Sist uppdaterad den 18 augusti 2020
Dataset kan förekomma saknade värden, vilket kan orsaka problem för många maskininlärningsalgoritmer.
Det är därför bra att identifiera och ersätta saknade värden för varje kolumn i indatadata före modellering av prediktionsuppgiften. Detta kallas imputering av saknade data, eller imputering i korthet.
En populär metod för imputering av data är att beräkna ett statistiskt värde för varje kolumn (t.ex. ett medelvärde) och ersätta alla saknade värden för den kolumnen med statistiken. Det är ett populärt tillvägagångssätt eftersom statistiken är lätt att beräkna med hjälp av träningsdatasetetet och eftersom det ofta resulterar i bra prestanda.
I den här handledningen kommer du att upptäcka hur man använder statistiska imputeringsstrategier för saknade data i maskininlärning.
När du har slutfört den här handledningen kommer du att veta:
- Som saknade värden måste markeras med NaN-värden och kan ersättas med statistiska mått för att beräkna kolumnen av värden.
- Hur man laddar ett CSV-värde med saknade värden och markerar de saknade värdena med NaN-värden och rapporterar antalet och procentandelen saknade värden för varje kolumn.
- Hur man imputerar saknade värden med hjälp av statistik som en metod för dataförberedelse när man utvärderar modeller och när man anpassar en slutgiltig modell för att göra förutsägelser på nya data.
Kicka igång ditt projekt med min nya bok Data Preparation for Machine Learning, inklusive steg-för-steg-handledning och Python-källkodfiler för alla exempel.
Sätt igång.
- Uppdaterad juni/2020:

Statistisk imputering för saknade värden i maskininlärning
Foto av Bernal Saborio, vissa rättigheter förbehållna.
Tutorial Overview
Denna tutorial är uppdelad i tre delar; de är:
- Statistisk imputering
- Dataset om hästkolik
- Statistisk imputering med SimpleImputer
- SimpleImputer-datatransformation
- SimpleImputer och modellutvärdering
- Genomförande av olika imputerad statistik
- SimpleImputer Transform när man gör en förutsägelse
Statistisk imputering
En datamängd kan ha saknade värden.
Dessa är rader av data där ett eller flera värden eller kolumner i den raden inte finns. Värdena kan saknas helt eller vara markerade med ett särskilt tecken eller värde, t.ex. ett frågetecken ”?”.
Dessa värden kan uttryckas på många olika sätt. Jag har sett dem visas som ingenting alls , en tom sträng , den explicita strängen NULL eller odefinierad eller N/A eller NaN, och numret 0, bland annat. Oavsett hur de förekommer i ditt dataset, om du vet vad du kan förvänta dig och kontrollerar att uppgifterna stämmer överens med denna förväntan kommer du att minska problemen när du börjar använda uppgifterna.
– Sida 10, Bad Data Handbook, 2012.
Värden kan saknas av många anledningar, som ofta är specifika för problemområdet, och kan inkludera orsaker som korrupta mätningar eller otillgänglighet av data.
De kan uppstå av flera olika anledningar, t.ex. dåligt fungerande mätutrustning, ändringar i försöksupplägget under datainsamlingen och sammanställning av flera liknande men inte identiska dataset.
– Sidan 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
De flesta algoritmer för maskininlärning kräver numeriska ingångsvärden och att det finns ett värde för varje rad och kolumn i en datamängd. Därför kan saknade värden orsaka problem för algoritmer för maskininlärning.
Det är därför vanligt att man identifierar saknade värden i ett dataset och ersätter dem med ett numeriskt värde. Detta kallas dataimputering eller imputering av saknade data.
En enkel och populär metod för dataimputering innebär att man använder statistiska metoder för att uppskatta ett värde för en kolumn från de värden som finns, och sedan ersätter alla saknade värden i kolumnen med den beräknade statistiken.
Det är enkelt eftersom statistiken är snabb att beräkna och det är populärt eftersom det ofta visar sig vara mycket effektivt.
Andra statistiska metoder som beräknas är bland annat:
- Kolonnens medelvärde.
- Kolonnens medianvärde.
- Kolonnens modusvärde.
- Kolonnens konstantvärde.
Nu när vi är bekanta med statistiska metoder för imputering av saknade värden kan vi ta en titt på ett dataset med saknade värden.
Vill du komma igång med datapreparering?
Ta min kostnadsfria 7-dagars snabbkurs via e-post nu (med exempelkod).
Klicka för att registrera dig och få en gratis PDF Ebook-version av kursen.
Ladda ner din kostnadsfria minikurs
Horse Colic Dataset
Horse Colic Datasetetet beskriver medicinska egenskaper hos hästar med kolik och om de levde eller dog.
Det finns 300 rader och 26 indatavariabler med en utdatavariabel. Det är en prediktionsuppgift med binär klassificering som innebär att man ska förutsäga 1 om hästen levde och 2 om hästen dog.
Det finns många fält som vi skulle kunna välja att förutsäga i det här datasetet. I det här fallet kommer vi att förutsäga om problemet var kirurgiskt eller inte (kolumnindex 23), vilket gör det till ett binärt klassificeringsproblem.
Dataset har många saknade värden för många av kolumnerna där varje saknat värde är markerat med ett frågetecken (”?”).
Nedan följer ett exempel på rader från datasetetet med markerade saknade värden.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Du kan läsa mer om datasetet här:
- Horse Colic Dataset
- Horse Colic Dataset Description
Det finns inget behov av att ladda ner datasetetet, eftersom vi hämtar det automatiskt i de fungerande exemplen.
Markera saknade värden med ett NaN-värde (not a number) i ett inläst dataset med hjälp av Python är bästa praxis.
Vi kan läsa in datasetetet med hjälp av Pandas-funktionen read_csv() och ange ”na_values” för att läsa in värden på ’?’ som saknade, markerade med ett NaN-värde.
|
1
2
3
4
|
…
# ladda dataset
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
|
När data väl är inlästa kan vi se över dem för att bekräfta att ”?” värdena är markerade som NaN.
|
1
2
3
|
…
# sammanfatta de första raderna
print(dataframe.head())
|
Vi kan sedan räkna upp varje kolumn och rapportera antalet rader med saknade värden för kolumnen.
|
1
2
3
4
5
6
7
|
…
# sammanfatta antalet rader med saknade värden för varje kolumn
for i in range(dataframe.shape):
# räkna antalet rader med saknade värden
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(’> %d, Saknas: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Det fullständiga exemplet på inläsning och sammanfattning av datamängden är sammanställt nedan.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# sammanfattning av datasetet för hästkolik
from pandas import read_csv
# laddning av datasetet
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# sammanfatta de första raderna
print(dataframe.head())
# sammanfatta antalet rader med saknade värden för varje kolumn
for i in range(dataframe.shape):
# räkna antalet rader med saknade värden
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(’> %d, Saknas: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Att köra exemplet laddar först datasetet och sammanfattar de fem första raderna.
Vi kan se att de saknade värdena som markerades med ett ”?”-tecken har ersatts med NaN-värden.
Nästan kan vi se listan över alla kolumner i datasetet och antalet och procentandelen saknade värden.
Vi kan se att vissa kolumner (t.ex. kolumnindex 1 och 2) inte har några saknade värden och att andra kolumner (t.ex. kolumnindex 15 och 21) har många eller till och med en majoritet av saknade värden.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Saknas: 1 (0,3 %)
> 1, saknas: 0 (0.0%)
> 2, saknas: 0 (0.0%)
> 3, saknas: 60 (20.0%)
> 4, saknas: 24 (8,0%)
> 5, saknas: 58 (19,3%)
> 6, saknas: 56 (18,7%)
> 7, saknas: 56 (18,7%)
> 7, saknas: 69 (23,0%)
> 8, saknas: (15,7%)
> 9, Saknas: 47 (15,7%)
> 9, Saknas: (10,7%)
> 10, saknas: 32 (10,7%)
> 10, saknas: 55 (18,3%)
> 11, saknas: 44 (14,7%)
> 12, saknas: 56 (18,7%)
> 13, Saknas: 56 (18,7%)
> 13, Saknas: 104 (34,7%)
> 14, saknas: (35,3%)
> 15, Saknas: 106 (35,3%)
> 15, Saknas: 247 (82,3%)
> 16, saknas: 102 (34,0%)
> 17, Saknas: 247 (34,0%)
> 17, Saknas: 118 (39,3%)
> 18, saknas: 29 (9,7%)
> 19, saknas: 33 (11,0 %)
> 20, saknas: 33 (11,0 %)
> 20, saknas: 165 (55,0%)
> 21, saknas: 198 (66,0%)
> 22, Saknas: 1 (0,3%)
> 23, saknas: 0 (0,0%)
> 24, saknas: 0 (0.0%)
> 25, saknas: 0 (0.0%)
> 26, saknas: 0 (0.0%)
> 27, saknas: 0 (0.0%)
|
Nu när vi är bekanta med hästkolikdatasetetet som har saknade värden ska vi titta på hur vi kan använda oss av statistisk imputering.
Statistisk imputering med SimpleImputer
Biblioteket för maskininlärning scikit-learn tillhandahåller klassen SimpleImputer som stöder statistisk imputering.
I det här avsnittet kommer vi att utforska hur man effektivt använder SimpleImputer-klassen.
SimpleImputer-datatransformation
SimpleImputer är en datatransformation som först konfigureras baserat på vilken typ av statistik som ska beräknas för varje kolumn, t.ex.t.ex. medelvärde.
|
1
2
3
|
…
# definiera imputer
imputer = SimpleImputer(strategy=’mean’)
|
Därefter anpassas imputern på ett dataset för att beräkna statistiken för varje kolumn.
|
1
2
3
|
…
# passar på datasetet
imputer.fit(X)
|
Passningsimputern appliceras sedan på ett dataset för att skapa en kopia av datasetetet med alla saknade värden för varje kolumn ersatta med ett statistiskt värde.
|
1
2
3
|
…
# omvandla datasetet
Xtrans = imputer.transform(X)
|
Vi kan demonstrera dess användning på datasetetet för hästkolik och bekräfta att det fungerar genom att summera det totala antalet saknade värden i datasetetet före och efter omvandlingen.
Det kompletta exemplet visas nedan.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# statistisk imputering Transformationsmetod för datasetet för hästkolik
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# ladda datasetet
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dela upp datasetet i input och output element
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# skriv ut totalt antal saknade
print(’Saknas: %d’ % sum(isnan(X).flatten()))
# definiera imputer
imputer = SimpleImputer(strategy=’mean’)
# passa in på datasetet
imputer.fit(X)
# transformera datasetet
Xtrans = imputer.transform(X)
# skriv ut totalt antal saknade
print(’Saknas: %d’ % sum(isnan(Xtrans).flatten())))
|
Att köra exemplet laddar först datasetetet och rapporterar det totala antalet saknade värden i datasetetet som 1 605.
Transformationen konfigureras, anpassas och utförs, och det resulterande nya datasetetet har inga saknade värden, vilket bekräftar att den utfördes som vi förväntade.
Varje saknat värde ersattes med medelvärdet för sin kolumn.
|
1
2
|
Missing: 1605
Missing: 0
|
SimpleImputer and Model Evaluation
Det är en bra metod att utvärdera modeller för maskininlärning på en datamängd med hjälp av k-fold cross-validation.
För att korrekt tillämpa statistisk imputering av saknade uppgifter och undvika dataläckage krävs det att den statistik som beräknas för varje kolumn endast beräknas på träningsdatamängden och sedan tillämpas på tränings- och testuppsättningarna för varje veck i datamängden.
Om vi använder resampling för att välja värden för inställningsparametrar eller för att uppskatta prestanda bör imputeringen införlivas i resamplingen.
– Sida 42, Applied Predictive Modeling, 2013.
Detta kan åstadkommas genom att skapa en pipeline för modellering där det första steget är den statistiska imputeringen och det andra steget är modellen. Detta kan åstadkommas med hjälp av klassen Pipeline.
Till exempel använder Pipeline nedan en SimpleImputer med en ”mean”-strategi, följt av en random forest-modell.
|
1
2
3
4
5
|
…
# definiera modelleringspipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
Vi kan utvärdera medel-imputerade datasetet och pipeline för random forest-modellering för hästkolikdatasetetet med upprepad 10-faldig korsvalidering.
Det fullständiga exemplet finns nedan.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# utvärdera genomsnittlig imputation och slumpmässig forest för datasetet för hästkolik
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# ladda dataset
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dela upp datasetetet i input- och outputelement
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# definiera modelleringspipeline
modell = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# definiera modellutvärdering
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# utvärdera modellen
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(’Mean Accuracy: %.3f (%.3f)’ % (mean(scores), std(scores))))
|
Den korrekta körningen av exemplet tillämpar dataimputering på varje veck i korsvalideringsproceduren.
Anmärkning: Dina resultat kan variera på grund av algoritmens eller utvärderingsförfarandets stokastiska natur eller skillnader i numerisk precision. Överväg att köra exemplet några gånger och jämför det genomsnittliga resultatet.
Pipeline utvärderas med hjälp av tre upprepningar av 10-faldig korsvalidering och rapporterar den genomsnittliga klassificeringsnoggrannheten på datasetetet som ca 86.3 procent, vilket är ett bra resultat.
|
1
|
Median Accuracy: 0.863 (0.054)
|
Variantjämförelse av olika imputerade statistiska uppgifter
Hur vet vi att det är bra eller bäst att använda en ”genomsnittlig” statistisk strategi för det här datasetet?
Svaret är att vi inte vet det och att det valdes godtyckligt.
Vi kan utforma ett experiment för att testa varje statistisk strategi och upptäcka vad som fungerar bäst för det här datasetet, genom att jämföra strategierna medelvärde, median, mode (mest frekvent) och konstant (0). Den genomsnittliga noggrannheten för varje strategi kan sedan jämföras.
Det fullständiga exemplet finns nedan.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# jämför Statistiska imputeringsstrategier för datasetet för hästkolik
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# delas upp i inmatnings- och utdataelement
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# utvärdera varje strategi på datasetet
resultat = list()
strategier =
for s in strategies:
# skapa modelleringspipeline
pipeline = Pipeline(steps=)
# utvärdera modellen
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# lagra resultat
results.append(scores)
print(’>%s %.3f (%.3f)’ % (s, mean(scores), std(scores)))
# plotta modellens prestanda för jämförelse
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
Då exemplet körs utvärderar man varje strategi för statistisk imputering av datamängden för hästkolik genom upprepad korsvalidering.
Anmärkningar: Dina resultat kan variera på grund av algoritmens eller utvärderingsförfarandets stokastiska natur eller skillnader i numerisk precision. Överväg att köra exemplet några gånger och jämför det genomsnittliga resultatet.
Den genomsnittliga noggrannheten för varje strategi rapporteras längs vägen. Resultaten tyder på att användningen av ett konstant värde, t.ex. 0, resulterar i den bästa prestandan på cirka 88,1 procent, vilket är ett enastående resultat.
|
1
2
3
4
|
>medelvärde 0.860 (0.054)
>median 0.862 (0.065)
>mest_frequent 0.872 (0.052)
>konstant 0.881 (0.047)
|
I slutet av körningen skapas en box- och whiskerdiagram för varje uppsättning resultat, vilket gör det möjligt att jämföra fördelningen av resultaten.
Vi kan tydligt se att fördelningen av noggrannhetsresultaten för den konstanta strategin är bättre än de andra strategierna.
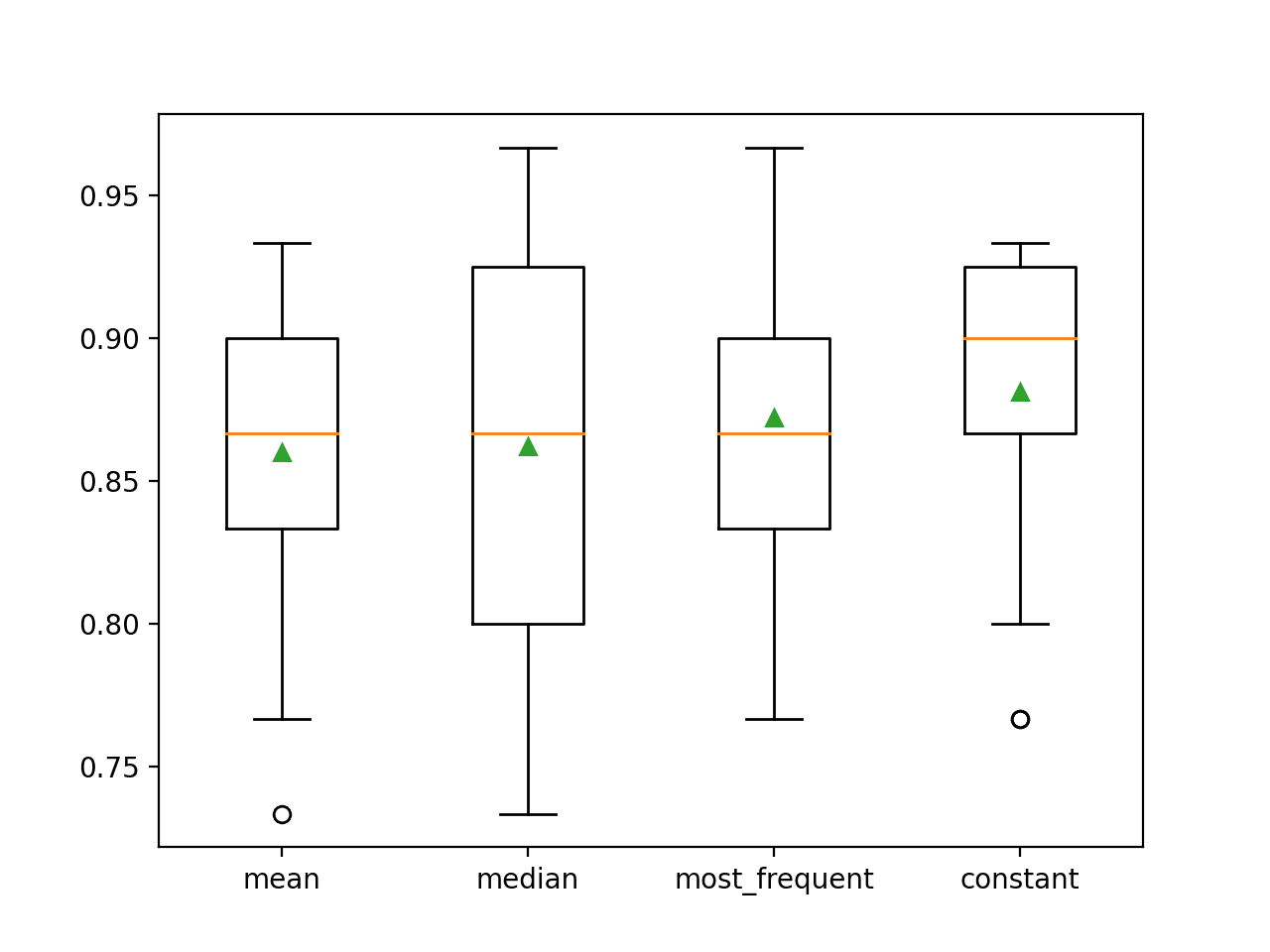
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
Vi kanske vill skapa en slutgiltig modelleringspipeline med den konstanta imputeringsstrategin och random forest-algoritmen, och sedan göra en prediktion för nya data.
Detta kan åstadkommas genom att definiera pipelinen och anpassa den på alla tillgängliga data, och sedan anropa funktionen predict() med nya data som argument.
Väsentligt är att raden med nya data måste markera eventuella saknade värden med hjälp av NaN-värdet.
|
1
2
3
|
…
# definiera nya data
row =
|
Det fullständiga exemplet finns nedan.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# konstant imputering Strategi och prediktion för datasetet för slangkolik
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# delas upp i inmatnings- och utdataelement
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# skapa modelleringspipeline
pipeline = Pipeline(steps=)
# anpassa modellen
pipeline.fit(X, y)
# definiera nya data
row =
# gör en förutsägelse
yhat = pipeline.predict()
# sammanfatta förutsägelsen
print(’Predicted Class: %d’ % yhat)
|
Avkörning av exemplet passar modelleringspipelinen på alla tillgängliga data.
En ny datarad definieras med saknade värden markerade med NaNs och en klassificeringsprediktion görs.
|
1
|
Prediktad klass: 2
|
Fördjupad läsning
Det här avsnittet innehåller fler resurser om ämnet om du vill fördjupa dig.
Relaterade handledningar
- Resultat för standardiserade datamängder för maskininlärning i form av klassificering och regression
- Hur man hanterar saknade data med Python
Böcker
- Handbok för dåliga data, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
APIs
- Imputering of missing values, scikit-learn Documentation.
- sklearn.impute.SimpleImputer API.
Dataset
- Horse Colic Dataset
- Horse Colic Dataset Description
Summary
I den här handledningen har du upptäckt hur du kan använda statistiska imputeringsstrategier för saknade data i maskininlärning.
Specifikt lärde du dig:
- Missade värden måste markeras med NaN-värden och kan ersättas med statistiska mått för att beräkna värdekolumnen.
- Hur man laddar ett CSV-värde med saknade värden och markerar de saknade värdena med NaN-värden och rapporterar antalet och procentandelen saknade värden för varje kolumn.
- Hur man imputerar saknade värden med statistik som en metod för dataförberedelse när man utvärderar modeller och när man anpassar en slutlig modell för att göra förutsägelser på nya data.
Har du några frågor?
Sätt dina frågor i kommentarerna nedan så ska jag göra mitt bästa för att svara.
Få grepp om modern datapreparering!

Förbered dina data för maskininlärning på några minuter
…med bara några få rader pythonkod
Upptäck hur i min nya Ebook:
Databeredning för maskininlärning
Den innehåller självstudier med full fungerande kod för:
Feature Selection, RFE, datarengöring, datatransformationer, skalning, dimensionalitetsreducering och mycket mer…
Har du moderna tekniker för datapreparering till
dina maskininlärningsprojekt
Se vad som finns inuti