Reinforcement Learning (RL) je jedním z nejžhavějších výzkumných témat v oblasti moderní umělé inteligence a jeho popularita jen roste. Podívejme se na 5 užitečných věcí, které člověk potřebuje vědět, aby mohl s RL začít.
Reinforcement Learning(RL) je typ techniky strojového učení, která umožňuje agentovi učit se v interaktivním prostředí metodou pokusů a omylů pomocí zpětné vazby z jeho vlastních akcí a zkušeností.
Ačkoli jak učení s dohledem, tak učení s posilováním používají mapování mezi vstupem a výstupem, na rozdíl od učení s dohledem, kde je zpětnou vazbou poskytovanou agentovi správný soubor akcí pro provedení úkolu, učení s posilováním používá odměny a tresty jako signály pro pozitivní a negativní chování.
V porovnání s učením bez dohledu se učení s posilováním liší z hlediska cílů. Zatímco cílem při nekontrolovaném učení je najít podobnosti a rozdíly mezi datovými body, v případě posilovacího učení je cílem najít vhodný model akce, který by maximalizoval celkovou kumulativní odměnu agenta. Následující obrázek znázorňuje zpětnovazební smyčku akce a odměny obecného modelu RL.

Jak formulovat základní problém učení s posilováním?
Několik klíčových pojmů, které popisují základní prvky problému RL, je následujících:
- Prostředí – Fyzický svět, ve kterém agent působí
- Stav – Aktuální situace agenta
- Odměna – Zpětná vazba z prostředí
- Politika – Metoda mapování stavu agenta na akce
- Hodnota – Budoucí odměna, kterou by agent získal provedením akce v určitém stavu
Problém RL lze nejlépe vysvětlit pomocí her. Vezměme si hru PacMan, kde je cílem agenta(PacMan) sníst jídlo v mřížce a přitom se vyhnout duchům na své cestě. V tomto případě je svět mřížky interaktivním prostředím pro agenta, ve kterém jedná. Agent dostává odměnu za konzumaci jídla a trest, pokud ho zabije duch (prohraje hru). Stavy jsou umístění agenta ve světě mřížky a celková kumulativní odměna je vítězství agenta ve hře.

Pro sestavení optimální politiky čelí agent dilematu, zda má zkoumat nové stavy a zároveň maximalizovat svou celkovou odměnu. Tomu se říká kompromis mezi průzkumem a využíváním. Pro vyvážení obojího může nejlepší celková strategie zahrnovat krátkodobé oběti. Proto by měl agent shromáždit dostatek informací, aby mohl v budoucnu učinit nejlepší celkové rozhodnutí.
Markovovy rozhodovací procesy (MDP) jsou matematické rámce pro popis prostředí v RL a téměř všechny problémy RL lze formulovat pomocí MDP. MDP se skládá z množiny konečných stavů prostředí S, množiny možných akcí A(s) v každém stavu, reálně oceněné funkce odměny R(s) a přechodového modelu P(s‘, s | a). V reálném prostředí však s větší pravděpodobností chybí jakákoli předchozí znalost dynamiky prostředí. V takových případech se hodí bezmodelové metody RL.
Q-learning je běžně používaný bezmodelový přístup, který lze použít pro sestavení samostatně hrajícího agenta PacMan. Točí se kolem pojmu aktualizace hodnot Q, které označují hodnotu provedení akce a ve stavu s. Následující pravidlo aktualizace hodnot je jádrem algoritmu Q-learning.

Tady je videoukázka agenta PacMan, který používá Deep Reinforcement Learning.
Jaké jsou nejpoužívanější algoritmy Reinforcement Learningu
Q-learning a SARSA (State-Action-Reward-State-Action) jsou dva běžně používané algoritmy RL bez modelu. Liší se svými strategiemi průzkumu, zatímco jejich strategie využití jsou podobné. Zatímco Q-learning je metoda off-policy, při níž se agent učí hodnotu na základě akce a* odvozené z jiné politiky, SARSA je metoda on-policy, při níž se učí hodnotu na základě své aktuální akce a odvozené z jeho aktuální politiky. Tyto dvě metody jsou jednoduché na implementaci, ale postrádají obecnost, protože nemají možnost odhadovat hodnoty pro neviděné stavy.
To lze překonat pokročilejšími algoritmy, jako jsou Deep Q-Networks(DQN), které k odhadu hodnot Q používají neuronové sítě. DQNs si však poradí pouze s diskrétními, nízkorozměrovými akčními prostory.
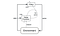
Hluboký deterministický gradient politik(DDPG) je bezmodelový, mimopolitický, aktérsko-kritický algoritmus, který tento problém řeší učením politik ve vysokorozměrových, spojitých akčních prostorech. Na obrázku níže je znázorněna architektura actor-critic.
Jaké jsou praktické aplikace Reinforcement Learning?
Protože RL vyžaduje velké množství dat, je nejvíce použitelné v oblastech, kde jsou snadno dostupná simulovaná data, jako je hraní her, robotika.
- RL se poměrně široce používá při vytváření umělé inteligence pro hraní počítačových her. AlphaGo Zero je první počítačový program, který porazil mistra světa ve starobylé čínské hře Go. Mezi další patří hry ATARI, Backgammon ,atd
- V robotice a průmyslové automatizaci se RL používá k tomu, aby robot mohl sám pro sebe vytvořit účinný adaptivní řídicí systém, který se učí z vlastních zkušeností a chování. Dobrým příkladem je práce společnosti DeepMind na projektu Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates. Podívejte se na toto zajímavé demonstrační video.
Další aplikace RL zahrnují abstraktní stroje pro sumarizaci textu, dialogové agenty (text, řeč), kteří se mohou učit z interakcí s uživatelem a s časem se zlepšovat, učení optimálních léčebných politik ve zdravotnictví a agenty založené na RL pro online obchodování s akciemi.
Jak mohu začít s Reinforcement Learningem?
Pro pochopení základních pojmů RL lze využít následující zdroje:
- Reinforcement Learning-An Introduction, kniha otce Reinforcement Learningu – Richarda Suttona a jeho doktoranda Andrewa Barta. Online návrh knihy je k dispozici zde.
- Výukový materiál od Davida Silvera včetně videopřednášek je skvělým úvodním kurzem o RL.
- Zde je další technický výukový materiál o RL od Pietera Abbeela a Johna Schulmana (Open AI/ Berkeley AI Research Lab).
Pro začátek tvorby a testování agentů RL mohou být užitečné následující zdroje.
- Tento blog o tom, jak trénovat agenta neuronové sítě ATARI Pong s Policy Gradients ze surových pixelů od Andreje Karpathyho, vám pomůže zprovoznit vašeho prvního agenta Deep Reinforcement Learning na pouhých 130 řádcích kódu Pythonu.
- DeepMind Lab je open source platforma podobná 3D hrám vytvořená pro agentový výzkum umělé inteligence s bohatým simulovaným prostředím.
- Project Malmo je další experimentální platforma pro podporu základního výzkumu umělé inteligence.
- OpenAI gym je sada nástrojů pro vytváření a porovnávání algoritmů reinforcement learning.
.