インフラストラクチャを仮想化し、仮想リソースを実行してビジネス クリティカルなワークロードを提供することにより、多くの素晴らしい利点がもたらされます。 VMware vSphere の場合、環境に高可用性を提供し、vSphere 環境でハードウェアとリソースを最も効率的に使用するための自動ワークロード スケジューリングなど、多くの注目すべき機能と性能を提供します。
この投稿では、企業における vSphere の中核的なクラスタ レベルの機能である vSphere HA と DRS の 2 つについて説明します。 この 2 つの機能は、企業で vSphere を実行する際に参照されることがほとんどです。
vSphere HA と DRS とは何ですか? これらは何をするのですか?
vSphere 環境でこの 2 つを実行すると、どのような利点があるのでしょうか。
ここでは、VMware vSphere の HA と DRS の基本的な紹介と、両者の比較、および両者を使用するメリットについて見ていきましょう。
VMware vSphere Clusters
VMware vSphere を利用してビジネス クリティカルなワークロードを実行する場合の明らかな利点およびベスト プラクティスの 1 つは、vSphere Cluster を実行することです。
vSphere Cluster とは何ですか?
vSphere Cluster とは、複数の VMware ESXi サーバーを集約し、vSphere Cluster に寄与するリソースのプールとして構成したものです。 CPU計算、メモリ、およびvSANのようなソフトウェア定義ストレージの場合はストレージなどのリソースは、各ESXiホストによって提供されます。
ビジネス クリティカルなワークロードを vSphere クラスター上で実行することが重要な理由
ハイパーバイザーを実行することで得られる利点について考えてみると、単一の物理ハードウェアのセット上で複数のサーバーを実行することが可能になります。 この方法でワークロードを仮想化すると、1 台の物理ハードウェア上で 1 台のサーバーを実行する場合と比較して、多くの効率的な利点が得られます。
ただし、ハードウェア障害の影響は、より多くのビジネス クリティカルなサービスやアプリケーションに影響を与えるため、これは仮想化ソリューションのアキレス腱にもなりえます。 多くの VM を実行している単一の VMware ESXi ホストしかない場合、その単一の ESXi ホストを失ったときの影響は計り知れないと想像できます。
vSphere Cluster で複数の VMware ESXi ホストを実行することが本当に重要なのです。
しかし、単にクラスタで複数のホストを実行すると、高可用性がどのように向上するのかと疑問に思われるかもしれません。 vSphere Cluster 内のホストは、他のホストが故障したことをどのようにして「知る」ことができるのでしょうか。 vSphere Cluster 上で実行されているワークロードの高可用性を管理するために使用される特別なメカニズムがあるのでしょうか。 はい、あります。
VMware の HA とは何ですか。
VMware は、vSphere Cluster で故障した ESXi ホストに対する保護を提供できるメカニズムが必要であることに気づきました。 この必要性から、VMware High-Availability (HA) が生まれました。
VMware vSphere HA は次のような利点を提供します。
VMware vSphere HA はコスト効率が高く、vSphere 環境でサーバー停止またはオペレーティング システム障害が検出された場合、VM と vSphere ホストの自動再起動を可能にします。
vSphere Cluster 内のすべての VMware vSphere Host & VM を監視します。
OS やアプリケーションにかかわらず仮想マシンで実行されているほとんどのアプリケーションに高い可用性を提供します。
VMware Cluster を介して実装される VMware の vSphere HA ソリューションの優れた点は、構成がシンプルであることです。 ウィザード形式のインターフェイスを数回クリックするだけで、高可用性を構成することができます。 従来の「クラスタリング」技術と比較するとどうでしょうか。
Windows Server Failover Clustering の比較
Windows Server Failover Clustering (WSFC) は、クラスタリング技術といえば、ほとんどの人が頭に浮かべるようになった技術でしょう。 WSFC で見られる問題は、WSFC サービスを正しく実行するために、特にアップグレード、パッチ適用、および一般的な運用タスクに関して、多くの専門知識が必要であるということです。
vSphere HA と WSFC を対比すると、運用上のオーバーヘッドは WSFC と比較して最小です。 HA はクラスタで有効か無効かのどちらかであるため、間違って設定される可能性はほとんどありません。 WSFCでは、設定と実装の両方のミスを避けるために、WSFCを構成する際に多くの考慮事項があります。 次のように考えてみてください。
- Failover Clustering にはクラスタリングをサポートするアプリケーション (SQL など) が必要
- Failover Clustering にはクォーラムが正しく構成されている必要がある
- Not supported by many legacy operating systems and applications
- Requires complex of cluster network names, resources and networking
Windows Server Failover Clustering はアプリケーション レベルではほぼゼロダウンタイムと宣伝されています。 しかし、適切に機能する HA ソリューションに必要な専門知識と WSFC の適切な実装を追加すると、アプリケーションとサービスの高可用性のために WSFC を使用する利点よりもリスクが大きくなりかねません。 これは、「ゼロダウンタイム」ソリューションが本当に必要でない多くの組織にとって、特に当てはまることです。 さらに、アプリケーションは WSFC を活用し、WSFC テクノロジーで適切に動作するように設計する必要があります。
vSphere HA では、フェイルオーバーが発生すると、健全なホスト上で仮想マシンを再起動する必要がありますが、ゲスト仮想マシン内に追加のソフトウェアをインストールする必要はなく、追加のクラスタリング テクノロジーで複雑に構成する必要もなく、アプリケーションまたは OS を特定のクラスタリング テクノロジーで動作するように設計する必要はありません。
従来のオペレーティング システムやアプリケーションは、高可用性を提供するためにサポートされているテクノロジーに関して、一般的に能力が制限されています。 そのため、ハードウェア障害の場合にフェイルオーバー機能を提供するネイティブ オプションがない場合があります。
vSphere HA 高可用性メカニズムは機能し、実装、構成、および管理も簡単です。 さらに、これは何千もの VMware の顧客環境で十分にテストされている技術であるため、安定した長い導入の成功実績があります。
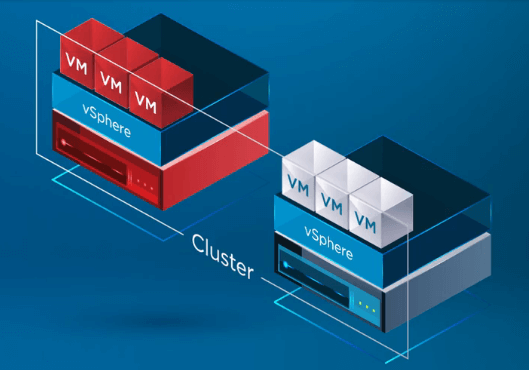
vSphere HA 動作の一般概要
vSphere Cluster の ESXi ホストに提供する利益を利用して、その最も基本的な形で、vSphere HA は vSphere Cluster のホスト間に監視メカニズムを実装しています。 この監視メカニズムは、vSphere Cluster 内のいずれかのホストに障害が発生したかどうかを判断する方法を提供します。
以下のインフォグラフィックでは、2 ノードの vSphere Cluster で、vSphere Cluster 内の ESXi ホストの 1 つに障害が発生した場合を示しています。 この vSphere Cluster では、クラスタ レベルで vSphere HA が有効になっています。
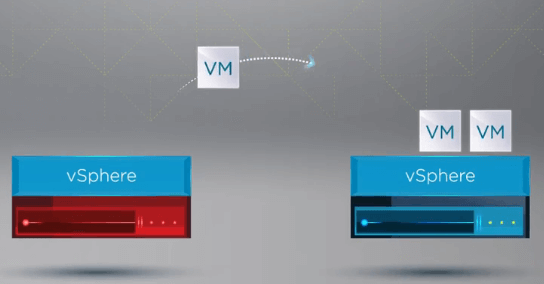
vSphereクラスタ内のホストが障害発生したことを認識すると、HA プロセスによって障害ホストから健全なホストに VM の登録が移動されます。
VMs が健康なホスト上に登録された後、vSphere HA は VM が再登録されたクラスタの健康な ESXi ホストにある障害ホストの全 VM を再起動させます。 発生する唯一のダウンタイムは、vSphere Cluster 内の健全なホスト上の VM の再起動です。
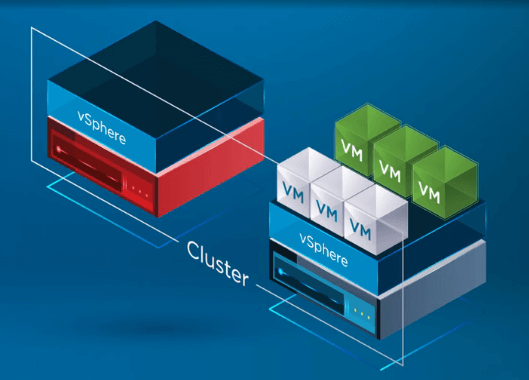
VSphere HA 技術概要
Prerequisites for vSphere HA
vSphere HA の機能にはどんな前提条件があるかと思われるかも知れません。 HA を有効にするには、単に VMware クラスタが必要なのでしょうか。 Windows Server のフェイルオーバー クラスタリングとは異なり、HA を動作させるために必要な要件はごくわずかです。
要件。
- 少なくとも 2 台の ESXi ホスト
- 各ホストに構成された少なくとも 4 GB のメモリ
- vCenter Server
- vSphere Standard License
- VM 用共有ストレージ
- Pingable Gateway またはその他の信頼できるネットワークノード
気づきましたら。 クォーラムコンポーネントは必要なく、複雑なネットワークの名前付けも必要なく、その他の特別なクラスタリソースを配置する必要もありません。
詳しくはこちら。 vSphere High Availability クラスターを構成する方法
VMware vSphere HA マスターと下位ホスト
クラスタで vSphere HA を有効にすると、vSphere Cluster の特定のホストが vSphere HAのマスターとして指定されます。 vSphere Cluster 内の残りの ESXi ホストは、vSphere HA 構成の従属ホストとして構成されます。
マスターに指定されたvSphere HA ESXiホストはどのような役割を担っているのでしょうか? vSphere HA マスターノード:
- Monitors the state of the slave subordinate hosts – If the subordinate host fails or is unreachable, the master host identifies which VMs need to be restarted
- Monitor the power state of all VMs that are protected.下位ホストの状態を監視すること。 VMが故障した場合、マスターvSphere HAノードは、そのVMが再起動されるようにします。 vSphere HA マスターは、VM の再起動が行われる場所(どの ESXi ホスト)を決定します。
- vSphere HA によって保護されているすべてのクラスタホストと VM の追跡を維持
- vSphere Cluster と vCenter Server 間の仲介者として指定されます。 HA マスターは、クラスタの健全性を vCenter に報告し、vCenter Server に対してクラスタの管理インターフェイスを提供します
- VM を自分で実行し、VM の状態を監視できます
- 保護された VM をクラスタ データストアに保存します
vSphere HA Subordinate Hosts:
- ローカルで仮想マシンを実行
- vSphereクラスタ内のVMのランタイム状態を監視
- 状態の更新をvSphere HAマスターに報告
Master Host Election and Master Failure
vSphere HAマスターホストはどのようにして選択されますか? クラスタに対して vSphere HA が有効な場合、すべてのアクティブなホスト (メンテナンス モードなどではない) がマスター ホストの選出に参加します。 選出されたマスターホストに障害が発生した場合、新しい選挙が行われ、その役割を果たす新しいマスターHAホストが選出されます。
VMware vSphere HA Cluster Failure Types
vSphere HA が有効なクラスタでは、vSphere HA フェイルオーバー イベントを引き起こすために起こり得る 3 つのタイプの障害があります。 これらのホスト障害の種類は次のとおりです。
- 障害 – 障害とは、直感的に思いつくものです。
- 分離 – ホストの分離は、一般に、vSphere HA クラスター内の他のホストから特定のホストを分離するネットワーク イベントによって発生します。
- Partition – Partition イベントは、下位ホストが vSphere HA クラスターのマスター ホストへのネットワーク接続を失うことが特徴です。
Heartbeating, Failure Detection, and Failure Actions
マスター ノードは、特定のホストに障害があるかどうかをどのようにして決定しますか?
ホストが故障したかどうかを判断するために、マスター ノードが使用するいくつかの異なるメカニズムがあります。
- マスター ノードは、クラスタの他のホストと毎秒ネットワーク ハートビートを交換します。
- ネットワーク ハートビートが失敗すると、マスター ホストはホスト liveness チェックにチェックします。
- マスターホストから下位ホストのHAエージェントと直接通信できず、管理アドレスへのICMP pingが失敗した場合、そのホストは障害とみなされ、VMは別のホストで再起動します。
- 下位ホストがデータストアとハートビートを交換していることがわかった場合、マスターホストはそのホストがネットワークパーティション内かネットワーク分離されていると見なします。 この場合、マスターは単にホストと VM を監視します。
- ネットワーク分離とは、下位ホストが実行されているが、管理ネットワーク上の HA 管理エージェントの観点からはもはや見ることができない事象です。 ホストがこのトラフィックを見なくなった場合、ホストはクラスタ分離アドレスにpingを送信しようとします。 この Ping が失敗した場合、ホストはネットワークから分離されていることを宣言します
- この場合、マスターノードは分離されたホスト上で実行されている VM を監視します。 VM が分離されたホスト上でパワーオフすると、マスター ノードは別のホスト上で VM を再起動します
Datastore Heartbeating
前述のように、障害検出を判断するために使用するメトリックの 1 つはデータストアのハートビート(心臓の鼓動)です。 これは具体的にどのようなものでしょうか。 VMware vCenterは、ハートビートするデータストアの優先セットを選択します。 そして、vSphere HAは各データストアのルートに、データストアのハートビートと保護対象のVMのリストを維持するための両方の目的で使用されるディレクトリを作成します。 このディレクトリは、.vSphere-HAという名前になります。
vSAN データストアに関して覚えておくべき重要な注意事項があります。 vSAN データストアは、データストアのハートビートには使用できません。 vSANデータストアしか利用できない場合、ハートビートデータストアは使用できません。
- VM and Application Monitoring
vSphere HAのもう1つの非常に強力な機能は、VMware Toolsを介して個々の仮想マシンを監視し、VMware Toolsのハートビートに応答しない仮想マシンを再起動する機能です。 Application Monitoringは、実行中のアプリケーションのハートビートが受信されない場合、VMを再起動させることができます。
- VM Monitoring – VM Monitoring サービスでは、VMware Tools を使用して、VMware Tools が生成するハートビートとディスク I/O の両方をチェックすることによって、各 VM が実行中かどうかを判断します。 これらのチェックが失敗した場合、VM Monitoring サービスは、ゲストオペレーティングシステムが失敗した可能性が高いと判断し、VM を再起動させます。 追加のディスク I/O チェックにより、VM またはアプリケーションがまだ適切に機能している場合、不要な VM のリセットを回避することができます。
Application Monitoring – アプリケーション監視機能は、vSphere HAプロセスによって監視されるアプリケーションのためにカスタマイズされたハートビートを設定できるサードパーティのソフトウェアベンダから適切なSDKを取得することによって有効にされます。 VM監視プロセスと同様に、アプリケーションのハートビートが受信されなくなると、VMはリセットされます。
VMware vSphere HA は、vSphere クラスタ内の ESXi ホストの一般的なホスト障害から保護するために、非常に弾力性のある高可用性を提供する優れた方法です。
VMware の DRS とは何ですか?
VMware Distributed Resource Scheduler (DRS) は、vSphere Cluster を実行する際に非常に強力な機能です。 これは、vSphere Cluster 全体でスケジューリングとロード バランシングを提供します。 VMware DRS は vSphere Cluster で見られる機能で、vSphere 環境内で実行中の仮想マシンに、効果的かつ効率的に実行するために必要なリソースが提供されるようにします。
DRS が有効なクラスターで最初に電源を入れるとすぐに、DRS は VM に必要なリソースを提供するように構成された最適なホスト上に VM を配置するので、通常 VM は初期段階で DRS の対象となります。 さらに、DRS は、リソース使用の観点から vSphere クラスタのバランスを保つように努めています。
vSphere Cluster がある時点でバランスされていても、VM が移動されたり変化したりして、クラスターリソースの不均衡が環境に再び入り込む可能性があります。 クラスタがアンバランスになると、vSphere Cluster で実行されている仮想マシンの全体的なパフォーマンスに悪影響が出る可能性があります。
デフォルトでは、DRS は vSphere クラスター上で 5 分ごとに自動的に実行され、vSphere クラスターのバランスを判断し、リソースをより有効に使用するために変更する必要があるかどうかを確認します。
VMware DRS の要件
VMware DRS を利用するには、分散リソース スケジューラー機能を利用するために満たす必要がある要件がいくつかあります。 4480>
- ESXi ホストのクラスタ
- vCenter Server
- Enterprise Plus ライセンス
- vMotion は自動負荷分散に必要
続きを読む: vSphere DRS クラスタの構成方法
VMware DRS Actions
VMware DRS が vSphere クラスタで 5 分ごとに実行されると、クラスタに存在する不均衡があるかどうか判断されます。 その場合、vMotion が実行され、指定された VM を 1 つの ESXi ホストから別の ESXi ホストに移動します。
DRS は、仮想マシンが 1 つの ESXi ホストまたは別のホストに適しているかどうか、正確にどのように判断するのでしょうか。
DRS は、特定の VM を収容する正しい ESXi ホストを判断するために特別なアルゴリズムを実行します。 VM がパワーオンされると、このアルゴリズムは、特定の VM が特定の ESXi ホストに配置された場合に制約違反がないことを確認した後、vSphere Cluster 全体のリソース配分を考慮します。
さらに、VM 自体の需要も考慮されるので、VM がパワーオンされたときにリソースが不足することがないように願っています。 VM の需要には何が含まれますか。 VM の需要には、実行に必要なリソースの量が含まれます。
- CPU の需要については、これは VM が現在消費している CPU の量に基づいて計算されます
- メモリについては、需要は次の式に基づいて計算されます。 VM メモリの需要 = Function(Active memory used, Swapped, Shared) + 25% (idle consumed memory). これは、DRS メモリ バランスが主に VM のアクティブ メモリ使用に基づいていることを示し、作業負荷の増加に対するクッションとしてそのアイドル消費メモリの少量を考慮することを意味します。
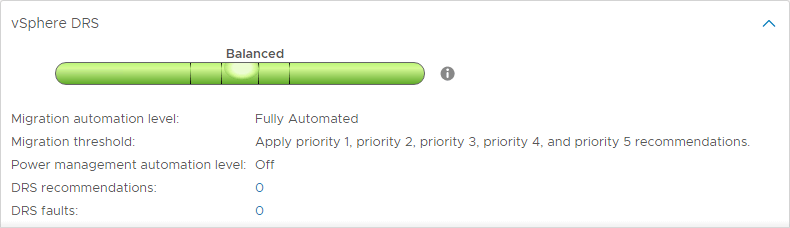
DRS オートメーション レベル
DRS の興味深い機能の 1 つに、DRS オートメーション レベルがあります。 DRS は vSphere Cluster をスキャンして 5 分ごとに推奨事項を提供し続けますが、DRS がその推奨事項を自動的に実行できるか、または行うべき変更のみを提案するかを決定することができます。 DRS には 3 つの DRS 自動化レベルがあります。 これらには以下のものがあります。
- 完全自動化 – 完全自動化では、DRS は初期配置と負荷分散の両方の推奨事項を自動的に適用します
- 部分自動化 – 部分自動化では、DRS は VM の初期配置にのみ推奨事項を適用します
- 手動 – 手動モードでは、手動で行います。 初期配置と負荷分散の両方の推奨を適用する必要があります
DRS Migration Thresholds
DRS には、DRS 推奨が行われる前に許容される不均衡の量を制御する、非常に便利な設定が含まれています。 許容されるアンバランスの量を制御するために、5 つの DRS マイグレーションしきい値があります。
範囲は 1(最も保守的)から 5(最も積極的)です。
より積極的な設定では、DRS はクラスター内の不均衡をより少なく許容します。 より保守的な設定にすると、DRSはより不均衡を許容するようになります。

VMware DRS VM/Host Rules
VMware DRS を使用して vSphere DRS 対応クラスタ内の VM の配置を制御すると、非常に役立つ機能が発見されます。 VM/Host Rules は、特定の VM を特定の ESXi ホストで実行することを可能にします。 これはある意味、アフィニティ・ルールと考えることができます。
VM/Host ルールを使用すると、次のことが可能になります。
- 仮想マシンをまとめる
- 仮想マシンを分離する
- 仮想マシンを特定のホストに結びつける
- 仮想マシンに結びつける
以下は、仮想マシンと ESXi ホストの VM/Host ルール作成の一例です。
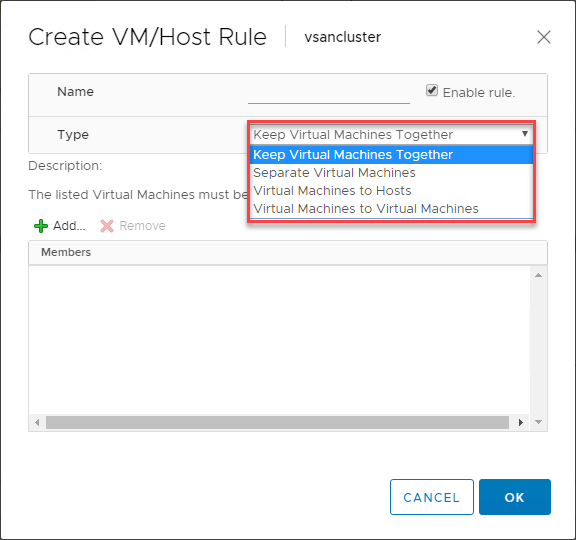
これらの VM/Host ルールにはどのような使用事例があるのでしょうか? 存在する古典的なユースケースの 1 つは、ドメイン コントローラーに関するものです。 一般的に、vSphere Cluster などの仮想化環境ですべてのドメイン コントローラーを実行している場合、ドメイン コントローラーの仮想マシンをクラスター内で互いに分離していることを確認したいと思います。 この方法では、ドメイン コントローラーの 1 つと一緒に ESXi ホストが停止した場合でも、Separate Virtual Machines ルールの対象となるドメイン コントローラーは、別の DC と同じホストに置かれないようにします。
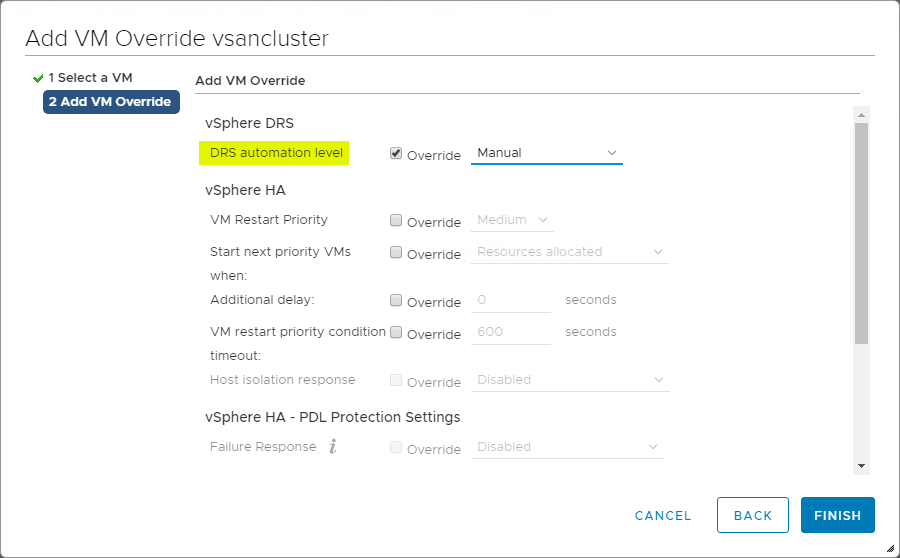
VM Overrides for DRS
vSphereクラスタは、vSphereクラスタの中の個々の VM に影響を与える操作に非常にきめ細やかな機能を提供します。 VM オーバーライドを作成して、HA および DRS のクラスタ レベルで設定されたグローバル設定を上書きし、個々の VM に対してより詳細な設定を定義できます。
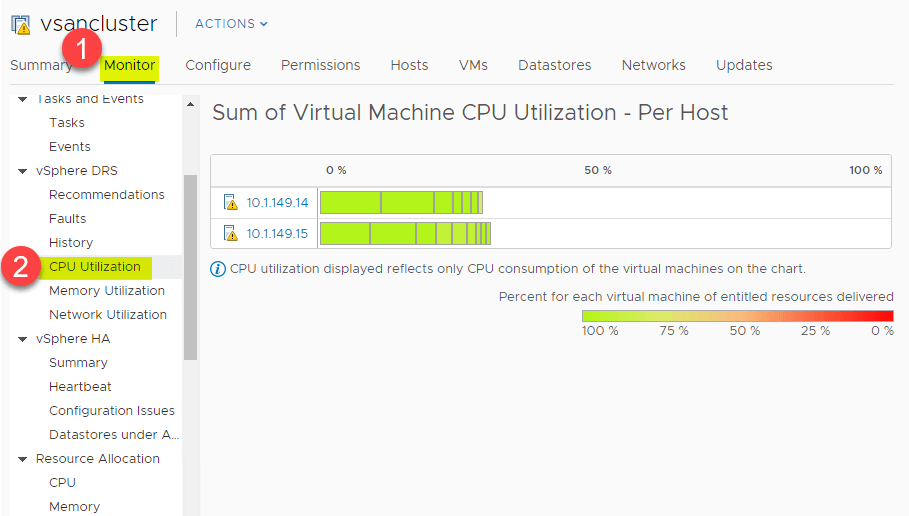
CPU and Memory Utilization Summary
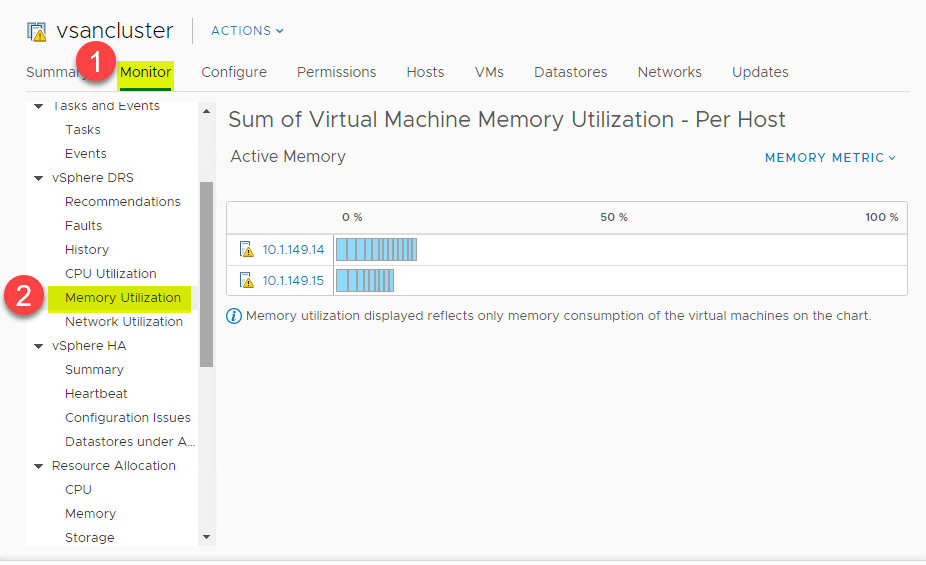
DRS には、vSphere Cluster の ESXi ホストの CPU リソースに対する優れたハイレベル ビューである CPU 利用サマリーがあります。 > 設定 > 監視 > vSphere DRS > CPU 利用率.
同じハイレベルな概要は、メモリ消費についても見ることができます。 > 設定 > 監視 > vSphere DRS > メモリ使用率
The Best of Both Worlds
VMware vSphere HA および VMware DRS は競合技術ですか?
いいえ、そうではありません。 実際、自動フェイルオーバーと負荷分散の特徴と機能を組み合わせるために、vSphere HA と VMware DRS の両方を一緒に使用することが強く推奨されています。 その結果、より弾力性があり、よりバランスのとれた vSphere 環境が実現します。
ESXi ホストに障害が発生した場合、vSphere HA は vSphere Cluster 内の残りの健全なホスト上の VM を再起動します。 そのため、当然ながら仮想マシンのリソースの可用性が最優先されます。 その後、VMware DRSが実行され、ワークロードを実行しているESXiホスト間に不均衡が存在するかどうかを判断し、構成された移行閾値に基づいてクラスタ内の不均衡を解消するための推奨事項を決定します。 自動化レベルに基づいて、これらの推奨事項は自動的に実行されるか、完全に自動化されていない場合は推奨事項のみとなります。
VMware vSphere HA および DRS に関する最後の考察
VMware vSphere HA と DRS の両方を運用することは、本番 vSphere Cluster で強く推奨されます。 両方のテクノロジーを使用することは、ワークロードを高可用性にし、VM の CPU/メモリ要求に基づいて必要なリソースを継続的に確保するのに役立ちます。
両方のメカニズムがどのように機能するかを理解することは、vSphere 管理者として、可能な限り最高の方法で、ベスト プラクティスに一致するように両方のテクノロジーを活用するのに役立ちます。 両方のテクノロジーがもたらす利点のうち、各機能の有効化と構成が非常に簡単であることが挙げられます。 vSphere クラスターのプロパティを数回クリックするだけで、これらのクラスターレベルの機能をすぐに利用できるようになります。
Follow our Twitter and Facebook feeds for new releases, updates, insightful posts and more.
。