GPI-förankrade proteiner är en udda figur. I introduktionskursen i cellbiologi fick vi lära oss att det finns fem typer av membranproteiner med följande namn: Typ I, typ II, typ III, typ IV och GPI-förankrade. Varför har vi denna märkliga klass av proteiner som är sammanfogade med en socker- och fettkedja? Vad gör de? Kan vi få några insikter om mitt intressanta protein – PrP – genom att lära oss mer om denna klass av proteiner som det tillhör?
Sonia och jag och vår lagkamrat Andrew och har läst en del om detta ämne och jag skriver det här blogginlägget för att dela med mig av en del av vad vi lärt oss.
Läsning
Vi började med att läsa ett par recensioner . Dessa behandlade mestadels strukturen och biogenesen av själva GPI-ankret, som man vet otroligt mycket om.
Detta ankare, vars fullständiga namn är glykosylfosfosphatidylinositol, är inte en monolit: det är en allmän beskrivning av en molekyl vars detaljer kan variera. I allmänhet har man, med utgångspunkt från ω (sista posttranslationellt närvarande) rest i proteinet, etanolamin, sedan en fosfat, sedan några sockerarter, sedan en fosfolipid. Den centrala sockerstommen är bevarad, men de sidokedjor som grenar av den kan variera, och både fosfolipidhuvudgruppen och fettsyrorna kan också variera. PrP:s GPI-ankare karakteriserades i , men inte ens då är det en monolit – man identifierade minst sex olika strukturer som skiljer sig åt i sammansättningen av sockersidekedjor.
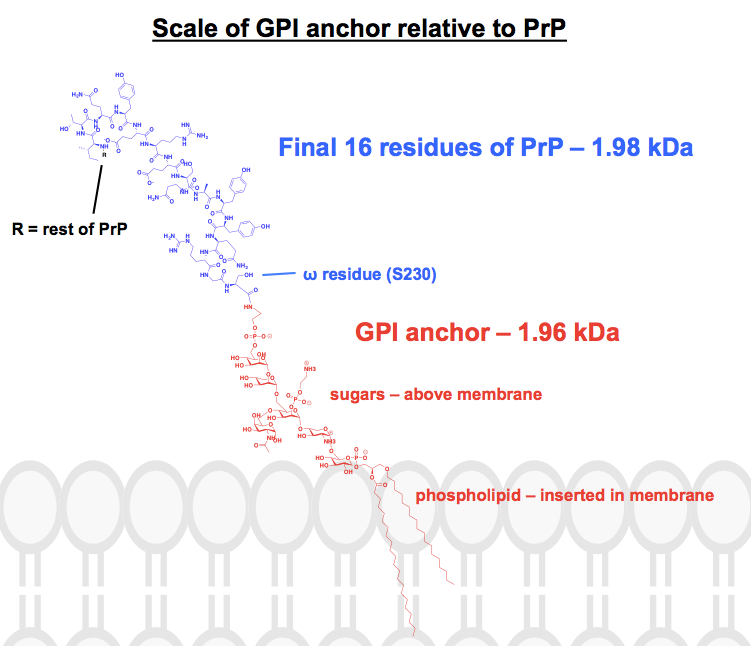
Alla kemiska strukturer som jag har hittat av GPI-ankrar har åtminstone vissa delar förkortade eller sammanfattade, och proteinet brukar bara visas som en bild. Jag ville få en uppfattning om hur dessa ankare faktiskt ser ut kemiskt, i samband med de bifogade proteinerna, så jag satte mig för att faktiskt rita en komplett struktur i ChemDraw. Jag utgick från figur 1 av – det närmaste en komplett skelettstruktur jag kunde hitta – och lade till detaljerna i en av PrP:s GPI-förankringar från den övre panelen i figur 6. Molekylvikten uppgick till 1 958 Da, så för att få ett sammanhang ritade jag in de sista 16 resterna av HuPrP23-230, som väger jämförelsevis 1 979 Da. Detta motsvarar ungefär 8 % av PrP:s posttranslationellt modifierade sekvens. Jag är inte säker på att jag fick alla bindningar rätt, men här är vad jag kom fram till:
I många fall har en gen flera isoformer, där en skarvningsprodukt ger upphov till ett GPI-förankrat protein medan andra ger upphov till utsöndrade eller transmembranformer. Exempel på detta är NCAM1, som har tre huvudsakliga isoformer, varav en är GPI-förankrad och de andra två är transmembranära , och ACHE (som kodar för acetylkolinesteras), vars GPI-förankrade form tydligen endast finns på röda blodkroppar (NCBI Genes). Den mest fascinerande historien här är den om musgen Ly6a som tack vare en genetisk polymorfism är GPI-förankrad i vissa musstammar och inte i andra. Endast i sin GPI-förankrade form fungerar den som receptor för virusvektorn AAV PHP.eB . (Denna vektor uppnår ett förvånansvärt effektivt upptag i hjärnans neuroner för genterapi , men tyvärr är det bara en musgen – vi människor har inte ens Ly6a).
Man vet mycket om hur GPI-ankrar syntetiseras och fästs på proteiner , med >20 proteiner inblandade i vägen, varav de flesta börjar med prefixet ”PIG” och kodas av gener som PIGA, PIGK och så vidare – se figur 2 för ett diagram. Den största delen av biosyntesen sker med ankaret infogat i membranet i ER men inte fäst vid något protein. I själva verket sker de första stegen på membranets cytosoliska blad, och först senare vänder ankaret till lumenalsidan (inne i ER). Det sista steget är när GPI-transamidas, ett komplex som består av minst fem proteiner, klyver GPI-signalen från proteinets C-terminus och fäster GPI-ankaret vid proteinets så kallade ω-resurs (den sista residen i den posttranslationellt modifierade sekvensen). Därefter sker ytterligare mognad av GPI-ankret när proteinet vandrar ut ur ER mot cellytan.
Det finns ett antal småmolekylära hämmare av GPI-biosyntesen hos svampar, varav vissa har man försökt utveckla som svampdödande läkemedel , men såvitt jag kunde se är den enda kända hämmaren av GPI-biosyntesen i däggdjursceller mannosamin, en mannosanalog som kemiskt sett är inkompatibel med inkorporering i GPI .
Jag letade och letade efter en sekvenslogotyp för vilket aminosyrasekvensmotiv GPI transamidas känner igen, men hittade ingen. Tydligen är sekvensmotivet ganska löst , och tydligen är GPI-signalerna inte ens homologa , vilket innebär att de inte utvecklats från en gemensam förfäderssekvens, utan snarare utvecklats konvergent, i den mån det ens finns någon konvergens. Den bästa beskrivningen som jag har kunnat hitta är att (om man läser N-till-C-terminal fram till slutet av proteinet) behöver man 1) ungefär 11 rester av en ostrukturerad länkare, 2) några rester med små sidokedjor inklusive en ω-rest som kan vara antingen S, N, D, G, A eller C, 3) en spacer av 5-10 polära aminosyror, och slutligen 4) 15-20 hydrofoba aminosyror . PrP följer löst detta motiv. Enligt publicerade strukturer slutar alfahelix 3 vid rest Q223, vilket gör att den ”ostrukturerade länken” bara är AYYYQR (något kortare än de föreskrivna 11 resterna). Den ”lilla sidokedjans” region skulle vara GS|SM (där röret betecknar transamidasets skärningsplats), den polära regionen skulle vara VLFSSPP och den hydrofoba C-terminalen skulle vara VILLISFLIFLIVG.
Vissa proteiner i GPI-biosyntesen och fästningsvägen är mycket viktiga, och ett antal allvarliga sjukdomar och syndrom av GPI-ankringsbrist har beskrivits, på grund av bialleliska funktionsbortfall eller uppenbarligen hypomorfa missense-mutationer i gener som PIGO, PIGV, PIGW, PGAP2 och PGAP3 .
Sonia hittade en utmärkt artikel från några år sedan där man gjorde en mutagenesscreening i haploida mänskliga celler för att identifiera gener som krävs för biogenesen av två GPI-förankrade proteiner: PrP och CD59 . De använde upprepad FACS-sortering av celler baserat på PrP och CD59 på cellytan för att identifiera celler med dramatiskt reducerade ytnivåer av dessa proteiner, och gjorde sedan sekvensering för att se vilka genknockouts som var berikade i dessa celler jämfört med moderpopulationen. Som man kan förvänta sig kom de flesta PIG-gener upp för båda proteinerna (figur 4), men alla träffar överlappade inte, vilket är lite förvånande, särskilt eftersom PrP och CD59 åtminstone på RNA-nivå är två av de proteiner som har de mest likartade uttrycksprofilerna i olika vävnader (se värmekartan längst ner i det här inlägget). Ett gäng enzymer som är involverade i modifiering av GPI-ankersidekedjan dök upp endast för CD59, vilket tyder på att CD59, men inte PrP, behöver dessa komplexa sidokedjor för att mogna och nå cellytan. Samtidigt hittades Sec62 och Sec63 endast för PrP – dessa proteiner är på något sätt involverade i co-translationell translokation till ER, men tydligen behövs de för PrP men inte för CD59 eller för CD55 eller CD109, två andra kontrollproteiner som de undersökte. Detta är ett fascinerande nytt kapitel i svaret på min fråga ”Är det något speciellt med PrP:s uttryck?”, där jag letade efter något unikt med PrP:s biogenes som skulle kunna vara potentiellt målinriktat med en liten molekyl. Naturligtvis, bara för att dessa proteiner inte var viktiga för tre andra kontrollproteiner i betyder det inte att de inte är viktiga – en studie fann att Sec62 behövdes för sekretion av många små proteiner , och SEC62-genen är helt utarmad för loss-of-function-varianter i den mänskliga populationen, vilket är tillräckligt för att antyda haploinsufficiens. SEC63 verkar vara mindre begränsad, även om det bara kan betyda att den verkar recessivt.
Ingen av ovanstående besvarar frågan om varför GPI-förankrade proteiner existerar. Min gamla cellbiologikurs utelämnade förresten en detalj: det finns faktiskt en sjätte klass av membranproteiner, så kallade svansförankrade (TA) proteiner , som bara har en hydrofob C-terminus som sticker in i membranet men inte sticker ut på andra sidan. Varför kunde inte alla dessa GPI-förankrade proteiner bara vara TA-proteiner? Varför utvecklade cellerna en så komplicerad väg för att syntetisera ett socker-fettankare i stället, och varför utvecklade de det så tidigt i spelet – GPI-ankare finns överallt i eukaryoter, inklusive i många encelliga patogener som infekterar människor.
De flesta av recensionerna ägnade inte mycket tid åt den här frågan, troligen för att det är den svåraste att besvara. De GPI-förankrade proteinerna i sig, i den mån deras ursprungliga funktioner är kända, har ett enormt utbud av funktioner – det finns enzymer (t.ex. AChE), celladhesionsmolekyler (t.ex. NCAM1), proteiner som reglerar komplement i immunsystemet (CD59) och så vidare . Det finns tydligen minst ett GPI-förankrat protein som är involverat i underhållet av myelin i perifera nerver . Men vad exakt kan GPI-förankrade proteiner göra som andra proteiner inte kan göra? I en översikt nämns några idéer som har föreslagits. En är att GPI-förankrade proteiner är bra på att tillfälligt dimerisera . Vissa studier har utforskat idén att homodimerisering spelar någon roll i prionbiologin , även om relevansen av de modellsystem som används där för in vivo-situationen ännu inte är klar. En annan idé är att eftersom GPI-förankrade proteiner kan avskiljas från cellytan, till exempel av angiotensin-converterande enzym (ACE) , kan deras lokalisering regleras på något dynamiskt sätt. Även här vet vi att PrP kan avskiljas, uppenbarligen av enzymet ADAM10 , även om en eventuell roll för PrP:s ursprungliga funktion ännu inte är klarlagd. En tredje idé, och kanske den som jag har hört mest talas om, är att GPI-förankrade proteiner selektivt samlas i ”lipid rafts” . Detta är kanske den mest lockande förklaringen, eftersom man kan föreställa sig alla typer av följdeffekter, där den ökade effektiva lokala koncentrationen av dessa proteiner möjliggör fler interaktioner och så vidare. Men i en av granskningarna påpekades att en invändning är att lipidflottar fortfarande är mer av en abstrakt idé än en konkret sak – även om de funktionellt definieras av att de är olösliga i tvättmedel och de flesta människor beskriver dem som rika på sfingomyelin och kolesterol, finns det ingen allmänt accepterad definition av vad som är och inte är en lipidflotte, och de empiriska bevisen tyder på att de kan vara mycket mindre och mer flyktiga än vad de flesta människor tror.
Med denna läsning i handen gav jag mig i kast med att skaffa en lista över dessa proteiner och göra några analyser på dem för att se om jag kunde få en bättre uppfattning om hur de ser ut.
analyser
Uniprot har en lista över 173 mänskliga GPI-förankrade proteiner. Dessa mappades till 140 gensymboler, som sjönk till 135 efter att ha kört det här skriptet för att uppdatera till de för närvarande HGNC-godkända proteinkodande gensymbolerna. Den slutliga listan med 135 gensymboler finns här.
Uniprot erbjuder ingen information om hur deras annotationer genererades, även om det måste finnas en betydande grad av manuell kuratering. Som jämförelse har Andrew också grävt fram en rad snygga artiklar där PI-PLD eller PI-PLC, två enzymer som klyver GPI-förankringar, används för att empiriskt isolera GPI-förankrade proteiner från celler . Genom att kombinera listorna från dessa artiklar och kartlägga dem med nuvarande gensymboler fick vi fram 107 gener. Vi kontrollerade flera av dessa slumpmässigt. Bland dem fanns välkända GPI-förankrade proteiner som glypican-1 (GPC1) och neural cell adhesion molecule (NCAM1), som båda rapporteras ha interaktioner med PrP . Men det fanns också flera gener för vilka ingen GPI-förankring tycktes vara känd i litteraturen, t.ex. VDAC3, varav några helt enkelt kan vara mycket rikliga proteiner eller falskt positiva av andra skäl. Samtidigt finns det uppenbara källor till falskt negativa: gener som helt enkelt inte uttrycktes i den studerade cellinjen, eller som inte var tillräckligt rikliga för att kunna plockas upp med masspektroskopi, och PrP-paralogerna SPRN och PRND fanns inte med i listorna. Totalt sett fanns 51 gener i båda listorna, en mycket signifikant anrikning (OR = 217, P < 1 × 10-84), vilket hjälper mig att försäkra mig om att Uniprots annotationer är förenliga med empiriska data. Men för vidare analyser bestämde vi oss för att använda Uniprot-listan eftersom den verkar mer känslig och specifik.
Med hjälp av denna lista ville jag se hur GPI-förankrade proteiner ligger till. PrP är ett enkelt exon, kort (208 aminosyror i sin mogna form), icke-essentiellt, brett uttryckt protein. Är dessa egenskaper typiska eller atypiska för ett GPI-förankrat protein?
Det visar sig att GPI-förankrade proteiner är över hela kartan, lika varierande på varje dimension jag tittade på som alla andra uppsättningar av proteiner är.
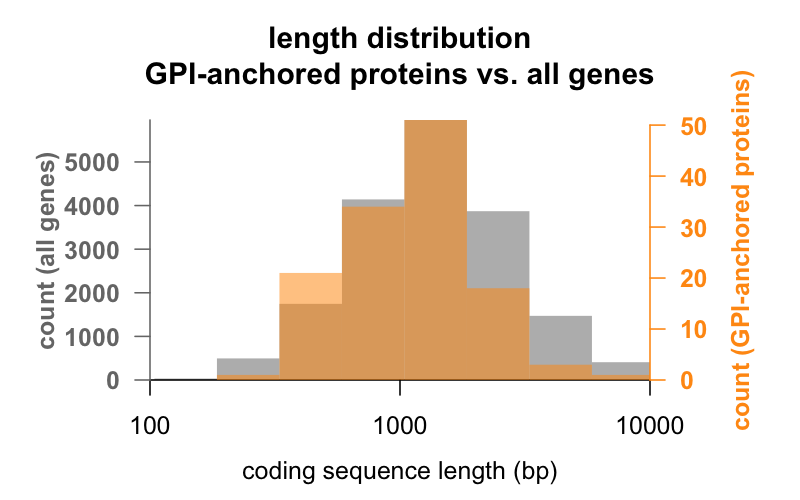
För det första, längden. Nedan visas överlagrade histogram av den kodande sekvensens längd i baspar för alla gener jämfört med gener som kodar för GPI-förankrade proteiner. Den GPI-förankrade fördelningen är knappt vänsterförskjuten. Den genomsnittliga GPI-förankrade proteingenen har 1 301 bp kodande sekvens, medan den genomsnittliga genen har 1 729, men denna skillnad i medelvärde är liten jämfört med variationen inom varje grupp. PrP, med bara 762 bp kodande sekvens, är definitivt på den lilla sidan, även om det inte på något sätt är ett undantag i någon av grupperna – CD52, med bara 186 baspar sekvens och tydligen bara 12 aminosyror i sin mogna form , är det minsta GPI-förankrade proteinet.
Hur är det med antalet exoner? GPI-förankrade proteiner har i genomsnitt något färre exoner jämfört med alla gener (medelvärde 7,8 jämfört med 10,1), vilket stämmer överens med den lilla skillnaden i längdfördelning som noterats ovan, men de flesta har flera exoner. Även här är PrP på den lilla sidan: det finns bara sex GPI-förankrade proteiner som bara har en kodande exon, och tre av dem är PrP och dess två paraloger, Sho och Dpl. (De andra tre generna är GAS1, SPACA4 och den fantastiskt namngivna OMG).
Nästan tittade jag på förlust av funktionsbegränsning. Constraint är ett mått på hur starkt naturligt urval en gen är utsatt för, baserat på hur utarmad den är för till exempel nonsense-, frameshift- och skarvplatsvariation i den allmänna populationen jämfört med förväntan baserat på mutationsfrekvensen. Detta mått är inte särskilt tolkningsbart för korta gener, både av statistiska skäl (antalet förväntade mutationer är lågt för korta gener, så det är svårt att kvantifiera utarmning) och av biologiska skäl (gener med ett enda exon är inte utsatta för nonsense-medierat sönderfall, så det är svårare att veta om proteintrunktionsvarianter verkligen är ”funktionsförluster” eller inte). Men eftersom de flesta GPI-förankrade proteiner inte är lika korta som PrP tyckte jag att det var värt att ta en titt. Resultatet: I genomsnitt är GPI-förankrade proteiner bara något mindre begränsade, vilket innebär att de har mer av den förväntade mängden förlust av funktionsvariationer än den genomsnittliga genen. Den genomsnittliga genen har 47 procent av sin funktionsförlustvariation, medan GPI-förankrade proteiner har 56 procent. Men som med allting här finns det en stor spridning i båda lägren. När det gäller GPI-förankrade proteiner har man i ena änden den absolut begränsade ACHE (17 LoFs förväntas och ingen observeras) och i den andra änden flera gener som inte tycks vara selekterade mot förlust av funktion överhuvudtaget – CNTN6, CD109, TREH och MSLN är några exempel på detta. PRNP hamnar i det senare lägret när man utesluter rester ≥145 där proteintrunkerande varianter orsakar en funktionsförstärkning .
Slutligt undrade jag var GPI-förankrade proteiner uttrycks. PRNP är högst i hjärnan men uttrycks överallt. Är detta typiskt? Jag laddade ner hela GTEx v7 ”gene median tpm”-sammanfattningsfilen (15 januari 2016), där varje rad är en gen och varje kolumn är en vävnad och cellerna är RPKM – RNA-seq reads per kilobas av exon per miljon mappade reads. Att arbeta med detta dataset krävde en del finess. Jag har hört att vissa bioinformatiker anser att <1 RPKM är ”inte uttryckt”, men uttrycksmatrisen är gles – de flesta gener är inte högt uttryckta i de flesta vävnader – så bruset under 1 RPKM kan dominera om man bara plottar de råa RPKM:erna. Samtidigt är genuttryck något som man måste tänka på på en logaritmisk skala, eftersom generna i en vävnad kan variera från <1 RPKM till >10 000 RPKM, så om man betraktar allting på en linjär skala kan också de få riktigt höguttryckta gen/vävnadskombinationerna dominera, vilket gör att matrisen ser ännu glesare ut än vad den är. Jag tog därför log10 av matrisen och trunkerade fördelningen vid , så den lila skala jag använde löper alltså över 1 – 10 – 100 – 1 000 – 10 000 RPKM. Sedan subsetted jag till Uniprot GPI-ankrade proteiner. För att visualisera detta gjorde jag för första gången i mitt liv en värmekarta. Jag har ofta sett dessa i artiklar och de brukar inte tala till mig, men här var mitt mål bara att få en uppfattning om uttrycksmönstret, och efter att ha lekt lite var detta det som gav mig mest insikt. Principen för en värmekarta är att raderna och kolumnerna är klustrade så att liknande saker hör ihop. Således är till exempel alla kolumner i hjärnvävnad uppradade efter varandra i en fläck på x-axeln, och alla starkt hjärnuttryckta gener är uppradade efter varandra i en fläck på y-axeln, så att deras skärningspunkt bildar en tät lila rektangel som kan tolkas som att ”det finns ett kluster av gener som främst är hjärnuttryckta”.
Interesserade läsare kan se den fullskaliga vektorkonst-PDF:n av värmekartan, men för att göra den mer omedelbart tillgänglig finns här en handantecknad version där de intressanta klustren anges:

Svaret är alltså nej – de flesta GPI-förankrade proteiner har inte samma uttrycksmönster som PRNP har. PRNP är en av den handfull som har ett högre och bredare uttryck och finns nära toppen av denna värmekarta, tillsammans med CD59, LY6E, GPC1 och BST2. De flesta GPI-förankrade proteiner har ett lägre eller mer vävnadsbegränsat uttryck, med några som nästan uteslutande uttrycks i hjärnan och andra som nästan uteslutande inte uttrycks i hjärnan, och andra mindre kluster som huvudsakligen tillhör specifika vävnader som testiklarna, till exempel PrP:s paralog PRND, vars knockout orsakar manlig sterilitet .
slutsatser
GPI-förankrade proteiner kan vara av nästan vilken storlek som helst, uttryckas i nästan vilken vävnad som helst och har uppenbarligen nästan vilken funktion som helst, i den mån deras funktioner är kända. Många GPI-förankrade proteiner har mycket tydliga nativa funktioner, men dessa funktioner är olika och det är inte klart varför de kräver GPI-förankring, särskilt eftersom många av dessa proteiner också finns i icke-GPI-förankrade isoformer. Samtidigt vet vi för andra GPI-förankrade proteiner, däribland PrP, inte tillräckligt mycket om den nativa funktionen till att börja med, så det är svårt att ens spekulera i varför den nativa funktionen kräver GPI-förankring. Ingen av de analyser jag gjorde eller recensioner jag läste kunde dra en enhetlig princip om varför denna förankringsmekanism existerar eller vad som gör att dessa proteiner kräver den. Det finns ett antal hypoteser om varför GPI-förankrade proteiner är unika, bland annat lipidflottar, homodimerer och avskiljning. Alla dessa hypoteser kan ha en viss giltighet. Men i slutändan verkar det osannolikt att svaret är ett eureka-ögonblick, utan snarare, som så mycket annat inom biologin, en prosaisk blandning av olika saker.
R-kod och rådatafiler för analyserna i det här inlägget finns här.