
Chcete-li se v Pythonu naučit více, zúčastněte se bezplatného kurzu DataCampu Úvod do Pythonu pro datovou vědu.
Všichni jste viděli datové sady. Někdy jsou malé, ale často jsou někdy enormně velké. Zpracování datových sad, které jsou velmi velké, se stává velmi náročným, přinejmenším natolik významným, že způsobuje úzké hrdlo při zpracování.
Takže, co způsobuje, že jsou tyto datové sady tak velké? No, jsou to funkce. Čím větší je počet rysů, tím větší budou datové sady. Tedy ne vždy. Najdete datové sady, kde je počet rysů velmi velký, ale neobsahují tolik případů. Ale to není předmětem této diskuse. Možná vás tedy bude zajímat, jak s komoditním počítačem v ruce zpracovávat tyto typy datových sad, aniž byste se mlátili do křoví.
Často se stává, že ve vysokorozměrné datové sadě zůstávají některé zcela nepodstatné, nevýznamné a nedůležité rysy. Bylo zjištěno, že přínos těchto typů rysů je často menší k prediktivnímu modelování ve srovnání s kritickými rysy. Jejich přínos může být i nulový. Tyto rysy způsobují řadu problémů, které následně brání procesu efektivního prediktivního modelování –
- Zbytečné přidělování zdrojů pro tyto rysy.
- Tyto rysy působí jako šum, pro který může model strojového učení fungovat strašně špatně.
- Trénování strojového modelu trvá déle.
Jaké je zde tedy řešení? Nejschůdnějším řešením je výběr funkcí.
Výběr funkcí je proces výběru nejvýznamnějších funkcí z daného souboru dat. V mnoha případech může výběr funkcí zvýšit i výkonnost modelu strojového učení.
Zní to zajímavě, že?
Dostali jste neformální úvod do výběru funkcí a jeho významu ve světě datové vědy a strojového učení. V tomto příspěvku se budete zabývat:
- Úvod do výběru prvků a pochopení jeho významu
- Rozdíl mezi výběrem prvků a redukcí dimenzionality
- Různé typy metod výběru prvků
- Implementace různých metod výběru prvků pomocí scikit-learn
Úvod do výběru příznaků
Výběr příznaků je také znám jako výběr proměnných nebo výběr atributů.
V podstatě se jedná o proces výběru nejdůležitějších/relevantních. Funkce souboru dat.
Pochopení důležitosti výběru funkcí
Důležitost výběru funkcí lze nejlépe rozpoznat, pokud pracujete se souborem dat, který obsahuje obrovské množství funkcí. Tento typ souboru dat se často označuje jako soubor dat s vysokou dimenzí. Nyní s touto vysokou dimenzionalitou přichází mnoho problémů, jako například – tato vysoká dimenzionalita výrazně prodlouží dobu trénování vašeho modelu strojového učení, může váš model velmi zkomplikovat, což zase může vést k Overfittingu.
Často ve vysoce dimenzionálním souboru funkcí zůstává několik funkcí, které jsou nadbytečné, což znamená, že tyto funkce nejsou ničím jiným než rozšířením jiných základních funkcí. Tyto nadbytečné rysy také efektivně nepřispívají k trénování modelu. Je tedy zřejmé, že je třeba extrahovat nejdůležitější a nejrelevantnější rysy pro soubor dat, aby se dosáhlo co nejefektivnějšího výkonu prediktivního modelování.
„Cíl výběru proměnných je trojí: zlepšit predikční výkon prediktorů, poskytnout rychlejší a nákladově efektivnější prediktory a poskytnout lepší pochopení základního procesu, který data generoval.“
Úvod do výběru proměnných a příznaků
Nyní pochopíme rozdíl mezi redukcí dimenzionality a výběrem příznaků.
Někdy se výběr příznaků zaměňuje s redukcí dimenzionality. Jsou však odlišné. Výběr příznaků se liší od redukce dimenzionality. Obě metody směřují ke snížení počtu atributů v souboru dat, ale metoda redukce dimenzionality tak činí vytvářením nových kombinací atributů (někdy se tomu říká transformace příznaků), zatímco metody výběru příznaků zahrnují a vylučují atributy přítomné v datech, aniž by je měnily.
Některé příklady metod redukce dimenzionality jsou analýza hlavních komponent, rozklad singulární hodnoty, lineární diskriminační analýza atd.
Dovolte mi, abych pro vás shrnul význam výběru příznaků:
- Umožňuje rychlejší trénování algoritmu strojového učení.
- Snižuje složitost modelu a usnadňuje jeho interpretaci.
- Zlepšuje přesnost modelu, pokud je vybrána správná podmnožina.
- Snižuje Overfitting.
V další části se budete zabývat různými typy obecných metod výběru příznaků – metodami filtru, metodami obalu a vloženými metodami.
Metody filtru
Metody výběru příznaků založené na filtru nejlépe vystihuje následující obrázek:

Zdroj obrázku: Vidhya
Filtrační metoda spoléhá na obecnou jedinečnost vyhodnocovaných dat a vybírá podmnožinu příznaků, nezahrnuje žádný miningalgoritmus. Metoda filtru používá přesné kritérium hodnocení, které zahrnuje vzdálenost, informaci, závislost a konzistenci. Metoda filtru používá hlavní kritéria techniky řazení a pro výběr proměnných používá metodu řazení. Důvodem pro použití metody řazení je jednoduchost, produkují vynikající a relevantní funkce. Metoda řazení odfiltruje irelevantní rysy před zahájením procesu klasifikace.
Metody filtru se obvykle používají jako krok předzpracování dat. Výběr rysů je nezávislý na jakémkoli algoritmu strojového učení. Rysy udávají pořadí na základě statistických skóre, která mají tendenci určovat korelaci rysů s výslednou proměnnou. Korelace je silně kontextový pojem a v jednotlivých pracích se liší. Definice korelačních koeficientů pro různé typy dat (v tomto případě spojitá a kategoriální) naleznete v následující tabulce.

Zdroj obrázku:
Mezi příklady některých filtračních metod patří Chí-kvadrát test, informační zisk a skóre korelačního koeficientu.
Dále se seznámíte s metodami Wrapper.
Obalovací metody
Stejně jako u filtračních metod vám uvedu stejný druh infografiky, která vám pomůže lépe pochopit obalovací metody:
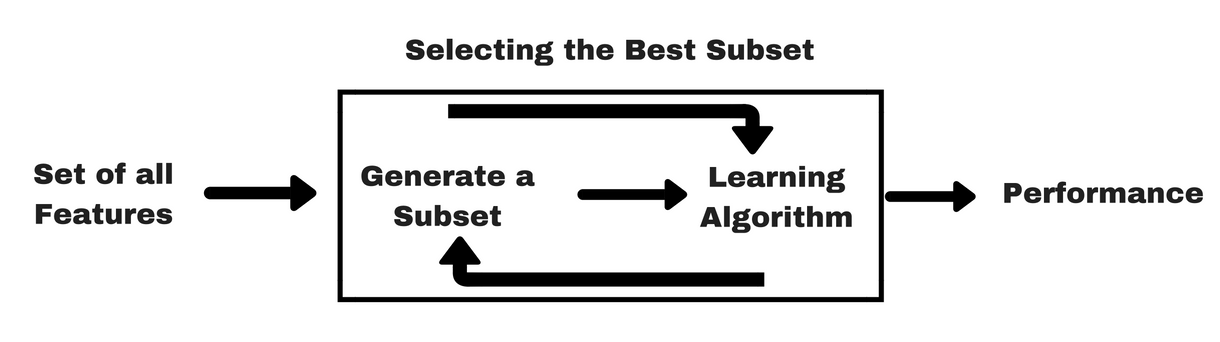
Zdroj obrázku: Jak vidíte na výše uvedeném obrázku, metoda wrapper potřebuje jeden algoritmus strojového učení a jako kritérium hodnocení používá jeho výkonnost. Tato metoda hledá funkci, která je nejvhodnější pro algoritmus strojového učení, a jejím cílem je zlepšit výkonnost těžby. K vyhodnocení příznaků se používá přesnost předpovědi pro klasifikační úlohy a vhodnost shluku se vyhodnocuje pomocí shlukování.
Některé typické příklady obalovacích metod jsou dopředný výběr příznaků, zpětná eliminace příznaků, rekurzivní eliminace příznaků atd.
- Dopředný výběr: Postup začíná s prázdnou množinou rysů . Určí se nejlepší z původních rysů a přidá se do redukované množiny. Při každé další iteraci se do množiny přidá nejlepší ze zbývajících původníchpříznaků.
- Zpětná eliminace: Postup začíná s úplnou množinou atributů. V každém kroku odstraní nejhorší atribut, který v množině zbývá.
- Kombinace dopředného výběru a zpětné eliminace: Metody postupného výběru vpřed a zpětné eliminace lze kombinovat tak, že v každém kroku postup vybere nejlepší atribut a odstraní nejhorší ze zbývajících atributů.
- Rekurzivní eliminace příznaků: Rekurzivní eliminace příznaků provádí chamtivé vyhledávání s cílem najít nejvýkonnější podmnožinu příznaků. Iterativně vytváří modely a v každé iteraci určuje nejlépe nebo nejhůře výkonný příznak. Další modely konstruuje s ponechanými rysy, dokud nejsou prozkoumány všechny rysy. Poté seřadí rysy na základě pořadí jejich vyřazení. V nejhorším případě, pokud datová sada obsahuje N počtu rysů, RFE provede chamtivé hledání 2N kombinací rysů.
Dostatečně!“
Nyní se věnujme vestavěným metodám.
Vestavěné metody
Vestavěné metody jsou iterativní v tom smyslu, že se starají o každou iteraci procesu trénování modelu a pečlivě extrahují ty rysy, které nejvíce přispívají k trénování pro danou iteraci. Regularizační metody jsou nejčastěji používané vložené metody, které penalizují funkci danou prahovou hodnotou koeficientu.
Proto se regularizačním metodám říká také penalizační metody, které do optimalizace predikčního algoritmu (například regresního algoritmu) zavádějí další omezení, která vychylují model směrem k nižší složitosti (menšímu počtu koeficientů).
Příkladem regularizačních algoritmů jsou LASSO, Elastic Net, Ridge Regression atd.
Rozdíl mezi filtračními a obalovými metodami
No, někdy může být matoucí rozlišovat mezi filtračními a obalovými metodami z hlediska jejich funkcí. Podívejme se, v jakých bodech se od sebe liší.
- Filtrační metody nezahrnují model strojového učení, aby určily, zda je funkce dobrá nebo špatná, zatímco wrapperové metody používají model strojového učení a trénují ho funkce, aby rozhodly, zda je podstatná, nebo ne.
- Filtrační metody jsou ve srovnání s wrapperovými metodami mnohem rychlejší, protože nezahrnují trénování modelů. Na druhou stranu jsou obalové metody výpočetně nákladné a v případě masivních datových souborů nejsou obalové metody nejefektivnější metodou výběru příznaků, která přichází v úvahu.
- Filtrační metody mohou selhat při nalezení nejlepší podmnožiny příznaků v situacích, kdy není k dispozici dostatek dat pro modelování statistické korelace příznaků, ale obalové metody mohou díky své vyčerpávající povaze vždy poskytnout nejlepší podmnožinu příznaků.
- Použití rysů z obalových metod v konečném modelu strojového učení může vést k nadměrnému přizpůsobení, protože obalové metody již s rysy trénují modely strojového učení, a to ovlivňuje skutečnou sílu učení. Ale rysy z filtračních metod ve většině případů k overfittingu nepovedou
Dosud jste studovali význam výběru rysů, pochopili jste jeho rozdíl oproti redukci dimenzionality. Rovněž jste se zabývali různými typy metod výběru příznaků. Zatím je to dobré!
Nyní se podíváme na některé pasti, do kterých se můžete dostat při provádění výběru příznaků:
Důležitá úvaha
Možná jste již pochopili, jakou hodnotu má výběr příznaků v pipeline strojového učení a jaké služby poskytuje, je-li integrován. Je však velmi důležité pochopit, na jakém místě přesně byste měli výběr příznaků do potrubí strojového učení začlenit.
Zjednodušeně řečeno, krok výběru příznaků byste měli zařadit před předáním dat modelu k trénování, zejména pokud používáte metody odhadu přesnosti, jako je křížová validace. Tím zajistíte, že výběr příznaků bude proveden na složce dat těsně před trénováním modelu. Pokud však nejprve provedete výběr příznaků, abyste připravili data, a poté provedete výběr modelu a trénování na vybraných příznacích, pak by to byla chyba.
Pokud provedete výběr příznaků na všech datech a poté provedete křížovou validaci, pak byla pro výběr příznaků použita také testovací data v každé složce postupu křížové validace, a to má tendenci zkreslovat výkon vašeho modelu strojového učení.
Dost bylo teorie! Přejděme nyní rovnou ke kódování.
Případová studie v jazyce Python
Pro tuto případovou studii použijete datovou sadu Pima Indians Diabetes. Popis datasetu naleznete zde.
Dataset odpovídá klasifikační úloze, na které musíte na základě 8 rysů předpovědět, zda má osoba cukrovku.
V datasetu je celkem 768 pozorování. Vaším prvním úkolem je načíst datovou sadu, abyste mohli pokračovat. Ještě předtím však naimportujme potřebné závislosti, které budete potřebovat. Další můžete importovat průběžně.
import pandas as pdimport numpy as npTeď, když jsou závislosti importovány, načtěme datovou sadu Pima Indians do objektu Dataframe pomocí knihovny Pandas.
data = pd.read_csv("diabetes.csv")Datová sada je úspěšně načtena do datového objektu Dataframe. Nyní se podívejme na data.
data.head()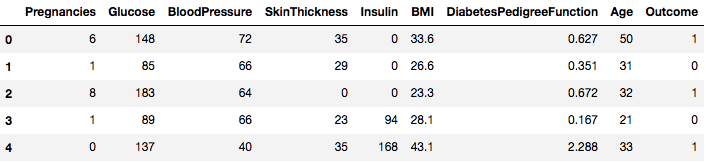
Vidíte tedy 8 různých funkcí označených do výsledků 1 a 0, kde 1 znamená, že pozorování má cukrovku, a 0 označuje, že pozorování cukrovku nemá. Je známo, že soubor dat obsahuje chybějící hodnoty. Konkrétně se jedná o chybějící pozorování pro některé sloupce, které jsou označeny jako nulová hodnota. Lze to odvodit z definice těchto sloupců a je nepraktické, aby nulová hodnota byla pro tato měření neplatná, např, nula pro index tělesné hmotnosti nebo krevní tlak je neplatná.
Pro tento tutoriál však budete používat přímo předzpracovanou verzi datové sady.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Data jste nyní načetli do objektu DataFrame s názvem dataframe.
Převedeme objekt DataFrame na pole NumPy, abychom dosáhli rychlejšího výpočtu. Také rozdělme data do samostatných proměnných, aby byly funkce a popisky odděleny.
array = dataframe.valuesX = arrayY = arrayBáječně! Připravili jste si data.
Nejprve zavedete statistický test Chi-Squared pro nezáporné rysy, abyste ze souboru dat vybrali 4 nejlepší rysy. Již jste viděli, že Chi-Squared test patří do třídy filtračních metod. Pokud by někoho zajímalo, jak poznat vnitřek Chi-Squared, toto video odvádí vynikající práci.
Knihovna scikit-learn poskytuje třídu SelectKBest, kterou lze použít se sadou různých statistických testů pro výběr určitého počtu rysů, v tomto případě je to Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Knihovny jste importovali pro spuštění experimentů. Nyní si je prohlédněte v akci.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretace:
Můžete si prohlédnout skóre jednotlivých atributů a 4 vybrané atributy (ty s nejvyšším skóre): plas, test, hmotnost a věk. Toto skóre vám dále pomůže při určování nejlepších rysů pro trénování modelu.
P.S.: První řádek označuje názvy rysů. Pro předběžné zpracování datové sady byly názvy číselně zakódovány.
Dále budete implementovat rekurzivní eliminaci rysů, což je typ obalové metody výběru rysů.
Rekurzivní eliminace rysů (neboli RFE) funguje tak, že rekurzivně odstraní atributy a sestaví model na těch atributech, které zůstanou.
Používá přesnost modelu k určení, které atributy (a kombinace atributů) nejvíce přispívají k předpovědi cílového atributu.
V dokumentaci scikit-learn se můžete dozvědět více o třídě RFE.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionPomocí RFE s klasifikátorem Logistic Regression vyberete 3 nejlepší rysy. Na výběru algoritmu příliš nezáleží, pokud je šikovný a konzistentní.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Vidíte, že RFE vybral 3 nejlepší rysy jako preg, mass a pedi.
Ty jsou v poli podpory označeny True a v poli klasifikace označeny volbou „1“. To zase označuje sílu těchto rysů.
Dále budete používat Ridgeovu regresi, což je v podstatě regularizační technika a také technika výběru vložených rysů.
Tento článek vám poskytne vynikající vysvětlení o Ridgeově regresi. Určitě se na něj podívejte.
# First things firstfrom sklearn.linear_model import RidgeDále použijete Ridgeovu regresi k určení koeficientu R2.
Také se podívejte na oficiální dokumentaci scikit-learnu k Ridgeově regresi.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Pro lepší pochopení výsledků Ridgeovy regrese budete implementovat malou pomocnou funkci, která vám pomůže výsledky lépe vypsat, abyste je mohli snadno interpretovat.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Dále této malé funkci předáte členy koeficientů Ridgeova modelu a uvidíte, co se stane.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Můžete si všimnout všech členů koeficientů doplněných o příznakové proměnné. To vám opět pomůže vybrat ty nejpodstatnější funkce. Níže je uvedeno několik bodů, které byste měli mít na paměti při použití Ridgeovy regrese:
- Je také známá jako L2-Regularizace.
- U korelovaných rysů to znamená, že mají tendenci získávat podobné koeficienty.
- Funkce, které mají záporné koeficienty, nepřispívají tolik. Ale ve složitějším scénáři, kdy máte co do činění s velkým množstvím rysů, pak vám toto skóre určitě pomůže v konečném rozhodovacím procesu výběru rysů.
No a tím končí část případové studie. Metody, které jste implementovali ve výše uvedené části, vám pomohou komplexně porozumět rysům konkrétní sady dat. Dovolte mi, abych vám k těmto technikám uvedl několik kritických bodů:
- Výběr příznaků je v podstatě součástí předzpracování dat, které je považováno za časově nejnáročnější část každého procesu strojového učení.
- Tyto techniky vám pomohou přistupovat k němu systematičtěji a šetrněji ke strojovému učení. Budete schopni interpretovat příznaky přesněji.
Zabalte to!“
V tomto příspěvku jste se zabývali jedním z nejlépe prostudovaných a prozkoumaných statistických témat, tj. výběrem příznaků. Seznámili jste se také s jeho různými variantami a použili jste je k tomu, abyste zjistili, které rysy v souboru dat jsou důležité.
Tento tutoriál můžete posunout dále tím, že do metody obalování sloučíte korelační míru a zjistíte, jak si vede. V průběhu činnosti můžete nakonec vytvořit vlastní mechanismus výběru příznaků. Takto vytvoříte základ pro svůj malý výzkum. Výzkumníci k provádění výběru používají také různé principy soft computingu. To je samo o sobě celá oblast studia a výzkumu. Také byste měli vyzkoušet existující algoritmy výběru příznaků na různých souborech dat a vyvodit vlastní závěry.
Proč se tyto tradiční metody výběru příznaků stále drží?“
Ano, tato otázka je zřejmá. Protože existují architektury neuronových sítí (například CNN), které jsou poměrně schopné extrahovat z dat nejvýznamnější rysy, ale i to má svá omezení. Použití CNN pro běžnou tabulkovou sadu dat, která nemá specifické vlastnosti (vlastnosti, které má typický obrázek, jako jsou přechodové vlastnosti, hrany, polohové vlastnosti, obrysy atd. Navíc, pokud máte omezená data a omezené zdroje, může se trénování CNN na běžných tabulkových souborech dat proměnit v naprosté plýtvání. V takových situacích se tedy určitě budou hodit metody, které jste studovali.
Následují některé zdroje, pokud byste chtěli do tohoto tématu více proniknout:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection:
- Výběr příznaků: seminář o statistických a optimalizačních perspektivách
- Výběr příznaků:
- Použití genetických algoritmů pro výběr příznaků v analýze dat
Níže jsou uvedeny odkazy, které byly použity při psaní tohoto tutoriálu.
- Data Mining: Koncepty a techniky; Jiawei Han Micheline Kamber Jian Pei.
- Úvod do výběru příznaků
- Článek Analytics Vidhya o výběru příznaků
- Hierarchický a smíšený model – kurz DataCamp
- Výběr příznaků pro strojové učení v jazyce Python
- Detekce odlehlých hodnot v proudových datech metodami strojového učení a výběru příznaků
- S. Visalakshi a V. Radha, „A literature review of feature selection techniques and applications: Review of feature selection in data mining,“ 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, s. 1-6.
.