Poslední aktualizace 18. srpna 2020
Datové soubory mohou obsahovat chybějící hodnoty, což může způsobit problémy mnoha algoritmům strojového učení.
Před modelováním predikční úlohy je proto vhodné identifikovat a nahradit chybějící hodnoty pro každý sloupec vstupních dat. Tomuto postupu se říká imputace chybějících dat, zkráceně imputace.
Oblíbeným přístupem k imputaci dat je výpočet statistické hodnoty pro každý sloupec (například průměr) a nahrazení všech chybějících hodnot pro tento sloupec touto statistikou. Je to oblíbený přístup, protože statistiku lze snadno vypočítat pomocí trénovacího souboru dat a protože často vede k dobrému výkonu.
V tomto tutoriálu zjistíte, jak používat statistické strategie imputace chybějících dat ve strojovém učení.
Po dokončení tohoto tutoriálu budete vědět:
- Chybějící hodnoty musí být označeny hodnotami NaN a mohou být nahrazeny statistickými mírami pro výpočet sloupce hodnot.
- Jak načíst hodnotu CSV s chybějícími hodnotami a označit chybějící hodnoty hodnotami NaN a vykázat počet a procento chybějících hodnot pro každý sloupec.
- Jak imputovat chybějící hodnoty pomocí statistických měr jako metodu přípravy dat při vyhodnocování modelů a při sestavování konečného modelu pro předpovědi na nových datech.
Začněte svůj projekt s mou novou knihou Příprava dat pro strojové učení, která obsahuje návody krok za krokem a zdrojové soubory jazyka Python pro všechny příklady.
Začněme.
- Aktualizováno červen/2020:

Statistická imputace chybějících hodnot ve strojovém učení
Foto: Bernal Saborio, některá práva vyhrazena.
Přehled učiva
Toto učivo je rozděleno do tří částí; jsou to:
- Statistická imputace
- Soubor dat koňské koliky
- Statistická imputace pomocí SimpleImputeru
- Transformace dat pomocí SimpleImputeru
- Transformace dat pomocí SimpleImputeru a vyhodnocení modelu
- Srovnání různých imputovaných statistik
- Transformace SimpleImputer při vytváření predikce
.
Statistická imputace
Soubor dat může obsahovat chybějící hodnoty.
Jedná se o řádky dat, ve kterých není přítomna jedna nebo více hodnot nebo sloupců v daném řádku. Hodnoty mohou chybět úplně nebo mohou být označeny zvláštním znakem nebo hodnotou, například otazníkem „?“.
Tyto hodnoty lze vyjádřit mnoha způsoby. Viděl jsem, že se zobrazují jako vůbec nic , prázdný řetězec , explicitní řetězec NULL nebo nedefinovaný nebo N/A nebo NaN a číslo 0, mimo jiné. Bez ohledu na to, jak se v datové sadě objevují, znalost toho, co očekávat, a kontrola, zda data odpovídají tomuto očekávání, omezí problémy, jakmile začnete data používat.
– Strana 10, Příručka špatných dat, 2012.
Hodnoty mohou chybět z mnoha důvodů, často specifických pro danou problémovou oblast, a mohou zahrnovat důvody, jako je poškození měření nebo nedostupnost dat.
Mohou se vyskytnout z řady důvodů, jako je nefunkční měřicí zařízení, změny v experimentálním designu během sběru dat a srovnávání několika podobných, ale ne stejných souborů dat.
– Strana 63, Data Mining: Praktické nástroje a techniky strojového učení, 2016.
Většina algoritmů strojového učení vyžaduje číselné vstupní hodnoty a pro každý řádek a sloupec v souboru dat musí být přítomna hodnota. Chybějící hodnoty jako takové mohou algoritmům strojového učení způsobit problémy.
Proto je běžné identifikovat chybějící hodnoty v souboru dat a nahradit je číselnou hodnotou. Tomuto postupu se říká imputace dat nebo imputace chybějících dat.
Jednoduchý a oblíbený přístup k imputaci dat zahrnuje použití statistických metod k odhadu hodnoty sloupce z těch hodnot, které jsou přítomny, a poté nahrazení všech chybějících hodnot ve sloupci vypočtenou statistikou.
Jednoduchý je proto, že výpočet statistiky je rychlý, a oblíbený proto, že se často ukáže jako velmi efektivní.
Mezi běžné vypočtené statistiky patří:
- Střední hodnota sloupce.
- Medián sloupce.
- Modus sloupce.
- Konstantní hodnota.
Teď, když jsme se seznámili se statistickými metodami imputace chybějících hodnot, podívejme se na soubor dat s chybějícími hodnotami.
Chcete začít s přípravou dat?“
Podstupte nyní můj bezplatný 7denní e-mailový rychlokurz (s ukázkovým kódem).
Klikněte pro registraci a získejte také bezplatnou verzi kurzu ve formátu PDF Ebook.
Stáhněte si svůj minikurz ZDARMA
Soubor dat o koňských kolikách
Soubor dat o koňských kolikách popisuje zdravotní charakteristiky koní s kolikami a to, zda žili nebo zemřeli.
Je zde 300 řádků a 26 vstupních proměnných s jednou výstupní proměnnou. Jedná se o binární klasifikační predikční úlohu, která spočívá v předpovědi 1, pokud kůň žil, a 2, pokud kůň zemřel.
V této datové sadě můžeme vybrat mnoho polí pro predikci. V tomto případě budeme předpovídat, zda se jednalo o operaci, nebo ne (index sloupce 23), takže se jedná o binární klasifikační úlohu.
Datový soubor obsahuje četné chybějící hodnoty u mnoha sloupců, kde je každá chybějící hodnota označena znakem otazníku („?“).
Níže uvádíme příklad řádků z datového souboru s označenými chybějícími hodnotami.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Další informace o datové sadě se dozvíte zde:
- Datová sada pro koňské koliky
- Popis datové sady pro koňské koliky
Není třeba stahovat datovou sadu, protože ji stáhneme automaticky ve zpracovaných příkladech.
Označení chybějících hodnot hodnotou NaN (ne číslo) v načteném datasetu pomocí Pythonu je osvědčený postup.
Můžeme načíst dataset pomocí funkce read_csv() Pandas a zadat „na_values“ pro načtení hodnot ‚?‘ jako chybějící, označené hodnotou NaN.
|
1
2
3
4
|
…
# load dataset
url = ‚https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv‘
dataframe = read_csv(url, header=None, na_values=‘?‘)
|
Po načtení můžeme zkontrolovat načtená data a potvrdit, že „?“ hodnoty jsou označeny jako NaN.
|
1
2
3
|
…
# shrnutí prvních několika řádků
print(dataframe.head())
|
Poté můžeme vypsat každý sloupec a ohlásit počet řádků s chybějícími hodnotami pro daný sloupec.
|
1
2
3
4
5
6
7
|
…
# shrňte počet řádků s chybějícími hodnotami pro každý sloupec
for i in range(dataframe.shape):
# spočítejte počet řádků s chybějícími hodnotami
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‚> %d, Chybí: %d (%.1f%%)‘ % (i, n_miss, perc))
|
Kompletní příklad načtení a shrnutí datové sady je uveden níže.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# sumarizace souboru dat o koňských kolikách
from pandas import read_csv
# načtení souboru dat
url = ‚https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv‘
dataframe = read_csv(url, header=None, na_values=‘?‘)
# shrňte prvních několik řádků
print(dataframe.head())
# shrňte počet řádků s chybějícími hodnotami pro každý sloupec
for i in range(dataframe.shape):
# spočítejte počet řádků s chybějícími hodnotami
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‚> %d, Missing: %d (%.1f%%)‘ % (i, n_miss, perc))
|
Spuštěním příkladu se nejprve načte soubor dat a shrne se prvních pět řádků.
Vidíme, že chybějící hodnoty, které byly označeny znakem „?“, byly nahrazeny hodnotami NaN.
Dále vidíme seznam všech sloupců datového souboru a počet a procento chybějících hodnot.
Vidíme, že některé sloupce (např. sloupce s indexy 1 a 2) nemají žádné chybějící hodnoty a jiné sloupce (např. sloupce s indexy 15 a 21) mají mnoho nebo dokonce většinu chybějících hodnot.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Missing: 0 (0,0%)
> 2, Chybí: 0 (0,0%)
> 3, Chybí: Chybí: 60 (20,0%)
> 4, Chybí: 5, Chybí: 24 (8,0 %)
> 5, Chybí: 60 (8,0 %)
> Chybí: 58 (19,3 %)
> 6, Chybí: Chybí: 56 (18,7 %)
> 7, Chybí: (23,0 %)
> 8, Chybí: 69 (23,0 %)
> 8, Chybí: 6 (23,0 %) (15,7 %)
> 9, Chybí: 47 (15,7 %)
> 9: (10,7 %)
> 10, Chybí: 32 (10,7 %)
> 10, Chybí: 55 (18,3 %)
> 11, Chybí: 10 (18,3 %)
> 44 (14,7 %)
> 12, Chybí: (18,7 %)
> 13, Chybí: 56 (18,7 %)
> 13, Chybí: (34,7 %)
> 14, Chybí: 104 (34,7 %)
> 14, Chybí: 1: (35,3%)
> 15, Chybí: 106 (35,3%)
> (82,3 %)
> 16, Chybí: 247 (82,3 %)
> 16, Chybí: 1: (34,0 %)
> 17, Chybí: 102 (34,0 %)
> 17, Chybí: 1: (39,3 %)
> 18, Chybí: 118 (39,3 %)
> 18, Chybí: (9,7 %)
> 19, Chybí: 29 (9,7 %)
> 19, Chybí: (11,0 %)
> 20, Chybí: 33 (11,0 %)
> (55,0 %)
> 21, Chybí: 165 (55,0 %)
> 21, Chybí: (66,0 %)
> 22, Chybí: 198 (66,0 %)
> 22, Chybí: Chybí: 1 (0,3 %)
> 23, Chybí: 1 (0,3 %)
> 0 (0,0 %)
> 24, Chybějící: 0 (0,0 %)
> 0 (0,0%)
> 25, Chybí: 0 (0.0%)
> 26, Chybí: 0 (0.0%)
> 27, Chybí:
|
Teď, když jsme se seznámili se souborem dat o koňské kolice, který obsahuje chybějící hodnoty, podívejme se, jak můžeme použít statistickou imputaci.
Statistická imputace pomocí SimpleImputer
Knihovna strojového učení scikit-learn poskytuje třídu SimpleImputer, která podporuje statistickou imputaci.
V této části se budeme zabývat tím, jak efektivně používat třídu SimpleImputer.
Transformace dat SimpleImputer
Třída SimpleImputer je datová transformace, která se nejprve nakonfiguruje na základě typu statistiky, která se má pro každý sloupec vypočítat, např.např. průměr.
|
1
2
3
|
…
# define imputer
imputer = SimpleImputer(strategy=’mean‘)
|
Poté se imputer napasuje na soubor dat, aby se vypočítala statistika pro každý sloupec.
|
1
2
3
|
…
# fit na dataset
imputer.fit(X)
|
Na dataset se pak aplikuje fit imputer, který vytvoří kopii datasetu se všemi chybějícími hodnotami pro každý sloupec nahrazenými statistickou hodnotou.
|
1
2
3
|
…
# transformovat soubor dat
Xtrans = imputer.transform(X)
|
Jeho použití můžeme demonstrovat na souboru dat o koňských kolikách a potvrdit jeho funkčnost shrnutím celkového počtu chybějících hodnot v souboru dat před transformací a po ní.
Kompletní příklad je uveden níže.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# statistická imputace transformace pro soubor dat koňské koliky
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# načti dataset
url = ‚https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv‘
dataframe = read_csv(url, header=None, na_values=‘?‘)
# rozděl na vstupní a výstupní prvky
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# vypište celkový počet chybějících
print(‚Chybí: %d‘ % sum(isnan(X).flatten()))
# define imputer
imputer = SimpleImputer(strategy=’mean‘)
# fit on the dataaset
imputer.fit(X)
# transformujte soubor dat
Xtrans = imputer.transform(X)
# vypište celkové chybějící údaje
print(‚Missing: %d‘ % sum(isnan(Xtrans).flatten())
|
Spuštěním příkladu se nejprve načte datová sada a ohlásí se celkový počet chybějících hodnot v datové sadě jako 1 605.
Transformace je nakonfigurována, přizpůsobena a provedena a výsledná nová datová sada neobsahuje žádné chybějící hodnoty, což potvrzuje, že byla provedena podle našich očekávání.
Každá chybějící hodnota byla nahrazena střední hodnotou svého sloupce.
|
1
2
|
Chybí: 1605
Chybí:
|
Jednoduché vyhodnocování počítačů a modelů
Je dobrým zvykem vyhodnocovat modely strojového učení na souboru dat pomocí k-násobné křížové validace.
Pro správné použití statistické imputace chybějících dat a zamezení úniku dat je nutné, aby statistiky vypočtené pro každý sloupec byly vypočteny pouze na trénovací datové sadě a poté aplikovány na trénovací a testovací množiny pro každý fold v datové sadě.
Používáme-li převzorkování k výběru hodnot parametrů ladění nebo k odhadu výkonnosti, měla by být imputace začleněna v rámci převzorkování.
– Strana 42, Aplikované prediktivní modelování, 2013.
Toho lze dosáhnout vytvořením modelovací pipeline, kde prvním krokem je statistická imputace, druhým krokem pak model. Toho lze dosáhnout pomocí třídy Pipeline.
Například níže uvedená Pipeline používá SimpleImputer se strategií „mean“, po níž následuje model random forest.
|
1
2
3
4
5
|
…
# define modeling pipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean‘)
pipeline = Pipeline(steps=)
|
Můžeme vyhodnotit střední hodnotu.imputovaný soubor dat a pipeline pro modelování náhodného lesa pro soubor dat koňské koliky s opakovanou desetinásobnou křížovou validací.
Kompletní příklad je uveden níže.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# vyhodnotit průměrnou imputaci a náhodný výběr forest pro soubor dat koňské koliky
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# načti dataset
url = ‚https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv‘
dataframe = read_csv(url, header=None, na_values=‘?‘)
# rozděl na vstupní a výstupní prvky
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# define modeling pipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean‘)
pipeline = Pipeline(steps=)
# define model evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# vyhodnocení modelu
scores = cross_val_score(pipeline, X, y, scoring=’accuracy‘, cv=cv, n_jobs=-1)
print(‚Mean Accuracy: %.3f (%.3f)‘ % (mean(scores), std(scores)))
|
Při spuštění příkladu se správně aplikuje imputace dat na každou složku postupu křížové validace.
Poznámka: Vaše výsledky se mohou lišit vzhledem ke stochastické povaze algoritmu nebo postupu vyhodnocení nebo k rozdílům v číselné přesnosti. Zvažte několikanásobné spuštění příkladu a porovnejte průměrný výsledek.
Pipeline je vyhodnocena pomocí tří opakování desetinásobné křížové validace a uvádí průměrnou klasifikační přesnost na souboru dat přibližně 86 bodů.3 %, což je dobrý výsledek.
|
1
|
Střední přesnost: 0,863 (0.054)
|
Srovnání různých imputovaných statistik
Jak víme, že použití „střední“ statistické strategie je pro tento soubor dat dobré nebo nejlepší?“
Odpovědí je, že nevíme a že byla zvolena libovolně.
Můžeme navrhnout experiment, ve kterém otestujeme jednotlivé statistické strategie a zjistíme, co je pro tento soubor dat nejlepší, a porovnáme strategie průměr, medián, modus (nejčastější) a konstantní (0). Poté lze porovnat průměrnou přesnost jednotlivých přístupů.
Kompletní příklad je uveden níže.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# porovnat statistické imputační strategie pro soubor dat koňské koliky
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = ‚https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv‘
dataframe = read_csv(url, header=None, na_values=‘?‘)
# rozdělit na vstupní a výstupní prvky
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# vyhodnotíme každou strategii na souboru dat
results = list()
strategies =
for s in strategies:
# vytvořte modelovací potrubí
pipeline = Pipeline(steps=)
# vyhodnoťte model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy‘, cv=cv, n_jobs=-1)
# uložení výsledků
results.append(scores)
print(‚>%s %.3f (%.3f)‘ % (s, mean(scores), std(scores)))
# vykreslete výkonnost modelu pro srovnání
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
Spuštěním příkladu se vyhodnotí každá statistická imputační strategie na souboru dat koňské koliky pomocí opakované křížové validace.
Poznámka: Vaše výsledky se mohou lišit vzhledem ke stochastické povaze algoritmu nebo postupu vyhodnocení nebo k rozdílům v numerické přesnosti. Zvažte několikanásobné spuštění příkladu a porovnejte průměrný výsledek.
Podélně je uvedena průměrná přesnost každé strategie. Z výsledků vyplývá, že použití konstantní hodnoty, např. 0, vede k nejlepšímu výsledku přibližně 88,1 %, což je vynikající výsledek.
|
1
2
3
4
|
>průměr 0.860 (0,054)
>medián 0,862 (0.065)
>nejčastější_výskyt 0,872 (0,052)
>konstanta 0,881 (0,047)
|
Na konci běhu je pro každou sadu výsledků vytvořen krabicový a metkový graf, který umožňuje porovnat rozložení výsledků.
Je jasně vidět, že rozložení výsledků přesnosti pro konstantní strategii je lepší než pro ostatní strategie.
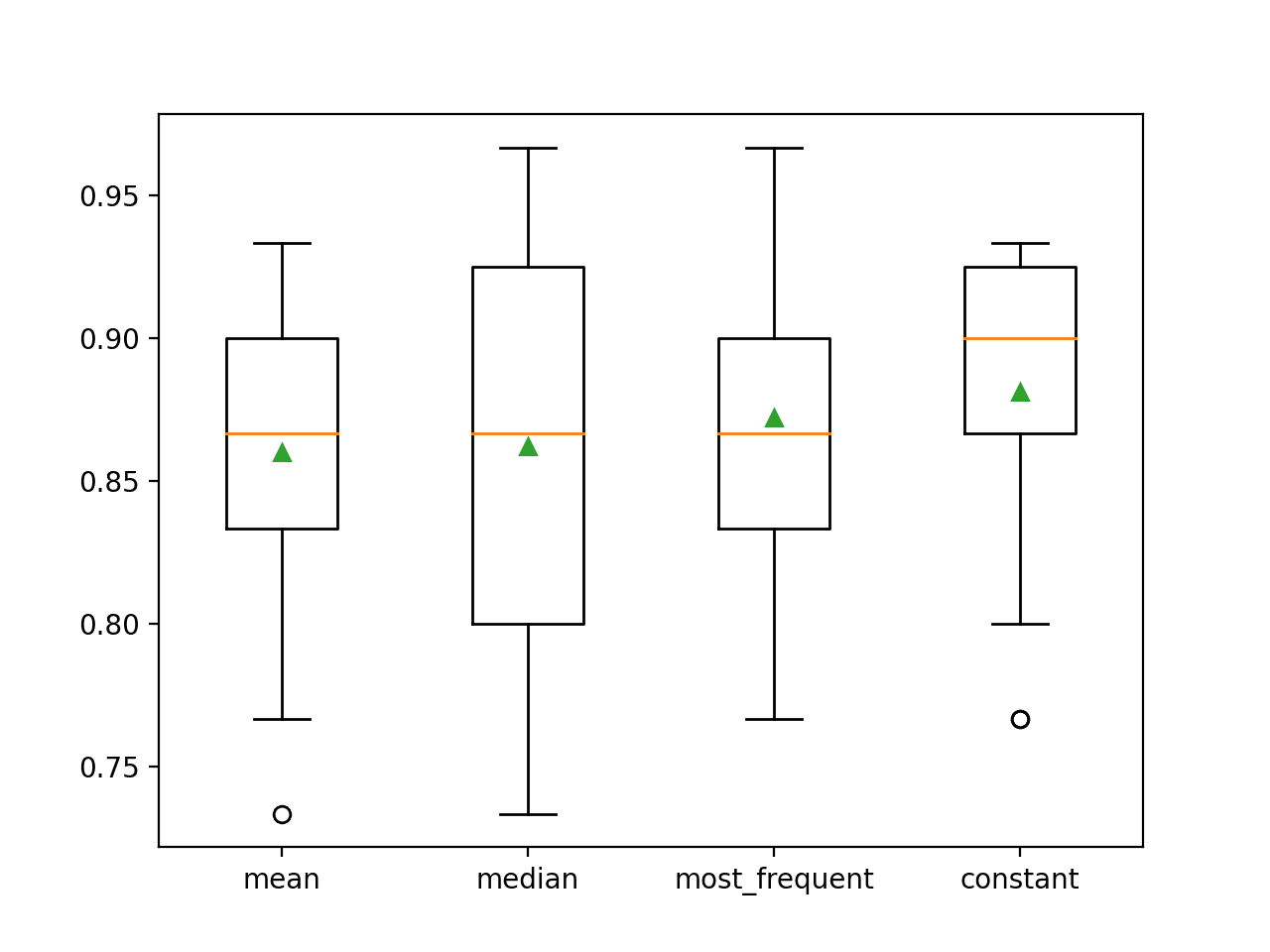
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
Jednoduchá počítačová transformace při vytváření předpovědi
Můžeme chtít vytvořit konečnou modelovací řadu s konstantní strategií imputace a algoritmem náhodného lesa a poté vytvořit předpověď pro nová data.
Toho lze dosáhnout definováním pipeline a jejím fitováním na všechna dostupná data, poté zavoláním funkce predict() s předáním nových dat jako argumentu.
Důležité je, že řádek nových dat musí označit všechny chybějící hodnoty pomocí hodnoty NaN.
|
1
2
3
|
…
# define new data
row =
|
Kompletní příklad je uveden níže.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# konstantní imputace strategie a predikce pro soubor dat o hadicové kolice
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ‚https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv‘
dataframe = read_csv(url, header=None, na_values=‘?‘)
# rozdělit na vstupní a výstupní prvky
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# vytvořte modelovací potrubí
pipeline = Pipeline(steps=)
# fitujte model
pipeline.fit(X, y)
# definujte nová data
row =
# proveďte predikci
yhat = pipeline.predict()
# shrňte predikci
print(‚Predikovaná třída: %d‘ % yhat)
|
Spuštění příkladu vyhovuje modelovací pipeline na všech dostupných datech.
Je definován nový řádek dat s chybějícími hodnotami označenými NaN a je provedena klasifikační predikce.
|
1
|
Predikovaná třída: 2
|
Další četba
Tato část obsahuje další zdroje k tématu, pokud chcete jít hlouběji.
Související výukové materiály
- Výsledky pro standardní klasifikační a regresní soubory dat strojového učení
- Jak pracovat s chybějícími daty pomocí Pythonu
Knihy
- Bad Data Handbook, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
APIs
- Imputation of missing values, scikit-learn Documentation.
- sklearn.impute.SimpleImputer API.
Datová sada
- Datová sada kolika koní
- Datová sada kolika koní Popis
Souhrn
V tomto tutoriálu jste zjistili, jak používat statistické strategie imputace chybějících dat ve strojovém učení.
Konkrétně jste se naučili:
- Chybějící hodnoty musí být označeny hodnotami NaN a mohou být nahrazeny statistickými mírami pro výpočet sloupce hodnot.
- Jak načíst hodnotu CSV s chybějícími hodnotami a označit chybějící hodnoty hodnotami NaN a vykázat počet a procento chybějících hodnot pro každý sloupec.
- Jak imputovat chybějící hodnoty pomocí statistiky jako metody přípravy dat při vyhodnocování modelů a při fitování finálního modelu pro předpovědi na nových datech.
Máte nějaké dotazy?
Pokládejte své dotazy v komentářích níže a já se je budu snažit zodpovědět.
Získejte přehled o moderní přípravě dat!

Připravte si data pro strojové učení během několika minut
…s pouhými několika řádky kódu v jazyce Python
Objevte, jak na to, v mé nové elektronické knize:
Příprava dat pro strojové učení
Nabízí samostudijní návody s plně funkčním kódem na:
Výběr vlastností, RFE, čištění dat, transformace dat, škálování, redukci dimenzionality a mnoho dalšího….
Zavedení moderních technik přípravy dat do
vašich projektů strojového učení
Podívejte se, co je uvnitř
.