Översikt
- Lär dig att tolka bias och varians i en given modell.
- Vad är skillnaden mellan Bias och Varians?
- Hur man uppnår Bias och Varians Tradeoff med hjälp av arbetsflöde för maskininlärning
Introduktion
Låt oss prata om vädret. Det regnar bara om det är lite fuktigt och det regnar inte om det blåser, är varmt eller fryser. Hur skulle du i det här fallet träna en prediktiv modell och se till att det inte blir några fel i väderprognosen? Du kanske säger att det finns många inlärningsalgoritmer att välja mellan. De skiljer sig åt på många sätt, men det finns en stor skillnad i vad vi förväntar oss och vad modellen förutsäger. Det är begreppet Bias and Variance Tradeoff.
Ovanligtvis lärs Bias and Variance Tradeoff ut genom täta matematiska formler. Men i den här artikeln har jag försökt att förklara bias och varians så enkelt som möjligt!
Mitt fokus kommer att vara att snurra dig genom processen att förstå problemformuleringen och se till att du väljer den bästa modellen där bias- och variansfelen är minimala.
För detta har jag tagit upp det populära datasetet för Pima Indians Diabetes. Datasetetet består av diagnostiska mätningar av vuxna kvinnliga patienter av indianskt Pima-arv. För detta dataset kommer vi att fokusera på variabeln ”Outcome” – som anger om patienten har diabetes eller inte. Detta är uppenbarligen ett binärt klassificeringsproblem och vi kommer att dyka rakt in och lära oss hur vi ska gå till väga.
Om du är intresserad av detta och datavetenskapliga begrepp och vill lära dig praktiskt hänvisar vi till vår kurs – Introduktion till datavetenskap
Tabellförteckning
- Utvärdering av en maskininlärningsmodell
- Problemformulering och primära steg
- Vad är bias?
- Vad är varians?
- Bias-Varians Tradeoff
Utvärdering av din maskininlärningsmodell
Maskinininlärningsmodellens primära mål är att lära sig från givna data och generera förutsägelser utifrån det mönster som observeras under inlärningsprocessen. Vår uppgift slutar dock inte där. Vi måste kontinuerligt göra förbättringar av modellerna, baserat på den typ av resultat som den genererar. Vi kvantifierar också modellens prestanda med hjälp av mått som noggrannhet, medelvärde av kvadratfel (MSE), F1-poäng osv. och försöker förbättra dessa mått. Detta kan ofta bli knepigt när vi måste behålla modellens flexibilitet utan att kompromissa med dess korrekthet.
En övervakad maskininlärningsmodell syftar till att träna sig själv på indatavariablerna (X) på ett sådant sätt att de förutspådda värdena (Y) ligger så nära de faktiska värdena som möjligt. Skillnaden mellan de faktiska värdena och de förutspådda värdena är felet och används för att utvärdera modellen. Felet för varje övervakad algoritm för maskininlärning består av tre delar:
- Biasfel
- Variansfel
- Bruset
Vidare bruset är det irreducerbara felet som vi inte kan eliminera, medan de andra två i.
I följande avsnitt kommer vi att behandla biasfelet, variansfelet och avvägningen mellan bias och varians, vilket kommer att hjälpa oss att välja den bästa modellen. Och det som är spännande är att vi kommer att täcka några tekniker för att hantera dessa fel genom att använda ett exempeldataset.
Problemformulering och primära steg
Som förklarats tidigare har vi tagit upp Pima Indians Diabetes-dataset och bildat ett klassificeringsproblem på det. Låt oss börja med att mäta datasetet och observera vilken typ av data vi har att göra med. Detta gör vi genom att importera de nödvändiga biblioteken:
Nu ska vi ladda in data i en dataram och observera några rader för att få en inblick i data.
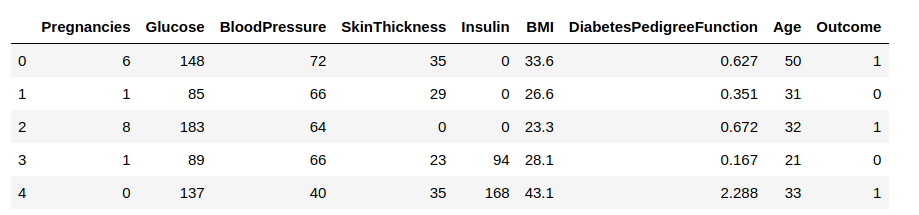
Vi måste förutsäga kolumnen ”Outcome”. Låt oss separera den och tilldela den till en målvariabel ”y”. Resten av dataramen kommer att vara uppsättningen av ingångsvariabler X.
Nu ska vi skala prediktionsvariablerna och sedan separera tränings- och testdata.
Då resultaten klassificeras i binär form kommer vi att använda den enklaste K-nearest neighbor-klassificatorn (Knn) för att klassificera om patienten har diabetes eller inte.
Men hur bestämmer vi värdet på ”k”?
- Kanske bör vi använda k = 1 så att vi får mycket goda resultat på våra träningsdata? Det kan fungera, men vi kan inte garantera att modellen kommer att prestera lika bra på våra testdata eftersom den kan bli för specifik
- Hur är det med att använda ett högt värde på k, till exempel k = 100 så att vi kan ta hänsyn till ett stort antal närmsta punkter för att även ta hänsyn till de avlägsna punkterna? Den här typen av modell blir dock för generisk och vi kan inte vara säkra på att den har beaktat alla möjliga bidragande egenskaper korrekt.
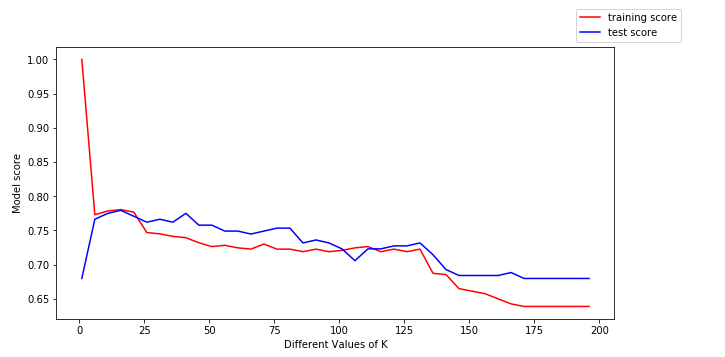
Låt oss ta några möjliga värden på k och anpassa modellen på träningsdata för alla dessa värden. Vi kommer också att beräkna träningsresultatet och testresultatet för alla dessa värden.
För att få mer insikt i detta kan vi plotta träningsdata (i rött) och testdata (i blått).
För att beräkna poängen för ett visst värde på k,
![]()
Vi kan dra följande slutsatser från ovanstående plottning:
- För låga värden på k är träningsresultatet högt, medan testresultatet är lågt
- När värdet på k ökar börjar testresultatet öka och träningsresultatet börjar minska.
- Hur som helst, vid ett visst värde på k, ligger både träningsresultatet och testresultatet nära varandra.
Det är här som bias och varians kommer in i bilden.
Vad är bias?
I de enklaste termerna är bias skillnaden mellan det förutsedda värdet och det förväntade värdet. För att förklara närmare gör modellen vissa antaganden när den tränar på de tillhandahållna uppgifterna. När den introduceras för test-/valideringsdata är dessa antaganden kanske inte alltid korrekta.
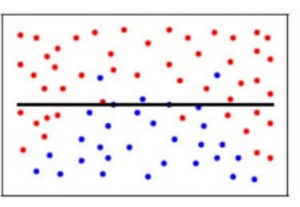
I vår modell kan modellen, om vi använder ett stort antal närmaste grannar, helt och hållet besluta att vissa parametrar inte alls är viktiga. Den kan till exempel bara anse att glukosnivån och blodtrycket avgör om patienten har diabetes. Denna modell skulle göra mycket starka antaganden om att de andra parametrarna inte påverkar resultatet. Man kan också se det som en modell som förutsäger ett enkelt förhållande när datapunkterna tydligt visar på ett mer komplext förhållande:
Matematiskt sett, låt ingångsvariablerna vara X och en målvariabel Y. Vi kartlägger förhållandet mellan de två med hjälp av en funktion f.
Därvidlag,
Y = f(X) + e
Här är ”e” felet som är normalt fördelat. Syftet med vår modell f'(x) är att förutsäga värden som ligger så nära f(x) som möjligt. Här är modellens bias:
Bias = E
Som jag förklarade ovan, när modellen gör generaliseringarna dvs. när det finns ett högt biasfel, resulterar det i en mycket förenklad modell som inte tar hänsyn till variationerna särskilt väl. Eftersom den inte lär sig träningsdata särskilt bra kallas det för Underfitting.
Vad är en varians?
I motsats till bias är variansen när modellen tar hänsyn till fluktuationerna i data dvs. även bruset. Så vad händer när vår modell har en hög varians?
Modellen kommer fortfarande att betrakta variansen som något att lära sig av. Det vill säga, modellen lär sig för mycket från träningsdata, så mycket att den när den konfronteras med nya data (testdata) inte kan förutsäga exakt utifrån dem.
Matematiskt sett är variansfelet i modellen:
Varians-E^2
Då modellen vid hög varians lär sig för mycket från träningsdata, kallas det för överanpassning.
I samband med våra data, om vi använder mycket få närmaste grannar, är det som att säga att om antalet graviditeter är mer än 3, glukosnivån är mer än 78, det diastoliska blodtrycket är mindre än 98, hudtjockleken är mindre än 23 mm och så vidare för varje funktion….. besluta att patienten har diabetes. Alla andra patienter som inte uppfyller ovanstående kriterier är inte diabetiker. Detta kan vara sant för en viss patient i träningsuppsättningen, men vad händer om dessa parametrar är avvikande värden eller till och med har registrerats felaktigt? Det är uppenbart att en sådan modell kan visa sig vara mycket kostsam!
Den här modellen skulle dessutom ha en hög felvarians eftersom förutsägelserna om huruvida patienten är diabetiker eller inte varierar kraftigt beroende på vilken typ av träningsdata vi tillhandahåller den. Så även om vi ändrar glukosnivån till 75 skulle modellen förutsäga att patienten inte har diabetes.
För att göra det enklare förutsäger modellen mycket komplexa förhållanden mellan utfallet och de ingående egenskaperna när en kvadratisk ekvation skulle ha räckt. Så här skulle en klassificeringsmodell se ut när det finns ett högt variansfel/överanpassning:
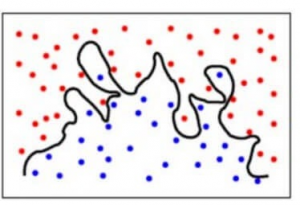
För att sammanfatta,
- En modell med ett högt biasfel underanpassar data och gör mycket förenklade antaganden om dem
- En modell med ett högt variansfel överanpassar data och lär sig för mycket av dem
- En bra modell är en modell där både bias- och variansfel är balanserade
Bias-variansavvägning
Hur relaterar vi ovanstående koncept till vår Knn-modell från tidigare? Låt oss ta reda på det!
I vår modell, säg, för, k = 1, kommer den punkt som ligger närmast datapunkten i fråga att beaktas. Här kan förutsägelsen vara korrekt för just den datapunkten, så biasfelet blir mindre.
Däremot kommer variansfelet att vara högt eftersom endast den ena närmsta punkten beaktas och detta tar inte hänsyn till de andra möjliga punkterna. Vilket scenario tror du att detta motsvarar? Ja, du tänker rätt, det betyder att vår modell är överanpassad.
Å andra sidan, för högre värden på k, kommer många fler punkter som ligger närmare datapunkten i fråga att beaktas. Detta skulle resultera i högre biasfel och underanpassning eftersom många punkter närmare datapunkten beaktas och därmed kan den inte lära sig de specifika detaljerna från träningsuppsättningen. Vi kan dock ta hänsyn till ett lägre variansfel för testuppsättningen som har okända värden.
För att uppnå en balans mellan biasfelet och variansfelet behöver vi ett sådant värde på k att modellen varken lär sig av bruset (överanpassning av data) eller gör svepande antaganden om data (underanpassning av data). För att hålla det enklare skulle en balanserad modell se ut så här:
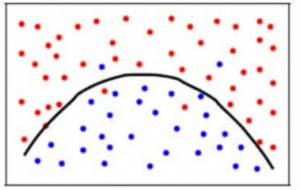
Trots att vissa punkter klassificeras felaktigt passar modellen i allmänhet in på de flesta datapunkterna korrekt. Balansen mellan biasfelet och variansfelet är bias-varians-avvägningen.
Följande bulls-eye-diagram förklarar avvägningen bättre:
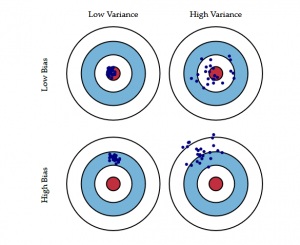
Centret, dvs. bulls-eye, är det modellresultat som vi vill uppnå och som perfekt förutspår alla värden på ett korrekt sätt. När vi rör oss bort från bull’s eye börjar vår modell göra fler och fler felaktiga förutsägelser.
En modell med låg bias och hög varians förutsäger punkter som ligger runt centrum generellt sett, men ganska långt ifrån varandra. En modell med hög bias och låg varians ligger ganska långt från kulan, men eftersom variansen är låg ligger de förutspådda punkterna närmare varandra.
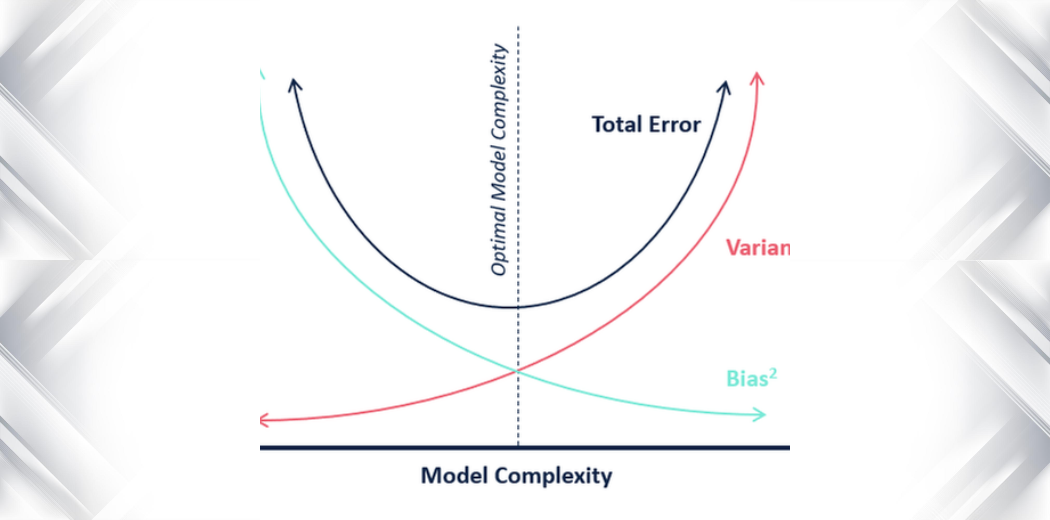
När det gäller modellens komplexitet kan vi använda följande diagram för att bestämma oss för den optimala komplexiteten hos vår modell.
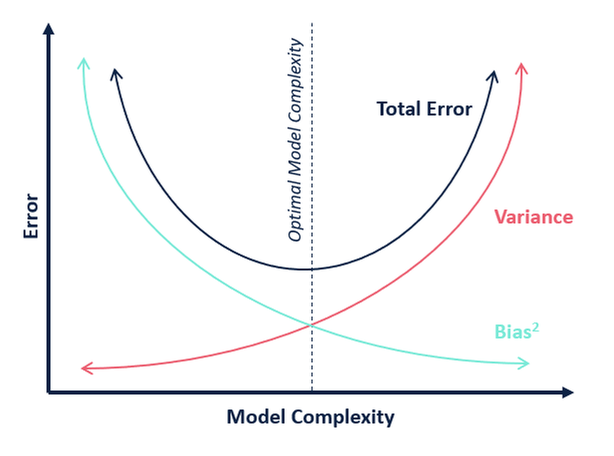
Så, vad tror du är det optimala värdet för k?
Utifrån ovanstående förklaring kan vi dra slutsatsen att det k för vilket
- testpoängen är högst och
- både testpoängen och träningspoängen ligger nära varandra
är det optimala värdet för k. Så även om vi kompromissar med ett lägre träningsresultat får vi fortfarande ett högt resultat för våra testdata, vilket är mer avgörande – testdata är trots allt okända data.
Låt oss göra en tabell för olika värden på k för att ytterligare bevisa detta:
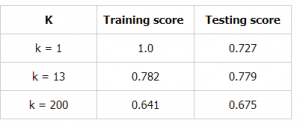
Slutsats
För att sammanfatta har vi i den här artikeln lärt oss att en idealisk modell skulle vara en modell där både biasfelet och variansfelet är låga. Vi bör dock alltid sträva efter en modell där modellpoängen för träningsdata ligger så nära modellpoängen för testdata som möjligt.
Det var där vi kom fram till hur vi kan välja en modell som inte är för komplex (hög varians och låg bias) vilket skulle leda till överanpassning och inte heller för enkel (hög bias och låg varians) vilket skulle leda till underanpassning.
Bias och varians spelar en viktig roll när det gäller att avgöra vilken prediktiv modell som ska användas. Jag hoppas att den här artikeln förklarade begreppet väl.