Att förstå grunderna för schemahantering är avgörande för att bygga och underhålla en effektiv PostgreSQL-databas. I den här artikeln kommer vi att titta på det traditionella sättet att hantera ett Postgresschema och på ett nyare, effektivare sätt att göra det visuellt, utan att behöva skriva någon kodrad.
Vad är ett PostgreSQL-schema?
För att lägga grunden för artikeln ska vi först reda ut lite terminologi. I Postgres kallas schemat också för ett namnområde. Namnsrymden kan associeras med ett familjenamn. Det används för att identifiera och särskilja vissa objekt i databasen (tabeller, vyer, kolumner osv.). Det är inte tillåtet att skapa två tabeller med samma namn i ett schema, men du kan göra det i två olika scheman. Vi kan till exempel ha två tabeller som båda heter table1 som finns i public- och postgres-scheman.
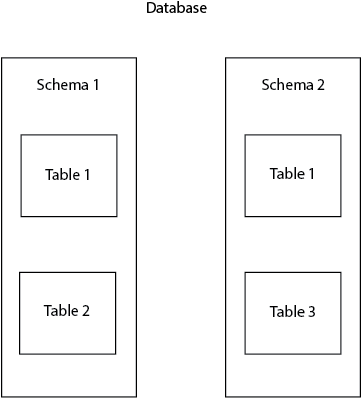
Varför använda scheman?
Scheman är mycket användbara för att organisera databasobjekt i logiska grupper och undvika namnkollisioner. Dessutom används scheman ofta för att olika användare ska kunna arbeta med databasen utan att störa varandra. Ett vanligt exempel är när varje databasanvändare arbetar med sitt eget schema, utan att störa andra användare och utan att undvika konflikter.
Det klassiska sättet att hantera PostgreSQL-scheman
Alla frågor nedan kommer att exekveras inifrån PostgreSQL-skalet.
Skapa ett schema
När du skapar en ny databas i Postgres är standardschemat public. Ett nytt schema kan skapas genom att utföra nästa fråga:
CREATE SCHEMA schema_1;
För att lägga till några tabeller, ska jag förklara två viktiga begrepp: kvalificerade och okvalificerade namn.
-
Ett kvalificerat namn är schemanamnet och tabellnamnet separerade med en punkt. Detta anger i vilket schema vi vill skapa vår tabell:
>
xxxxxxxxxx
CREATE TABLE schema_name.table_name (...);
-
Ett okvalificerat namn består endast av tabellnamnet. Tabellen skapas i den valda databasen som är offentlig som standard. Detta kan ändras via search_path, men vi kommer att beskriva det i detalj senare. Ett exempel på okvalificerat namn är:
>.
xxxxxxxxxx
CREATE TABLE table_name (...);
Tabellernas kolumner kommer att definieras inom parenteserna från frågorna ovan (…).
För att skapa en ny tabell i vårt nya schema utför vi:
.
xxxxxxxxxx
CREATE TABLE schema_1.persons (name text, age int);
För att släppa schemat, har vi två möjligheter. Om schemat är tomt (innehåller inga tabeller, vyer eller andra objekt) kan vi köra:
xxxxxxxxxx
DROP SCHEMA schema_1;
Om schemat innehåller databasobjekt, kommer vi att infoga kaskadkommandot:
>
xxxxxxxxxx
DROP SCHEMA schema_1 CASCADE;
I PostgreSQL är det också möjligt att skapa ett schema som ägs av en annan användare med:
xxxxxxxxxx
CREATE SCHEMA schema_name AUTHORIZATION username;
Sökningssökväg
När du utför ett kommando med ett okvalificerat namn, följer Postgres en sökväg för att avgöra vilka scheman som ska användas. Som standard är sökvägen inställd på det offentliga schemat. Du kan visa det genom att utföra följande:
xxxxxxxxxx
SHOW search_path;
Om ingenting har ändrats i din databas, bör den här frågan ge nästa resultat:
xxxxxxxxxx
search_path
--------------
"$user",public
Sökvägen kan ändras så att systemet automatiskt väljer ett annat schema om du använder ett okvalificerat namn. Det första schemat i sökvägen kallas aktuellt schema. Jag ställer till exempel in schema_1 som aktuellt schema:
xxxxxxxxxx
SET search_path TO schema_1,public;
Nästa fråga använder ett okvalificerat namn för att skapa en tabell. Det kommer automatiskt att skapas i schema_1:
xxxxxxxxxx
CREATE TABLE address (city text, street text, number int);
Den nya vägen: Hantera utan kod!
Det finns ett enklare sätt att utföra alla schemahanteringsuppgifter utan att behöva skriva någon rad kod. Med hjälp av DbSchema kan du utföra alla ovanstående frågor från ett intuitivt grafiskt gränssnitt med bara några få klick. Att ansluta till databasen tar bara några sekunder. Från början kan du välja vilket schema du vill arbeta med.
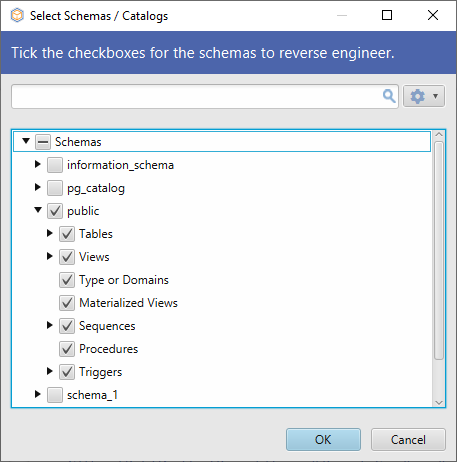
Det valda schemat eller de valda schemana kommer att omvändas av DbSchema och visas i layouten.
För att skapa ett nytt schema är det bara att högerklicka på schemamappen i vänstermenyn och välja Create Schema.
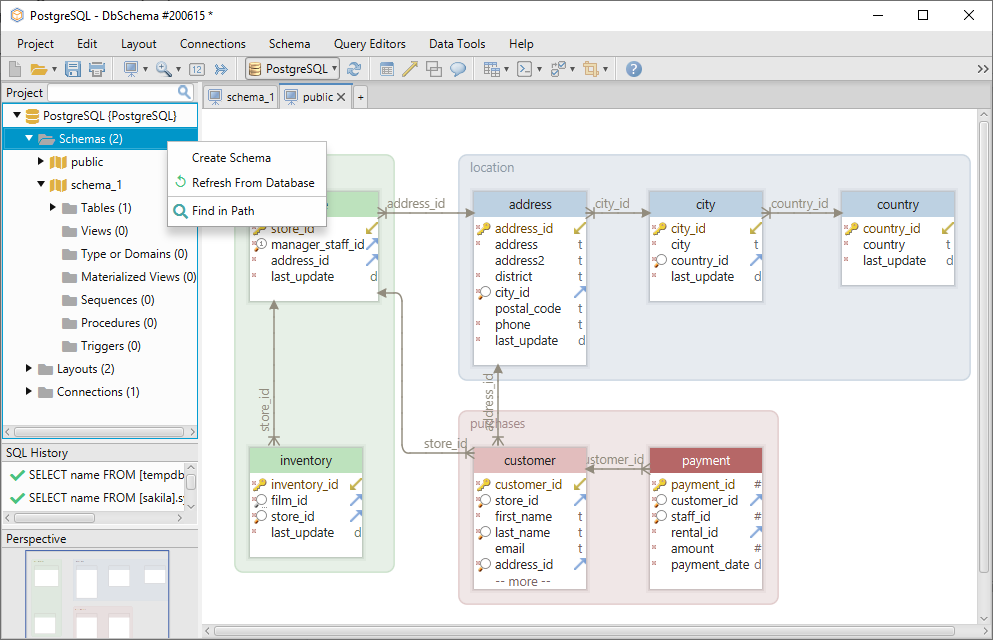
För att skapa en ny tabell i schemat högerklickar du på layouten och väljer Create Table.
Skemat kan släppas genom att högerklicka på dess namn i den vänstra menyn.
För att lägga till ett annat schema från databasen väljer du Uppdatera från databasen.
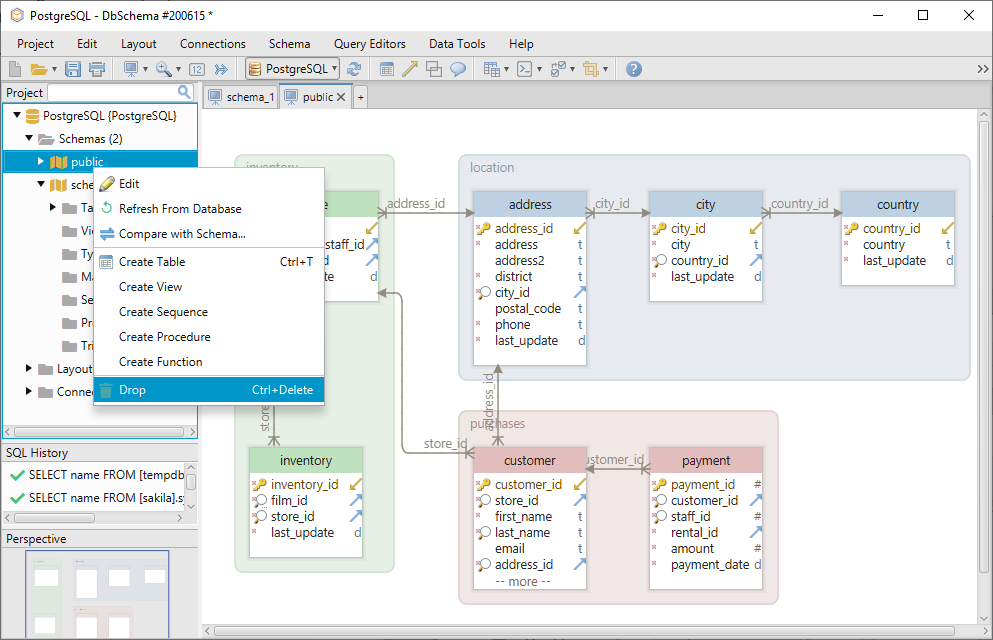
Med DbSchema behöver du inte använda syntaxen show_path eftersom du kan skapa tabellerna direkt i layouten. En layout kan jämföras med ett ritbord på vilket du kan lägga till tabellerna och redigera dem. Varje layout har ett schema associerat med den, så om du befinner dig på layouten schema_1 kommer tabellerna automatiskt att skapas där.
Work Offline
DbSchema lagrar en lokal avbildning av schemat i en lokal projektfil. Detta innebär att projektfilen kan öppnas utan databasanslutning (offline). När du är offline kan du göra alla åtgärder som presenteras ovan och mer, men utan data. Efter återanslutning till databasen kan du jämföra projektfilen med databasen och välja vilka åtgärder du vill behålla eller släppa.
Det går att göra samma sak mellan två olika versioner av samma projektfil. Om du till exempel arbetar i ett team kan det vara så att det finns flera scheman (produktion, testning, utveckling) med varsin projektfil. Om en ändring dyker upp i utveckling och du vill implementera den i de andra två scheman kan du bara jämföra och synkronisera de två projektfilerna.
Slutsats
Med förståelse för de begrepp som anges ovan kan du enkelt hantera dina PostgreSQL-scheman. Att använda en visuell designer som DbSchema kommer att göra ditt arbete ännu enklare genom att du kan göra allt visuellt, utan att behöva skriva en enda kodrad.