GPI-geankerde proteïnen zijn het buitenbeentje. In de inleidende cursus celbiologie leerden we dat er vijf soorten membraaneiwitten zijn, die als volgt worden genoemd: Type I, Type II, Type III, Type IV, en GPI-verankerd. Waarom hebben we deze vreemde klasse van eiwitten die zijn samengesmolten met een suiker-en-vetketen? Wat doen ze? Kunnen we enig inzicht krijgen in mijn interessant eiwit – PrP – door meer te weten te komen over deze klasse van eiwitten waartoe het behoort?
Sonia en ik en onze teamgenoot Andrew hebben wat gelezen over dit onderwerp en ik schrijf deze blog post om wat van wat we geleerd hebben te delen.
lezen
We zijn begonnen met het lezen van een paar reviews . Deze behandelden vooral de structuur en biogenese van het GPI-anker zelf, waarover verbazingwekkend veel bekend is.
Dit anker, waarvan de volledige naam glycosylfosfatidylinositol is, is geen monoliet: het is een algemene beschrijving van een molecule waarvan de details kunnen variëren. In het algemeen heb je, beginnend bij het ω (laatste post-translationeel aanwezige) residu van het eiwit, ethanolamine, dan een fosfaat, dan wat suikers, en dan een fosfolipide. De suikerkern is geconserveerd, maar de zijketens die zich daarvan aftakken kunnen variëren, en de fosfolipidehoofdgroep en de vetzuren kunnen ook variëren. Het GPI-anker van PrP werd gekarakteriseerd in , maar zelfs dan is het geen monoliet – zij identificeerden ten minste zes verschillende structuren die verschillen in suikerzijketensamenstelling.
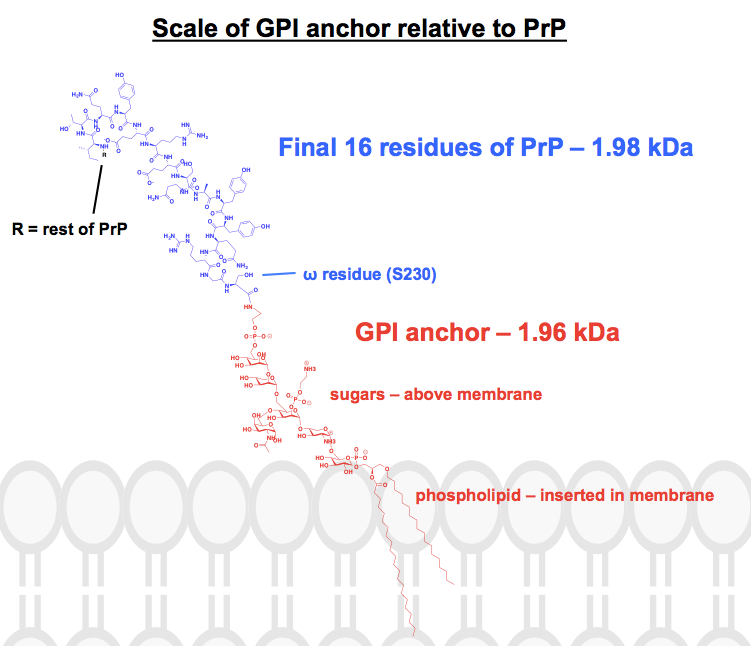
Iedere chemische structuur die ik heb gevonden van GPI-ankers heeft ten minste enkele delen afgekort of samengevat, en het eiwit wordt meestal alleen getoond als een afbeelding. Ik wilde een idee krijgen van hoe deze ankers er chemisch gezien eigenlijk uitzien, in de context van de eiwitten waaraan ze zijn verbonden, dus ben ik begonnen met het tekenen van een volledige structuur in ChemDraw. Werkend vanuit Figuur 1 van – het dichtst bij een complete skeletstructuur die ik kon vinden – voegde ik de details toe van een van PrP’s GPI ankers uit het bovenste paneel van Figuur 6. Het molecuulgewicht kwam uit op 1.958 Da, dus voor de context heb ik de laatste 16 residuen van HuPrP23-230 erbij getekend, die ongeveer evenveel wegen, namelijk 1.979 Da. Dit is ongeveer 8% van de post-translationeel gewijzigde sequentie van PrP. Ik weet niet zeker of ik elke binding goed heb, maar dit is wat ik heb gevonden:
In veel gevallen heeft een gen meerdere isovormen, waarbij het ene splicingproduct leidt tot een GPI-geankerd eiwit, terwijl de andere leidt tot gesecreteerde of transmembraanvormen. Voorbeelden hiervan zijn NCAM1, dat drie belangrijke isovormen heeft, waarvan er één GPI-geankerd is en de andere twee transmembraan zijn, en ACHE (dat acetylcholinesterase codeert), waarvan de GPI-geankerde vorm blijkbaar alleen in rode bloedcellen wordt aangetroffen (NCBI Genes). Het meest fascinerende verhaal hier is dat van het muizengen Ly6a dat, dankzij een genetisch polymorfisme, in sommige muizenstammen GPI-verankerd is en in andere niet. Alleen in zijn GPI-verankerde vorm fungeert het als receptor voor de virale vector AAV PHP.eB. (Deze vector bereikt een verbazingwekkend efficiënte opname in hersenneuronen voor gentherapie, maar helaas is het alleen een muizengen – wij mensen hebben Ly6a niet eens).
Er is veel bekend over hoe GPI-ankers worden gesynthetiseerd en aan eiwitten worden gehecht, met >20 eiwitten die betrokken zijn bij de pathway, waarvan de meeste beginnen met het voorvoegsel “PIG” en worden gecodeerd door genen zoals PIGA, PIGK, enzovoort – zie figuur 2 voor een diagram. Het grootste deel van de biosynthese vindt plaats terwijl het anker in het ER-membraan is ingebracht, maar niet aan een eiwit is gekoppeld. In feite vinden de eerste stappen plaats op het cytosolische blad van het membraan, en pas later klapt het anker om naar de lumenale zijde (binnen het ER). De laatste stap is wanneer GPI transamidase, een complex van ten minste vijf eiwitten, het GPI-signaal van de C-terminus van het eiwit afsplitst en het GPI-anker aan het zogenaamde ω-residu van het eiwit hecht (het laatste residu in de post-translationeel gewijzigde sequentie). Vervolgens wordt het GPI-anker verder gerijpt terwijl het eiwit uit de ER naar het celoppervlak migreert.
Er bestaan een aantal kleine molecule-remmers van de GPI-biosynthese in schimmels, waarvan sommige zijn ontwikkeld als antischimmelmedicijn, maar voor zover ik weet is de enige bekende remmer van de GPI-biosynthese in zoogdiercellen mannosamine, een mannose-analoog die chemisch incompatibel is met incorporatie in GPI.
Ik heb gezocht en gezocht naar een sequentie-logo van welk aminozuur-sequentie-motief GPI transamidase herkent, maar vond er geen. Blijkbaar is het sequentiemotief nogal los, en blijkbaar zijn de GPI-signalen niet eens homoloog, wat betekent dat ze niet zijn geëvolueerd vanuit een gemeenschappelijke voorouderlijke sequentie, maar eerder convergent zijn geëvolueerd, voor zover er zelfs maar sprake is van convergentie. De beste beschrijving die ik heb kunnen vinden is dat (als je N-to-C-terminaal leest tot aan het einde van het eiwit) je 1) ongeveer 11 residuen van een ongestructureerde linker nodig hebt, 2) een paar residuen met kleine zijketens waaronder een ω-residu dat zowel S, N, D, G, A, of C kan zijn, 3) een spacer van 5-10 polaire aminozuren, en tenslotte 4) 15-20 hydrofobe aminozuren. PrP volgt losjes dit motief. Volgens gepubliceerde structuren eindigt alpha-helix 3 bij residu Q223, waardoor de “ongestructureerde linker” slechts AYYQR is (iets korter dan de voorgeschreven 11 residuen). Het gebied met de “kleine zijketens” zou GS|SM zijn (met de pijp als snijpunt van de transamidase), het polaire gebied VLFSSPP, en het hydrofobe C-eindpunt VILLISFLIFLIVG.
Sommige eiwitten in de GPI biosynthese en aanhechtingsroute zijn zeer belangrijk, en een aantal ernstige ziekten en syndromen van GPI anker deficiëntie zijn beschreven, als gevolg van biallelic verlies van functie of schijnbaar hypomorfe missense mutaties in genen zoals PIGO, PIGV, PIGW, PGAP2, en PGAP3 .
Sonia vond een uitstekend artikel van een paar jaar geleden waar ze een mutagenese-onderzoek deden in haploïde menselijke cellen om genen te identificeren die nodig zijn voor de biogenese van twee GPI-verankerde eiwitten: PrP en CD59 . Zij gebruikten herhaaldelijk FACS sorteren van cellen op basis van celoppervlak PrP en CD59 om cellen te identificeren met dramatisch verlaagde oppervlaktespiegels van deze eiwitten, en deden vervolgens sequencing om te zien welke gen-knockouts verrijkt waren in deze cellen ten opzichte van de ouderpopulatie. Zoals je zou verwachten, kwamen de meeste PIG genen naar boven voor beide eiwitten (Figuur 4), maar niet alle hits overlapten, wat een beetje verrassend is, vooral omdat op RNA-niveau PrP en CD59 tenminste twee van de eiwitten zijn met de meest vergelijkbare expressieprofielen in verschillende weefsels (zie de warmtekaart onderaan dit bericht). Een aantal enzymen die betrokken zijn bij de modificatie van de GPI-anker zijketens werden alleen gevonden voor CD59, wat suggereert dat CD59, maar niet PrP, deze complexe zijketens nodig heeft om te rijpen en het celoppervlak te bereiken. Ondertussen werden Sec62 en Sec63 alleen gevonden voor PrP – dit zijn eiwitten die op de een of andere manier betrokken zijn bij co-translationele translocatie naar de ER, maar blijkbaar zijn ze nodig voor PrP maar niet voor CD59 of voor CD55 of CD109, twee andere controle-eiwitten die zij hebben onderzocht. Dit is een fascinerend nieuw hoofdstuk in het antwoord op mijn vraag: “Is er iets speciaals aan de expressie van PrP?”, waarin ik zocht naar iets unieks aan de biogenese van PrP dat mogelijk met een klein molecuul zou kunnen worden aangepakt. Natuurlijk betekent het feit dat deze eiwitten niet belangrijk waren voor drie andere controle-eiwitten niet dat ze niet belangrijk zijn – een studie heeft aangetoond dat Sec62 nodig is voor de secretie van vele kleine eiwitten , en het SEC62-gen is volledig uitgeput voor varianten met verlies van functie in de menselijke populatie, genoeg om haploinsufficiëntie te suggereren. SEC63 lijkt minder beperkt, maar dat zou kunnen betekenen dat het recessief werkt.
Geen van de bovenstaande antwoorden geeft antwoord op de vraag waarom er GPI-geankerde eiwitten bestaan. Mijn oude celbiologieles liet trouwens een detail weg: er is eigenlijk een zesde klasse van membraaneiwitten, genaamd tail-anchored (TA) eiwitten , die alleen een hydrofobe C terminus hebben die in het membraan steekt maar er aan de andere kant niet uitsteekt. Waarom kunnen al deze GPI-geankerde eiwitten niet gewoon TA-eiwitten zijn? Waarom hebben cellen zo’n ingewikkelde route ontwikkeld om in plaats daarvan een suiker-vet anker te synthetiseren, en waarom hebben ze dat zo vroeg in het spel gedaan – GPI ankers zijn aanwezig in alle eukaryoten, inclusief in veel eencellige ziekteverwekkers die de mens infecteren.
De meeste reviews besteedden niet veel tijd aan deze vraag, waarschijnlijk omdat het het moeilijkste is om te beantwoorden. De GPI-geankerde eiwitten zelf, voor zover hun natieve functies bekend zijn, hebben een enorm scala aan functies – er zijn enzymen (zoals AChE), celadhesiemoleculen (zoals NCAM1), eiwitten die het complement in het immuunsysteem reguleren (CD59), enzovoort . Er is blijkbaar ten minste één GPI-geankerd eiwit betrokken bij het myeline-onderhoud in perifere zenuwen. Maar wat kunnen GPI-geankerde eiwitten nu precies doen dat andere eiwitten niet kunnen? In een overzicht worden een paar ideeën genoemd die zijn voorgesteld. Eén daarvan is dat GPI-geankerde eiwitten goed zijn in het tijdelijk dimeren. In sommige studies is het idee onderzocht dat homodimerisatie een rol speelt in de prionbiologie, maar het is nog niet duidelijk in hoeverre de daar gebruikte modelsystemen relevant zijn voor de in vivo situatie. Een ander idee is dat GPI-geankerde eiwitten van het celoppervlak kunnen worden verwijderd, bijvoorbeeld door angiotensine-converting enzyme (ACE), en dat hun lokalisatie op dynamische wijze kan worden gereguleerd. Ook hier weten we dat PrP kan worden afgestoten, blijkbaar door het enzym ADAM10 , hoewel een eventuele rol in de eigen functie van PrP nog niet duidelijk is. Een derde idee, en misschien wel het idee waarover ik het meest heb horen spreken, is dat GPI-geankerde eiwitten selectief samenkomen in “lipid rafts”. Dit is misschien de meest aanlokkelijke verklaring, want je zou je allerlei domino-effecten kunnen voorstellen, waarbij de verhoogde effectieve lokale concentratie van deze eiwitten meer interacties mogelijk maakt, enzovoort. Maar een review wees erop dat een voorbehoud is dat lipid rafts nog steeds meer een abstract idee zijn dan een concreet ding – terwijl ze functioneel worden gedefinieerd door de onoplosbaarheid van detergenten en de meeste mensen ze beschrijven als rijk aan sfingomyeline en cholesterol, is er geen universeel aanvaarde definitie van wat wel en niet een lipid raft is, en het empirisch bewijs suggereert dat ze veel kleiner en meer vergankelijk zijn dan de meeste mensen denken.
Met die gegevens in de hand, ben ik op zoek gegaan naar een lijst van deze eiwitten en heb ik ze geanalyseerd om te zien of ik een beter idee kon krijgen hoe ze in elkaar zitten.
analyses
Uniprot heeft een lijst van 173 menselijke GPI-geankerde eiwitten. Deze komen overeen met 140 gensymbolen, die daalden tot 135 na het uitvoeren van dit script om de huidige HGNC-goedgekeurde eiwit-coderende gensymbolen aan te passen. De uiteindelijke lijst van 135 gensymbolen is hier.
Uniprot biedt geen informatie over hoe hun annotaties werden gegenereerd, hoewel er een aanzienlijke mate van handmatige curatie moet zijn. Ter vergelijking heeft Andrew ook een reeks keurige artikelen opgegraven waarin gebruik wordt gemaakt van PI-PLD of PI-PLC, twee enzymen die GPI-ankers splitsen, om op empirische wijze GPI-geankerde eiwitten uit cellen te isoleren. Het combineren van de lijsten uit deze artikelen en de mapping naar de huidige gensymbolen leverde 107 genen op. We controleerden een aantal van deze genen steekproefsgewijs. Onder hen waren bekende GPI-geankerde eiwitten zoals glypican-1 (GPC1) en neural cell adhesion molecule (NCAM1), die beide naar verluidt interacties hebben met PrP . Maar er waren ook verschillende genen aanwezig waarvoor in de literatuur geen GPI-verankering bekend leek te zijn, zoals VDAC3, waarvan sommige gewoon zeer overvloedige eiwitten kunnen zijn of om andere redenen vals-positieven. Intussen zijn er duidelijke bronnen van vals-negatieve resultaten: genen die in de bestudeerde cellijn gewoon niet tot expressie kwamen, of niet talrijk genoeg waren om met mass spec te worden opgepikt, en de PrP-paralogen SPRN en PRND stonden niet op de lijsten. In totaal kwamen 51 genen in beide lijsten voor, een zeer significante verrijking (OR = 217, P < 1 × 10-84), wat me geruststelt dat de annotaties van Uniprot consistent zijn met empirische gegevens. Maar voor verdere analyses hebben we besloten om te gaan met de Uniprot lijst als het lijkt meer gevoelige en specifieke.
Gewapend met deze lijst, wilde ik zien hoe GPI-geankerde eiwitten stack up. PrP is een enkel exon, kort (208 aminozuren in zijn rijpe vorm), niet-essentieel, breed-geëxpresseerd eiwit. Zijn deze kenmerken typisch of atypisch voor een GPI-geankerd eiwit?
Het blijkt dat GPI-geankerde eiwitten alle kanten op gaan, net zo variabel op elke dimensie die ik heb bekeken als elke andere groep eiwitten.
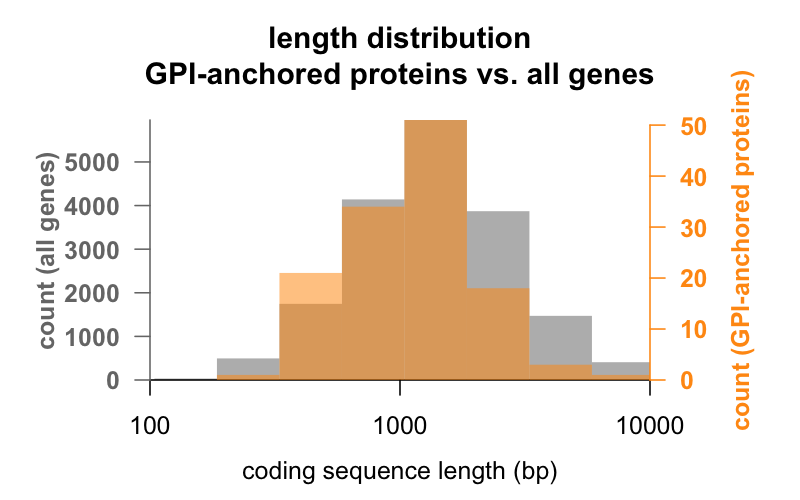
Eerst de lengte. Hieronder ziet u over elkaar liggende histogrammen van de lengte van de coderende sequentie in basenparen voor alle genen, versus genen die coderen voor GPI-geankerde eiwitten. De GPI-geankerde verdeling is nauwelijks naar links verschoven. Het gemiddelde GPI-geankerde eiwitgen heeft 1.301 bp coderende sequentie, terwijl het gemiddelde gen er 1.729 heeft, maar dit verschil van gemiddelden is klein vergeleken met de variatie binnen elke groep. PrP, met slechts 762 bp coderende sequentie, is zeker aan de kleine kant, hoewel het in geen van beide groepen een uitschieter is – CD52, met slechts 186 basenparen sequentie en blijkbaar slechts 12 aminozuren in zijn rijpe vorm, is het kleinste GPI-geankerde eiwit.
Hoe zit het met het aantal exonen? GPI-geankerde eiwitten hebben gemiddeld iets minder exonen dan alle andere genen (gemiddeld 7,8 vs. 10,1), wat in overeenstemming is met het kleine verschil in lengteverdeling dat hierboven is opgemerkt, maar de meeste zijn multi-exon. Ook hier is PrP aan de kleine kant: er zijn slechts zes GPI-geankerde eiwitten die slechts één coderend exon hebben, en drie daarvan zijn PrP en zijn twee paralogen, Sho en Dpl. (De andere drie genen zijn GAS1, SPACA4, en de fabelachtig genaamde OMG).
Daarnaast keek ik naar loss-of-function constraint. Constraint is een maat voor hoe sterk de natuurlijke selectie is die een gen ondergaat, gebaseerd op hoe uitgeput het is voor, laten we zeggen, nonsense, frameshift, en splice site variatie in de algemene populatie in vergelijking met de verwachting op basis van de mutatiecijfers. Deze metriek is niet erg interpreteerbaar voor korte genen, zowel om statistische redenen (het aantal verwachte mutaties is laag voor korte genen, dus is het moeilijk om de depletie te kwantificeren) als om biologische redenen (single exon genen zijn niet onderhevig aan nonsens-gemedieerd verval, dus is het moeilijker om te weten of eiwit-afknottende varianten echt “loss-of-function” zijn of niet). Maar aangezien de meeste GPI-geankerde eiwitten niet zo kort zijn als PrP, vond ik het de moeite waard om er eens naar te kijken. Het resultaat: gemiddeld zijn GPI-geankerde eiwitten net iets minder beperkt, wat betekent dat ze meer van hun verwachte hoeveelheid verlies-van-functie variatie hebben, dan het gemiddelde gen. Het gemiddelde gen heeft 47% van zijn verlies-van-functie variatie, en GPI-geankerde proteïnen hebben 56%. Maar zoals met alles hier, is er een grote spreiding in beide kampen. Voor GPI-geankerde eiwitten heb je aan de ene kant de absoluut beperkte ACHE (17 LoF’s verwacht en geen waargenomen) en aan de andere kant verschillende genen die helemaal niet geselecteerd lijken te zijn tegen verlies van functie – CNTN6, CD109, TREH, en MSLN zijn enkele voorbeelden. PRNP valt in het laatste kamp als je de residuen ≥145 uitsluit, waar eiwit-afbrekende varianten een toename van de functie veroorzaken.
Ten slotte vroeg ik me af waar GPI-geankerde eiwitten tot expressie komen. PRNP is het hoogst in de hersenen, maar komt overal tot expressie. Is dat typisch? Ik heb het volledige GTEx v7 “gene median tpm” overzichtsbestand gedownload (15 jan 2016), waarin elke rij een gen is en elke kolom een weefsel en de cellen zijn RPKMs – RNA-seq reads per kilobase van exon per miljoen gemapte reads. Het werken met deze dataset vergde enige finesses. Ik heb gehoord dat sommige bioinformatici <1 RPKM beschouwen als “niet tot expressie gebracht”, maar de expressiematrix is schaars – de meeste genen komen in de meeste weefsels niet sterk tot expressie – zodat de ruis onder 1 RPKM kan overheersen als je alleen de ruwe RPKMs uitzet. Ondertussen is genexpressie iets dat je op een log-schaal moet bekijken, aangezien genen in een weefsel kunnen variëren van <1 RPKM tot >10.000 RPKM, dus als je alles op een lineaire schaal bekijkt, dan kunnen de paar echt hoog tot expressie komende gen/weefsel-combinaties ook domineren, waardoor de matrix er nog kariger uitziet dan hij is. Daarom heb ik log10 van de matrix genomen en de verdeling afgekapt op , dus de paarse schaal die ik gebruikte loopt van 1 – 10 – 100 – 1,000 – 10,000 RPKM. Vervolgens heb ik een subset gemaakt van de Uniprot GPI-geankerde eiwitten. Om dit te visualiseren, heb ik voor de eerste keer in mijn leven een heatmap gemaakt. Ik heb deze vaak gezien in papers en ze spreken me meestal niet aan, maar hier was mijn doel gewoon om een idee te krijgen van het expressiepatroon, en na een beetje spelen, gaf dit me het meeste inzicht. Het principe van een heatmap is dat de rijen en kolommen zo geclusterd zijn dat gelijksoortige dingen bij elkaar staan. Dus, bijvoorbeeld, alle hersenweefsel kolommen worden op een rij gezet in een gebied op de x-as, en alle genen met een hoge hersen-expressie worden op een rij gezet in een gebied op de y-as, zodat hun kruising een dichte paarse rechthoek vormt die kan worden geïnterpreteerd als, “er bestaat een cluster van genen die voornamelijk tot hersen-expressie komen”.
Interesseerde lezers kunnen de vector art PDF op ware grootte van de heatmap bekijken, maar om het directer toegankelijk te maken, is hier een met de hand geannoteerde versie waarin de clusters van belang worden genoemd:

Het antwoord is dus nee – de meeste GPI-geankerde eiwitten hebben niet hetzelfde expressiepatroon als PRNP heeft. PRNP is een van de weinige eiwitten die het meest tot expressie komen en staat bovenaan deze heatmap, samen met CD59, LY6E, GPC1 en BST2. De meeste GPI-geankerde eiwitten hebben een lagere of meer weefsel-beperkte expressie, met sommige bijna uniek tot expressie gebracht in de hersenen en andere bijna uniek niet tot expressie gebracht in de hersenen, en andere kleinere clusters die voornamelijk behoren tot specifieke weefsels zoals de testes, zoals PrP’s paralogus PRND, waarvan knock-out mannelijke steriliteit veroorzaakt .
conclusies
GPI-geankerde eiwitten kunnen zowat elke grootte hebben, tot expressie komen in zowat elk weefsel, en blijkbaar zowat elke functie hebben, voor zover hun functies bekend zijn. Veel GPI-geankerde eiwitten hebben zeer duidelijke natieve functies, maar deze functies zijn divers en het is niet duidelijk waarom zij GPI-verankering vereisen, vooral omdat veel van deze eiwitten ook in niet-GPI-geankerde isovormen bestaan. Voor andere GPI-geankerde eiwitten, waaronder PrP, weten we nog maar weinig over de natieve functie, zodat het moeilijk is om zelfs maar te speculeren waarom de natieve functie GPI-verankering vereist. Geen van de analyses die ik heb uitgevoerd of de reviews die ik heb gelezen, hebben een eenduidig principe kunnen opleveren over het bestaan van dit verankeringsmechanisme of over de vraag waarom deze eiwitten dit nodig hebben. Er zijn een aantal hypotheses over waarom GPI-geankerde eiwitten uniek zijn, zoals lipid rafts, homodimeren en afschuiving. Al deze hypotheses kunnen steek houden. Maar aan het eind van de dag lijkt het onwaarschijnlijk dat het antwoord een eureka-moment is, maar eerder, zoals zo veel in de biologie, een prozaïsche mix van verschillende dingen.
R-code en ruwe gegevensbestanden voor analyses in dit bericht zijn hier.