Reinforcement Learning (RL) är ett av de hetaste forskningsämnena inom modern artificiell intelligens och dess popularitet ökar bara. Låt oss titta på 5 användbara saker man behöver veta för att komma igång med RL.
Reinforcement Learning(RL) är en typ av teknik för maskininlärning som gör det möjligt för en agent att lära sig i en interaktiv miljö genom att prova sig fram och göra fel med hjälp av återkoppling från sina egna handlingar och erfarenheter.
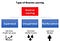
Och även om både övervakad och förstärkningsinlärning använder sig av en mappning mellan inmatning och utmatning, till skillnad från övervakad inlärning, där återkopplingen till agenten är en uppsättning korrekta åtgärder för att utföra en uppgift, använder sig förstärkningsinlärning av belöningar och bestraffningar som signaler för positivt och negativt beteende.
Vid jämförelse med oövervakad inlärning är förstärkningsinlärning annorlunda när det gäller mål. Medan målet vid oövervakad inlärning är att hitta likheter och skillnader mellan datapunkter, är målet vid förstärkningsinlärning att hitta en lämplig handlingsmodell som maximerar agentens totala kumulativa belöning. I figuren nedan illustreras återkopplingsslingan mellan handling och belöning i en generisk RL-modell.

Hur formulerar man ett grundläggande problem med förstärkningsinlärning?
Några nyckeltermer som beskriver de grundläggande delarna av ett RL-problem är:
- Miljö – Fysisk värld där agenten verkar
- Tillstånd – Agentens nuvarande situation
- Belöning – Återkoppling från miljön
- Policy – Metod för att mappa agentens tillstånd till åtgärder
- Värde – Framtida belöning som agenten skulle få om han eller hon vidtog en åtgärd i ett visst tillstånd
Ett RL-problem kan bäst förklaras genom spel. Låt oss ta spelet PacMan där agentens (PacMan) mål är att äta upp maten i rutnätet och samtidigt undvika spökena på vägen. I det här fallet är nätvärlden den interaktiva miljön för agenten där den agerar. Agenten får en belöning för att äta maten och ett straff om den dödas av ett spöke (förlorar spelet). Tillstånden är agentens plats i rutnätsvärlden och den totala kumulativa belöningen är agenten som vinner spelet.

För att bygga upp en optimal policy står agenten inför dilemmat att utforska nya tillstånd och samtidigt maximera sin totala belöning. Detta kallas för en avvägning mellan utforskning och exploatering. För att balansera båda kan den bästa övergripande strategin innebära kortsiktiga uppoffringar. Därför bör agenten samla in tillräckligt med information för att kunna fatta det bästa övergripande beslutet i framtiden.
Markov Decision Processes (MDPs) är matematiska ramar för att beskriva en miljö i RL och nästan alla RL-problem kan formuleras med hjälp av MDPs. En MDP består av en uppsättning ändliga miljötillstånd S, en uppsättning möjliga åtgärder A(s) i varje tillstånd, en realvärderad belöningsfunktion R(s) och en övergångsmodell P(s’, s | a). I verkliga miljöer är det dock mer troligt att det inte finns någon förhandskunskap om miljöns dynamik. Modellfria RL-metoder är praktiska i sådana fall.
Q-learning är en vanligt förekommande modellfri metod som kan användas för att bygga en självspelande PacMan-agent. Den kretsar kring begreppet uppdatering av Q-värden som anger värdet av att utföra åtgärd a i tillstånd s. Följande värdeuppdateringsregel är kärnan i Q-learning-algoritmen.

Här är en videodemonstration av en PacMan-agent som använder djup förstärkningsinlärning.
Vad är några av de mest använda algoritmerna för förstärkningsinlärning?
Q-learning och SARSA (State-Action-Reward-State-Action) är två vanligt förekommande modellfria RL-algoritmer. De skiljer sig åt när det gäller deras utforskningsstrategier medan deras utnyttjandestrategier är likartade. Medan Q-learning är en metod utan policy där agenten lär sig värdet baserat på åtgärd a* som härrör från en annan policy, är SARSA en metod med policy där agenten lär sig värdet baserat på sin nuvarande åtgärd a som härrör från sin nuvarande policy. Dessa två metoder är enkla att genomföra, men saknar generalitet eftersom de inte har möjlighet att uppskatta värden för oanade tillstånd.
Detta kan övervinnas genom mer avancerade algoritmer som Deep Q-Networks (DQNs) som använder neurala nätverk för att uppskatta Q-värden. Men DQNs kan endast hantera diskreta, lågdimensionella handlingsutrymmen.
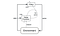
Deep Deterministic Policy Gradient(DDPG) är en modellfri, icke-politisk, aktörskritisk algoritm som tar itu med detta problem genom att lära sig policyer i högdimensionella, kontinuerliga handlingsutrymmen. Figuren nedan är en representation av en aktörskritisk arkitektur.
Vilka praktiska tillämpningar av förstärkningsinlärning finns det?
Då RL kräver mycket data är det mest tillämpbart inom områden där simulerade data är lättillgängliga, t.ex. spel och robotteknik.
- RL används i stor utsträckning för att bygga AI för att spela dataspel. AlphaGo Zero är det första datorprogram som har besegrat en världsmästare i det gamla kinesiska spelet Go. Andra inkluderar ATARI-spel, Backgammon ,etc
- I robotik och industriell automation används RL för att göra det möjligt för roboten att skapa ett effektivt adaptivt styrsystem för sig själv som lär sig av sin egen erfarenhet och sitt eget beteende. DeepMinds arbete med Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates är ett bra exempel på samma sak. Titta på denna intressanta demonstrationsvideo.
Andra tillämpningar av RL omfattar abstrakta textsammanfattningsmotorer, dialogagenter (text, tal) som kan lära sig av användarinteraktioner och förbättras med tiden, lära sig optimala behandlingsstrategier inom hälso- och sjukvården och RL-baserade agenter för aktiehandel online.
Hur kan jag komma igång med Reinforcement Learning?
För att förstå de grundläggande begreppen för RL kan man använda följande resurser.
- Reinforcement Learning-An Introduction, en bok av Richard Sutton, fadern till Reinforcement Learning, och hans doktorsrådgivare Andrew Barto. Ett onlineutkast av boken finns här.
- Undervisningsmaterial från David Silver, inklusive videoföreläsningar, är en utmärkt introduktionskurs om RL.
- Här finns en annan teknisk handledning om RL av Pieter Abbeel och John Schulman (Open AI/ Berkeley AI Research Lab).
För att komma igång med att bygga och testa RL-agenter kan följande resurser vara till hjälp.
- Den här bloggen om hur man tränar en Neural Network ATARI Pong-agent med Policy Gradients från råa pixlar av Andrej Karpathy hjälper dig att få igång din första Deep Reinforcement Learning-agent på bara 130 rader Pythonkod.
- DeepMind Lab är en 3D-spelliknande plattform med öppen källkod som skapats för agentbaserad AI-forskning med rika simulerade miljöer.
- Project Malmo är en annan AI-experimenteringsplattform för stöd till grundläggande AI-forskning.
- OpenAI gym är en verktygslåda för att bygga och jämföra algoritmer för förstärkningsinlärning.