Overview
- Leer de Bias en Variantie in een gegeven model te interpreteren.
- Wat is het verschil tussen Bias en Variantie?
- Hoe Bias en Variantie Tradeoff te bereiken met Machine Learning workflow
Inleiding
Laten we het eens over het weer hebben. Het regent alleen als het een beetje vochtig is en regent niet als het waait, warm is of vriest. Hoe zou u in dit geval een voorspellend model trainen en ervoor zorgen dat er geen fouten optreden bij het voorspellen van het weer? Je zou kunnen zeggen dat er veel leeralgoritmen zijn om uit te kiezen. Ze zijn in veel opzichten verschillend, maar er is een groot verschil in wat wij verwachten en wat het model voorspelt. Dat is het concept Bias and Variance Tradeoff.
Gewoonlijk wordt Bias and Variance Tradeoff aan de hand van dichte wiskundige formules onderwezen. Maar in dit artikel heb ik geprobeerd de bias en variantie zo eenvoudig mogelijk uit te leggen.
Ik zal me erop richten u door het proces van het begrijpen van de probleemstelling te leiden en ervoor te zorgen dat u het beste model kiest waarbij de bias- en variantiefouten minimaal zijn.
Voor dit doel heb ik de populaire Pima Indians Diabetes-dataset genomen. De dataset bestaat uit diagnostische metingen van volwassen vrouwelijke patiënten van de Indiaanse Pima-erfenis. Voor deze dataset gaan we ons concentreren op de “Outcome” variabele – die aangeeft of de patiënt diabetes heeft of niet. Het is duidelijk dat dit een binair classificatieprobleem is en we gaan er meteen in duiken en leren hoe we het moeten aanpakken.
Als u geïnteresseerd bent in deze en data science-concepten en praktisch wilt leren, raadpleeg dan onze cursus Inleiding tot Data Science
Inhoudsopgave
- Evaluatie van een Machine Learning-model
- Probleemstelling en primaire stappen
- Wat is bias?
- Wat is Variantie?
- Bias-Variantie Tradeoff
Evaluatie van uw Machine Learning Model
Het primaire doel van het Machine Learning model is te leren van de gegeven data en voorspellingen te genereren op basis van het patroon dat tijdens het leerproces is waargenomen. Onze taak houdt daar echter niet op. Wij moeten het model voortdurend verbeteren op basis van de resultaten die het oplevert. Wij kwantificeren ook de prestaties van het model aan de hand van metingen zoals nauwkeurigheid, gemiddelde kwadratische fout (MSE), F1-score, enz. en proberen deze metingen te verbeteren. Dit kan vaak lastig worden wanneer we de flexibiliteit van het model moeten behouden zonder afbreuk te doen aan de juistheid ervan.
Een Machine Learning model met supervisie traint zichzelf op de ingangsvariabelen(X) op zo’n manier dat de voorspelde waarden(Y) zo dicht mogelijk bij de werkelijke waarden liggen. Dit verschil tussen de werkelijke waarden en de voorspelde waarden is de fout en wordt gebruikt om het model te evalueren. De fout voor elk Machine Learning-algoritme met supervisie bestaat uit 3 delen:
- Biasfout
- Variantiefout
- De ruis
De ruis is de onherleidbare fout die we niet kunnen elimineren, terwijl de andere twee, d.w.z.In de volgende secties zullen wij de Bias-fout, de Variant-fout en de Bias-Variantie-ruil behandelen, die ons zullen helpen bij de beste modelselectie. En het interessante is dat we enkele technieken zullen behandelen om met deze fouten om te gaan aan de hand van een voorbeelddataset.
Probleemstelling en primaire stappen
Zoals eerder uitgelegd, hebben we de Diabetes-dataset van de Pima-indianen genomen en er een classificatieprobleem van gemaakt. Laten we beginnen met de dataset te peilen en te zien met wat voor soort gegevens we te maken hebben. We doen dit door de benodigde bibliotheken te importeren:
Nu gaan we de gegevens in een gegevensframe laden en een aantal rijen observeren om inzicht in de gegevens te krijgen.
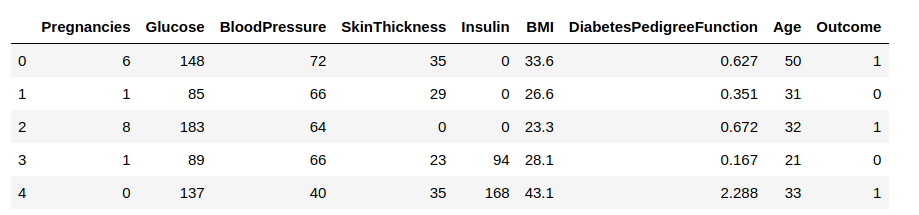
We moeten de kolom ‘Uitkomst’ voorspellen. Laten we deze scheiden en toewijzen aan een doelvariabele ‘y’. De rest van het gegevensframe wordt de verzameling invoervariabelen X.
Nu schalen we de voorspellende variabelen en scheiden we de trainings- en de testgegevens.
Omdat de uitkomsten binair zijn, gebruiken we de eenvoudigste K-nearest neighbor classifier (Knn) om te bepalen of de patiënt diabetes heeft of niet.
Hoe bepalen we echter de waarde van ‘k’?
- Misschien moeten we k = 1 gebruiken, zodat we zeer goede resultaten op onze trainingsgegevens krijgen? Dat zou kunnen werken, maar we kunnen niet garanderen dat het model even goed zal presteren op onze testgegevens, omdat het te specifiek kan worden
- Hoe zit het met het gebruik van een hoge waarde voor k, bijvoorbeeld k = 100, zodat we een groot aantal dichtstbijzijnde punten in aanmerking kunnen nemen om ook rekening te houden met de verafgelegen punten? Een dergelijk model zal echter te algemeen zijn en we kunnen er niet zeker van zijn dat het alle mogelijke bijdragende kenmerken correct in aanmerking heeft genomen.
Laten we een paar mogelijke waarden van k nemen en het model voor al die waarden op de trainingsgegevens passen. We berekenen ook de trainingsscore en de testscore voor al die waarden.
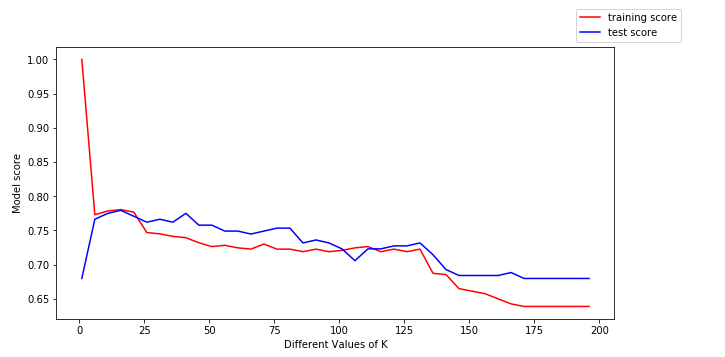
Om hier meer inzicht uit te krijgen, laten we de trainingsgegevens (in rood) en de testgegevens (in blauw) plotten.
Om de scores voor een bepaalde waarde van k te berekenen,
![]()
U kunnen uit bovenstaande plot de volgende conclusies trekken:
- Voor lage waarden van k is de trainingsscore hoog, terwijl de testscore laag is
- Naarmate de waarde van k toeneemt, begint de testscore te stijgen en de trainingsscore te dalen.
- Bij een bepaalde waarde van k liggen de trainingsscore en de testscore echter dicht bij elkaar.
Daar komen Bias en Variantie in beeld.
Wat is Bias?
In de eenvoudigste bewoordingen is Bias het verschil tussen de voorspelde waarde en de verwachte waarde. Om het verder uit te leggen, het model maakt bepaalde veronderstellingen wanneer het traint op de verstrekte gegevens. Wanneer het wordt ingevoerd in de test-/validatiegegevens, zijn deze veronderstellingen niet altijd correct.
In ons model, als we een groot aantal nearest neighbors gebruiken, kan het model volledig besluiten dat sommige parameters helemaal niet belangrijk zijn. Het kan er bijvoorbeeld gewoon van uitgaan dat het Glusoce-niveau en de bloeddruk bepalen of de patiënt diabetes heeft. Dit model zou zeer sterke veronderstellingen maken over het feit dat de andere parameters geen invloed hebben op de uitkomst. U kunt het ook zien als een model dat een eenvoudige relatie voorspelt terwijl de datapunten duidelijk op een complexere relatie wijzen:
Mathematisch gezien zijn de inputvariabelen X en een doelvariabele Y. We brengen de relatie tussen de twee in kaart met behulp van een functie f.
Daarom
Y = f(X) + e
Hierbij is ‘e’ de fout die normaal verdeeld is. Het doel van ons model f'(x) is waarden te voorspellen die zo dicht mogelijk bij f(x) liggen. Hier is de bias van het model:
Bias = E
Zoals ik hierboven heb uitgelegd, resulteert het model, wanneer het generaliseert, d.w.z. wanneer er een hoge biasfout is, in een zeer simplistisch model dat de variaties niet goed in aanmerking neemt. Aangezien het model de trainingsgegevens niet goed leert, spreekt men van Underfitting.
Wat is een Variantie?
In tegenstelling tot de bias, houdt het model bij de Variantie ook rekening met de fluctuaties in de gegevens, d.w.z. met de ruis. Wat gebeurt er dus als ons model een hoge variantie heeft?
Het model zal de variantie nog steeds beschouwen als iets om van te leren. Dat wil zeggen, het model leert te veel van de trainingsgegevens, zo veel zelfs, dat wanneer het wordt geconfronteerd met nieuwe (test)gegevens, het niet in staat is om op basis daarvan nauwkeurig te voorspellen.
Mathematisch is de variantiefout in het model:
Variantie-E^2
Omdat in het geval van een hoge variantie, het model te veel leert van de trainingsgegevens, wordt dit overfitting genoemd.
In de context van onze gegevens, als we zeer weinig naaste buren gebruiken, is het alsof we zeggen dat als het aantal zwangerschappen meer dan 3 is, de glucosespiegel meer dan 78 is, de diastolische bloeddruk minder dan 98 is, de huiddikte minder dan 23 mm is enzovoort voor elk kenmerk….. besluiten dat de patiënt diabetes heeft. Alle andere patiënten die niet aan de bovenstaande criteria voldoen, zijn geen diabetici. Dit mag dan waar zijn voor één bepaalde patiënt in de trainingsset, maar wat als deze parameters de uitbijters zijn of zelfs onjuist werden geregistreerd? Het is duidelijk dat een dergelijk model zeer duur zou kunnen blijken te zijn!
Bovendien zou dit model een hoge variatiefout hebben, omdat de voorspellingen of een patiënt al dan niet diabeet is, sterk variëren met het soort trainingsgegevens dat we het verstrekken. Dus zelfs een verandering van het glucosegehalte in 75 zou ertoe leiden dat het model voorspelt dat de patiënt geen diabetes heeft.
Om het eenvoudiger te maken: het model voorspelt zeer complexe verbanden tussen het resultaat en de inputkenmerken, terwijl een kwadratische vergelijking zou hebben volstaan. Zo ziet een classificatiemodel eruit wanneer er sprake is van een hoge variantiefout/wanneer er sprake is van overfitting:
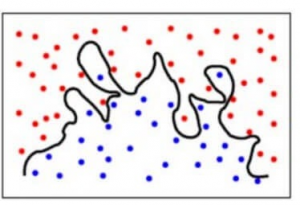
Om samen te vatten,
- Een model met een hoge bias-fout past de gegevens te weinig aan en maakt er zeer simplistische veronderstellingen over
- Een model met een hoge variantiefout past de gegevens te veel aan en leert er te veel van
- Een goed model is een model waarbij zowel de bias- als de variantiefout in evenwicht zijn
Bias-Variance Tradeoff
Hoe relateren we de bovenstaande concepten aan ons Knn-model van eerder? Laten we dat eens uitzoeken!
In ons model, zeg, voor, k = 1, zal het punt dat het dichtst bij het datapunt in kwestie ligt in aanmerking worden genomen. Hier kan de voorspelling voor dat gegevenspunt nauwkeurig zijn, zodat de vertekeningsfout kleiner zal zijn.
De variantiefout zal echter groot zijn, omdat alleen het dichtstbijzijnde punt in aanmerking wordt genomen en er geen rekening wordt gehouden met de andere mogelijke punten. Met welk scenario denk je dat dit overeenkomt? Ja, u denkt juist, dit betekent dat ons model overfitting is.
Aan de andere kant, voor hogere waarden van k, zullen veel meer punten die dichter bij het datapunt in kwestie liggen in aanmerking worden genomen. Dit zou resulteren in een hogere biasfout en underfitting, aangezien veel punten dichter bij het datapunt in aanmerking worden genomen en het model dus niet de specifieke kenmerken van de trainingsset kan leren. We kunnen echter rekening houden met een lagere variantiefout voor de testreeks die onbekende waarden heeft.
Om een evenwicht te bereiken tussen de biasfout en de variantiefout, hebben we een zodanige waarde van k nodig dat het model noch leert van de ruis (overfit op de gegevens), noch ingrijpende veronderstellingen maakt over de gegevens (underfit op de gegevens). Om het eenvoudiger te houden, zou een evenwichtig model er als volgt uitzien:
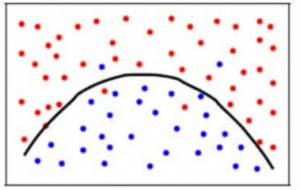
Hoewel sommige punten onjuist worden geclassificeerd, past het model over het algemeen goed bij de meeste datapunten. Het evenwicht tussen de Bias-fout en de Variantiefout is de Bias-Variance Tradeoff.
Het volgende bulls-eye-diagram verklaart de tradeoff beter:
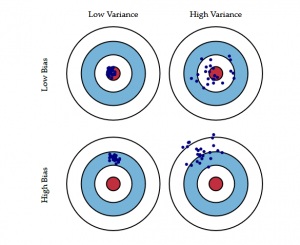
Het centrum, d.w.z. de bull’s eye, is het modelresultaat dat we willen bereiken en dat alle waarden perfect en correct voorspelt. Naarmate we ons verder van de bull’s eye verwijderen, begint ons model steeds meer verkeerde voorspellingen te doen.
Een model met een lage bias en een hoge variantie voorspelt punten die over het algemeen rond het centrum liggen, maar vrij ver van elkaar verwijderd zijn. Een model met een hoge bias en een lage variantie is vrij ver van de roos verwijderd, maar omdat de variantie laag is, liggen de voorspelde punten dichter bij elkaar.
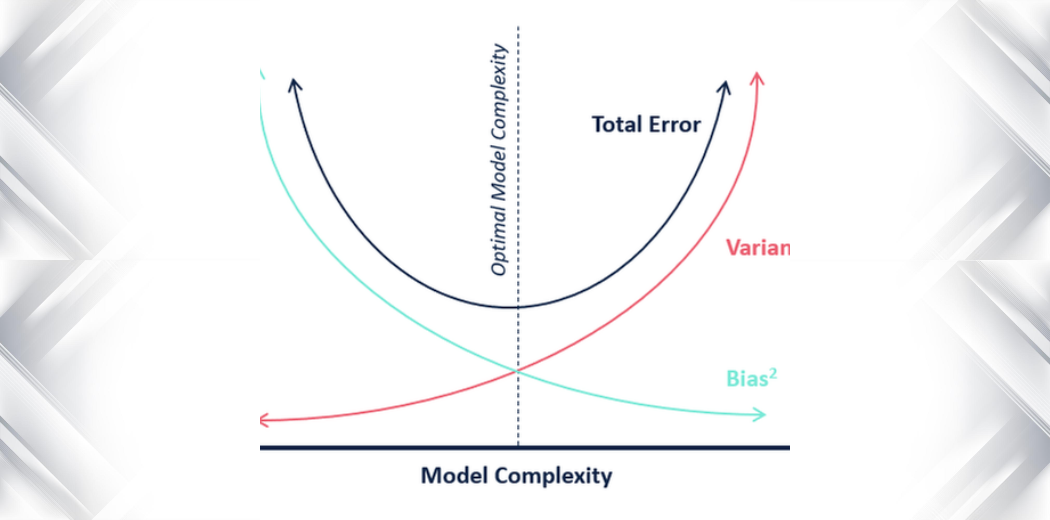
In termen van modelcomplexiteit kunnen we het volgende diagram gebruiken om te beslissen over de optimale complexiteit van ons model.
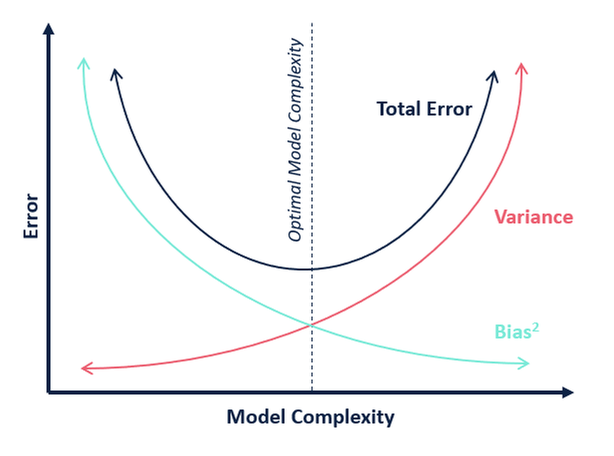
Wat is volgens u de optimale waarde voor k?
Uit de bovenstaande uitleg kunnen we concluderen dat de k waarvoor
- de testscore het hoogst is, en
- zowel de testscore als de trainingsscore dicht bij elkaar liggen
de optimale waarde van k is. Dus ook al leveren we een lagere trainingsscore in, we krijgen toch een hoge score voor onze testgegevens, wat crucialer is – de testgegevens zijn tenslotte onbekende gegevens.
Laten we een tabel maken voor verschillende waarden van k om dit verder te bewijzen:
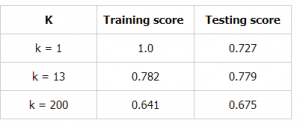
Conclusie
Om samen te vatten: in dit artikel hebben we geleerd dat een ideaal model er een is waarbij zowel de bias- als de variantiefout laag zijn. We moeten echter altijd streven naar een model waarbij de modelscore voor de trainingsgegevens zo dicht mogelijk ligt bij de modelscore voor de testgegevens.
Daar hebben we uitgezocht hoe we een model kunnen kiezen dat niet te complex is (hoge variantie en lage bias), wat zou leiden tot overfitting, en ook niet te eenvoudig (hoge bias en lage variantie), wat zou leiden tot underfitting.
Bias en Variantie spelen een belangrijke rol bij de beslissing welk voorspellend model te gebruiken. Ik hoop dat dit artikel het concept goed heeft uitgelegd.