Bílkoviny s kotvou GPI jsou zvláštní. V úvodu buněčné biologie nás učili, že existuje pět typů membránových proteinů, které se jmenují následovně: Typ I, typ II, typ III, typ IV a kotvené GPI. Proč máme tuto podivnou třídu proteinů spojených řetězcem cukru a tuku? K čemu slouží? Můžeme získat nějaké poznatky o proteinu mého zájmu – PrP – tím, že se dozvíme více o této třídě proteinů, do které patří?
Sonia a já a náš týmový kolega Andrew a jsme si o tomto tématu něco přečetli a já píšu tento příspěvek na blog, abych se podělil o některé z toho, co jsme se dozvěděli.
čtení
Začali jsme přečtením několika recenzí . Ty se většinou zabývaly strukturou a biogenezí samotné kotvy GPI, o které se toho ví úžasně mnoho.
Tato kotva, jejíž celý název zní glykosylfosfatidylinositol, není monolit: je to obecný popis molekuly, jejíž detaily se mohou lišit. Obecně platí, že počínaje ω (posledním posttranslačně přítomným) zbytkem bílkoviny máte etanolamin, pak fosfát, pak nějaké cukry, pak fosfolipid. Základní cukerná páteř je zachována, ale postranní řetězce, které se od ní odvíjejí, se mohou lišit a lišit se může i fosfolipidová hlavová skupina a mastné kyseliny. GPI kotva PrP byla charakterizována v roce , ale ani tehdy to není monolit – identifikovali nejméně šest různých struktur lišících se složením postranních řetězců cukrů.
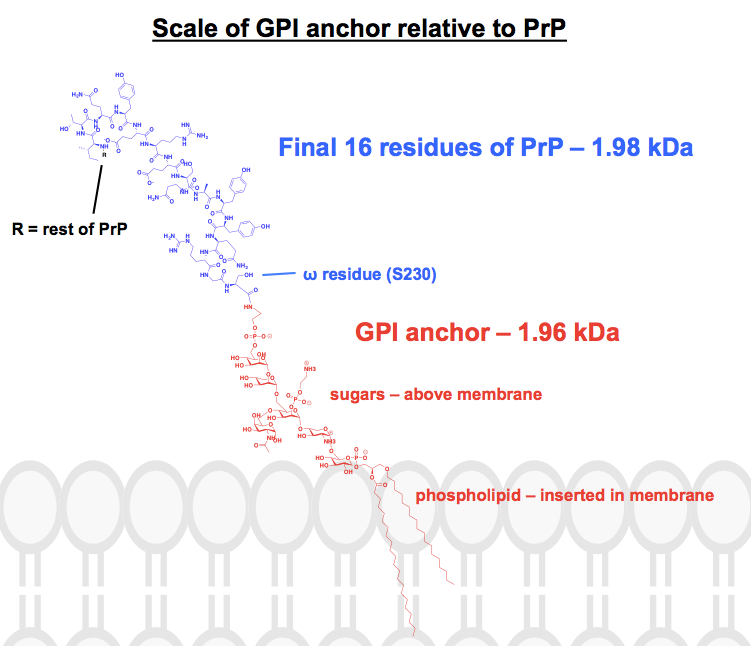
Každá chemická struktura GPI kotvy, kterou jsem našel, má alespoň některé části zkrácené nebo shrnuté a protein je obvykle zobrazen jen jako obrázek. Chtěl jsem získat představu o tom, jak tyto kotvy vlastně vypadají chemicky, v kontextu k nim připojených proteinů, a tak jsem se rozhodl jednu kompletní strukturu skutečně nakreslit v programu ChemDraw. Vycházel jsem z obrázku 1 – nejbližšího obrázku kompletní kosterní struktury, který jsem našel – a přidal jsem detaily jedné z GPI kotev PrP z horního panelu obrázku 6. Molekulová hmotnost vyšla na 1 958 Da, takže jsem pro kontext zakreslil posledních 16 zbytků HuPrP23-230, které váží srovnatelných 1 979 Da. To je asi 8 % posttranslačně modifikované sekvence PrP. Nejsem si jistý, že jsem všechny vazby trefil správně, ale tady je to, k čemu jsem dospěl:
V mnoha případech má gen více izoforem, přičemž jeden produkt sestřihu dává vzniknout proteinu s kotvou GPI, zatímco jiné dávají vzniknout sekretovaným nebo transmembránovým formám. Příkladem může být NCAM1, který má tři hlavní izoformy, z nichž jedna je zakotvena v GPI a další dvě jsou transmembránové , a ACHE (kódující acetylcholinesterázu), jejíž forma zakotvená v GPI se zřejmě vyskytuje pouze na červených krvinkách (NCBI Genes). Nejvíce fascinující je zde příběh myšího genu Ly6a, který je díky genetickému polymorfismu u některých myších kmenů zakotven v GPI a u jiných ne. Pouze ve své GPI-ukotvené formě funguje jako receptor pro virový vektor AAV PHP.eB . (Tento vektor dosahuje úžasně účinného vstřebávání do mozkových neuronů pro genovou terapii , ale bohužel je to pouze myší gen – my lidé Ly6a ani nemáme).
O tom, jak se GPI kotvy syntetizují a připojují k proteinům , se toho ví hodně , přičemž do této cesty je zapojeno >20 proteinů, z nichž většina začíná předponou „PIG“ a jsou kódovány geny jako PIGA, PIGK atd – schéma viz obrázek 2. Většina biosyntézy probíhá s kotvou vloženou do membrány v ER, ale nepřipojenou k žádnému proteinu. Ve skutečnosti se několik prvních kroků odehrává na cytosolovém listu membrány a teprve později se kotva překlopí na lumenální stranu (uvnitř ER). Posledním krokem je, když GPI transamidáza, komplex složený z nejméně pěti proteinů, odštěpí GPI signál z C-konce proteinu a připojí GPI kotvu k tzv. ω zbytku proteinu (poslední zbytek v posttranslačně modifikované sekvenci). Poté dochází k dalšímu zrání kotvy GPI, když protein migruje z ER směrem k povrchu buňky.
Existuje řada malých molekul inhibitorů biosyntézy GPI u hub, z nichž některé se lidé snažili vyvinout jako antimykotika , ale pokud vím, jediným známým inhibitorem biosyntézy GPI u savčích buněk je mannosamin, analog manózy, který je chemicky neslučitelný s inkorporací do GPI .
Hledal jsem a hledal sekvenční logo toho, jaký motiv aminokyselinové sekvence GPI transamidáza rozpoznává, ale žádné jsem nenašel. Podle všeho je sekvenční motiv poměrně volný , a podle všeho signály GPI nejsou ani homologní , což znamená, že se nevyvinuly ze společné ancestrální sekvence, ale spíše se vyvinuly konvergentně, nakolik vůbec existuje nějaká konvergence. Nejlepší popis, který se mi podařilo najít, je, že (čteno od N k C-konci až ke konci proteinu) potřebujete 1) asi 11 zbytků nestrukturovaného linkeru, 2) několik zbytků s malými postranními řetězci včetně zbytku ω, který může být buď S, N, D, G, A, nebo C, 3) spacer 5-10 polárních aminokyselin a nakonec 4) 15-20 hydrofobních aminokyselin . PrP se volně řídí tímto motivem. Podle publikovaných struktur končí alfa šroubovice 3 na zbytku Q223, což ponechává „nestrukturovaný linker“ pouze jako AYYQR (o něco kratší než předepsaných 11 zbytků). Oblast „malého postranního řetězce“ by byla GS|SM (s fajfkou označující místo řezu transamidasy), polární oblast by byla VLFSSPP a hydrofobní C terminus jako VILLISFLIFLIVG.
Některé z proteinů v dráze biosyntézy a vazby GPI jsou velmi důležité a byla popsána řada závažných onemocnění a syndromů nedostatku kotvy GPI, způsobených bialelickou ztrátou funkce nebo zřejmě hypomorfními missense mutacemi v genech jako PIGO, PIGV, PIGW, PGAP2 a PGAP3 .
Sonia našla vynikající článek z doby před několika lety, kde provedli mutagenetický screening v haploidních lidských buňkách, aby identifikovali geny potřebné pro biogenezi dvou proteinů s kotvou GPI: PrP a CD59 . Použili opakované třídění buněk pomocí FACS na základě buněčného povrchu PrP a CD59, aby identifikovali buňky s dramaticky sníženou hladinou těchto proteinů na povrchu, a poté provedli sekvenování, aby zjistili, které knockouty genů jsou v těchto buňkách obohaceny oproti rodičovské populaci. Jak se dalo očekávat, většina genů PIG se objevila pro oba proteiny (obrázek 4), ale ne všechny shody se překrývaly, což je trochu překvapivé, zejména proto, že přinejmenším na úrovni RNA jsou PrP a CD59 dva z proteinů s nejpodobnějšími expresními profily napříč tkáněmi (viz tepelná mapa na konci tohoto příspěvku). Skupina enzymů, které se podílejí na modifikaci postranních řetězců GPI kotvy, se objevila pouze u CD59, což naznačuje, že CD59, ale ne PrP, potřebuje tyto složité postranní řetězce, aby mohl dozrát a dostat se na povrch buněk. Mezitím se Sec62 a Sec63 objevily pouze pro PrP – to jsou proteiny nějakým způsobem zapojené do ko-translační translokace do ER, ale zřejmě jsou potřebné pro PrP, ale ne pro CD59 ani pro CD55 nebo CD109, dva další kontrolní proteiny, které zkoumali. To je fascinující nová kapitola v odpovědi na mou otázku „je něco zvláštního na expresi PrP?“, kde jsem hledal něco jedinečného na biogenezi PrP, na co by bylo možné potenciálně cílit malou molekulou. Samozřejmě to, že tyto proteiny nebyly důležité pro tři další kontrolní proteiny v, neznamená, že nejsou důležité – jedna studie zjistila, že Sec62 je potřebný pro sekreci mnoha malých proteinů , a gen SEC62 je v lidské populaci zcela ochuzen o varianty se ztrátou funkce, což stačí na to, aby se dalo usuzovat na haploinsuficienci. SEC63 se zdá být méně omezený, i když to může znamenat, že působí pouze recesivně.
Nic z výše uvedeného neodpovídá na otázku, proč existují proteiny s kotvou GPI. Moje staré hodiny buněčné biologie mimochodem vynechaly jeden detail: ve skutečnosti existuje šestá třída membránových proteinů, tzv. tail-anchored (TA) proteiny , které mají pouze hydrofobní C terminus, který se zapichuje do membrány, ale nevyčnívá na druhé straně. Proč by všechny tyto GPI ukotvené proteiny nemohly být jen TA proteiny? Proč se v buňkách vyvinula tak složitá cesta, aby místo toho syntetizovaly cukernatou kotvu, a proč se vyvinula tak brzy – kotvy GPI jsou přítomny u všech eukaryot včetně mnoha jednobuněčných patogenů, které infikují člověka.
Většina recenzí nevěnovala této otázce mnoho času, pravděpodobně proto, že je nejtěžší na ni odpovědět. Samotné proteiny s kotvou GPI, pokud jsou známy jejich nativní funkce, mají obrovskou škálu funkcí – jsou zde enzymy (např. AChE), molekuly buněčné adheze (např. NCAM1), proteiny regulující komplement v imunitním systému (CD59) atd . Zřejmě existuje nejméně jeden protein s kotvou GPI, který se podílí na udržování myelinu v periferních nervech . Co přesně však mohou proteiny ukotvené v GPI dělat, co jiné proteiny nemohou? V jednom přehledu je uvedeno několik myšlenek, které byly navrženy. Jednou z nich je, že GPI-ukotvené proteiny jsou dobré v přechodné dimerizaci . Některé studie se zabývaly myšlenkou, že homodimerizace hraje určitou roli v biologii prionů , i když relevance tam použitých modelových systémů pro situaci in vivo zatím není jasná. Další myšlenka spočívá v tom, že vzhledem k tomu, že bílkoviny s kotvou GPI mohou být z povrchu buněk vylučovány, například angiotenzin konvertujícím enzymem (ACE) , může být jejich lokalizace nějakým dynamickým způsobem regulována. I v tomto případě víme, že PrP může být vylučován, zřejmě enzymem ADAM10 , ačkoli jakákoli úloha v nativní funkci PrP není dosud jasná. Třetí myšlenka, o které jsem možná slyšel mluvit nejvíce, je, že proteiny s kotvou GPI se selektivně shromažďují v „lipidových raftech“ . To je asi nejlákavější vysvětlení, protože si lze představit nejrůznější knock-on efekty, kdy zvýšená efektivní lokální koncentrace těchto proteinů umožňuje více interakcí atd. Jedna recenze však upozornila na to, že výhradou je, že lipidové rafty jsou stále spíše abstraktní myšlenkou než konkrétní věcí – ačkoli jsou funkčně definovány nerozpustností detergentů a většina lidí je popisuje jako bohaté na sfingomyelin a cholesterol, neexistuje žádná všeobecně přijímaná definice toho, co je a co není lipidový raft, a empirické důkazy naznačují, že mohou být mnohem menší a přechodnější, než si většina lidí myslí.
S tímto čtením v ruce jsem se rozhodl získat seznam těchto proteinů a provést na nich nějakou analýzu, abych zjistil, zda si mohu udělat lepší představu o tom, jaké jsou.
analýzy
Uniprot obsahuje seznam 173 lidských proteinů s kotvou GPI. Ty byly namapovány na 140 genových symbolů, které po spuštění tohoto skriptu pro aktualizaci na aktuálně schválené genové symboly kódující proteiny HGNC klesly na 135. Konečný seznam 135 genových symbolů je zde.
Uniprot nenabízí žádné informace o tom, jak byly jejich anotace generovány, ačkoli zde musí být značná míra ruční kurately. Pro srovnání Andrew také vyhrabal řadu přehledných článků, které používají PI-PLD nebo PI-PLC, dva enzymy, které štěpí kotvy GPI, k empirické izolaci proteinů s kotvou GPI z buněk . Kombinací seznamů z těchto článků a mapováním na současné genové symboly získal 107 genů. Namátkově jsme zkontrolovali několik z nich. Byly mezi nimi dobře známé proteiny s kotvou GPI, jako je glypican-1 (GPC1) a molekula adheze nervových buněk (NCAM1), u nichž se uvádí interakce s PrP . Přítomno však bylo i několik genů, u nichž se zdálo, že v literatuře není známo žádné ukotvení GPI, jako například VDAC3, přičemž některé z nich mohou být jednoduše velmi hojné proteiny nebo falešně pozitivní z jiných důvodů. Mezitím existují zjevné zdroje falešně negativních genů: geny, které prostě nebyly ve studované buněčné linii exprimovány nebo nebyly dostatečně hojné, aby je bylo možné zachytit pomocí hmotnostní spektrometrie, a paralogy PrP SPRN a PRND nebyly v seznamech. Celkově bylo v obou seznamech 51 genů, což je vysoce významné obohacení (OR = 217, P < 1 × 10-84), které mě ujišťuje, že anotace Uniprot jsou v souladu s empirickými údaji. Pro další analýzy jsme se však rozhodli pro seznam Uniprot, protože se zdá být citlivější a specifičtější.
Pomocí tohoto seznamu jsem se chtěl podívat, jak si stojí proteiny ukotvené v GPI. PrP je jednoexonový, krátký (208 aminokyselin ve zralé formě), neesenciální, široce exprimovaný protein. Jsou tyto vlastnosti typické nebo netypické pro bílkoviny s kotvou GPI?
Ukázalo se, že bílkoviny s kotvou GPI jsou všude na mapě, stejně variabilní v každém rozměru, na který jsem se podíval, jako jakákoli jiná skupina bílkovin.
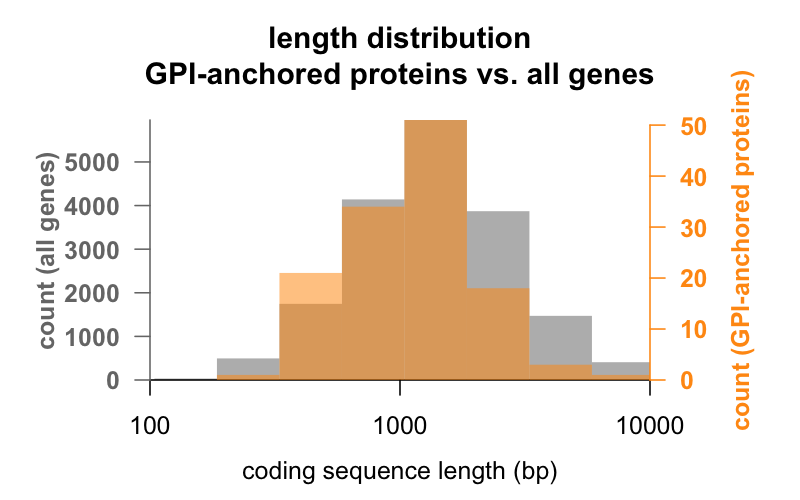
Nejprve délka. Níže jsou překryvné histogramy délky kódující sekvence v párech bází pro všechny geny ve srovnání s geny kódujícími proteiny s kotvou GPI. Rozložení genů s kotvou GPI je jen těsně posunuto doleva. Průměrný gen kódující protein s kotvou GPI má 1 301 bp kódující sekvence, zatímco průměrný gen má 1 729, ale tento rozdíl průměrů je malý ve srovnání s variabilitou v rámci každé skupiny. PrP s pouhými 762 bp kódující sekvence je rozhodně na malé straně, i když v žádném případě není v žádné ze skupin odlehlý – CD52 s pouhými 186 páry bází sekvence a zřejmě pouze 12 aminokyselinami ve zralé formě , je nejmenším proteinem kotveným GPI.
A co počet exonů? GPI-ukotvené proteiny mají v průměru o něco méně exonů ve srovnání se všemi geny (průměr 7,8 vs. 10,1), což odpovídá mírnému rozdílu v rozložení délky, který byl uveden výše, ale většina z nich je víceexonová. I zde je PrP na menší straně: existuje pouze šest proteinů s kotvou GPI, které mají pouze jeden kódující exon, a tři z nich jsou PrP a jeho dva paralogy, Sho a Dpl. (Další tři geny jsou GAS1, SPACA4 a pohádkově pojmenovaný OMG).
Dále jsem se podíval na omezení ztráty funkce. Omezení je měřítkem toho, jak silnému přírodnímu výběru je gen vystaven, na základě toho, jak je ochuzen například o nonsense, frameshift a splice site variace v obecné populaci v porovnání s očekáváním založeným na míře mutací. Tato metrika není příliš interpretovatelná pro krátké geny, a to jak ze statistických důvodů (počet očekávaných mutací je u krátkých genů nízký, takže je těžké kvantifikovat vyčerpání), tak z biologických důvodů (geny s jedním exonem nepodléhají rozpadu zprostředkovanému nesmysly, takže je těžší zjistit, zda varianty zkracující proteiny jsou skutečně „ztrátou funkce“, nebo ne). Ale protože většina proteinů s kotvou GPI není tak krátká jako PrP, myslel jsem, že stojí za to se na to podívat. Výsledek: v průměru jsou GPI-ukotvené proteiny jen o něco méně omezené, což znamená, že mají větší očekávané množství variant ztráty funkce, než průměrný gen. Průměrný gen má 47 % své variability ztráty funkce a proteiny s kotvou GPI mají 56 %. Ale jako u všeho i zde platí, že v obou táborech existuje široké rozdělení. U proteinů s GPI kotvou máme na jedné straně naprosto omezené ACHE (17 očekávaných LoF a žádná nepozorovaná) a na druhé straně několik genů, u kterých se zdá, že selekce proti ztrátě funkce vůbec neprobíhá – CNTN6, CD109, TREH a MSLN jsou několika příklady. PRNP spadá do druhého tábora, jakmile vyloučíte zbytky ≥145, kde varianty zkracující protein způsobují zisk funkce .
Nakonec mě zajímalo, kde jsou exprimovány proteiny s kotvou GPI. PRNP má nejvyšší expresi v mozku, ale je exprimován všude. Je to typické? Stáhl jsem si úplný souhrnný soubor GTEx v7 „gene median tpm“ (15. ledna 2016), kde každý řádek je gen a každý sloupec je tkáň a buňky jsou RPKM – RNA-seq reads per kilobase of exon per million mapped reads. Práce s tímto souborem dat vyžadovala určité doladění. Slyšel jsem, že někteří bioinformatici považují <1 RPKM za „neexprimované“, ale expresní matice je řídká – většina genů není ve většině tkání vysoce exprimovaná – takže šum pod 1 RPKM může dominovat, pokud jen vykreslíte surové RPKM. Mezitím je třeba uvažovat o expresi genů v logaritmickém měřítku, protože geny ve tkáni se mohou pohybovat od <1 RPKM do >10 000 RPKM, takže pokud vše uvažujete v lineárním měřítku, pak může dominovat i několik opravdu vysoce exprimovaných kombinací genů a tkání, takže matice vypadá ještě řidší, než je. Proto jsem vzal log10 matice a rozdělení zkrátil na , takže fialová stupnice, kterou jsem použil, probíhá 1 – 10 – 100 – 1 000 – 10 000 RPKM. Poté jsem provedl subsetování na proteiny ukotvené na Uniprot GPI. Pro vizualizaci jsem poprvé v životě vytvořil heatmapu. Často jsem je viděl v článcích a obvykle mě neoslovily, ale tady bylo mým cílem jen získat představu o vzorci exprese a po chvíli hraní mi to poskytlo největší vhled. Princip tepelné mapy spočívá v tom, že řádky a sloupce jsou seskupeny tak, že podobné věci jdou spolu. Tak například všechny sloupce mozkové tkáně jsou seřazeny postupně do políčka na ose x a všechny geny s vysokou expresí v mozku jsou seřazeny postupně do políčka na ose y, takže jejich průsečík tvoří hustý fialový obdélník, který lze interpretovat jako: „existuje shluk genů, které jsou většinou exprimovány v mozku“.
Zájemci si mohou prohlédnout vektorovou mapu v plném měřítku ve formátu PDF, ale aby byla bezprostředněji přístupná, zde je ručně komentovaná verze, která vyvolává zajímavé shluky:

Odpověď tedy zní ne – většina proteinů s kotvou GPI nemá stejný vzorec exprese jako PRNP. PRNP je jedním z hrstky těch silněji a šířeji exprimovaných, které se objevují blízko vrcholu této tepelné mapy spolu s CD59, LY6E, GPC1 a BST2. Většina proteinů s kotvou GPI má nižší nebo více tkáňově omezenou expresi, přičemž některé jsou téměř výhradně exprimovány v mozku a jiné téměř výhradně v mozku exprimovány nejsou, a další menší shluky patří hlavně do specifických tkání, jako jsou varlata, například paralog PrP PRND, jehož knockout způsobuje mužskou sterilitu .
závěry
Bílkoviny s kotvou GPI mohou mít téměř jakoukoli velikost, mohou být exprimovány v téměř jakékoli tkáni a zřejmě mají téměř jakoukoli funkci, pokud jsou jejich funkce známy. Mnoho proteinů s kotvou GPI má velmi jasné nativní funkce, ale tyto funkce jsou rozmanité a není jasné, proč vyžadují kotvu GPI, zejména proto, že mnoho těchto proteinů existuje i v izoformách bez kotvy GPI. Zatímco u jiných proteinů s kotvou GPI, včetně PrP, víme o nativní funkci pro začátek jen málo, takže je obtížné i jen spekulovat, proč nativní funkce vyžaduje kotvu GPI. Žádná z analýz, které jsem provedl, ani recenzí, které jsem četl, nebyla schopna vyvodit jednotící princip, proč tento mechanismus ukotvení existuje nebo proč ho tyto proteiny vyžadují. Existuje řada hypotéz, proč jsou proteiny s kotvou GPI jedinečné, včetně lipidových raftů, homodimerů a vylučování. Všechny tyto hypotézy mohou mít určité opodstatnění. Nakonec se však zdá, že odpovědí nebude žádný heuréka moment, ale spíše, stejně jako v mnoha jiných oblastech biologie, prozaická směs různých věcí.
Kód R a surové datové soubory pro analýzy v tomto příspěvku jsou zde.
.