Het begrijpen van de basis van schema management is cruciaal voor het bouwen en onderhouden van een effectieve PostgreSQL database. In dit artikel gaan we kijken naar de traditionele manier om een Postgres schema te beheren en naar een nieuwere, meer effectieve manier om dit visueel te doen, zonder ook maar een regel code te hoeven schrijven.
Wat is een PostgreSQL Schema?
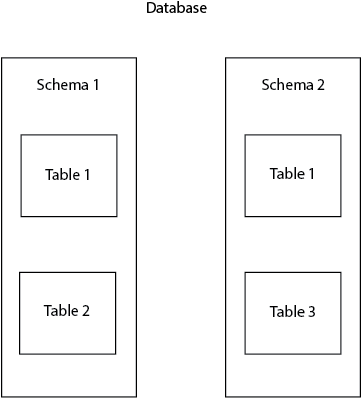
Laten we eerst eens wat terminologie uit de doeken doen, om de basis voor dit artikel te leggen. In Postgres, wordt het schema ook aangeduid als een namespace. De namespace kan geassocieerd worden met een familienaam. Ze wordt gebruikt om bepaalde objecten in de database (tabellen, views, kolommen, enz.) te identificeren en te onderscheiden. Het is niet toegestaan om twee tabellen met dezelfde naam aan te maken in één schema, maar het kan wel in twee verschillende schema’s. Bijvoorbeeld, we kunnen twee tabellen hebben, beide genaamd table1, aanwezig in public en in postgres schema’s.
Waarom schema’s gebruiken?
Schema’s zijn erg nuttig om databaseobjecten in logische groepen te ordenen en naamsconflicten te vermijden. Daarnaast worden schema’s vaak gebruikt om verschillende gebruikers in staat te stellen met de database te werken zonder elkaar te storen. Een veel voorkomend voorbeeld is wanneer iedere database gebruiker aan zijn eigen schema werkt, zonder andere gebruikers te hinderen en conflicten te vermijden.
De klassieke manier om PostgreSQL schema’s te beheren
Alle onderstaande queries worden uitgevoerd vanuit de PostgreSQL shell.
Een schema maken
Wanneer u een nieuwe database in Postgres maakt, is het standaard schema publiek. Een nieuw schema kan worden gemaakt door het uitvoeren van de volgende query:
CREATE SCHEMA schema_1;
Alvorens er enkele tabellen aan toe te voegen, zal ik twee belangrijke concepten uitleggen: gekwalificeerde en ongekwalificeerde namen.
-
Een gekwalificeerde naam is de schema naam en de tabel naam gescheiden door een punt. Hiermee wordt het schema gespecificeerd waarin we onze tabel willen maken:
xxxxxxxxxx
CREATE TABLE schema_name.table_name (...);
-
Een niet-gekwalificeerde naam bestaat alleen uit de tabelnaam. Hiermee wordt de tabel aangemaakt in de geselecteerde database, die standaard openbaar is. Dit kan worden veranderd via het zoek_pad, maar we zullen dit later in detail bespreken. Een voorbeeld van een ongekwalificeerde naamgeving is:
xxxxxxxxxx
CREATE TABLE table_name (...);
De kolommen van de tabellen zullen worden gedefinieerd binnen de haakjes van de bovenstaande query’s (…).
Om een nieuwe tabel in ons nieuwe schema te maken, voeren we uit:
xxxxxxxxxx
CREATE TABLE schema_1.persons (name text, age int);
Om het schema te laten vallen, hebben we twee mogelijkheden. Als het schema leeg is (bevat geen tabel, view, of andere objecten), kunnen we uitvoeren:
xxxxxxxxxx
DROP SCHEMA schema_1;
Als het schema databaseobjecten bevat, zullen we het cascade commando invoegen:
xxxxxxxxxx
DROP SCHEMA schema_1 CASCADE;
In PostgreSQL is het ook mogelijk om een schema te maken dat eigendom is van een andere gebruiker met:
xxxxxxxxxx
CREATE SCHEMA schema_name AUTHORIZATION username;
Zoekpad
Wanneer u een opdracht uitvoert met een ongekwalificeerde naam, volgt Postgres een zoekpad om te bepalen welke schema’s moeten worden gebruikt. Standaard is het zoekpad ingesteld op het publieke schema. Om het te bekijken, voert u uit:
xxxxxxxxxx
SHOW search_path;
Als er niets is veranderd in uw database, zou deze query het volgende resultaat moeten opleveren:
xxxxxxxxxx
search_path
--------------
"$user",public
Het zoek_pad kan worden aangepast zodat het systeem automatisch een ander schema kiest als u een ongekwalificeerde naam gebruikt. Het eerste schema in het zoekpad wordt het huidige schema genoemd. Bijvoorbeeld, ik zal schema_1 instellen als het huidige schema:
xxxxxxxxxx
SET search_path TO schema_1,public;
De volgende query zal een ongekwalificeerde naam gebruiken om een tabel aan te maken. Deze wordt automatisch aangemaakt in schema_1:
xxxxxxxxxx
CREATE TABLE address (city text, street text, number int);
De nieuwe manier: Beheer zonder code!
Er is een eenvoudigere manier om alle schema beheer taken uit te voeren, zonder ook maar een regel code te hoeven schrijven. Met behulp van DbSchema kunt u alle bovenstaande queries uitvoeren vanuit een intuïtieve GUI met slechts een paar klikken. Verbinding maken met de database duurt slechts een paar seconden. Vanaf het begin kunt u selecteren op welk schema u wilt werken.
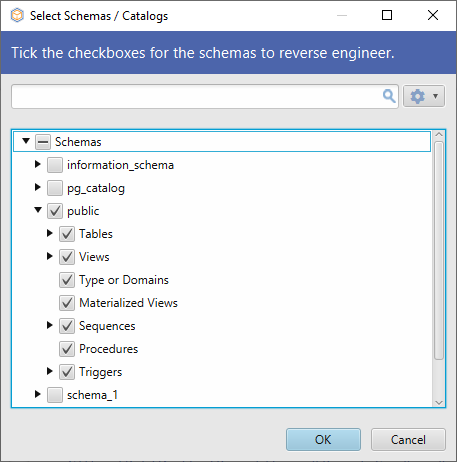
Het geselecteerde schema of schema’s zullen door DbSchema worden reverse-engineered en in de layout worden getoond.
Om een nieuw schema te maken, klikt u met de rechtermuisknop op de schema-map in het linkermenu en kiest u Schema maken.
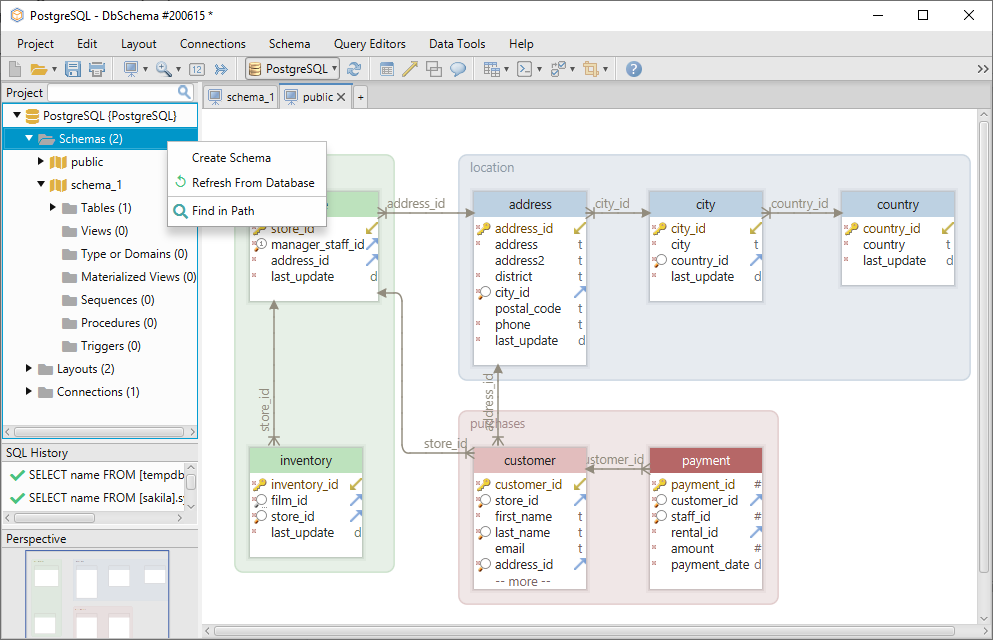
Om een nieuwe tabel in het schema te maken, klikt u met de rechtermuisknop op de lay-out en kiest u Tabel maken.
Om een nieuwe tabel in het schema te maken, klikt u met de rechtermuisknop op de lay-out en kiest u Tabel maken.
Het schema kan worden verwijderd door met de rechtermuisknop te klikken op de naam ervan in het linkermenu.
Om een ander schema uit de database toe te voegen, kiest u Refresh From Database.
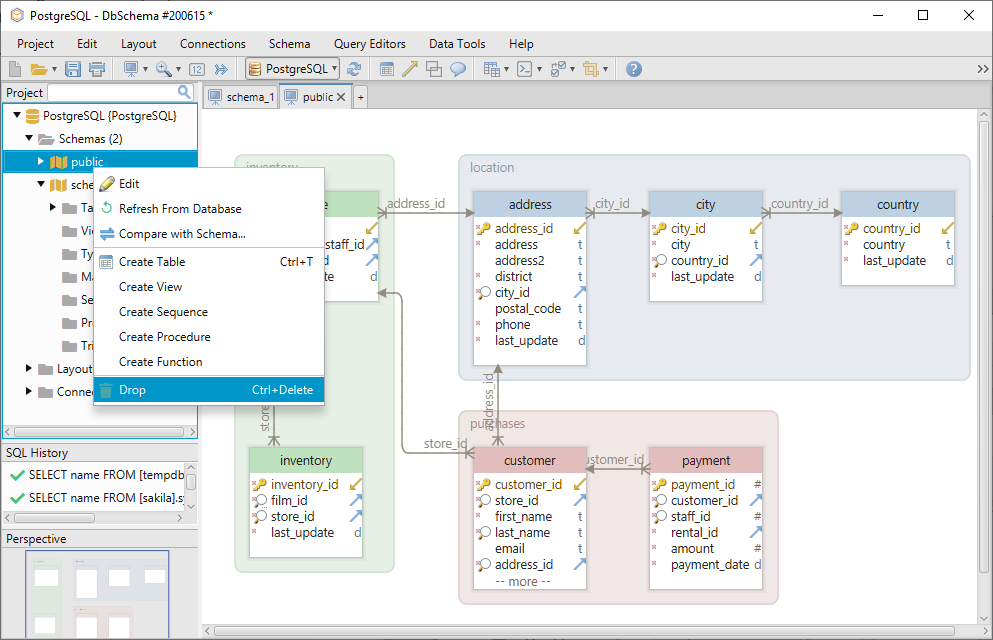
Met DbSchema hoeft u de show_path syntaxis niet te gebruiken, omdat u de tabellen direct in de layout kunt aanmaken. Een layout kan worden vergeleken met een tekentafel waarop u de tabellen kunt toevoegen en bewerken. Elke layout heeft een schema dat ermee geassocieerd is, dus als u op de schema_1 layout bent, zullen de tabellen daar automatisch aangemaakt worden.
Offline werken
DbSchema slaat een lokale afbeelding van het schema op in een lokaal projectbestand. Dit betekent dat het project bestand kan worden geopend zonder database connectiviteit (offline). Terwijl offline, kunt u alle acties doen die hierboven zijn gepresenteerd en meer, maar zonder gegevens. Na het opnieuw verbinden met de database, kunt u het projectbestand vergelijken met de database en kiezen welke acties te behouden of te laten vallen.
Hetzelfde kan worden gedaan tussen twee verschillende versies van hetzelfde projectbestand. Als u bijvoorbeeld in een team werkt, kan het voorkomen dat er meerdere schema’s zijn (productie, testen, ontwikkeling), elk met een eigen projectbestand. Als een wijziging verschijnt in ontwikkeling en je wilt die doorvoeren over de andere twee schema’s, dan kun je gewoon de twee project bestanden vergelijken en synchroniseren.
Conclusie
Inzicht in de hierboven genoemde concepten zal u helpen om uw PostgreSQL schema’s gemakkelijk te beheren. Het gebruik van een visuele ontwerper zoals DbSchema zal uw werk nog eenvoudiger maken door u in staat te stellen alles visueel te doen, zonder ook maar één regel code te hoeven schrijven.