Inleiding
Als u uw gegevens analyseert met behulp van meervoudige regressie en een van uw onafhankelijke variabelen is gemeten op een nominale of ordinale schaal, moet u weten hoe u dummyvariabelen kunt maken en de resultaten ervan kunt interpreteren. De reden hiervoor is dat nominale en ordinale onafhankelijke variabelen, meer algemeen bekend als categorische onafhankelijke variabelen, niet rechtstreeks in een meervoudige regressieanalyse kunnen worden ingevoerd. In plaats daarvan moeten zij worden omgezet in dummy-variabelen. Een uitzondering vormen ordinale onafhankelijke variabelen die in een meervoudige regressie worden ingevoerd als continue onafhankelijke variabelen, die niet in dummyvariabelen hoeven te worden omgezet. Daarom laten we in deze handleiding zien hoe u dummyvariabelen kunt maken wanneer u categorische onafhankelijke variabelen hebt.
Eerst geven we het voorbeeld dat we gebruiken om te laten zien hoe u dummyvariabelen kunt maken in SPSS Statistics, voordat we uitleggen hoe u uw gegevens in de vensters Variable View en Data View van SPSS Statistics zo instelt dat u dummyvariabelen kunt maken. Als u niet bekend bent met het gebruik van dummy-variabelen, raden wij u aan eerst enkele basisprincipes van dummy-variabelen en dummy-codering door te nemen, waaronder: (a) het aantal dummy-variabelen dat u in uw analyse moet maken; en (b) hoe u dummy-variabelen en dummy-codering maakt. In het gedeelte Procedure dat volgt, beschrijven we de eenvoudige, uit 3 stappen bestaande procedure Create Dummy Variables in SPSS Statistics die kan worden gebruikt om dummyvariabelen te creëren. Tenslotte leggen we de SPSS Statistics-uitvoer uit na het uitvoeren van de Create Dummy Variables-procedure, inclusief de manier waarop uw dummyvariabelen nu zullen worden ingesteld in de vensters Variable View en Data View van SPSS Statistics.
Note: Als u vindt dat de procedures in deze gids niet het type dummyvariabelen bestrijken dat u wilt maken, neem dan contact met ons op. Misschien kunnen we een andere gids op de site zetten om u te helpen.
SPSS Statistics
Voorbeeld gebruikt in deze gids
In deze gids gebruiken we het voorbeeld van 10 triatleten aan wie werd gevraagd hun favoriete sport te kiezen uit de drie sporten die ze beoefenen bij een triatlon: zwemmen, fietsen en hardlopen. Hun antwoorden werden geregistreerd in de nominale onafhankelijke variabele, favoriete_sport, die drie categorieën heeft: “zwemmen”, “fietsen” en “hardlopen”. Deze nominale onafhankelijke variabele, favoriete_sport, moest worden opgenomen in een meervoudige regressieanalyse die ook een aantal continue onafhankelijke variabelen bevatte. Aangezien deze onafhankelijke variabele categorisch was (d.w.z. nominale variabelen en ordinale variabelen kunnen grofweg worden geclassificeerd als categorische variabelen), moesten dummy-variabelen worden gecreëerd voordat ze in de meervoudige regressieanalyse kon worden ingevoerd.
Belangrijk: Merk op dat favoriete_sport een nominale variabele is, maar u kunt ook dummy-variabelen creëren voor een ordinale variabele. Bovendien is het proces voor het maken van dummyvariabelen hetzelfde, ongeacht of u een ordinale of nominale variabele hebt, met uitzondering van één kleine wijziging die u moet aanbrengen bij het opzetten van uw gegevens, die hieronder wordt uitgelegd.
Opmerking 1: De “categorieën” van een categorische onafhankelijke variabele worden ook wel “groepen” of “niveaus” genoemd, maar de term “niveaus” wordt gewoonlijk gereserveerd voor categorieën die een volgorde hebben (de ordinale onafhankelijke variabele, “fitnessniveau”, kan bijvoorbeeld drie niveaus hebben: “laag”, “gemiddeld” en “hoog”). Deze drie termen – “categorieën”, “groepen” en “niveaus” – kunnen echter door elkaar worden gebruikt. In deze gids zullen wij naar hen verwijzen als categorieën, maar u kunt naar hen verwijzen als groepen of niveaus als u verkiest.
Note 2: De term “factoren” wordt soms gebruikt in plaats van “categorische onafhankelijke variabelen” (d.w.z. onafhankelijke variabelen die “ordinaal” of “nominaal” zijn). Deze twee termen – “categorische onafhankelijke variabelen” en “factoren” – kunnen echter door elkaar worden gebruikt. In deze handleiding verwijzen we ernaar als categorische onafhankelijke variabelen en u zult ook zien dat SPSS Statistics ernaar verwijst als onafhankelijke variabelen in plaats van factoren in zijn meervoudige regressieprocedure. U kunt ze echter desgewenst als factoren aanduiden.
SPSS Statistics
Het opzetten van uw gegevens in SPSS Statistics
Bij het maken van dummy-variabelen begint u met een enkele categorische onafhankelijke variabele (bijv. favoriete_sport). Om deze categorische onafhankelijke variabele op te zetten, beschikt SPSS Statistics over een Variabeleweergave waarin u het type variabele definieert dat u analyseert en een Gegevensweergave waarin u uw gegevens voor deze variabele invoert. In dit gedeelte laten we eerst zien hoe u een categorische onafhankelijke variabele instelt in het venster Variable View van SPSS Statistics, voordat u laat zien hoe u uw gegevens invoert in het venster Data View. We doen dit met onze categorische onafhankelijke variabele, favoriete_sport, die drie categorieën heeft: “zwemmen”, “fietsen” en “hardlopen”.
De Variabele Weergave in SPSS Statistics
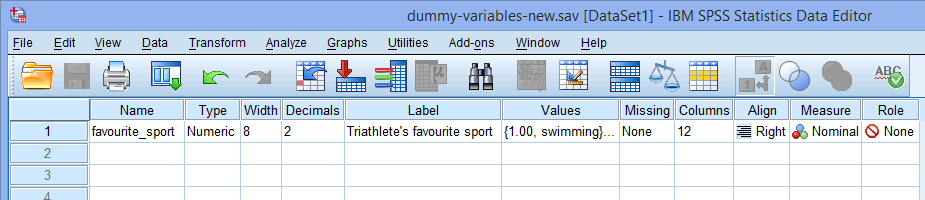
Voor een enkele categorische onafhankelijke variabele (bijv, favoriete_sport) ziet uw venster Variabeleweergave eruit als hieronder:
Noot: U kunt het venster Variabeleweergave in SPSS Statistics openen door te klikken op het tabblad ![]() in de linkerbenedenhoek van de SPSS Statistics-software.
in de linkerbenedenhoek van de SPSS Statistics-software.
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
De naam van uw categorische onafhankelijke variabele moet worden ingevoerd in de cel onder de kolom ![]() (bijv, “favourite_sport” in rij
(bijv, “favourite_sport” in rij ![]() om onze categorische onafhankelijke variabele, favourite_sport, weer te geven. Er zijn bepaalde “illegale” tekens die niet in de cel
om onze categorische onafhankelijke variabele, favourite_sport, weer te geven. Er zijn bepaalde “illegale” tekens die niet in de cel ![]() kunnen worden ingevoerd. Als u daarom een foutmelding krijgt en u wilt dat wij een SPSS Statistics guide toevoegen om uit te leggen wat deze illegale tekens zijn, neem dan contact met ons op.
kunnen worden ingevoerd. Als u daarom een foutmelding krijgt en u wilt dat wij een SPSS Statistics guide toevoegen om uit te leggen wat deze illegale tekens zijn, neem dan contact met ons op.
Note: Voor uw eigen duidelijkheid kunt u ook een label geven voor uw variabelen in de ![]() kolom. Bijvoorbeeld, het label dat we hebben ingevoerd voor “favoriete_sport” was “Favoriete sport van de triatleet”.
kolom. Bijvoorbeeld, het label dat we hebben ingevoerd voor “favoriete_sport” was “Favoriete sport van de triatleet”.
De cel onder de kolom ![]() moet de informatie bevatten over de categorieën van uw categorische onafhankelijke variabele (bijvoorbeeld “zwemmen”, “fietsen” en “hardlopen” voor favoriete_sport. Om deze informatie in te voeren, klikt u in de cel onder de kolom
moet de informatie bevatten over de categorieën van uw categorische onafhankelijke variabele (bijvoorbeeld “zwemmen”, “fietsen” en “hardlopen” voor favoriete_sport. Om deze informatie in te voeren, klikt u in de cel onder de kolom ![]() voor uw onafhankelijke variabele. De knop
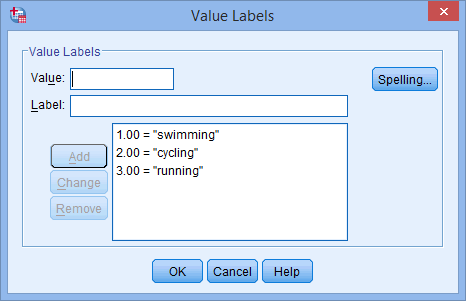
voor uw onafhankelijke variabele. De knop ![]() verschijnt in de cel. Klik op deze knop en het dialoogvenster Waardelabels verschijnt. U moet nu elke categorie van uw onafhankelijke variabele een “waarde” geven, die u in het vak Waarde: invoert (bijv. “1”), alsmede een “label”, dat u in het vak Label: invoert (bijv. “zwemmen”). Door op de
verschijnt in de cel. Klik op deze knop en het dialoogvenster Waardelabels verschijnt. U moet nu elke categorie van uw onafhankelijke variabele een “waarde” geven, die u in het vak Waarde: invoert (bijv. “1”), alsmede een “label”, dat u in het vak Label: invoert (bijv. “zwemmen”). Door op de ![]() knop te klikken verschijnt de codering in het hoofdvak (b.v. “1.00=”zwemmen” voor favoriete_sport). De opzet voor onze categorische onafhankelijke variabele wordt getoond in het dialoogvenster Waardelabels hieronder:
knop te klikken verschijnt de codering in het hoofdvak (b.v. “1.00=”zwemmen” voor favoriete_sport). De opzet voor onze categorische onafhankelijke variabele wordt getoond in het dialoogvenster Waardelabels hieronder:
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
In de cel onder de kolom ![]() moet
moet ![]() verschijnen als u een nominale onafhankelijke variabele hebt (bijv, favoriete_sport, zoals in ons voorbeeld) of
verschijnen als u een nominale onafhankelijke variabele hebt (bijv, favoriete_sport, zoals in ons voorbeeld) of ![]() als u een ordinale onafhankelijke variabele hebt (stel u bijvoorbeeld een ordinale variabele voor zoals “Body Mass Index” (BMI), BMI), die vier niveaus heeft: “Ondergewicht”, “Gezond/Normaal Gewicht”, “Overgewicht”, en “Zwaarlijvig”). Ten slotte moet de cel onder de kolom
als u een ordinale onafhankelijke variabele hebt (stel u bijvoorbeeld een ordinale variabele voor zoals “Body Mass Index” (BMI), BMI), die vier niveaus heeft: “Ondergewicht”, “Gezond/Normaal Gewicht”, “Overgewicht”, en “Zwaarlijvig”). Ten slotte moet de cel onder de kolom ![]()
![]() .
.
Noot: Wij stellen voor om de cel onder de kolom ![]() te wijzigen van
te wijzigen van ![]() in
in ![]() , maar u hoeft deze wijziging niet aan te brengen. Wij stellen voor dat u dit wel doet, omdat er bepaalde analyses in SPSS Statistics zijn waarbij de instelling
, maar u hoeft deze wijziging niet aan te brengen. Wij stellen voor dat u dit wel doet, omdat er bepaalde analyses in SPSS Statistics zijn waarbij de instelling ![]() tot gevolg heeft dat uw variabelen automatisch worden overgebracht naar bepaalde velden van de dialoogvensters die u gebruikt. Aangezien u deze variabelen wellicht niet wilt overdragen, raden wij u aan de instelling
tot gevolg heeft dat uw variabelen automatisch worden overgebracht naar bepaalde velden van de dialoogvensters die u gebruikt. Aangezien u deze variabelen wellicht niet wilt overdragen, raden wij u aan de instelling ![]() te wijzigen in
te wijzigen in ![]() , zodat dit niet automatisch gebeurt.
, zodat dit niet automatisch gebeurt.
U hebt nu met succes alle informatie die SPSS Statistics over uw categorische onafhankelijke variabele moet weten, ingevoerd in het venster Variable View. In de volgende sectie laten we zien hoe u uw gegevens in het venster Data View invoert.
The Data View in SPSS Statistics
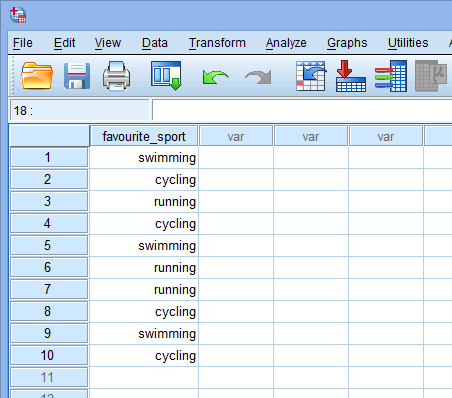
Op basis van de bestandsopstelling voor uw categorische onafhankelijke variabele in het venster Variable View hierboven, ziet het venster Data View er als volgt uit:
Note: U kunt het venster Data View in SPSS Statistics openen door te klikken op het tabblad ![]() in de linkerbenedenhoek van de SPSS Statistics-software.
in de linkerbenedenhoek van de SPSS Statistics-software.
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Uw categorische onafhankelijke variabele wordt in de eerste kolom weergegeven, aangezien dit de volgorde was waarin we de variabele in het venster Variabeleweergave hebben ingevoerd. In ons voorbeeld worden de antwoorden van de 10 triatleten weergegeven onder de kolom ![]() . U hoeft nu alleen nog maar uw gegevens in te voeren in de cellen onder deze eerste kolom. Vergeet niet dat elke rij één geval vertegenwoordigt (een geval kan bijvoorbeeld een enkele deelnemer zijn). Dus, in rij
. U hoeft nu alleen nog maar uw gegevens in te voeren in de cellen onder deze eerste kolom. Vergeet niet dat elke rij één geval vertegenwoordigt (een geval kan bijvoorbeeld een enkele deelnemer zijn). Dus, in rij ![]() van ons voorbeeld, vertegenwoordigt het eerste geval een triatleet wiens favoriete sport “zwemmen” was. Aangezien deze cellen aanvankelijk leeg zijn, moet u in de cellen klikken om uw gegevens in te voeren. U zult merken dat wanneer u in de cellen onder de kolom
van ons voorbeeld, vertegenwoordigt het eerste geval een triatleet wiens favoriete sport “zwemmen” was. Aangezien deze cellen aanvankelijk leeg zijn, moet u in de cellen klikken om uw gegevens in te voeren. U zult merken dat wanneer u in de cellen onder de kolom ![]() klikt, SPSS Statistics u een vervolgkeuzemogelijkheid geeft met uw categorieën al ingevuld.
klikt, SPSS Statistics u een vervolgkeuzemogelijkheid geeft met uw categorieën al ingevuld.
Nu u uw gegevens hebt ingesteld in de vensters Variable View en Data View van SPSS Statistics, raden wij u aan de volgende sectie te lezen: Inzicht in dummy-variabelen en dummy-codering, waarin we de basisprincipes van dummy-variabelen en dummy-codering uitleggen. Als u echter al bekend bent met de basisprincipes van dummy-variabelen en dummy-codering, kunt u deze sectie overslaan en direct naar de proceduresectie gaan, waar we de procedure Create Dummy Variables in SPSS Statistics uiteenzetten die wordt gebruikt om dummy-variabelen te creëren.
SPSS Statistics
Inzicht in dummy-variabelen en dummy-codering
Zoals we in de Inleiding hebben vermeld, moet u, als u uw gegevens analyseert met behulp van meervoudige regressie en een van uw onafhankelijke variabelen op een nominale of ordinale schaal is gemeten, weten hoe u dummy-variabelen maakt en de resultaten ervan interpreteert. Dit komt doordat categorische onafhankelijke variabelen (d.w.z. nominale en ordinale onafhankelijke variabelen) niet rechtstreeks in een meervoudige regressie kunnen worden ingevoerd. In plaats daarvan moeten zij worden omgezet in dummy-variabelen. Een uitzondering vormen ordinale onafhankelijke variabelen die in een meervoudige regressie worden ingevoerd als continue onafhankelijke variabelen, die niet in dummyvariabelen behoeven te worden omgezet. In de onderstaande paragrafen lichten wij toe: (a) het aantal dummyvariabelen dat u moet maken; en (b) hoe u dummyvariabelen en dummycodering maakt.
Het aantal dummyvariabelen dat u moet maken
Het aantal dummyvariabelen dat u moet maken, hangt af van het aantal categorieën dat uw categorische onafhankelijke variabele heeft. Als algemene regel geldt dat u één dummyvariabele minder maakt dan het aantal categorieën in uw categorische onafhankelijke variabele. Bijvoorbeeld, als u een categorische onafhankelijke variabele hebt met drie categorieën (bijv. favoriete_sport, met de volgende drie categorieën: “zwemmen”, “fietsen” en “hardlopen”), maak je twee dummyvariabelen en selecteer je één categorie om als referentiecategorie te fungeren (bijv. “zwemmen” en “fietsen” worden dummyvariabelen en “hardlopen” wordt de referentiecategorie). We leggen meer uit over referentiecategorieën na de volgende tabel, die enkele voorbeelden geeft van categorische onafhankelijke variabelen en het aantal dummyvariabelen dat moet worden aangemaakt:
| Naam van de categorische onafhankelijke variabele | Type variabele | Aantal categorieën | Aantal dummy-variabelen | ||||
|---|---|---|---|---|---|---|---|
| 1 | Gender | Nominal | Two (Males & Females) |
One=Males “Females” is de referentiecategorie |
|||
| 2 | Hoogte | Ordinaal | Twee (Onder 180cm & 180cm en hoger) |
Een=Onder 180cm “180cm en meer” is de referentiecategorie |
|||
| 3 | Ethniciteit | Nominaal | Drie (Afro-Amerikaans, Kaukasisch & Hispanic) |
Two=Afrikaans-Amerikaans & Kaukasisch “Hispanic” is de referentiecategorie |
|||
| 4 | Physical activity level | Ordinal | Three (Low, Matig & Hoog) |
Twee=Laag & Matig “Hoog” is de referentiecategorie |
|||
| 5 | Beroepsgroep | Nominaal | Vier (Chirurg, Dokter, Verpleegkundige & Therapeut) |
Drie=Chirurg, Dokter & Verpleegkundige “Therapeut” is de referentiecategorie |
|||
| 6 | Graad van overeenstemming | Ordinaal | Vier (Sterk mee eens, Mee eens, Oneens, Sterk oneens) |
Drie=Zwaar mee eens, Mee eens & Oneens “Sterk mee oneens” is de referentiecategorie |
|||
| 7 | Onderwerpsgebied | Nominaal | Vijf (Bedrijfswetenschappen, Psychologie, Biologische wetenschappen, Ingenieurswetenschappen & Rechten) |
Vier=Zakwetenschappen, Psychologie, Biologische wetenschappen & Ingenieurswetenschappen “Rechten” is de referentiecategorie |
|||
| 8 | Leeftijd | Ordinaal | Vijf (jonger dan 18 jaar, 19-30, 31-40, 41-50, 51-60) |
Vier=Onder 18, 19-30, 31-40 & 41-50 “51-60” is de referentiecategorie |
|||
| Tabel: Voorbeelden van categorische onafhankelijke variabelen en hun respectieve dummy-variabelen | |||||||
Zoals uit bovenstaande tabel blijkt, hoeft u slechts één dummy-variabele minder aan te maken dan het aantal categorieën in uw categorische onafhankelijke variabele. Dit komt omdat u dit aantal dummyvariabelen alleen in een meervoudige regressie hoeft (en moet) overbrengen wanneer u een categorische onafhankelijke variabele hebt. Er zijn echter goede redenen om voor elke categorie van de categorische onafhankelijke variabele een dummyvariabele te creëren: (a) het is flexibeler en (b) het maakt het mogelijk om meerdere vergelijkingen te maken (zie de opmerking hieronder). Met andere woorden, als uw categorische onafhankelijke variabele drie categorieën heeft, zou u drie dummyvariabelen maken, en niet slechts twee.
Gelukkig maakt de procedure Create Dummy Variables in SPSS Statistics versie 22 en hoger automatisch een dummyvariabele voor elke categorie van uw categorische onafhankelijke variabele. Dit is echter niet het geval voor de procedure Hercoderen in verschillende variabelen in SPSS Statistics versie 21 of eerder. Daarom zult u onder normale omstandigheden de volgende opzet in SPSS Statistics hebben gemaakt, afhankelijk van het feit of u versie 21 of eerder of versie 22 en hoger hebt:
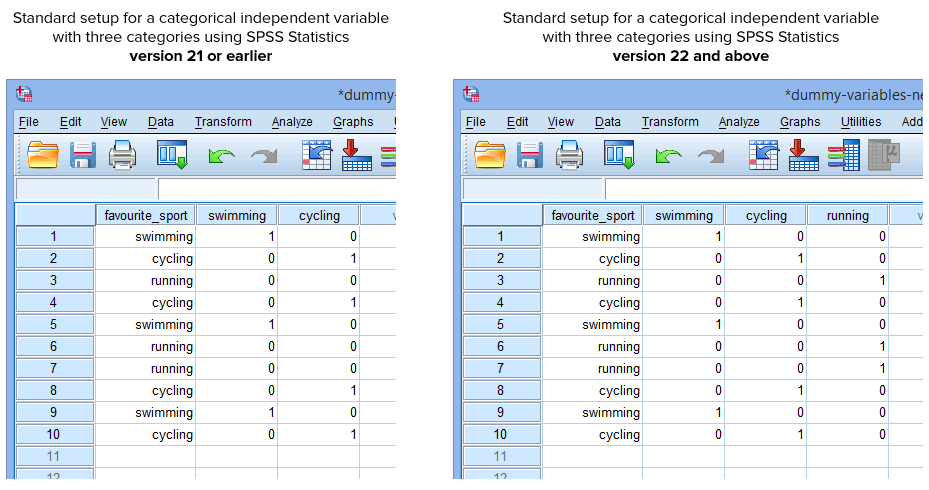
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Note: Zoals hierboven vermeld, is het maken van een dummyvariabele voor elke categorie van de categorische onafhankelijke variabele om twee redenen gunstig: (a) het is flexibeler en (b) het maakt het mogelijk meerdere vergelijkingen te maken. We gaan hieronder kort in op deze voordelen:
Het is flexibeler:
Wanneer u een dummy-variabele hebt gemaakt voor elke categorie van uw categorische onafhankelijke variabele, kunt u vervolgens elke categorie als referentiecategorie beschouwen. In ons voorbeeld beschouwden we de categorie “hardlopen” als de referentiecategorie, wat betekent dat we “zwemmen” en “fietsen” in de meervoudige regressievergelijking zouden hebben overgebracht. Als we later echter van gedachten zouden veranderen over onze keuze van referentiecategorie, zouden we de dummy-variabele procedure opnieuw moeten uitvoeren (tenzij u SPSS Statistics versie 22 of hoger hebt). Laten we bijvoorbeeld aannemen dat we nu de categorie “fietsen” als referentiecategorie willen beschouwen. We zouden nu de dummy-variabelen “zwemmen” en “hardlopen” in de meervoudige regressievergelijking kunnen overbrengen, omdat we ook de dummy-variabele “hardlopen” hebben.
Hiermee kunnen meerdere vergelijkingen worden gemaakt:
De coëfficiënt van een dummy-variabele vertegenwoordigt het verschil tussen de categorie die die dummy-variabele vertegenwoordigt en de referentiecategorie. Bijvoorbeeld, met “hardlopen” als referentiecategorie, vertegenwoordigt de coëfficiënt van de dummyvariabele “zwemmen” het verschil in de afhankelijke variabele tussen de categorieën “zwemmen” en “hardlopen”. Met deze methode zullen niet alle combinaties van categorieën mogelijk zijn. Dit probleem kan worden opgelost door verschillende referentiecategorieën te gebruiken. Dit is mogelijk als alle categorieën van de categorische variabele een dummyvariabele hebben.
Hoe dummyvariabelen en dummycodering te creëren
Er zijn twee stappen om dummyvariabelen in een meervoudige regressie met succes op te zetten: (1) dummy-variabelen creëren die de categorieën van uw categorische onafhankelijke variabele vertegenwoordigen; en (2) waarden in deze dummy-variabelen invoeren – bekend als dummy-codering – om de categorieën van de categorische onafhankelijke variabele weer te geven. We leggen dit proces hieronder uit aan de hand van het voorbeeld dat we hierboven hebben gegeven.
Uitleg: Dummy-variabelen zijn eenvoudigweg nieuwe variabelen die fungeren als “plaatshouders” voor een bepaald coderingsschema. Zij bevatten op zich geen gegevens. In plaats daarvan moeten gegevens/waarden aan deze dummy-variabelen worden toegevoegd, zodat ze hun doel kunnen vervullen en de categorieën van uw categorische onafhankelijke variabele kunnen weergeven. Er zijn veel verschillende soorten coderingsschema’s die de waarden dicteren die in dummy-variabelen worden ingevoerd, maar wij gebruiken een heel gewoon coderingsschema dat dummy-codering of, als alternatief, indicatorcodering wordt genoemd (N.B., laat u niet in verwarring brengen want dummy-variabelen en dummy-codering zijn niet hetzelfde). Dummy-codering werkt door elke dummy-variabele te gebruiken om een specifieke categorie van een categorische onafhankelijke variabele te identificeren, met uitzondering van een referentiecategorie, die we hieronder uitleggen.
Laten we beginnen met ons voorbeeld van een categorische onafhankelijke variabele, favoriete_sport, die drie categorieën heeft: “zwemmen”, “fietsen” en “hardlopen”. Aangezien er drie categorieën zijn, moeten er twee dummyvariabelen zijn die twee van de categorieën vertegenwoordigen, en een referentiecategorie die de derde categorie vertegenwoordigt.
Note: onthoud uit de discussie hierboven dat een meervoudige regressie vereist dat u één dummyvariabele minder overbrengt dan het aantal categorieën in uw categorische onafhankelijke variabele (d.w.z. twee in ons voorbeeld). U kunt echter een dummy-variabele maken voor elke categorie van de categorische onafhankelijke variabele met het oog op een grotere flexibiliteit en de mogelijkheid om meerdere vergelijkingen te maken. Niettemin benadrukken we in de onderstaande discussie alleen wat nodig is voor een meervoudige regressie, namelijk de creatie van één dummyvariabele minder dan het aantal categorieën in uw categorische onafhankelijke variabele, waarbij de categorie die niet direct wordt gerepresenteerd de “referentiecategorie” wordt.
Voorbeeld, laat dummyvariabele #1 de categorie “zwemmen” vertegenwoordigen en dummyvariabele #2 de categorie “fietsen”. Er blijft dan geen dummy voor de categorie “hardlopen” over. Deze “ontbrekende” categorie is de referentiecategorie en die is niet nodig. Bovendien is het geheel uw beslissing welke categorie u als referentiecategorie wilt gebruiken. We hadden evengoed de categorie “zwemmen” als referentiecategorie kunnen kiezen in plaats van de categorie “hardlopen”. De enige reden waarom we dat niet hebben gedaan, is dat SPSS Statistics standaard de laatste categorie die u in de Variabeleweergave voor uw categorische onafhankelijke variabele hebt gecodeerd, als referentiecategorie gebruikt (zie de opmerking hieronder).
Note: Zoals eerder uitgelegd in de sectie Gegevensinstellingen en zoals hieronder weergegeven in het dialoogvenster Waardelabels, was de derde en laatste categorie van onze categorische onafhankelijke variabele “hardlopen” (d.w.z., 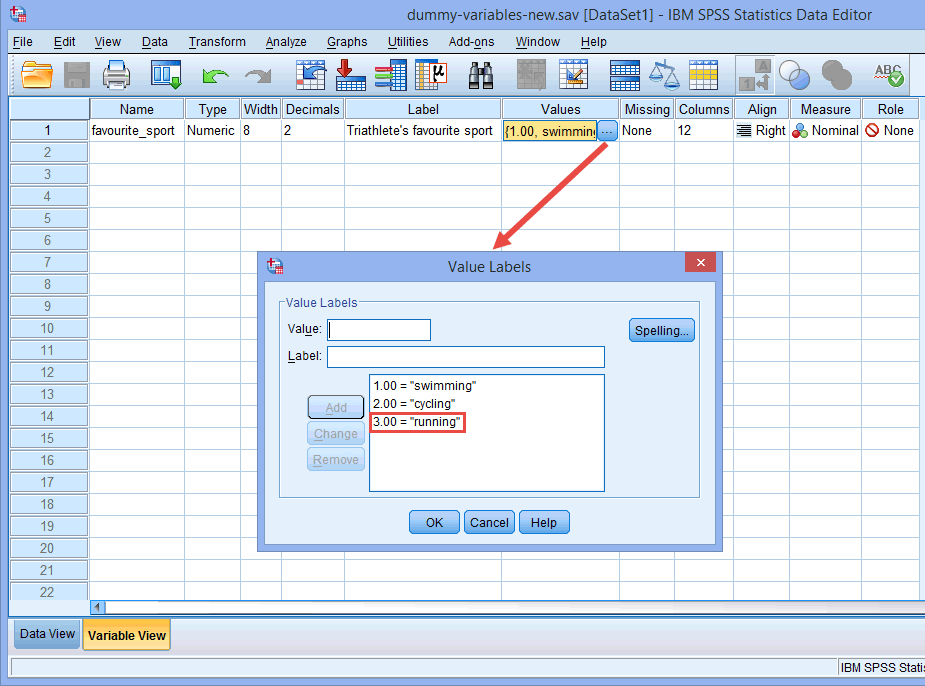
Er was geen theoretische of statistische reden om van de categorie “Lopen” de derde en laatste categorie te maken, waardoor dit in SPSS Statistics standaard de referentiecategorie werd. We hebben het gewoon zo gedaan omdat triatleten die aan een triatlon deelnemen, eerst zwemmen, dan fietsen en ten slotte naar de finish rennen. Daarom leek het logisch om onze categorische onafhankelijke variabele op deze manier te coderen. We hadden hem echter ook kunnen coderen als 1=fietsen, 2=lopen en 3=zwemmen; het zou geen verschil hebben gemaakt, behalve dan dat “zwemmen” als derde en laatste categorie standaard onze referentiecategorie zou zijn geworden in SPSS Statistics.
Wanneer u dummy-variabelen maakt, moet u ze een betekenisvolle naam geven. Aangezien elk van onze dummy-variabelen een categorie van onze categorische onafhankelijke variabele vertegenwoordigt, is het gebruikelijk om naar elke dummy-variabele te verwijzen met de naam van de categorie die ze vertegenwoordigt. Daarom hebben wij dummy variabele #1 “zwemmen” genoemd, omdat zij de categorie zwemmen vertegenwoordigt. Op dezelfde manier hebben we dummy variabele #2 “fietsen” genoemd, omdat deze de fietscategorie vertegenwoordigt. Door deze twee dummy-variabelen te creëren, hebben we twee nieuwe kolommen in onze gegevensverzameling in SPSS Statistics, zoals hieronder weergegeven:
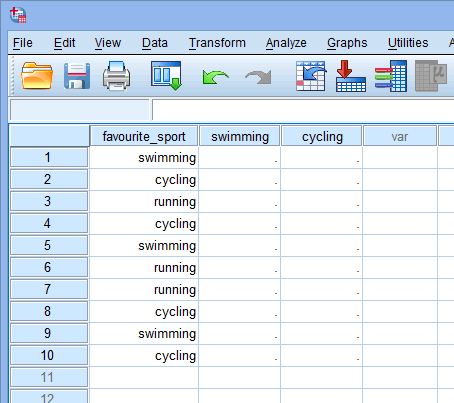
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Nu we twee dummy-variabelen hebben gecreëerd en ze de juiste namen hebben gegeven, moeten we waarden in deze variabelen invoeren, zodat elke dummy-variabele werkelijk zijn categorie van de categorische onafhankelijke variabele vertegenwoordigt. Met dummy codering is dit heel eenvoudig. U voert een “1” in voor elk geval (bv. een deelnemer in uw gegevensverzameling) dat de categorie heeft, en een “0” (nul) als ze de categorie niet hebben. Neem eerst de dummyvariabele “zwemmen”, zoals hieronder weergegeven:
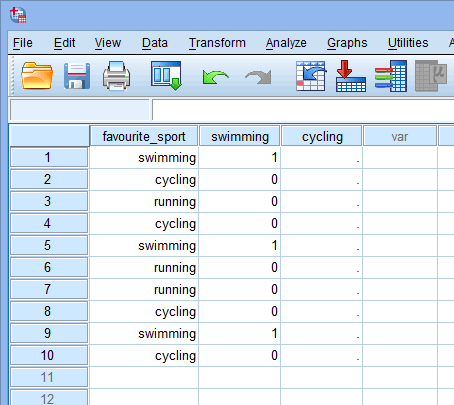
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Als een van de triatleten aangeeft dat “zwemmen” zijn “favoriete” sport is, voeren we een “1” in de cel onder de dummyvariabele kolom “zwemmen” (![]() ) in voor die triatleet die aangeeft dat zwemmen zijn “favoriete” sport is. Als een van de triatleten echter aangaf dat “fietsen” of “hardlopen” hun “favoriete” sport was, zouden we een “0” invoeren in de cel onder de dummy-variabele kolom zwemmen (
) in voor die triatleet die aangeeft dat zwemmen zijn “favoriete” sport is. Als een van de triatleten echter aangaf dat “fietsen” of “hardlopen” hun “favoriete” sport was, zouden we een “0” invoeren in de cel onder de dummy-variabele kolom zwemmen (![]() ) voor die triatleet die aangaf dat zwemmen “niet” zijn favoriete sport was (dit betekent dat ofwel “fietsen” of “hardlopen” de favoriete sport van die triatleet was). Dit wordt hieronder benadrukt voor alle 10 triatleten:
) voor die triatleet die aangaf dat zwemmen “niet” zijn favoriete sport was (dit betekent dat ofwel “fietsen” of “hardlopen” de favoriete sport van die triatleet was). Dit wordt hieronder benadrukt voor alle 10 triatleten:
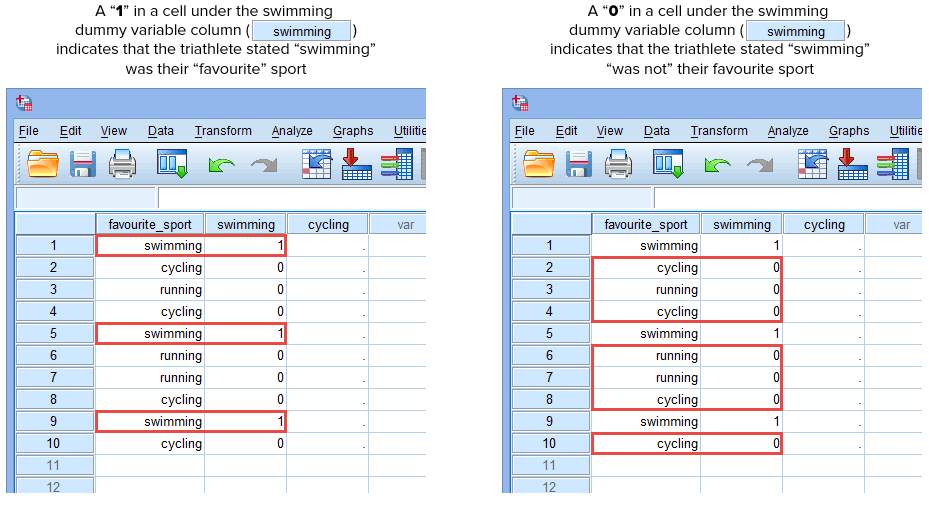
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
We herhalen dit proces voor de andere dummy-variabele, “fietsen”, zoals hieronder getoond:
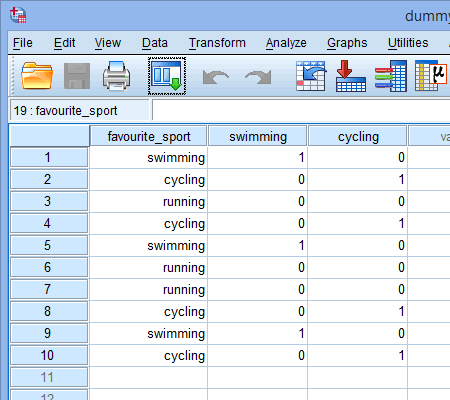
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Als een van de triatleten aangaf dat “fietsen” hun “favoriete” sport was, voeren we een “1” in in de cel onder de kolom met de dummyvariabele voor fietsen (![]() ) voor die triatleet die aangaf dat fietsen zijn “favoriete” sport was. Als een van de triatleten echter aangaf dat “zwemmen” of “hardlopen” hun “favoriete” sport was, vulden we een “0” in in de cel onder de dummy-variabele wielrennen (
) voor die triatleet die aangaf dat fietsen zijn “favoriete” sport was. Als een van de triatleten echter aangaf dat “zwemmen” of “hardlopen” hun “favoriete” sport was, vulden we een “0” in in de cel onder de dummy-variabele wielrennen (![]() ) voor die triatleet die aangaf dat fietsen “niet” zijn favoriete sport was (d.w.z., dit betekent dat ofwel “zwemmen” of “hardlopen” de favoriete sport van die triatleet was). Dit wordt hieronder voor alle 10 triatleten aangegeven:
) voor die triatleet die aangaf dat fietsen “niet” zijn favoriete sport was (d.w.z., dit betekent dat ofwel “zwemmen” of “hardlopen” de favoriete sport van die triatleet was). Dit wordt hieronder voor alle 10 triatleten aangegeven:
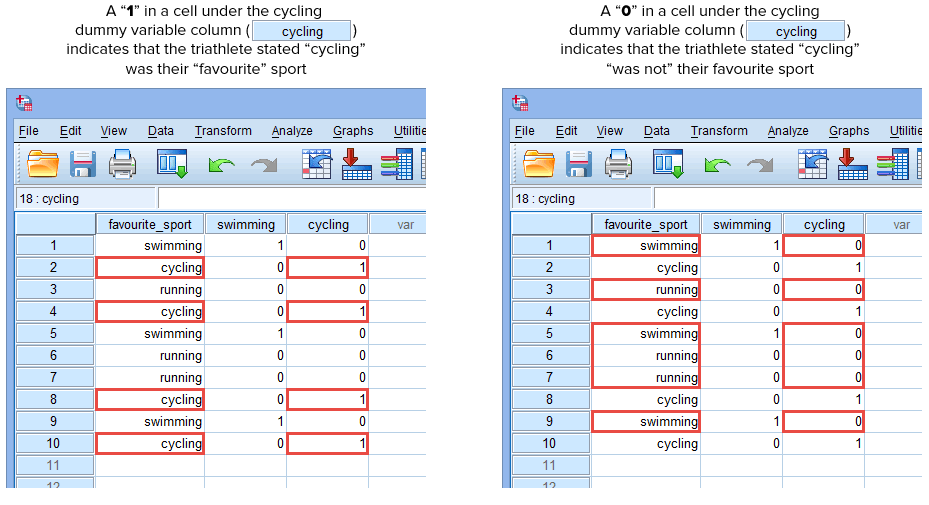
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Door op deze manier “1 “s en “0 “s in uw dummy-variabelen in te voeren, hebt u een reeks dummy-variabelen gecreëerd die u in een meervoudige regressieanalyse kunt invoeren. In het gedeelte Procedure dat volgt, laten we u zien hoe u deze dummyvariabelen kunt maken met de procedure Create Dummy Variables.
SPSS Statistics
Procedure in SPSS Statistics om dummyvariabelen te maken
Er zijn twee procedures in SPSS Statistics om dummyvariabelen te maken: de procedure Create Dummy Variables en de procedure Recode into Different Variables. In deze handleiding laten we zien hoe u de procedure Dummy-variabelen maken gebruikt, een eenvoudige procedure die uit 3 stappen bestaat. Deze procedure is echter alleen beschikbaar als u SPSS Statistics versie 22 of hoger hebt, waarbij versie 26 (en de abonnementsversie van SPSS Statistics) de nieuwste versie van SPSS Statistics is. Als u niet zeker weet welke versie van SPSS Statistics u gebruikt, raadpleegt u onze handleiding: Uw versie van SPSS Statistics identificeren. Als u SPSS Statistics versie 21 of eerder hebt, of als u meerdere vergelijkingen wilt maken bij het uitvoeren van uw meervoudige regressieanalyse, raadpleegt u de onderstaande opmerking:
Note: Als u SPSS Statistics versie 21 of eerder hebt, kunt u de procedure Dummy-variabelen maken niet gebruiken. Daarom kunt u met de procedure Hercoderen in verschillende variabelen in ieder geval dummy-variabelen in SPSS Statistics maken. Hoewel u de procedure Recode into Different Variables ook kunt gebruiken om dummyvariabelen te maken als u SPSS Statistics versie 22 of later hebt, hebben we de procedure Create Dummy Variables in deze handleiding opgenomen omdat deze speciaal is bedoeld voor het maken van dummyvariabelen en een stuk eenvoudiger en sneller in gebruik is. Er zijn bijvoorbeeld slechts 3 stappen nodig om dummyvariabelen te maken voor het voorbeeld dat in deze gids wordt gebruikt, vergeleken met 28 stappen voor hetzelfde voorbeeld met behulp van de procedure Recode into Different Variables.
Als u SPSS Statistics versie 21 of eerder hebt, bevat onze uitgebreide gids over het maken van dummyvariabelen in de sectie voor leden op Laerd Statistics een pagina die laat zien hoe u deze procedure van 28 stappen voor Recode into Different Variables kunt uitvoeren. U kunt toegang krijgen tot deze uitgebreide gids door u te abonneren op Laerd Statistics. U kunt ook gewoon de onderstaande procedure voor het maken van dummy-variabelen gebruiken.
Om dummy-variabelen te maken wanneer u SPSS Statistics versie 22 of later hebt, volgt u de onderstaande procedure voor het maken van dummy-variabelen in 3 stappen:
- Klik op Transform > Create Dummy Variables in het hoofdmenu, zoals hieronder afgebeeld:

Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
U krijgt het dialoogvenster Create Dummy Variables te zien, zoals hieronder afgebeeld:
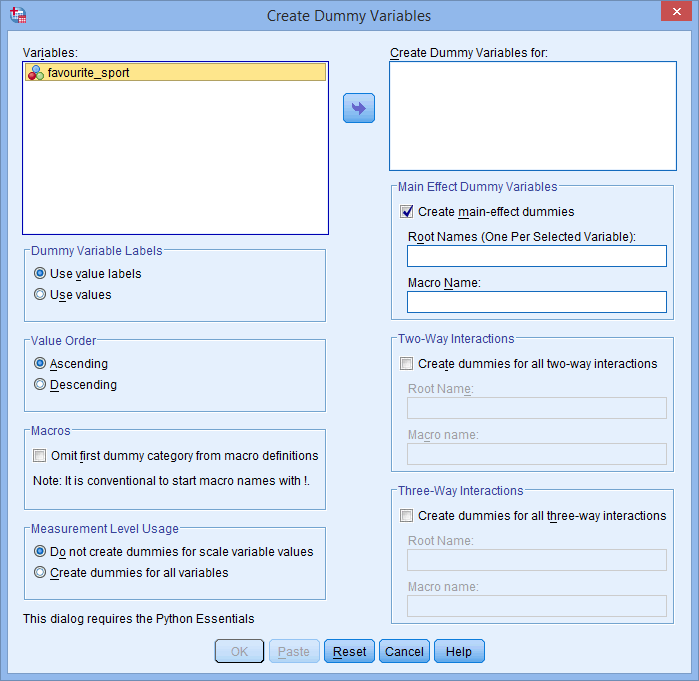
Publicated with written permission from SPSS Statistics, IBM Corporation.
- Breng de categorische onafhankelijke variabele, favourite_sport, over in het vak Create Dummy Variables for: door deze te selecteren (door erop te klikken) en vervolgens op de knop
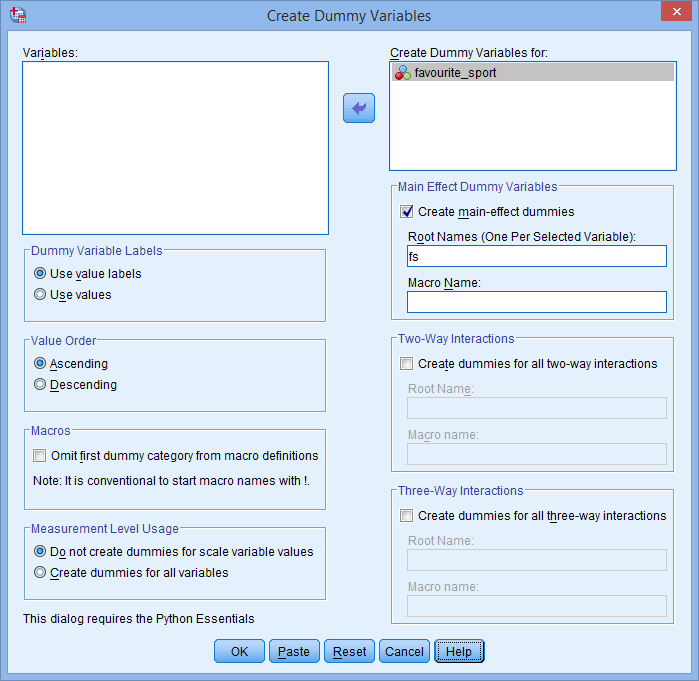
 te klikken. Voer ook een “wortel”-naam in die alle nieuwe dummy-variabelen kan vertegenwoordigen in het vak Wortelnamen (één per geselecteerde variabele): in het gebied -Main Effect Dummy Variables-. Wij hebben de stamnaam “fs” ingevoerd als een afkorting voor onze categorische onafhankelijke variabele, “favourite_sport”, zoals hieronder weergegeven:
te klikken. Voer ook een “wortel”-naam in die alle nieuwe dummy-variabelen kan vertegenwoordigen in het vak Wortelnamen (één per geselecteerde variabele): in het gebied -Main Effect Dummy Variables-. Wij hebben de stamnaam “fs” ingevoerd als een afkorting voor onze categorische onafhankelijke variabele, “favourite_sport”, zoals hieronder weergegeven:
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Noot: SPSS Statistics voegt een volgnummer (d.w.z. 1, 2, 3, 4, enz.) toe aan het einde van de stamnaam die u kiest om uw categorische onafhankelijke variabele weer te geven. Voor elk van de dummy-variabelen die u wilt maken, wordt een volgnummer aangemaakt (bijv. als u twee dummy-variabelen hebt, worden een 1 en een 2 toegevoegd aan het eind van de stamnaam, maar als u zes dummy-variabelen hebt, worden een 1, 2, 3, 4, 5 en 6 toegevoegd aan het eind van de stamnaam). Dit wordt voor ons voorbeeld getoond in het onderstaande venster Variabeleweergave:
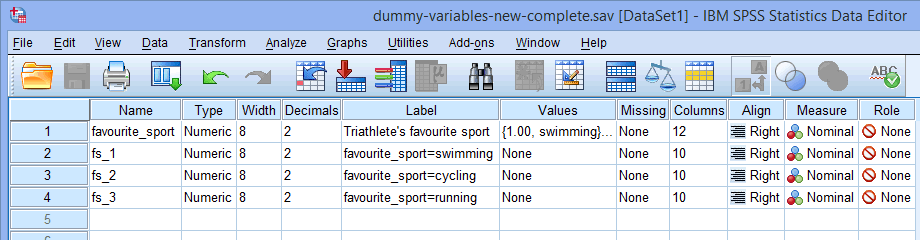
Omdat onze categorische onafhankelijke variabele, favoriete_sport, drie categorieën had (namelijk zwemmen, fietsen en hardlopen), maakt de procedure Dummy-variabelen maken drie dummy-variabelen (namelijk één voor zwemmen, één voor fietsen en één voor hardlopen). Deze drie dummy-variabelen zijn aangegeven in de kolom hierboven: “fs_1” (voor zwemmen), “fs_2” (voor fietsen) en “fs_3” (voor hardlopen). U kunt deze later een andere naam geven, zodat ze zinvoller zijn. We benadrukken dit alleen zodat u weet hoe het vak Root Names (One Per Selected Variable): hierboven werkt.
hierboven: “fs_1” (voor zwemmen), “fs_2” (voor fietsen) en “fs_3” (voor hardlopen). U kunt deze later een andere naam geven, zodat ze zinvoller zijn. We benadrukken dit alleen zodat u weet hoe het vak Root Names (One Per Selected Variable): hierboven werkt.
Ook kan de root name die u invoert in het vak Root Names (One Per Selected Variable): niet dezelfde zijn als de naam van uw categorische onafhankelijke variabele, zoals hieronder wordt getoond (d.w.z., waar we de stamnaam, “favourite_sport”, hebben ingevoerd om te illustreren hoe we onze stamnaam niet konden noemen):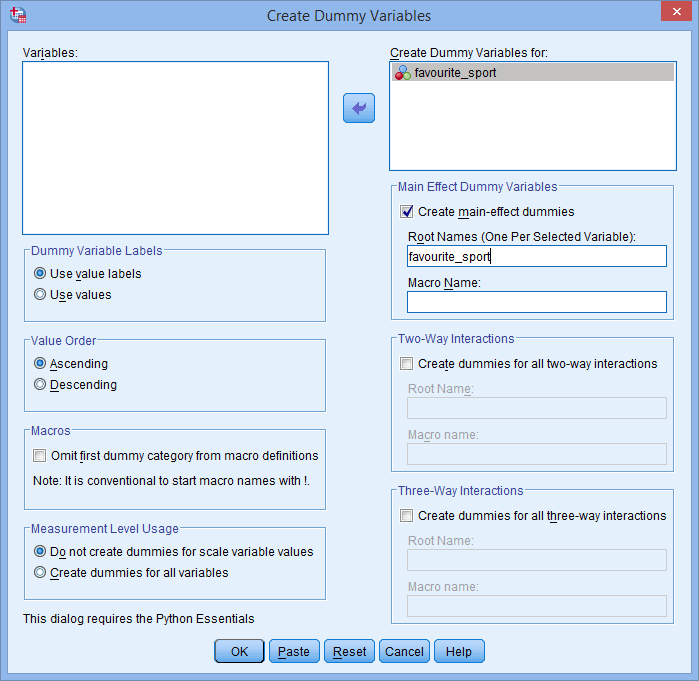
Als de stamnaam die u invoert dezelfde is als de naam van uw categorische onafhankelijke variabele, zoals hierboven getoond, krijgt u wanneer u op de knop klikt de volgende waarschuwing:
klikt de volgende waarschuwing:
- Klik op de knop .
Na het uitvoeren van de bovenstaande procedure in 3 stappen voor het maken van dummy-variabelen hebt u dummy-variabelen gemaakt voor uw categorische onafhankelijke variabele. In het volgende gedeelte wordt de uitvoer belicht die ontstaat in de variabelenweergave en de gegevensweergave van SPSS Statistics na het uitvoeren van deze procedure Create Dummy Variables.
SPSS Statistics
Output and data setup in SPSS Statistics after creating dummy variables
Nadat u uw dummyvariabelen hebt gemaakt, produceert SPSS Statistics de volgende tabel voor het maken van variabelen in de IBM SPSS Statistics Viewer:
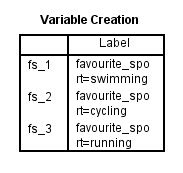
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
De tabel voor het aanmaken van variabelen bevestigt dat u met succes dummy variabelen hebt aangemaakt. Er moeten evenveel rijen zijn als er nieuwe dummy variabelen zijn. Aangezien we drie dummy variabelen hebben aangemaakt, zijn er drie rijen in de tabel, “fs_1”, “fs_2” en “fs_3”, die de stamnaam en de opeenvolgende nummering weergeven die in Stap 2 van de procedure Dummy Variabelen aanmaken in het vorige hoofdstuk zijn ingevoerd. Voor elk van deze dummy-variabelen wordt in de tabel een label gegeven om duidelijk te maken welke categorie van de categorische onafhankelijke variabele elke dummy-variabele vertegenwoordigt. Bijvoorbeeld, het label “favourite_sport=swimming” wordt gegeven voor “fs_1”, waarmee wordt aangegeven dat “fs_1” de dummy-variabele is voor de categorie “zwemmen” van de categorische onafhankelijke variabele, favourite_sport.
Naar aanleiding hiervan gaat u naar het venster Variable View van SPSS Statistics door op het tabblad ![]() te klikken. De drie dummy-variabelen zijn toegevoegd, zoals hieronder is weergegeven (d.w.z. de dummy-variabelen, “fs_1”, “fs_2” en “fs_3”, in de kolom
te klikken. De drie dummy-variabelen zijn toegevoegd, zoals hieronder is weergegeven (d.w.z. de dummy-variabelen, “fs_1”, “fs_2” en “fs_3”, in de kolom ![]() ):
):
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Noot: U kunt de namen van de dummy-variabelen in de kolom ![]() wijzigen om duidelijker te maken wat deze zijn. Wij hebben bijvoorbeeld “fs_1” veranderd in “zwemmen”, “fs_2” in “fietsen” en “fs_3” in “hardlopen”, zoals hieronder getoond:
wijzigen om duidelijker te maken wat deze zijn. Wij hebben bijvoorbeeld “fs_1” veranderd in “zwemmen”, “fs_2” in “fietsen” en “fs_3” in “hardlopen”, zoals hieronder getoond:
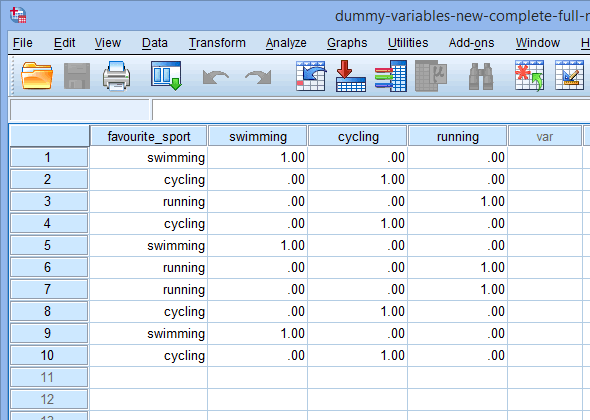
Daarna gaat u naar het venster Gegevensweergave van SPSS Statistics door op het tabblad ![]() te klikken. De dummy-codering wordt weergegeven onder elk van de dummy-variabelen die zijn aangemaakt. Bijvoorbeeld, in de rijen onder de kolom “fs_1” wordt de categorie “zwemmen” gecodeerd als “1.00”, terwijl de categorieën “fietsen” en “hardlopen” worden gecodeerd als “.00”, zoals hieronder getoond. Als u niet zeker weet waarom deze dummyvariabelen op deze manier gecodeerd zijn, zie dan de paragraaf: Dummyvariabelen en dummycodering begrijpen.
te klikken. De dummy-codering wordt weergegeven onder elk van de dummy-variabelen die zijn aangemaakt. Bijvoorbeeld, in de rijen onder de kolom “fs_1” wordt de categorie “zwemmen” gecodeerd als “1.00”, terwijl de categorieën “fietsen” en “hardlopen” worden gecodeerd als “.00”, zoals hieronder getoond. Als u niet zeker weet waarom deze dummyvariabelen op deze manier gecodeerd zijn, zie dan de paragraaf: Dummyvariabelen en dummycodering begrijpen.
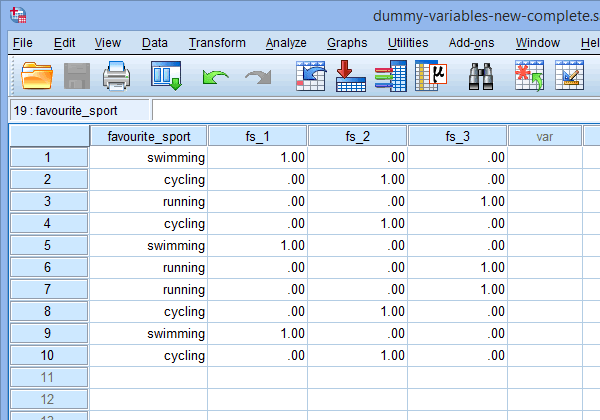
Gepubliceerd met schriftelijke toestemming van SPSS Statistics, IBM Corporation.
Noot 1: Als gevolg van de standaardinstellingen van SPSS Statistics worden uw dummyvariabelen gecodeerd als “1.00” of “.00” in plaats van respectievelijk “1” of “0”. Zij zijn identiek. U zult echter vaak dummy-coderingen zien die zijn geschreven in termen van 1’s en 0’s in plaats van decimalen.
Note 2: Als u de namen van de dummy-variabelen in de kolom ![]() van het bovenstaande venster Variable View hebt gewijzigd, zullen deze ook zijn gewijzigd in de kolommen van het venster Data View, zoals hieronder wordt weergegeven (de kolomkop
van het bovenstaande venster Variable View hebt gewijzigd, zullen deze ook zijn gewijzigd in de kolommen van het venster Data View, zoals hieronder wordt weergegeven (de kolomkop ![]() heeft nu bijvoorbeeld de titel
heeft nu bijvoorbeeld de titel ![]() ):
):