Last bijgewerkt op 18 augustus 2020
Datasets kunnen ontbrekende waarden bevatten, en dit kan problemen veroorzaken voor veel machine learning-algoritmen.
Het is daarom een goede gewoonte om ontbrekende waarden voor elke kolom in uw invoergegevens te identificeren en te vervangen voordat u uw voorspellingstaak modelleert. Dit wordt imputatie van ontbrekende gegevens genoemd, of kortweg imputatie.
Een populaire aanpak voor gegevensimputatie is om een statistische waarde voor elke kolom (zoals een gemiddelde) te berekenen en alle ontbrekende waarden voor die kolom te vervangen door de statistiek. Het is een populaire aanpak omdat de statistiek eenvoudig te berekenen is met behulp van de trainingsdataset en omdat het vaak tot goede prestaties leidt.
In deze tutorial ontdekt u hoe u statistische imputatiestrategieën voor ontbrekende gegevens in machine learning kunt gebruiken.
Na het voltooien van deze tutorial weet u:
- Missende waarden moeten worden gemarkeerd met NaN-waarden en kunnen worden vervangen door statistische maten om de kolom met waarden te berekenen.
- Hoe u een CSV-waarde met ontbrekende waarden kunt laden en de ontbrekende waarden met NaN-waarden kunt markeren en het aantal en het percentage ontbrekende waarden voor elke kolom kunt rapporteren.
- Hoe u ontbrekende waarden kunt imputeren met statistieken als een gegevensvoorbereidingsmethode bij het evalueren van modellen en bij het fitten van een definitief model om voorspellingen te doen op nieuwe gegevens.
Kick-start je project met mijn nieuwe boek Data Preparation for Machine Learning, inclusief stap-voor-stap tutorials en de Python broncodebestanden voor alle voorbeelden.
Let’s get started.
- Bijgewerkt juni/2020: De kolom die wordt gebruikt voor voorspellingen in voorbeelden is gewijzigd.

Statistic Imputation for Missing Values in Machine Learning
Foto door Bernal Saborio, sommige rechten voorbehouden.
Tutorial Overview
Deze tutorial is onderverdeeld in drie delen; deze zijn:
- Statistic Imputation
- Horse Colic Dataset
- Statistical Imputation With SimpleImputer
- SimpleImputer Data Transform
- SimpleImputer and Model Evaluation
- Vergelijking van verschillende geïmputeerde statistieken
- SimpleImputer Transform When Making a Prediction
Statistische Imputatie
Een dataset kan ontbrekende waarden hebben.
Dit zijn rijen gegevens waar een of meer waarden of kolommen in die rij niet aanwezig zijn. De waarden kunnen volledig ontbreken of ze kunnen zijn gemarkeerd met een speciaal teken of een speciale waarde, zoals een vraagteken “?”.
Deze waarden kunnen op vele manieren worden uitgedrukt. Ik heb ze zien verschijnen als helemaal niets, een lege string, de expliciete string NULL of undefined of N/A of NaN, en het getal 0, onder andere. Hoe ze ook voorkomen in je dataset, als je weet wat je kunt verwachten en controleert of de gegevens aan die verwachting voldoen, zul je minder problemen ondervinden wanneer je de gegevens gaat gebruiken.
– Pagina 10, Bad Data Handbook, 2012.
Waarden kunnen om allerlei redenen ontbreken, vaak specifiek voor het probleemdomein, en kunnen redenen zijn als corrupte metingen of niet-beschikbaarheid van gegevens.
Ze kunnen om een aantal redenen voorkomen, zoals slecht werkende meetapparatuur, veranderingen in het experimentele ontwerp tijdens het verzamelen van gegevens, en het samenvoegen van verschillende vergelijkbare maar niet identieke datasets.
– Pagina 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
De meeste algoritmen voor machinaal leren vereisen numerieke invoerwaarden, en een waarde die aanwezig moet zijn voor elke rij en kolom in een dataset. Als zodanig kunnen ontbrekende waarden problemen veroorzaken voor machine learning-algoritmen.
Zo is het gebruikelijk om ontbrekende waarden in een dataset te identificeren en ze te vervangen door een numerieke waarde. Dit wordt imputatie van gegevens of imputatie van ontbrekende gegevens genoemd.
Een eenvoudige en populaire benadering van imputatie van gegevens omvat het gebruik van statistische methoden om een waarde voor een kolom te schatten uit de waarden die aanwezig zijn, en vervolgens alle ontbrekende waarden in de kolom te vervangen door de berekende statistiek.
Het is eenvoudig omdat de statistiek snel te berekenen is en het is populair omdat het vaak zeer effectief blijkt.
Gemeenschappelijk berekende statistieken omvatten:
- Het kolomgemiddelde.
- De kolommediane waarde.
- De kolommoduswaarde.
- Een constante waarde.
Nu we bekend zijn met statistische methoden voor imputatie van ontbrekende waarden, laten we eens kijken naar een dataset met ontbrekende waarden.
Wil je aan de slag met gegevensvoorbereiding?
Doe nu mee aan mijn gratis 7-daagse spoedcursus per e-mail (met voorbeeldcode).
Klik om in te schrijven en ontvang ook een gratis PDF Ebook versie van de cursus.
Download Uw GRATIS Mini-Cursus
Dataset voor paardenkoliek
De dataset voor paardenkoliek beschrijft medische kenmerken van paarden met koliek en of ze leefden of stierven.
Er zijn 300 rijen en 26 input variabelen met één output variabele. Het is een binaire classificatievoorspellingstaak waarbij 1 wordt voorspeld als het paard leefde en 2 als het paard stierf.
Er zijn veel velden die we zouden kunnen selecteren om in deze dataset te voorspellen. In dit geval zullen we voorspellen of het probleem chirurgisch was of niet (kolomindex 23), waardoor het een binair classificatieprobleem is.
De dataset heeft talrijke ontbrekende waarden voor veel van de kolommen, waarbij elke ontbrekende waarde is gemarkeerd met een vraagteken (“?”).
Hieronder vindt u een voorbeeld van rijen uit de dataset met gemarkeerde ontbrekende waarden.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
U kunt hier meer over de dataset te weten komen:
- Dataset voor paardenkoliek
- Datasetbeschrijving voor paardenkoliek
U hoeft de dataset niet te downloaden, omdat we deze automatisch downloaden in de uitgewerkte voorbeelden.
Het markeren van ontbrekende waarden met een NaN-waarde (geen getal) in een geladen dataset met behulp van Python is een best practice.
We kunnen de dataset laden met behulp van de read_csv() Pandas-functie en de “na_values” specificeren om waarden van ‘?’ als missing te laden, gemarkeerd met een NaN waarde.
|
1
2
3
4
|
…
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
|
Eenmaal geladen, kunnen we de geladen gegevens bekijken om te bevestigen dat “?” waarden zijn gemarkeerd als NaN.
|
1
2
3
|
…
# vat de eerste paar rijen samen
print(dataframe.head())
|
We kunnen dan elke kolom opsommen en het aantal rijen rapporteren met ontbrekende waarden voor de kolom.
|
1
2
3
4
5
6
7
|
…
# vat het aantal rijen met ontbrekende waarden voor elke kolom samen
for i in range(dataframe.shape):
# tel het aantal rijen met ontbrekende waarden
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Ontbreekt: %d (%.1f%%)’ % (i, n_miss, perc))
|
Hierna volgt het volledige voorbeeld van het laden en samenvatten van de dataset.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# vat de dataset voor paardenkoliek samen
from pandas import read_csv
# laad dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# vat de eerste paar rijen samen
print(dataframe.head())
# vat het aantal rijen met ontbrekende waarden voor elke kolom samen
for i in range(dataframe.shape):
# tel het aantal rijen met ontbrekende waarden
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Missing: %d (%.1f%%)’ % (i, n_miss, perc))
|
Het uitvoeren van het voorbeeld laadt eerst de dataset en vat de eerste vijf rijen samen.
We kunnen zien dat de ontbrekende waarden die met een “?”-teken waren gemarkeerd, zijn vervangen door NaN-waarden.
Volgende zien we de lijst van alle kolommen in de dataset en het aantal en percentage ontbrekende waarden.
We kunnen zien dat sommige kolommen (bijv. kolomindexen 1 en 2) geen ontbrekende waarden hebben en andere kolommen (bijv. kolomindexen 15 en 21) veel of zelfs een meerderheid van ontbrekende waarden hebben.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Missing: 1 (0.3%)
> 1, Ontbreekt: 0 (0,0%)
> 2, Ontbreekt: 0 (0,0%)
> 3, Ontbreekt: 60 (20,0%)
> 4, Ontbreekt: 24 (8,0%)
> 5, Ontbreekt: 58 (19,3%)
> 6, Ontbreekt: 56 (18,7%)
> 7, Ontbreekt: 69 (23,0%)
> 8, Ontbreekt: 47 (15,7%)
> 9, Ontbreekt: 32 (10,7%)
> 10, Ontbreekt: 55 (18,3%)
> 11, Ontbreekt: 44 (14,7%)
> 12, Ontbreekt: 56 (18,7%)
> 13, Ontbreekt: 104 (34,7%)
> 14, Ontbreekt: 106 (35,3%)
> 15, Ontbreekt: 247 (82,3%)
> 16, Ontbreekt: 102 (34,0%)
> 17, Ontbreekt: 118 (39,3%)
> 18, Ontbreekt: 29 (9,7%)
> 19, Ontbreekt: 33 (11,0%)
> 20, Ontbreekt: 165 (55,0%)
> 21, Ontbreekt: 198 (66,0%)
> 22, Ontbreekt: 1 (0,3%)
> 23, Ontbreekt: 0 (0,0%)
> 24, Ontbreekt: 0 (0,0%)
> 25, Ontbreekt: 0 (0,0%)
> 26, Ontbreekt: 0 (0.0%)
> 27, Ontbreekt: 0 (0,0%)
|
Nu we vertrouwd zijn met de dataset paardenkoliek die ontbrekende waarden heeft, laten we eens kijken hoe we statistische imputatie kunnen gebruiken.
Statistische imputatie met SimpleImputer
De scikit-learn-bibliotheek voor machinaal leren biedt de klasse SimpleImputer die statistische imputatie ondersteunt.
In deze sectie zullen we onderzoeken hoe we de SimpleImputer klasse effectief kunnen gebruiken.
SimpleImputer Data Transform
De SimpleImputer is een data transform die eerst wordt geconfigureerd op basis van het type statistiek dat voor elke kolom moet worden berekend, bijv.b.v. gemiddelde.
|
1
2
3
|
…
# definieer imputer
imputer = SimpleImputer(strategy=’mean’)
|
Dan wordt de imputer gefit op een dataset om de statistiek voor elke kolom te berekenen.
|
1
2
3
|
…
# fit op de dataset
imputer.fit(X)
|
De fit imputer wordt vervolgens toegepast op een dataset om een kopie van de dataset te maken waarbij alle ontbrekende waarden voor elke kolom zijn vervangen door een statistische waarde.
|
1
2
3
|
…
# transformeer de dataset
Xtrans = imputer.transform(X)
|
We kunnen het gebruik ervan demonstreren op de dataset voor paardenkoliek en bevestigen dat het werkt door het totale aantal ontbrekende waarden in de dataset voor en na de transformatie samen te vatten.
Het volledige voorbeeld staat hieronder.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# statistische imputatie transformatie voor de dataset paardenkoliek
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# splitsen in invoer- en uitvoerelementen
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# print total missing
print(‘Ontbreekt: %d’ % som(isnan(X).flatten())
# definieer imputer
imputer = SimpleImputer(strategy=’mean’)
# fit op de dataset
imputer.fit(X)
# transformeer de dataset
Xtrans = imputer.transform(X)
# print totale missing
print(‘Missing: %d’ % som(isnan(Xtrans).flatten())
|
Het uitvoeren van het voorbeeld laadt eerst de dataset en rapporteert het totale aantal ontbrekende waarden in de dataset als 1.605.
De transformatie wordt geconfigureerd, aangepast en uitgevoerd en de resulterende nieuwe dataset heeft geen ontbrekende waarden, wat bevestigt dat de transformatie is uitgevoerd zoals we hadden verwacht.
Elke ontbrekende waarde werd vervangen door de gemiddelde waarde van zijn kolom.
|
1
2
|
Missing: 1605
Verbreekt: 0
|
SimpelImputer en Model Evaluatie
Het is een goede gewoonte om machine learning modellen te evalueren op een dataset met behulp van k-voudige kruisvalidatie.
Om statistische imputatie van ontbrekende gegevens correct toe te passen en gegevenslekken te voorkomen, is het vereist dat de statistieken die voor elke kolom worden berekend, alleen op de trainingsdataset worden berekend en vervolgens worden toegepast op de train- en testsets voor elke vouw in de dataset.
Als we resampling gebruiken om afstemmingsparameterwaarden te selecteren of om de prestaties te schatten, moet de imputatie in de resampling worden opgenomen.
– Pagina 42, Applied Predictive Modeling, 2013.
Dit kan worden bereikt door een modelleerpijplijn te maken waarin de eerste stap de statistische imputatie is, en de tweede stap het model. Dit kan worden bereikt met behulp van de klasse Pipeline.
De onderstaande Pipeline maakt bijvoorbeeld gebruik van een SimpleImputer met een ‘mean’-strategie, gevolgd door een random forest-model.
|
1
2
3
4
5
|
…
# definieer modelleerpijplijn
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
We kunnen de gemiddelde-geïmputeerde dataset en de random forest modelleerpijplijn voor de dataset paardenkoliek evalueren met herhaalde 10-voudige kruisvalidatie.
Het volledige voorbeeld staat hieronder.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# evalueer gemiddelde imputatie en willekeurig forest voor de dataset paardenkoliek
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# splitsen in invoer- en uitvoerelementen
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# definieer modelleerpijplijn
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# definieer modelevaluatie
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evalueer model
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(‘Gemiddelde Nauwkeurigheid: %.3f (%.3f)’ % (gemiddelde(scores), std(scores))
|
Bij het uitvoeren van het voorbeeld wordt de gegevensimputatie correct toegepast op elke vouw van de kruisvalidatieprocedure.
Noot: uw resultaten kunnen afwijken door de stochastische aard van het algoritme of de evaluatieprocedure, of door verschillen in numerieke precisie. Overweeg het voorbeeld een paar keer uit te voeren en vergelijk de gemiddelde uitkomst.
De pijplijn is geëvalueerd met behulp van drie herhalingen van 10-voudige kruisvalidatie en rapporteert de gemiddelde classificatienauwkeurigheid op de dataset als ongeveer 86.3 procent, wat een goede score is.
|
1
|
Gemiddelde nauwkeurigheid: 0,863 (0.054)
|
Vergelijking van verschillende geïmputeerde statistieken
Hoe weten we dat het gebruik van een ‘gemiddelde’ statistische strategie goed of het beste is voor deze dataset?
Het antwoord is dat we dat niet weten en dat die strategie willekeurig is gekozen.
We kunnen een experiment opzetten om elke statistische strategie te testen en te ontdekken wat het beste werkt voor deze dataset, waarbij we het gemiddelde, de mediaan, de modus (meest frequent), en de constante (0) strategieën vergelijken. De gemiddelde nauwkeurigheid van elke aanpak kan dan worden vergeleken.
Het volledige voorbeeld staat hieronder.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# vergelijk statistische imputatiestrategieën voor de dataset paardenkoliek
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# splitsen in invoer- en uitvoerelementen
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# evalueer elke strategie op de dataset
resultaten = lijst()
strategieën =
voor s in strategieën:
# maak de modelleerpijplijn
pijplijn = pijplijn(stappen=)
# evalueer het model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# sla resultaten op
resultaten.append(scores)
print(‘>%s %.3f (%.3f)’ % (s, mean(scores), std(scores))
# plot model performance for comparison
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
Het uitvoeren van het voorbeeld evalueert elke statistische imputatiestrategie op de dataset paardenkoliek met behulp van herhaalde kruisvalidatie.
Opmerking: uw resultaten kunnen afwijken door de stochastische aard van het algoritme of de evaluatieprocedure, of door verschillen in numerieke precisie. Overweeg het voorbeeld een paar keer uit te voeren en vergelijk de gemiddelde uitkomst.
De gemiddelde nauwkeurigheid van elke strategie wordt gaandeweg gerapporteerd. De resultaten suggereren dat het gebruik van een constante waarde, b.v. 0, resulteert in de beste prestatie van ongeveer 88,1 procent, wat een uitstekend resultaat is.
|
1
2
3
4
|
>geman 0.860 (0.054)
>mediaan 0.862 (0.065)
>most_frequent 0.872 (0.052)
>constant 0.881 (0.047)
|
Aan het eind van de run wordt voor elke reeks resultaten een box and whisker-plot gemaakt, zodat de verdeling van de resultaten kan worden vergeleken.
We kunnen duidelijk zien dat de verdeling van de nauwkeurigheidsscores voor de constante strategie beter is dan voor de andere strategieën.
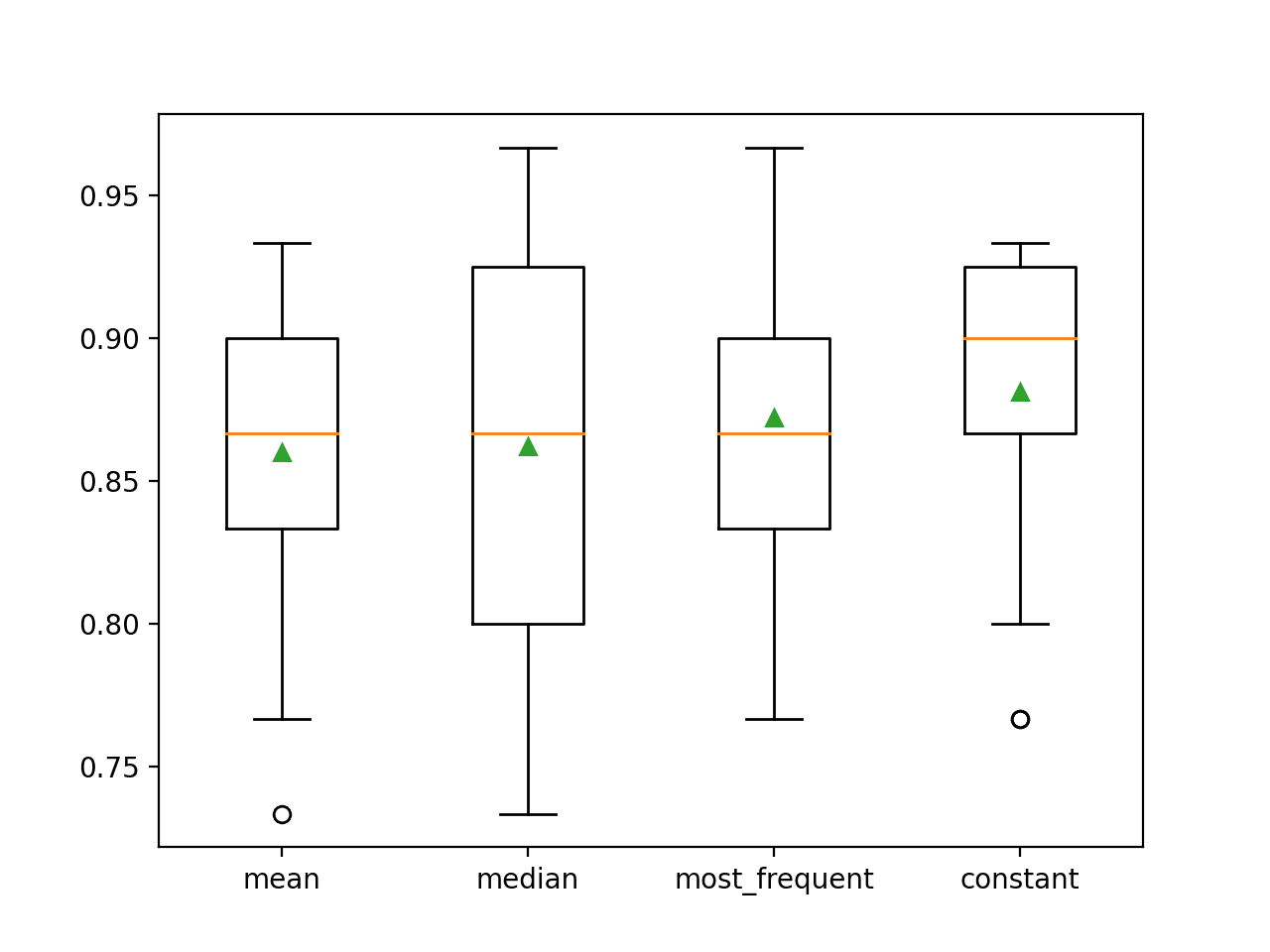
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
Wij willen misschien een definitieve modelleringspijplijn maken met de constante imputatiestrategie en het random forest algoritme, en dan een voorspelling doen voor nieuwe gegevens.
Dit kan worden bereikt door de pijplijn te definiëren en aan te passen aan alle beschikbare gegevens, en vervolgens de predict()-functie aan te roepen en nieuwe gegevens als argument mee te geven.
Belangrijk is dat de rij met nieuwe gegevens alle ontbrekende waarden markeert met de NaN-waarde.
|
1
2
3
|
…
# definieer nieuwe gegevens
row =
|
Het volledige voorbeeld staat hieronder.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# constante imputatie strategie en voorspelling voor de dataset slangenkoliek
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# splitsen in invoer- en uitvoerelementen
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# maak de modelleerpijplijn
pijplijn = pijplijn(stappen=)
# pas het model
pijplijn.fit(X, y)
# definieer nieuwe gegevens
row =
# doe een voorspelling
yhat = pipeline.predict()
# vat voorspelling samen
print(‘Voorspelde klasse: %d’ % yhat)
|
Het uitvoeren van het voorbeeld past de modelleerpijplijn op alle beschikbare gegevens.
Er wordt een nieuwe rij gegevens gedefinieerd waarbij ontbrekende waarden worden gemarkeerd met NaN’s en er wordt een classificatievoorspelling gedaan.
|
1
|
Geprojecteerde klasse: 2
|
Verder lezen
In dit gedeelte vindt u meer bronnen over dit onderwerp als u dieper op het onderwerp wilt ingaan.
Gerelateerde tutorials
- Resultaten voor standaardclassificatie en regressie Machine Learning-datasets
- Hoe om te gaan met ontbrekende gegevens met Python
Boeken
- Bad Data Handbook, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
API’s
- Imputatie van ontbrekende waarden, scikit-learn Documentatie.
- sklearn.impute.SimpleImputer API.
Dataset
- Horse Colic Dataset
- Horse Colic Dataset Beschrijving
Samenvatting
In deze tutorial heb je ontdekt hoe je statistische imputatiestrategieën kunt gebruiken voor ontbrekende gegevens in machine learning.
Specifiek leerde u:
- Missende waarden moeten worden gemarkeerd met NaN-waarden en kunnen worden vervangen door statistische maatregelen om de kolom met waarden te berekenen.
- Hoe een CSV-waarde met ontbrekende waarden te laden en de ontbrekende waarden te markeren met NaN-waarden en het aantal en het percentage ontbrekende waarden voor elke kolom te rapporteren.
- Hoe ontbrekende waarden toe te schrijven met statistieken als een gegevensvoorbereidingsmethode bij het evalueren van modellen en bij het passen van een definitief model om voorspellingen te doen op nieuwe gegevens.
Heeft u nog vragen?
Stel uw vragen in de commentaren hieronder en ik zal mijn best doen om ze te beantwoorden.
Krijg grip op moderne datavoorbereiding!

Prepareer uw Machine Learning-data in enkele minuten
…met slechts een paar regels python code
Ontdek hoe in mijn nieuwe Ebook:
Data Preparation for Machine Learning
Het biedt zelfstudie tutorials met volledig werkende code over:
Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction, en nog veel meer.
Breng moderne datavoorbereidingstechnieken naar
uw Machine Learning-projecten
Zie wat er in