Door: Derek Colley | Bijgewerkt: 2014-01-29 | Comments (5) | Related: Meer > Functies – Systeem
Probleem
U bent op zoek naar een willekeurige steekproef uit een SQL Server-queryresultatenreeks. Misschien bent u op zoek naar een representatieve steekproef van gegevens uit een grote klantendatabase; misschien bent u op zoek naar enkele gemiddelden, of een idee van het type gegevens dat u bezit. SELECT TOP N is niet altijd ideaal, aangezien gegevensuitschieters vaak aan het begin en het einde van gegevensreeksen voorkomen, vooral wanneer ze alfabetisch of volgens een scalaire waarde zijn geordend. U hebt misschien ook TABLESAMPLE gebruikt, maar dat heeft beperkingen, vooral met kleine of scheve gegevensreeksen. Misschien heeft uw baas u gevraagd om een willekeurige selectie van 100 klantnamen en locaties; of u neemt deel aan een audit en moet een willekeurige steekproef van gegevens ophalen voor analyse. Hoe zou u deze taak uitvoeren? Bekijk deze tip voor meer informatie.
Oplossing
Deze tip laat zien hoe u TABLESAMPLE in T-SQL kunt gebruiken om pseudo-willekeurige gegevensmonsters op te halen, en gaat in op de interne aspecten van TABLESAMPLE en waar het niet geschikt is. We zullen ook een alternatieve methode laten zien – een wiskundige methode die NEWID() gebruikt in combinatie met CHECKSUM en een bitwise operator, opgemerkt door Microsoft in het TABLESAMPLE TechNet artikel. We zullen het hebben over statistische steekproeftrekking in het algemeen (de verschillen tussen willekeurig, systematisch en gestratificeerd) met voorbeelden, en we zullen een kijkje nemen naar hoe SQL statistieken worden bemonsterd als een voorbeeld, en de opties die we kunnen gebruiken om deze steekproeftrekking op te heffen. Na het lezen van deze tip zou u een appreciatie moeten hebben van de voordelen van sampling boven het gebruik van methodes zoals TOP N en weten hoe u minstens één methode moet toepassen om dit in SQL Server te bereiken.
Setup
Voor deze tip zal ik een data set gebruiken die een identiteit INT kolom bevat (om de mate van willekeurigheid vast te stellen bij het selecteren van rijen) en andere kolommen gevuld met pseudo-willekeurige data van verschillende datatypes, om (vaag) echte data in een tabel na te bootsen. U kunt de onderstaande T-SQL code gebruiken om dit op te zetten. Het duurt slechts een paar minuten om te draaien en is getest op SQL Server 2012 Developer Edition.
Het selecteren van de bovenste 10 rijen gegevens levert dit resultaat op (om u een idee te geven van de vorm van de gegevens).Terzijde: dit is een algemeen stukje code dat ik heb gemaakt om willekeurige gegevens te genereren wanneer ik die nodig had – voel je vrij om het te gebruiken en het naar hartelust uit te breiden/plunderen!
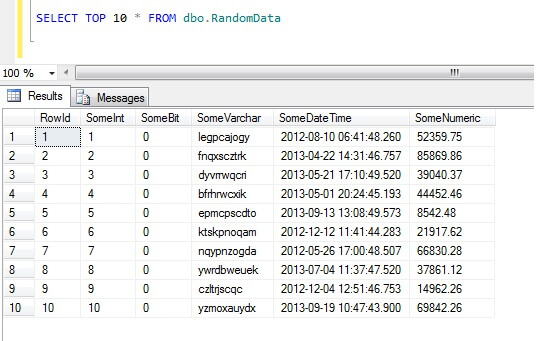
Hoe geen gegevensmonsters te nemen in SQL Server
Nu we onze gegevensmonsters hebben, laten we eens kijken naar de slechtste manieren om een monster te krijgen. In de AdventureWorks database, bestaat er een tabel genaamd Person.Address. Laten we een steekproef nemen van de top 10 resultaten, in willekeurige volgorde:
SELECT TOP 10 * FROM Person.Address
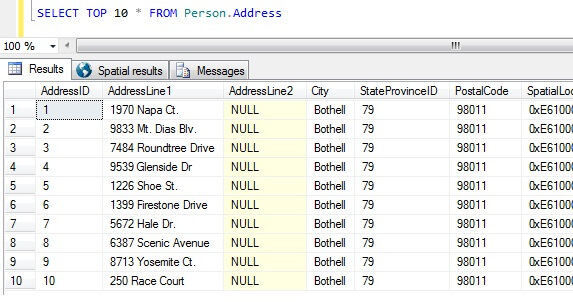
Uitsgaande van deze steekproef alleen al, kunnen we zien dat alle geretourneerde personen in Bothell wonen en postcode 98011 hebben. Dit komt omdat de resultaten niet in een bepaalde volgorde zouden worden teruggestuurd, maar wel in de volgorde van de kolom AddressID. Merk op dat dit GEEN gegarandeerd gedrag is voor heap gegevens in het bijzonder – zie dit citaat van BOL:
“Gewoonlijk worden gegevens aanvankelijk opgeslagen in de volgorde waarin de rijen in de tabel worden ingevoegd, maar de Database Engine kan gegevens in de heap verplaatsen om de rijen efficiënt op te slaan; de volgorde van de gegevens kan dus niet worden voorspeld. Om de volgorde van de rijen die uit een heap worden teruggestuurd te garanderen, moet u de ORDER BY-clausule gebruiken.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Uitsgaande van deze resultatenverzameling zou iemand die niet op de hoogte is van de aard van de tabel, kunnen concluderen dat al hun klanten in Bothell wonen.
Types of Data Sampling in SQL Server
Het bovenstaande is duidelijk onjuist, dus we hebben een betere manier van bemonsteren nodig. Hoe zit het met het nemen van een steekproef op regelmatige intervallen in de tabel?
Dit zou 47 rijen moeten opleveren:
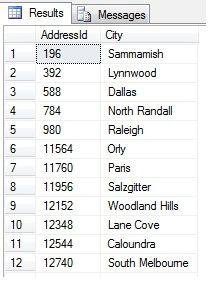
Zo ver, zo goed. We hebben een rij genomen op regelmatige intervallen in onze gegevensverzameling en een statistische doorsnede teruggegeven – of niet? Niet noodzakelijk. Vergeet niet, de volgorde is niet gegarandeerd. We kunnen een of twee conclusies trekken uit deze gegevens. Laten we ze samenvoegen om ze te illustreren. Voer het bovenstaande codefragment opnieuw uit, maar verander het laatste SELECT-blok als volgt:
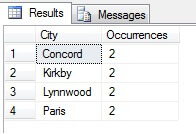
U kunt in mijn voorbeeld zien dat ik uit een totale telling van meer dan 19.000 rijen in de tabel Person.Address, ongeveer 1/4% van de rijen heb bemonsterd en daarom kan ik concluderen dat (in mijn voorbeeld) Concord, Kirkby, Lynnwood en Paris het grootste aantal inwoners hebben en bovendien even bevolkt zijn. Nauwkeurig? Onzin, natuurlijk:
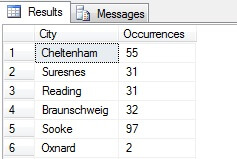
Zoals u ziet, behoorde geen van mijn vier plaatsen daadwerkelijk tot de top vier van plaatsen om te wonen, zoals beoordeeld in deze tabel. Niet alleen waren de steekproefgegevens te klein, maar ik heb deze kleine steekproef samengevoegd en geprobeerd er een conclusie uit te trekken. Dit betekent dat mijn resultaten statistisch niet significant zijn -aantonen van statistische significantie is een van de belangrijkste bewijslasten bij het presenteren van statistische overzichten (of zou dat moeten zijn) en een belangrijke ondergang van veel populaire infographics en marketing-gestuurde datagrammen.
Dus, steekproeftrekking op deze manier (systematische steekproeftrekking genoemd) is effectief, maar alleen voor een statistisch significante populatie. Er zijn factoren zoals periodiciteit en proportie die een steekproef kunnen ruïneren – laten we proportie in actie zien door een steekproef van 10 steden uit de tabel Person.Address te nemen, met behulp van de volgende code, die een afzonderlijke lijst met steden uit de tabel Person.Address haalt, en vervolgens 10 steden uit die lijst selecteert met behulp van systematische steekproeven:
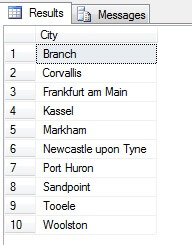
Lijkt een goede steekproef, toch? Laten we dit nu eens vergelijken met een steekproef van NIET-distinctieve steden in oplopende volgorde, d.w.z. elke n-de stad, waarbij n het totale aantal rijen is, gedeeld door 10. Deze maatstaf houdt rekening met de steekproefpopulatie:
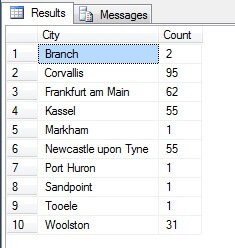
De teruggekeerde gegevens zijn totaal verschillend – niet door toeval, maar door de presentatie van een representatieve steekproef. Merk op dat deze lijst, waarop ik de tellingen van elke stad in de brontabel heb opgenomen om aan te geven hoezeer de bevolking een rol speelt bij de selectie van de gegevens, de top vier van de dichtstbevolkte steden in de steekproef omvat, wat (als je een geordende niet-onderscheidende lijst beschouwt) de eerlijkste vertegenwoordiging is. Het is niet noodzakelijkerwijs de beste representatie voor uw behoeften, dus wees voorzichtig bij het kiezen van uw statistische steekproefmethode.
Andere steekproefmethoden
Clusterbemonstering – hierbij wordt de te bemonsteren populatie verdeeld in clusters, of deelverzamelingen, en vervolgens wordt van elk van deze deelverzamelingen willekeurig bepaald of ze al dan niet in de outputresultaatverzameling worden opgenomen. Indien opgenomen, wordt elk lid van die deelverzameling teruggegeven in de resultatenverzameling. Zie TABELSAMPLE hieronder voor een voorbeeld hiervan.
Disproportionele steekproeftrekking – dit lijkt op gestratificeerde steekproeftrekking, waarbij leden van subgroepen worden geselecteerd om de hele groep te vertegenwoordigen, maar in plaats van proportioneel, kunnen er verschillende aantallen leden van elke groep worden geselecteerd om de vertegenwoordiging van elke groep gelijk te maken. Bv. gegeven de steden in Person.Address in het voorbeeld uit de bovenstaande paragraaf, was de eerste resultatenverzameling onevenredig omdat ze geen rekening hield met de bevolking, maar de tweede resultatenverzameling was evenredig omdat ze het aantal steden in de Person.Address-tabel vertegenwoordigde. Dit soort steekproeven is in feite nuttig als een bepaalde categorie ondervertegenwoordigd is in de gegevensverzameling, en proportie niet belangrijk is (bijvoorbeeld, 100 willekeurige klanten uit 100 willekeurige steden gestratificeerd per stad – de steden in de subset zouden moeten worden genormaliseerd – onevenredige steekproeven zouden kunnen worden gebruikt).
SQL Server Willekeurige Gegevens met TABLESAMPLE
QL Server wordt geleverd met een handige methode om gegevens te steekproeven. Laten we het eens in actie zien. Gebruik de volgende code om ongeveer 100 rijen te retourneren (als het 0 rijen retourneert, voer het dan opnieuw uit – ik leg het zo uit) met gegevens uit dbo.RandomData die we eerder hebben gedefinieerd.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
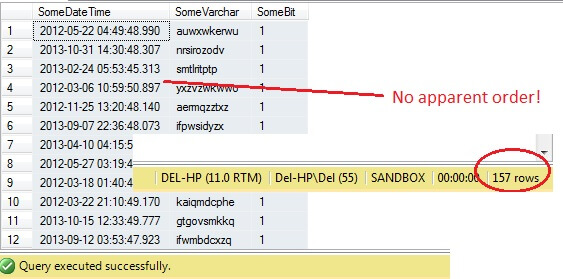
Zo ver, zo goed, toch? Wacht even – we kunnen de Id-kolom niet zien. Laten we dit opnemen en opnieuw uitvoeren:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
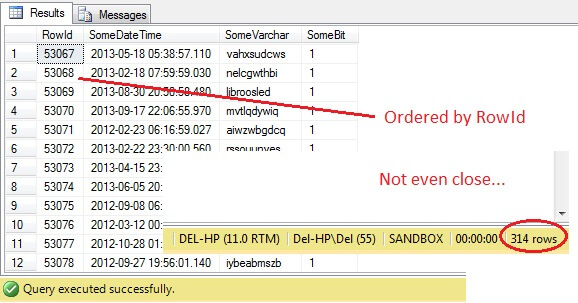
Oh jee – TABLESAMPLE heeft een stuk gegevens geselecteerd, maar het is niet willekeurig – de RowId laat een duidelijk afgebakend stuk zien met een minimum- en een maximumwaarde. Wat meer is, het heeft ook niet precies 100 rijen teruggegeven. Wat is er aan de hand?
TABLESAMPLE gebruikt de impliciete SYSTEM modifier. Deze modifier, standaard ingeschakeld en een ANSI-SQL specificatie, d.w.z. niet optioneel, neemt elke 8KB pagina waar de tabel zich op bevindt en beslist of alle rijen op die pagina die zich in die tabel bevinden al dan niet worden opgenomen in het geproduceerde monster, op basis van het percentage of N ROWS dat wordt doorgegeven. Vandaar dat een tabel die op veel pagina’s staat, d.w.z. grote gegevensrijen heeft, een meer gerandomiseerde steekproef zou moeten opleveren, omdat er meer pagina’s in de steekproef zullen zijn. Het werkt niet voor een voorbeeld als het onze, waar de gegevens scalair en klein zijn en zich op slechts een paar pagina’s bevinden – als een aantal pagina’s de cut niet haalt, kan dit de output steekproef aanzienlijk vertekenen. Dit is het nadeel van TABLESAMPLE – het werkt niet goed voor “kleine” gegevens en het houdt geen rekening met de verdeling van de gegevens over de pagina’s. Dus de rangschikking van de gegevens op de pagina’s is uiteindelijk verantwoordelijk voor de steekproef die door deze methode wordt geretourneerd.
Klinkt dit bekend? Het is in wezen clusterbemonstering, waarbij alle leden (rijen) in de geselecteerde groepen (clusters) in de resultatenset vertegenwoordigd zijn.
Laten we het eens testen op een grote tabel om het punt van omgekeerde niet-schaalbaarheid te benadrukken. Laten we eerst de grootste tabel in de AdventureWorks database identificeren. We gebruiken hiervoor een standaard rapport – gebruik SSMS, rechtsklik op de AdventureWorks2012 database, ga naar Rapporten -> Standaardrapporten -> Schijfgebruik door Hoofdtabellen. Sorteer op Data(KB) door op de kolomkop te klikken (misschien wilt u dit twee keer doen voor een aflopende volgorde). U ziet het onderstaande rapport.
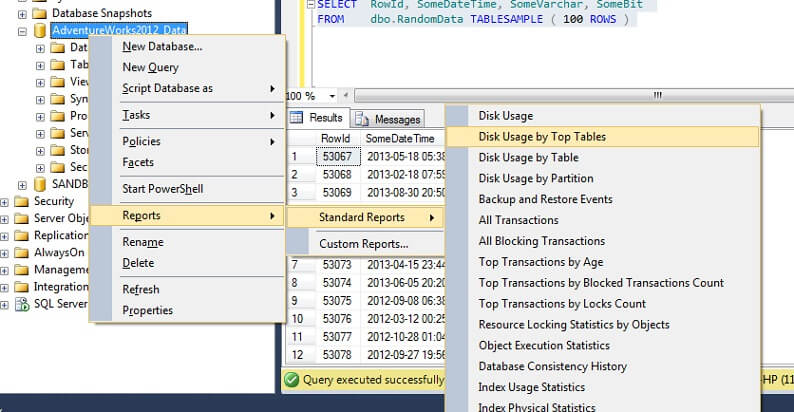
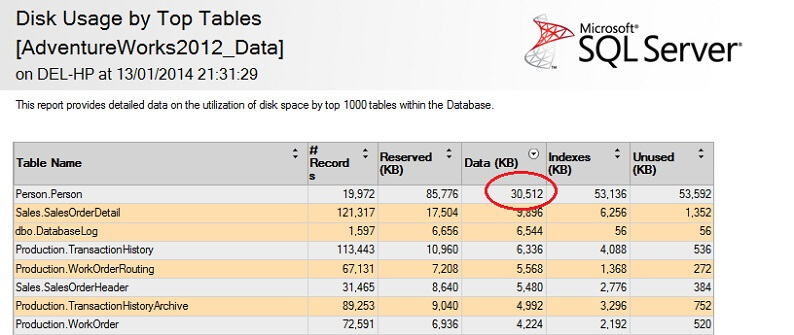
Ik heb het interessante cijfer omcirkeld – de tabel Person. Person tabel verbruikt 30.5MB aan gegevens en is de grootste tabel (volgens gegevens, niet volgens aantal records). Laten we eens proberen een voorbeeld te nemen uit deze tabel:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
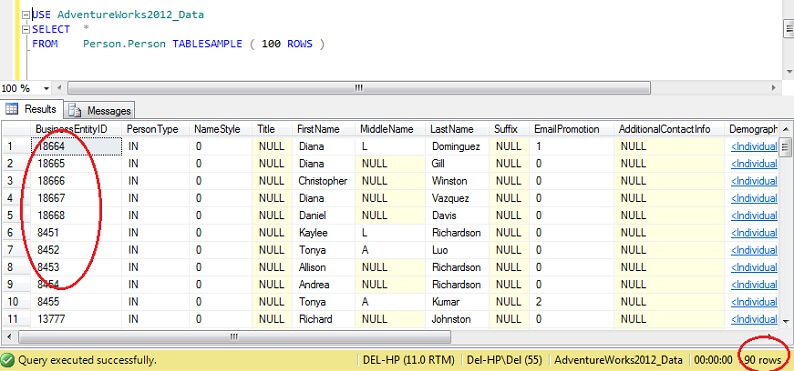
Je ziet dat we veel dichter bij de 100 rijen zitten, maar van cruciaal belang is dat er niet veel clustering lijkt te zijn op de primaire sleutel (hoewel er wel wat is, aangezien er meer dan 1 rij per pagina is).
Dientengevolge is TABLESAMPLE goed voor grote gegevens, en wordt catastrofaal slechter naarmate de dataset kleiner is. Dit is niet goed voor ons wanneer we steekproeven nemen uit gestratificeerde gegevens of geclusterde gegevens, waar we veel steekproeven nemen uit kleine groepen of deelverzamelingen van gegevens en die dan samenvoegen. Laten we eens kijken naar een alternatieve methode.
Random SQL Server Data met ORDER BY NEWID()
Hier volgt een citaat van BOL over het verkrijgen van een echt willekeurig monster:
“Als u echt een willekeurig monster van individuele rijen wilt, pas dan uw query aan om rijen willekeurig te filteren, in plaats van TABLESAMPLE te gebruiken. De volgende query gebruikt bijvoorbeeld de NEWID-functie om ongeveer één procent van de rijen van de tabel Sales.SalesOrderDetail terug te geven:
Hoe werkt dit? Laten we de WHERE-clausule eruit halen en deze uitleggen.
De CHECKSUM-functie berekent een controlesom over de items in de lijst. Het is betwistbaar of SalesOrderID zelfs nodig is, aangezien NEWID() een functie is die een nieuwe willekeurige GUID teruggeeft, dus het vermenigvuldigen van een willekeurig getal met een constante zou hoe dan ook een willekeurige moeten opleveren.Inderdaad, het uitsluiten van SalesOrderID lijkt geen verschil te maken. Als u een fervent statisticus bent en kunt rechtvaardigen dat dit wordt meegerekend, gebruik dan de commentaarsectie hieronder en laat me weten waarom ik het mis heb!
De CHECKSUM functie retourneert een VARBINARY. Het uitvoeren van een bitwise AND bewerking met 0x7fffffff, wat het equivalent is van (111111111…) in binair, levert een decimale waarde op die in feite een representatie is van een willekeurige reeks van 0-en en 1-en. Gedeeld door de coëfficiënt 0x7fffffff normaliseert dit decimale getal in feite tot een getal tussen 0 en 1. Om vervolgens te beslissen of elke rij in de uiteindelijke resultatenverzameling moet worden opgenomen, wordt een drempel van 1/x gebruikt (in dit geval 0,01), waarbij x het percentage van de gegevens is dat als steekproef moet worden genomen.
Wees er op bedacht dat deze methode een vorm van aselecte steekproeftrekking is in plaats van systematische steekproeftrekking, zodat u waarschijnlijk gegevens uit alle delen van uw brongegevens zult krijgen, maar de sleutel hier is dat u *misschien* niet krijgt. De aard van aselecte steekproeftrekking houdt in dat elke steekproef die u verzamelt een vertekend beeld kan geven van één segment van uw gegevens, dus om te profiteren van regressie naar het gemiddelde (tendens naar een willekeurig resultaat, in dit geval) moet u ervoor zorgen dat u meerdere steekproeven neemt en een selectie maakt uit een deelverzameling daarvan, als uw resultaten er scheef uitzien. U kunt ook steekproeven nemen uit deelverzamelingen van uw gegevens en deze samenvoegen – dit is een ander type steekproeftrekking, genaamd gestratificeerde steekproeftrekking.
Hoe worden SQL Server-statistieken bemonsterd?
In SQL Server vindt automatische bijwerking van kolom- of door de gebruiker gedefinieerde statistieken plaats wanneer een ingestelde drempel van tabelrijen voor een bepaalde tabel wordt gewijzigd. Voor 2012 wordt deze drempel berekend op SQRT(1000 * TR) waarbij TR het aantal tabelrijen in de tabel is. Vóór 2005, zal de automatische update van de statistiek job afgaan voor elke (500 rijen + 20% verandering) van tabel rijen. Zodra het automatische bijwerkingsproces begint, zal de bemonstering *het aantal bemonsterde rijen verminderen naarmate de tabel groter wordt*, met andere woorden, er is een relatie die lijkt op omgekeerd evenredig tussen het percentage tabelbemonstering en de grootte van de tabel, maar volgt een eigen algoritme.
Interessant is dat dit het tegenovergestelde lijkt te zijn van de TABELSAMPLE (N PERCENT) optie, waar het aantal bemonsterde rijen in normale verhouding staat tot het aantal rijen in de tabel. We kunnen automatische statistieken uitschakelen (wees hier voorzichtig mee) en statistieken handmatig bijwerken – dit wordt bereikt door NORECOMPUTE te gebruiken op het UPDATE STATISTICS statement. Met UPDATE STATISTICS kunnen we sommige opties opheffen – we kunnen bijvoorbeeld kiezen om N rijen te bemonsteren, of N procent (vergelijkbaar met TABLESAMPLE), een FULLSCAN uit te voeren, of gewoon RESAMPLE met het laatst bekende percentage.
Volgende stappen
Voor verder lezen, Joseph Sack is een Microsoft MVP bekend om zijn werk in de statistische analyse van SQL Server – zie hieronder voor een aantal links naar zijn werk, samen met een aantal verwijzingen naar werk gebruikt voor dit artikel en naar een aantal gerelateerde tips van MSSQLTips.com. Bedankt voor het lezen!
Last Bijgewerkt: 2014-01-29


Over de auteur
 Derek Colley is een in het Verenigd Koninkrijk gevestigde DBA en BI Developer met meer dan een decennium ervaring in het werken met SQL Server, Oracle en MySQL.
Derek Colley is een in het Verenigd Koninkrijk gevestigde DBA en BI Developer met meer dan een decennium ervaring in het werken met SQL Server, Oracle en MySQL.Bekijk al mijn tips
- Meer tips voor database-ontwikkelaars…