
Voordat ik begon aan deze reis om informatica te leren, waren er bepaalde termen en zinsdelen waardoor ik de andere kant op wilde rennen.
Maar in plaats van te rennen, veinsde ik dat ik er verstand van had, knikte ik mee in gesprekken en deed ik alsof ik wist waar iemand het over had, ook al had ik in werkelijkheid geen idee en was ik eigenlijk helemaal gestopt met luisteren toen ik die super enge computerwetenschapsterm™ hoorde. In de loop van deze serie ben ik erin geslaagd veel te behandelen en veel van die termen zijn een stuk minder eng geworden!
Er is echter één grote, die ik een tijdje heb vermeden. Tot nu toe, als ik deze term hoorde, voelde ik me verlamd. Het kwam ter sprake in informele gesprekken op meet-ups en soms in conferentiegesprekken. Elke keer weer denk ik aan machines die ronddraaien en computers die reeksen code uitspugen die niet te ontcijferen zijn, behalve dat alle anderen om me heen ze wel kunnen ontcijferen, zodat ik eigenlijk alleen ben die niet weet wat er aan de hand is (whoops hoe is dit gebeurd?!).
Misschien ben ik niet de enige die zich zo heeft gevoeld. Maar, ik veronderstel dat ik je moet vertellen wat deze term eigenlijk is, toch? Nou, maak je klaar, want ik heb het over de altijd ongrijpbare en schijnbaar verwarrende abstract syntax tree, of kortweg AST. Na vele jaren geïntimideerd te zijn geweest, ben ik opgewonden om eindelijk niet meer bang te zijn voor deze term en echt te begrijpen wat het in hemelsnaam is.
Het is tijd om de wortel van de abstracte syntax boom onder ogen te zien – en ons parsing spel op een hoger niveau te brengen!
Elke goede zoektocht begint met een solide basis, en onze missie om deze structuur te demystificeren moet op precies dezelfde manier beginnen: met een definitie, natuurlijk!
Een abstracte syntaxisboom (meestal gewoon een AST genoemd) is eigenlijk niets meer dan een vereenvoudigde, verkorte versie van een parse tree. In de context van compilerontwerp wordt de term “AST” door elkaar gebruikt met syntax tree.

We denken vaak na over syntaxisbomen (en hoe ze zijn opgebouwd) in vergelijking met hun parse tree tegenhangers, waar we al behoorlijk vertrouwd mee zijn. We weten dat parse trees boomdatastructuren zijn die de grammaticale structuur van onze code bevatten; met andere woorden, ze bevatten alle syntactische informatie die in een “zin” van een code voorkomt, en is rechtstreeks afgeleid van de grammatica van de programmeertaal zelf.
Een abstracte syntaxisboom daarentegen negeert een aanzienlijke hoeveelheid van de syntatische informatie die een parse tree anders zou bevatten.
Een AST bevat daarentegen alleen de informatie die betrekking heeft op het analyseren van de brontekst, en slaat alle andere extra inhoud over die wordt gebruikt bij het parseren van de tekst.
Dit onderscheid wordt duidelijker als we ons concentreren op de “abstractheid” van een AST.
We zullen ons herinneren dat een parse tree een geïllustreerde, illustratieve versie is van de grammaticale structuur van een zin. Met andere woorden, we kunnen zeggen dat een parse tree precies weergeeft hoe een uitdrukking, zin of tekst eruit ziet. Het is in feite een directe vertaling van de tekst zelf; we nemen de zin en zetten elk klein stukje ervan – van de interpunctie tot de uitdrukkingen tot de tokens – om in een boomstructuur. Het onthult de concrete syntaxis van een tekst, daarom wordt het ook wel een concrete syntaxisboom, of CST, genoemd. We gebruiken de term concreet om deze structuur te beschrijven omdat het een grammaticale kopie is van onze code, token voor token, in boomformaat.
Maar wat maakt iets concreet tegenover abstract? Nou, een abstracte syntax boom laat ons niet precies zien hoe een expressie eruit ziet, zoals een parse tree dat doet.

In plaats daarvan laat een abstracte syntaxisboom ons de “belangrijke” stukjes zien – de dingen waar we echt om geven, die betekenis geven aan onze code-“zin” zelf. Syntaxbomen tonen ons de belangrijke stukken van een uitdrukking, of de geabstraheerde syntaxis van onze brontekst. In vergelijking met concrete syntaxbomen zijn deze structuren dus abstracte representaties van onze code (en in sommige opzichten minder exact), en dat is precies hoe ze hun naam hebben gekregen.
Nu we het onderscheid begrijpen tussen deze twee datastructuren en de verschillende manieren waarop ze onze code kunnen representeren, is het de moeite waard de vraag te stellen: waar past een abstracte syntaxboom in de compiler? Laten we onszelf eerst herinneren aan alles wat we tot nu toe weten over het compilatieproces.

Laten we zeggen dat we een superkorte en zoete brontekst hebben, die er als volgt uitziet: 5 + (1 x 12).
We herinneren ons dat het eerste wat gebeurt in het compilatieproces het scannen van de tekst is, een taak die wordt uitgevoerd door de scanner, die resulteert in het opdelen van de tekst in de kleinst mogelijke delen, die lexemen worden genoemd. Dit deel zal taal-onafhankelijk zijn, en we zullen eindigen met de gestripte versie van onze brontekst.
Daarna worden deze lexemen doorgegeven aan de lexer/tokenizer, die deze kleine representaties van onze brontekst omzet in tokens, die specifiek zullen zijn voor onze taal. Onze tokens zullen er ongeveer zo uitzien: . De gezamenlijke inspanning van de scanner en de tokenizer vormen de lexicale analyse van de compilatie.
Zodra onze invoer getoken is, worden de resulterende tokens doorgegeven aan onze parser, die dan de brontekst neemt en er een parse tree van maakt. De onderstaande illustratie laat zien hoe onze getoken code eruit ziet, in parse tree-indeling.
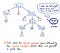
Het werk van het omzetten van tokens in een parse tree wordt ook wel parsing genoemd, en staat bekend als de syntaxis-analysefase. De syntaxis-analyse is direct afhankelijk van de lexicale analyse; de lexicale analyse moet dus altijd als eerste in het compilatieproces aan de orde komen, omdat de parser van onze compiler zijn werk pas kan doen als de tokenizer zijn werk heeft gedaan!
We kunnen de onderdelen van de compiler zien als goede vrienden, die allemaal van elkaar afhankelijk zijn om ervoor te zorgen dat onze code correct wordt omgezet van een tekst of bestand in een parse tree.
Maar terug naar onze oorspronkelijke vraag: waar past de abstracte syntaxboom in deze vriendengroep? Om die vraag te kunnen beantwoorden, moeten we eerst de noodzaak van een AST begrijpen.
Het samenvoegen van de ene boom in de andere
Okee, nu hebben we dus twee bomen om in ons hoofd recht te houden. We hadden al een parse tree, en nu moeten we nog een andere gegevensstructuur leren! En blijkbaar is deze AST-gegevensstructuur gewoon een vereenvoudigde parse tree. Dus, waarom hebben we het nodig? Wat is eigenlijk het nut ervan?
Wel, laten we eens kijken naar onze parse tree, zullen we?
We weten al dat parse trees ons programma in zijn meest verschillende delen weergeven; dit was inderdaad de reden waarom de scanner en de tokenizer zo’n belangrijke taak hebben om onze expressie in zijn kleinste delen op te splitsen!
Wat betekent het eigenlijk om een programma in zijn meest verschillende delen weer te geven?
Zoals blijkt, zijn soms alle afzonderlijke delen van een programma eigenlijk niet altijd zo nuttig voor ons.
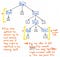
Laten we eens kijken naar de hier getoonde illustratie, die onze oorspronkelijke expressie, 5 + (1 x 12), weergeeft in de vorm van een parse tree. Als we deze boom met een kritisch oog bekijken, zien we dat er een paar gevallen zijn waarin een knooppunt precies één kind heeft. Deze knooppunten worden ook wel “single-successor”-knooppunten genoemd, omdat ze maar één kindknooppunt hebben dat uit hen voortkomt (oftewel één “opvolger”).
In het geval van ons parse tree voorbeeld, hebben de single-successor nodes een parent node van een Expression, of Exp, die een enkele opvolger hebben van een bepaalde waarde, zoals 5, 1, of 12. Echter, de Exp parent nodes hier voegen eigenlijk niets van waarde aan ons toe, of wel? We kunnen zien dat ze token/terminal child nodes bevatten, maar we geven niet echt om de “expression” parent node; alles wat we echt willen weten is wat de expressie is?
De parent node geeft ons helemaal geen extra informatie als we onze boom hebben geparseerd. In plaats daarvan zijn we echt bezorgd over het enige kind, enkele opvolger knoop. Dat is namelijk het knooppunt dat ons de belangrijke informatie geeft, het deel dat voor ons van belang is: het getal en de waarde zelf! Gezien het feit dat deze parent nodes voor ons nogal overbodig zijn, wordt het duidelijk dat deze parse tree een soort verbose is.
Al deze single-successor nodes zijn voor ons behoorlijk overbodig, en helpen ons helemaal niet. Laten we ze dus weggooien!
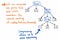
Als we de single-successor nodes in onze parse tree comprimeren, krijgen we een meer gecomprimeerde versie van exact dezelfde structuur. Als we naar de bovenstaande illustratie kijken, zien we dat we nog steeds exact dezelfde nesten als voorheen behouden, en dat onze nodes/tokens/terminals nog steeds op de juiste plaats in de boom verschijnen. Maar we zijn er wel in geslaagd om het wat slanker te maken.
En we kunnen ook nog wat meer van onze boom bijknippen. Als we bijvoorbeeld kijken naar onze huidige parse tree, dan zien we dat er een spiegelstructuur in zit. De sub-expressie van (1 x 12) is genest binnen haakjes (), die op zichzelf al tokens zijn.
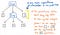
Deze haakjes helpen ons echter niet echt als we onze tree eenmaal hebben staan. We weten al dat 1 en 12 argumenten zijn die zullen worden doorgegeven aan de vermenigvuldigingsoperatie x, dus de haakjes zeggen ons op dit punt niet zo veel. In feite zouden we onze parse tree nog verder kunnen comprimeren en ons ontdoen van deze overbodige bladknopen.
Als we eenmaal onze parse tree comprimeren en vereenvoudigen en ons ontdoen van het overbodige syntactische “stof”, eindigen we met een structuur die er op dit punt zichtbaar anders uitziet. Die structuur is in feite onze nieuwe en langverwachte vriend: de abstracte syntaxisboom.

De afbeelding hierboven illustreert exact dezelfde uitdrukking als onze parse tree: 5 + (1 x 12). Het verschil is dat de uitdrukking is geabstraheerd van de concrete syntaxis. We zien geen haakjes meer () in deze boom, omdat ze niet nodig zijn. Evenzo zien we geen niet-terminalen als Exp, omdat we al hebben bedacht wat de “expressie” is, en we in staat zijn om de waarde die er voor ons echt toe doet eruit te halen – bijvoorbeeld het getal 5.
Dit is precies de onderscheidende factor tussen een AST en een CST. We weten dat een abstracte syntaxboom een aanzienlijke hoeveelheid van de syntactische informatie die een parse tree bevat negeert, en “extra inhoud” overslaat die bij het parsen wordt gebruikt. Maar nu kunnen we precies zien hoe dat gebeurt!

Nu we zelf een parse tree hebben gecondenseerd, zullen we veel beter in staat zijn om enkele patronen op te pikken die een AST onderscheiden van een CST.
Er zijn een paar manieren waarop een abstracte syntaxisboom visueel verschilt van een parse tree:
- Een AST zal nooit syntactische details bevatten, zoals komma’s, haakjes en puntkomma’s (afhankelijk, natuurlijk, van de taal).
- Een AST zal samengevouwen versies hebben van wat anders zou verschijnen als enkelvoudige opeenvolgende knooppunten; zij zal nooit “ketens” bevatten van knooppunten met een enkel kind.
- Tot slot zullen alle operator-tokens (zoals
+,-,x, en/) interne (parent) nodes in de boom worden, in plaats van de bladeren die in een parse tree eindigen.
Visueel zal een AST altijd compacter lijken dan een parse tree, omdat het per definitie een gecomprimeerde versie van een parse tree is, met minder syntactische details.
Het zou dan ook logisch zijn dat, als een AST een gecomprimeerde versie van een parse tree is, we pas echt een abstracte syntaxisboom kunnen maken als we om te beginnen de dingen hebben om een parse tree te maken!
Dit is inderdaad hoe de abstracte syntaxisboom in het grotere compilatieproces past. Een AST heeft een directe verbinding met de parse trees waarover we al hebben geleerd, terwijl hij tegelijkertijd afhankelijk is van de lexer om zijn werk te doen voordat er ooit een AST kan worden gemaakt.

De abstracte syntaxisboom wordt gecreëerd als eindresultaat van de syntaxisanalyse-fase. De parser, die tijdens de syntaxisanalyse als belangrijkste “personage” naar voren komt, genereert al dan niet altijd een parse tree, of CST. Afhankelijk van de compiler zelf, en hoe die ontworpen is, kan de parser direct overgaan tot het construeren van een syntax tree, of AST. Maar de parser zal altijd een AST als uitvoer genereren, ongeacht of hij tussendoor een parse tree maakt, of hoeveel stappen hij daarvoor moet nemen.
Anatomie van een AST
Nu we weten dat de abstracte syntax tree belangrijk is (maar niet per se intimiderend!), kunnen we beginnen hem een klein beetje meer te ontleden. Een interessant aspect van hoe de AST is opgebouwd heeft te maken met de nodes van deze boom.
De onderstaande afbeelding is een voorbeeld van de anatomie van een enkele node binnen een abstracte syntaxisboom.
We zullen zien dat deze node lijkt op andere die we eerder hebben gezien, in die zin dat hij een aantal gegevens bevat (een token en zijn value). Hij bevat echter ook een aantal zeer specifieke verwijzingen. Elke node in een AST bevat verwijzingen naar zijn volgende sibling node, evenals naar zijn eerste child node.
Zo zou bijvoorbeeld onze eenvoudige uitdrukking 5 + (1 x 12) kunnen worden geconstrueerd in een gevisualiseerde illustratie van een AST, zoals hieronder.
We kunnen ons voorstellen dat het lezen, doorkruisen, of “interpreteren” van deze AST zou kunnen beginnen bij de onderste niveaus van de boom, en zo naar boven zou kunnen werken om aan het eind een waarde of een return result op te bouwen.
Het kan ook helpen om een gecodeerde versie van de uitvoer van een parser te zien om onze visualisaties aan te vullen. We kunnen leunen op verschillende hulpmiddelen en reeds bestaande parsers gebruiken om een snel voorbeeld te zien van hoe onze uitdrukking eruit zou kunnen zien wanneer die door een parser wordt gehaald. Hieronder staat een voorbeeld van onze brontekst, 5 + (1 * 12), die door Esprima, een ECMAScript parser, is gehaald en de resulterende abstracte syntax boom, gevolgd door een lijst van de verschillende tokens.
In dit formaat kunnen we de nesting van de boom zien als we naar de geneste objecten kijken. We zullen zien dat de waarden die 1 en 12 bevatten, respectievelijk de left en right kinderen zijn van een ouderbewerking, *. We zullen ook zien dat de vermenigvuldigingsoperatie (*) de rechter subtree vormt van de gehele expressie zelf, en daarom is genest binnen het grotere BinaryExpression object, onder de sleutel "right". Op dezelfde manier is de waarde van 5 het enige "left" kind van het grotere BinaryExpression object.

Het meest intrigerende aspect van de abstracte syntaxisboom is echter het feit dat, ook al zijn ze nog zo compact en schoon, ze niet altijd een gemakkelijke gegevensstructuur zijn om te proberen te construeren. In feite kan het bouwen van een AST behoorlijk complex zijn, afhankelijk van de taal waarmee de parser te maken heeft!
De meeste parsers zullen gewoonlijk ofwel een parse tree (CST) construeren en die dan converteren naar een AST-formaat, omdat dat soms gemakkelijker kan zijn – ook al betekent het meer stappen, en in het algemeen, meer passen door de brontekst. Het bouwen van een CST is eigenlijk vrij eenvoudig zodra de parser de grammatica kent van de taal die hij probeert te parsen. Het hoeft geen ingewikkeld werk te doen om uit te zoeken of een token “significant” is of niet; in plaats daarvan neemt het gewoon precies wat het ziet, in de specifieke volgorde waarin het het ziet, en spuugt het allemaal uit in een boom.
Aan de andere kant zijn er sommige parsers die zullen proberen om dit alles te doen als een proces in één stap, waarbij ze meteen overgaan tot het construeren van een abstracte syntaxisboom.
Het direct opbouwen van een AST kan lastig zijn, omdat de parser niet alleen de tokens moet vinden en correct moet weergeven, maar ook moet beslissen welke tokens er voor ons toe doen en welke niet.
In compilerontwerp is de AST uiteindelijk om meer dan één reden superbelangrijk. Ja, het kan lastig zijn om het te construeren (en waarschijnlijk gemakkelijk te verknoeien), maar het is ook het laatste en definitieve resultaat van de gecombineerde lexicale en syntaxis-analyse-fasen! De lexicale en syntax analyse fasen worden vaak samen de analyse fase genoemd, of het front-end van de compiler.

We kunnen over de abstracte syntax boom denken als het “eindproject” van het front-end van de compiler. Het is het belangrijkste deel, omdat het het laatste is wat de front-end voor zichzelf moet laten zien. De technische term hiervoor heet de intermediate code representation of de IR, omdat het de datastructuur wordt die uiteindelijk door de compiler wordt gebruikt om een brontekst weer te geven.
Een abstracte syntaxisboom is de meest voorkomende vorm van IR, maar ook, soms de meest verkeerd begrepen. Maar nu we het een beetje beter begrijpen, kunnen we beginnen om onze perceptie van deze enge structuur te veranderen! Hopelijk is het nu een beetje minder intimiderend voor ons.
Bronnen
Er zijn een heleboel bronnen over ASTs, in verschillende talen. Weten waar je moet beginnen kan lastig zijn, vooral als je meer wilt leren. Hieronder vind je een paar beginnersvriendelijke bronnen die dieper op de materie ingaan zonder te veel te vergen. Happy asbtracting!
- The AST vs the Parse Tree, Professor Charles N. Fischer
- Wat is het verschil tussen parse trees en abstract syntax trees? StackOverflow
- Abstract vs. Concrete Syntax Trees, Eli Bendersky
- Abstract Syntax Trees, Professor Stephen A. Edwards
- Abstract Syntax Trees & Top-Down Parsing, Professor Konstantinos (Kostis) Sagonas
- Lexical and Syntax Analysis of Programming Languages, Chris Northwood
- AST Explorer, Felix Kling