Introduktion
Om du analyserar dina data med hjälp av multipel regression och någon av de oberoende variablerna mättes på en nominal- eller ordinalskala, måste du veta hur du skapar dummyvariabler och tolkar deras resultat. Detta beror på att nominella och ordinala oberoende variabler, mer allmänt kända som kategoriska oberoende variabler, inte kan föras in direkt i en multipel regressionsanalys. I stället måste de omvandlas till dummyvariabler. Undantaget är ordinala oberoende variabler som förs in i en multipel regressionsanalys som kontinuerliga oberoende variabler, vilka inte behöver omvandlas till dummyvariabler. I den här guiden visar vi därför hur man skapar dummyvariabler när man har kategoriska oberoende variabler.
Först beskriver vi det exempel som vi använder för att visa hur man skapar dummyvariabler i SPSS Statistics, innan vi förklarar hur man ställer in data i fönstren Variable View (Variabelvisning) och Data View (Datavyn) i SPSS Statistics så att man kan skapa dummyvariabler. Om du inte är bekant med användningen av dummyvariabler rekommenderar vi att du läser om några av de grundläggande principerna för dummyvariabler och dummykodning, bland annat: (a) hur många dummyvariabler du behöver skapa i din analys och b) hur du skapar dummyvariabler och dummykodning. I avsnittet Procedur som följer beskriver vi den enkla trestegsproceduren Skapa dummyvariabler i SPSS Statistics som kan användas för att skapa dummyvariabler. Slutligen förklarar vi SPSS Statistics utdata efter att ha kört Create Dummy Variables-proceduren, inklusive hur dina dummyvariabler nu kommer att ställas in i fönstren Variable View och Data View i SPSS Statistics.
Anm.: Om du upptäcker att procedurerna i den här guiden inte täcker den typ av dummyvariabler som du vill skapa, vänligen kontakta oss. Vi kanske kan lägga till en annan guide på webbplatsen för att hjälpa till.
SPSS Statistics
Exempel som används i den här guiden
I den här guiden kommer vi att använda exemplet med 10 triathleter som ombads att välja sin favoritsport bland de tre sporter som de utför när de utför en triathlon: simning, cykling och löpning. Deras svar registrerades i den nominella oberoende variabeln favourite_sport, som har tre kategorier: ”simning”, ”cykling” och ”löpning”. Denna nominella oberoende variabel, favourite_sport, skulle ingå i en multipel regressionsanalys som också innehöll ett antal kontinuerliga oberoende variabler. Eftersom denna oberoende variabel var kategorisk (dvs. nominella variabler och ordinala variabler kan i stort sett klassificeras som kategoriska variabler) måste dummyvariabler skapas innan den kunde tas med i den multipla regressionsanalysen.
Viktigt: Observera att favourite_sport är en nominell variabel, men det går också att skapa dummyvariabler för en ordinell variabel. Dessutom är processen för att skapa dummyvariabler densamma oavsett om du har en ordinal- eller nominalvariabel, med undantag för en liten ändring som du måste göra när du ställer in dina data, vilket förklaras nedan.
Anm. 1: ”Kategorierna” i en kategorisk oberoende variabel kallas också ”grupper” eller ”nivåer”, men termen ”nivåer” reserveras vanligen för kategorier som har en ordning (t.ex. kan den ordinella oberoende variabeln, ”konditionsnivå”, ha tre nivåer: ”låg”, ”måttlig” och ”hög”). Dessa tre termer – ”kategorier”, ”grupper” och ”nivåer” – kan dock användas omväxlande. I den här guiden kommer vi att hänvisa till dem som kategorier, men du kan hänvisa till dem som grupper eller nivåer om du föredrar det.
Anm. 2: Termen ”faktorer” används ibland i stället för ”kategoriska oberoende variabler” (dvs. oberoende variabler som är ”ordinala” eller ”nominella”). Dessa två termer – ”kategoriska oberoende variabler” och ”faktorer” – kan dock användas omväxlande. I den här guiden kommer vi att hänvisa till dem som kategoriska oberoende variabler och du kommer också att se SPSS Statistics hänvisa till dem som oberoende variabler i stället för faktorer i sitt förfarande för multipel regression. Du kan dock hänvisa till dem som faktorer om du föredrar det.
SPSS Statistics
Inställning av data i SPSS Statistics
När du skapar dummyvariabler börjar du med en enda kategorisk oberoende variabel (t.ex. favourite_sport). För att ställa in denna kategoriska oberoende variabel har SPSS Statistics en variabelvy där du definierar vilka typer av variabler du analyserar och en datavy där du anger dina data för denna variabel. I det här avsnittet visar vi först hur du ställer in en kategorisk oberoende variabel i fönstret Variable View i SPSS Statistics, innan vi visar hur du anger dina data i fönstret Data View. Vi gör detta med hjälp av vår kategoriska oberoende variabel, favourite_sport, som har tre kategorier: ”simning”, ”cykling” och ”löpning”.
Vyn för variabler i SPSS Statistics
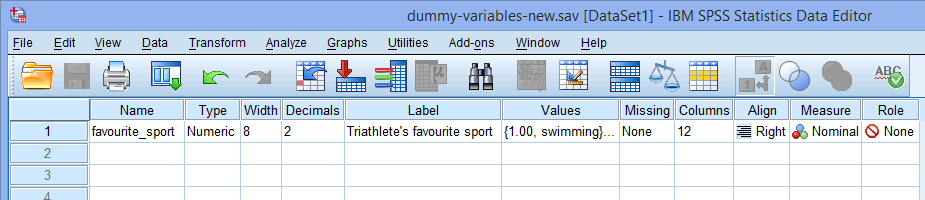
För en enda kategorisk oberoende variabel (t.ex, favourite_sport) ser fönstret Variable View ut som nedan:
Note: Du kan komma åt fönstret Variable View i SPSS Statistics genom att klicka på fliken ![]() i det nedre vänstra hörnet av SPSS Statistics-programmet.
i det nedre vänstra hörnet av SPSS Statistics-programmet.
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Namnet på din kategoriska oberoende variabel ska skrivas in i cellen under kolumnen ![]() (t.ex, ”favourite_sport” i rad
(t.ex, ”favourite_sport” i rad ![]() för att representera vår kategoriska oberoende variabel, favourite_sport. Det finns vissa ”olagliga” tecken som inte kan anges i cellen
för att representera vår kategoriska oberoende variabel, favourite_sport. Det finns vissa ”olagliga” tecken som inte kan anges i cellen ![]() . Om du därför får ett felmeddelande och vill att vi ska lägga till en SPSS Statistics-guide för att förklara vad dessa olagliga tecken är, vänligen kontakta oss.
. Om du därför får ett felmeddelande och vill att vi ska lägga till en SPSS Statistics-guide för att förklara vad dessa olagliga tecken är, vänligen kontakta oss.
Anmärkning: För din egen tydlighet kan du också ange en etikett för dina variabler i kolumnen ![]() . Den etikett vi angav för ”favourite_sport” var till exempel ”Triathlete’s favourite sport”.
. Den etikett vi angav för ”favourite_sport” var till exempel ”Triathlete’s favourite sport”.
Cellen under kolumnen ![]() ska innehålla information om kategorierna för din kategoriska oberoende variabel (t.ex. ”swimming”, ”cycling” och ”running” för favourite_sport. För att ange denna information klickar du i cellen under kolumnen
ska innehålla information om kategorierna för din kategoriska oberoende variabel (t.ex. ”swimming”, ”cycling” och ”running” för favourite_sport. För att ange denna information klickar du i cellen under kolumnen ![]() för din oberoende variabel. Knappen
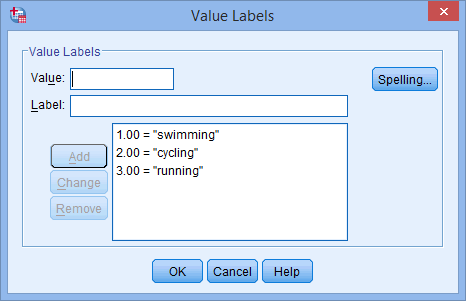
för din oberoende variabel. Knappen ![]() kommer att visas i cellen. Klicka på denna knapp och dialogrutan Värdeetiketter visas. Du måste nu ge varje kategori av din oberoende variabel ett ”värde”, som du anger i rutan Värde: (t.ex. ”1”), samt en ”etikett”, som du anger i rutan Etikett: (t.ex. ”simning”). Genom att klicka på knappen
kommer att visas i cellen. Klicka på denna knapp och dialogrutan Värdeetiketter visas. Du måste nu ge varje kategori av din oberoende variabel ett ”värde”, som du anger i rutan Värde: (t.ex. ”1”), samt en ”etikett”, som du anger i rutan Etikett: (t.ex. ”simning”). Genom att klicka på knappen ![]() kommer kodningen att visas i huvudrutan (t.ex. ”1.00=”simning” för favourite_sport). Inställningen för vår kategoriska oberoende variabel visas i dialogrutan Value Labels nedan:
kommer kodningen att visas i huvudrutan (t.ex. ”1.00=”simning” för favourite_sport). Inställningen för vår kategoriska oberoende variabel visas i dialogrutan Value Labels nedan:
Publicerad med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Cellen under kolumnen ![]() bör visa
bör visa ![]() om du har en nominell oberoende variabel (t.ex, favourite_sport, som i vårt exempel) eller
om du har en nominell oberoende variabel (t.ex, favourite_sport, som i vårt exempel) eller ![]() om du har en ordinal oberoende variabel (t.ex. tänk dig en ordinalvariabel som ”Body Mass Index” (BMI), BMI), som har fyra nivåer: ”Undervikt”, ”hälsosam/normal vikt”, ”övervikt” och ”fetma”). Slutligen bör cellen under kolumnen
om du har en ordinal oberoende variabel (t.ex. tänk dig en ordinalvariabel som ”Body Mass Index” (BMI), BMI), som har fyra nivåer: ”Undervikt”, ”hälsosam/normal vikt”, ”övervikt” och ”fetma”). Slutligen bör cellen under kolumnen ![]() visa
visa ![]() .
.
Anmärkning: Vi föreslår att cellen under kolumnen ![]() ändras från
ändras från ![]() till
till ![]() , men du behöver inte göra denna ändring. Vi föreslår att du gör det eftersom det finns vissa analyser i SPSS Statistics där inställningen
, men du behöver inte göra denna ändring. Vi föreslår att du gör det eftersom det finns vissa analyser i SPSS Statistics där inställningen ![]() resulterar i att dina variabler automatiskt överförs till vissa fält i de dialogrutor du använder. Eftersom du kanske inte vill överföra dessa variabler föreslår vi att du ändrar inställningen
resulterar i att dina variabler automatiskt överförs till vissa fält i de dialogrutor du använder. Eftersom du kanske inte vill överföra dessa variabler föreslår vi att du ändrar inställningen ![]() till
till ![]() så att detta inte sker automatiskt.
så att detta inte sker automatiskt.
Du har nu framgångsrikt matat in all information som SPSS Statistics behöver veta om din kategoriska oberoende variabel i fönstret Variable View. I nästa avsnitt visar vi hur du matar in dina data i fönstret Data View.
Datavyn i SPSS Statistics
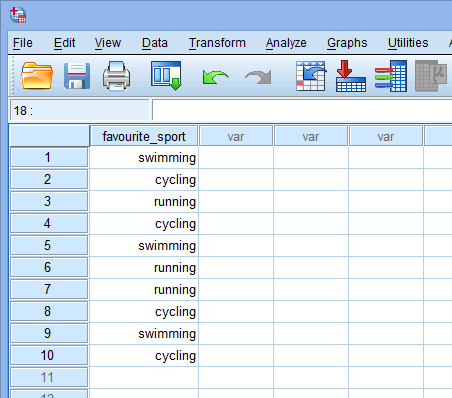
Baserat på filinställningen för din kategoriska oberoende variabel i fönstret Variable View ovan ser fönstret Data View ut på följande sätt:
Anm.: Du kommer åt fönstret Data View i SPSS Statistics genom att klicka på fliken ![]() i det nedre vänstra hörnet av SPSS Statistics-programmet.
i det nedre vänstra hörnet av SPSS Statistics-programmet.
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Din kategoriska oberoende variabel kommer att visas i den första kolumnen eftersom det var i den ordningen som vi skrev in variabeln i fönstret Variable View. I vårt exempel presenteras svaren från de 10 triathleterna under kolumnen ![]() . Nu behöver du bara skriva in dina data i cellerna under denna första kolumn. Kom ihåg att varje rad representerar ett fall (ett fall kan t.ex. vara en enskild deltagare). I rad
. Nu behöver du bara skriva in dina data i cellerna under denna första kolumn. Kom ihåg att varje rad representerar ett fall (ett fall kan t.ex. vara en enskild deltagare). I rad ![]() i vårt exempel representerar därför det första fallet en triathlet vars favoritsport är ”simning”. Eftersom dessa celler till en början kommer att vara tomma måste du klicka i cellerna för att skriva in dina uppgifter. Du kommer att märka att när du klickar i cellerna under kolumnen
i vårt exempel representerar därför det första fallet en triathlet vars favoritsport är ”simning”. Eftersom dessa celler till en början kommer att vara tomma måste du klicka i cellerna för att skriva in dina uppgifter. Du kommer att märka att när du klickar i cellerna under kolumnen ![]() kommer SPSS Statistics att ge dig ett rullgardinsalternativ där dina kategorier redan är ifyllda.
kommer SPSS Statistics att ge dig ett rullgardinsalternativ där dina kategorier redan är ifyllda.
Nu när du har ställt in dina data i fönstren Variable View (variabelvisning) och Data View (datavyn) i SPSS Statistics rekommenderar vi att du läser nästa avsnitt: Förståelse för dummyvariabler och dummykodning, där vi förklarar de grundläggande principerna för dummyvariabler och dummykodning. Om du dock redan är bekant med grunderna för dummyvariabler och dummykodning kan du hoppa över det här avsnittet och gå direkt till proceduravsnittet där vi beskriver proceduren Create Dummy Variables (Skapa dummyvariabler) i SPSS Statistics som används för att skapa dummyvariabler.
SPSS Statistics
Förståelse av dummyvariabler och dummykodning
Som vi nämnde i inledningen måste du veta hur man skapar dummyvariabler och tolkar deras resultat om du analyserar dina data med hjälp av multipel regression och någon av dina oberoende variabler mättes på en nominell eller ordinal skala. Detta beror på att kategoriska oberoende variabler (dvs. nominella och ordinala oberoende variabler) inte kan föras in direkt i en multipel regression. I stället måste de omvandlas till dummyvariabler. Undantaget är ordinala oberoende variabler som förs in i en multipel regression som kontinuerliga oberoende variabler, vilka inte behöver omvandlas till dummyvariabler. I avsnitten nedan förklarar vi detta: (a) hur många dummyvariabler du behöver skapa och (b) hur du skapar dummyvariabler och dummykodning.
Antalet dummyvariabler du behöver skapa
Antalet dummyvariabler du behöver skapa beror på hur många kategorier din kategoriska oberoende variabel har. Som en allmän regel ska du skapa en mindre dummyvariabel än antalet kategorier i din kategoriska oberoende variabel. Om du till exempel har en kategorisk oberoende variabel med tre kategorier (t.ex. favorite_sport, med följande tre kategorier: ”simning”, ”cykling” och ”löpning”), skapar du två dummyvariabler och väljer en kategori som referenskategori (t.ex. blir ”simning” och ”cykling” dummyvariabler och ”löpning” blir referenskategori). Vi förklarar mer om referenskategorier efter följande tabell, som ger några exempel på kategoriska oberoende variabler och antalet dummyvariabler som måste skapas:
| Namn på den kategoriska oberoende variabeln | Typ av variabel | Antal kategorier | Antal dummyvariabler | ||||
|---|---|---|---|---|---|---|---|
| 1 | Genus | Nominellt | Två (Män & Kvinnor) |
En=Män ”Kvinnor” är referenskategori |
|||
| 2 | Höjd | Ordinell | Två (Under 180cm & 180cm och över) |
Ett=Under 180cm ”180cm och över” är referenskategorin |
|||
| 3 | Ethnicitet | Nominell | Tre (Afroamerikan, Caucasian & Hispanic) |
Two=African American & Caucasian ”Hispanic” är referenskategorin |
|||
| 4 | Fysisk aktivitetsnivå | Ordinal | Three (Low, Måttlig & Hög) |
Två=Låg & Måttlig ”Hög” är referenskategorin |
|||
| 5 | Profession | Nominell | Fyra (Kirurg, Läkare, Sjuksköterska & Terapeut) |
Tre=Kirurg, Läkare & Sjuksköterska ”Terapeut” är referenskategorin |
|||
| 6 | Intyckesnivå | Ordinal | Fyra (Instämmer helt, Instämmer, Instämmer inte, Instämmer inte alls) |
Tre=Stark instämmer, Instämmer & Instämmer inte ”Instämmer inte alls” är referenskategorin |
|||
| 7 | Syfteområde | Nominellt | Fem (Företagsekonomi, Psykologi, biologi, teknik & juridik) |
Fyra=affärsvetenskap, psykologi, biologi & teknik ”Juridik” är referenskategori |
|||
| 8 | Ålder | Ordinal | Fem (Under 18 år, 19-30, 31-40, 41-50, 51-60) |
Fyra=Under 18, 19-30, 31-40 & 41-50 ”51-60” är referenskategorin |
|||
| Tabell: Exempel på kategoriska oberoende variabler och deras respektive dummyvariabler | |||||||
Som framgår av tabellen ovan behöver du bara skapa en dummyvariabel mindre än antalet kategorier i din kategoriska oberoende variabel. Detta beror på att du bara behöver (och bör) överföra detta antal dummyvariabler till en multipel regression när du har en kategorisk oberoende variabel. Det finns dock goda skäl att skapa en dummyvariabel för varje kategori i den kategoriska oberoende variabeln: (a) det är mer flexibelt och (b) det gör det möjligt att göra flera jämförelser (se anmärkningen nedan). Med andra ord, om din kategoriska oberoende variabel har tre kategorier skulle du skapa tre dummyvariabler, inte bara två.
Tyvärr skapar proceduren Skapa dummyvariabler i SPSS Statistics version 22 och senare automatiskt en dummyvariabel för varje kategori av din kategoriska oberoende variabel. Detta gäller dock inte för proceduren Recode into Different Variables i SPSS Statistics version 21 eller tidigare. Under normala omständigheter kommer du därför att ha skapat följande uppställning i SPSS Statistics, beroende på om du har version 21 eller tidigare eller version 22 eller senare:
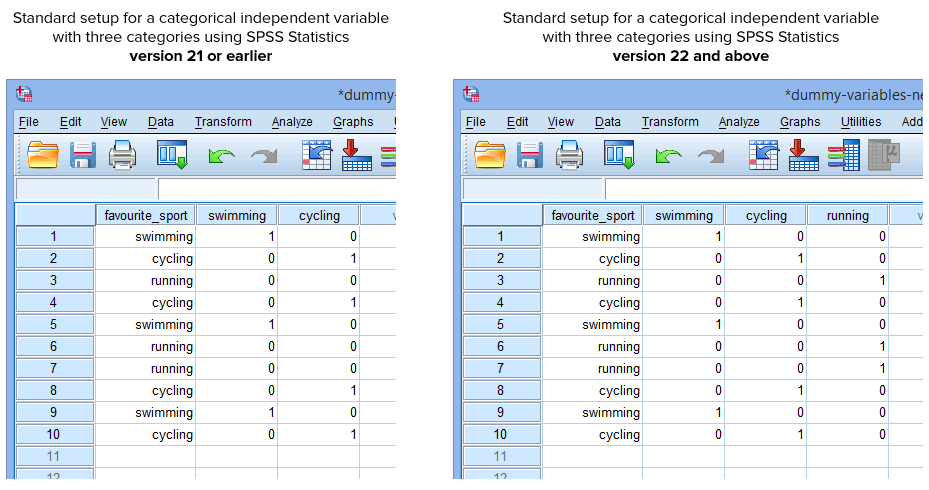
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Notera: Som nämnts ovan är det fördelaktigt att skapa en dummy-variabel för varje kategori av den kategoriska oberoende variabeln av två skäl: (a) det är mer flexibelt och (b) det gör det möjligt att göra flera jämförelser. Vi berör kortfattat dessa fördelar nedan:
Det är mer flexibelt:
När du har skapat en dummyvariabel för varje kategori i din kategoriska oberoende variabel kan du sedan betrakta vilken kategori som helst som en referenskategori. I vårt exempel betraktade vi kategorin ”löpning” som referenskategori, vilket innebär att vi skulle ha överfört ”simning” och ”cykling” till den multipla regressionsekvationen. Om vi senare ändrar oss om vårt val av referenskategori måste vi dock köra dummyvariabelförfarandet igen (om du inte har SPSS Statistics version 22 eller senare). Låt oss till exempel anta att vi nu vill använda kategorin ”cykling” som referenskategori. Vi skulle nu kunna överföra dummyvariablerna ”simning” och ”löpning” till ekvationen för multipel regression eftersom vi också har dummyvariabeln ”löpning”.
Det gör det möjligt att göra flera jämförelser:
Koefficienten för en dummyvariabel representerar skillnaden mellan den kategori som dummyvariabeln representerar och referenskategorin. Med ”löpning” som referenskategori representerar t.ex. koefficienten för dummyvariabeln ”simning” skillnaden i den beroende variabeln mellan kategorierna ”simning” och ”löpning”. Med denna metod är inte alla kombinationer av kategorier möjliga. Detta problem kan lösas genom att använda olika referenskategorier. Detta är möjligt om alla kategorier av den kategoriska variabeln har en dummyvariabel.
Hur man skapar dummyvariabler och dummykodning
Det finns två steg för att framgångsrikt inrätta dummyvariabler i en multipel regression: (1) skapa dummyvariabler som representerar kategorierna för din kategoriska oberoende variabel, och (2) ange värden i dessa dummyvariabler – så kallad dummykodning – för att representera kategorierna för den kategoriska oberoende variabeln. Vi förklarar denna process nedan med hjälp av det exempel som vi gav ovan.
Förklaring: Dummyvariabler är helt enkelt nya variabler som fungerar som ”platshållare” för ett visst kodningsschema. De innehåller i sig inga uppgifter alls. I stället måste uppgifter/värden läggas till dessa dummyvariabler så att de kan uppfylla sitt syfte att representera kategorierna för din kategoriska oberoende variabel. Det finns många olika typer av kodningsscheman som bestämmer vilka värden som ska föras in i dummyvariablerna, men vi använder ett mycket vanligt kodningsschema som kallas dummykodning eller alternativt indikatorkodning (bli inte förvirrad, för dummyvariabler och dummykodning är inte samma sak). Dummy-kodning fungerar genom att varje dummy-variabel används för att identifiera en specifik kategori av en kategorisk oberoende variabel med undantag för en referenskategori, som vi förklarar nedan.
Låt oss börja med att betrakta vårt exempel på en kategorisk oberoende variabel, favourite_sport, som har tre kategorier: ”simning”, ”cykling” och ”löpning”. Eftersom det finns tre kategorier måste det finnas två dummyvariabler som representerar två av kategorierna och en referenskategori som representerar den tredje kategorin.
Notera: Kom ihåg från diskussionen ovan att en multipel regression kräver att du överför en dummyvariabel mindre än antalet kategorier i din kategoriska oberoende variabel (dvs. två i vårt exempel). Du kan dock skapa en dummyvariabel för varje kategori i den kategoriska oberoende variabeln för att få större flexibilitet och möjlighet att göra flera jämförelser. I diskussionen nedan lyfter vi ändå bara fram det som krävs för en multipel regression, det vill säga skapandet av en dummyvariabel mindre än antalet kategorier i din kategoriska oberoende variabel, där den kategori som inte är direkt representerad blir ”referenskategori”.
Till exempel, låt dummyvariabel nr 1 representera kategorin ”simning” och dummyvariabel nr 2 representera kategorin ”cykling”. Då återstår ingen dummyvariabel för kategorin ”löpning”. Denna ”saknade” kategori är referenskategorin och behövs inte. Dessutom är det helt och hållet ditt beslut vilken kategori du vill använda som referenskategori. Vi kunde lika gärna ha valt kategorin ”simning” som referenskategori i stället för kategorin ”löpning”. Den enda anledningen till att vi inte gjorde det är att SPSS Statistics som standard använder den sista kategorin som du har kodat i variabelvyn för din kategoriska oberoende variabel som referenskategori (se anmärkningen nedan).
Anmärkning: Som förklarats i avsnittet Datainställningar tidigare och som visas nedan i dialogrutan Värdeetiketter var den tredje och sista kategorin för vår kategoriska oberoende variabel ”löpning” (dvs, 3=”running”).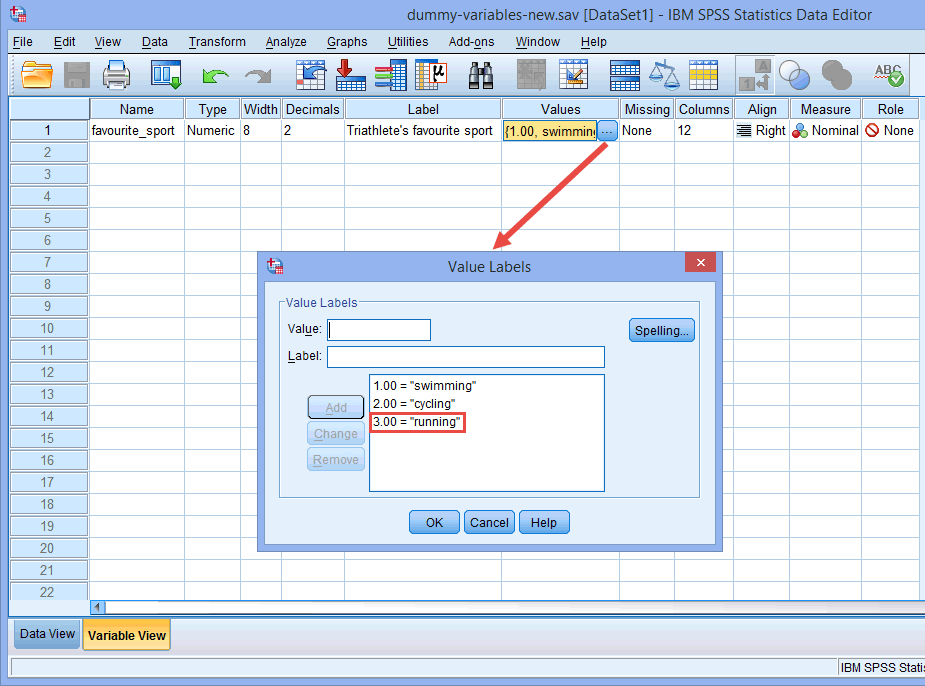
Det fanns ingen teoretisk eller statistisk anledning för oss att göra kategorin ”running” till den tredje och sista kategorin, vilket gjorde den till referenskategori i SPSS Statistics som standard. Vi gjorde helt enkelt så här eftersom när triathleter deltar i en triathlon, gör de först simningen, sedan cyklar de, innan de slutligen springer till mållinjen. Därför verkade det logiskt att koda vår kategoriska oberoende variabel på detta sätt. Vi kunde dock ha kodat den som 1=cykling, 2=löpning och 3=simning; det skulle inte ha gjort någon skillnad förutom det faktum att ”simning” som tredje och sista kategori skulle ha blivit vår referenskategori som standard i SPSS Statistics.
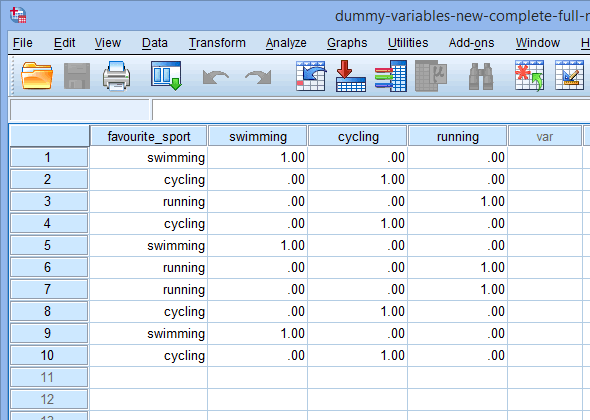
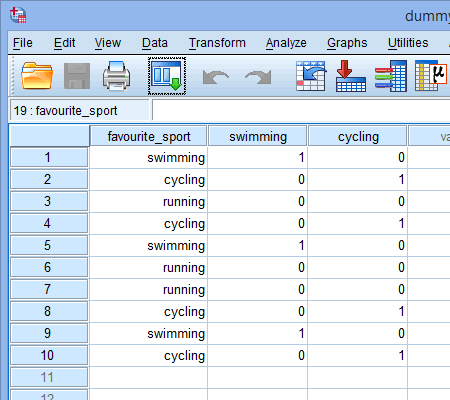
När du skapar dummyvariabler bör du ge dem ett meningsfullt namn. Eftersom var och en av våra dummyvariabler representerar en kategori av vår kategoriska oberoende variabel är det vanligt att hänvisa till varje dummyvariabel med namnet på den kategori den representerar. Därför har vi kallat dummyvariabel nr 1 ”simning” eftersom den representerar kategorin simning. På samma sätt har vi kallat dummyvariabel nr 2 ”cykling” eftersom den representerar kategorin cykling. Genom att skapa dessa två dummyvariabler får vi två nya kolumner i vår datamängd i SPSS Statistics, enligt nedan:
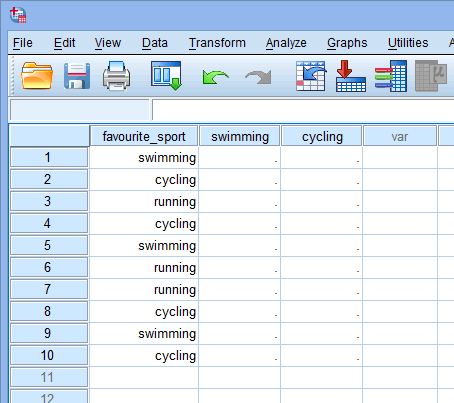
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Nu när vi har skapat två dummyvariabler och givit dem lämpliga namn måste vi ange värden i dessa variabler så att varje dummyvariabel verkligen representerar sin kategori av den kategoriska oberoende variabeln. Med dummy-kodning är detta mycket enkelt. Du anger en ”1” för att representera varje fall (t.ex. en deltagare i din datamängd) som har kategorin och anger en ”0” (noll) om de inte har kategorin. Först tar vi dummyvariabeln ”simning” som visas nedan:
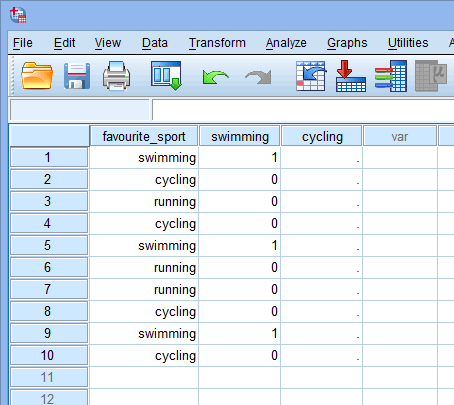
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Om en av triathleterna uppgav att ”simning” var deras ”favoritsport”, skulle vi skriva in en ”1” i cellen under kolumnen för dummyvariabeln ”simning” (![]() ) för den triathlonspelare som uppgav att simning var deras ”favoritsport”. Om en av triathleterna uppgav att ”cykling” eller ”löpning” var deras ”favoritsport”, skulle vi i cellen under kolumnen för dummyvariabeln för simning (
) för den triathlonspelare som uppgav att simning var deras ”favoritsport”. Om en av triathleterna uppgav att ”cykling” eller ”löpning” var deras ”favoritsport”, skulle vi i cellen under kolumnen för dummyvariabeln för simning (![]() ) ange en ”0” för den triathlet som uppgav att simning ”inte” var deras favoritsport (det betyder att antingen ”cykling” eller ”löpning” var den triathletens favoritsport). Detta markeras nedan för alla 10 triathleter:
) ange en ”0” för den triathlet som uppgav att simning ”inte” var deras favoritsport (det betyder att antingen ”cykling” eller ”löpning” var den triathletens favoritsport). Detta markeras nedan för alla 10 triathleter:
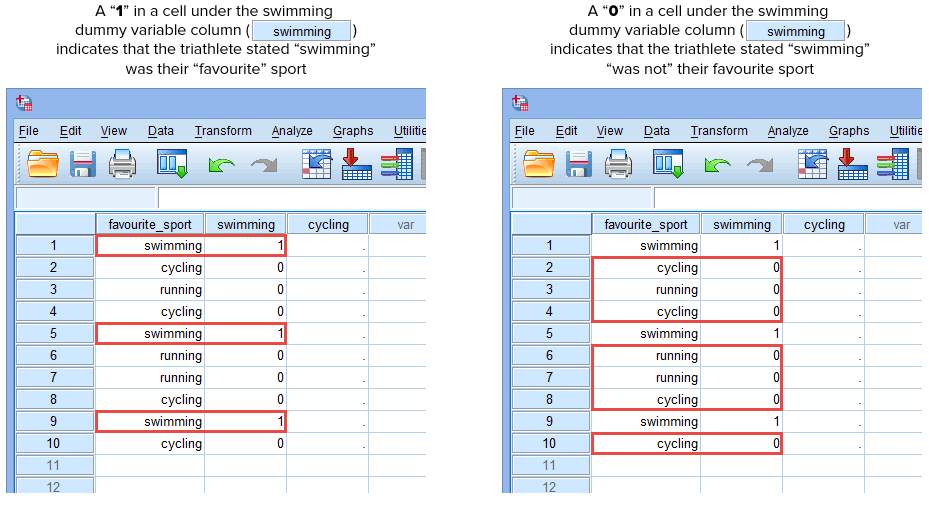
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Vi upprepar denna process för den andra dummy-variabeln, ”cykling”, vilket visas nedan:
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Om en av triathleterna uppgav att ”cykling” var deras ”favoritsport” skulle vi skriva in en ”1” i cellen under kolumnen för dummyvariabeln cykling (![]() ) för den triathlet som uppgav att cykling var deras ”favoritsport”. Om en av triathleterna uppgav att ”simning” eller ”löpning” var deras ”favoritsport”, skulle vi i stället skriva in en ”0” i cellen under kolumnen för dummyvariabeln cykling (
) för den triathlet som uppgav att cykling var deras ”favoritsport”. Om en av triathleterna uppgav att ”simning” eller ”löpning” var deras ”favoritsport”, skulle vi i stället skriva in en ”0” i cellen under kolumnen för dummyvariabeln cykling (![]() ) för den triathlet som uppgav att cykling ”inte” var deras favoritsport (dvs. detta innebär att antingen ”simning” eller ”löpning” var triathletens favoritsport). Detta markeras nedan för alla 10 triathleter:
) för den triathlet som uppgav att cykling ”inte” var deras favoritsport (dvs. detta innebär att antingen ”simning” eller ”löpning” var triathletens favoritsport). Detta markeras nedan för alla 10 triathleter:
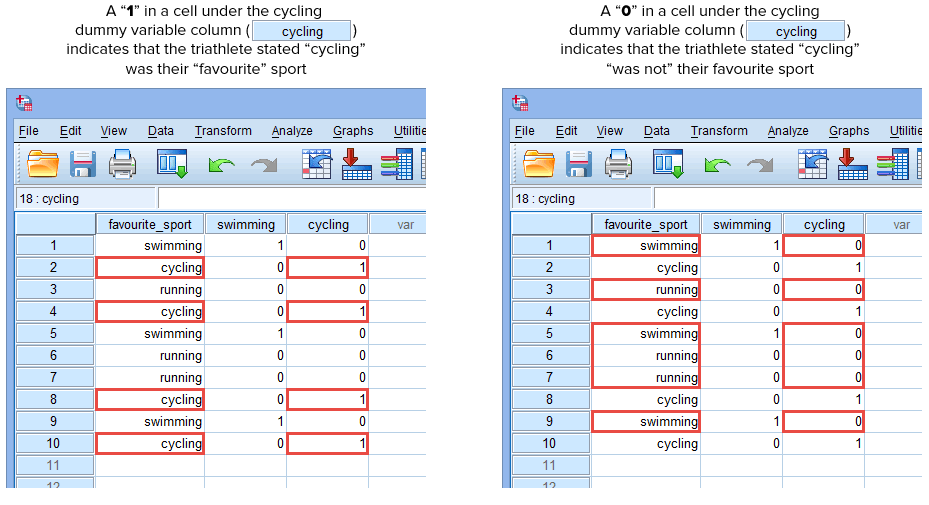
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Om du skriver in ”1” och ”0” i dina dummy-variabler på detta sätt har du skapat en uppsättning dummy-variabler som du kan skriva in i en multipel regressionsanalys. I avsnittet Procedurer som följer visar vi hur du skapar dessa dummyvariabler med hjälp av proceduren Skapa dummyvariabler.
SPSS Statistics
Procedur i SPSS Statistics för att skapa dummyvariabler
Det finns två procedurer i SPSS Statistics för att skapa dummyvariabler: Proceduren Skapa dummyvariabler och Proceduren Omkodning till olika variabler. I den här guiden visar vi hur du använder proceduren Create Dummy Variables, som är en enkel procedur i tre steg. Den är dock endast tillgänglig om du har SPSS Statistics version 22 eller senare, där version 26 (och prenumerationsversionen av SPSS Statistics) är den senaste versionen av SPSS Statistics. Om du är osäker på vilken version av SPSS Statistics du använder, se vår guide: Identifiera din version av SPSS Statistics. Om du har SPSS Statistics version 21 eller tidigare eller om du är intresserad av att göra flera jämförelser när du utför din multipla regressionsanalys, se anmärkningen nedan:
Anmärkning: Om du har SPSS Statistics version 21 eller tidigare kan du inte använda proceduren Create Dummy Variables. Därför kan du med proceduren Recode into Different Variables åtminstone skapa dummyvariabler i SPSS Statistics. Även om du också kan använda Recode into Different Variables-proceduren för att skapa dummy-variabler om du har SPSS Statistics version 22 eller senare, har vi beskrivit Create Dummy Variables-proceduren i den här guiden eftersom den är avsedd för att skapa dummy-variabler och är mycket enklare och snabbare att använda. Det krävs till exempel bara tre steg för att skapa dummyvariabler för det exempel som används i den här guiden, jämfört med 28 steg för samma exempel med hjälp av Recode into Different Variables-proceduren.
Om du har SPSS Statistics version 21 eller tidigare innehåller vår förbättrade guide Creating dummy variables i medlemsavsnittet om Laerd Statistics en sida som visar hur man utför denna 28-stegs Recode into Different Variables-procedur. Du kan få tillgång till denna förbättrade guide genom att prenumerera på Laerd Statistics. Alternativt kan du helt enkelt använda proceduren Skapa dummyvariabler nedan.
För att skapa dummyvariabler när du har SPSS Statistics version 22 eller senare följer du proceduren Skapa dummyvariabler i tre steg nedan:
- Klicka på Transformera > Skapa dummyvariabler på huvudmenyn, enligt nedan:

Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Den dialogrutan Skapa dummyvariabler visas nedan:
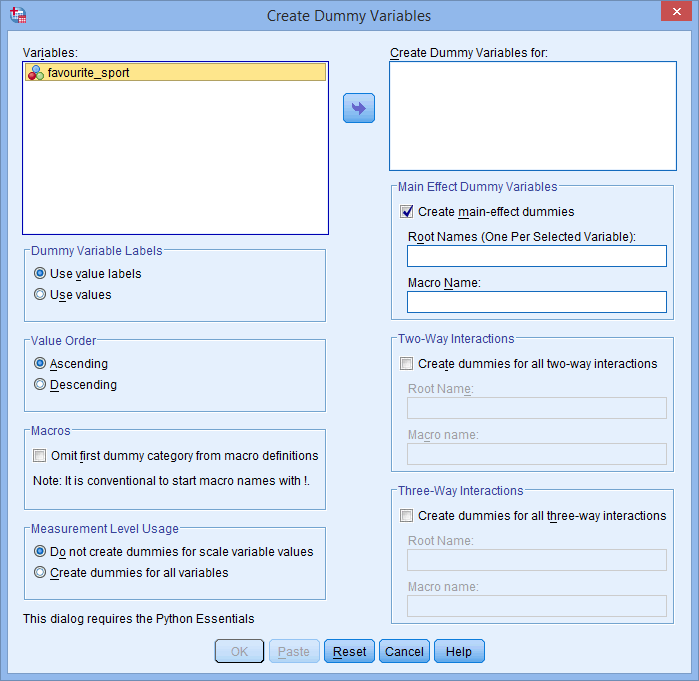
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
- Förflytta den kategoriska oberoende variabeln, favourite_sport, till rutan Skapa dummyvariabler för: genom att markera den (genom att klicka på den) och sedan klicka på knappen
 . Ange också ett ”rotnamn” som kan representera alla de nya dummyvariablerna i rutan Root Names (One Per Selected Variable): i området -Main Effect Dummy Variables-. Vi har angett rotnamnet ”fs” som en förkortning för vår kategoriska oberoende variabel, ”favourite_sport”, som visas nedan:
. Ange också ett ”rotnamn” som kan representera alla de nya dummyvariablerna i rutan Root Names (One Per Selected Variable): i området -Main Effect Dummy Variables-. Vi har angett rotnamnet ”fs” som en förkortning för vår kategoriska oberoende variabel, ”favourite_sport”, som visas nedan:
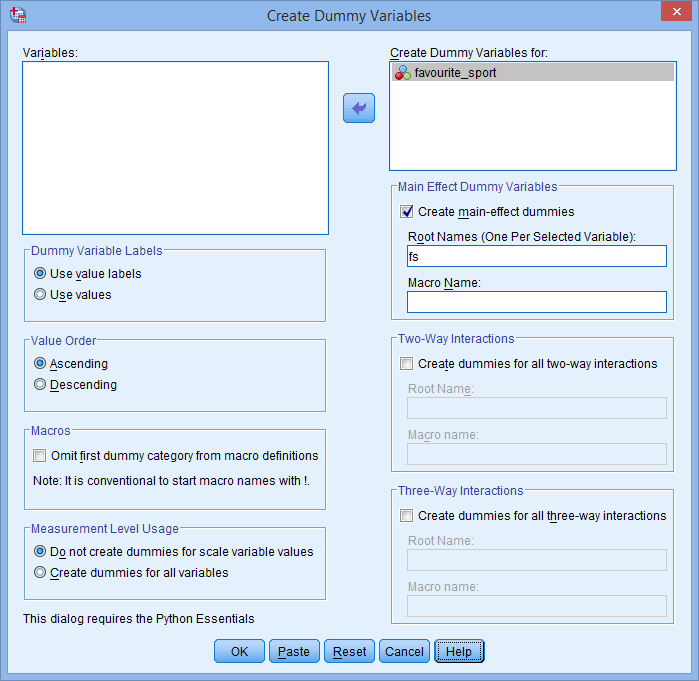
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Notera: SPSS Statistics kommer att lägga till ett löpande nummer (t.ex. 1, 2, 3, 4 osv.) i slutet av rotnamnet som du väljer för att representera din kategoriska oberoende variabel. Ett löpande nummer skapas för var och en av de dummyvariabler du vill skapa (om du t.ex. har två dummyvariabler läggs 1 och 2 till i slutet av rotnamnet, men om du har sex dummyvariabler läggs 1, 2, 3, 4, 5 och 6 till i slutet av rotnamnet). Detta visas för vårt exempel i fönstret Variable View nedan:
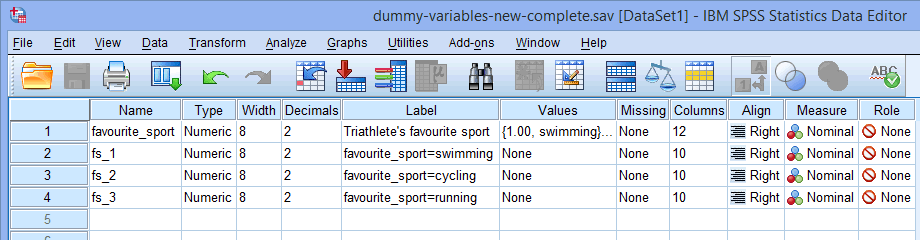
Då vår kategoriska oberoende variabel, favourite_sport, hade tre kategorier (dvs. simning, cykling och löpning), skapar proceduren Create Dummy Variables (Skapa dummyvariabler) tre dummyvariabler (dvs. en för simning, en för cykling och en för löpning). Dessa tre dummyvariabler är markerade i kolumnen ovan: ”fs_1” (för simning), ”fs_2” (för cykling) och ”fs_3” (för löpning). Du kan byta namn på dessa senare så att de blir mer meningsfulla. Vi lyfter bara fram detta så att du vet hur rutan Root Names (One Per Selected Variable): ovan fungerar.
ovan: ”fs_1” (för simning), ”fs_2” (för cykling) och ”fs_3” (för löpning). Du kan byta namn på dessa senare så att de blir mer meningsfulla. Vi lyfter bara fram detta så att du vet hur rutan Root Names (One Per Selected Variable): ovan fungerar.
Det rotnamn som du anger i rutan Root Names (One Per Selected Variable): kan inte heller vara samma som namnet på din kategoriska oberoende variabel, vilket visas nedan (dvs, där vi har angett rotnamnet ”favourite_sport” för att illustrera vad vi inte kan kalla vårt rotnamn):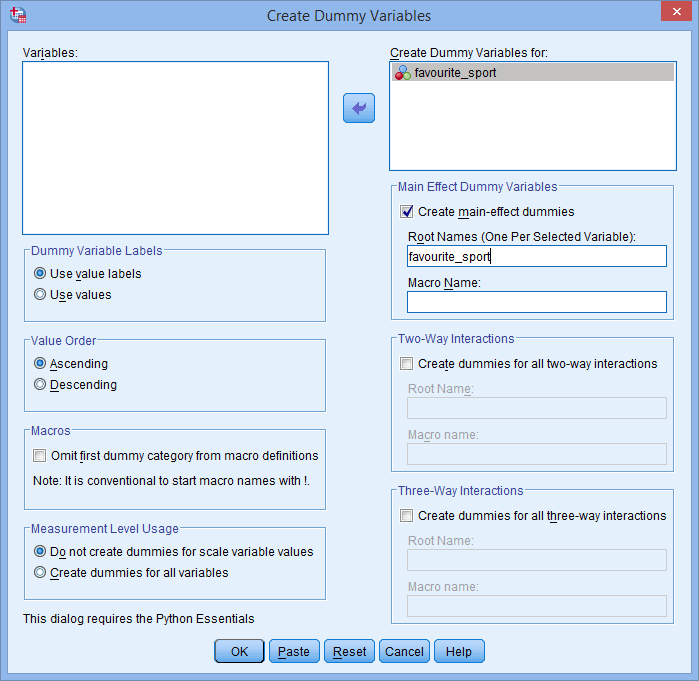
Om rotnamnet du anger är detsamma som namnet på din kategoriska oberoende variabel, som visas ovan, får du följande varning när du klickar på knappen :
:
- Klicka på knappen .
Efter att ha utfört ovanstående trestegsprocedur Skapa dummyvariabel har du skapat dummyvariabler för din kategoriska oberoende variabel. I nästa avsnitt markerar du det utdata som skapas i Variable View och Data View i SPSS Statistics efter att ha kört denna Create Dummy Variables-procedur.
SPSS Statistics
Output och datauppsättning i SPSS Statistics efter att ha skapat dummy-variabler
När du har skapat dina dummy-variabler producerar SPSS Statistics följande Variable Creation-tabell i sin IBM SPSS Statistics Viewer:
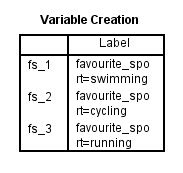
Publicerad med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Tabellen Variabelskapande bekräftar att du har skapat dummyvariabler. Det bör finnas lika många rader som det finns nya dummyvariabler. Eftersom vi skapade tre dummyvariabler finns det tre rader i tabellen, ”fs_1”, ”fs_2” och ”fs_3”, som återspeglar det rotnamn och den sekventiella numrering som angavs i steg 2 i proceduren Skapa dummyvariabler i föregående avsnitt. För var och en av dessa dummyvariabler anges en etikett i tabellen för att klargöra vilken kategori av den kategoriska oberoende variabeln som varje dummyvariabel representerar. Exempelvis anges etiketten ”favourite_sport=swimming” för ”fs_1”, vilket anger att ”fs_1” är dummyvariabeln för kategorin ”simning” i den kategoriska oberoende variabeln favourite_sport.
Nästan går du till fönstret Variable View (variabelvisning) i SPSS Statistics genom att klicka på fliken ![]() . De tre dummyvariablerna kommer att ha lagts till enligt nedan (dvs. dummyvariablerna ”fs_1”, ”fs_2” och ”fs_3” i kolumnen
. De tre dummyvariablerna kommer att ha lagts till enligt nedan (dvs. dummyvariablerna ”fs_1”, ”fs_2” och ”fs_3” i kolumnen ![]() ):
):
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Anmärkningar: Du kan ändra namnen på dummyvariablerna i kolumnen ![]() för att det ska bli tydligare vad det är. Vi har till exempel ändrat ”fs_1” till ”simning”, ”fs_2” till ”cycling” och ”fs_3” till ”running”, vilket visas nedan:
för att det ska bli tydligare vad det är. Vi har till exempel ändrat ”fs_1” till ”simning”, ”fs_2” till ”cycling” och ”fs_3” till ”running”, vilket visas nedan:
Finnligen går du till fönstret Data View (datavisning) i SPSS Statistics genom att klicka på fliken ![]() . Dummy-kodningen visas under var och en av de dummy-variabler som har skapats. I raderna under kolumnen ”fs_1” är till exempel kategorin ”simning” kodad som ”1,00”, medan kategorierna ”cykling” och ”löpning” är kodade som ”,00”, vilket visas nedan. Om du är osäker på varför dessa dummyvariabler är dummykodade på detta sätt, se avsnittet:
. Dummy-kodningen visas under var och en av de dummy-variabler som har skapats. I raderna under kolumnen ”fs_1” är till exempel kategorin ”simning” kodad som ”1,00”, medan kategorierna ”cykling” och ”löpning” är kodade som ”,00”, vilket visas nedan. Om du är osäker på varför dessa dummyvariabler är dummykodade på detta sätt, se avsnittet:
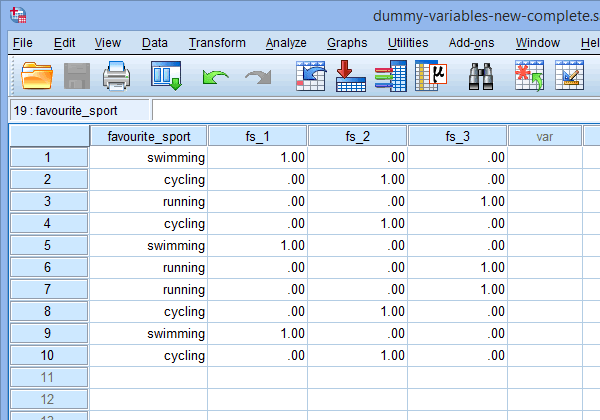
Publicerat med skriftligt tillstånd från SPSS Statistics, IBM Corporation.
Anm. 1: På grund av standardinställningarna i SPSS Statistics kommer dina dummyvariabler att kodas med ”1.00” eller ”.00” i stället för ”1” eller ”0”. De är identiska. Du kommer dock ofta att se dummy-kodning skriven i termer av 1:or och 0:or i stället för att inkludera decimaler.
Anmärkning 2: Om du ändrade namnen på dummy-variablerna i kolumnen ![]() i fönstret Variable View ovan, kommer dessa också att ha ändrats i kolumnerna i fönstret Data View, vilket visas nedan (t.ex. har rubriken för kolumnen
i fönstret Variable View ovan, kommer dessa också att ha ändrats i kolumnerna i fönstret Data View, vilket visas nedan (t.ex. har rubriken för kolumnen ![]() nu titeln
nu titeln ![]() ):
):