Gegevensversleuteling in ruste is een must voor elk modern internetbedrijf. Veel bedrijven versleutelen hun schijven echter niet, omdat ze bang zijn voor het mogelijke prestatieverlies als gevolg van de overhead van versleuteling.
Versleuteling van gegevens in ruste is van vitaal belang voor Cloudflare, met meer dan 200 datacenters over de hele wereld. In deze post onderzoeken we de prestaties van schijfversleuteling op Linux en leggen we uit hoe we het ten minste twee keer sneller hebben gemaakt voor onszelf en onze klanten!
Versleuteling van gegevens in ruste
Als het gaat om het versleutelen van gegevens in ruste, zijn er verschillende manieren waarop het kan worden geïmplementeerd op een modern besturingssysteem (OS). De beschikbare technieken zijn nauw verbonden met een typische OS-opslagstack. Een vereenvoudigde versie van de opslagstapel en versleutelingsoplossingen is te vinden in het onderstaande diagram:
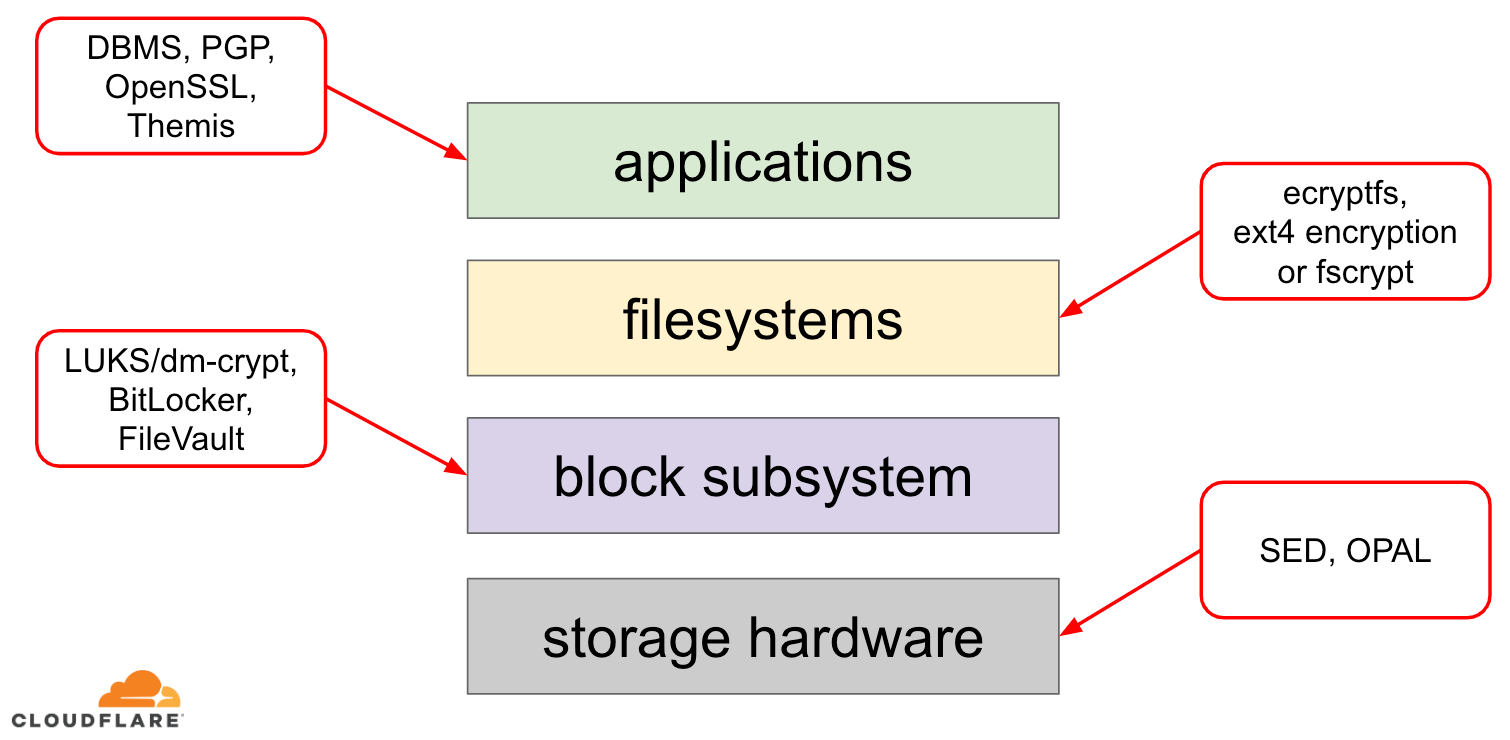
Bovenaan de stapel staan toepassingen, die gegevens lezen en schrijven in bestanden (of streams). Het bestandssysteem in de kernel van het besturingssysteem houdt bij welke blokken van het onderliggende blokapparaat bij welke bestanden horen en vertaalt deze gelezen en geschreven bestanden in gelezen en geschreven blokken, maar de hardware-specificaties van het onderliggende opslagapparaat worden van het bestandssysteem weggelaten. Tenslotte geeft het blok-subsysteem de gelezen en geschreven blokken door aan de onderliggende hardware met behulp van de juiste apparaatstuurprogramma’s.
Het concept van de opslagstapel is eigenlijk vergelijkbaar met het bekende netwerk OSI-model, waarbij elke laag een meer hoog niveau zicht heeft op de informatie en de implementatiedetails van de lagere lagen zijn weg geabstraheerd van de hogere lagen. En net als bij het OSI-model kan encryptie op verschillende lagen worden toegepast (denk aan TLS vs IPsec of een VPN).
Voor gegevens in rust kunnen we encryptie toepassen op de bloklagen (in hardware of in software) of op bestandsniveau (rechtstreeks in toepassingen of in het bestandssysteem).
Block vs file encryption
In het algemeen geldt dat hoe hoger in de stack we encryptie toepassen, hoe meer flexibiliteit we hebben. Met versleuteling op applicatieniveau kunnen de applicatie-beheerders elke versleutelingscode toepassen die ze maar willen op de gegevens die ze nodig hebben. Het nadeel van deze aanpak is dat zij het zelf moeten implementeren en dat versleuteling in het algemeen niet erg ontwikkelaarvriendelijk is: men moet de ins en outs van een specifiek cryptografisch algoritme kennen, sleutels, nonces, IV’s enz. op de juiste manier genereren. Bovendien maakt versleuteling op applicatieniveau geen gebruik van caching op OS-niveau en Linux-pagina-cache in het bijzonder: elke keer dat de applicatie de gegevens moet gebruiken, moet het deze ofwel opnieuw ontsleutelen, waardoor CPU-cycli worden verspild, of zijn eigen ontsleutelde “cache” implementeren, wat meer complexiteit aan de code toevoegt.
Versleuteling op bestandssysteemniveau maakt gegevensversleuteling transparant voor applicaties, omdat het bestandssysteem zelf de gegevens versleutelt voordat het deze doorgeeft aan het blok-subsysteem, zodat bestanden worden versleuteld ongeacht of de applicatie crypto-ondersteuning heeft of niet. Bestandssystemen kunnen ook worden geconfigureerd om alleen een bepaalde map te versleutelen of om verschillende sleutels te hebben voor verschillende bestanden. Deze flexibiliteit gaat echter ten koste van een complexere configuratie. Bestandssysteemversleuteling wordt ook minder veilig geacht dan blokversleuteling, omdat alleen de inhoud van de bestanden wordt versleuteld. Bestanden hebben ook bijbehorende metadata, zoals de bestandsgrootte, het aantal bestanden, de indeling van de mappenstructuur, enz. die nog steeds zichtbaar zijn voor een potentiële tegenstander.
Versleuteling op de bloklaag (vaak schijfversleuteling of volledige schijfversleuteling genoemd) maakt gegevensversleuteling ook transparant voor toepassingen en zelfs voor hele bestandssystemen. In tegenstelling tot versleuteling op bestandssysteemniveau versleutelt het alle gegevens op de schijf, inclusief bestandsmetadata en zelfs vrije ruimte. Het is echter minder flexibel – men kan alleen de hele schijf versleutelen met een enkele sleutel, dus er is geen configuratie per map, per bestand of per gebruiker. Vanuit het cryptoperspectief kunnen niet alle cryptografische algoritmen worden gebruikt, omdat de bloklaag geen overzicht meer heeft op hoog niveau van de gegevens, en dus elk blok onafhankelijk moet verwerken. De meeste gangbare algoritmen vereisen een of andere vorm van block chaining om veilig te zijn, en zijn dus niet toepasbaar voor schijfversleuteling. In plaats daarvan zijn speciale modi ontwikkeld voor dit specifieke gebruik.
Dus welke laag te kiezen? Zoals altijd, dat hangt ervan af… Encryptie op toepassings- en bestandssysteemniveau is meestal de beste keuze voor client-systemen vanwege de flexibiliteit. Bijvoorbeeld, iedere gebruiker op een multi-user desktop kan zijn eigen home directory willen versleutelen met een sleutel die hij bezit en sommige gedeelde directories onversleuteld laten. Op serversystemen, beheerd door SaaS/PaaS/IaaS-bedrijven (waaronder Cloudflare), gaat de voorkeur daarentegen uit naar eenvoud van configuratie en veiligheid – met ingeschakelde volledige schijfversleuteling worden alle gegevens van elke toepassing automatisch versleuteld, zonder uitzonderingen of overschrijvingen. Wij zijn van mening dat alle gegevens moeten worden beschermd zonder ze te sorteren in “belangrijke” versus “niet belangrijke” emmers, dus de selectieve flexibiliteit die de bovenste lagen bieden is niet nodig.
Hardware vs software schijfversleuteling
Bij het versleutelen van gegevens op de bloklaag is het mogelijk om dit direct in de opslaghardware te doen, als de hardware dit ondersteunt. Dit geeft meestal betere lees/schrijfprestaties en verbruikt minder bronnen van de host. Aangezien de meeste hardware-firmware echter propriëtair is, krijgt deze niet zoveel aandacht en beoordeling van de beveiligingsgemeenschap. In het verleden heeft dit geleid tot fouten in sommige implementaties van hardwarematige schijfversleuteling, waardoor het hele beveiligingsmodel onbruikbaar werd. Microsoft, bijvoorbeeld, begon sindsdien de voorkeur te geven aan software-gebaseerde schijfversleuteling.
We wilden onze gegevens en die van onze klanten niet blootstellen aan het risico van het gebruik van potentieel onveilige oplossingen en we geloven sterk in open-source. Daarom vertrouwen we alleen op software-schijfversleuteling in de Linux-kernel, die open is en door veel beveiligingsprofessionals over de hele wereld is gecontroleerd.
Linux-schijfversleutelingsprestaties
We willen niet alleen bandbreedtekosten voor onze klanten besparen, maar de inhoud zo snel mogelijk aan internetgebruikers leveren.
Op een gegeven moment merkten we dat onze schijven niet zo snel waren als we zouden willen. Wat profilering en een snelle A/B test wezen in de richting van Linux schijfversleuteling. Omdat het niet versleutelen van de data (zelfs als het een publieke Internet cache zou moeten zijn) geen houdbare optie is, besloten we om de prestaties van Linux schijfversleuteling nader te bekijken.
Device mapper en dm-crypt
Linux implementeert transparante schijfversleuteling via een dm-crypt module en dm-crypt zelf is onderdeel van het device mapper kernel raamwerk. In een notendop, de device mapper staat pre/post-processing IO verzoeken toe terwijl ze reizen tussen het bestandssysteem en het onderliggende block device.
dm-crypt in het bijzonder versleutelt “schrijf” IO verzoeken alvorens ze verder de stack in te sturen naar het eigenlijke block device en ontsleutelt “lees” IO verzoeken alvorens ze omhoog te sturen naar het bestandssysteem stuurprogramma. Eenvoudig en gemakkelijk! Of toch niet?
Benchmarking setup
Voor de goede orde, de cijfers in dit bericht zijn verkregen door het uitvoeren van gespecificeerde commando’s op een ongebruikte Cloudflare G9 server die niet in productie is. De opstelling zou echter gemakkelijk reproduceerbaar moeten zijn op elke moderne x86 laptop.
In het algemeen is het moeilijk om iets rond een opslagstapel te benchmarken vanwege de ruis die door de opslaghardware zelf wordt geïntroduceerd. Niet alle schijven zijn gelijk, dus voor het doel van dit bericht zullen we de snelste schijven gebruiken die er zijn – dat is geen schijven.
In plaats daarvan heeft Linux een optie om een schijf direct in RAM te emuleren. Aangezien RAM veel sneller is dan enige persistente opslag, zou dit weinig bias in onze resultaten moeten introduceren.
Het volgende commando creëert een 4GB ramdisk:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Nu kunnen we er een dm-crypt instantie bovenop zetten en zo encryptie voor de schijf mogelijk maken. Eerst moeten we de sleutel voor de schijfversleuteling genereren, de schijf “formatteren” en een wachtwoord opgeven om de nieuw gegenereerde sleutel te ontgrendelen.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Diegenen die bekend zijn met LUKS/dm-crypt hebben misschien opgemerkt dat we hier een LUKS detached header hebben gebruikt. Normaal slaat LUKS de met een wachtwoord versleutelde schijfversleutelingssleutel op dezelfde schijf op als de gegevens, maar aangezien we de lees/schrijfprestaties tussen versleutelde en onversleutelde apparaten willen vergelijken, zouden we de versleutelde sleutel later tijdens onze benchmarking per ongeluk kunnen overschrijven. Door de versleutelde sleutel in een apart bestand te bewaren, wordt dit probleem in het kader van dit bericht vermeden.
Nu kunnen we het versleutelde apparaat “ontgrendelen” voor onze tests:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0Op dit punt kunnen we nu de prestaties van versleutelde versus onversleutelde ramdisk vergelijken: als we gegevens lezen/schrijven naar /dev/ram0, worden deze opgeslagen in onversleutelde tekst. Als we data lezen/schrijven naar /dev/mapper/encrypted-ram0, wordt deze onderweg ontsleuteld/versleuteld door dm-crypt en opgeslagen in cijfertekst.
Het is de moeite waard om op te merken dat we geen bestandssysteem creëren bovenop onze block devices om te voorkomen dat de resultaten worden vertekend door de overhead van het bestandssysteem.
Doorvoer meten
Als het aankomt op opslag testen/benchmarken is Flexible I/O tester de gebruikelijke oplossing. Laten we een eenvoudige sequentiële lees/schrijf belasting simuleren met 4K blokgrootte op de ramdisk zonder encryptie:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Het bovenstaande commando zal een lange tijd draaien, dus we stoppen het na een tijdje. Zoals we kunnen zien in de statistieken, zijn we in staat om te lezen en te schrijven met ongeveer dezelfde doorvoer rond 1126 MB/s. Laten we de test herhalen met de versleutelde ramdisk:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, dat is een daling! We krijgen nu nog maar ~147 MB/s, dat is meer dan 7 keer langzamer! En dit is op een totaal inactieve machine!
Misschien is crypto gewoon traag
Het eerste wat we overwogen is om ervoor te zorgen dat we de snelste crypto gebruiken. cryptsetup stelt ons in staat om alle beschikbare crypto implementaties op het systeem te benchmarken om de beste te selecteren:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/AHet lijkt erop dat aes-xts met een 256-bit data encryptie sleutel hier het snelst is. Maar welke gebruiken we eigenlijk voor onze versleutelde ramdisk?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0We gebruiken aes-xts met een 256-bit data-encryptie sleutel (tel alle nullen die gemakkelijk gemaskeerd worden door dmsetup gereedschap – als u de werkelijke bytes wilt zien, voeg dan de --showkeys optie toe aan het bovenstaande commando). De getallen tellen echter niet op: cryptsetup benchmark vertelt ons hierboven niet te vertrouwen op de resultaten, omdat “Tests zijn bij benadering met alleen geheugen (geen opslag IO)”, maar dat is precies hoe we ons experiment met de ramdisk hebben opgezet. In een iets slechter geval (ervan uitgaande dat we alle data lezen en dan sequentieel versleutelen/decoderen zonder parallellisme) zouden we door back-of-the-envelope berekeningen ongeveer (1126 * 1823) / (1126 + 1823) =~696 MB/s moeten krijgen, wat nog steeds vrij ver van de werkelijke 147 * 2 = 294 MB/s is (totaal voor lezen en schrijven).
dm-crypt performance flags
Tijdens het lezen van de cryptsetup man page viel het ons op dat er twee opties zijn met --perf-, die waarschijnlijk te maken hebben met performance tuning. De eerste is --perf-same_cpu_crypt met een nogal cryptische beschrijving:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Dus we schakelen de optie
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Note: volgens de laatste man pagina is er ook een cryptsetup refresh commando, dat kan gebruikt worden om deze opties live in te schakelen zonder het gecodeerde apparaat te moeten “sluiten” en “heropenen”. Onze cryptsetup ondersteunde dit echter nog niet.
Verifiëren of de optie echt is ingeschakeld:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptJa, we kunnen nu same_cpu_crypt in de uitvoer zien, wat is wat we wilden. Laten we de benchmark opnieuw uitvoeren:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, nu is het ~136 MB/s wat iets slechter is dan voorheen, dus niet goed. Hoe zit het met de tweede optie --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Misschien, we zijn in de “sommige situatie” hier, dus laten we het proberen:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusEn nu de benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, dat is een beetje beter, maar nog steeds niet goed…
Vraag de gemeenschap
Twijfelend besloten we steun te zoeken op het Internet en plaatsten onze bevindingen op de dm-crypt mailing list, maar de respons die we kregen was niet erg bemoedigend:
Als de cijfers u storen, dan komt dat door een gebrek aan inzicht aan uw kant. U bent zich er waarschijnlijk niet van bewust dat encryptie een zware bewerking is…
We besloten een wetenschappelijk onderzoek naar dit onderwerp te doen door “is encryptie duur” in te typen in Google Search en een van de topresultaten, die daadwerkelijk zinvolle metingen bevat, is… onze eigen post over de kosten van encryptie, maar dan in de context van TLS! Dit is een fascinerende lezing op zichzelf, maar de essentie is: moderne crypto op moderne hardware is zeer goedkoop, zelfs op Cloudflare schaal (miljoenen versleutelde HTTP verzoeken per seconde doen). Het is zelfs zo goedkoop dat Cloudflare de eerste provider was die gratis SSL/TLS voor iedereen aanbood.
Diepen in de broncode
Toen we probeerden de hierboven beschreven aangepaste dm-crypt opties te gebruiken, waren we nieuwsgierig waarom ze überhaupt bestaan en wat dat “offloading” allemaal inhoudt. Oorspronkelijk verwachtten we dat dm-crypt een eenvoudige “proxy” zou zijn, die gewoon gegevens versleutelt/decodeert terwijl ze door de stack stromen. Het blijkt dat dm-crypt meer doet dan alleen geheugenbuffers versleutelen en een (vereenvoudigd) IO-traverse pad diagram wordt hieronder gepresenteerd:

Wanneer het bestandssysteem een schrijfverzoek geeft, verwerkt dm-crypt het niet onmiddellijk – in plaats daarvan zet het het in een werkqueue met de naam “kcryptd”. In een notendop, een kernel werkqueue plant gewoon wat werk (encryptie in dit geval) om op een later tijdstip te worden uitgevoerd, wanneer het beter uitkomt. Als “de tijd” daar is, stuurt dm-crypt het verzoek naar de Linux Crypto API voor de eigenlijke encryptie. Echter, de moderne Linux Crypto API is ook asynchroon, dus afhankelijk van welke implementatie uw systeem zal gebruiken, zal het waarschijnlijk niet onmiddellijk worden verwerkt, maar opnieuw in de wachtrij worden geplaatst voor een “later tijdstip”. Wanneer Linux Crypto API uiteindelijk de encryptie zal doen, kan dm-crypt proberen om in behandeling zijnde schrijf-verzoeken te sorteren door elk verzoek in een rood-zwarte boom te zetten. Dan neemt een aparte kernel thread weer op “een later tijdstip” daadwerkelijk alle IO verzoeken in de boom en stuurt ze naar beneden de stack.
Nu voor lees verzoeken: deze keer moeten we de versleutelde data eerst van de hardware krijgen, maar dm-crypt vraagt niet gewoon naar het stuurprogramma voor de data, maar plaatst het verzoek in een wachtrij in een andere workqueue genaamd “kcryptd_io”. Op een later tijdstip, wanneer we de versleutelde data daadwerkelijk hebben, plannen we het voor ontcijfering met de nu bekende “kcryptd” workqueue. “kcryptd” stuurt het verzoek naar de Linux Crypto API, die de data ook asynchroon kan ontsleutelen.
Om eerlijk te zijn doorloopt het verzoek niet altijd al deze wachtrijen, maar het belangrijkste hier is dat schrijfverzoeken tot 4 keer in dm-crypt in de wachtrij kunnen worden geplaatst en leesverzoeken tot 3 keer. Op dit punt vroegen we ons af of al deze extra wachtrijen kunnen leiden tot prestatieproblemen. Er is bijvoorbeeld een mooie presentatie van Google over de relatie tussen queueing en tail latency. Een belangrijke conclusie uit de presentatie is:
Een aanzienlijk deel van staartlatentie is te wijten aan wachtrij-effecten
Dus, waarom zijn al deze wachtrijen er en kunnen we ze verwijderen?
Git-archeologie
Niemand schrijft meer complexe code zomaar voor de lol, zeker niet voor de OS-kernel. Dus al deze wachtrijen moeten er met een reden zijn neergezet. Gelukkig wordt de Linux kernel broncode beheerd door git, dus we kunnen proberen de veranderingen en de beslissingen eromheen te traceren.
De “kcryptd” werkqueue stond al in de broncode sinds het begin van de beschikbare geschiedenis met het volgende commentaar:
Nodig omdat het erg onverstandig zou zijn om decryptie te doen in een interrupt context, dus bios die terugkomen van leesverzoeken worden hier in een wachtrij geplaatst.
Dus het was alleen voor lezen, maar dan nog – waarom zouden we ons druk maken over interruptcontext of niet, als Linux Crypto API waarschijnlijk toch een speciale thread/queue zal gebruiken voor encryptie? Wel, in 2005 was Crypto API niet asynchroon, dus dit was volkomen logisch.
In 2006 begon dm-crypt de “kcryptd” workqueue niet alleen te gebruiken voor encryptie, maar ook voor het indienen van IO-verzoeken:
Deze patch is ontworpen om dm-crypt te helpen voldoen aan de nieuwe beperkingen die zijn opgelegd door de volgende patch in -mm: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Het lijkt erop dat het doel hier niet was om meer concurrency toe te voegen, maar eerder om het kernel stackgebruik te verminderen, wat opnieuw logisch is aangezien de kernel een gemeenschappelijke stack heeft voor alle code, dus het is een vrij beperkte bron. Het is echter vermeldenswaard dat de Linux kernel stack in 2014 is uitgebreid voor x86-platforms, dus dit is misschien geen probleem meer.
Een eerste versie van “kcryptd_io” workqueue werd toegevoegd in 2007 met de bedoeling om te voorkomen:
starvation veroorzaakt door veel verzoeken die wachten op geheugentoewijzing…
De verwerking van het verzoek was hier een knelpunt op een enkele workqueue, dus de oplossing was om er nog een toe te voegen. Dat klinkt logisch.
Wij zijn zeker niet de eersten die te maken hebben met prestatievermindering door uitgebreide wachtrijen: in 2011 werd een wijziging doorgevoerd om de wachtrijen voor leesaanvragen voorwaardelijk terug te draaien:
Als er genoeg geheugen is, kan de code direct een bio indienen in plaats van deze bewerking in een aparte thread in de wachtrij te plaatsen.
In die tijd waren Linux kernel commit-berichten helaas niet zo uitgebreid als tegenwoordig, dus er zijn geen prestatiegegevens beschikbaar.
In 2015 begon dm-crypt met het sorteren van schrijfopdrachten in een aparte “dmcrypt_write”-thread voordat deze naar de stack werden gestuurd:
Op een multiprocessormachine eindigen encryptieverzoeken in een andere volgorde dan waarin ze zijn ingediend. Bijgevolg zouden schrijfverzoeken in een andere volgorde worden ingediend en dit zou een ernstige prestatievermindering kunnen veroorzaken.
Het is wel logisch, aangezien sequentiële schijftoegang vroeger veel sneller was dan de willekeurige en dm-crypt dit patroon doorbrak. Maar dit geldt vooral voor draaiende schijven, die in 2015 nog dominant waren. Het is misschien niet zo belangrijk met moderne snelle SSD’s (inclusief NVME SSD’s).
Een ander deel van het commit-bericht is het vermelden waard:
…in het bijzonder stelt het IO schedulers zoals CFQ in staat om effectiever te sorteren…
Het vermeldt de prestatievoordelen voor de CFQ IO scheduler, maar Linux schedulers zijn sindsdien verbeterd tot het punt dat CFQ scheduler in 2018 uit de kernel is verwijderd.
Dezelfde patchset vervangt de sorteerlijst door een rood-zwarte boom:
In theorie zou het sorteren moeten worden uitgevoerd door de onderliggende schijfplanner, maar in de praktijk accepteert en sorteert de schijfplanner slechts een eindig aantal verzoeken. Om het sorteren van alle aanvragen mogelijk te maken, moet dm-crypt zijn eigen sortering implementeren.
De overhead geassocieerd met rbtree-gebaseerde sortering wordt als verwaarloosbaar beschouwd, dus het wordt niet voorwaardelijk gebruikt.
Dat klinkt allemaal logisch, maar het zou leuk zijn om wat ondersteunende gegevens te hebben.
In dezelfde patchset zien we de introductie van onze vertrouwde “submit_from_crypt_cpus”-optie:
Er zijn enkele situaties waarin het offloaden van schrijfbios van de encryptie-threads naar een enkele thread de prestaties aanzienlijk vermindert
Over het geheel genomen kunnen we zien dat elke verandering redelijk en nodig was, maar sindsdien zijn er dingen veranderd:
- hardware werd sneller en slimmer
- Linux resource-allocatie werd opnieuw bekeken
- gekoppelde Linux-subsystemen werden opnieuw gearchitectureerd
En veel van de bovenstaande ontwerpkeuzes zijn mogelijk niet van toepassing op moderne Linux.
De “clean-up”
Gebaseerd op bovenstaand onderzoek besloten we om te proberen alle extra queueing en asynchroon gedrag te verwijderen en dm-crypt terug te brengen naar zijn oorspronkelijke doel: eenvoudig IO verzoeken versleutelen/decoderen terwijl ze passeren. Maar omwille van de stabiliteit en verdere benchmarking hebben we uiteindelijk niet de eigenlijke code verwijderd, maar in plaats daarvan nog een dm-crypt optie toegevoegd, die alle wachtrijen/threads omzeilt, indien ingeschakeld. De vlag stelt ons in staat om te schakelen tussen het huidige en het nieuwe gedrag tijdens runtime onder volledige productiebelasting, zodat we onze wijzigingen gemakkelijk kunnen terugdraaien als we neveneffecten zien. De resulterende patch kan worden gevonden op de Cloudflare GitHub Linux repository.
Synchrone Linux Crypto API
Van het bovenstaande diagram herinneren we ons dat niet alle queueing is geïmplementeerd in dm-crypt. De moderne Linux Crypto API kan ook asynchroon zijn en omwille van dit experiment willen we ook daar wachtrijen elimineren. Maar wat betekent “kan zijn”? Het OS kan verschillende implementaties van hetzelfde algoritme bevatten (bijvoorbeeld, hardware-versnelde AES-NI op x86 platformen en generieke C-code AES implementaties). Standaard kiest het systeem het “beste” algoritme, gebaseerd op de ingestelde algoritme-prioriteit. dm-crypt maakt het mogelijk dit gedrag op te heffen en een bepaalde code-implementatie aan te vragen met het capi: voorvoegsel. Er is echter een probleem. Laten we eens kijken naar de beschikbare AES-XTS (dit is ons schijfversleutelingscijfer, weet je nog?) implementaties op ons systeem:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64We willen expliciet een synchroon cijfer kiezen uit bovenstaande lijst om wachtrij-effecten in threads te voorkomen, maar de enige twee ondersteunde zijn xts(ecb(aes-generic)) (de generieke C implementatie) en __xts-aes-aesni (de x86 hardware-versnelde implementatie). We willen absoluut de laatste omdat die veel sneller is (we mikken hier op performance), maar hij is verdacht gemarkeerd als intern (zie internal: yes). Als we de broncode bekijken:
Markeer een cijfer als een service-implementatie die alleen bruikbaar is door een ander cijfer en nooit door een normale gebruiker van de kernel crypto API
Dus dit cijfer is bedoeld om alleen te worden gebruikt door andere wikkelcode in de Crypto API en niet daarbuiten. In de praktijk betekent dit, dat de aanroeper van de Crypto API expliciet deze vlag moet specificeren, wanneer hij een bepaalde code-implementatie aanvraagt, maar dm-crypt doet dit niet, omdat het volgens het ontwerp geen deel uitmaakt van de Linux Crypto API, maar een “externe” gebruiker is. We patchen de dm-crypt module al, dus we kunnen net zo goed gewoon de relevante vlag toevoegen. Er is echter nog een probleem met AES-NI in het bijzonder: x86 FPU. “Floating point” zegt u? Waarom hebben we drijvende komma wiskunde nodig om symmetrische encryptie te doen die alleen over bit shifts en XOR operaties zou moeten gaan? We hebben de wiskunde niet nodig, maar AES-NI instructies gebruiken enkele van de CPU registers, die zijn gereserveerd voor de FPU. Helaas bewaart de Linux kernel deze registers niet altijd in interrupt context om prestatieredenen (opslaan/herstellen van FPU is duur). Maar dm-crypt kan code uitvoeren in interrupt context, dus we riskeren dat we andere proces gegevens beschadigen en we gaan terug naar “het zou zeer onverstandig zijn om decryptie te doen in een interrupt context” verklaring in de originele code.
Onze oplossing om het bovenstaande aan te pakken was om een andere ietwat “slimme” Crypto API module te maken. Deze module is synchroon en rolt niet zijn eigen crypto, maar is slechts een “router” van encryptie verzoeken:
- als we de FPU (en dus AES-NI) in de huidige uitvoeringscontext kunnen gebruiken, sturen we het encryptieverzoek gewoon door naar de snellere, “interne”
__xts-aes-aesniimplementatie (en die kunnen we hier gebruiken, omdat we nu deel uitmaken van de Crypto API) - anders sturen we het encryptie verzoek gewoon door naar de langzamere, generieke C-gebaseerde
xts(ecb(aes-generic))implementatie
Het geheel gebruiken
Laten we eens door het proces lopen om het allemaal samen te gebruiken. De eerste stap is om de patches te pakken en de kernel opnieuw te compileren (of alleen dm-crypt en onze xtsproxy modules te compileren).
Volgende, laten we onze IO werklast herstarten in een aparte terminal, zodat we er zeker van kunnen zijn dat we de kernel kunnen herconfigureren tijdens runtime onder belasting:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...In de hoofdterminal ervoor zorgen dat onze nieuwe Crypto API module is geladen en beschikbaar is:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Configureer de versleutelde schijf om onze nieuw geladen module te gebruiken en activeer onze gepatchte dm-crypt vlag (we moeten low-level dmsetup tool gebruiken omdat cryptsetup uiteraard niet op de hoogte is van onze wijzigingen):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0We hebben zojuist de nieuwe configuratie “geladen”, maar om het effect te laten hebben, moeten we het versleutelde apparaat opschorten/hervatten:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0En nu het resultaat observeren. We kunnen teruggaan naar de andere terminal die de fio job uitvoert en naar de uitvoer kijken, maar om het wat leuker te maken, is hier een momentopname van de waargenomen lees/schrijf doorvoer in Grafana:
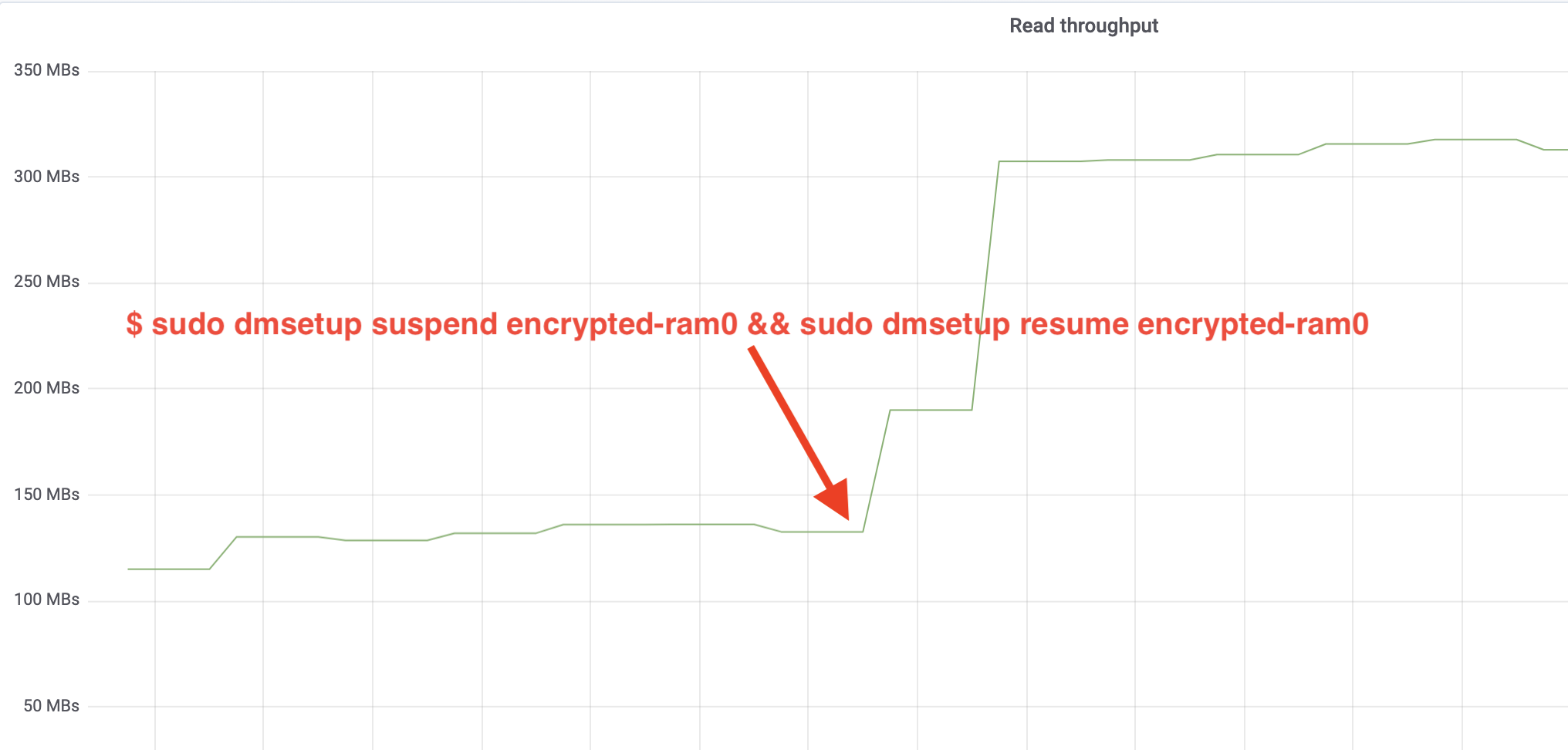
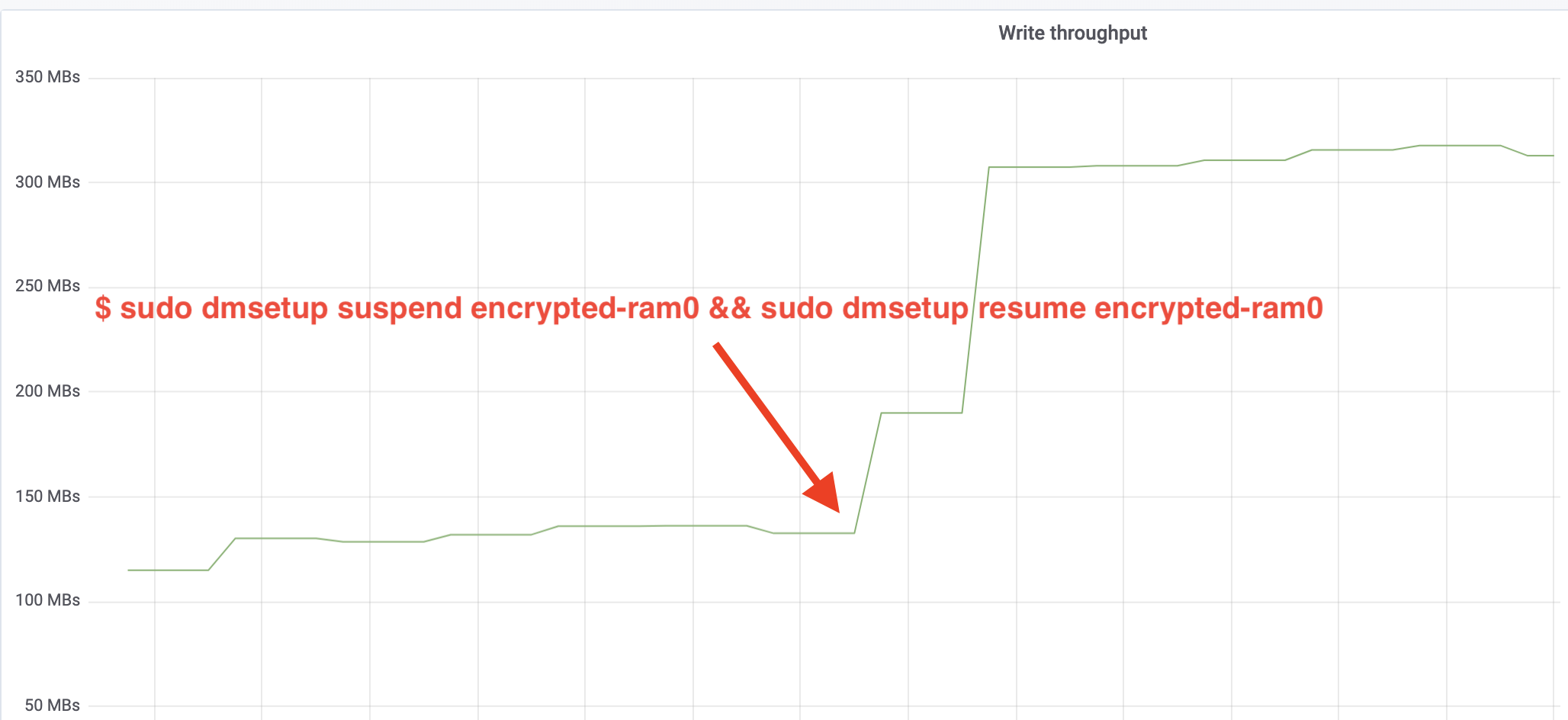
Wauw, we hebben de doorvoer meer dan verdubbeld! Met de totale doorvoer van ~640 MB/s zitten we nu veel dichter bij de verwachte ~696 MB/s van hierboven. Hoe zit het met de IO latency? (De await statistiek van de iostat rapportage tool):
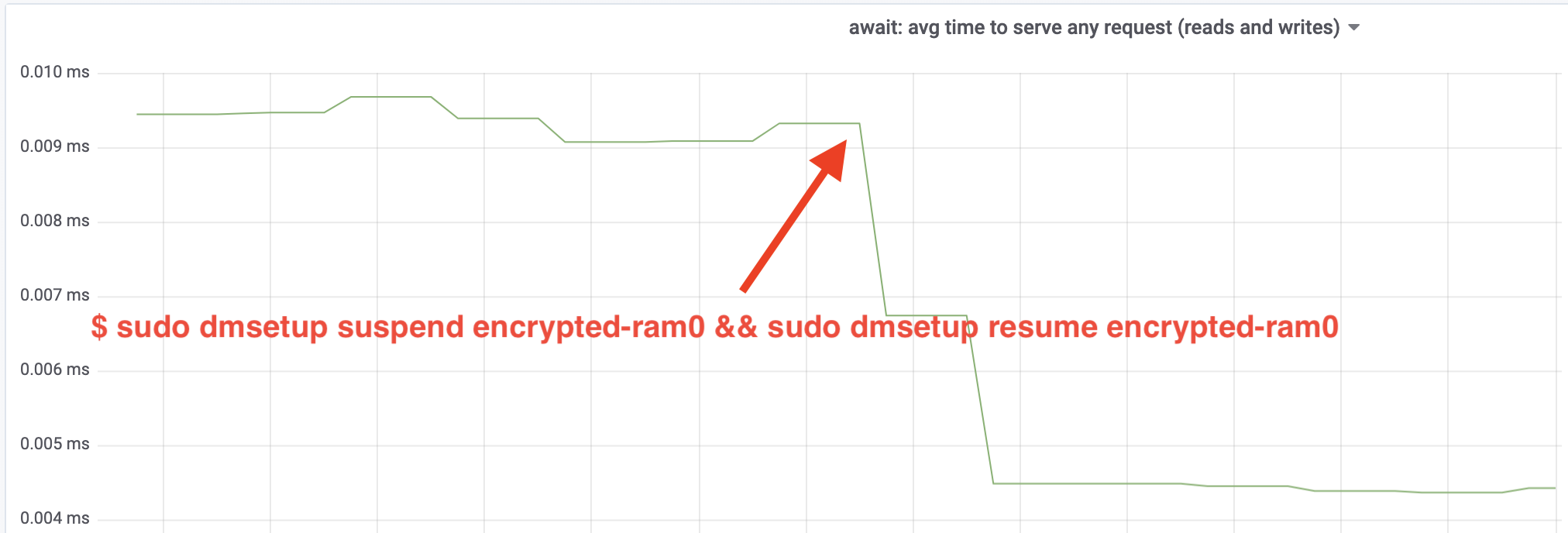
De latency is ook gehalveerd!
Naar productie
Tot nu toe hebben we een synthetische setup gebruikt waarbij sommige delen van de volledige productie stack ontbraken, zoals bestandssystemen, echte hardware en het belangrijkste, de productie werklast. Om er zeker van te zijn dat we geen denkbeeldige dingen optimaliseren, is hier een momentopname van de productie-impact die deze wijzigingen hebben op het caching-gedeelte van onze stack:

Deze grafiek toont een vergelijking in drie richtingen van de slechtst denkbare responstijden (99e percentiel) voor een cache-hit in een van onze servers. De groene lijn is van een server met ongecodeerde schijven, die we als basislijn zullen gebruiken. De rode lijn is van een server met versleutelde schijven met de standaard Linux schijfversleuteling implementatie en de blauwe lijn is van een server met versleutelde schijven en onze optimalisaties ingeschakeld. Zoals we kunnen zien heeft de standaard Linux disk encryptie implementatie een significante impact op onze cache latency in worst-case scenario’s, terwijl de verbeterde implementatie niet te onderscheiden is van geen encryptie gebruiken. Met andere woorden, de verbeterde encryptie-implementatie heeft geen enkele invloed op onze cache response snelheid, dus we krijgen het in principe gratis! Dat is winst!
We zijn nog maar net begonnen
Dit bericht laat zien hoe een architectuur-herziening de prestaties van een systeem kan verdubbelen. Ook hebben we opnieuw bevestigd dat moderne cryptografie niet duur is en dat er meestal geen excuus is om je gegevens niet te beschermen.
We gaan dit werk indienen voor opname in de kernel source tree, maar waarschijnlijk niet in de huidige vorm. Hoewel de resultaten er bemoedigend uitzien, moeten we niet vergeten dat Linux een zeer draagbaar besturingssysteem is: het draait zowel op krachtige servers als op kleine IoT-apparaten met beperkte middelen en ook op veel andere CPU-architecturen. De huidige versie van de patches optimaliseert alleen de schijfversleuteling voor een bepaalde werklast op een bepaalde architectuur, maar Linux heeft een oplossing nodig die overal soepel draait.
Dat gezegd hebbende, als je denkt dat je geval vergelijkbaar is en je wilt nu profiteren van de prestatieverbeteringen, kun je de patches pakken en hopelijk feedback geven. De runtime flag maakt het eenvoudig om de functionaliteit on the fly aan te zetten en een eenvoudige A/B test kan worden uitgevoerd om te zien of het een bepaalde case of setup ten goede komt. Deze patches hebben gedraaid in ons brede netwerk van meer dan 200 datacenters op vijf generaties hardware, dus kunnen redelijk stabiel worden geacht. Geniet van de prestaties en veiligheid van Cloudflare voor iedereen!

Update (11 oktober 2020)
De belangrijkste patch uit deze blog (in een licht aangepaste vorm) is samengevoegd in de mainline Linux-kernel en is beschikbaar vanaf versie 5.9 en hoger. Het belangrijkste verschil is dat de mainline versie twee vlaggen blootstelt in plaats van één, die de mogelijkheid bieden om dm-crypt werkqueues voor lezen en schrijven onafhankelijk te omzeilen. Voor details, zie de officiële dm-crypt documentatie.