
Om du vill lära dig mer om Python kan du delta i DataCamps kostnadsfria kurs Introduktion till Python för datavetenskap.
Alla har sett datamängder. Ibland är de små, men ofta ibland är de enormt stora i storlek. Det blir en stor utmaning att bearbeta datamängder som är mycket stora, åtminstone tillräckligt stora för att orsaka en flaskhals i bearbetningen.
Så, vad är det som gör att dessa datamängder är så här stora? Jo, det är funktioner. Ju fler funktioner desto större blir datamängderna. Det är inte alltid. Du kommer att hitta dataset där antalet funktioner är väldigt mycket, men de innehåller inte så många instanser. Men det är inte det som diskuteras här. Så du kanske undrar med en vanlig dator i handen hur man kan bearbeta den här typen av datamängder utan att slå på fingrarna.
Ofta finns det i en högdimensionell datamängd fortfarande några helt irrelevanta, obetydliga och oviktiga funktioner kvar. Det har visat sig att bidraget från dessa typer av funktioner ofta är mindre till prediktiv modellering jämfört med de kritiska funktionerna. De kan till och med ha ett nollbidrag. Dessa funktioner orsakar ett antal problem som i sin tur förhindrar processen för effektiv prediktiv modellering –
- Unödig resursallokering för dessa funktioner.
- Dessa funktioner fungerar som ett brus för vilket maskininlärningsmodellen kan prestera fruktansvärt dåligt.
- Maskinmodellen tar mer tid att träna upp.
Så, vad är lösningen här? Den mest ekonomiska lösningen är Feature Selection.
Feature Selection är processen att välja ut de mest betydelsefulla funktionerna från ett givet dataset. I många fall kan Feature Selection även förbättra prestandan hos en maskininlärningsmodell.
Låter intressant eller hur?
Du fick en informell introduktion till Feature Selection och dess betydelse i datavetenskapens och maskininlärningens värld. I det här inlägget kommer du att täcka:
- Introduktion till funktionsval och förståelse av dess betydelse
- Skillnaden mellan funktionsval och dimensionalitetsreducering
- Differenta typer av funktionsvalsmetoder
- Implementering av olika funktionsvalsmetoder med scikit-learn
Introduktion till feature selection
Feature selection är också känt som Variable selection eller Attribute selection.
I huvudsak är det processen att välja de viktigaste/relevanta. Funktioner i ett dataset.
Förstå vikten av funktionsval
Vikten av funktionsval kan bäst kännas igen när man har att göra med ett dataset som innehåller ett stort antal funktioner. Denna typ av dataset kallas ofta för ett högdimensionellt dataset. Med denna höga dimensionalitet följer många problem, till exempel – denna höga dimensionalitet kommer att avsevärt öka träningstiden för din maskininlärningsmodell, den kan göra din modell mycket komplicerad, vilket i sin tur kan leda till överanpassning.
Ofta finns det i en högdimensionell funktionsuppsättning flera funktioner som är överflödiga, vilket innebär att dessa funktioner inte är något annat än förlängningar av de andra viktiga funktionerna. Dessa överflödiga funktioner bidrar inte heller effektivt till modellutbildningen. Det är alltså uppenbart att det finns ett behov av att extrahera de viktigaste och mest relevanta funktionerna för en datamängd för att få den mest effektiva prediktiva modelleringsprestandan.
”Målet med val av variabler är trefaldigt: att förbättra prediktionsprestandan för prediktorerna, att tillhandahålla snabbare och mer kostnadseffektiva prediktorer och att ge en bättre förståelse för den underliggande processen som genererade data.”
-En introduktion till val av variabler och funktioner
Nu ska vi förstå skillnaden mellan dimensionalitetsreducering och funktionsval.
Ibland förväxlas funktionsval med dimensionalitetsreducering. Men de är olika. Feature selection skiljer sig från dimensionalitetsreduktion. Båda metoderna tenderar att minska antalet attribut i datamängden, men en metod för dimensionalitetsreducering gör det genom att skapa nya kombinationer av attribut (ibland kallat feature transformation), medan metoder för feature selection inkluderar och utesluter attribut som finns i datamängden utan att ändra dem.
Några exempel på dimensionalitetsminskningsmetoder är Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis etc.
Låt mig sammanfatta betydelsen av funktionsval för dig:
- Det gör det möjligt för maskininlärningsalgoritmen att träna snabbare.
- Det minskar komplexiteten hos en modell och gör den lättare att tolka.
- Det förbättrar noggrannheten hos en modell om rätt delmängd väljs.
- Det minskar överanpassning.
I nästa avsnitt kommer du att studera de olika typerna av allmänna metoder för urval av funktioner – filtermetoder, Wrapper-metoder och inbäddade metoder.
Filtermetoder
Följande bild beskriver bäst filterbaserade metoder för urval av funktioner:

Bildkälla: Filtreringsmetod: Analytics Vidhya
Filtreringsmetoden bygger på den allmänna unika karaktären hos de data som ska utvärderas och väljer delmängder av funktioner, utan att inkludera någon gruvningsalgoritm. Filtermetoden använder det exakta bedömningskriteriet som omfattar avstånd, information, beroende och konsistens. Filtermetoden använder de viktigaste kriterierna i rangordningstekniken och använder rangordningsmetoden för val av variabler. Anledningen till att rangordningsmetoden används är att den är enkel och ger utmärkta och relevanta egenskaper. Rankingmetoden filtrerar bort irrelevanta egenskaper innan klassificeringsprocessen startar.
Filtermetoder används i allmänhet som ett förbehandlingssteg för data. Valet av funktioner är oberoende av någon algoritm för maskininlärning. Funktioner ger rangordning på grundval av statistiska poäng som tenderar att bestämma funktionernas korrelation med utfallsvariabeln. Korrelation är en mycket kontextuell term som varierar från arbete till arbete. Du kan se följande tabell för att definiera korrelationskoefficienter för olika typer av data (i det här fallet kontinuerliga och kategoriska).

Bildkälla: Några exempel på några filtermetoder är Chi-kvadrat-testet, informationsvinst och korrelationskoefficientpoäng.
Nästan kommer du att se Wrapper-metoder.
Wrapper methods
Likt filtermetoderna vill jag ge dig en liknande infografik som hjälper dig att förstå wrapper methods bättre:
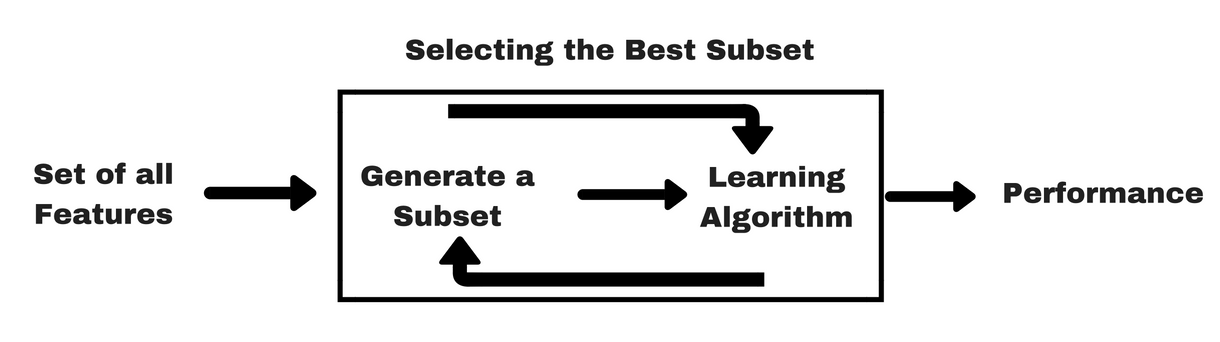
Bildkälla: Som du kan se i bilden ovan behöver en wrapper-metod en algoritm för maskininlärning och använder dess prestanda som utvärderingskriterium. Denna metod söker efter en funktion som är bäst lämpad för den maskininlärande algoritmen och syftar till att förbättra gruvprestanda. För att utvärdera funktionerna används den prediktiva noggrannheten för klassificeringsuppgifter och klustrens godhet utvärderas med hjälp av klusterbildning.
Några typiska exempel på omslagsmetoder är forward feature selection, backward feature elimination, recursive feature elimination etc.
- Forward Selection: Förfarandet börjar med en tom uppsättning egenskaper . Den bästa av de ursprungliga funktionerna bestäms och läggs till den reducerade uppsättningen. Vid varje efterföljande iteration läggs den bästa av de återstående ursprungliga egenskaperna till mängden.
- Backward Elimination: Förfarandet börjar med den fullständiga uppsättningen attribut. Vid varje steg avlägsnas det sämsta attributet som återstår i uppsättningen.
- Kombination av framåtriktad selektering och bakåtriktad eliminering: Metoderna för stegvis framåtriktad selektering och bakåtriktad eliminering kan kombineras så att förfarandet i varje steg väljer det bästa attributet och tar bort det sämsta från de kvarvarande attributen.
- Recursive Feature elimination: Recursive feature elimination utför en greedy search för att hitta den bäst presterande delmängden av egenskaper. Den skapar modeller iterativt och bestämmer den bästa eller sämsta egenskapen vid varje iteration. De efterföljande modellerna konstrueras med de kvarvarande funktionerna tills alla funktioner har undersökts. Därefter rangordnas funktionerna utifrån den ordning i vilken de elimineras. I värsta fall, om ett dataset innehåller N antal funktioner kommer RFE att göra en girig sökning efter 2N kombinationer av funktioner.
Godt nog!
Nu ska vi studera inbäddade metoder.
Inbäddade metoder
Inbäddade metoder är iterativa i den bemärkelsen att de tar hand om varje iteration av modellträningsprocessen och noggrant extraherar de funktioner som bidrar mest till träningen för en viss iteration. Regulariseringsmetoder är de vanligaste inbäddade metoderna som straffar en funktion givet ett koefficienttröskelvärde.
Detta är anledningen till att Regulariseringsmetoder även kallas för straffmetoder som introducerar ytterligare begränsningar i optimeringen av en prediktiv algoritm (t.ex. en regressionsalgoritm) som snedvrider modellen mot lägre komplexitet (färre koefficienter).
Exempel på regulariseringsalgoritmer är LASSO, Elastic Net, Ridge Regression etc.
Skillnaden mellan filter- och omslagsmetoder
Ja, det kan ibland bli förvirrande att skilja mellan filtermetoder och omslagsmetoder när det gäller deras funktioner. Låt oss ta en titt på vilka punkter de skiljer sig från varandra.
- Filtermetoder innehåller inte en maskininlärningsmodell för att avgöra om en funktion är bra eller dålig medan omslagsmetoder använder en maskininlärningsmodell och tränar den funktionen för att avgöra om den är viktig eller inte.
- Filtermetoder är mycket snabbare jämfört med omslagsmetoder eftersom de inte involverar träning av modellerna. Å andra sidan är omslagsmetoder beräkningsmässigt kostsamma, och när det gäller massiva datamängder är omslagsmetoder inte den mest effektiva metoden för val av funktioner att överväga.
- Filtermetoder kan misslyckas med att hitta den bästa delmängden funktioner i situationer när det inte finns tillräckligt med data för att modellera funktionernas statistiska korrelation, men omslagsmetoder kan alltid ge den bästa delmängden funktioner på grund av deras uttömmande karaktär.
- Användning av funktioner från omslagsmetoder i din slutliga maskininlärningsmodell kan leda till överanpassning eftersom omslagsmetoder redan tränar maskininlärningsmodeller med funktionerna och det påverkar inlärningens verkliga kraft. Men funktioner från filtermetoder kommer inte att leda till överanpassning i de flesta fall
So långt har du studerat betydelsen av funktionsval och förstått skillnaden med dimensionalitetsreduktion. Du har också behandlat olika typer av metoder för funktionsurval. Så långt, så bra!
Nu ska vi se några fällor som du kan hamna i när du utför funktionsval:
Viktigt övervägande
Du kanske redan har förstått värdet av funktionsval i en pipeline för maskininlärning och vilken typ av tjänster det ger om det integreras. Men det är mycket viktigt att förstå exakt var du bör integrera funktionsval i din pipeline för maskininlärning.
Simpelt uttryckt bör du inkludera funktionsvalssteget innan du matar in data till modellen för träning, särskilt när du använder metoder för uppskattning av noggrannhet, t.ex. korsvalidering. Detta säkerställer att funktionsurvalet utförs på datafilen precis innan modellen tränas. Men om du utför funktionsval först för att förbereda dina data och sedan utför modellval och träning på de valda funktionerna skulle det vara ett misstag.
Om du utför funktionsval på alla data och sedan korsvaliderar, användes även testdata i varje veck i korsvalideringsproceduren för att välja funktionerna, och detta tenderar att snedvrida prestandan hos din maskininlärningsmodell.
Tillräckligt med teorier! Låt oss gå direkt till kodning nu.
En fallstudie i Python
För den här fallstudien kommer du att använda datasetet Pima Indians Diabetes. Beskrivningen av datasetet finns här.
Datasetet motsvarar klassificeringsuppgifter där du måste förutsäga om en person har diabetes baserat på 8 funktioner.
Det finns totalt 768 observationer i datasetet. Din första uppgift är att ladda datasetet så att du kan fortsätta. Men innan dess ska vi importera de nödvändiga beroendena, du kommer att behöva. Du kan importera de andra under tiden.
import pandas as pdimport numpy as npNu när beroendena är importerade ska vi ladda Pima Indians-dataset till ett Dataframe-objekt med hjälp av Pandas-biblioteket.
data = pd.read_csv("diabetes.csv")Dataset är framgångsrikt laddat till Dataframe-objektet data. Låt oss nu ta en titt på data.
data.head()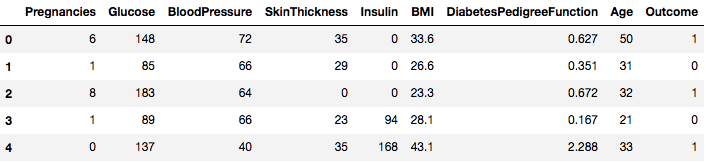
Så du kan se 8 olika funktioner märkta i utfallen 1 och 0 där 1 står för att observationen har diabetes och 0 betecknar att observationen inte har diabetes. Det är känt att datasetet har saknade värden. Närmare bestämt saknas observationer för vissa kolumner som är markerade som ett nollvärde. Du kan härleda detta från definitionen av dessa kolumner, och det är opraktiskt att ha ett nollvärde är ogiltigt för dessa mått, t.ex, noll för kroppsmasseindex eller blodtryck är ogiltigt.
Men för den här handledningen kommer du att direkt använda den förbehandlade versionen av datasetet.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Du laddade data i ett DataFrame-objekt som heter dataframe nu.
Låt oss konvertera DataFrame-objektet till en NumPy-array för att uppnå en snabbare beräkning. Låt oss också separera data till separata variabler så att funktionerna och etiketterna separeras.
array = dataframe.valuesX = arrayY = arrayVackert! Du har förberett dina data.
Först ska du implementera ett statistiskt Chi-Squared-test för icke-negativa funktioner för att välja ut 4 av de bästa funktionerna från datasetet. Du har redan sett att Chi-Squared-testet tillhör klassen filtermetoder. Om någon är nyfiken på att känna till det interna i Chi-Squared gör den här videon ett utmärkt jobb.
Biblioteket scikit-learn tillhandahåller klassen SelectKBest som kan användas med en rad olika statistiska tester för att välja ett visst antal funktioner, i det här fallet är det Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Du har importerat biblioteken för att köra experimenten. Nu ska vi se det i praktiken.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Tolkning:
Du kan se poängen för varje attribut och de fyra attribut som valts ut (de med högst poäng): plas, test, massa och ålder. Dessa poäng kommer att hjälpa dig att bestämma de bästa egenskaperna för att träna din modell.
P.S.: Den första raden anger namnen på egenskaperna. För förbehandling av datamängden har namnen kodats numeriskt.
Nästan kommer du att implementera Recursive Feature Elimination som är en typ av omslagsmetod för urval av funktioner.
Recursive Feature Elimination (eller RFE) fungerar genom att rekursivt ta bort attribut och bygga en modell på de attribut som återstår.
Den använder modellens noggrannhet för att identifiera vilka attribut (och kombinationer av attribut) som bidrar mest till att förutsäga målattributet.
Du kan lära dig mer om RFE-klassen i scikit-learn-dokumentationen.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionDu kommer att använda RFE med Logistic Regression-klassificatorn för att välja ut de tre bästa funktionerna. Valet av algoritm spelar inte så stor roll så länge den är skicklig och konsekvent.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Du kan se att RFE valde de tre bästa funktionerna som preg, mass och pedi.
Dessa är markerade med True i support arrayen och markerade med ett val ”1” i ranking arrayen. Detta indikerar i sin tur styrkan hos dessa funktioner.
Nästan kommer du att använda Ridge regression som i princip är en regulariseringsteknik och en inbäddad teknik för val av funktioner också.
Denna artikel ger dig en utmärkt förklaring om Ridge regression. Se till att kolla in den.
# First things firstfrom sklearn.linear_model import RidgeNästan kommer du att använda Ridge regression för att bestämma koefficienten R2.
Kolla också in scikit-learns officiella dokumentation om Ridge regression.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)För att bättre förstå resultaten av Ridge regression kommer du att implementera en liten hjälpfunktion som kommer att hjälpa dig att skriva ut resultaten i en bättre så att du kan tolka dem enkelt.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Nästan kommer du att skicka Ridge-modellens koefficienttermer till den här lilla funktionen och se vad som händer.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Du kan se alla koefficienttermerna bifogade med funktionsvariablerna. Det kommer återigen att hjälpa dig att välja de mest väsentliga funktionerna. Nedan följer några punkter som du bör tänka på när du tillämpar Ridge-regression:
- Det är också känt som L2-regularisering.
- För korrelerade funktioner innebär det att de tenderar att få liknande koefficienter.
- Funktioner med negativa koefficienter bidrar inte så mycket. Men i ett mer komplext scenario där du har att göra med många funktioner kommer denna poäng definitivt att hjälpa dig i den slutliga beslutsprocessen för val av funktioner.
Detta avslutar avsnittet om fallstudier. De metoder som du implementerade i avsnittet ovan kommer att hjälpa dig att förstå funktionerna i ett visst dataset på ett heltäckande sätt. Låt mig ge dig några kritiska punkter om dessa tekniker:
- Väljning av egenskaper är i huvudsak en del av förbearbetning av data som anses vara den mest tidskrävande delen av varje pipeline för maskininlärning.
- Dessa tekniker hjälper dig att närma dig det på ett mer systematiskt sätt och ett maskininlärningsvänligt sätt. Du kommer att kunna tolka funktionerna mer exakt.
Växla upp!
I det här inlägget täckte du ett av de mest välstuderade och välforskade statistiska ämnena, dvs. val av funktioner. Du blev också bekant med dess olika varianter och använde dem för att se vilka funktioner i en datamängd som är viktiga.
Du kan ta den här handledningen vidare genom att slå in ett korrelationsmått i wrapper-metoden och se hur det fungerar. Under handlingsförloppet kan det sluta med att du skapar en egen mekanism för val av funktioner. På så sätt lägger du grunden för din lilla forskning. Forskare använder också olika principer för soft computing för att utföra urvalet. Detta är i sig ett helt område för studier och forskning. Du bör också prova de befintliga algoritmerna för funktionsurval på olika datamängder och dra dina egna slutsatser.
Varför håller dessa traditionella metoder för funktionsurval fortfarande?
Ja, den frågan är uppenbar. Eftersom det finns neurala nätarkitekturer (t.ex. CNN) som är fullt kapabla att extrahera de mest betydelsefulla funktionerna från data, men även detta har en begränsning. Att använda ett CNN för ett vanligt tabellerat dataset som inte har specifika egenskaper (de egenskaper som en typisk bild har, t.ex. övergångsegenskaper, kanter, positionsegenskaper, konturer etc.) är inte det klokaste beslutet att fatta. När du dessutom har begränsade data och begränsade resurser kan det bli ett fullständigt slöseri att träna en CNN på vanliga tabulära datamängder. Så i sådana situationer kommer de metoder som du har studerat definitivt att komma till nytta.
Följande är några resurser om du vill gräva mer i det här ämnet:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection: Statistical and Optimization Perspectives Workshop
- Feature Selection: Problemställning och användningsområden
- Användning av genetiska algoritmer för urval av funktioner i dataanalys
Nedan följer de referenser som användes för att skriva den här handledningen.
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- En introduktion till funktionsval
- Analytics Vidhya artikel om funktionsval
- Hierarkisk och blandad modell – DataCamp kurs
- Feature Selection For Machine Learning in Python
- Outlier Detection in Stream Data by MachineLearning and Feature Selection Methods
- S. Visalakshi och V. Radha, ”A literature review of feature selection techniques and applications: Review of feature selection in data mining”, 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, s. 1-6.
.