsobem.

Nezabývejte se detaily toho, co se děje. Schéma LSTM si projdeme krok za krokem později. Prozatím se jen zkusme sžít se zápisem, který budeme používat.

V uvedeném diagramu nese každý řádek celý vektor, od výstupu jednoho uzlu ke vstupům ostatních. Růžová kolečka představují bodové operace, jako je sčítání vektorů, zatímco žlutá pole jsou naučené vrstvy neuronové sítě. Slučování řádků označuje spojování, zatímco rozvětvení řádku značí, že jeho obsah je kopírován a kopie jdou na různá místa.
Klíčová myšlenka LSTM
Klíčem k LSTM je stav buňky, vodorovná čára procházející horní částí diagramu.
Stav buňky je něco jako dopravní pás. Probíhá přímo dolů celým řetězcem, pouze s některými drobnými lineárními interakcemi. Je velmi snadné, aby po něm informace prostě proudily beze změny.

LSTM má možnost odebírat nebo přidávat informace do stavu buňky, což pečlivě regulují struktury zvané brány.
Brány jsou způsob, jak volitelně propouštět informace. Skládají se ze sigmoidní vrstvy neuronové sítě a operace bodového násobení.

Sigmoidní vrstva dává na výstup čísla mezi nulou a jedničkou, která popisují, kolik jednotlivých složek má být propuštěno. Hodnota nula znamená „nepropustit nic“, zatímco hodnota jedna znamená „propustit všechno!“
LSTM má tři tato hradla, která slouží k ochraně a kontrole stavu buňky.
Procházka LSTM krok za krokem
Prvním krokem v našem LSTM je rozhodnutí, jaké informace ze stavu buňky vyhodíme. Toto rozhodnutí provádí sigmoidní vrstva nazývaná „vrstva zapomínacího hradla“. Ta se podívá na \(h_{t-1}\) a \(x_t\) a pro každé číslo ve stavu buňky \(C_{t-1}\) vypíše číslo mezi \(0\) a \(1\). Hodnota \(1\) znamená „zcela si to ponechat“, zatímco hodnota \(0\) znamená „zcela se toho zbavit“.
Vraťme se k našemu příkladu jazykového modelu, který se snaží předpovědět další slovo na základě všech předchozích. V takovém problému by stav buňky mohl zahrnovat rod přítomného subjektu, aby bylo možné použít správná zájmena. Když se objeví nový podmět, chceme zapomenout na rod starého podmětu.

Dalším krokem je rozhodnutí, jaké nové informace budeme do stavu buňky ukládat. To má dvě části. Nejprve sigmoidní vrstva zvaná „vrstva vstupního hradla“ rozhodne, které hodnoty budeme aktualizovat. Dále vrstva tanh vytvoří vektor nových kandidátních hodnot, \(\tilde{C}_t\), které by mohly být přidány do stavu. V dalším kroku je zkombinujeme a vytvoříme aktualizaci stavu.
V příkladu našeho jazykového modelu bychom chtěli do stavu buňky přidat rod nového subjektu, který nahradí starý, na který jsme zapomněli.

Nyní je čas aktualizovat starý stav buňky, \(C_{t-1}\), do nového stavu buňky \(C_t\). Předchozí kroky již rozhodly, co máme udělat, jen to musíme skutečně udělat.
Starý stav vynásobíme \(f_t\), přičemž zapomeneme na věci, které jsme se rozhodli zapomenout dříve. Pak přidáme \(i_t*\tilde{C}_t\). To jsou nové kandidátské hodnoty, odstupňované podle toho, jak moc jsme se rozhodli aktualizovat jednotlivé hodnoty stavu.
V případě jazykového modelu bychom zde vlastně vypustili informaci o pohlaví starého subjektu a přidali novou informaci, jak jsme se rozhodli v předchozích krocích.

Nakonec se musíme rozhodnout, co budeme vypisovat. Tento výstup bude vycházet ze stavu naší buňky, ale bude to filtrovaná verze. Nejprve spustíme sigmoidní vrstvu, která rozhodne, jaké části stavu buňky budeme vypisovat. Poté projdeme stav buňky přes \(\tanh\) (abychom posunuli hodnoty tak, aby byly mezi \(-1\) a \(1\)) a vynásobíme je výstupem sigmoidního hradla, takže na výstupu budou jen ty části, o kterých jsme rozhodli.
Pro příklad jazykového modelu, protože právě viděl podmět, by mohl chtít na výstup informace relevantní pro sloveso, pro případ, že to bude následovat. Například by mohl vypsat, zda je podmět v jednotném nebo množném čísle, abychom věděli, do jakého tvaru se má sloveso sklonit, pokud to bude následovat.

Varianty dlouhé krátkodobé paměti
To, co jsem zatím popsal, je docela normální LSTM. Ale ne všechny LSTM jsou stejné jako výše uvedené. Ve skutečnosti se zdá, že téměř každá práce týkající se LSTM používá trochu jinou verzi. Rozdíly jsou drobné, ale stojí za to se o některých z nich zmínit.
Jednou z populárních variant LSTM, kterou představil Gers & Schmidhuber (2000), je přidání „kukátkových spojení“. To znamená, že necháme vrstvy hradel nahlížet do stavu buňky.

Výše uvedené schéma přidává ke všem hradlům „peepholes“, ale v mnoha pracích budou některá „peepholes“ uvedena a jiná ne.
Další variantou je použití spřažených zapomínacích a vstupních hradel. Místo abychom zvlášť rozhodovali, co zapomenout a k čemu přidat novou informaci, děláme tato rozhodnutí společně. Zapomínáme pouze tehdy, když se chystáme místo toho něco zadat. Nové hodnoty do stavu zadáváme pouze tehdy, když zapomeneme něco staršího.

O něco dramatičtější variantou LSTM je Gated Recurrent Unit neboli GRU, kterou představil Cho, et al. (2014). Ta kombinuje zapomínací a vstupní brány do jediné „aktualizační brány“. Slučuje také stav buňky a skrytý stav a provádí některé další změny. Výsledný model je jednodušší než standardní modely LSTM a je stále populárnější.

Toto je jen několik nejvýznamnějších variant LSTM. Existuje spousta dalších, například RNN s hloubkovou regulací (Depth Gated RNNs) od Yao a dalších (2015). Existují také zcela odlišné přístupy k řešení dlouhodobých závislostí, například Clockwork RNNs od Koutnik, et al. (2014).
Která z těchto variant je nejlepší? Mají tyto rozdíly nějaký význam? Greff, et al. (2015) provádí pěkné srovnání populárních variant a zjišťuje, že jsou všechny přibližně stejné. Jozefowicz, et al. (2015) testovali více než deset tisíc architektur RNN a zjistili, že některé fungují v určitých úlohách lépe než LSTM.
Závěr
Předtím jsem se zmínil o pozoruhodných výsledcích, kterých lidé dosahují s RNN. V podstatě všech jich dosahují pomocí LSTM. Ty opravdu fungují pro většinu úloh mnohem lépe!“
Napsané jako soubor rovnic vypadají LSTM dost děsivě. Doufejme, že díky tomu, že jsme je v této eseji prošli krok za krokem, jsme se jim trochu přiblížili.
LSTM byly velkým krokem v tom, čeho můžeme s RNN dosáhnout. Je přirozené se ptát: existuje další velký krok? Mezi výzkumníky panuje častý názor: „Ano! Existuje další krok a je to pozornost!“ Jde o to, aby si každý krok RNN vybral informace, na které se bude dívat, z nějaké větší sbírky informací. Pokud například používáte RNN k vytvoření popisku popisujícího obrázek, může si pro každé slovo, které vypustí, vybrat část obrázku, na kterou se podívá. Ve skutečnosti Xu a další (2015) dělají přesně tohle – to by mohl být zábavný výchozí bod, pokud chcete prozkoumat pozornost! Existuje řada opravdu zajímavých výsledků využívajících pozornost a zdá se, že mnoho dalších je za rohem…
Pozornost není jediným vzrušujícím vláknem ve výzkumu RNN. Například Grid LSTM od Kalchbrennera a dalších (2015) se zdají být nesmírně slibné. Velmi zajímavě se jeví také práce využívající RNN v generativních modelech – například Gregor, et al. (2015), Chung, et al. (2015) nebo Bayer & Osendorfer (2015). Posledních několik let bylo pro rekurentní neuronové sítě vzrušujícím obdobím a ty nadcházející slibují, že budou jen vzrušující!“
Poděkování
Jsem vděčný řadě lidí za to, že mi pomohli lépe porozumět LSTM, komentovali vizualizace a poskytli zpětnou vazbu k tomuto příspěvku.
Jsem velmi vděčný svým kolegům ve společnosti Google za užitečnou zpětnou vazbu, zejména Oriolu Vinyalsovi, Gregu Corrado, Jonu Shlensovi, Luku Vilnisovi a Iljovi Sutskeverovi. Jsem také vděčný mnoha dalším přátelům a kolegům za to, že si našli čas a pomohli mi, včetně Daria Amodeie a Jacoba Steinhardta. Zvláště jsem vděčný Kyunghyun Choovi za nesmírně promyšlenou korespondenci o mých schématech.
Před tímto příspěvkem jsem si procvičoval vysvětlování LSTM během dvou sérií seminářů o neuronových sítích, které jsem vedl. Děkuji všem, kteří se jich zúčastnili, za trpělivost, kterou se mnou měli, a za zpětnou vazbu.
-
Kromě původních autorů přispělo k moderním LSTM mnoho lidí. Neúplný seznam je následující: Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo a Alex Graves.
Další příspěvky
Pozornost a rozšířené rekurentní neuronové sítě
O Distill
Konv. sítě
Modulární perspektiva
Neuronové sítě, Manifolds, and Topology