Wat is Data Cleaning?
Data cleaning is het proces van het voorbereiden van data voor analyse door het verwijderen of wijzigen van data die onjuist, incompleet, irrelevant, gedupliceerd, of onjuist geformatteerd zijn.
Deze gegevens zijn meestal niet nodig of nuttig bij het analyseren van gegevens, omdat ze het proces kunnen hinderen of onnauwkeurige resultaten kunnen opleveren. Er zijn verschillende methoden voor het opschonen van gegevens, afhankelijk van de manier waarop ze zijn opgeslagen en de antwoorden die worden gezocht.
Dataschoning is niet simpelweg het wissen van informatie om ruimte te maken voor nieuwe gegevens, maar eerder het vinden van een manier om de nauwkeurigheid van een dataset te maximaliseren zonder noodzakelijkerwijs informatie te verwijderen.
Zo omvat het opschonen van gegevens meer acties dan het verwijderen van gegevens, zoals het herstellen van fouten in spelling en syntaxis, het standaardiseren van datasets en het corrigeren van fouten zoals lege velden, ontbrekende codes en het identificeren van dubbele datapunten. Data cleaning wordt beschouwd als een fundamenteel element van de basis van data science, omdat het een belangrijke rol speelt in het analytische proces en het blootleggen van betrouwbare antwoorden.
Het belangrijkste doel van data cleaning is het creëren van datasets die gestandaardiseerd en uniform zijn, zodat tools voor business intelligence en data-analyse gemakkelijk toegang hebben tot de juiste gegevens en deze voor elke query kunnen vinden.
Hoe kan ik gegevens opschonen gebruiken?
Gelijk welk type analyse of gegevensvisualisaties u nodig hebt, het opschonen van gegevens is een essentiële stap om ervoor te zorgen dat de antwoorden die u genereert, nauwkeurig zijn. Bij het verzamelen van gegevens uit verschillende stromen en met handmatige invoer van gebruikers, kan informatie fouten bevatten, onjuist zijn ingevoerd of hiaten vertonen.
Dataschoning helpt ervoor te zorgen dat informatie altijd overeenkomt met de juiste velden, terwijl het gemakkelijker wordt voor business intelligence-tools om te interageren met datasets om efficiënter informatie te vinden. Een van de meest voorkomende voorbeelden van gegevensopschoning is de toepassing ervan in datawarehouses.

In een succesvol datawarehouse wordt een verscheidenheid aan gegevens uit verschillende bronnen opgeslagen en geoptimaliseerd voor analyse voordat er modellen worden gemaakt. Om dit te doen, moeten magazijnapplicaties miljoenen inkomende gegevenspunten analyseren om er zeker van te zijn dat ze accuraat zijn voordat ze in de juiste database, tabel of andere structuur kunnen worden geplaatst.
Organisaties die rechtstreeks gegevens verzamelen van consumenten die enquêtes, vragenlijsten en formulieren invullen, maken ook uitgebreid gebruik van het opschonen van gegevens. Daarbij wordt gecontroleerd of de gegevens in het juiste veld zijn ingevoerd, of er geen ongeldige tekens in voorkomen en of er geen hiaten in de verstrekte informatie zitten.
Zie het in actie:
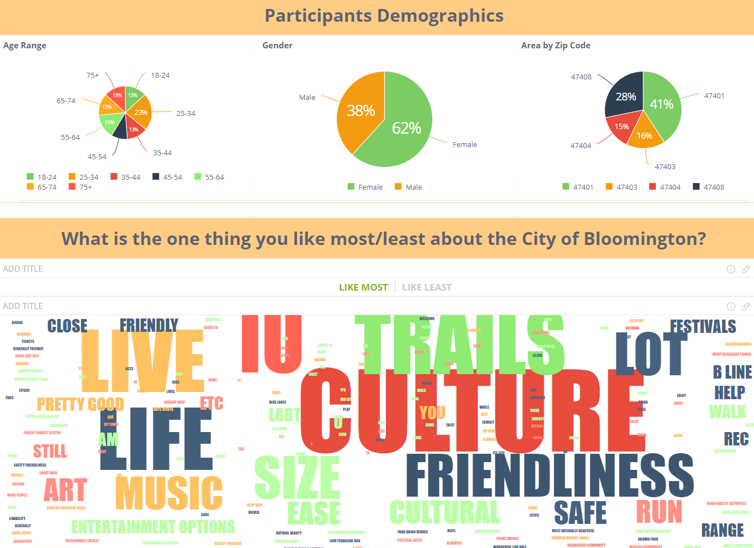 Verkijk Dashboard
Verkijk Dashboard