
Innan jag började den här resan med att försöka lära mig datavetenskap fanns det vissa termer och fraser som fick mig att vilja springa åt andra hållet.
Men i stället för att springa låtsades jag att jag kände till dem, nickade med i samtal och låtsades som om jag visste vad någon hänvisade till trots att sanningen var att jag inte hade någon aning och faktiskt hade slutat lyssna helt och hållet när jag hörde den där superskrämmande datavetenskapstermen™. Under den här seriens gång har jag lyckats täcka en hel del område och många av dessa termer har faktiskt blivit mycket mindre skrämmande!
Det finns dock en stor term som jag har undvikit under en längre tid. Fram till nu har jag varje gång jag har hört den här termen känt mig förlamad. Det har dykt upp i vardagliga samtal på träffar och ibland i konferensföreläsningar. Varje gång tänker jag på maskiner som snurrar och datorer som spottar ut kodsträngar som är omöjliga att tyda förutom att alla andra runt omkring mig faktiskt kan tyda dem så att det faktiskt bara är jag som inte vet vad som pågår (oj, hur kunde det hända?!).
Kanske är jag inte den enda som har känt så. Men jag antar att jag borde berätta vad den här termen faktiskt är, eller hur? Ja, gör er redo, för jag talar om det ständigt svårfångade och till synes förvirrande abstrakta syntaxträdet, eller AST förkortat. Efter många år av skrämselhicka är jag glad över att äntligen sluta vara rädd för denna term och verkligen förstå vad i hela världen det är.
Det är dags att möta roten till det abstrakta syntaxträdet rakt på sak – och höja nivån på vårt parsingspel!
Alla goda uppdrag börjar med en solid grund, och vårt uppdrag att avmystifiera denna struktur bör börja på exakt samma sätt: med en definition, förstås!
Ett abstrakt syntaxträd (vanligtvis bara kallat AST) är egentligen inget annat än en förenklad, kondenserad version av ett parse tree. I samband med kompilatorkonstruktion används termen ”AST” omväxlande med syntaxträd.

Vi tänker ofta på syntaxträd (och hur de konstrueras) i jämförelse med deras motsvarigheter i form av parseträd, som vi redan är ganska bekanta med. Vi vet att parse trees är träddatastrukturer som innehåller den grammatiska strukturen i vår kod; med andra ord innehåller de all syntaktisk information som förekommer i en ”mening” i koden, och som härleds direkt från grammatiken i själva programmeringsspråket.
Ett abstrakt syntaxträd ignorerar å andra sidan en betydande del av den syntaktiska information som ett parse tree annars skulle innehålla.
En AST innehåller däremot bara den information som är relaterad till analysen av källtexten, och hoppar över allt annat extra innehåll som används under analysen av texten.
Denna distinktion börjar bli mycket mer meningsfull om vi fokuserar på ”abstraktheten” hos en AST.
Vi kommer ihåg att ett parseträd är en illustrerad, bildlig version av den grammatiska strukturen i en mening. Med andra ord kan vi säga att ett parse tree representerar exakt hur ett uttryck, en mening eller en text ser ut. Det är i princip en direktöversättning av själva texten; vi tar meningen och förvandlar varje liten del av den – från interpunktionen till uttrycken och tokenerna – till en träddatastruktur. Det avslöjar den konkreta syntaxen i en text, vilket är anledningen till att det också kallas ett konkret syntaxträd, eller CST. Vi använder termen konkret för att beskriva denna struktur eftersom det är en grammatisk kopia av vår kod, token för token, i trädformat.
Men vad är det som gör något konkret kontra abstrakt? Jo, ett abstrakt syntaxträd visar oss inte exakt hur ett uttryck ser ut, på samma sätt som ett parseträd gör.

Snarare visar ett abstrakt syntaxträd oss de ”viktiga” bitarna – det som vi verkligen bryr oss om, som ger mening åt själva vår kod ”mening”. Syntaxträd visar oss de viktiga bitarna i ett uttryck, eller den abstrakta syntaxen i vår källtext. I jämförelse med konkreta syntaxträd är dessa strukturer därför abstrakta representationer av vår kod (och på vissa sätt mindre exakta), vilket är exakt så de fått sitt namn.
När vi nu förstår skillnaden mellan dessa två datastrukturer och de olika sätt på vilka de kan representera vår kod, är det värt att ställa frågan: var passar ett abstrakt syntaxträd in i kompilatorn? Låt oss först påminna oss om allt vi vet om kompileringsprocessen så som vi känner till den hittills.

Vad sägs om vi har en superkort och snygg källtext, som ser ut så här: 5 + (1 x 12).
Vi kommer ihåg att det första som händer i kompileringsprocessen är skanning av texten, ett jobb som utförs av skannern, vilket resulterar i att texten delas upp i minsta möjliga delar, som kallas lexem. Denna del kommer att vara språkanvänd, och vi kommer att sluta med den avskalade versionen av vår källtext.
Nästan skickas just dessa lexemes vidare till lexer/tokenizer, som förvandlar dessa små representationer av vår källtext till tokens, som kommer att vara specifika för vårt språk. Våra tokens kommer att se ut ungefär så här: . Den gemensamma insatsen av skannern och tokenizern utgör den lexikala analysen av kompilering.
När vår indata väl har tokeniserats skickas de resulterande tokenerna vidare till vår parser, som sedan tar källtexten och bygger upp ett parseträd av den. Illustrationen nedan exemplifierar hur vår tokeniserade kod ser ut, i parseträdsformat.
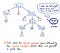
Arbetet med att förvandla tokens till ett parseträd kallas också för parsing, och är känt som syntaxanalysfasen. Syntaxanalysfasen är direkt beroende av den lexikala analysfasen; därför måste den lexikala analysen alltid komma först i kompileringsprocessen, eftersom vår kompilators parser bara kan göra sitt jobb när tokenizern gör sitt jobb!
Vi kan se kompilatorns delar som goda vänner, som alla är beroende av varandra för att se till att vår kod omvandlas korrekt från en text eller fil till ett parseträd.
Men tillbaka till vår ursprungliga fråga: var passar det abstrakta syntaxträdet in i den här kompisgruppen? Tja, för att kunna besvara den frågan hjälper det att förstå behovet av ett AST i första hand.
Kondensering av ett träd till ett annat
Okej, så nu har vi två träd att hålla rakt i våra huvuden. Vi hade redan ett parse tree, och hur det finns ännu en datastruktur att lära sig! Och tydligen är den här AST-datastrukturen bara ett förenklat parse tree. Så varför behöver vi den? Vad är ens poängen med det?
Nja, låt oss ta en titt på vårt parseträd, ska vi?
Vi vet redan att parseträd representerar vårt program i dess mest distinkta delar; det var faktiskt därför som skannern och tokenizern har så viktiga uppgifter att bryta ner vårt uttryck till dess minsta delar!
Vad innebär det egentligen att representera ett program med dess mest distinkta delar?
Det visar sig att ibland är alla distinkta delar av ett program faktiskt inte så användbara för oss hela tiden.
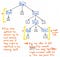
Vi kan ta en titt på illustrationen som visas här, som representerar vårt ursprungliga uttryck, 5 + (1 x 12), i parse tree tree-format. Om vi tittar närmare på det här trädet med ett kritiskt öga ser vi att det finns några fall där en nod har exakt ett barn, vilka också kallas single-successor-noder, eftersom de bara har en barnnod som härstammar från dem (eller en ”efterträdare”).
I fallet med vårt parseträdsexempel har single-successor-noderna en överordnad nod av typen Expression eller Exp, som har en enda efterföljare av något värde, till exempel 5, 1 eller 12. Men Exp-föräldernoderna här tillför egentligen ingenting av värde för oss, eller hur? Vi kan se att de innehåller token/terminal-barnnoder, men vi bryr oss egentligen inte om modernoden ”expression”; allt vi egentligen vill veta är vad uttrycket är?
Den överordnade noden ger oss ingen ytterligare information alls när vi väl har analyserat vårt träd. Istället är det den enda barn- och efterträdarnoden som vi verkligen är intresserade av. Det är faktiskt den noden som ger oss den viktiga informationen, den del som är betydelsefull för oss: själva antalet och värdet! Med tanke på att dessa överordnade noder är ganska onödiga för oss, blir det uppenbart att det här parseträdet är ett slags verbose.
Alla dessa single-successor-noder är ganska överflödiga för oss, och hjälper oss inte alls. Så låt oss göra oss av med dem!
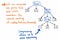
Om vi komprimerar single-successor-knutarna i vårt parseträd, kommer vi att få en mer komprimerad version av exakt samma struktur. Om vi tittar på illustrationen ovan ser vi att vi fortfarande behåller exakt samma nesting som tidigare, och våra noder/tokens/terminaler dyker fortfarande upp på rätt plats i trädet. Men vi har lyckats banta det lite.
Och vi kan trimma lite mer av vårt träd också. Om vi till exempel tittar på vårt parse-träd som det ser ut just nu, ser vi att det finns en spegelstruktur i det. Underuttrycket (1 x 12) är inbäddat i parenteser (), som i sig själva är tokens.
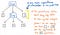
De här parenteserna är dock inte till någon större hjälp när vi väl har fått vårt träd på plats. Vi vet redan att 1 och 12 är argument som kommer att skickas till multiplikationsoperationen x, så parenteserna säger oss inte så mycket i det här läget. Faktum är att vi skulle kunna komprimera vårt parseträd ännu mer och göra oss av med dessa överflödiga bladnoder.
När vi komprimerar och förenklar vårt parseträd och gör oss av med det överflödiga syntaktiska ”dammet” får vi en struktur som ser synligt annorlunda ut i det här läget. Den strukturen är faktiskt vår nya och efterlängtade vän: det abstrakta syntaxträdet.

Bilden ovan illustrerar exakt samma uttryck som vårt parse-träd: 5 + (1 x 12). Skillnaden är att det har abstraherat uttrycket från den konkreta syntaxen. Vi ser inga fler parenteser () i det här trädet, eftersom de inte är nödvändiga. På samma sätt ser vi inga icke-terminaler som Exp, eftersom vi redan har räknat ut vad ”uttrycket” är, och vi kan dra ut det värde som verkligen betyder något för oss – till exempel talet 5.
Det är just detta som skiljer ett AST från ett CST. Vi vet att ett abstrakt syntaxträd ignorerar en betydande mängd av den syntaktiska information som ett parseträd innehåller, och hoppar över ”extra innehåll” som används vid parsning. Men nu kan vi se exakt hur det sker!

När vi nu har kondenserat ett eget parsaträd kommer vi att bli mycket bättre på att plocka upp några av de mönster som skiljer en AST från en CST.
Det finns några sätt på vilka ett abstrakt syntaxträd kommer att skilja sig visuellt från ett parseträd:
- En AST kommer aldrig att innehålla syntaktiska detaljer, såsom kommatecken, parenteser och semikolon (beroende naturligtvis på språket).
- En AST kommer att ha en sammanfälld version av vad som annars skulle framstå som noder med en enda efterträdare; den kommer aldrig att innehålla ”kedjor” av noder med ett enda barn.
- Finalt kommer alla operatörstoken (såsom
+,-,xoch/) att bli interna (överordnade) noder i trädet, snarare än de blad som slutar i ett parseträd.
Visuellt sett kommer ett AST alltid att verka mer kompakt än ett parseträd, eftersom det definitionsmässigt är en komprimerad version av ett parseträd, med färre syntaktiska detaljer.
Det skulle då vara logiskt att om ett AST är en komprimerad version av ett parseträd, så kan vi egentligen bara skapa ett abstrakt syntaxträd om vi har sakerna för att bygga ett parseträd till att börja med!
Det är faktiskt så här det abstrakta syntaxträdet passar in i den större kompileringsprocessen. Ett AST har en direkt koppling till de parseträd som vi redan har lärt oss om, samtidigt som det förlitar sig på att lexern gör sitt jobb innan ett AST någonsin kan skapas.

Det abstrakta syntaxträdet skapas som slutresultat av syntaxanalysfasen. Parseraren, som är den främsta ”karaktären” under syntaxanalysen, genererar kanske eller kanske inte alltid ett parse tree, eller CST. Beroende på kompilatorn och hur den är utformad kan analysatorn direkt övergå till att konstruera ett syntaxträd (AST). Men parsern kommer alltid att generera ett AST som sitt resultat, oavsett om den skapar ett parseträd däremellan, eller hur många överfarter den kan behöva göra för att göra det.
Anatomi av ett AST
När vi nu vet att det abstrakta syntaxträdet är viktigt (men inte nödvändigtvis skrämmande!) kan vi börja dissekera det en liten bit till. En intressant aspekt av hur AST är konstruerat har att göra med noderna i detta träd.
Bilden nedan visar hur en enskild nod i ett abstrakt syntaxträd ser ut.
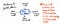
Vi märker att den här noden liknar andra noder som vi har sett tidigare genom att den innehåller data (en token och dess value). Den innehåller dock också några mycket specifika pekare. Varje nod i en AST innehåller hänvisningar till dess nästa syskonnod, samt dess första barnnod.
Till exempel skulle vårt enkla uttryck 5 + (1 x 12) kunna konstrueras till en visualiserad illustration av en AST, som den nedan.

Vi kan föreställa oss att läsning, traversering eller ”tolkning” av detta AST kan börja från de nedersta nivåerna i trädet och arbeta sig tillbaka uppåt för att bygga upp ett värde eller en retur result i slutet.
Det kan också vara till hjälp att se en kodad version av resultatet från en parser för att komplettera våra visualiseringar. Vi kan luta oss mot olika verktyg och använda redan existerande parsers för att se ett snabbt exempel på hur vårt uttryck kan se ut när det körs genom en parser. Nedan visas ett exempel på vår källtext, 5 + (1 * 12), som körs genom Esprima, en ECMAScript-parser, och dess resulterande abstrakta syntaxträd, följt av en lista över dess distinkta tokens.
I det här formatet kan vi se hur trädet är nästlat om vi tittar på de nästlade objekten. Vi märker att de värden som innehåller 1 och 12 är left respektive right barn till en överordnad operation, *. Vi ser också att multiplikationsoperationen (*) utgör det högra underträdet till hela uttrycket självt, vilket är anledningen till att den är inbäddad i det större BinaryExpression-objektet, under nyckeln "right". På samma sätt är värdet av 5 det enda "left" barnet i det större BinaryExpression objektet.

Den mest fascinerande aspekten av abstrakta syntaxträd är dock det faktum att även om de är så kompakta och rena är de inte alltid en enkel datastruktur att försöka konstruera. Faktum är att det kan vara ganska komplicerat att bygga upp ett AST, beroende på vilket språk parsern har att göra med!
De flesta parsers brukar antingen konstruera ett parseträd (CST) och sedan konvertera det till ett AST-format, eftersom det ibland kan vara enklare – även om det innebär fler steg, och generellt sett fler passager genom källtexten. Att bygga ett CST är faktiskt ganska enkelt när parseraren känner till grammatiken för det språk som den försöker parsa. Den behöver inte göra något komplicerat arbete för att räkna ut om en token är ”signifikant” eller inte; istället tar den bara exakt vad den ser, i den specifika ordning den ser det, och spottar ut allt i ett träd.
Å andra sidan finns det en del parsers som försöker göra allt detta som en process i ett enda steg, och hoppar direkt till att konstruera ett abstrakt syntaxträd.
Att bygga ett AST direkt kan vara knepigt, eftersom parsern inte bara måste hitta tokens och representera dem korrekt, utan också bestämma vilka tokens som är viktiga för oss och vilka som inte är det.
I kompilatorkonstruktion slutar AST:et med att vara superviktigt av mer än en anledning. Ja, det kan vara knepigt att konstruera (och förmodligen lätt att klanta sig), men det är också det sista och slutgiltiga resultatet av de lexikala och syntaxanalytiska faserna tillsammans! De lexikala och syntaxanalytiska faserna kallas ofta tillsammans för analysfasen, eller kompilatorns front-end.

Vi kan se på det abstrakta syntaxträdet som det ”slutgiltiga projektet” för kompilatorns front-end. Det är den viktigaste delen, eftersom det är det sista som frontenden har att visa upp. Den tekniska termen för detta kallas intermediate code representation eller IR, eftersom det blir den datastruktur som i slutändan används av kompilatorn för att representera en källtext.
Ett abstrakt syntaxträd är den vanligaste formen av IR, men också, ibland den mest missförstådda. Men nu när vi förstår den lite bättre kan vi börja ändra vår uppfattning om denna skrämmande struktur! Förhoppningsvis är den lite mindre skrämmande för oss nu.
Resurser
Det finns en hel del resurser där ute om ASTs, i en mängd olika språk. Att veta var man ska börja kan vara svårt, särskilt om man vill lära sig mer. Nedan finns några nybörjarvänliga resurser som går in på en hel del mer detaljer utan att vara alltför överväldigande. Glad asbtracting!
- The AST vs the Parse Tree, Professor Charles N. Fischer
- Vad är skillnaden mellan parse trees och abstract syntax trees?, StackOverflow
- Abstrakta vs. konkreta syntaxträd, Eli Bendersky
- Abstrakta syntaxträd, professor Stephen A. Edwards
- Abstrakta syntaxträd & Top-Down Parsing, professor Konstantinos (Kostis) Sagonas
- Lexikalisk och syntaxanalys av programmeringsspråk, Chris Northwood
- AST Explorer, Felix Kling