Det finns många stora fördelar med att virtualisera infrastrukturen och köra virtuella resurser för att hantera affärskritiska arbetsbelastningar. När det gäller VMware vSphere erbjuder den många anmärkningsvärda funktioner och möjligheter som ger hög tillgänglighet i miljön samt automatiserad schemaläggning av arbetsuppgifter för att säkerställa den mest effektiva användningen av hårdvara och resurser i din vSphere-miljö.
I det här inlägget kommer vi att tala om två av de centrala funktionerna på klusternivå i vSphere i företag – vSphere HA och DRS. Du har med största sannolikhet sett båda dessa refereras tillsammans med körning av vSphere i företaget.
Vad är vSphere HA och DRS? Vad gör de?
Hur har du nytta av att köra båda i din vSphere-miljö?
Låt oss ta en titt på en grundläggande introduktion till HA och DRS i VMware vSphere och se hur de är jämförbara och vilka fördelar det finns med att använda dem.
VMware vSphere Clusters
En av de uppenbara fördelarna och bästa metoderna när man använder VMware vSphere för att köra affärskritiska arbetsbelastningar är att köra ett vSphere Cluster.
Vad är ett vSphere-kluster?
Ett vSphere-kluster är en konfiguration av mer än en VMware ESXi-server som aggregeras tillsammans som en pool av resurser som bidrar till vSphere-klustret. Resurser som CPU-beräkning, minne och, när det gäller mjukvarudefinierad lagring som vSAN, lagring, bidrar varje ESXi-värd.
Varför är det viktigt att köra dina affärskritiska arbetsbelastningar ovanpå ett vSphere-kluster?
När man tänker på fördelarna med att köra en hypervisor kan fler än en server köras ovanpå en enda uppsättning fysisk maskinvara. Att virtualisera arbetsbelastningar på det här sättet ger många effektivitetsfördelar i storleksordningar jämfört med att köra en enda server på en enda uppsättning fysisk hårdvara.
Det här kan dock också bli akilleshälen för en virtualiserad lösning, eftersom effekten av ett hårdvarufel kan påverka många fler affärskritiska tjänster och applikationer. Du kan föreställa dig att om du bara har en enda VMware ESXi-värd som kör många virtuella maskiner, skulle konsekvenserna av att förlora den enda ESXi-värden bli enorma.
Det är här som körning av flera VMware ESXi-värdar i ett vSphere Cluster verkligen briljerar.
Hursomhelst kanske du frågar dig själv, hur kan det att bara köra flera värdar i ett kluster förbättra din höga tillgänglighet? Hur ”vet” en värd i vSphere Cluster om en annan värd har gått sönder? Finns det en särskild mekanism som används för att ta hand om hanteringen av hög tillgänglighet för arbetsbelastningar som körs på ett vSphere Cluster? Ja, det finns det. Låt oss se.
Vad är HA i VMware?
VMware insåg behovet av att ha en mekanism för att kunna ge skydd mot en misslyckad ESXi-värd i vSphere Cluster. Med detta behov föddes VMware High-Availability (HA).
VMware vSphere HA ger följande fördelar:
VMware vSphere HA är kostnadseffektivt och möjliggör automatiska omstarter av virtuella maskiner och vSphere-värdar när ett serveravbrott eller ett operativsystemfel upptäcks i vSphere-miljön
Övervakar alla VMware vSphere-värdar & VM:s i vSphere Cluster
Levererar hög tillgänglighet till de flesta applikationer som körs i virtuella maskiner, oberoende av operativsystem och applikationer.
Skönheten med VMwares vSphere HA-lösning som implementeras via VMware Cluster är den enkelhet med vilken den kan konfigureras. Med några få klick genom ett guide-drivet gränssnitt kan hög tillgänglighet konfigureras. Hur står detta i jämförelse med traditionell ”klusterteknik”
Windows Server Failover Clustering Comparison
Windows Server Failover Clustering (WSFC) har blivit den klusterteknik som de flesta tänker på när de har klusterteknik i åtanke. Problemet med WSFC är att det krävs mycket specialiserad expertis för att köra WSFC-tjänsterna korrekt, särskilt när det gäller uppgraderingar, patching och allmänna operativa uppgifter.
Vid jämförelse mellan vSphere HA och WSFC är driftskostnaden minimal i jämförelse med WSFC. Det finns liten chans att HA kan konfigureras felaktigt eftersom det antingen är aktiverat på ett kluster eller inte. Med WSFC finns det många överväganden som måste göras när man konfigurerar WSFC för att undvika både konfigurations- och implementeringsfel. Tänk på följande:
- Failover clustering kräver applikationer som stödjer kluster (SQL, etc)
- Failover clustering kräver att quorum är korrekt konfigurerat
- Stöds inte av många äldre operativsystem och applikationer
- Kräver komplexitet i klusterns nätverksnamn, resurser och nätverk
Windows Server Failover Clustering marknadsförs för att ge nästan noll nedtid på applikationsnivå. Men när man lägger till den expertis som krävs för en korrekt fungerande HA-lösning, tillsammans med korrekt implementering av WSFC, kan riskerna börja uppväga fördelarna med att använda WSFC för hög tillgänglighet för applikationer och tjänster. Detta gäller särskilt för de flesta organisationer som kanske inte verkligen behöver en ”nolltidslösning”. Dessutom måste din applikation utformas för att dra nytta av WSFC och fungera korrekt med WSFC-tekniken.
Vi behöver visserligen starta om de virtuella maskinerna på en frisk värddator när en felövergång inträffar, men det krävs ingen installation av ytterligare programvara i de virtuella gästmaskinerna, inga komplexa konfigurationer av ytterligare klusterteknik och applikationer eller operativsystem behöver inte utformas för att fungera med en viss klusterteknik.
Legacy-operativsystem och -program har i allmänhet begränsade möjligheter när det gäller teknik som stöds för att ge hög tillgänglighet. Så det kan bokstavligen inte finnas några naturliga alternativ för att tillhandahålla failover-funktionalitet vid maskinvarufel.
Högtillgänglighetsmekanismen vSphere HA fungerar och är enkel att implementera, konfigurera och hantera. Dessutom är detta en teknik som är väl testad i tusentals VMware-kundmiljöer, så den har en stabil och lång historia av framgångsrika driftsättningar.
Generell översikt över vSphere HA:s beteende
Med hjälp av fördelarna för ESXi-värdarna i ett vSphere Cluster implementerar vSphere HA, i sin mest grundläggande form, en övervakningsmekanism mellan värdarna i vSphere Cluster. Övervakningsmekanismen ger ett sätt att avgöra om någon värd i vSphere Cluster har gått sönder.
I infografiken nedan har ett vSphere Cluster med två noder drabbats av ett fel på en av ESXi-värdarna i vSphere Cluster. I vSphere Cluster är vSphere HA aktiverat på klusternivå.
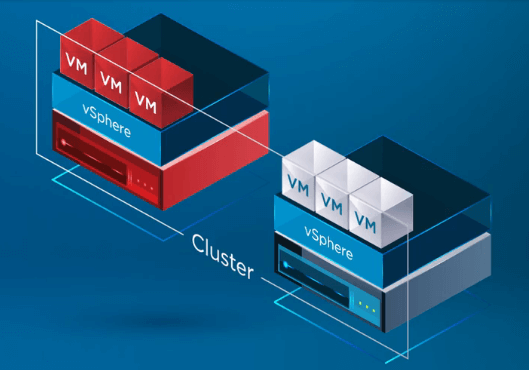
När vSphere HA upptäcker att en värddator i vSphere Cluster har misslyckats flyttar HA-processen registreringen av virtuella maskiner från den misslyckade värddatorn över till en frisk värddator.
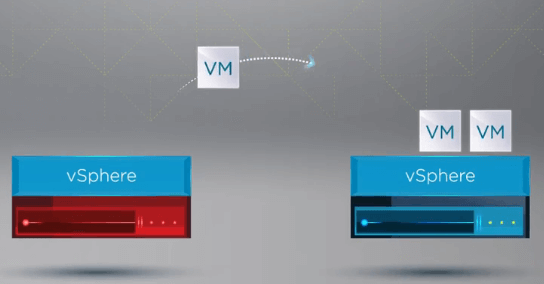
När de virtuella maskinerna har registrerats på en frisk värddator startar vSphere HA om alla virtuella maskiner från den misslyckade värddatorn på en frisk ESXi-värd i klustret där de virtuella maskinerna registrerades på nytt. Den enda nedtid som uppstår är vid omstarten av de virtuella maskinerna på en frisk värd i vSphere-klustret.
VSphere HA Teknisk översikt
Förutsättningar för vSphere HA
Du kan undra vilka underliggande förutsättningar som kan krävas för att vSphere HA ska fungera. Behöver du bara ett VMware Cluster för att aktivera HA? Till skillnad från Windows Server Failover Clustering är det bara några få krav som måste finnas på plats för att HA ska fungera.
Krav:
- Minst två ESXi-värdar
- Minst 4 GB minne konfigurerat på varje värd
- vCenter Server
- vSphere Standard License
- Delad lagring för virtuella maskiner
- Pingable gateway eller annan pålitlig nätverksnod
Om du märker, krävs ingen quorumkomponent, ingen komplex nätverksnamngivning och inga andra speciella klusterresurser som måste finnas på plats.
Läs mer: Hur du konfigurerar ett vSphere High Availability Cluster
VMware vSphere HA Master vs Subordinate Hosts
När du aktiverar vSphere HA i ett kluster utses en viss värd i vSphere Cluster till master för vSphere HA. De återstående ESXi-värdarna i vSphere Cluster konfigureras som underordnade i vSphere HA-konfigurationen.
Vilken roll spelar den ESXi-värd i vSphere HA som utsetts till huvudvärd? Master-noden för vSphere HA:
- Övervakar tillståndet för de slaviska underordnade värddatorerna – Om den underordnade värddatorn misslyckas eller är omöjlig att nå identifierar master-värden vilka virtuella maskiner som behöver startas om
- Övervakar strömtillståndet för alla virtuella maskiner som är skyddade. Om en virtuell maskin går sönder ser master vSphere HA-noden till att den virtuella maskinen startas om. Master-noden för vSphere HA bestämmer var omstarten av den virtuella maskinen sker (vilken ESXi-värd).
- Håller reda på alla klustervärdar och virtuella maskiner som skyddas av vSphere HA
- Är utsedd till medlare mellan vSphere Cluster och vCenter Server. HA-mastern rapporterar klusterhälsan till vCenter och tillhandahåller hanteringsgränssnittet till klustret för vCenter Server
- Kan själv köra virtuella maskiner och övervaka statusen för virtuella maskiner
- Lagrar skyddade virtuella maskiner i klusterets datastores
vSphere HA Subordinate Hosts:
- Kör virtuella maskiner lokalt
- Övervaka körtidsstatusen för de virtuella maskinerna i vSphere Cluster
- Rapportera statusuppdateringar till vSphere HA-mastern
Väljning av huvudvärd och fel på huvudvärd
Hur väljs huvudvärd för vSphere HA? När vSphere HA aktiveras för ett kluster deltar alla aktiva värddatorer (inget underhållsläge etc.) i valet av huvudvärd. Om den valda huvudvärden misslyckas sker ett nytt val där en ny HA-mästarvärd väljs för att fylla den rollen.
VMware vSphere HA Cluster Failure Types
I ett vSphere HA-aktiverat kluster finns det tre typer av fel som kan inträffa för att utlösa en vSphere HA failover-händelse. Dessa typer av värdfel är:
- Fel – Ett fel är intuitivt vad du tror. En värd har slutat fungera i någon form eller på något sätt på grund av maskinvara eller andra problem.
- Isolering – Isoleringen av en värd sker i allmänhet på grund av en nätverkshändelse som isolerar en viss värd från de andra värddatorerna i vSphere HA-klustret.
- Partition – En partitionshändelse kännetecknas av att en underordnad värd förlorar nätverksanslutningen till huvudvärden i vSphere HA-klustret.
Hjärtslag, upptäckt av fel och åtgärder vid fel
Hur avgör huvudnoden om det finns ett fel på en viss värd?
Det finns flera olika mekanismer som huvudnoden använder för att avgöra om en värddator har misslyckats:
- Mästarnoden utbyter nätverkshjärtslag med de andra värddatorerna i klustret varje sekund.
- När nätverkshjärtslaget har misslyckats kontrollerar huvudvärden för kontroll av värdens livskraft.
- Kontrollen av värdens livskraft fastställer om den underordnade värddatorn utbyter hjärtslag med en av datastorerna. Därefter skickas ICMP-pings till IP-adresserna för hantering
- Om det inte går att kommunicera direkt med HA-agenten för en underordnad värddator från huvudvärddatorn och ICMP-pings till hanteringsadressen misslyckas, betraktas värddatorn som misslyckad och virtuella maskiner startas om på en annan värddator.
- Om det visar sig att den underordnade värddatorn utbyter hjärtslag med datalageret antar huvudvärddatorn att värddatorn befinner sig i en nätverkspartition eller är nätverksisolerad. I det här fallet övervakar huvudvärden helt enkelt värddatorn och de virtuella maskinerna
- Nätverksisolering är händelsen där en underordnad värddator körs, men inte längre kan ses från ett HA-hanteringsagentperspektiv i hanteringsnätverket. Om en värddator slutar att se den här trafiken försöker den pinga klusterisoleringsadresserna. Om detta ping misslyckas förklarar värden att den är isolerad från nätverket
- I detta fall övervakar huvudnoden de virtuella maskiner som körs på den isolerade värden. Om de virtuella maskinerna stängs av på den isolerade värden startar huvudnoden om de virtuella maskinerna på en annan värd
Datastore Heartbeating
Som nämnts ovan är en av de mätvärden som används för att avgöra feldetektering datastore heartbeating. Vad är detta exakt? VMware vCenter väljer en föredragen uppsättning datastores för heartbeating. Därefter skapar vSphere HA en katalog vid roten av varje datalagret som används både för heartbeating av datalagret och för att hålla reda på listan över skyddade virtuella maskiner. Den här katalogen heter .vSphere-HA.
Det finns en viktig notering att komma ihåg när det gäller vSAN-datastores. En vSAN-databas kan inte användas för datastore heartbeating. Om du bara har en vSAN-datalagring tillgänglig kan inga heartbeat-datalagringar användas.
- Övervakning av virtuella maskiner och program
En annan extremt kraftfull funktion i vSphere HA är möjligheten att övervaka enskilda virtuella maskiner via VMware Tools och starta om virtuella maskiner som inte svarar på VMware Tools hjärtslag. Programövervakning kan starta om en virtuell maskin om hjärtslag för ett program som körs inte tas emot.
- VM-övervakning – Med VM-övervakning använder VM-övervakningstjänsten VMware Tools för att avgöra om varje virtuell maskin körs genom att kontrollera både hjärtslag och disk-I/O som genereras av VMware Tools. Om dessa kontroller misslyckas fastställer VM Monitoring-tjänsten att gästoperativsystemet sannolikt har misslyckats och VM startas om. Den extra disk-I/O-kontrollen hjälper till att undvika onödiga återställningar av virtuella maskiner om de virtuella maskinerna eller programmen fortfarande fungerar som de ska.
Approgramövervakning – Funktionen för programövervakning aktiveras genom att skaffa lämplig SDK från en tredjepartsleverantör av programvara som gör det möjligt att ställa in anpassade hjärtslag för de program som ska övervakas av vSphere HA-processen. Precis som i processen för övervakning av virtuella maskiner återställs den virtuella maskinen om hjärtslag för applikationer slutar att tas emot.
Båda dessa övervakningsfunktioner kan konfigureras ytterligare med övervakningskänslighet och även maximal återställning per virtuell maskin för att undvika att återställa virtuella maskiner upprepade gånger på grund av programvarufel eller falskt positiva fel.
VMware vSphere HA är ett utmärkt sätt att se till att ditt vSphere-kluster ger en mycket motståndskraftig hög tillgänglighet för att skydda mot generella värddatorfel för ESXi-värdarna i ditt vSphere-kluster.
Hur är det med att säkerställa en effektiv användning av resurser i ditt vSphere-kluster? Låt oss ta en titt på nästa vSphere Cluster-bestämmelse för att säkerställa effektiv användning av dina vSphere Cluster-resurser och kapacitet.
Vad är DRS i VMware?
VMware Distributed Resource Scheduler (DRS) är en riktigt kraftfull funktion när du kör vSphere Clusters. Den tillhandahåller schemaläggning och lastbalansering i ett vSphere Cluster. VMware DRS är den funktion som finns i vSphere Clusters som ser till att virtuella maskiner som körs i din vSphere-miljö får de resurser de behöver för att kunna köras effektivt och ändamålsenligt.
VM:er är i allmänhet föremål för DRS tidigt i livet eftersom DRS placerar de virtuella maskinerna på den bästa värddatorn som är konfigurerad för att tillhandahålla de resurser som krävs för den virtuella maskinen så snart de är påslagna. Dessutom strävar DRS efter att hålla vSphere-kluster balanserade ur ett resursanvändningsperspektiv.
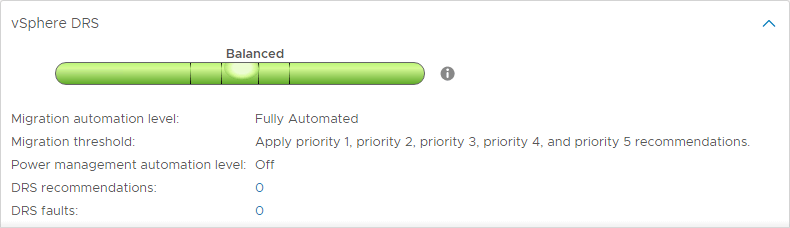
Även om ett vSphere-kluster är balanserat vid en viss tidpunkt kan virtuella maskiner flyttas runt eller förändras på ett sådant sätt att en obalans av klusterresurser kan smyga sig in i miljön igen. När kluster blir obalanserade kan det vara skadligt för den totala prestandan hos virtuella maskiner som körs i ett vSphere Cluster.
Som standard körs DRS automatiskt på ett vSphere-kluster var femte minut för att fastställa balansen i ett vSphere-kluster och se om några ändringar måste göras för att resurserna ska kunna användas mer effektivt.
Krav för VMware DRS
För att dra nytta av VMware DRS finns det flera krav som måste uppfyllas för att man ska kunna dra nytta av funktionaliteten Distributed Resource Scheduler. Dessa inkluderar:
- Ett kluster av ESXi-värdar
- vCenter Server
- Enterprise Plus-licens
- vMotion krävs för automatisk belastningsbalansering
Läs mer: Hur du konfigurerar ett vSphere DRS-kluster
VMware DRS-åtgärder
När VMware DRS körs på ett vSphere-kluster var femte minut, fastställs det om det finns några obalanser i klustret. Om så är fallet utförs en vMotion för att flytta utsedda virtuella maskiner från en ESXi-värd till en annan.
Hur exakt avgör DRS om virtuella maskiner passar bättre på en ESXi-värd eller en annan?
DRS kör en särskild algoritm för att avgöra vilken ESXi-värd som är den rätta för en viss virtuell maskin. När en virtuell maskin startas tar algoritmen hänsyn till resursfördelningen i vSphere-klustret efter att den säkerställer att det inte förekommer några överträdelser av begränsningar om en viss virtuell maskin placeras på en viss ESXi-värd.
Den virtuella maskinens egen efterfrågan beaktas dessutom så att den virtuella maskinen förhoppningsvis aldrig blir svältfödd på resurser när den sätts på. Vad ingår i efterfrågan på den virtuella maskinen? En VM:s efterfrågan omfattar den mängd resurser som behövs för att köras.
- För CPU-behovet beräknas detta baserat på mängden CPU som den virtuella maskinen för närvarande använder
- För minnet beräknas behovet baserat på formeln: För minnesbehov används följande formel: VM-minnesbehov = Funktion(Aktivt minne som används, utbytt, delat) + 25 % (inaktivt förbrukat minne). Detta visar att DRS:s minnesbalans huvudsakligen baseras på den virtuella maskinens aktiva minnesanvändning, samtidigt som en liten del av det inaktiva förbrukade minnet beaktas som en buffert för en eventuell ökning av arbetsbelastningen.
DRS automatiseringsnivåer
En av de intressanta funktionerna i DRS är DRS-automatiseringsnivåerna. Medan DRS fortsätter att skanna vSphere Cluster och ge rekommendationer var femte minut kan du bestämma om DRS ska kunna genomföra sina rekommendationer automatiskt eller bara föreslå ändringar som bör göras. DRS har tre DRS-automatiseringsnivåer. Dessa inkluderar:
- Helt automatiserad – I det helt automatiserade tillvägagångssättet tillämpar DRS både rekommendationerna för initial placering och lastbalansering automatiskt
- Delvis automatiserad – Med partiell automatisering tillämpar DRS rekommendationerna endast för initial placering av virtuella maskiner
- Manuell – I manuellt läge, måste du tillämpa rekommendationerna för både första placering och lastbalansering
DRS Migration Thresholds
DRS innehåller en annan mycket användbar inställning för att styra hur mycket obalans som ska tolereras innan DRS rekommendationer görs. Det finns fem tröskelvärden för DRS-migrering för att kontrollera hur mycket obalans som tolereras.
Insatserna sträcker sig från 1 (mest konservativ) till 5 (mest aggressiv).
Med mer aggressiva inställningar tolererar DRS mindre obalans i ett kluster. Ju mer konservativ, desto mer tolererar DRS obalans.

VMware DRS VM/Host-regler
Det finns en extremt användbar funktion som du hittar när du använder VMware DRS för att styra placeringen av virtuella maskiner i dina vSphere DRS-aktiverade kluster. Med VM/Host-reglerna kan du köra specifika virtuella maskiner på specifika ESXi-värdar. Du kan tänka på detta som affinitetsregler på ett sätt.
Med VM/Host-reglerna kan du:
- Hålla virtuella maskiner tillsammans
- Separera virtuella maskiner
- Binda virtuella maskiner till specifika värdar
- Binda virtuella maskiner till virtuella maskiner
Nedan visas ett exempel på hur du kan skapa en VM/Host-regel för virtuella maskiner och ESXi-värdar.
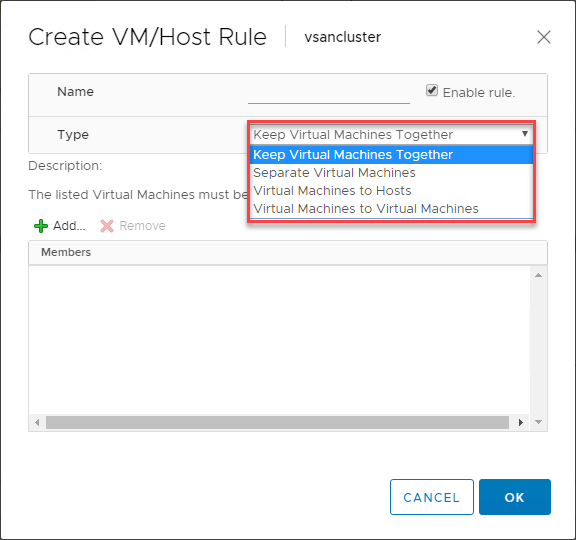
Vilken typ av användningsfall finns för dessa VM/Host-regler? Ett av de klassiska användningsfallen är domänkontrollanter. Om du kör alla dina domänkontrollanter i en virtualiserad miljö, t.ex. ett vSphere-kluster, vill du se till att dina virtuella maskiner för domänkontrollanter är separerade från varandra i klustret. Om en ESXi-värd går ner tillsammans med en av dina domänkontrollanter har du fortfarande en domänkontrollant som omfattas av en regel för separata virtuella maskiner som håller den borta från samma värd som en annan virtuell kontrollant.
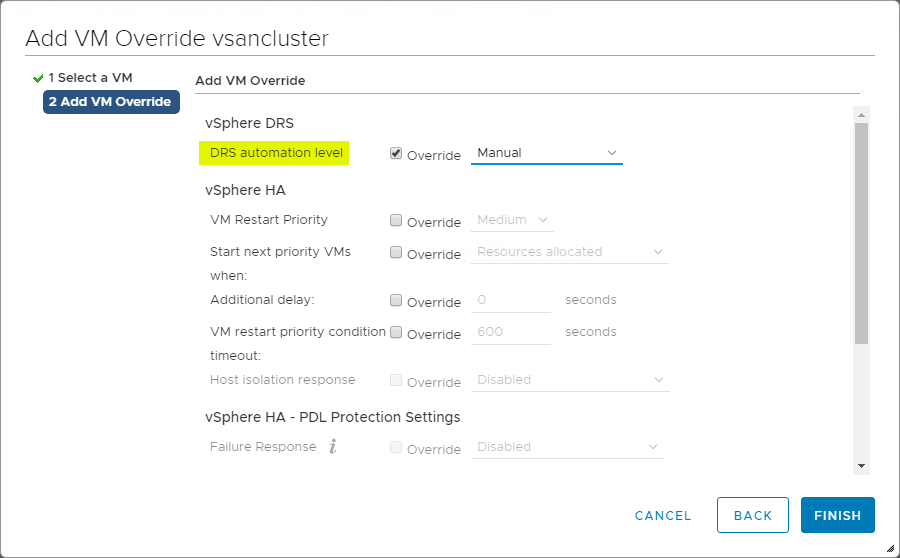
VM Overrides for DRS
VSphere Cluster ger en stor granularitet för åtgärder som påverkar enskilda virtuella maskiner i vSphere Cluster. Du kan skapa VM-overrides för att åsidosätta globala inställningar som fastställts på klusternivå för HA och DRS för att definiera mer specifika inställningar för varje enskild VM.
CPU and Memory Utilization Summary
DRS ger en bra översikt på hög nivå av CPU-utnyttjandets sammanfattning av CPU-resurserna för ESXi-värdarna i vSphere Cluster. Navigera till > Inställningar > Övervakning > vSphere DRS > CPU-utnyttjande.
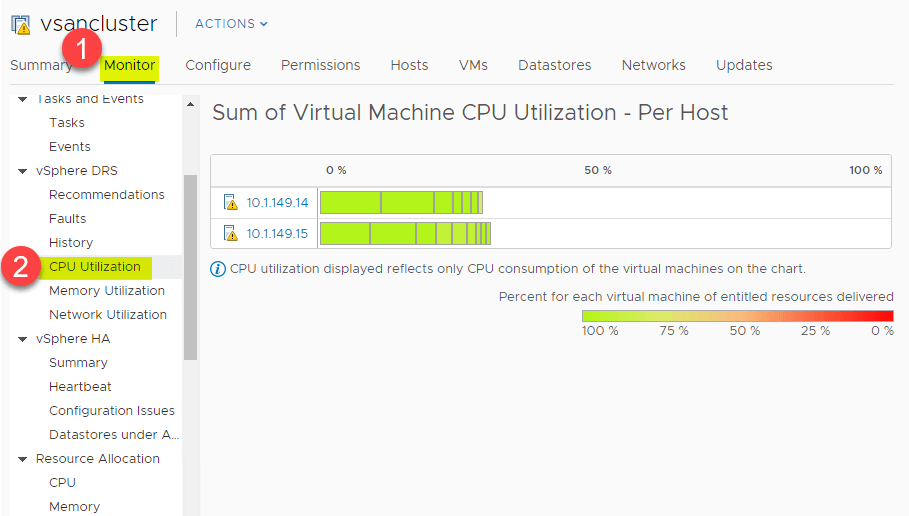
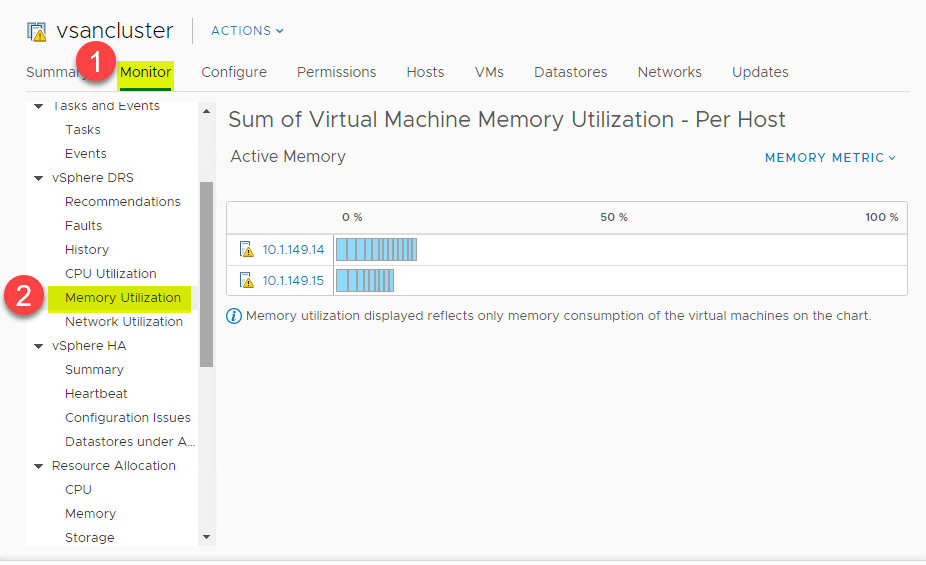
Den samma översikt på hög nivå kan även ses för minnesförbrukning. Navigera till > Inställningar > Övervaka > vSphere DRS > Minnesutnyttjande
Det bästa av två världar
Är VMware vSphere HA och VMware DRS konkurrerande teknologier?
Nej, det är de inte. Faktum är att det rekommenderas starkt att använda både vSphere HA och VMware DRS tillsammans för att kombinera automatisk växling vid fel med funktioner och funktioner för lastbalansering. Detta resulterar i en mycket mer motståndskraftig och balanserad vSphere-miljö.
Om ett fel inträffar på en ESXi-värd startar vSphere HA om de virtuella maskinerna på de återstående friska värddatorerna i ett vSphere-kluster. Så den första prioriteringen är naturligtvis tillgången till resurser för virtuella maskiner. VMware DRS kommer sedan att köra och avgöra om det finns någon obalans mellan de ESXi-värdar som kör arbetsbelastningarna och kommer att ge rekommendationer för att lösa eventuella obalanser i klustret baserat på den konfigurerade migrationströskeln. Baserat på automatiseringsnivån kommer dessa rekommendationer antingen att åtgärdas automatiskt eller endast rekommenderas om de inte är helt automatiserade.
Avslutande tankar om VMware vSphere HA och DRS
Att köra både VMware vSphere HA och DRS rekommenderas starkt i ett vSphere-kluster i produktion. Att använda båda teknikerna bidrar till att göra dina arbetsbelastningar högtillgängliga och säkerställer att de kontinuerligt har de resurser som krävs baserat på den virtuella maskinens krav på CPU och minne.
En förståelse för hur de båda mekanismerna fungerar hjälper dig som vSphere-administratör att utnyttja båda teknikerna på bästa möjliga sätt och i enlighet med bästa praxis. Bland de fördelar som båda teknikerna medför är att varje funktion är extremt enkel att aktivera och konfigurera. Med några enkla klick i egenskaperna för dina vSphere-kluster kan du snabbt börja dra nytta av dessa tillgängliga funktioner på klusternivå.
Följ våra Twitter- och Facebook-flöden för nya versioner, uppdateringar, insiktsfulla inlägg och mycket mer.