Virtualizace infrastruktury a provozování virtuálních prostředků pro obsluhu kritických pracovních úloh přináší mnoho velkých výhod. V případě VMware vSphere poskytuje mnoho pozoruhodných funkcí a možností, které zajišťují vysokou dostupnost prostředí a také automatizované plánování pracovních zátěží, které zajišťuje co nejefektivnější využití hardwaru a zdrojů v prostředí vSphere.
V tomto příspěvku budeme hovořit o dvou základních funkcích vSphere na úrovni clusteru v podniku – vSphere HA a DRS. S největší pravděpodobností jste se s oběma těmito funkcemi setkali v souvislosti s provozem vSphere v podniku.
Co je vSphere HA a DRS? K čemu slouží?
Jaké výhody přináší provoz obou v prostředí vSphere?
Podívejme se na základní seznámení s HA a DRS v prostředí VMware vSphere a zjistěme, jaké je jejich srovnání a výhody jejich používání.
Klastry VMware vSphere
Jednou ze zřejmých výhod a osvědčených postupů při používání prostředí VMware vSphere pro provoz kritických pracovních zátěží je provozování clusteru vSphere.
Co je to cluster vSphere?
Cluster vSphere je konfigurace více než jednoho serveru VMware ESXi sdružená jako fond prostředků přispívajících do clusteru vSphere. Zdroje, jako je výpočetní jednotka CPU, paměť a v případě softwarově definovaného úložiště, jako je vSAN, úložiště, jsou poskytovány každým hostitelem ESXi.
Proč je důležité provozovat kritické pracovní úlohy nad clusterem vSphere?
Pokud se zamyslíte nad výhodami, které poskytuje provoz hypervizoru, umožňuje provozovat více než jeden server nad jednou sadou fyzického hardwaru. Virtualizace pracovních zátěží tímto způsobem poskytuje mnoho řádových výhod v oblasti efektivity ve srovnání s provozem jednoho serveru na jedné sadě fyzického hardwaru.
To se však může stát také Achillovou patou virtualizovaného řešení, protože dopad selhání hardwaru může ovlivnit mnohem více kritických podnikových služeb a aplikací. Dovedete si představit, že pokud máte pouze jednoho hostitele VMware ESXi, na kterém běží mnoho virtuálních počítačů, dopad ztráty tohoto jediného hostitele ESXi by byl obrovský.
Tady skutečně zazáří provoz více hostitelů VMware ESXi v clusteru vSphere.
Můžete si však položit otázku, jak pouhý provoz více hostitelů v clusteru zvyšuje vaši vysokou dostupnost? Jak hostitel v clusteru vSphere „pozná“, že jiný hostitel selhal? Existuje nějaký speciální mechanismus, který se stará o správu vysoké dostupnosti pracovních zátěží provozovaných v clusteru vSphere? Ano, existuje. Podívejme se na to.
Co je HA ve VMware?
VMware si uvědomil potřebu mít mechanismus, který by dokázal zajistit ochranu proti selhání hostitele ESXi v clusteru vSphere. Díky této potřebě vznikla technologie VMware High-Availability (HA).
VMware vSphere HA přináší následující výhody:
VMware vSphere HA je nákladově efektivní a umožňuje automatizované restartování virtuálních počítačů a hostitelů vSphere při výpadku serveru nebo při zjištění selhání operačního systému v prostředí vSphere
Sleduje všechny hostitele VMware vSphere &virtuální počítače v clusteru vSphere
Zajišťuje vysokou dostupnost většiny aplikací běžících ve virtuálních počítačích bez ohledu na operační systém a aplikace.
Krása řešení VMware vSphere HA, které je implementováno prostřednictvím clusteru VMware, spočívá v jednoduchosti, s jakou jej lze nakonfigurovat. Pomocí několika kliknutí přes rozhraní řízené průvodcem lze nakonfigurovat vysokou dostupnost. Jaké je srovnání s tradičními „clusterovými“ technologiemi?“
Srovnání clusterů s podporou převzetí služeb při selhání systému Windows Server
Clustery s podporou převzetí služeb při selhání systému Windows Server (WSFC) se staly clusterovou technologií, kterou si většina vybaví, když má na mysli clusterovou technologii. Problém viděný u WSFC spočívá v tom, že pro správný provoz služeb WSFC je zapotřebí mnoho specializovaných znalostí, zejména pokud jde o upgrady, záplatování a obecné provozní úkoly.
Při porovnání vSphere HA s WSFC je provozní režie ve srovnání s WSFC minimální. Je jen malá pravděpodobnost, že by HA mohl být nakonfigurován nesprávně, protože je v clusteru buď povolen, nebo ne. V případě WSFC je třeba při konfiguraci WSFC zohlednit mnoho aspektů, aby nedošlo k chybám při konfiguraci i implementaci. Zamyslete se nad následujícími skutečnostmi:
- Clusterování s podporou převzetí služeb vyžaduje aplikace, které podporují clusterování (SQL atd.)
- Clusterování s podporou převzetí služeb vyžaduje správnou konfiguraci kvora
- Není podporováno mnoha staršími operačními systémy a aplikacemi
- Vyžaduje složitost síťových názvů clusteru, prostředků a sítí
Indows Server Failover Clustering je inzerován tak, aby poskytoval téměř nulové prostoje na úrovni aplikace. Když však připočtete odborné znalosti potřebné pro správně fungující řešení HA spolu se správnou implementací WSFC, mohou rizika začít převažovat nad výhodami použití WSFC pro vysokou dostupnost aplikací a služeb. To platí zejména v případě většiny organizací, které nemusí skutečně potřebovat řešení „nulového výpadku“. Kromě toho musí být aplikace navržena tak, aby využívala výhod technologie WSFC a správně s ní pracovala.
Přestože vSphere HA vyžaduje při výpadku restart virtuálních počítačů na zdravém hostiteli, nevyžaduje instalaci dalšího softwaru uvnitř hostovaných virtuálních počítačů, žádné složité konfigurace dalších clusterových technologií a aplikace nebo operační systémy nemusí být navrženy tak, aby pracovaly s konkrétní clusterovou technologií.
Starší operační systémy a aplikace mají obecně omezené schopnosti, pokud jde o podporované technologie pro zajištění vysoké dostupnosti. Takže doslova nemusí existovat žádné nativní možnosti, jak zajistit funkci převzetí služeb při selhání v případě selhání hardwaru.
Mechanismus vysoké dostupnosti vSphere HA funguje a je jednoduchý na implementaci, konfiguraci a správu. Navíc se jedná o technologii, která je dobře otestovaná v tisících zákaznických prostředích VMware, takže má stabilní a dlouhou historii úspěšných nasazení.
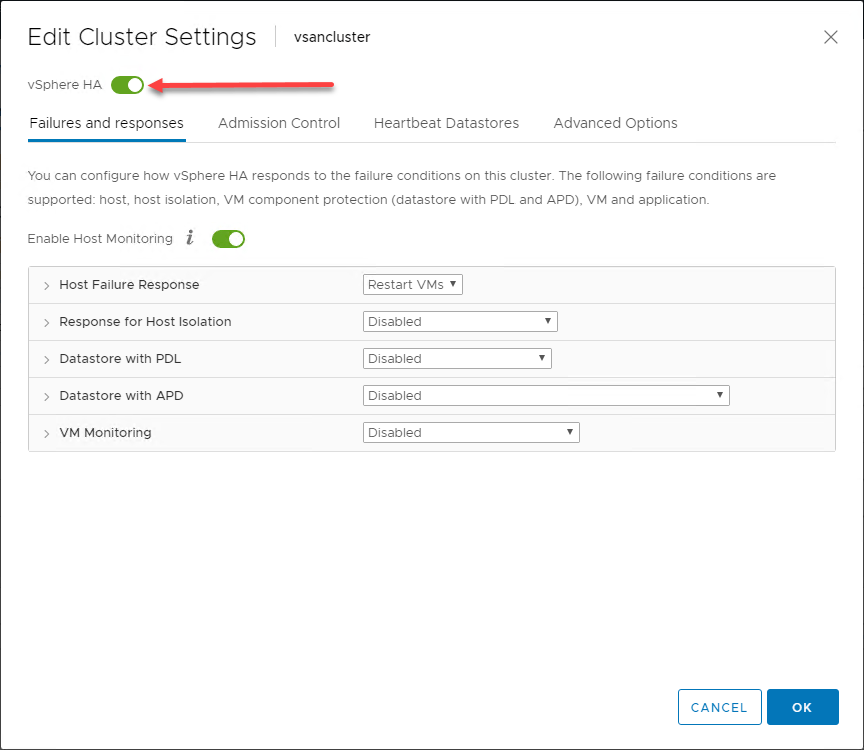
Všeobecný přehled chování vSphere HA
S využitím výhod poskytovaných hostitelům ESXi v clusteru vSphere je vSphere HA ve své nejzákladnější podobě implementován mechanismus monitorování mezi hostiteli v clusteru vSphere. Mechanismus monitorování poskytuje způsob, jak zjistit, zda některý hostitel v clusteru vSphere selhal.
Na infografice níže došlo v clusteru vSphere Cluster se dvěma uzly k selhání jednoho z hostitelů ESXi v clusteru vSphere Cluster. Cluster vSphere má na úrovni clusteru povolenou funkci vSphere HA.
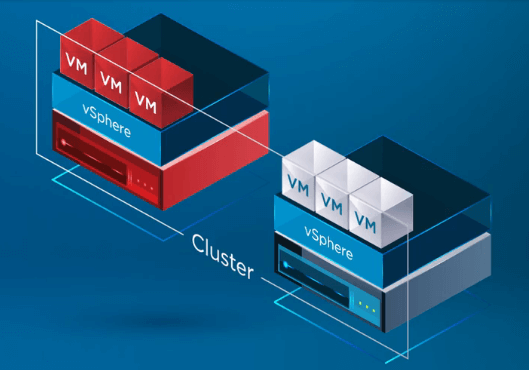
Poté, co systém vSphere HA rozpozná, že hostitel v clusteru vSphere selhal, proces HA přesune registraci virtuálních počítačů ze selhaného hostitele na zdravého hostitele.
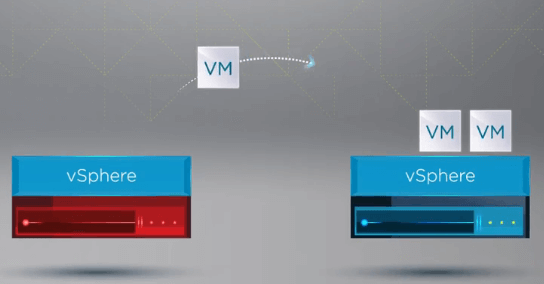
Po registraci virtuálních počítačů na zdravém hostiteli systém vSphere HA restartuje všechny virtuální počítače selhávajícího hostitele na zdravém hostiteli ESXi v clusteru, kde byly virtuální počítače přeregistrovány. Jediný výpadek vzniká při restartování virtuálních počítačů na zdravém hostiteli v clusteru vSphere.
Technický přehled vSphere HA
Předpoklady pro vSphere HA
Možná vás zajímá, jaké základní předpoklady mohou být nutné, aby vSphere HA fungovala. Potřebujete k aktivaci HA jednoduše cluster VMware? Na rozdíl od clusterů s podporou převzetí služeb při selhání v systému Windows Server musí být pro fungování HA splněno jen několik požadavků.
Požadavky:
- Nejméně dva hostitelé ESXi
- Nejméně 4 GB paměti nakonfigurované na každém hostiteli
- vCenter Server
- licence vSphere Standard
- Sdílené úložiště pro virtuální počítače
- Pingovatelná brána nebo jiný spolehlivý síťový uzel
Pokud si všimnete, není zapotřebí žádná komponenta kvora, žádné složité síťové pojmenování ani žádné další speciální prostředky clusteru, které by musely být k dispozici.
Přečtěte si více: Jak nakonfigurovat cluster vSphere s vysokou dostupností
VMware vSphere HA Master vs. podřízení hostitelé
Při zapnutí vSphere HA v clusteru je konkrétní hostitel v clusteru vSphere určen jako master vSphere HA. Ostatní hostitelé ESXi v clusteru vSphere jsou v konfiguraci vSphere HA nakonfigurováni jako podřízení.
Jakou roli hraje hostitel ESXi vSphere HA, který je určen jako master? Hlavní uzel vSphere HA:
- Sleduje stav podřízených podřízených hostitelů – Pokud podřízený hostitel selže nebo je nedostupný, hlavní hostitel určí, které virtuální počítače je třeba restartovat
- Sleduje stav napájení všech chráněných virtuálních počítačů. Pokud dojde k selhání virtuálního počítače, hlavní uzel vSphere HA zajistí jeho restartování. Hlavní uzel vSphere HA rozhoduje o tom, kde se restart VM uskuteční (který hostitel ESXi).
- Sleduje všechny hostitele clusteru a VM, které jsou chráněny pomocí vSphere HA
- Je určen jako prostředník mezi clusterem vSphere a serverem vCenter Server. HA master hlásí stav clusteru do vCenter a poskytuje rozhraní pro správu clusteru pro vCenter Server
- Může sám spouštět virtuální počítače a sledovat stav virtuálních počítačů
- Ukládá chráněné virtuální počítače do datových úložišť clusteru
podřízených hostitelů vSphere HA:
- Spouští virtuální počítače lokálně
- Sleduje stavy běhu virtuálních počítačů v clusteru vSphere
- Hlásí aktualizace stavu hlavnímu hostiteli vSphere HA
Volba a selhání hlavního hostitele
Jak se vybírá hlavní hostitel vSphere HA? Když je pro cluster povolena funkce vSphere HA, účastní se volby hlavního hostitele všichni aktivní hostitelé (bez režimu údržby atd.). Pokud zvolený hlavní hostitel selže, proběhne nová volba, při níž je zvolen nový hlavní hostitel HA, který bude tuto roli plnit.
Typy selhání clusteru VMware vSphere HA
V clusteru s povolenou funkcí vSphere HA mohou nastat tři typy selhání, které mohou vyvolat událost převzetí služeb vSphere HA při selhání. Tyto typy selhání hostitelů jsou:
- Selhání – Selhání je intuitivně to, co si myslíte. Hostitel přestal nějakým způsobem fungovat kvůli hardwarovým nebo jiným problémům.
- Izolace – K izolaci hostitele obvykle dochází v důsledku síťové události, která izoluje konkrétního hostitele od ostatních hostitelů v clusteru vSphere HA.
- Rozdělení – Událost rozdělení je charakterizována tím, že podřízený hostitel ztratí síťové připojení k hlavnímu hostiteli clusteru vSphere HA.
Heartbeating, detekce selhání a akce při selhání
Jak hlavní uzel určí, zda došlo k selhání konkrétního hostitele?
Existuje několik různých mechanismů, které hlavní uzel používá k určení, zda došlo k selhání hostitele:
- Hlavní uzel si s ostatními hostiteli v clusteru každou sekundu vyměňuje síťový srdeční tep.
- Po selhání síťového srdečního tepu hlavní uzel zkontroluje kontrolu živosti hostitele.
- Kontrola živosti hostitele určuje, zda si podřízený hostitel vyměňuje srdeční tep s některým z datových úložišť. Poté odešle ICMP pingy na jeho IP adresy správy
- Pokud není možná přímá komunikace s agentem HA podřízeného hostitele z hlavního hostitele a ICMP pingy na adresu správy selžou, je hostitel považován za neúspěšného a virtuální počítače jsou restartovány na jiném hostiteli.
- Pokud je zjištěno, že si podřízený hostitel vyměňuje srdeční tepy s datovým úložištěm, hlavní hostitel předpokládá, že je hostitel v síťovém oddílu nebo je síťově izolován. V takovém případě nadřazený hostitel jednoduše monitoruje hostitele a virtuální počítače
- Síťová izolace je případ, kdy podřízený hostitel běží, ale z pohledu agenta správy HA již není v síti správy vidět. Pokud hostitel přestane tento provoz vidět, pokusí se o ping na adresy izolace clusteru. Pokud tento ping selže, hostitel prohlásí, že je izolován od sítě
- V tomto případě hlavní uzel monitoruje virtuální počítače, které jsou spuštěny na izolovaném hostiteli. Pokud se virtuální počítače na izolovaném hostiteli vypnou, hlavní uzel restartuje virtuální počítače na jiném hostiteli
Datastore Heartbeating
Jak bylo uvedeno výše, jednou z metrik používaných k určení detekce selhání je datastore heartbeating. Co to přesně je? VMware vCenter vybírá preferovanou sadu datových úložišť pro heartbeating. Poté vSphere HA vytvoří v kořenovém adresáři každého datového úložiště adresář, který se používá jak pro heartbeating datového úložiště, tak pro udržování seznamu chráněných virtuálních počítačů. Tento adresář se jmenuje .vSphere-HA.
V souvislosti s datovými sklady vSAN je třeba mít na paměti důležitou poznámku. Datové úložiště vSAN nelze použít pro heartbeating datového úložiště. Pokud máte k dispozici pouze datové úložiště vSAN, nelze použít žádné datové úložiště pro heartbeat.
- Monitorování virtuálních počítačů a aplikací
Další mimořádně výkonnou funkcí vSphere HA je možnost monitorovat jednotlivé virtuální počítače prostřednictvím nástrojů VMware Tools a restartovat všechny virtuální počítače, které nereagují na srdeční buzení nástrojů VMware Tools. Funkce Application Monitoring dokáže restartovat virtuální počítač, pokud nejsou přijímány srdeční signály pro spuštěnou aplikaci.
- Sledování virtuálních počítačů – Při sledování virtuálních počítačů služba Sledování virtuálních počítačů pomocí nástrojů VMware Tools zjišťuje, zda jsou jednotlivé virtuální počítače spuštěny, a to kontrolou srdečních tepů i diskových I/O generovaných nástroji VMware Tools. V případě, že tyto kontroly selžou, služba VM Monitoring určí, že s největší pravděpodobností selhal hostovaný operační systém, a virtuální počítač je restartován. Dodatečná kontrola diskových I/O pomáhá zabránit zbytečnému resetování virtuálního počítače, pokud virtuální počítače nebo aplikace stále fungují správně.
Monitorování aplikací – Funkce monitorování aplikací je povolena získáním příslušné sady SDK od dodavatele softwaru třetí strany, která umožňuje nastavení vlastních srdečních tepů pro aplikace, které mají být monitorovány procesem vSphere HA. Stejně jako u procesu monitorování virtuálních počítačů platí, že pokud přestanou být přijímány srdeční signály aplikací, virtuální počítač se resetuje.
Obě tyto monitorovací funkce lze dále konfigurovat pomocí citlivosti monitorování a také maximálního počtu resetů pro jednotlivé virtuální počítače, aby se zabránilo opakovanému resetování virtuálních počítačů kvůli softwarovým nebo falešně pozitivním chybám.
VMware vSphere HA je skvělý způsob, jak zajistit, aby váš vSphere Cluster poskytoval velmi odolnou vysokou dostupnost pro ochranu proti obecným selháním hostitelů ESXi ve vašem vSphere Clusteru.
Co zajištění efektivního využití zdrojů ve vašem vSphere Clusteru? Podívejme se na další ustanovení clusteru vSphere, které pomůže zajistit efektivní využití zdrojů a kapacity clusteru vSphere.
Co je DRS ve VMware?
Systém DRS (Distributed Resource Scheduler) společnosti VMware je opravdu výkonná funkce při provozování clusterů vSphere. Zajišťuje plánování a vyrovnávání zátěže v rámci clusteru vSphere. VMware DRS je funkce, která se nachází v prostředí vSphere Clusters a která zajišťuje, že virtuální počítače běžící uvnitř prostředí vSphere mají k dispozici prostředky, které potřebují k efektivnímu a účinnému běhu.
VM obecně podléhají službě DRS již na počátku svého života, protože od prvního zapnutí v clusteru s podporou DRS umisťuje služba DRS virtuální počítače na nejlepšího hostitele nakonfigurovaného tak, aby virtuálnímu počítači poskytoval požadované prostředky ihned po zapnutí. Kromě toho se DRS snaží udržovat clustery vSphere vyvážené z hlediska využití prostředků.
I když je cluster vSphere v určitém okamžiku vyvážený, mohou se virtuální počítače přesouvat nebo měnit takovým způsobem, že se do prostředí může opět vplížit nerovnováha prostředků clusteru. Pokud se clustery stanou nevyváženými, může to mít negativní vliv na celkový výkon virtuálních počítačů běžících v clusteru vSphere.
Ve výchozím nastavení se DRS spouští automaticky na clusteru vSphere každých pět minut, aby určil vyváženost clusteru vSphere a zjistil, zda je třeba provést nějaké změny pro efektivnější využití zdrojů.
Požadavky na službu VMware DRS
Chcete-li využívat výhod služby VMware DRS, je třeba splnit několik požadavků, které zajistí využití funkcí distribuovaného plánování prostředků. Mezi ně patří:
- Cluster hostitelů ESXi
- vCenter Server
- Licence Enterprise Plus
- Pro automatické vyrovnávání zátěže je vyžadována licence vMotion
Přečtěte si více: Jak nakonfigurovat cluster vSphere DRS
Akce VMware DRS
Když VMware DRS běží na clusteru vSphere každých pět minut, zjišťuje, zda v clusteru existuje nerovnováha. Pokud ano, provede se vMotion, který přesune určené virtuální počítače z jednoho hostitele ESXi na druhého.
Jak přesně DRS určuje, zda jsou virtuální počítače vhodnější na jednom nebo druhém hostiteli ESXi?
DRS spouští speciální algoritmus pro určení správného hostitele ESXi, na kterém by měl být umístěn konkrétní virtuální počítač. Při zapnutí virtuálního počítače tento algoritmus bere v úvahu rozložení prostředků v clusteru vSphere poté, co zajistí, že nedojde k porušení omezení, pokud je konkrétní virtuální počítač umístěn na konkrétním hostiteli ESXi.
Dále se berou v úvahu požadavky samotného virtuálního počítače, takže virtuální počítač snad nikdy nebude mít při zapnutí nedostatek prostředků. Co je zahrnuto v poptávce virtuálního počítače? Požadavek virtuálního počítače zahrnuje množství prostředků potřebných ke spuštění.
- Pro poptávku po procesoru se počítá na základě množství procesoru, které virtuální počítač aktuálně spotřebovává
- Pro poptávku po paměti se počítá podle vzorce: VM memory demand = Function(Active memory used, Swapped, Shared) + 25% (idle consumed memory). To ukazuje, že vyvážení paměti DRS je založeno především na aktivním využití paměti virtuálního počítače, přičemž se bere v úvahu malé množství jeho nečinné spotřebované paměti jako polštář pro případné zvýšení pracovní zátěže.
Úrovně automatizace DRS
Jednou ze zajímavých funkcí DRS jsou úrovně automatizace DRS. Zatímco DRS nadále skenuje cluster vSphere a každých 5 minut poskytuje doporučení, můžete určit, zda DRS dokáže svá doporučení realizovat automaticky, nebo zda pouze navrhne změny, které by měly být provedeny. DRS má tři úrovně automatizace DRS. Patří mezi ně:
- Plně automatizovaný – Při plně automatizovaném přístupu uplatňuje DRS automaticky doporučení pro počáteční umístění i vyrovnávání zátěže
- Částečně automatizovaný – Při částečné automatizaci uplatňuje DRS doporučení pouze pro počáteční umístění virtuálních počítačů
- Ruční – V ručním režimu, musíte použít doporučení pro počáteční umístění i doporučení pro rozložení zátěže
Prahové hodnoty migrace DRS
DRS obsahuje další velmi užitečné nastavení pro kontrolu velikosti nevyváženosti, která bude tolerována před provedením doporučení DRS. K dispozici je pět migračních prahů DRS, které řídí množství tolerované nevyváženosti.
Rozsah je 1 (nejkonzervativnější) až 5 (nejagresivnější).
Při agresivnějším nastavení DRS toleruje menší nevyváženost v clusteru. Čím konzervativnější, tím více DRS toleruje nevyváženost.

Pravidla VMware DRS pro virtuální počítače/hostitele
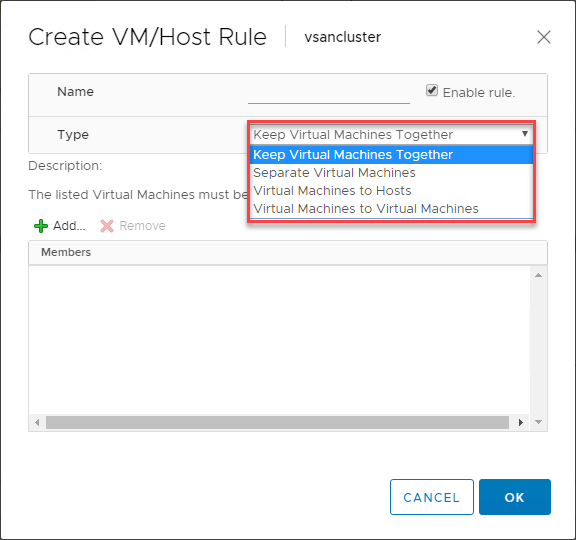
Při používání služby VMware DRS pro řízení umístění virtuálních počítačů v clusterech s podporou služby vSphere DRS lze nalézt velmi užitečnou funkci. Pravidla VM/Host Rules umožňují spouštět konkrétní virtuální počítače na konkrétním hostiteli ESXi. Svým způsobem si to můžete představit jako pravidla afinity.
Pravidla VM/Host umožňují:
- Udržet virtuální počítače pohromadě
- Oddělit virtuální počítače
- Vázat virtuální počítače na konkrétní hostitele
- Vázat virtuální počítače na virtuální počítače
Níže je uveden příklad vytvoření pravidla VM/Host pro virtuální počítače a hostitele ESXi.
Jaký typ použití existuje pro tato pravidla VM/Host? Jedním z klasických případů použití, které existují, jsou řadiče domény. Obecně řečeno, pokud provozujete všechny řadiče domény ve virtualizovaném prostředí, například v clusteru vSphere, chcete zajistit, aby byly virtuální počítače řadičů domény uvnitř clusteru od sebe odděleny. Tímto způsobem, pokud dojde k výpadku hostitele ESXi spolu s jedním z řadičů domény, máte stále řadič domény, který podléhá pravidlu oddělených virtuálních strojů, které jej drží mimo stejného hostitele jako jiný DC.
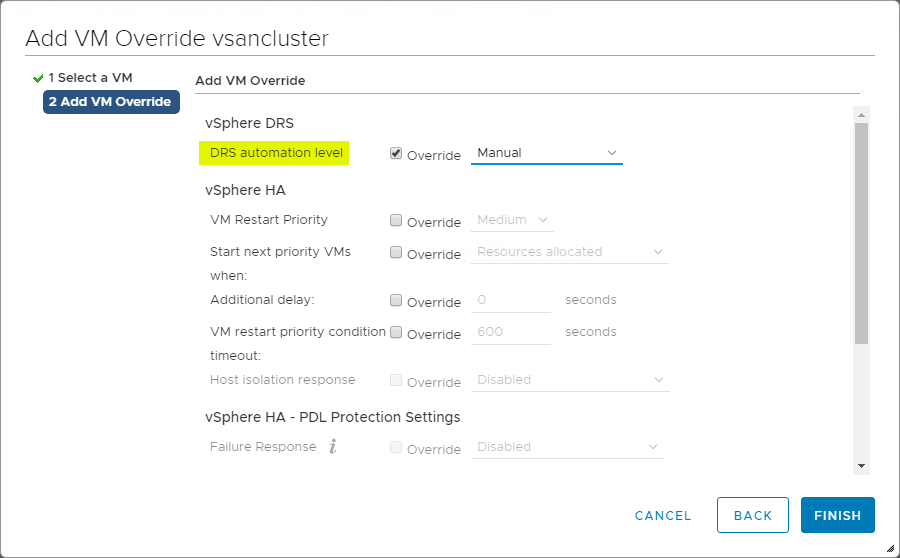
VM Overrides for DRS
Cluster vSphere poskytuje velkou granularitu operací ovlivňujících jednotlivé virtuální stroje uvnitř clusteru vSphere. Můžete vytvořit VM Overrides, které přepíší globální nastavení nastavená na úrovni clusteru pro HA a DRS a definují konkrétnější nastavení pro jednotlivé virtuální počítače.
CPU and Memory Utilization Summary
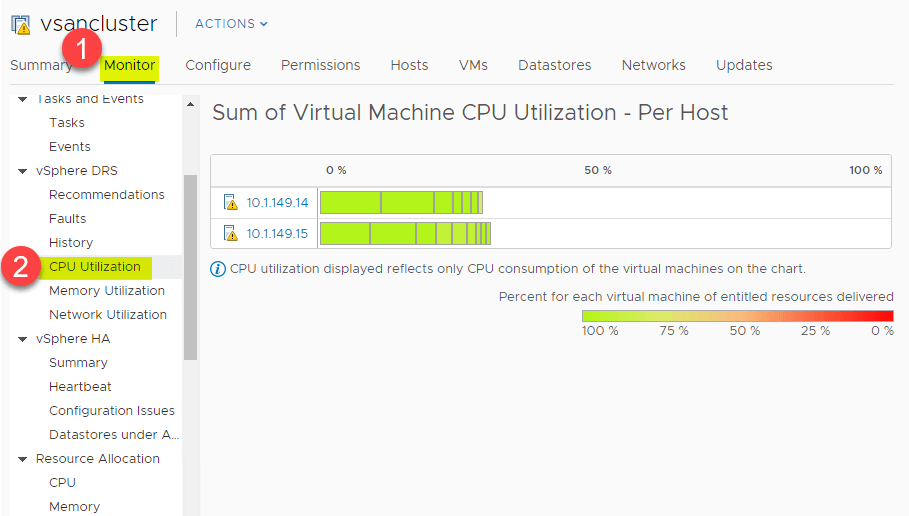
DRS poskytuje skvělý přehled na vysoké úrovni o využití prostředků CPU hostitelů ESXi v clusteru vSphere. Přejděte na > Nastavení > Sledovat > vSphere DRS > Využití CPU.
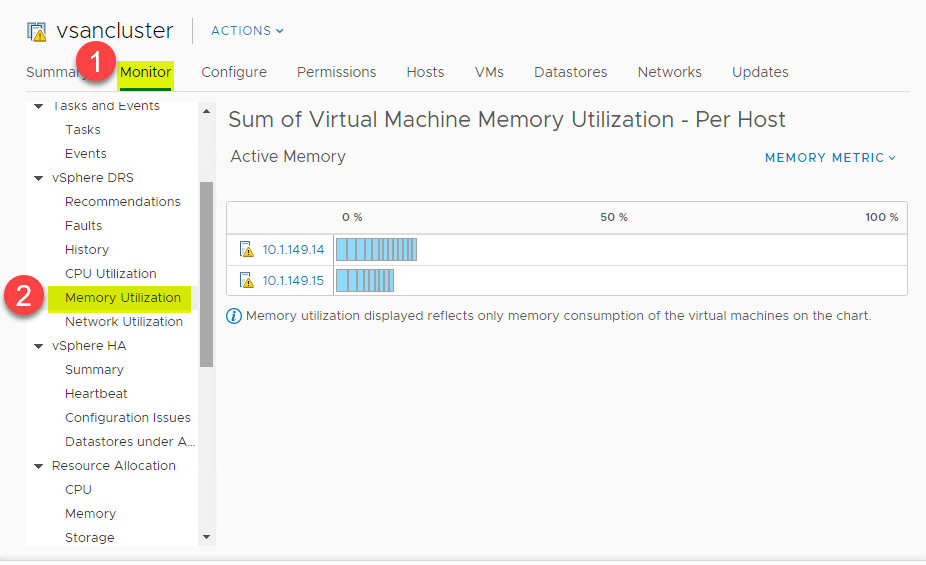
Stejný přehled na vysoké úrovni lze zobrazit také pro spotřebu paměti. Přejděte na > Nastavení > Monitor > vSphere DRS > Využití paměti
To nejlepší z obou světů
Jsou VMware vSphere HA a VMware DRS konkurenční technologie?
Ne, nejsou. Ve skutečnosti se důrazně doporučuje používat vSphere HA i VMware DRS společně, aby bylo možné kombinovat automatické převzetí služeb při selhání s funkcemi a vlastnostmi vyrovnávání zátěže. Výsledkem je mnohem odolnější a vyváženější prostředí vSphere.
Pokud dojde k selhání hostitele ESXi, vSphere HA restartuje virtuální počítače na zbývajících zdravých hostitelích v clusteru vSphere. První prioritou je tedy samozřejmě dostupnost prostředků virtuálních počítačů. Poté se spustí služba VMware DRS a zjistí, zda existuje nerovnováha mezi hostiteli ESXi, na kterých běží pracovní zátěže, a na základě nakonfigurovaného migračního prahu vydá doporučení k vyřešení případné nerovnováhy v clusteru. Na základě úrovně automatizace budou tato doporučení buď automaticky provedena, nebo pouze doporučena, pokud nejsou plně automatizovaná.
Závěrečné úvahy o VMware vSphere HA a DRS
V produkčním clusteru vSphere se důrazně doporučuje používat jak VMware vSphere HA, tak DRS. Použití obou technologií pomáhá zajistit vysokou dostupnost pracovních zátěží a zajišťuje, že mají neustále k dispozici potřebné zdroje na základě požadavků na CPU/paměť virtuálního počítače.
Pochopení fungování obou mechanismů vám jako správci vSphere pomůže využít obě technologie co nejlépe a v souladu s osvědčenými postupy. Mezi výhody, které obě technologie přinášejí, patří mimořádně snadné zapnutí a konfigurace každé z funkcí. Několika jednoduchými kliknutími ve vlastnostech clusterů vSphere můžete rychle začít využívat tyto dostupné funkce na úrovni clusteru.
Sledujte naše kanály na Twitteru a Facebooku, kde najdete nové verze, aktualizace, zasvěcené příspěvky a další informace.