Er zijn veel grote voordelen verbonden aan het virtualiseren van uw infrastructuur en het uitvoeren van virtuele resources voor bedrijfskritische workloads. In het geval van VMware vSphere biedt het veel opmerkelijke functies en mogelijkheden die hoge beschikbaarheid in de omgeving bieden, evenals geautomatiseerde planning van werklasten om te zorgen voor het meest efficiënte gebruik van hardware en resources in uw vSphere-omgeving.
In dit bericht zullen we het hebben over twee van de kernfuncties op clusterniveau van vSphere in de onderneming – vSphere HA en DRS. Je hebt waarschijnlijk gezien dat naar beide verwezen wordt samen met het draaien van vSphere in de onderneming.
Wat zijn vSphere HA en DRS? Wat doen ze?
Hoe profiteert u van het draaien van beide in uw vSphere-omgeving?
Laten we eens kijken naar een basisintroductie van HA en DRS in VMware vSphere en zien hoe ze zich verhouden en wat de voordelen zijn van het gebruik ervan.
VMware vSphere Clusters
Een van de voor de hand liggende voordelen en best practices bij het gebruik van VMware vSphere voor het uitvoeren van bedrijfskritische workloads is het uitvoeren van een vSphere Cluster.
Wat is een vSphere Cluster?
Een vSphere cluster is een configuratie van meer dan één VMware ESXi-server die wordt samengevoegd als een pool van resources die worden bijgedragen aan het vSphere cluster. Resources zoals CPU compute, geheugen, en in het geval van software-defined storage zoals vSAN, storage, worden bijgedragen door elke ESXi host.
Waarom is het belangrijk om uw bedrijfskritische werklasten bovenop een vSphere-cluster uit te voeren?
Wanneer u nadenkt over de voordelen van het uitvoeren van een hypervisor, kunt u meer dan één server uitvoeren bovenop een enkele set fysieke hardware. Het op deze manier virtualiseren van workloads biedt vele efficiencyvoordelen in ordes van grootte in vergelijking met het draaien van een enkele server op een enkele set fysieke hardware.
Dit kan echter ook de achilleshiel van een gevirtualiseerde oplossing worden, aangezien de impact van een hardwarestoring veel meer bedrijfskritische diensten en toepassingen kan treffen. U kunt zich voorstellen dat als u slechts één VMware ESXi-host hebt waarop veel VM’s draaien, de impact van het verlies van die ene ESXi-host immens zou zijn.
Dit is waar het draaien van meerdere VMware ESXi hosts in een vSphere Cluster echt uitblinkt.
Hoe dan ook, u kunt zich afvragen hoe het draaien van meerdere hosts in een cluster uw high-availability kan verbeteren? Hoe “weet” een host in het vSphere Cluster of een andere host is uitgevallen? Is er een speciaal mechanisme dat wordt gebruikt om te zorgen voor het beheer van de hoge beschikbaarheid van werklasten die op een vSphere Cluster draaien? Ja, dat is er.
Wat is HA in VMware?
VMware realiseerde zich dat er behoefte was aan een mechanisme om bescherming te kunnen bieden tegen een falende ESXi-host in het vSphere Cluster. Met deze behoefte werd VMware High-Availability (HA) geboren.
VMware vSphere HA biedt de volgende voordelen:
VMware vSphere HA is kosteneffectief en maakt geautomatiseerde herstarts van VM’s en vSphere-hosts mogelijk wanneer er een serverstoring of een storing in het besturingssysteem wordt gedetecteerd in de vSphere-omgeving
Bewaakt alle VMware vSphere-hosts & VM’s in de vSphere-cluster
Levert hoge beschikbaarheid voor de meeste toepassingen die in virtuele machines worden uitgevoerd, ongeacht het besturingssysteem en de toepassingen.
Het mooie van VMware’s vSphere HA-oplossing die wordt geïmplementeerd via het VMware Cluster, is de eenvoud waarmee deze kan worden geconfigureerd. Met een paar klikken via een wizard-gestuurde interface kan high-availability worden geconfigureerd. Hoe verhoudt zich dit tot traditionele “clustering” technologieën?
Windows Server Failover Clustering Vergelijking
Windows Server Failover Clustering (WSFC) is de clustering technologie geworden waar de meesten aan denken als ze clustering technologie in gedachten hebben. Het probleem met WSFC is dat het veel specialistische expertise vereist om WSFC-diensten correct uit te voeren, vooral als het gaat om upgrades, patches en algemene operationele taken.
In vergelijking met vSphere HA en WSFC is de operationele overhead minimaal. Er is weinig kans dat HA verkeerd wordt geconfigureerd, omdat het ofwel is ingeschakeld op een cluster of niet. Met WSFC zijn er veel overwegingen die gemaakt moeten worden bij het configureren van WSFC om zowel configuratie- als implementatiefouten te voorkomen. Denk aan het volgende:
- Failover clustering vereist toepassingen die clustering ondersteunen (SQL, enz.)
- Failover clustering vereist dat quorum correct is geconfigureerd
- Niet ondersteund door veel legacy besturingssystemen en toepassingen
- Veist complexiteit van clusternetwerknamen, bronnen en netwerken
Windows Server Failover Clustering wordt geadverteerd om bijna nul-downtime te bieden op toepassingsniveau. Echter, wanneer u de expertise toevoegt die nodig is voor een goed functionerende HA oplossing, samen met de juiste implementatie van WSFC, kunnen de risico’s beginnen op te wegen tegen de voordelen van het gebruik van WSFC voor hoge beschikbaarheid van applicaties en diensten. Dit geldt vooral voor de meeste organisaties die misschien niet echt een “zero downtime” oplossing nodig hebben. Bovendien moet uw applicatie worden ontworpen om te profiteren van WSFC en goed te werken met WSFC-technologie.
Wile vSphere HA vereist een herstart van de virtuele machines op een gezonde host wanneer een failover optreedt, het vereist geen installatie van extra software in de gast virtuele machines, geen complexe configuraties van extra clustering technologieën, en toepassingen of OS’s hoeven niet te worden ontworpen om te werken met bepaalde clustering technologie.
Legacy besturingssystemen en applicaties hebben over het algemeen beperkte mogelijkheden als het gaat om ondersteunde technologieën om high-availability te bieden. Er kunnen dus letterlijk geen native opties zijn om failover-functionaliteit te bieden in het geval van hardwarestoringen.
Het vSphere HA-mechanisme voor hoge beschikbaarheid werkt en is eenvoudig te implementeren, configureren en beheren. Bovendien is dit een technologie die goed is getest in duizenden VMware-klantomgevingen, dus het heeft een stabiele en lange geschiedenis van succesvolle implementaties.
Algemeen overzicht van vSphere HA-gedrag
Door gebruik te maken van de voordelen die worden geboden aan de ESXi-hosts in een vSphere Cluster, implementeert vSphere HA in zijn meest basale vorm een bewakingsmechanisme tussen de hosts in het vSphere Cluster. Het bewakingsmechanisme biedt een manier om te bepalen of een host in de vSphere Cluster is uitgevallen.
In de onderstaande infographic heeft een vSphere Cluster met twee knooppunten te maken gehad met een storing van een van de ESXi-hosts in het vSphere Cluster. Voor het vSphere Cluster is vSphere HA ingeschakeld op clusterniveau.
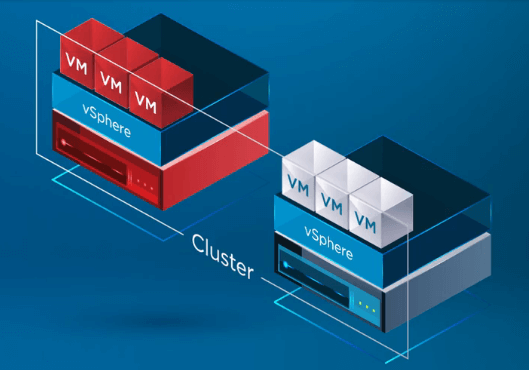
Nadat vSphere HA heeft vastgesteld dat een host in het vSphere Cluster is uitgevallen, verplaatst het HA-proces de registratie van VM’s van de defecte host naar een gezonde host.
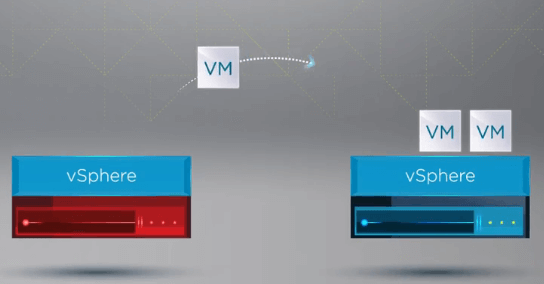
Nadat de VM’s zijn geregistreerd op een gezonde host, start vSphere HA alle VM’s van de gefaalde host opnieuw op een gezonde ESXi-host in het cluster waar de VM’s opnieuw zijn geregistreerd. De enige downtime die optreedt, is de herstart van de VM’s op een gezonde host in het vSphere-cluster.
VSphere HA Technical Overview
Voorwaarde voor vSphere HA
U vraagt zich wellicht af welke onderliggende vereisten nodig zijn om vSphere HA te laten werken. Heb je alleen een VMware Cluster nodig om HA mogelijk te maken? In tegenstelling tot Windows Server Failover Clustering, zijn er maar een paar vereisten die aanwezig moeten zijn om HA te laten werken.
Eisen:
- Minimaal twee ESXi-hosts
- Minimaal 4 GB geheugen geconfigureerd op elke host
- vCenter Server
- vSphere Standard License
- Gedeelde opslag voor VM’s
- Pingable gateway of een ander betrouwbaar netwerkknooppunt
Als u merkt, er is geen quorum component nodig, geen complexe netwerk naamgeving, en geen andere speciale cluster resources die op hun plaats moeten zijn.
Lees meer: Hoe configureert u een vSphere High Availability Cluster
VMware vSphere HA Master vs Subordinate Hosts
Wanneer u vSphere HA op een cluster inschakelt, wordt een bepaalde host in het vSphere Cluster aangewezen als de master van vSphere HA. De overige ESXi-hosts in het vSphere Cluster worden geconfigureerd als ondergeschikten in de vSphere HA-configuratie.
Welke rol speelt de vSphere HA ESXi host die is aangewezen als de master? Het vSphere HA-masterknooppunt:
- Waakt over de status van de ondergeschikte slave-hosts – Als de ondergeschikte host uitvalt of onbereikbaar is, identificeert de masterhost welke VM’s opnieuw moeten worden gestart
- Waakt over de stroomstatus van alle VM’s die worden beschermd. Als een VM faalt, zorgt de master vSphere HA node ervoor dat de VM opnieuw wordt gestart. De vSphere HA-master beslist waar de VM opnieuw wordt gestart (welke ESXi-host).
- Houdt alle clusterhosts en VM’s bij die worden beschermd door vSphere HA
- Wordt aangewezen als de bemiddelaar tussen het vSphere-cluster en vCenter Server. De HA-master rapporteert de clustergezondheid aan vCenter en biedt de beheerinterface voor het cluster voor vCenter Server
- Kan zelf VM’s uitvoeren en de status van VM’s bewaken
- Slaat beschermde VM’s op in clusterdatastores
vSphere HA Subordinate Hosts:
- Run virtual machines lokaal
- Monitor the runtime states of the VMs in the vSphere Cluster
- Report state updates to the vSphere HA master
Master Host Election and Master Failure
Hoe wordt de vSphere HA master host geselecteerd? Wanneer vSphere HA is ingeschakeld voor een cluster, nemen alle actieve hosts (geen onderhoudsmodus, etc) deel aan de verkiezing van de master host. Als de gekozen master host faalt, vindt een nieuwe verkiezing plaats waarbij een nieuwe master HA host wordt gekozen om die rol te vervullen.
VMware vSphere HA Cluster Failure Types
In een vSphere HA ingeschakeld cluster, zijn er drie soorten storingen die kunnen optreden om een vSphere HA failover event te triggeren. Deze hoststoringstypen zijn:
- Storing – Een storing is intuïtief wat u denkt. Een host is gestopt met werken in een of andere vorm of manier als gevolg van hardware of andere problemen.
- Isolation – De isolatie van een host gebeurt meestal als gevolg van een netwerkgebeurtenis die een bepaalde host isoleert van de andere hosts in de vSphere HA cluster.
- Partitie – Een partitiegebeurtenis wordt gekenmerkt door een ondergeschikte host die de netwerkconnectiviteit met de masterhost van het vSphere HA-cluster verliest.
Heartbeating, Failure Detection, and Failure Actions
Hoe bepaalt het masterknooppunt of er sprake is van een storing van een bepaalde host?
Er zijn verschillende mechanismen die de master node gebruikt om te bepalen of een host is uitgevallen:
- De master node wisselt elke seconde netwerk heartbeats uit met de andere hosts in het cluster.
- Nadat de netwerk heartbeat is uitgevallen, controleert de master host of er een host liveness check is.
- De host liveness check bepaalt of de ondergeschikte host heartbeats uitwisselt met een van de datastores. Vervolgens stuurt het ICMP pings naar zijn management IP-adressen
- Als directe communicatie met de HA-agent van een ondergeschikte host vanaf de master host niet mogelijk is en de ICMP pings naar het managementadres mislukken, wordt de host als mislukt beschouwd en worden VM’s opnieuw opgestart op een andere host.
- Als blijkt dat de ondergeschikte host heartbeats uitwisselt met de datastore, gaat de master host ervan uit dat de host zich in een netwerkpartitie bevindt of geïsoleerd is van het netwerk. In dit geval controleert de master gewoon de host en de VM’s
- Netwerkisolatie is de gebeurtenis waarbij een ondergeschikte host draait, maar niet langer kan worden gezien vanuit het perspectief van een HA-managementagent op het managementnetwerk. Als een host dit verkeer niet meer ziet, probeert hij de isolatie-adressen van het cluster te pingen. Als deze ping mislukt, verklaart de host dat hij geïsoleerd is van het netwerk
- In dit geval controleert het master knooppunt de VM’s die draaien op de geïsoleerde host. Als de VM’s op de geïsoleerde host worden uitgeschakeld, start de master node de VM’s opnieuw op een andere host
Datastore heartbeating
Zoals hierboven vermeld, is datastore heartbeating een van de metrieken die wordt gebruikt om faaldetectie te bepalen. Wat is dit precies? VMware vCenter selecteert een voorkeursset van datastores voor heartbeating. Vervolgens maakt vSphere HA een directory aan bij de root van elke datastore die wordt gebruikt voor zowel datastore heartbeating als voor het bijhouden van de lijst met beschermde VM’s. Deze directory heeft de naam .vSphere-HA.
Er is een belangrijke opmerking die moet worden onthouden met betrekking tot vSAN-datastores. Een vSAN-datastore kan niet worden gebruikt voor datastore heartbeating. Als u alleen een vSAN datastore beschikbaar heeft, kunnen er geen heartbeat datastores worden gebruikt.
- VM- en applicatiemonitoring
Een andere uiterst krachtige functie van vSphere HA is de mogelijkheid om afzonderlijke virtuele machines te monitoren via VMware Tools en virtuele machines opnieuw op te starten die niet reageren op VMware Tools heartbeats. Application Monitoring kan een VM herstarten als de heartbeats voor een draaiende applicatie niet worden ontvangen.
- VM-monitoring – Met VM-monitoring gebruikt de VM-monitoringservice VMware Tools om te bepalen of elke VM wordt uitgevoerd door te controleren op zowel heartbeats als schijf-I/O die wordt gegenereerd door VMware Tools. Als deze controles mislukken, bepaalt de VM Monitoring-service hoogstwaarschijnlijk dat het gastbesturingssysteem is uitgevallen en wordt de VM opnieuw gestart. De extra schijf-I/O-controle helpt bij het voorkomen van onnodige VM-resets als VM’s of applicaties nog goed functioneren.
Applicatiebewaking – De functie voor applicatiebewaking wordt ingeschakeld door de juiste SDK van een externe softwareleverancier aan te schaffen, waarmee aangepaste heartbeats kunnen worden ingesteld voor de applicaties die door het vSphere HA-proces moeten worden bewaakt. Net als bij het VM-monitoringproces wordt de VM gereset als er geen applicatie-hartslagen meer worden ontvangen.
Beide monitoringfuncties kunnen verder worden geconfigureerd met monitoringgevoeligheid en ook maximale per-VM-resets om te helpen voorkomen dat VM’s herhaaldelijk worden gereset voor software- of vals-positieve fouten.
VMware vSphere HA is een geweldige manier om ervoor te zorgen dat uw vSphere Cluster een zeer veerkrachtige high-availability biedt ter bescherming tegen algemene hoststoringen van ESXi-hosts in uw vSphere Cluster.
Hoe zit het met het zorgen voor efficiënt gebruik van resources in uw vSphere Cluster? Laten we eens kijken naar de volgende vSphere Cluster-bepaling om te helpen zorgen voor efficiënt gebruik van uw vSphere Cluster-bronnen en -capaciteit.
Wat is DRS in VMware?
VMware Distributed Resource Scheduler (DRS) is een zeer krachtige functie bij het uitvoeren van vSphere Clusters. Het biedt scheduling en load balancing binnen een vSphere Cluster. VMware DRS is de functie in vSphere Clusters die ervoor zorgt dat virtuele machines die in uw vSphere-omgeving worden uitgevoerd, worden voorzien van de resources die ze nodig hebben om effectief en efficiënt te werken.
VM’s vallen over het algemeen al vroeg onder DRS, omdat DRS de VM’s vanaf hun eerste inschakeling in een DRS-geactiveerd cluster plaatst op de beste host die is geconfigureerd om de vereiste resources aan de VM te leveren zodra ze worden ingeschakeld. Bovendien streeft DRS ernaar vSphere-clusters vanuit het oogpunt van resourcegebruik in balans te houden.
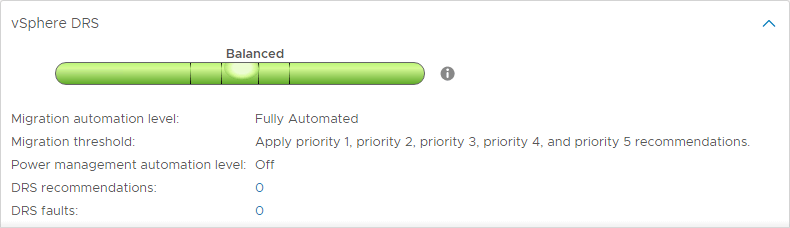
Zelfs als een vSphere-cluster op een bepaald moment in de tijd in balans is, kunnen VM’s worden verplaatst of zodanig veranderen dat een onbalans van clusterresources weer in de omgeving kan binnensluipen. Wanneer clusters uit balans raken, kan dit nadelig zijn voor de algehele prestaties van virtuele machines die in een vSphere Cluster worden uitgevoerd.
Standaard wordt DRS elke vijf minuten automatisch op een vSphere-cluster uitgevoerd om de balans van een vSphere-cluster te bepalen en te zien of er wijzigingen moeten worden aangebracht om de resources effectiever te gebruiken.
VMware DRS-vereisten
Om te kunnen profiteren van VMware DRS, moet aan een aantal vereisten worden voldaan om te kunnen profiteren van de Distributed Resource Scheduler-functionaliteit. Deze omvatten:
- Een cluster van ESXi-hosts
- vCenter Server
- Enterprise Plus License
- vMotion is vereist voor automatische load balancing
Lees meer: Hoe configureert u een vSphere DRS-cluster
VMware DRS-acties
Wanneer VMware DRS elke vijf minuten op een vSphere-cluster wordt uitgevoerd, wordt bepaald of er sprake is van onevenwichtigheden in het cluster. Als dat het geval is, wordt een vMotion uitgevoerd om aangewezen VM’s van de ene ESXi-host naar de andere te verplaatsen.
Hoe bepaalt DRS precies of virtuele machines beter geschikt zijn op de ene ESXi-host of een andere?
DRS voert een speciaal algoritme uit om de juiste ESXi-host te bepalen die een bepaalde VM moet huisvesten. Wanneer een VM wordt ingeschakeld, houdt dit algoritme rekening met de verdeling van de resources over het vSphere-cluster, waarna het ervoor zorgt dat er geen schendingen van restricties zijn als een bepaalde VM op een bepaalde ESXi-host wordt geplaatst.
Daarnaast wordt ook rekening gehouden met de vraag van de VM zelf, zodat de VM hopelijk nooit een tekort aan resources zal hebben wanneer deze wordt ingeschakeld. Wat is inbegrepen in de VM-vraag? De vraag van een VM omvat de hoeveelheid resources die nodig zijn om de VM te laten draaien.
- Voor CPU-vraag wordt dit berekend op basis van de hoeveelheid CPU die de VM op dat moment gebruikt
- Voor geheugen wordt de vraag berekend op basis van de formule: VM geheugenvraag = Functie(Actief gebruikt geheugen, Swapped, Shared) + 25% (idle verbruikt geheugen). Hieruit blijkt dat de DRS-geheugenbalans voornamelijk is gebaseerd op het actieve geheugengebruik van een VM, terwijl een klein deel van het ongebruikte verbruikte geheugen in aanmerking wordt genomen als buffer voor een eventuele toename van de werkbelasting.
DRS Automation Levels
Eén van de interessante eigenschappen van DRS zijn de DRS automation levels. Terwijl DRS doorgaat met het scannen van de vSphere Cluster en elke 5 minuten aanbevelingen doet, kunt u bepalen of DRS al dan niet in staat is om zijn aanbevelingen automatisch uit te voeren of alleen wijzigingen voorstelt die zouden moeten worden doorgevoerd. DRS heeft drie DRS-automatiseringsniveaus. Deze omvatten:
- Volledig geautomatiseerd – Bij de volledig geautomatiseerde aanpak past DRS zowel de aanbevelingen voor initiële plaatsing als voor load balancing automatisch toe
- Gedeeltelijk geautomatiseerd – Bij gedeeltelijke automatisering past DRS alleen aanbevelingen toe voor initiële plaatsing van VM’s
- Handmatig – In de handmatige modus, moet u de aanbevelingen toepassen voor zowel de initiële plaatsing als de aanbevelingen voor load balancing
DRS Migration Thresholds
DRS bevat nog een zeer nuttige instelling om de hoeveelheid onbalans te regelen die wordt getolereerd voordat DRS-aanbevelingen zullen worden gedaan. Er zijn vijf DRS migratie drempels om de hoeveelheid getolereerde onbalans te bepalen.
Het bereik is 1 (meest conservatief) tot 5 (meest agressief).
Met agressievere instellingen tolereert DRS minder onbalans in een cluster. Hoe conservatiever, hoe meer DRS onevenwichtigheid tolereert.

VMware DRS VM/Host-regels
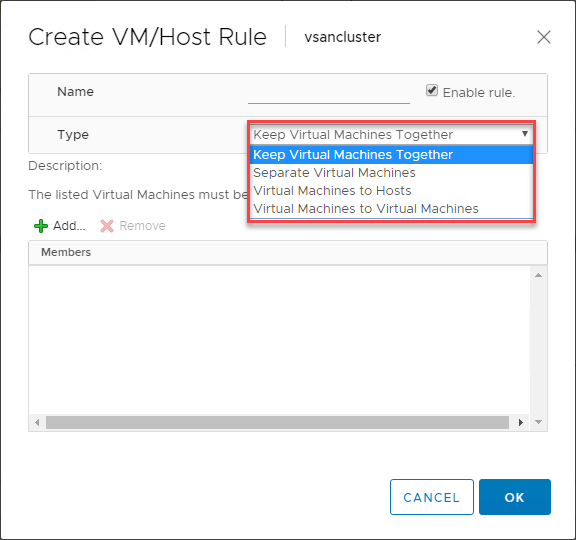
Er is een uiterst nuttige functie beschikbaar wanneer u VMware DRS gebruikt om de plaatsing van VM’s in uw voor vSphere DRS geschikte clusters te regelen. Met de VM/Host Rules kunt u specifieke VM’s op specifieke ESXi-hosts laten draaien. U kunt dit in zekere zin beschouwen als affiniteitsregels.
De VM/Host-regels stellen u in staat:
- Virtuele machines bij elkaar te houden
- Virtuele machines te scheiden
- Virtuele machines aan specifieke hosts te koppelen
- Virtuele machines aan virtuele machines te koppelen
Hieronder ziet u een voorbeeld van het maken van een VM/Host-regel voor virtuele machines en ESXi hosts.
Wat voor soort use-case bestaat er voor deze VM/Host-regels? Een van de klassieke use-cases is die met domain controllers. In het algemeen, als u al uw domeincontrollers in een gevirtualiseerde omgeving zoals een vSphere Cluster uitvoert, wilt u er zeker van zijn dat uw domeincontroller virtuele machines van elkaar gescheiden zijn binnen het cluster. Op deze manier hebt u, als een ESXi-host samen met een van uw domeincontrollers uitvalt, nog steeds een domeincontroller die is onderworpen aan een regel voor afzonderlijke virtuele machines die hem weghoudt van dezelfde host als een ander DC.
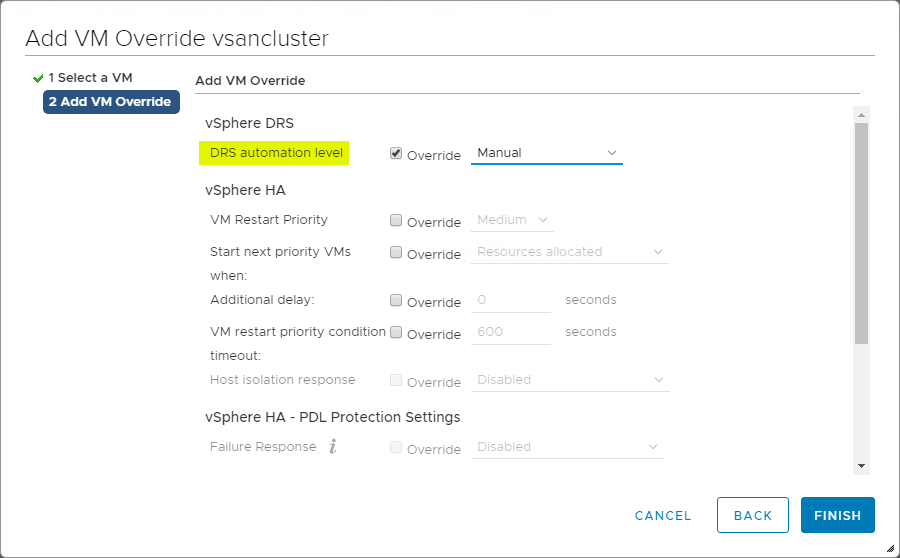
VM-overrides voor DRS
De vSphere Cluster biedt een grote granulariteit voor bewerkingen die van invloed zijn op afzonderlijke VM’s binnen de vSphere Cluster. U kunt VM Overrides maken om globale instellingen die op clusterniveau zijn ingesteld voor HA en DRS te overschrijven om meer specifieke instellingen voor elke afzonderlijke VM te definiëren.
CPU and Memory Utilization Summary
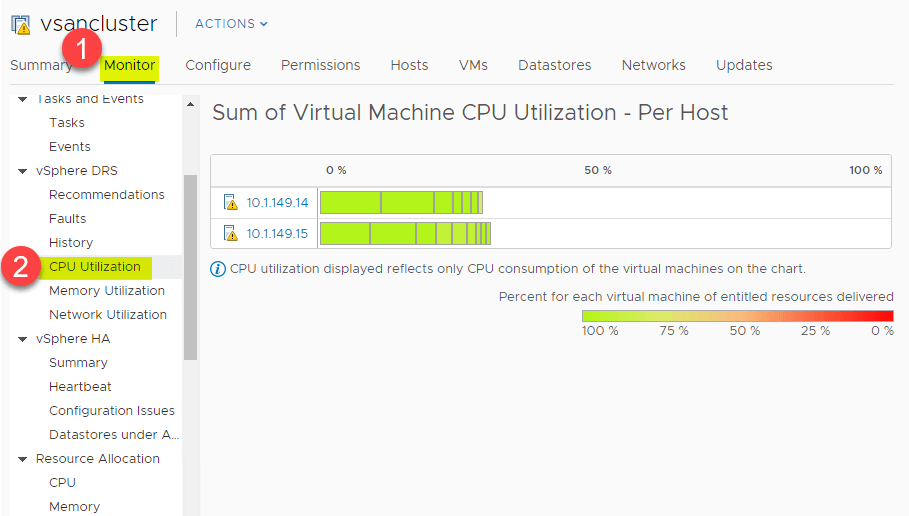
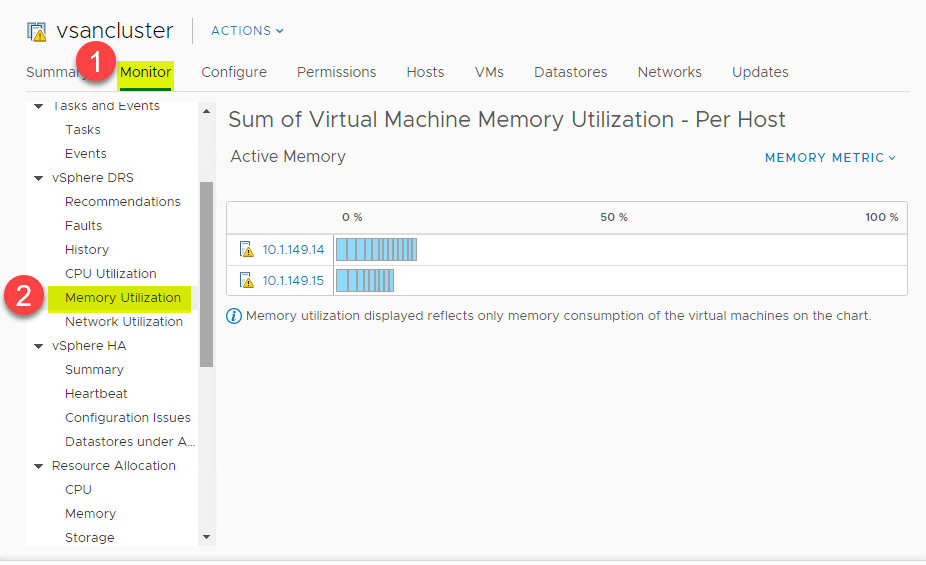
DRS biedt een geweldig overzicht op hoog niveau van het CPU-gebruiksoverzicht van de CPU-bronnen van ESXi-hosts in het vSphere Cluster. Navigeer naar > Instellingen > Monitor > vSphere DRS > CPU-gebruik.
Hetzelfde overzicht op hoog niveau kan ook worden bekeken voor geheugengebruik. Navigeer naar > Instellingen > Monitor > vSphere DRS > Geheugengebruik
Het beste van twee werelden
Is VMware vSphere HA en VMware DRS een concurrerende technologie?
Nee, dat zijn ze niet. Het wordt zelfs ten zeerste aanbevolen om vSphere HA en VMware DRS samen te gebruiken om automatische failover te combineren met functies en functionaliteit voor load balancing. Dit resulteert in een veel veerkrachtigere en evenwichtigere vSphere-omgeving.
Als een ESXi-host uitvalt, start vSphere HA de VM’s opnieuw op de resterende gezonde hosts in een vSphere-cluster. De eerste prioriteit is dus natuurlijk de beschikbaarheid van resources voor virtuele machines. VMware DRS wordt vervolgens uitgevoerd en bepaalt of er sprake is van onbalans tussen de ESXi-hosts waarop de workloads worden uitgevoerd en doet aanbevelingen om eventuele onbalansen in het cluster op te lossen op basis van de geconfigureerde migratiedrempel. Gebaseerd op het automatiseringsniveau, worden deze aanbevelingen automatisch uitgevoerd of alleen aanbevolen als ze niet volledig geautomatiseerd zijn.
Eindgedachten over VMware vSphere HA en DRS
Het uitvoeren van zowel VMware vSphere HA als DRS wordt ten zeerste aanbevolen in een productie-VSphere-cluster. Het gebruik van beide technologieën helpt om uw workloads zeer beschikbaar te maken en zorgt ervoor dat ze continu over de benodigde resources beschikken op basis van de CPU-/geheugenvereisten van de VM.
Inzicht in de werking van beide mechanismen helpt u als vSphere-beheerder om beide technologieën op de best mogelijke manier en in overeenstemming met best practices te benutten. Naast de voordelen die beide technologieën met zich meebrengen, is elke functie uiterst eenvoudig in te schakelen en te configureren. Met een paar eenvoudige klikken in de eigenschappen van uw vSphere Clusters, kunt u snel beginnen te profiteren van deze beschikbare functies op clusterniveau.
Volg onze Twitter- en Facebook-feeds voor nieuwe releases, updates, verhelderende berichten en meer.