Datakryptering i vila är ett måste för alla moderna Internetföretag. Många företag krypterar dock inte sina diskar eftersom de är rädda för den potentiella prestandaförlust som orsakas av krypteringsoverhead.
Kryptering av data i vila är viktigt för Cloudflare med mer än 200 datacenter över hela världen. I det här inlägget kommer vi att undersöka prestandan för diskkryptering på Linux och förklara hur vi gjorde den minst två gånger snabbare för oss själva och våra kunder!
Kryptering av data i vila
När det gäller att kryptera data i vila finns det flera sätt som det kan implementeras på i ett modernt operativsystem (OS). Tillgängliga tekniker är nära kopplade till en typisk lagringsstack i operativsystemet. En förenklad version av lagringsstacken och krypteringslösningar finns i diagrammet nedan:
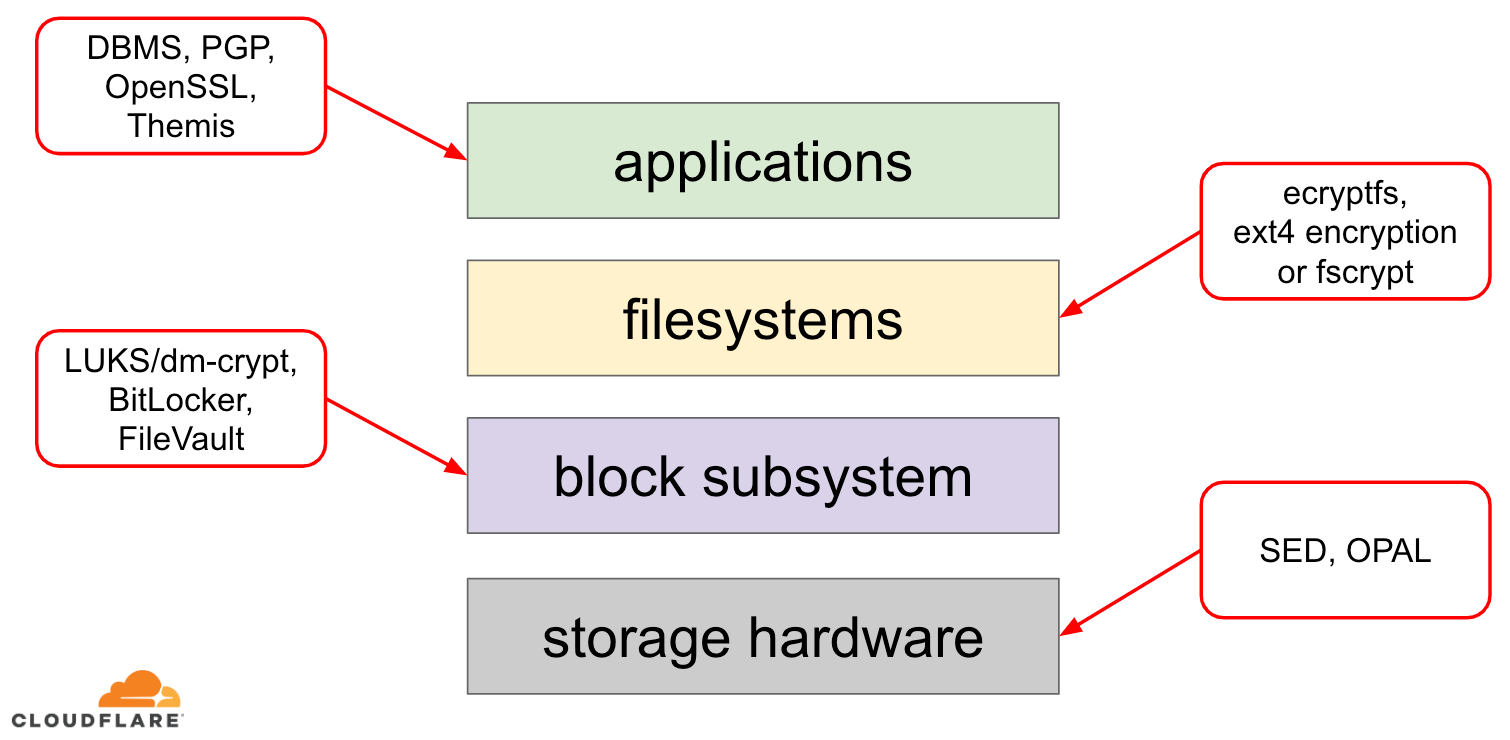
Ovanpå stacken finns program som läser och skriver data i filer (eller strömmar). Filsystemet i operativsystemets kärna håller reda på vilka block på den underliggande blockenheten som tillhör vilka filer och översätter dessa filläsningar och -skrivningar till blockläsningar och -skrivningar, men den underliggande lagringsenhetens hårdvaruspecifika egenskaper är abstraherade från filsystemet. Slutligen överför blocksubsystemet faktiskt blockläsningar och blockskrivningar till den underliggande maskinvaran med hjälp av lämpliga enhetsdrivrutiner.
Begreppet lagringsstack liknar faktiskt den välkända nätverksmodellen OSI-modellen, där varje lager har en mer överordnad bild av informationen och detaljerna i genomförandet av de lägre lagren abstraheras bort från de övre lagren. Och i likhet med OSI-modellen kan man tillämpa kryptering på olika lager (tänk på TLS vs IPsec eller en VPN).
För data i vila kan vi tillämpa kryptering antingen på blocklagren (antingen i hårdvara eller mjukvara) eller på filnivå (antingen direkt i program eller i filsystemet).
Block- vs filkryptering
Generellt sett är det så att ju högre upp i stapeln vi tillämpar kryptering, desto mer flexibilitet har vi. Med kryptering på applikationsnivå kan applikationsansvariga tillämpa vilken krypteringskod de vill på de särskilda data de behöver. Nackdelen med detta tillvägagångssätt är att de faktiskt måste implementera det själva, och kryptering i allmänhet är inte särskilt utvecklarvänligt: man måste känna till alla detaljer i en specifik kryptografisk algoritm, generera nycklar, nonces, IVs etc. på rätt sätt. Dessutom utnyttjar kryptering på applikationsnivå inte caching på OS-nivå och i synnerhet inte Linux page cache: varje gång applikationen behöver använda data måste den antingen dekryptera den igen, vilket slösar CPU-cykler, eller implementera sin egen dekrypterade ”cache”, vilket gör koden mer komplex.
Kryptering på filsystemnivå gör datakryptering genomskinlig för applikationerna, eftersom filsystemet självt krypterar data innan det överlämnar dem till blocksubsystemet, så att filerna krypteras oberoende av om applikationen har stöd för krypto eller inte. Dessutom kan filsystem konfigureras så att de endast krypterar en viss katalog eller har olika nycklar för olika filer. Denna flexibilitet kommer dock till priset av en mer komplex konfiguration. Kryptering av filsystem anses också vara mindre säker än kryptering av blockenheter eftersom endast filernas innehåll krypteras. Filerna har också tillhörande metadata, som filstorlek, antal filer, katalogträdets layout etc., som fortfarande är synliga för en potentiell motståndare.
Kryptering nere i blocklagret (ofta kallad disk kryptering eller full disk kryptering) gör också att datakryptering blir transparent för program och till och med för hela filsystem. Till skillnad från kryptering på filsystemnivå krypterar den alla data på disken, inklusive filmetadata och till och med ledigt utrymme. Den är dock mindre flexibel – man kan bara kryptera hela disken med en enda nyckel, så det finns ingen konfiguration per katalog, per fil eller per användare. Ur kryptoperspektivet kan inte alla kryptografiska algoritmer användas eftersom blocklagret inte längre har en översikt på hög nivå över data, så det måste behandla varje block oberoende av varandra. De flesta vanliga algoritmerna kräver någon form av blockkedja för att vara säkra, så de är inte tillämpbara för diskkryptering. Istället utvecklades särskilda lägen bara för detta specifika användningsfall.
Så vilket lager ska man välja? Som alltid beror det på… Kryptering på applikations- och filsystemnivå är vanligtvis det bästa valet för klientsystem på grund av flexibiliteten. Till exempel kan varje användare på ett skrivbord med flera användare vilja kryptera sin hemkatalog med en egen nyckel och lämna vissa delade kataloger okrypterade. På serversystem som hanteras av SaaS/PaaS/IaaS-företag (inklusive Cloudflare) är det tvärtom enkel konfiguration och säkerhet som är det föredragna valet – med full diskkryptering aktiverad krypteras alla data från alla program automatiskt utan några undantag eller åsidosättanden. Vi anser att alla data behöver skyddas utan att sortera dem i ”viktiga” respektive ”oviktiga” hinkar, så den selektiva flexibilitet som de övre lagren ger behövs inte.
Hårdvaru- vs. mjukvaru-diskkryptering
När man krypterar data på blocklagret kan man göra det direkt i lagringshårdvaran, om hårdvaran har stöd för det. Att göra så ger vanligtvis bättre prestanda vid läsning/skrivning och förbrukar mindre resurser från värddatorn. Eftersom den fasta programvaran för hårdvara oftast är proprietär får den dock inte lika mycket uppmärksamhet och granskning från säkerhetsvärlden. Tidigare har detta lett till brister i vissa implementeringar av hårdvaruskryptering av diskar, vilket har gjort hela säkerhetsmodellen oanvändbar. Microsoft, till exempel, har sedan dess börjat föredra mjukvarubaserad diskkryptering.
Vi ville inte utsätta våra data och våra kunders data för risken att använda potentiellt osäkra lösningar och vi tror starkt på öppen källkod. Därför förlitar vi oss endast på mjukvaru-diskryptering i Linuxkärnan, som är öppen och har granskats av många säkerhetsexperter över hela världen.
Linux-diskrypteringsprestanda
Vi strävar inte bara efter att spara bandbreddskostnader för våra kunder, utan också efter att leverera innehåll till internetanvändare så snabbt som möjligt.
Vid ett tillfälle märkte vi att våra diskar inte var så snabba som vi hade velat att de skulle vara. Viss profilering samt ett snabbt A/B-test pekade på Linux-diskkryptering. Eftersom det inte är ett hållbart alternativ att inte kryptera data (även om det är tänkt att vara en offentlig internetcache) bestämde vi oss för att ta en närmare titt på prestandan för Linux disk-kryptering.
Device mapper och dm-crypt
Linux implementerar transparent diskkryptering via en dm-crypt-modul och dm-crypt är i sig självt en del av device mapper kernel framework. I ett nötskal gör device mapper det möjligt att för- och efterbehandla IO-förfrågningar när de färdas mellan filsystemet och den underliggande blockenheten.
dm-crypt krypterar framför allt IO-förfrågningar för ”skrivning” innan de skickas längre ner i stapeln till den faktiska blockenheten och dekrypterar IO-förfrågningar för ”läsning” innan de skickas upp till filsystemets drivrutin. Enkelt och lätt! Eller är det?
Benchmarking setup
För säkerhets skull har siffrorna i det här inlägget erhållits genom att köra angivna kommandon på en inaktiv Cloudflare G9-server utanför produktionen. Uppställningen bör dock lätt kunna reproduceras på vilken modern x86-laptop som helst.
Generellt sett är det svårt att benchmarka något kring en lagringsstack på grund av det brus som introduceras av själva lagringshårdvaran. Alla diskar är inte skapade lika, så för det här inlägget kommer vi att använda de snabbaste diskarna som finns tillgängliga där ute – det vill säga inga diskar.
Istället har Linux ett alternativ för att emulera en disk direkt i RAM. Eftersom RAM är mycket snabbare än någon annan beständig lagring bör det introducera lite bias i våra resultat.
Följande kommando skapar en 4GB ramdisk:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Nu kan vi sätta upp en dm-crypt-instans ovanpå den och på så sätt möjliggöra kryptering för disken. Först måste vi generera diskens krypteringsnyckel, ”formatera” disken och ange ett lösenord för att låsa upp den nyligen genererade nyckeln.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:De som är bekanta med LUKS/dm-crypt har kanske lagt märke till att vi använde en LUKS-detacherad rubrik här. Normalt lagrar LUKS den lösenords-krypterade diskkrypteringsnyckeln på samma disk som data, men eftersom vi vill jämföra läs- och skrivprestanda mellan krypterade och okrypterade enheter kan vi råka skriva över den krypterade nyckeln av misstag under vår benchmarking senare. Genom att hålla den krypterade nyckeln i en separat fil undviks detta problem för det här inlägget.
Nu kan vi faktiskt ”låsa upp” den krypterade enheten för vår testning:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0I det här läget kan vi nu jämföra prestandan för krypterad respektive okrypterad ramdisk: om vi läser/skriver data till /dev/ram0, kommer den att lagras i klartext. På samma sätt, om vi läser/skriver data till /dev/mapper/encrypted-ram0, kommer den att dekrypteras/krypteras på vägen av dm-crypt och lagras i ciphertext.
Det är värt att notera att vi inte skapar något filsystem ovanpå våra blockenheter för att undvika att resultaten förvrängs av ett filsystems overhead.
Mätning av genomströmning
När det gäller lagringstestning/benchmarking är Flexible I/O tester den vanliga lösningen. Låt oss simulera enkel sekventiell läs- och skrivbelastning med 4K blockstorlek på ramdisken utan kryptering:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Ovanstående kommando kommer att köras under lång tid, så vi stoppar det bara efter ett tag. Som vi kan se i statistiken kan vi läsa och skriva ungefär med samma genomströmning runt 1126 MB/s. Låt oss upprepa testet med den krypterade ramdisk:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, det är en minskning! Vi får bara ~147 MB/s nu, vilket är mer än 7 gånger långsammare! Och detta är på en helt tomgångsmaskin!
Kanske är kryptot bara långsamt
Det första vi funderade på är att se till att vi använder det snabbaste kryptot. Med cryptsetup kan vi jämföra alla tillgängliga kryptoimplementationer i systemet för att välja den bästa:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/ADet verkar som om aes-xts med en 256-bitars datakrypteringsnyckel är den snabbaste här. Men vilken använder vi egentligen för vår krypterade ramdisk?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Vi använder faktiskt aes-xts med en 256-bitars datakrypteringsnyckel (räkna alla nollor som lämpligen maskeras av dmsetup-verktyget – om du vill se de faktiska bytena lägger du till --showkeys-alternativet till ovanstående kommando). Siffrorna går dock inte ihop: cryptsetup benchmark säger ovan att vi inte ska lita på resultaten, eftersom ”Testerna är ungefärliga och använder endast minne (inga lagrings-IO)”, men det är exakt så vi har satt upp vårt experiment med ramdisk. I ett något sämre fall (om vi antar att vi läser alla data och sedan krypterar/avkrypterar dem sekventiellt utan någon parallellitet) bör vi genom att göra back-of-the-envelope-beräkningar få omkring (1126 * 1823) / (1126 + 1823) =~696 MB/s, vilket fortfarande är ganska långt ifrån de faktiska 147 * 2 = 294 MB/s (totalt för läsningar och skrivningar).
dm-crypt performance flags
När vi läste man-sidan för cryptsetup märkte vi att den har två alternativ med prefixet --perf-, som troligen är relaterade till prestandainställning. Det första är --perf-same_cpu_crypt med en ganska kryptisk beskrivning:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Så vi aktiverar alternativet
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Notera: enligt den senaste man-sidan finns det också ett cryptsetup refresh-kommando, som kan användas för att aktivera dessa alternativ live utan att behöva ”stänga” och ”öppna” den krypterade enheten igen. Vår cryptsetup hade dock inte stöd för det ännu.
Verifiera om alternativet verkligen har aktiverats:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptJa, vi kan nu se same_cpu_crypt i utdata, vilket är vad vi ville. Låt oss köra benchmarken på nytt:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, nu är det ~136 MB/s vilket är något sämre än tidigare, så det är inte bra. Vad sägs om det andra alternativet --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Kanske är vi i ”någon situation” här, så låt oss prova det:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusOch nu är riktmärket:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, vilket är lite bättre, men fortfarande inte bra…
Sökande i samhället
Vi var desperata och bestämde oss för att söka stöd på Internet och postade våra resultat på sändlistan dm-crypt, men svaret vi fick var inte särskilt uppmuntrande:
Om siffrorna stör dig så beror det på bristande förståelse från din sida. Du är förmodligen inte medveten om att kryptering är en tung operation…
Vi bestämde oss för att göra en vetenskaplig undersökning om detta ämne genom att skriva ”is encryption expensive” i Google Search och ett av de främsta resultaten, som faktiskt innehåller meningsfulla mätningar, är… vårt eget inlägg om kostnaden för kryptering, men i samband med TLS! Det är en fascinerande läsning i sig själv, men kontentan är: modern krypto på modern hårdvara är mycket billigt även i Cloudflare-skalan (med miljontals krypterade HTTP-förfrågningar per sekund). Faktum är att det är så billigt att Cloudflare var den första leverantören som erbjöd gratis SSL/TLS för alla.
Digging into the source code
När vi försökte använda de anpassade dm-crypt-alternativen som beskrivs ovan blev vi nyfikna på varför de överhuvudtaget existerar och vad den där ”avlastningen” handlar om. Ursprungligen förväntade vi oss att dm-crypt skulle vara en enkel ”proxy”, som bara krypterar/avkrypterar data när den flödar genom stacken. Det visar sig att dm-crypt gör mer än att bara kryptera minnesbuffertar och ett (förenklat) IO traverse path diagram presenteras nedan:

När filsystemet utfärdar en skrivbegäran behandlar dm-crypt den inte omedelbart – i stället lägger den den i en arbetskö med namnet ”kcryptd”. I ett nötskal kan man säga att en kärnarbets kö bara schemalägger ett visst arbete (kryptering i det här fallet) för att utföras vid en senare tidpunkt, när det är mer lämpligt. När ”tiden” är inne skickar dm-crypt begäran till Linux Crypto API för själva krypteringen. Det moderna Linux Crypto API är dock också asynkront, så beroende på vilken implementering ditt system kommer att använda, kommer den sannolikt inte att behandlas omedelbart, utan köas igen till ”senare”. När Linux Crypto API slutligen utför krypteringen kan dm-crypt försöka sortera väntande skrivförfrågningar genom att placera varje förfrågan i ett röd-svart träd. Sedan tar en separat kärntråd återigen vid ”en viss tidpunkt senare” faktiskt alla IO-förfrågningar i trädet och skickar dem ner i stapeln.
Nu för läsförfrågningar: den här gången måste vi först få de krypterade uppgifterna från maskinvaran, men dm-crypt frågar inte bara efter drivrutinen för att få uppgifterna, utan ställer förfrågan i kö i en annan arbetskö som heter ”kcryptd_io”. Någon gång senare, när vi faktiskt har de krypterade uppgifterna, schemalägger vi dem för dekryptering med hjälp av den numera välkända ”kcryptd”-arbetskön. ”kcryptd” skickar begäran till Linux Crypto API, som också kan dekryptera data asynkront.
För att vara rättvis så passerar inte begäran alltid alla dessa köer, men det viktiga här är att skrivförfrågningar kan ställas i kö upp till 4 gånger i dm-crypt och läsförfrågningar upp till 3 gånger. Vid det här laget undrade vi om all denna extra köbildning kan orsaka några prestandaproblem. Det finns till exempel en trevlig presentation från Google om förhållandet mellan köbildning och latenstid. En viktig del av presentationen är:
En betydande del av svanslatensiteten beror på köeffekter
Så, varför finns alla dessa köer där och kan vi ta bort dem?
Git arkeologi
Ingen skriver mer komplicerad kod bara för skojs skull, särskilt inte för OS-kärnan. Så alla dessa köer måste ha placerats där av en anledning. Som tur är hanteras Linuxkärnans källkod av git, så vi kan försöka spåra ändringarna och besluten kring dem.
Arbetskön ”kcryptd” fanns i källkoden sedan början av den tillgängliga historiken med följande kommentar:
Behövs för att det skulle vara mycket oklokt att göra dekryptering i ett avbrottssammanhang, så bios som återvänder från läsförfrågningar hamnar i kö här.
Så det var bara för läsning, men även då – varför bryr vi oss om huruvida det är en avbrottskontext eller inte, om Linux Crypto API troligen kommer att använda en särskild tråd/kö för kryptering ändå? Tja, 2005 var Crypto API inte asynkron, så det här var helt logiskt.
2006 började dm-crypt använda ”kcryptd”-arbetsledet inte bara för kryptering, utan även för att skicka IO-förfrågningar:
Den här patchen är utformad för att hjälpa dm-crypt att följa de nya begränsningar som införs av följande patch i -mm: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Det verkar som om målet här inte var att lägga till mer samtidighet, utan snarare att minska kärnans stackanvändning, vilket är logiskt igen eftersom kärnan har en gemensam stack för all kod, så det är en ganska begränsad resurs. Det är dock värt att notera att Linux kernel stack har utökats 2014 för x86-plattformar, så detta kanske inte är ett problem längre.
En första version av ”kcryptd_io” workqueue lades till 2007 med avsikten att undvika:
hunger orsakad av många förfrågningar som väntar på minnesallokering…
Förfrågningsbehandlingen flaskade upp en enda workqueue här, så lösningen var att lägga till ytterligare en. Det låter vettigt.
Vi är definitivt inte de första som upplever prestandaförlust på grund av omfattande köbildning: 2011 infördes en ändring för att villkorligt återgå till en del av köbildningen för läsförfrågningar:
Om det finns tillräckligt med minne kan koden skicka in bio direkt i stället för att ställa den här operationen i kö i en separat tråd.
Olyckligtvis var Linux-kärnans commit-meddelanden på den tiden inte lika utförliga som idag, så det finns inga prestandadata att tillgå.
Under 2015 började dm-crypt sortera skrivningar i en separat ”dmcrypt_write”-tråd innan de skickas ner i stacken:
På en multiprocessormaskin avslutas krypteringsförfrågningar i en annan ordning än den de skickades in. Följaktligen skulle skrivförfrågningar skickas in i en annan ordning och det skulle kunna orsaka allvarlig prestandaförlust.
Det är logiskt eftersom sekventiell diskåtkomst brukade vara mycket snabbare än den slumpmässiga och dm-crypt bröt mönstret. Men detta gäller främst för snurrande diskar, som fortfarande var dominerande 2015. Det kanske inte är lika viktigt med moderna snabba SSD-diskar (inklusive NVME SSD-diskar).
En annan del av commit-meddelandet är värd att nämna:
…i synnerhet gör det det möjligt för IO-schedulatorer som CFQ att sortera effektivare…
Det nämns prestandafördelar för CFQ:s IO-schedulatorer, men Linux-schedulatorer har förbättrats sedan dess så till den grad att CFQ-schedulatorer har tagits bort från kärnan 2018.
I samma patchsats ersätts sorteringslistan med ett röd-svart träd:
I teorin ska sorteringen utföras av den underliggande diskschemaläggaren, men i praktiken tar diskschemaläggaren bara emot och sorterar ett begränsat antal förfrågningar. För att möjliggöra sortering av alla förfrågningar måste dm-crypt implementera sin egen sortering.
Den overhead som är förknippad med rbtree-baserad sortering anses försumbar, så den används inte villkorligt.
Allt detta är vettigt, men det skulle vara trevligt att ha några backingdata.
Interessant nog ser vi i samma patchset införandet av vårt välbekanta alternativ ”submit_from_crypt_cpus”:
Det finns vissa situationer där avlastning av skrivbios från krypteringstrådarna till en enskild tråd försämrar prestandan avsevärt
Sammanfattningsvis kan vi konstatera att varje ändring var rimlig och behövdes, men saker och ting har dock förändrats sedan dess:
- hårdvaran blev snabbare och smartare
- Linux resursallokering omprövades
- kopplade Linux-undersystem omarkitekturerades
Och många av designvalen ovan kanske inte är tillämpliga på moderna Linux.
”Clean-up”
Baserat på forskningen ovan bestämde vi oss för att försöka ta bort all extra köbildning och asynkront beteende och återgå till dm-crypts ursprungliga syfte: att helt enkelt kryptera/avkryptera IO-förfrågningar när de passerar. Men för stabilitetens och ytterligare benchmarkingens skull slutade det med att vi inte tog bort den faktiska koden utan lade till ännu ett dm-crypt-alternativ, som förbigår alla köer/trådar, om det är aktiverat. Flaggan gör det möjligt för oss att växla mellan det nuvarande och det nya beteendet vid körning under full produktionsbelastning, så att vi enkelt kan återkalla våra ändringar om vi skulle se några bieffekter. Den resulterande patchen finns på Cloudflare GitHub Linux repository.
Synkron Linux Crypto API
Från diagrammet ovan kommer vi ihåg att inte all köbildning är implementerad i dm-crypt. Moderna Linux Crypto API kan också vara asynkrona och för det här experimentets skull vill vi eliminera köer även där. Vad betyder dock ”kan vara”? Operativsystemet kan innehålla olika implementeringar av samma algoritm (till exempel hårdvaruaccelererad AES-NI på x86-plattformar och generiska AES-implementeringar i C-kod). Som standard väljer systemet den ”bästa” baserat på den konfigurerade algoritmprioriteten. dm-crypt gör det möjligt att åsidosätta detta beteende och begära en viss chifferimplementation med hjälp av prefixet capi:. Det finns dock ett problem. Låt oss faktiskt kontrollera de tillgängliga AES-XTS-implementationerna (detta är vårt disk-krypterings-chiffer, minns du?) på vårt system:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64Vi vill uttryckligen välja ett synkront chiffer från listan ovan för att undvika köeffekter i trådar, men de enda två som stöds är xts(ecb(aes-generic)) (den generiska C-implementationen) och __xts-aes-aesni (den x86-hårdvaruaccelererade implementationen). Vi vill definitivt ha den senare eftersom den är mycket snabbare (vi siktar på prestanda här), men den är misstänkt markerad som intern (se internal: yes). Om vi kontrollerar källkoden:
Markera ett chiffer som en tjänsteimplementation som endast kan användas av ett annat chiffer och aldrig av en normal användare av kärnans krypto-API
Det här chiffret är alltså tänkt att användas endast av annan omslagskod i krypto-API:et och inte utanför det. I praktiken innebär detta att den som anropar Crypto API uttryckligen måste ange denna flagga när han/hon begär en viss chifferimplementering, men dm-crypt gör det inte, eftersom det enligt konstruktionen inte är en del av Linux Crypto API, utan snarare en ”extern” användare. Vi patchar redan dm-crypt-modulen, så vi kan lika gärna bara lägga till den relevanta flaggan. Det finns dock ett annat problem med AES-NI i synnerhet: x86 FPU. ”Floating point” säger du? Varför behöver vi matematik med flytande punkter för att göra symmetrisk kryptering som bara borde handla om bitförskjutningar och XOR-operationer? Vi behöver inte matematiken, men AES-NI-instruktionerna använder en del av CPU-registren, som är avsedda för FPU. Tyvärr bevarar Linuxkärnan inte alltid dessa register i avbrottskontext av prestandaskäl (det är dyrt att spara/återställa FPU). Men dm-crypt kan exekvera kod i avbrottskontext, så vi riskerar att korrumpera någon annan processdata och vi återgår till ”det skulle vara mycket oklokt att utföra dekryptering i en avbrottskontext” i den ursprungliga koden.
Vår lösning för att ta itu med ovanstående var att skapa en annan något ”smart” Crypto API-modul. Denna modul är synkron och rullar inte sitt eget krypto, utan är bara en ”router” av krypteringsförfrågningar:
- Om vi kan använda FPU:n (och därmed AES-NI) i den aktuella exekveringskontexten, vidarebefordrar vi bara krypteringsbegäran till den snabbare, ”interna”
__xts-aes-aesniimplementationen (och vi kan använda den här, eftersom vi nu är en del av Crypto API) - I annat fall vidarebefordrar vi bara krypteringsbegäran till den långsammare, generiska C-baserade
xts(ecb(aes-generic))-implementationen
Användning av hela paketet
Låt oss gå igenom processen för att använda det hela tillsammans. Det första steget är att hämta patcherna och kompilera om kärnan (eller bara kompilera dm-crypt och våra xtsproxy-moduler).
Nästan ska vi starta om vår IO-arbetsbelastning i en separat terminal, så att vi kan försäkra oss om att vi kan konfigurera om kärnan vid körning under belastning:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...I huvudterminalen ska vi försäkra oss om att vår nya Crypto API-modul är laddad och tillgänglig:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Omkonfigurera den krypterade disken så att den använder vår nyligen inlästa modul och aktiverar vår patchade dm-crypt-flagga (vi måste använda dmsetup-verktyget på låg nivå eftersom cryptsetup uppenbarligen inte känner till våra modifieringar):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Vi har just ”laddat” den nya konfigurationen, men för att den ska träda i kraft måste vi avbryta/återuppta den krypterade enheten:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0Och observera nu resultatet. Vi kan gå tillbaka till den andra terminalen som kör fio-jobbet och titta på utdata, men för att göra saker och ting trevligare, här är en ögonblicksbild av den observerade läs-/skrivgenomströmningen i Grafana:
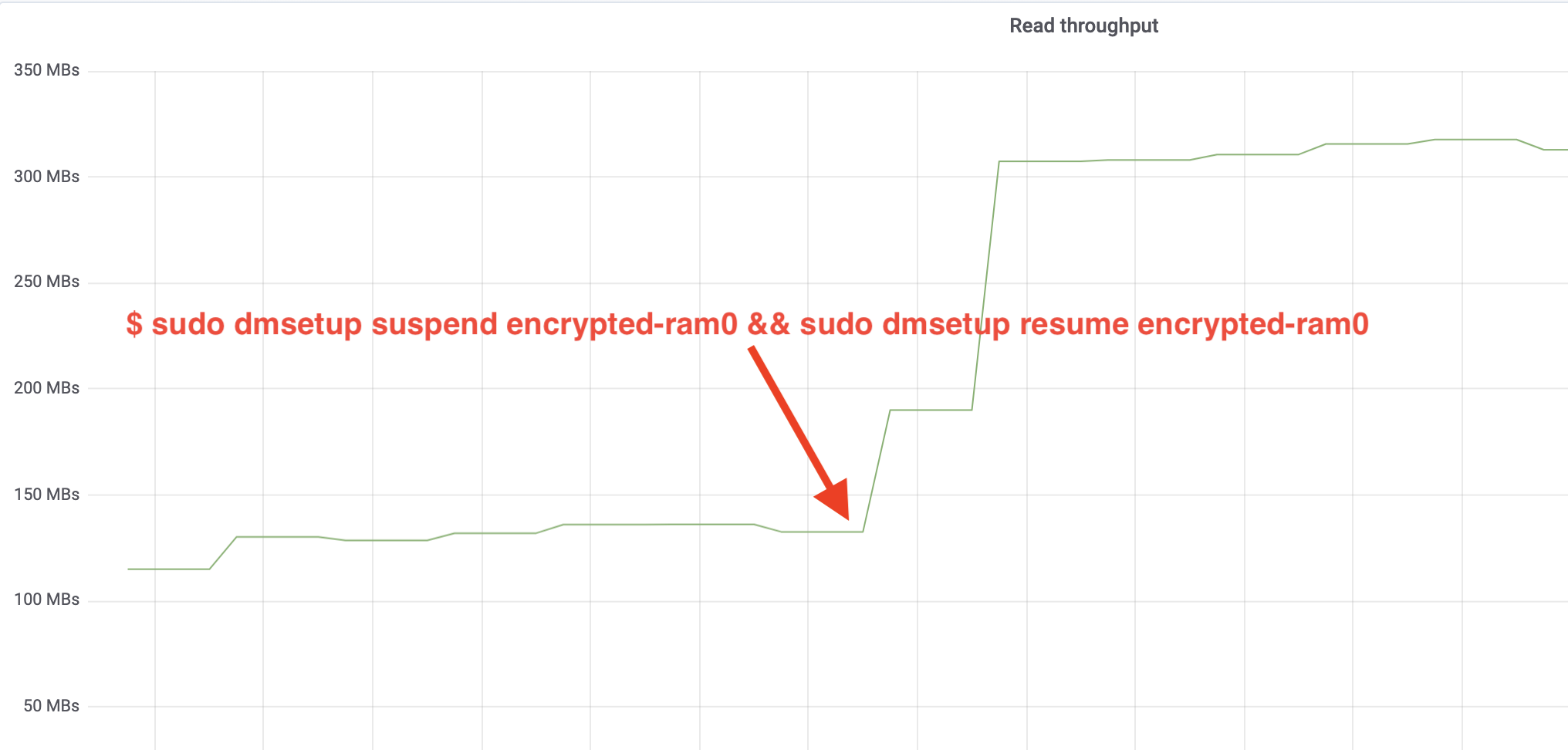
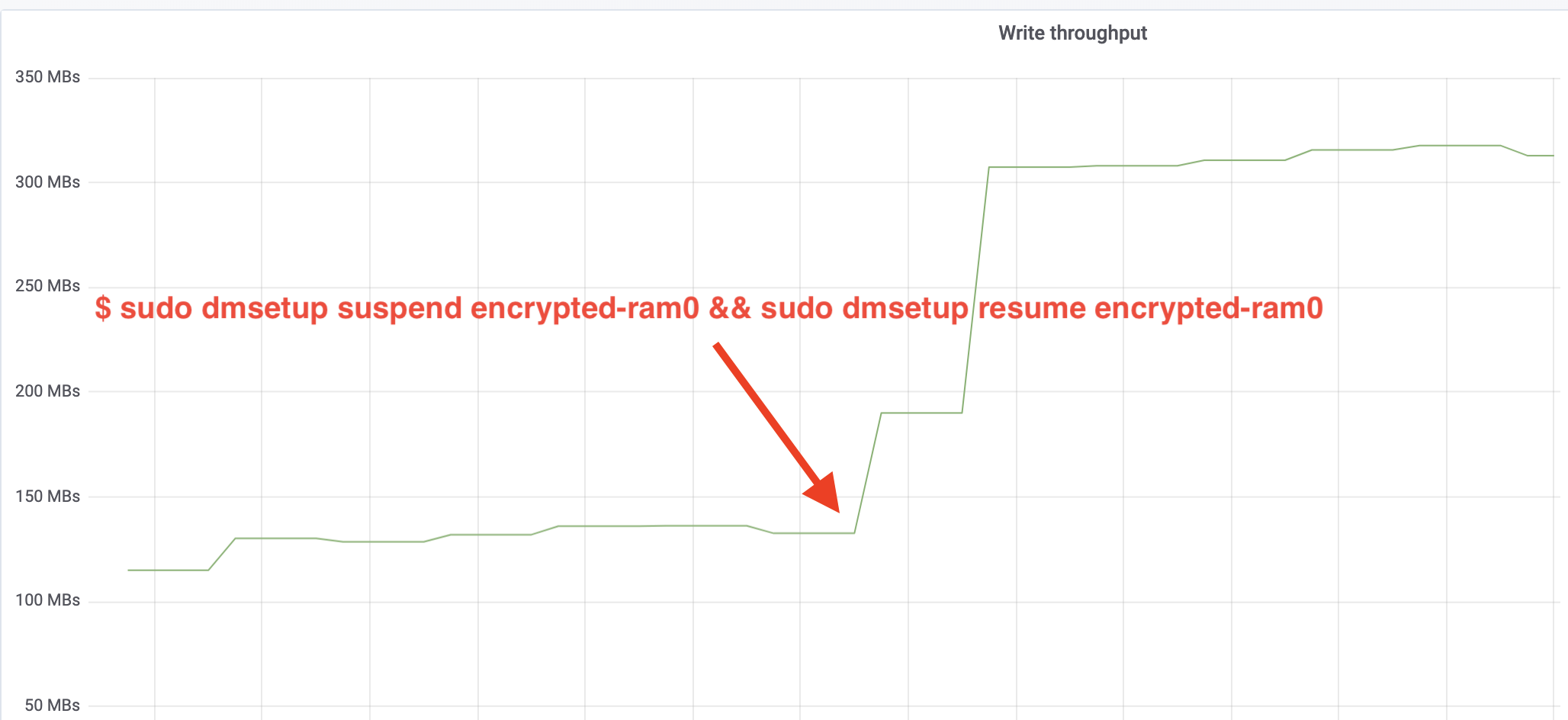
Wow, vi har mer än fördubblat genomströmningen! Med en total genomströmning på ~640 MB/s är vi nu mycket närmare det förväntade ~696 MB/s från ovan. Hur är det med IO-latenstiden? (Statistiken await från rapporteringsverktyget iostat):
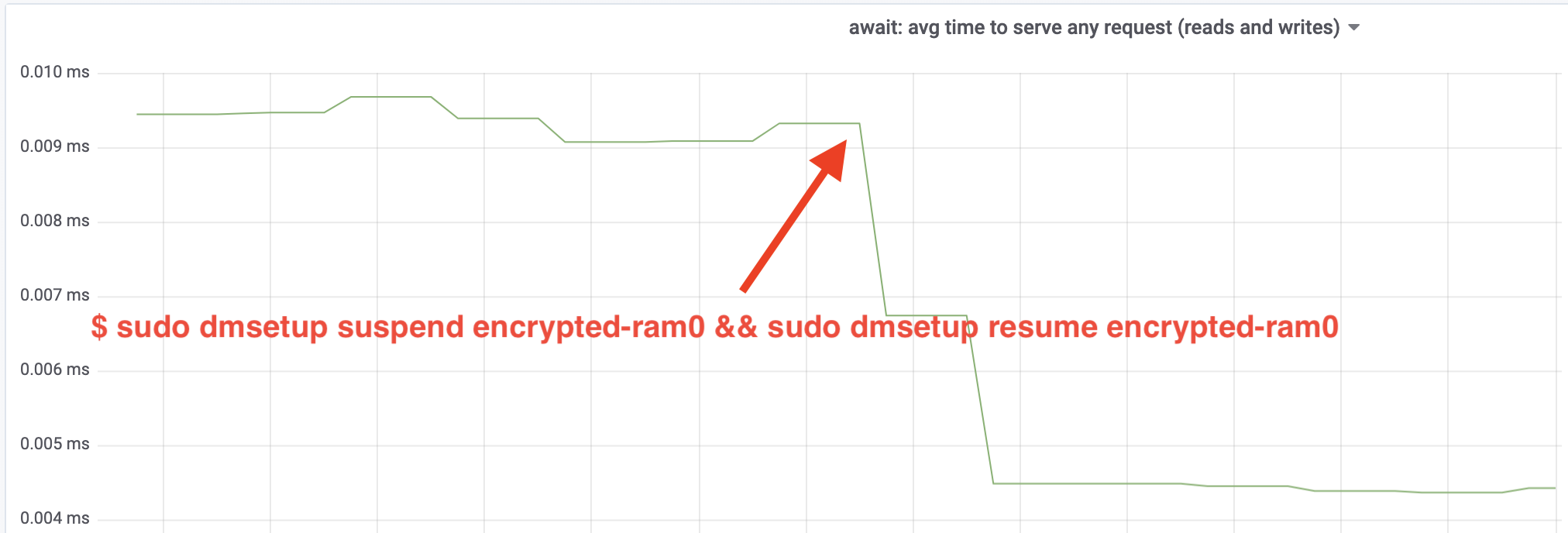
Latensiteten har också halverats!
Till produktion
Här långt har vi använt en syntetisk uppställning där vissa delar av hela produktionsstacken saknas, som filsystem, riktig hårdvara och viktigast av allt, produktionsarbetsbelastning. För att säkerställa att vi inte optimerar imaginära saker, är här en ögonblicksbild av den produktionseffekt som dessa ändringar ger till cachingdelen av vår stack:

Denna graf representerar en trevägsjämförelse av de värsta svarstiderna (99:e percentilen) för en cacheträff i en av våra servrar. Den gröna linjen är från en server med okrypterade diskar, som vi kommer att använda som baslinje. Den röda linjen är från en server med krypterade diskar med Linux standarddiskkryptering och den blå linjen är från en server med krypterade diskar och våra optimeringar aktiverade. Som vi kan se har standardimplementationen av Linux-diskkryptering en betydande inverkan på vår cachelatens i värsta fall, medan den patchade implementationen inte går att skilja från att inte använda kryptering överhuvudtaget. Med andra ord har den förbättrade krypteringsimplementationen ingen inverkan alls på vår svarshastighet i cacheminnet, så vi får den i princip gratis! Det är en vinst!
Vi har bara börjat
Detta inlägg visar hur en arkitekturöversyn kan fördubbla ett systems prestanda. Dessutom bekräftade vi återigen att modern kryptografi inte är dyrt och att det vanligtvis inte finns någon ursäkt för att inte skydda dina data.
Vi kommer att skicka in detta arbete för att inkluderas i kärnans huvudkällkodsträd, men troligtvis inte i sin nuvarande form. Även om resultaten ser uppmuntrande ut måste vi komma ihåg att Linux är ett mycket portabelt operativsystem: det körs på kraftfulla servrar såväl som på små IoT-enheter med begränsade resurser och på många andra CPU-arkitekturer också. Den nuvarande versionen av patcherna optimerar bara diskkryptering för en viss arbetsbelastning på en viss arkitektur, men Linux behöver en lösning som fungerar smidigt överallt.
Detta sagt, om du tror att ditt fall är liknande och du vill dra nytta av prestandaförbättringarna nu, kan du ta tag i patcherna och förhoppningsvis ge feedback. Körtidsflaggan gör det enkelt att växla funktionaliteten i farten och ett enkelt A/B-test kan utföras för att se om det gynnar ett visst fall eller en viss inställning. Dessa patchar har körts i vårt breda nätverk av mer än 200 datacenter på fem generationer av hårdvara, så de kan rimligen betraktas som stabila. Njut av både prestanda och säkerhet från Cloudflare för alla!

Uppdatering (11 oktober 2020)
Den viktigaste patchen från den här bloggen (i en något uppdaterad form) har lagts in i Linuxkärnan och är tillgänglig från och med version 5.9 och framåt. Den största skillnaden är att mainline-versionen exponerar två flaggor istället för en, vilket ger möjlighet att kringgå dm-crypt-arbetsköer för läs- och skrivningar oberoende av varandra. För mer information, se den officiella dm-crypt-dokumentationen.