
Als je meer wilt leren in Python, volg dan de gratis cursus Intro to Python for Data Science van DataCamp.
Jullie hebben allemaal wel eens datasets gezien. Soms zijn ze klein, maar vaak zijn ze enorm groot in omvang. Het wordt erg uitdagend om de datasets te verwerken die erg groot zijn, in ieder geval significant genoeg om een verwerkingsknelpunt te veroorzaken.
Dus, wat maakt deze datasets zo groot? Nou, het zijn kenmerken. Hoe meer kenmerken, hoe groter de datasets. Nou, niet altijd. Er zijn datasets met heel veel features, maar die bevatten niet zo veel instanties. Maar dat is niet het punt van discussie hier. Je kunt je dus afvragen hoe je met een commodity computer in de hand dit soort datasets kunt verwerken zonder er omheen te draaien.
Vaak blijven er in een hoogdimensionale dataset enkele volstrekt irrelevante, onbelangrijke en onbelangrijke kenmerken over. Men heeft gezien dat de bijdrage van dit soort kenmerken vaak geringer is voor de voorspellende modellering in vergelijking met de kritische kenmerken. Zij kunnen zelfs geen enkele bijdrage leveren. Deze kenmerken veroorzaken een aantal problemen die op hun beurt het proces van efficiënte voorspellende modellering verhinderen –
- Onnodige toewijzing van middelen voor deze kenmerken.
- Deze kenmerken fungeren als een ruis waarvoor het machine learning model verschrikkelijk slecht kan presteren.
- Het machine model kost meer tijd om getraind te worden.
Dus, wat is hier de oplossing? De meest economische oplossing is Feature Selectie.
Feature Selectie is het proces van het selecteren van de meest significante features uit een gegeven dataset. In veel gevallen kan Feature Selection ook de prestaties van een machine learning model verbeteren.
Klinkt interessant toch?
Je hebt een informele introductie gekregen in Feature Selection en het belang ervan in de wereld van Data Science en Machine Learning. In deze post ga je behandelen:
- Inleiding tot feature selectie en het begrijpen van het belang ervan
- Verschil tussen feature selectie en dimensionaliteitsreductie
- Verschillende soorten feature selectiemethoden
- Implementatie van verschillende feature selectiemethoden met scikit-leren
Inleiding tot feature selectie
Feature selectie is ook bekend als Variabele selectie of Attribuut selectie.
In essentie is het het proces van het selecteren van de meest belangrijke/relevante. Features van een dataset.
Het belang van feature selection
Het belang van feature selection kan het best worden onderkend wanneer u te maken heeft met een dataset die een enorm aantal features bevat. Dit type dataset wordt vaak een hoog dimensionele dataset genoemd. Nu, met deze hoge dimensionaliteit, komt een heleboel problemen zoals – deze hoge dimensionaliteit zal de trainingstijd van uw machine learning model aanzienlijk verhogen, het kan uw model zeer ingewikkeld maken wat op zijn beurt kan leiden tot Overfitting.
Vaak in een hoog dimensionele feature set, blijven er verschillende features die redundant zijn, wat betekent dat deze features niets anders zijn dan extensies van de andere essentiële features. Deze overbodige kenmerken dragen ook niet effectief bij aan de modeltraining. Het is dus duidelijk dat de belangrijkste en meest relevante kenmerken voor een dataset moeten worden geëxtraheerd om de meest effectieve voorspellende modelprestaties te verkrijgen.
“Het doel van variabelenselectie is drieledig: de voorspellende prestaties van de voorspellers verbeteren, snellere en meer kosteneffectieve voorspellers bieden, en een beter inzicht verschaffen in het onderliggende proces dat de gegevens heeft gegenereerd.”
-Inleiding tot variabele- en kenmerkselectie
Laten we nu eens het verschil begrijpen tussen dimensionaliteitsreductie en kenmerkselectie.
Soms wordt kenmerkselectie verward met dimensionaliteitsreductie. Maar ze zijn verschillend. Feature selectie is anders dan dimensionaliteitsreductie. Beide methoden hebben de neiging het aantal attributen in de dataset te verminderen, maar een dimensionaliteitsreductiemethode doet dit door nieuwe combinaties van attributen te maken (soms feature transformatie genoemd), terwijl feature selectiemethoden attributen die in de gegevens aanwezig zijn, opnemen en uitsluiten zonder ze te veranderen.
Enkele voorbeelden van dimensionaliteitsreductiemethoden zijn Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis, enz.
Laat me het belang van feature selection voor u samenvatten:
- Het stelt het machine learning-algoritme in staat om sneller te trainen.
- Het vermindert de complexiteit van een model en maakt het eenvoudiger te interpreteren.
- Het verbetert de nauwkeurigheid van een model als de juiste subset wordt gekozen.
- Het vermindert Overfitting.
In het volgende gedeelte bestudeert u de verschillende typen algemene kenmerkselectiemethoden – Filtermethoden, Wrapper-methoden, en Embedded methoden.
Filtermethoden
De volgende afbeelding beschrijft het best filtergebaseerde kenmerkselectiemethoden:

Afbeelding Bron: Analytics Vidhya
Filtermethode vertrouwt op de algemene uniciteit van de te evalueren gegevens en kiest feature subset, zonder enig miningalgoritme. De filtermethode maakt gebruik van het exacte beoordelingscriterium dat afstand, informatie, afhankelijkheid en consistentie omvat. De filtermethode maakt gebruik van de belangrijkste criteria van de rangschikkingstechniek en gebruikt de rangschikkingsmethode voor de selectie van variabelen. De reden voor het gebruik van de rangschikkingsmethode is eenvoud en het produceren van uitstekende en relevante kenmerken. De rangschikkingsmethode zal irrelevante kenmerken uitfilteren voordat het classificatieproces begint.
Filtermethoden worden over het algemeen gebruikt als een data preprocessing stap. De selectie van features is onafhankelijk van een machine learning algoritme. Kenmerken geven een rangorde op basis van statistische scores die de neiging hebben de correlatie van de kenmerken met de uitkomstvariabele te bepalen. Correlatie is een sterk contextgebonden term, die van werk tot werk verschilt. U kunt de volgende tabel raadplegen voor het definiëren van correlatiecoëfficiënten voor verschillende soorten gegevens (in dit geval continue en categorische).

Afbeelding Bron: Analytics Vidhya
Enkele voorbeelden van enkele filtermethoden zijn de Chi-kwadraattoets, de informatiewinst en de scores van de correlatiecoëfficiënt.
Volgende ziet u Wrapper-methoden.
Wrapper methods
Let op filtermethoden, laat me u een zelfde soort info-grafiek geven die u zal helpen om wrapper methoden beter te begrijpen:
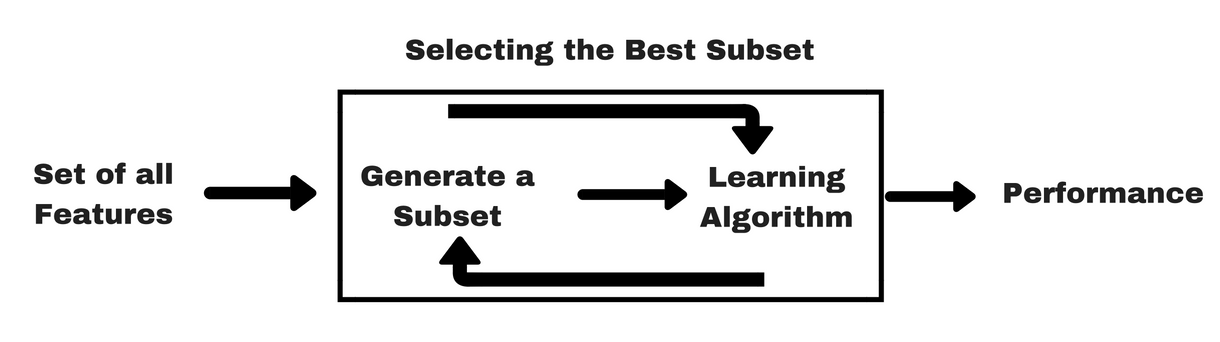
Image Source: Analytics Vidhya
Zoals u in de bovenstaande afbeelding kunt zien, heeft een wrapper-methode één machine learning-algoritme nodig en gebruikt de prestaties ervan als evaluatiecriteria. Deze methode zoekt naar een kenmerk dat het best geschikt is voor het machine-learningalgoritme en beoogt de ontginningsprestaties te verbeteren. Om de kenmerken te evalueren, wordt de voorspellende nauwkeurigheid gebruikt voor classificatietaken en de goedheid van de cluster wordt geëvalueerd met behulp van clustering.
Enkele typische voorbeelden van wrapper-methoden zijn voorwaartse selectie van kenmerken, achterwaartse eliminatie van kenmerken, recursieve eliminatie van kenmerken, enz.
- Voorwaartse selectie: De procedure begint met een lege set features . De beste van de oorspronkelijke kenmerken wordt bepaald en toegevoegd aan de gereduceerde set. Bij elke volgende iteratie wordt het beste van de resterende originele kenmerken aan de verzameling toegevoegd.
- Achterwaartse eliminatie: De procedure begint met de volledige reeks attributen. Bij elke stap wordt het slechtste attribuut uit de verzameling verwijderd.
- Combinatie van voorwaartse selectie en achterwaartse eliminatie: De stapsgewijze voorwaartse selectie en achterwaartse eliminatie kunnen worden gecombineerd, zodat de procedure bij elke stap het beste kenmerk selecteert en het slechtste kenmerk uit de resterende kenmerken verwijdert.
- Recursieve kenmerkeliminatie: Recursieve feature elimination voert een greedy-zoekopdracht uit om de best presterende feature-subset te vinden. Er worden iteratief modellen gemaakt en bij elke iteratie wordt bepaald welk kenmerk het best of het slechtst presteert. Het construeert de volgende modellen met de overgebleven kenmerken totdat alle kenmerken zijn onderzocht. Vervolgens worden de kenmerken gerangschikt op basis van de volgorde waarin ze zijn geëlimineerd. In het ergste geval, als een dataset N aantal features bevat, zal RFE een greedy search doen voor 2N combinaties van features.
Goed genoeg!
Nu gaan we embedded methods bestuderen.
Embedded methods
Embedded methods zijn iteratief in die zin dat ze elke iteratie van het model-trainingsproces voor hun rekening nemen en zorgvuldig die features extraheren die het meest bijdragen aan de training voor een bepaalde iteratie. Regularisatiemethoden zijn de meest gebruikte ingebedde methoden, die een kenmerk bestraffen gegeven een coëfficiëntdrempel.
Daarom worden regularisatiemethoden ook wel bestraffingsmethoden genoemd, die extra beperkingen introduceren in de optimalisatie van een voorspellend algoritme (zoals een regressiealgoritme) die het model in de richting van lagere complexiteit (minder coëfficiënten) sturen.
Voorbeelden van regularisatiealgoritmen zijn LASSO, Elastic Net, Ridge Regression, enz.
Verschil tussen filter- en wrapper-methoden
Wel, het kan soms verwarrend zijn om onderscheid te maken tussen filtermethoden en wrapper-methoden in termen van hun functionaliteiten. Laten we eens kijken op welke punten ze van elkaar verschillen.
- Filtermethoden bevatten geen machine-leermodel om te bepalen of een functie goed of slecht is, terwijl wrapper-methoden een machine-leermodel gebruiken en het de functie trainen om te beslissen of deze essentieel is of niet.
- Filtermethoden zijn veel sneller in vergelijking met wrapper-methoden, omdat ze geen training van de modellen vereisen. Aan de andere kant zijn wrapper-methoden rekentechnisch kostbaar, en in het geval van massieve datasets zijn wrapper-methoden niet de meest effectieve methode voor kenmerkselectie om te overwegen.
- Filtermethoden kunnen er niet in slagen de beste subset van kenmerken te vinden in situaties waarin er niet genoeg gegevens zijn om de statistische correlatie van de kenmerken te modelleren, maar wrapper-methoden kunnen altijd de beste subset van kenmerken opleveren vanwege hun uitputtende aard.
- Het gebruik van features uit wrapper-methoden in uw uiteindelijke machine-leermodel kan leiden tot overfitting, omdat wrapper-methoden al machine-leermodellen trainen met de features en het de ware kracht van het leren aantast. Maar de features van filtermethoden zullen in de meeste gevallen niet tot overfitting leiden
Tot nu toe heb je het belang van feature selectie bestudeerd, het verschil met dimensionaliteitsreductie begrepen. Je hebt ook verschillende soorten methoden voor feature selectie behandeld. Tot zover alles goed!
Nu, laten we eens kijken naar een aantal valkuilen waar je in terecht kunt komen tijdens het uitvoeren van feature selectie:
Belangrijke overweging
Je hebt misschien al begrepen wat feature selectie waard is in een machine learning pijplijn en wat voor diensten het biedt als het wordt geïntegreerd. Maar het is heel belangrijk om te begrijpen op welk punt u feature selectie precies moet integreren in uw machine learning pijplijn.
Simpel gezegd moet u de feature selectie stap opnemen voordat u de gegevens aan het model voert voor training, vooral wanneer u nauwkeurigheidsschattingsmethoden zoals cross-validatie gebruikt. Dit zorgt ervoor dat de selectie van de kenmerken op de gegevens wordt uitgevoerd voordat het model wordt getraind. Maar als je eerst feature selectie uitvoert om je data voor te bereiden, en dan de modelselectie en -training uitvoert op de geselecteerde features, dan zou dat een blunder zijn.
Als je feature selectie uitvoert op alle data en dan kruisvalideert, dan zijn de testdata in elke fold van de kruisvalidatieprocedure ook gebruikt om de features te kiezen, en dit neigt ertoe de prestaties van je machine learning model te vertekenen.
Goeg theorieën! Laten we nu meteen gaan coderen.
Een casestudy in Python
Voor deze casestudy gebruik je de Pima Indians Diabetes dataset. De beschrijving van de dataset vindt u hier.
De dataset komt overeen met classificatietaken waarbij u moet voorspellen of een persoon diabetes heeft op basis van 8 kenmerken.
Er zijn in totaal 768 observaties in de dataset. Uw eerste taak is het laden van de dataset, zodat u verder kunt gaan. Maar eerst moeten we de nodige afhankelijkheden importeren, die je nodig zult hebben. U kunt de andere importeren als je verder gaat.
import pandas as pdimport numpy as npNu dat de afhankelijkheden zijn geïmporteerd laten we de Pima Indianen dataset laden in een Dataframe object met de hulp van Pandas bibliotheek.
data = pd.read_csv("diabetes.csv")De dataset is met succes geladen in het Dataframe object gegevens. Laten we nu eens kijken naar de gegevens.
data.head()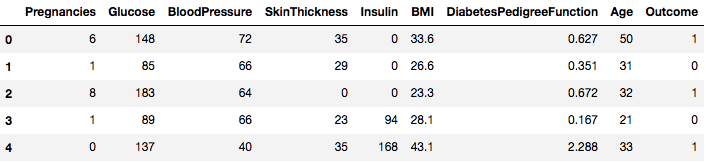
U ziet dus 8 verschillende kenmerken gelabeld in de uitkomsten van 1 en 0 waarbij 1 staat voor de waarneming heeft diabetes, en 0 geeft aan dat de waarneming geen diabetes heeft. Het is bekend dat de dataset ontbrekende waarden heeft. Meer bepaald ontbreken er waarnemingen voor sommige kolommen die als een nulwaarde zijn gemarkeerd. U kunt dit afleiden uit de definitie van die kolommen, en het is onpraktisch om voor die maatregelen een nulwaarde ongeldig te laten zijn, bv, nul voor body mass index of bloeddruk is ongeldig.
Maar voor deze tutorial zult u direct de voorbewerkte versie van de dataset gebruiken.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)U hebt de gegevens nu in een DataFrame-object met de naam dataframe geladen.
Laten we het DataFrame-object converteren naar een NumPy-array om snellere berekeningen te bereiken. Laten we ook de gegevens in aparte variabelen scheiden, zodat de kenmerken en de labels gescheiden zijn.
array = dataframe.valuesX = arrayY = arrayWonderlijk! Je hebt je data voorbereid.
Eerst ga je een Chi-Squared statistische test voor niet-negatieve features implementeren om 4 van de beste features uit de dataset te selecteren. Je hebt al gezien dat de Chi-kwadraattest tot de klasse van filtermethoden behoort. Als iemand nieuwsgierig is naar de internals van Chi-Squared, deze video doet een uitstekende job.
De scikit-learn bibliotheek biedt de SelectKBest klasse die kan worden gebruikt met een reeks van verschillende statistische tests om een specifiek aantal kenmerken te selecteren, in dit geval is het Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Je hebt de bibliotheken geïmporteerd om de experimenten uit te voeren. Nu, laten we het in actie zien.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretatie:
U ziet de scores voor elk kenmerk en de 4 gekozen kenmerken (die met de hoogste scores): plas, test, massa, en leeftijd. Deze scores zullen u verder helpen bij het bepalen van de beste kenmerken voor het trainen van uw model.
P.S.: De eerste rij geeft de namen van de kenmerken aan. Voor de voorbewerking van de dataset zijn de namen numeriek gecodeerd.
Volgende, zul je Recursive Feature Elimination implementeren, wat een soort wrapper feature selectie methode is.
De Recursive Feature Elimination (of RFE) werkt door recursief attributen te verwijderen en een model te bouwen op de attributen die overblijven.
Het gebruikt de nauwkeurigheid van het model om te bepalen welke attributen (en combinatie van attributen) het meest bijdragen aan het voorspellen van het doelattribuut.
Je kunt meer te weten komen over de RFE klasse in de scikit-learn documentatie.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionJe zult RFE gebruiken met de Logistic Regression classifier om de top 3 kenmerken te selecteren. De keuze van het algoritme maakt niet al te veel uit, zolang het maar vaardig en consistent is.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: U kunt zien dat RFE de top 3 features koos als preg, mass, en pedi.
Deze zijn gemarkeerd met True in de support array en gemarkeerd met een keuze “1” in de ranking array. Dit geeft op zijn beurt de sterkte van deze kenmerken aan.
De volgende stap is het gebruik van Ridge-regressie, wat in feite een regularisatietechniek is en ook een ingebedde kenmerkselectietechniek.
Dit artikel geeft u een uitstekende uitleg over Ridge-regressie. Zorg ervoor dat u het uit te checken.
# First things firstfrom sklearn.linear_model import RidgeVolgende, zult u Ridge regressie gebruiken om de coëfficiënt R2.
Ook, check scikit-learn’s officiële documentatie over Ridge regressie.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Om de resultaten van Ridge regressie beter te begrijpen, zult u een kleine helper functie die u zal helpen om de resultaten af te drukken in een beter, zodat u ze gemakkelijk kunt interpreteren implementeren.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Volgende, u zult de coëfficiënt termen van het Ridge model aan deze kleine functie doorgeven en zien wat er gebeurt.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7U kunt alle coëfficiënt termen zien die aan de kenmerk variabelen zijn toegevoegd. Het zal u weer helpen om de meest essentiële kenmerken te kiezen. Hieronder volgen enkele punten die u in gedachten moet houden bij het toepassen van Ridge-regressie:
- Het is ook bekend als L2-Regularisatie.
- Voor gecorreleerde kenmerken betekent dit dat ze de neiging hebben vergelijkbare coëfficiënten te krijgen.
- Feature met negatieve coëfficiënten dragen niet zo veel bij. Maar in een complexer scenario waar je te maken hebt met veel features, dan zal deze score je zeker helpen in het uiteindelijke feature selectie besluitvormingsproces.
Wel, dat concludeert de case study sectie. De methoden die je in de bovenstaande sectie hebt geïmplementeerd, zullen je helpen om de kenmerken van een bepaalde dataset op een uitgebreide manier te begrijpen. Laat me u enkele kritische punten over deze technieken geven:
- Feature selectie is in wezen een onderdeel van data preprocessing dat wordt beschouwd als het meest tijdrovende onderdeel van elke machine learning pipeline.
- Deze technieken zullen u helpen om het op een meer systematische manier en machine learning vriendelijke manier te benaderen. Je zult in staat zijn om de features nauwkeuriger te interpreteren.
Wrap up!
In deze post heb je een van de meest bestudeerde en goed onderzochte statistische onderwerpen behandeld, namelijk feature selectie. Je bent ook vertrouwd geraakt met de verschillende varianten ervan en hebt ze gebruikt om te zien welke features in een dataset belangrijk zijn.
Je kunt deze tutorial verder brengen door een correlatiemaat samen te voegen in de wrapper-methode en te kijken hoe die presteert. In de loop van de actie, zou je kunnen eindigen met het creëren van uw eigen feature selectie mechanisme. Zo leg je de basis voor je kleine onderzoek. Onderzoekers gebruiken ook verschillende soft computing principes om de selectie uit te voeren. Dit is zelf een heel gebied van studie en onderzoek. Ook moet je de bestaande feature selection algoritmes uitproberen op verschillende datasets en je eigen conclusies trekken.
Waarom houden deze traditionele feature selection methodes nog stand?
Ja, deze vraag ligt voor de hand. Want er zijn neurale netarchitecturen (bijvoorbeeld CNN’s) die heel goed in staat zijn om de meest significante features uit data te halen, maar ook dat heeft een beperking. Een CNN gebruiken voor een gewone tabel-dataset die geen specifieke eigenschappen heeft (de eigenschappen die een typisch beeld heeft zoals overgangseigenschappen, randen, positionele eigenschappen, contouren enz. Bovendien, wanneer je beperkte gegevens en middelen hebt, kan het trainen van een CNN op gewone tabulaire datasets een complete verspilling worden. In dat soort situaties komen de methoden die je hebt bestudeerd dus zeker van pas.
Hieronder staan enkele bronnen als je meer over dit onderwerp wilt weten:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection: Statistical and Optimization Perspectives Workshop
- Feature Selection: Problem statement and uses
- U using genetic algorithms for feature selection in Data Analytics
Hieronder staan de referenties die zijn gebruikt om deze tutorial te schrijven.
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- Een introductie in feature selection
- Analytics Vidhya artikel over feature selection
- Hierarchical and Mixed Model – DataCamp course
- Feature Selection For Machine Learning in Python
- Outlier Detection in Stream Data by MachineLearning and Feature Selection Methods
- S. Visalakshi and V. Radha, “A literature review of feature selection techniques and applications: Review of feature selection in data mining,” 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.