Reinforcement Learning(RL) is een van de populairste onderzoeksonderwerpen op het gebied van moderne Kunstmatige Intelligentie en de populariteit ervan neemt alleen maar toe. Laten we eens kijken naar 5 nuttige dingen die men moet weten om aan de slag te gaan met RL.
Reinforcement Learning(RL) is een type machine leertechniek die een agent in staat stelt om te leren in een interactieve omgeving door trial and error met behulp van feedback van zijn eigen acties en ervaringen.
Hoewel zowel supervised learning als reinforcement learning gebruik maken van mapping tussen input en output, maakt reinforcement learning, in tegenstelling tot supervised learning waarbij de feedback die aan de agent wordt gegeven bestaat uit de juiste reeks acties voor het uitvoeren van een taak, gebruik van beloningen en straffen als signalen voor positief en negatief gedrag.
Vergeleken met ongesuperviseerd leren, is bekrachtigingsleren anders in termen van doelen. Terwijl het doel bij unsupervised learning is om overeenkomsten en verschillen tussen datapunten te vinden, is het doel bij reinforcement learning om een geschikt actiemodel te vinden dat de totale cumulatieve beloning van de agent maximaliseert. De onderstaande figuur illustreert de actie-beloning feedbacklus van een generiek RL-model.

Hoe formuleer je een basisprobleem op het gebied van reinforcement learning?
Enkele belangrijke termen die de basiselementen van een RL-probleem beschrijven zijn:
- Omgeving – Fysieke wereld waarin de agent opereert
- Toestand – Huidige situatie van de agent
- Beloning – Terugkoppeling van de omgeving
- Beleid – Methode om de toestand van de agent in kaart te brengen in acties
- Waarde – Toekomstige beloning die een agent zou ontvangen door een actie in een bepaalde toestand te ondernemen
Een RL-probleem kan het best worden uitgelegd aan de hand van spelletjes. Laten we het spel van PacMan nemen waar het doel van de agent (PacMan) is om het voedsel in het rooster te eten terwijl het vermijden van de spoken op zijn weg. In dit geval is de rasterwereld de interactieve omgeving voor de agent waar hij handelt. De agent krijgt een beloning voor het eten van voedsel en een straf als hij wordt gedood door een spook (verliest het spel). De toestanden zijn de locaties van de agent in de rasterwereld en de totale cumulatieve beloning is de agent die het spel wint.

Om een optimaal beleid op te stellen, staat de agent voor het dilemma om nieuwe toestanden te verkennen en tegelijkertijd zijn totale beloning te maximaliseren. Dit wordt de afweging tussen exploratie en exploitatie genoemd. Om beide in evenwicht te brengen, kan de beste algemene strategie offers op korte termijn inhouden. Daarom moet de agent genoeg informatie verzamelen om in de toekomst de beste beslissing te kunnen nemen.
Markov Decision Processes(MDP’s) zijn wiskundige raamwerken om een omgeving in RL te beschrijven en bijna alle RL problemen kunnen worden geformuleerd met MDP’s. Een MDP bestaat uit een verzameling eindige omgevingstoestanden S, een verzameling mogelijke acties A(s) in elke toestand, een reëel gewaardeerde beloningsfunctie R(s) en een overgangsmodel P(s’, s | a). In reële omgevingen is het echter waarschijnlijker dat er geen voorafgaande kennis is van de dynamica van de omgeving. Modelvrije RL methoden komen in zulke gevallen goed van pas.
Q-learning is een veelgebruikte modelvrije benadering die kan worden gebruikt voor het bouwen van een zelfspelende PacMan agent. Het draait om de notie van het updaten van Q-waarden die de waarde weergeven van het uitvoeren van actie a in toestand s. De volgende waarde update regel is de kern van het Q-learning algoritme.

Hier is een videodemonstratie van een PacMan-agent die gebruik maakt van Deep Reinforcement Learning.
Wat zijn enkele van de meest gebruikte Reinforcement Learning-algoritmen?
Q-learning en SARSA (State-Action-Reward-State-Action) zijn twee veelgebruikte modelvrije RL-algoritmen. Zij verschillen wat betreft hun exploratiestrategieën, terwijl hun exploitatiestrategieën vergelijkbaar zijn. Terwijl Q-learning een off-policy methode is waarbij de agent de waarde leert op basis van actie a* afgeleid van het andere beleid, is SARSA een on-policy methode waarbij de agent de waarde leert op basis van zijn huidige actie a afgeleid van zijn huidige beleid. Deze twee methoden zijn eenvoudig te implementeren, maar missen generaliteit omdat ze niet de mogelijkheid hebben om waarden in te schatten voor ongeziene toestanden.
Dit kan worden ondervangen door meer geavanceerde algoritmen zoals Deep Q-Networks(DQNs) die neurale netwerken gebruiken om Q-waarden in te schatten. Maar DQN’s kunnen alleen overweg met discrete, laagdimensionale actieruimten.
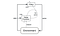
Deep Deterministic Policy Gradient(DDPG) is een modelvrij, off-policy, actor-kritisch algoritme dat dit probleem aanpakt door beleid te leren in hoogdimensionale, continue actieruimten. De onderstaande figuur is een weergave van de actor-kritische architectuur.
Wat zijn de praktische toepassingen van Reinforcement Learning?
Omdat RL veel data vereist, is het het meest toepasbaar in domeinen waar gesimuleerde data gemakkelijk beschikbaar is, zoals gameplay, robotica.
- RL wordt vrij veel gebruikt bij het bouwen van AI voor het spelen van computerspelletjes. AlphaGo Zero is het eerste computerprogramma dat een wereldkampioen heeft verslagen in het oude Chinese spel Go. Andere spellen zijn ATARI games, Backgammon, enz.
- In robotica en industriële automatisering wordt RL gebruikt om de robot in staat te stellen een efficiënt adaptief besturingssysteem voor zichzelf te maken dat leert van zijn eigen ervaring en gedrag. DeepMind’s werk aan Deep Reinforcement Learning voor robotmanipulatie met asynchrone beleidsupdates is daar een goed voorbeeld van. Bekijk deze interessante demonstratievideo.
Andere toepassingen van RL zijn onder meer abstracte tekstsamenvattingsengines, dialoogagenten (tekst, spraak) die kunnen leren van gebruikersinteracties en met de tijd kunnen verbeteren, het leren van optimaal behandelingsbeleid in de gezondheidszorg en op RL gebaseerde agenten voor online aandelenhandel.
Hoe kan ik aan de slag met Reinforcement Learning?
Voor het begrijpen van de basisconcepten van RL, kan men de volgende bronnen raadplegen.
- Reinforcement Learning-An Introduction, een boek door de vader van Reinforcement Learning- Richard Sutton en zijn doctoraal adviseur Andrew Barto. Een online concept van het boek is hier beschikbaar.
- Leermateriaal van David Silver inclusief video lezingen is een geweldige inleidende cursus over RL.
- Hier is een andere technische tutorial over RL door Pieter Abbeel en John Schulman (Open AI/ Berkeley AI Research Lab).
Voor het aan de slag gaan met het bouwen en testen van RL agenten, kunnen de volgende bronnen nuttig zijn.
- Deze blog over hoe je een Neuraal Netwerk ATARI Pong agent kunt trainen met Policy Gradients van ruwe pixels door Andrej Karpathy zal je helpen om je eerste Deep Reinforcement Learning agent up and running te krijgen in slechts 130 regels Python code.
- DeepMind Lab is een open source 3D game-achtig platform gemaakt voor agent-gebaseerd AI-onderzoek met rijke gesimuleerde omgevingen.
- Project Malmo is een ander AI-experimentatieplatform voor de ondersteuning van fundamenteel onderzoek in AI.
- OpenAI gym is een toolkit voor het bouwen en vergelijken van reinforcement learning algoritmen.