Podle: Derek Colley | Aktualizováno: 2014-01-29 | Komentáře (5) | Související: Více > Funkce – Systém
Problém
Chcete získat náhodný vzorek ze sady výsledků dotazu SQL Serveru. Možná hledáte reprezentativní vzorek dat z velké databáze zákazníků; možná hledáte nějaké průměry nebo představu o typu dat, která máte k dispozici. SELECT TOP N není vždy ideální, protože na začátku a na konci datových sad se často objevují odlehlé hodnoty, zejména pokud jsou seřazeny abecedně nebo podle nějaké skalární hodnoty. Podobně jste možná použili TABLESAMPLE, ale ten má svá omezení zejména u malých nebo zkreslených souborů dat. Možná vás šéf požádal o náhodný výběr 100 jmen a míst zákazníků; nebo se účastníte auditu a potřebujete získat náhodný vzorek dat pro analýzu. Jak byste tento úkol splnili? Podívejte se na tento tip a dozvíte se více.
Řešení
Tento tip vám ukáže, jak použít TABLESAMPLE v jazyce T-SQL k získání pseudonáhodných vzorků dat, a probereme si vnitřní informace o TABLESAMPLE a o tom, kde není vhodný. Ukáže vám také alternativní metodu – matematickou metodu využívající NEWID() ve spojení s CHECKSUM a bitovým operátorem, na kterou upozorňuje společnost Microsoft v článku TABLESAMPLE na TechNetu. Povíme si něco málo o statistickém vzorkování obecně (rozdíly mezi náhodným, systematickým a stratifikovaným) s příklady a jako příklad se podíváme na způsob vzorkování statistik SQL a na možnosti, kterými můžeme toto vzorkování přepsat. Po přečtení tohoto tipu byste měli mít přehled o výhodách vzorkování oproti použití metod jako TOP N a měli byste vědět, jak použít alespoň jednu metodu k jeho dosažení v SQL Serveru.
Nastavení
Pro tento tip budu používat datovou sadu obsahující identifikační sloupec INT (pro stanovení míry náhodnosti při výběru řádků) a další sloupce vyplněné pseudonáhodnými daty různých datových typů, abych (vágně) simuloval skutečná data v tabulce. K nastavení můžete použít níže uvedený kód T-SQL. Jeho spuštění by mělo trvat jen několik minut a je testováno na serveru SQL Server 2012 Developer Edition.
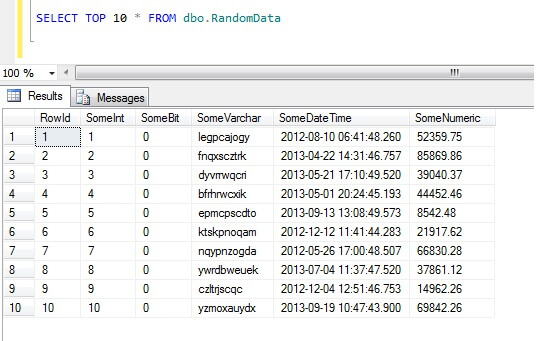
Výběr prvních 10 řádků dat dává tento výsledek (jen pro představu o tvaru dat).Na okraj dodejme, že toto je obecný kus kódu, který jsem vytvořil pro generování náhodně vybraných dat, kdykoli jsem je potřeboval – klidně si ho vezměte a rozšiřte/vyplenujte dle libosti!“
Jak nevytvářet vzorky dat v SQL Serveru
Teď máme vzorky dat, pojďme se zamyslet nad nejhoršími způsoby získání vzorku. V databázi AdventureWorks existuje tabulka s názvem Person.Address. Vezměme si vzorek tak, že vezmeme 10 nejlepších výsledků, bez konkrétního pořadí:
SELECT TOP 10 * FROM Person.Address
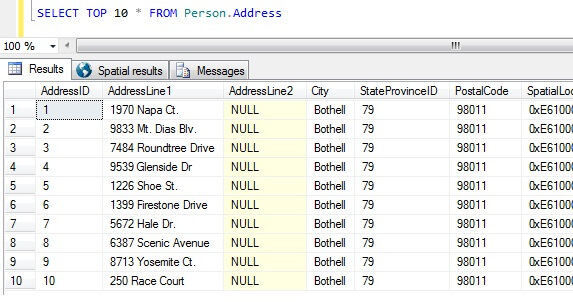
Jen z tohoto vzorku vidíme, že všechny vrácené osoby žijí v Bothellu a mají společné poštovní směrovací číslo 98011. Je to proto, že bylo zadáno, že výsledky mají být vráceny bez určitého pořadí, ale ve skutečnosti byly vráceny v pořadí podle sloupce AddressID. Všimněte si, že toto NENÍ zaručené chování zejména pro data na hromadě – viz tato citace z BOL:
„Obvykle jsou data zpočátku uložena v pořadí, v jakém jsou řádky vloženy do tabulky, ale Database Engine může data na hromadě přesouvat, aby řádky uložil efektivně; pořadí dat tedy nelze předvídat. Chcete-li zaručit pořadí řádků vrácených z haldy, musíte použít klauzuli ORDER BY.“
http://technet.microsoft.com/en-us/library/hh213609.aspx
Podle této sady výsledků by člověk neinformovaný o povaze tabulky mohl dojít k závěru, že všichni jeho zákazníci žijí v Bothellu.
Typy vzorkování dat v SQL Serveru
Výše uvedené je zjevně nepravdivé, proto potřebujeme lepší způsob vzorkování. Co takhle odebírat vzorek v pravidelných intervalech v celé tabulce?“
Toto by mělo vrátit 47 řádků:
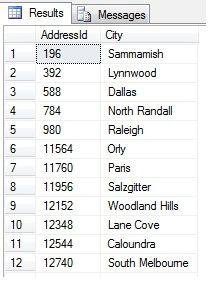
Tak zatím to jde. Vzali jsme řádek v pravidelných intervalech v celém našem souboru dat a vrátili statistický průřez – nebo ne? Ne nutně. Nezapomeňte, že pořadí není zaručeno. O těchto datech bychom mohli učinit jeden nebo dva závěry. Pro ilustraci je shrňme. Znovu spusťte výše uvedený úryvek kódu, ale závěrečný blok SELECT změňte takto:
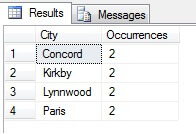
V mém příkladu vidíte, že z celkového počtu více než 19 000 řádků v tabulce Person.Address jsem vybral asi 1/4 % řádků, a proto mohu vyvodit závěr, že (v mém příkladu) nejvíce obyvatel mají Concord, Kirkby, Lynnwood a Paris a navíc jsou stejně zalidněné. Je to přesné? Samozřejmě nesmysl:
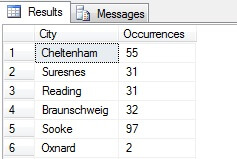
Jak vidíte, žádné z mých čtyř míst nebylo ve skutečnosti mezi čtyřmi nejlepšími místy pro život, jak je posuzuje tato tabulka. Nejenže byl vzorek dat příliš malý, ale já jsem tento malý vzorek agregoval a snažil se z něj vyvodit závěr. To znamená, že můj soubor výsledků je statisticky nevýznamný – pozor, prokázání statistické významnosti je jedním z hlavních důkazních břemen při prezentaci statistických souhrnů (nebo by mělo být) a hlavním nedostatkem mnoha populárních infografik a marketingově vedených datagramů.
Takže výběr vzorků tímto způsobem (tzv. systematický výběr) je účinný, ale pouze pro statisticky významnou populaci. Existují faktory, jako je periodicita a proporce, které mohou vzorek zničit – podívejme se na proporce v akci při výběru vzorku 10 měst z tabulky Person.Address pomocí následujícího kódu, který získá odlišný seznam měst z tabulky Person.Address a poté z tohoto seznamu vybere 10 měst pomocí systematického vzorkování:
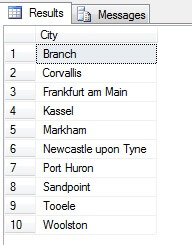
Vypadá to jako dobrý vzorek, že? Nyní jej porovnejme se vzorkem NEROZLIŠNÝCH měst seřazených vzestupně, tj. každé n-té město, kde n je celkový počet řádků dělený 10. Toto opatření zohledňuje výběrový soubor:
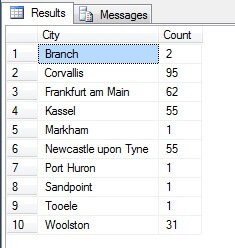
Vrácená data jsou zcela odlišná – nikoliv náhodou, ale prezentací reprezentativního vzorku. Všimněte si, že tento seznam, na kterém jsem uvedl počty jednotlivých měst ve zdrojové tabulce, abych nastínil, jak velkou roli při výběru dat hraje počet obyvatel, zahrnuje čtyři nejlidnatější města ve vzorku, což je (pokud uvažujete uspořádaný nedistinktivní seznam) nejspravedlivější reprezentace. Nemusí to být nutně nejlepší reprezentace pro vaše potřeby, proto buďte při výběru statistické metody výběru opatrní.
Jiné metody výběru vzorků
Výběr vzorků shlukem – při něm se populace, která má být vybrána, rozdělí na shluky neboli podmnožiny a pak se náhodně určí, zda každá z těchto podmnožin bude či nebude zahrnuta do výstupního souboru výsledků. Pokud je zahrnut, je každý člen této podmnožiny vrácen do výsledné množiny. Příklad tohoto postupu je uveden níže v tabulce TABLESAMPLE.
Disproporcionální výběr – jedná se o obdobu stratifikovaného výběru, kdy jsou vybíráni členové podskupin tak, aby reprezentovali celou skupinu, ale namísto proporcionálního výběru může být vybrán různý počet členů z každé skupiny, aby bylo zastoupení z každé skupiny vyrovnané. Tj. vzhledem k městům v Person.Address v příkladu z předchozí části byl první soubor výsledků neproporcionální, protože nebral v úvahu počet obyvatel, ale druhý soubor výsledků byl proporcionální, protože reprezentoval počet záznamů měst v tabulce Person.Address. Tento typ vzorkování je ve skutečnosti užitečný, pokud je určitá kategorie v souboru dat nedostatečně zastoupena a podíl není důležitý (například 100 náhodných zákazníků ze 100 náhodných měst stratifikovaných podle měst – města v podsouboru by potřebovala normalizaci – lze použít neproporcionální vzorkování).
SQL Server Random Data with TABLESAMPLE
SQL Server užitečně přichází s metodou vzorkování dat. Podívejme se na ni v akci. Použijte následující kód, který vrátí přibližně 100 řádků (pokud vrátí 0 řádků, spusťte jej znovu – vysvětlím za chvíli) dat z dbo.RandomData, která jsme definovali dříve.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
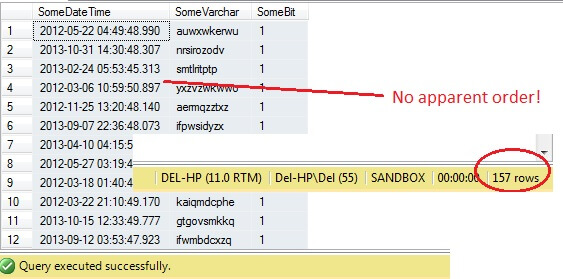
Tak zatím to jde, že? Počkejte – nevidíme sloupec Id. Zahrneme to a spustíme znovu:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
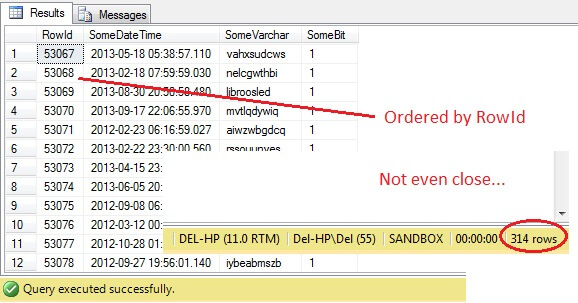
A jéje – TABLESAMPLE vybrala výsek dat, ale není náhodný – RowId ukazuje jasně ohraničený výsek s minimální a maximální hodnotou. Navíc ani nevrátil přesně 100 řádků. Co se děje?
TABLESAMPLE používá implicitní modifikátor SYSTEM. Tento modifikátor, který je ve výchozím nastavení zapnutý a je specifikací ANSI-SQL, tj. není volitelný, vezme každou 8KB stránku, na které se tabulka nachází, a rozhodne, zda do vytvořeného vzorku zahrne všechny řádky na této stránce, které jsou v dané tabulce, na základě předaného procenta nebo N ŘÁDKŮ. Proto by tabulka, která se nachází na mnoha stránkách, tj. má velké datové řádky, měla vrátit více náhodný vzorek, protože ve vzorku bude více stránek. U příkladu, jako je náš, kde jsou data skalární a malá a nacházejí se jen na několika málo stránkách, to selhává – pokud se některá ze stránek nedostane do výběru, může to výrazně zkreslit výstupní vzorek. To je nevýhoda TABLESAMPLE – nefunguje dobře pro „malá“ data a nebere v úvahu rozložení dat na stránkách. Za vzorek vrácený touto metodou je tedy v konečném důsledku zodpovědné uspořádání dat na stránkách.
Zní vám to povědomě? V podstatě se jedná o shlukový výběr, kdy jsou ve výsledném souboru zastoupeni všichni členové (řádky) vybraných skupin (shluků).
Vyzkoušejme to na velké tabulce, abychom zdůraznili bod inverzní neškálovatelnosti. Nejprve identifikujme největší tabulku v databázi AdventureWorks. Použijeme k tomu standardní sestavu – pomocí SSMS klikněte pravým tlačítkem myši na databázi AdventureWorks2012, přejděte na položku Reports -> Standard Reports -> Disk Usage by Top Tables. Seřaďte podle Data(KB) kliknutím na záhlaví sloupce (možná to budete chtít udělat dvakrát pro sestupné řazení). Zobrazí se vám následující sestava:
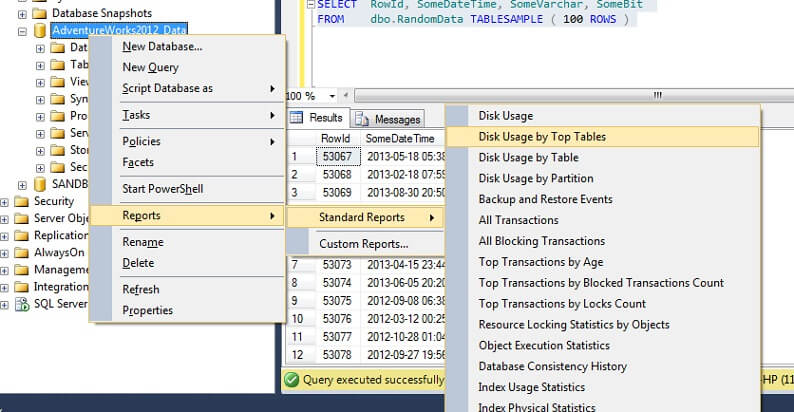
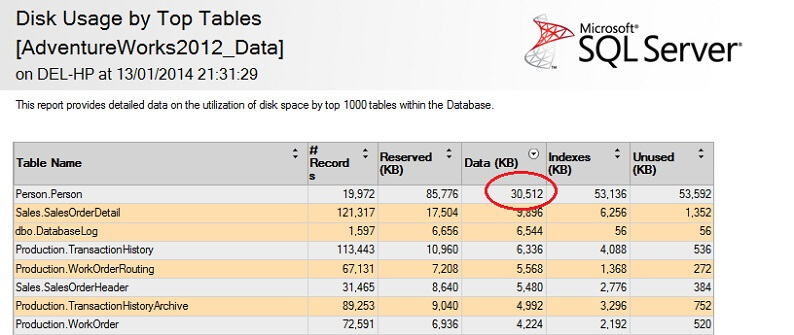
Zakroužkoval jsem zajímavý údaj – Osoba. Tabulka Osoba spotřebuje 30,5 MB dat a je největší (podle dat, nikoliv podle počtu záznamů) tabulkou. Zkusme tedy místo toho vzít vzorek z této tabulky:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
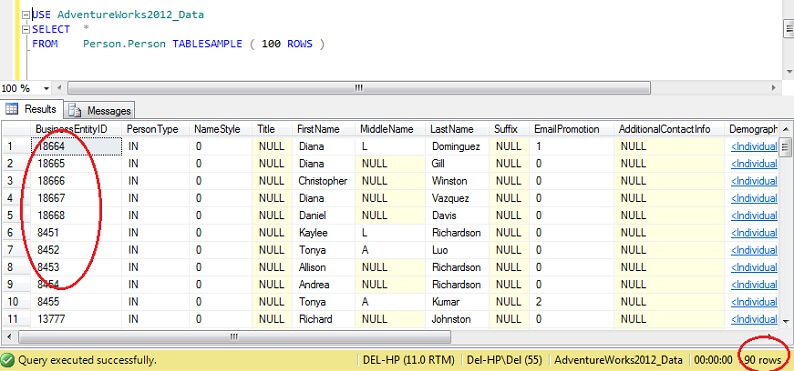
Vidíte, že jsme mnohem blíže 100 řádkům, ale co je podstatné, nezdá se, že by docházelo k velkému shlukování na primárním klíči (i když nějaké je, protože na jedné stránce je více než 1 řádek).
V důsledku toho je TABLESAMPLE dobrý pro velká data a katastrofálně se zhoršuje, čím menší je datový soubor. To se nám nehodí při výběru vzorků ze stratifikovaných dat nebo shlukovaných dat, kde odebíráme mnoho vzorků z malých skupin nebo podmnožin dat a ty pak agregujeme. Podívejme se tedy na alternativní metodu.
Náhodná data SQL Serveru s ORDER BY NEWID()
Tady je citace z BOL o získání skutečně náhodného vzorku:
„Pokud opravdu chcete náhodný vzorek jednotlivých řádků, upravte svůj dotaz tak, aby místo použití TABLESAMPLE náhodně filtroval řádky. Například následující dotaz používá funkci NEWID k vrácení přibližně jednoho procenta řádků tabulky Sales.SalesOrderDetail:
Jak to funguje? Rozdělíme klauzuli WHERE a vysvětlíme ji.
Funkce CHECKSUM počítá kontrolní součet nad položkami v seznamu. Je sporné, zda je SalesOrderID vůbec nutné, protože NEWID() je funkce, která vrací nový náhodný GUID, takže vynásobení náhodného čísla konstantou by mělo v každém případě vést k náhodnému číslu. ve skutečnosti se zdá, že vyloučení SalesOrderID na tom nic nemění. Pokud jste zanícený statistik a dokážete zdůvodnit zahrnutí této položky, použijte prosím níže uvedenou sekci komentářů a dejte mi vědět, proč se mýlím!
Funkce CHECKSUM vrací VARBINARY. Provedením bitové operace AND s 0x7fffffff, což je ekvivalent (111111111…) v binární soustavě, získáte desítkovou hodnotu, která je vlastně reprezentací náhodného řetězce 0 a 1. V tomto případě se jedná o desetinnou hodnotu. Dělením koeficientem 0x7fffffff se tato desetinná hodnota efektivně normalizuje na hodnotu mezi 0 a 1. Poté se pro rozhodnutí, zda si každý řádek zaslouží zařazení do konečné výsledné sady, použije práh 1/x (v tomto případě 0,01), kde x je procento dat, které se má získat jako vzorek.
Upozorňujeme, že tato metoda je spíše formou náhodného výběru než systematického výběru, takže pravděpodobně získáte data ze všech částí zdrojových dat, ale klíčové je, že *nemusíte*. Povaha náhodného výběru znamená, že každý jeden vzorek, který odeberete, může být zkreslený směrem k jednomu segmentu vašich dat, takže chcete-li využít regrese k průměru (v tomto případě tendence k náhodnému výsledku), zajistěte, abyste odebrali více vzorků a vybrali z jejich podmnožiny, pokud vaše výsledky vypadají zkresleně. Případně odebírejte vzorky z podmnožin dat a ty pak slučujte – jedná se o další typ vzorkování, tzv. stratifikované vzorkování.
Jak se provádí vzorkování statistik SQL Serveru?
V SQL Serveru probíhá automatická aktualizace sloupcových nebo uživatelsky definovaných statistik vždy, když se pro danou tabulku změní stanovený práh řádků. Pro rok 2012 je tato prahová hodnota vypočtena jako SQRT(1000 * TR), kde TR je počet řádků tabulky v tabulce. Před rokem 2005 se úloha automatické aktualizace statistiky spustí při každé (500 řádků + 20 % změny) řádků tabulky. Jakmile se proces automatické aktualizace spustí, vzorkování *snižuje počet vzorkovaných řádků tím více, čím je tabulka větší*, jinými slovy existuje vztah, který je podobný inverzní úměrnosti mezi procentem vzorkování tabulky a velikostí tabulky, ale řídí se vlastním algoritmem.
Zajímavé je, že to vypadá jako opak možnosti TABLESAMPLE (N PERCENT), kde je počet vzorkovaných řádků v normálním poměru k počtu řádků v tabulce. Můžeme vypnout automatické statistiky (při tomto postupu buďte opatrní) a aktualizovat statistiky ručně – toho dosáhneme použitím příkazu NORECOMPUTE v příkazu UPDATE STATISTICS. Pomocí příkazu UPDATE STATISTICS můžeme nadefinovat některé volby – například můžeme zvolit vzorkování N řádků nebo N procent (podobně jako u TABLESAMPLE), provést FULLSCAN nebo jednoduše RESAMPLE s použitím poslední známé míry.
Další kroky
Pro další čtení: Joseph Sack je Microsoft MVP známý svou prací v oblasti statistické analýzy SQL Serveru – níže naleznete několik odkazů na jeho práce spolu s odkazy na některé práce použité pro tento článek a na některé související tipy z MSSQLTips.com. Děkujeme za přečtení!
Poslední aktualizace: 2014-01-29


O autorovi
 Derek Colley je britský DBA a BI vývojář s více než desetiletými zkušenostmi s prací s SQL Serverem, Oracle a MySQL.
Derek Colley je britský DBA a BI vývojář s více než desetiletými zkušenostmi s prací s SQL Serverem, Oracle a MySQL.Zobrazit všechny mé tipy
- Další tipy pro vývojáře databází…
.