Var: Derek Colley | Uppdaterad: 2014-01-29 | Kommentarer (5) | Relaterad: Mer > Funktioner – System
Problem
Du vill hämta ett slumpmässigt urval från en SQL Server-frågoresultatuppsättning. Kanske söker du ett representativt urval av data från en stor kunddatabas, kanske söker du några medelvärden eller en uppfattning om vilken typ av data du har. SELECT TOP N är inte alltid idealiskt, eftersom datautfall ofta förekommer i början och slutet av datamängderna, särskilt när de är ordnade i alfabetisk ordning eller efter ett skalärvärde. På samma sätt kan du ha använt TABLESAMPLE, men det har begränsningar, särskilt när det gäller små eller skeva datamängder. Din chef kanske har bett dig om ett slumpmässigt urval av 100 kundnamn och platser, eller så deltar du i en revision och behöver hämta ett slumpmässigt urval av data för analys. Hur skulle du utföra denna uppgift? Läs det här tipset för att få veta mer.
Lösning
Det här tipset visar hur du använder TABLESAMPLE i T-SQL för att hämta pseudo-slumpmässiga dataprover, och går igenom de interna delarna av TABLESAMPLE och var det inte är lämpligt. Det visar också en alternativ metod – en matematisk metod som använder NEWID() i kombination med CHECKSUM och en bitvis operatör, som Microsoft nämner i artikeln TABLESAMPLE TechNet. Vi kommer att prata lite om statistisk provtagning i allmänhet (skillnaderna mellan slumpmässig, systematisk och stratifierad) med exempel, och vi kommer att ta en titt på hur SQL-statistik provtas som ett exempel, och de alternativ vi kan använda för att åsidosätta denna provtagning. Efter att ha läst det här tipset bör du ha en uppskattning av fördelarna med sampling jämfört med att använda metoder som TOP N och veta hur man tillämpar minst en metod för att uppnå detta i SQL Server.
Setup
För det här tipset kommer jag att använda en datauppsättning som innehåller en identitetsINT-kolumn (för att fastställa graden av slumpmässighet när man väljer rader) och andra kolumner som är fyllda med pseudo-slumpmässiga data av olika datatyper, för att (vagt) simulera verkliga data i en tabell. Du kan använda T-SQL-koden nedan för att ställa in detta. Det bör bara ta ett par minuter att köra och är testat på SQL Server 2012 Developer Edition.
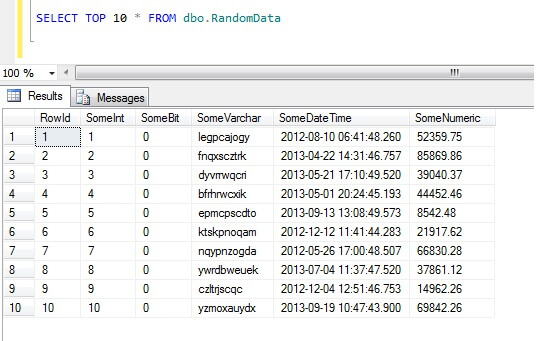
Väljning av de 10 översta dataraderna ger detta resultat (bara för att ge dig en uppfattning om hur data ser ut).Som ett sidospår är detta en allmän kod som jag skapade för att generera random-ishdata när jag behövde det – ta gärna den och förstärk/plundra den efter eget tycke och smak!
Hur man inte tar prov på data i SQL Server
När vi nu har våra dataprover ska vi fundera på de sämsta sätten att få fram ett prov på. I databasen AdventureWorks finns det en tabell som heter Person.Address. Låt oss ta ett prov genom att ta de tio bästa resultaten, utan särskild ordning:
SELECT TOP 10 * FROM Person.Address
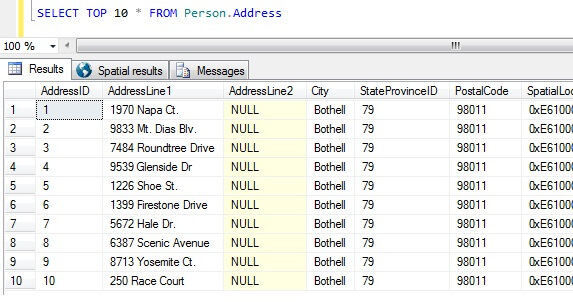
Genom att bara utgå från det här provet kan vi se att alla personer som returneras bor i Bothell, och delar postnummer 98011. Detta beror på att resultaten inte skulle returneras i någon särskild ordning, utan i själva verket returnerades de i ordning efter kolumnen AddressID. Observera att detta INTE är ett garanterat beteende för heapdata i synnerhet – se detta citat från BOL:
”Vanligtvis lagras data initialt i den ordning som raderna sätts in i tabellen, men databasmotorn kan flytta data runt i heap för att lagra raderna på ett effektivt sätt, så dataraden kan inte förutsägas. För att garantera ordningen på de rader som returneras från en heap måste du använda ORDER BY-klausulen.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Med den här resultatuppsättningen skulle en person som inte är informerad om tabellens karaktär kunna dra slutsatsen att alla deras kunder bor i Bothell.
Typer av datauttag i SQL Server
Ovanstående är helt klart falskt, så vi behöver ett bättre sätt att göra provtagningar. Vad sägs om att ta ett urval med jämna mellanrum i hela tabellen?
Detta bör ge 47 rader:
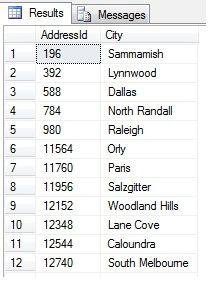
Så långt, så bra. Vi har tagit en rad med jämna mellanrum i hela vår datamängd och returnerat ett statistiskt tvärsnitt – eller har vi? Inte nödvändigtvis. Glöm inte att ordningen inte är garanterad. Vi kan dra en eller två slutsatser om dessa data. Låt oss aggregera den för att illustrera det. Kör kodutdraget ovan igen, men ändra det sista SELECT-blocket på följande sätt:
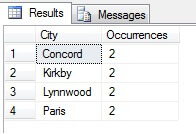
Du kan se i mitt exempel att från ett totalt antal på mer än 19 000 rader i tabellen Person.Address har jag tagit ett urval på cirka 1/4 % av raderna och därför kan jag dra slutsatsen att (i mitt exempel) Concord, Kirkby, Lynnwood och Paris har flest invånare och att de dessutom är lika befolkade. Är det korrekt? Nonsens, förstås:
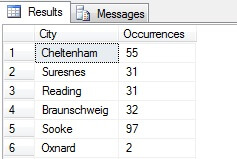
Som ni kan se var ingen av mina fyra faktiskt bland de fyra bästa platserna att bo på, enligt denna tabell. Inte nog med att urvalet var för litet, jag aggregerade detta lilla urval och försökte dra en slutsats av det. Detta innebär att min resultatuppsättning är statistiskt obetydlig – att bevisa statistisk signifikans är en av de största bevisbördorna när man presenterar statistiska sammanfattningar (eller borde vara det) och ett stort misslyckande för många populära infografiker och marknadsföringsledda datagram.
Så, provtagning på det här sättet (kallat systematiskt urval) är effektivt, men bara för en statistiskt signifikant population. Det finns faktorer som periodicitet och proportion som kan förstöra ett urval – låt oss se proportion i praktiken genom att ta ett urval av 10 städer från tabellen Person.Address, genom att använda följande kod, som hämtar en distinkt lista med städer från tabellen Person.Address och sedan väljer 10 städer från den listan med hjälp av systematiskt urval:
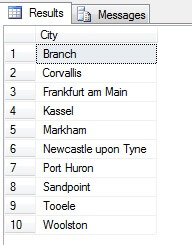
Det ser ut som ett bra urval, eller hur? Låt oss nu jämföra det med ett urval av icke-distinkta städer som listas i stigande ordning, dvs. var n:e stad, där n är det totala antalet rader dividerat med 10. Detta mått tar hänsyn till urvalspopulationen:
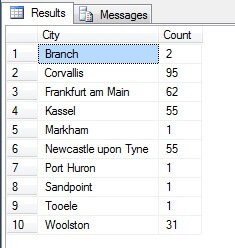
Den återgivna informationen är helt annorlunda – inte av en slump, utan genom presentation av ett representativt urval. Observera att denna lista, på vilken jag har inkluderat antalet städer i källtabellen för att visa hur mycket befolkningen spelar in i dataurvalet, innehåller de fyra mest tätbefolkade städerna i urvalet, vilket (om man betraktar en ordnad icke-distinktiv lista) är den mest rättvisande representationen. Det är inte nödvändigtvis den bästa representationen för dina behov, så var försiktig när du väljer din statistiska provtagningsmetod.
Andra provtagningsmetoder
Klusterprovtagning – här delas populationen som ska provtas in i kluster, eller delmängder, och sedan bestäms var och en av dessa delmängder slumpmässigt för att inkluderas eller inte inkluderas i utdataresultatet. Om de ingår, returneras varje medlem av denna delmängd i resultatmängden. Se TABLESAMPLE nedan för ett exempel på detta.
Disproportionell provtagning – detta är som stratifierad provtagning, där medlemmar av undergrupperna väljs ut för att representera hela gruppen, men i stället för att vara proportionerliga kan det finnas olika antal medlemmar från varje grupp som väljs ut för att utjämna representationen från varje grupp. Med tanke på städerna i Person.Address i exemplet från avsnittet ovan var den första resultatuppsättningen oproportionerlig eftersom den inte tog hänsyn till befolkningsmängden, men den andra resultatuppsättningen var proportionerlig eftersom den representerade antalet stadsposter i tabellen Person.Address. Den här typen av provtagning är faktiskt användbar om en viss kategori är underrepresenterad i datamängden och proportionen inte är viktig (till exempel 100 slumpmässiga kunder från 100 slumpmässiga städer stratifierade efter stad – städerna i delmängden skulle behövanormaliseras – oproportionerlig provtagning skulle kunna användas).
SQL Server Slumpmässiga data med TABELLEREMPROCENT
SQL Server kommer hjälpsamt nog med en metod för att ta stickprov på data. Låt oss se den i praktiken. Använd följande kod för att returnera cirka 100 rader (om den returnerar 0 rader, kör om – jag förklarar strax) av data från dbo.RandomData som vi definierade tidigare.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
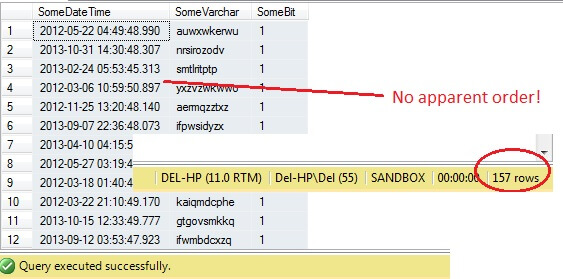
Så långt, så bra, eller hur? Vänta lite – vi kan inte se kolumnen Id. Låt oss inkludera detta och köra om:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
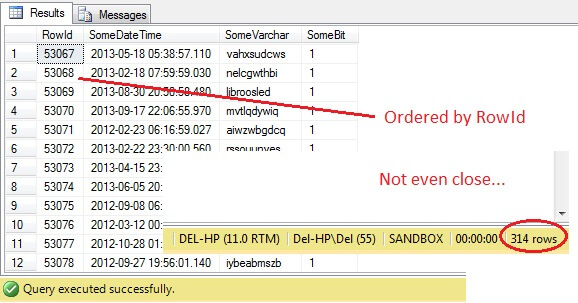
Oh kära nån – TABLESAMPLE har valt en dataskiva, men det är inte slumpmässigt – RowId visar en tydligt avgränsad skiva med ett minimi- och ett maximivärde. Dessutom har den inte heller returnerat exakt 100 rader. Vad är det som händer?
TABLESAMPLE använder den implicita modifikationen SYSTEM. Denna modifierare, som är aktiverad som standard och en ANSI-SQL-specifikation, dvs. inte valfri, tar varje 8KB-sida som tabellen finns på och bestämmer om alla rader på den sidan som finns i tabellen ska inkluderas i det producerade provet eller inte, baserat på den procentsats eller det N ROWS-värde som anges. Därför bör en tabell som finns på många sidor, dvs. som har stora datarader, ge ett mer slumpmässigt urval eftersom det kommer att finnas fler sidor i urvalet. Det misslyckas för ett exempel som vårt, där uppgifterna är skalära och små och finns på bara några få sidor – om något antal sidor inte klarar sig kan det ge en betydande snedvridning av det utmatade urvalet. Detta är TABLESAMPLEs nackdel – den fungerar inte bra för ”små” data och tar inte hänsyn till fördelningen av data på sidorna. Så arrangemanget av data på sidorna är i slutändan ansvarig för det urval som returneras av denna metod.
Låter detta bekant? Det är i huvudsak klusterprovtagning, där alla medlemmar (rader) i de valda grupperna (kluster) är representerade i resultatmängden.
Låt oss testa den på en stor tabell för att understryka poängen med den omvända icke skalbarheten. Låt oss först identifiera den största tabellen i AdventureWorks-databasen. Vi använder en standardrapport för detta – använd SSMS, högerklicka på AdventureWorks2012-databasen, gå till Reports -> Standard Reports -> Disk Usage by Top Tables. Ordna efter Data(KB) genom att klicka på kolumnrubriken (du kanske vill göra detta två gånger för fallande ordning). Du får se rapporten nedan.
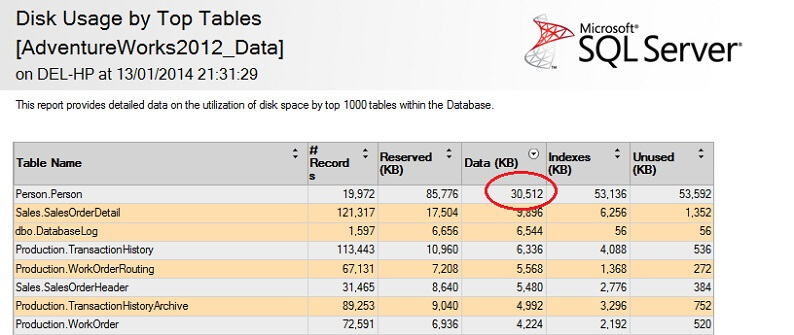
Jag har inringat den intressanta siffran – personen. Persontabellen förbrukar 30,5 MB data och är den största tabellen (med avseende på data, inte antal poster). Så låt oss försöka ta ett prov från denna tabell istället:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
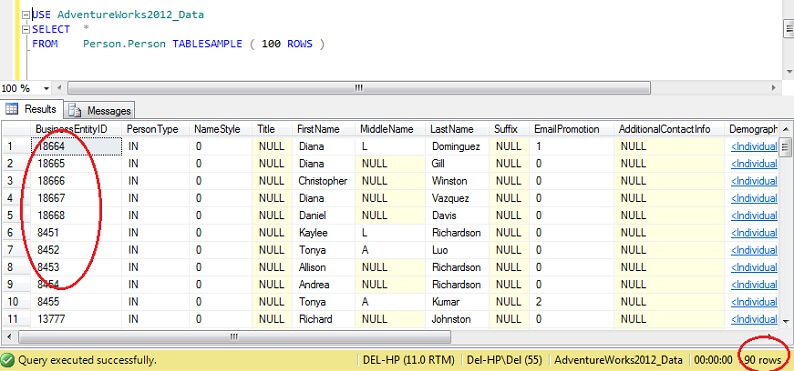
Du kan se att vi är mycket närmare 100 rader, men det viktiga är att det inte verkar finnas mycket kluster på primärnyckeln (även om det finns en viss klusterbildning, eftersom det finns mer än en rad per sida).
Följaktligen är TABLESAMPLE bra för stora data, och blir katastrofalt sämre ju mindre datasetet är. Detta är inte bra för oss när vi tar prover från stratifierade data eller klustrade data, där vi tar många prover från små grupper eller delmängder av data och sedan aggregerar dessa. Låt oss då titta på en alternativ metod.
Random SQL Server Data with ORDER BY NEWID()
Här är ett citat från BOL om att få ett verkligt slumpmässigt urval:
”Om du verkligen vill ha ett slumpmässigt urval av enskilda rader, modifiera din fråga så att du kan filtrera ut rader slumpmässigt, istället för att använda TABLESAMPLE. I följande fråga används till exempel NEWID-funktionen för att returnera ungefär en procent av raderna i tabellen Sales.SalesOrderDetail:
Hur fungerar det här? Låt oss dela upp WHERE-klausulen och förklara den.
Funktionen CHECKSUM beräknar en kontrollsumma över objekten i listan. Man kan diskutera om SalesOrderID ens behövs, eftersom NEWID() är en funktion som returnerar ett nytt slumpmässigt GUID, så att multiplicera en slumpmässig siffra med en konstant borde resultera i ett slumpmässigt i vilket fall som helst.Faktum är att det inte verkar göra någon skillnad att utesluta SalesOrderID. Om du är en skicklig statistiker och kan motivera att detta ingår, använd kommentarsfältet nedan och låt mig veta varför jag har fel!
Funktionen CHECKSUM returnerar en VARBINARY. Genom att utföra en bitvis AND-operation med 0x7fffffffff, som motsvarar (11111111111…) i binär form, erhålls ett decimalvärde som i praktiken är en representation av en slumpmässig sträng av 0:or och 1:or. Genom att dividera med koefficienten 0x7fffffffff normaliseras detta decimaltal till en siffra mellan 0 och 1. För att avgöra om varje rad förtjänar att ingå i den slutliga resultatuppsättningen används sedan ett tröskelvärde på 1/x (i det här fallet 0,01), där x är den procentuella andel av datan som ska hämtas som ett stickprov.
Var försiktig med att den här metoden är en form av slumpmässigt stickprov snarare än systematiskt stickprov, så det är troligt att du kommer att få data från alla delar av dina källdata, men nyckeln här är att det *möjligen inte*. Naturen av slumpmässigt urval innebär att ett urval som du samlar in kan vara snedvridet mot ett segment av dina data, så för att dra nytta av regression mot medelvärdet (tendens mot ett slumpmässigt resultat, i det här fallet) se till att du tar flera urval och väljer från en delmängd av dessa, om dina resultat ser snedvridna ut. Alternativt kan du ta prover från delmängder av dina data och sedan aggregera dessa – detta är en annan typ av provtagning som kallas stratifierad provtagning.
Hur tas prover på SQL Server-statistik?
I SQL Server sker automatisk uppdatering av kolumn- eller användardefinierad statistik varje gång ett fastställt tröskelvärde av tabellrader ändras för en viss tabell. För 2012 beräknas detta tröskelvärde till SQRT(1000 * TR) där TR är antalet tabellrader i tabellen. Före 2005 startades det automatiska uppdateringsjobbet för statistik för varje (500 rader + 20 % förändring) tabellrader. När den automatiska uppdateringsprocessen startar kommer provtagningen att *minskas antalet rader som provtas ju större tabellen blir*, med andra ord finns det ett förhållande som liknar omvänd proportion mellan tabellens provtagningsprocent och tabellens storlek, men följer en egen algoritm.
Interessant nog verkar detta vara motsatsen till alternativet TABLESAMPLE (N PERCENT), där de rader som provtas står i normal proportion till antalet rader i tabellen. Vi kan inaktivera automatisk statistik (var försiktig med detta) och uppdatera statistiken manuellt – detta uppnås genom att använda NORECOMPUTE på UPDATE STATISTICS-instruktionen. Med UPDATE STATISTICS kan vi åsidosätta några av alternativen – till exempel kan vi välja att ta stickprov på N rader eller N procent (liknande TABLESAMPLE), utföra en FULLSCAN eller helt enkelt RESAMPLE med hjälp av det senast kända värdet.
Nästa steg
För ytterligare läsning, Joseph Sack är en Microsoft MVP känd för sitt arbete med statistisk analys av SQL Server – se nedan för några länkar till hans arbete, tillsammans med några referenser till arbete som använts för den här artikeln och till några relaterade tips från MSSQLTips.com. Tack för att du läste!
Sist uppdaterad: 2014-01-29


Om författaren
 Derek Colley är en brittisk DBA- och BI-utvecklare med över tio års erfarenhet av att arbeta med SQL Server, Oracle och MySQL.
Derek Colley är en brittisk DBA- och BI-utvecklare med över tio års erfarenhet av att arbeta med SQL Server, Oracle och MySQL.Se alla mina tips
- Mer tips för databasutvecklare…