By: Derek Colley|Updated: 2014-01-29| コメント (5) | 関連記事 その他の > 関数 – システム
問題
SQL Server のクエリ結果セットからランダムなサンプルを取得しようとしているときです。 おそらく、大規模な顧客データベースからデータの代表サンプルを探している場合、いくつかの平均値を探している場合、または、保持しているデータの種類のアイデアを探している場合でしょう。 特に、アルファベット順やスカラー値で並べた場合、データセットの先頭や末尾にデータの異常値が現れることがよくあるため、SELECT TOP Nは必ずしも理想的ではありません。 同様に、TABLESAMPLEも使用したことがあるかもしれませんが、特に小さいデータセットや歪んだデータセットでは限界があります。 上司から、100人の顧客の名前と場所をランダムに選択するように言われた場合、または監査に参加していて、分析のためにデータのランダムなサンプルを取得する必要がある場合などです。 このような場合、どのようにすればよいのでしょうか。
解決策
このヒントでは、T-SQLでTABLESAMPLEを使用して擬似ランダムなデータサンプルを取得する方法を紹介し、TABLESAMPLEの内部とそれが適切でない場所について説明します。 また、別の方法として、NEWID()とCHECKSUMおよびビット演算子を組み合わせた数学的な方法を紹介します。 一般的な統計的サンプリング(無作為、系統的、階層的の違い)について例を挙げて説明し、SQL統計のサンプリング方法と、このサンプリングを上書きするためのオプションについて見ていきます。 このヒントを読んだ後は、TOP N のような方法を使用するよりもサンプリングすることの利点を理解し、SQL Server でこれを達成するために少なくとも 1 つの方法を適用する方法を知っているはずです。
Setup
このヒントでは、テーブル内の実際のデータを(ぼんやりと)シミュレートするため、ID INT 列(行の選択時のランダム性の程度を定める)と異なるデータタイプの疑似ランダムデータで満たした他の列を含むデータセットは使用することにします。 以下のT-SQLコードを使ってセットアップすることができます。 実行には数分しかかからず、SQL Server 2012 Developer Edition でテストされています。
データの上位 10 行を選択すると、このような結果になります (データの形がわかるように)。余談ですが、これは私が必要なときにランダムなイッシュデータを生成するために作成した一般的なコードの一部です。 AdventureWorksデータベースには、Person.Addressというテーブルが存在します。 上位10件を順不同でサンプルしてみましょう。
SELECT TOP 10 * FROM Person.Address
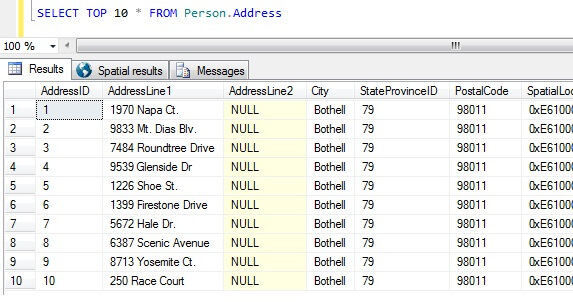
このサンプルだけから見ていくと、返された人はすべてBothellに住んでいて、郵便番号98011を共有していることがわかります。 これは、結果が順不同で返されるように指定されていたのに、実際には AddressID 列の順で返されたためです。 BOL:
の引用を参照してください。「通常、データは最初に行がテーブルに挿入された順序で格納されますが、データベース エンジンは行を効率的に格納するためにヒープ内でデータを移動させることができるため、データの順序を予測することはできません。 ヒープから返される行の順序を保証するには、ORDER BY句を使用する必要があります。
http://technet.microsoft.com/en-us/library/hh213609.aspx
この結果セットを使用すると、テーブルの性質について何も知らない人は、すべての顧客がボセルに住んでいると結論付けるかもしれません。
Typies of Data Sampling in SQL Server
上記は明らかに間違っているので、サンプリングの良い方法が必要です。
これは 47 行を返すはずです:
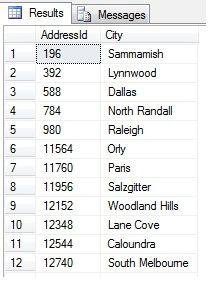
ここまでは順調です。 データセット全体を通して一定の間隔で行を取り、統計的な横断面を返したことになります。 必ずしもそうではありません。 順序が保証されていないことを忘れないでください。 このデータについて、1つか2つの結論を出すことができるかもしれません。 説明のために集計してみましょう。 上記のコード スニペットを再実行し、最後の SELECT ブロックを次のように変更します。
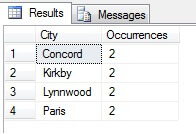
この例では、Person.Address テーブルの 19,000 行以上の総カウントから約 1/4 の行をサンプリングしたため、(この例では)Concord、Kirkby、Lynnwood および Paris が最も住民数が多く、さらに同様に人口が多いと結論付けられることがおわかりいただけると思います。 正確ですか? もちろん無意味です。
見ての通り、私の4つは、この表で判断すると、実際には住みたい場所の上位4つには入っていません。 サンプルデータが少なすぎるだけでなく、この小さなサンプルを集計して、そこから結論を出そうとしたのです。 統計的な有意性を証明することは、統計的なサマリーを提示する際の大きな負担であり(あるいはそうあるべきで)、多くの人気のあるインフォグラフィックスやマーケティング主導のデータグラムの大きな欠点です。
したがって、この方法でのサンプリング(系統的サンプリングと呼ばれます)は有効ですが、統計的に有意な集団にのみ適用されます。 サンプルを台無しにする周期性や割合などの要因があります。次のコードで Person.Address テーブルから都市の個別のリストを取得し、そのリストから系統的サンプリングを使って 10 都市を選択することにより、割合を実際に見てみましょう:
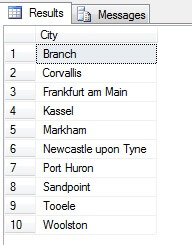
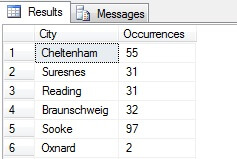
いいサンプルに見えますよね? では、昇順にリストアップされた非同一都市のサンプル、つまりn番目の都市ごとに対比してみましょう(nは行の総数を10で割ったものです)。 この測定では、サンプルの母集団を考慮に入れています:
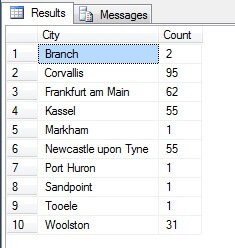
返されたデータは完全に異なっています。 このリストには、データ選択において人口がどの程度影響するかを概説するために、ソースのテーブルに各都市の数を含めていますが、サンプルの中で最も人口の多い上位4都市が含まれており、これは(順序付き非分離リストを考慮すれば)最も公正な表現であることに注意してください。
Other Sampling Methods
Cluster sampling – これは、サンプリングされる人口をクラスタ、またはサブセットに分割し、これらのサブセットの各々が出力結果セットに含まれるかどうかをランダムに決定するものである。 含まれる場合、そのサブセットのすべてのメンバーが結果セットで返されます。 この例については、以下の TABLESAMPLE を参照してください。
不均衡サンプリング – これは層別サンプリングに似ており、グループ全体を代表するためにサブセット グループのメンバーが選択されますが、比例するのではなく、各グループからの代表を均等にするために、選択される各グループからのメンバーの数が異なることがあります。 例えば、上のセクションの例でPerson.Addressに都市がある場合、最初の結果セットは人口を考慮していないので不均衡ですが、2番目の結果セットはPerson.Addressテーブルの都市のエントリ数を表しているので不均衡になります。 このタイプのサンプリングは、特定のカテゴリがデータ セットで十分に表現されておらず、割合が重要でない場合に実際に役立ちます (たとえば、都市で層別した 100 のランダムな都市から 100 のランダムな顧客 – サブセットの都市は正規化が必要 – 不均衡なサンプリングを使用できます)。
SQL Server Random Data with TABLESAMPLE
SQL Server には、有用なデータ サンプリングのメソッドが付属しています。 それを実際に見てみましょう。 次のコードを使用して、先ほど定義した dbo.RandomData から約 100 行のデータを返します(0 行を返した場合は再実行します – 後で説明します)
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
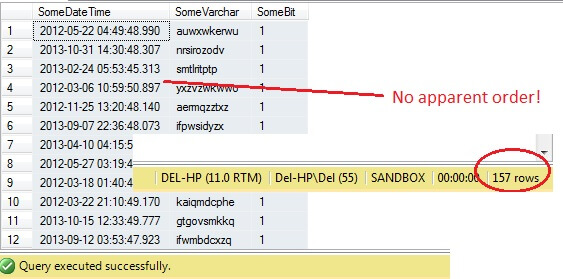
ここまで、順調でしょう? ちょっと待ってください。Id 列が表示されません。
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
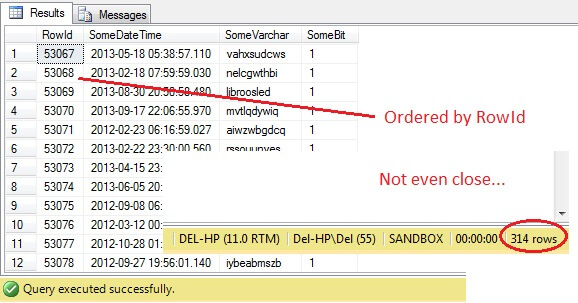
あらら – TABLESAMPLEはデータのスライスを選択しましたが、ランダムではありません – RowIdは最小値と最大値で明確に区分されたスライスであることが示されています。 さらに、それはちょうど100行を返していません。 何が起こっているのでしょうか。
TABLESAMPLE は暗黙の SYSTEM 修飾を使用しています。 この修飾子はデフォルトでオンになっており、ANSI-SQLの仕様、つまりオプションではありません。テーブルが存在する各8KBページを取得し、渡されたパーセントまたはN ROWSに基づいて、そのテーブル内にあるそのページ上のすべての行を生成されるサンプルに含めるかどうかを決定します。 したがって、多くのページに存在するテーブル、すなわち大きなデータ行を持つテーブルは、サンプルに含まれるページ数が多くなるため、より無作為化されたサンプルを返すはずです。 しかし、私たちのようにデータがスカラーで小さく、数ページにしか存在しないような例では、サンプルに含まれるページが少なくなり、出力サンプルが大きく歪む可能性があります。 これはTABLESAMPLEの欠点で、「小さい」データにはうまく機能せず、ページ上のデータの分布が考慮されません。 つまり、ページ上のデータの配置が、このメソッドによって返されるサンプルの最終的な原因です。
これは聞き覚えがありませんか? これは本質的にクラスターサンプリングであり、選択されたグループ (クラスタ) のすべてのメンバー (行) が結果セットで表されます。
逆非スケール性のポイントを強調するために、大きなテーブルでテストしてみましょう。 まず、AdventureWorksデータベースで最大のテーブルを特定しましょう。 これには標準のレポートを使用します。SSMS を使用して、AdventureWorks2012 データベースを右クリックし、[レポート]-[> 標準レポート]-[> トップ テーブルによるディスク使用率]を選択します。 列のヘッダーをクリックして、データ(KB)で並べます(降順にするには、この操作を2回行うとよいでしょう)。
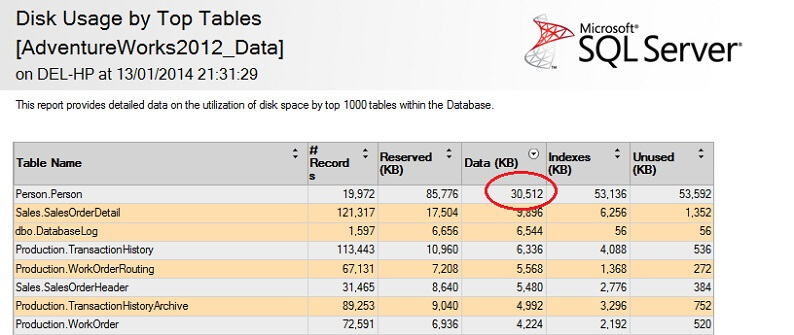
興味深い数字を丸で囲みました – Person.Data.Data.Data。 Person テーブルは 30.5MB のデータを消費し、(レコード数ではなくデータで)最も大きなテーブルです。
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
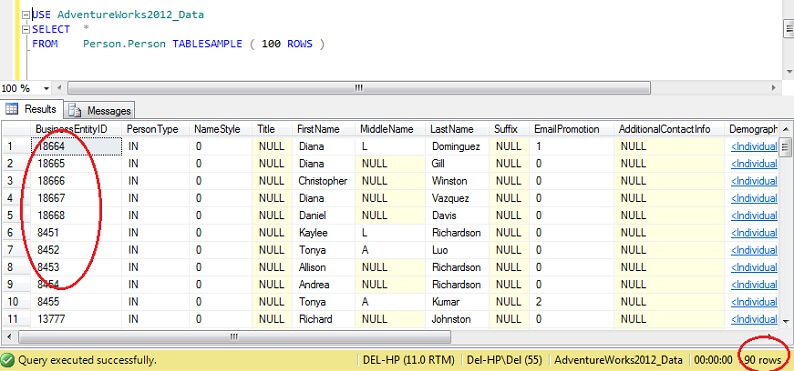
100 行にかなり近づいていることがわかりますが、決定的なのは、主キーにあまりクラスタリングがないように見えることです(ページあたり 1 行以上あるため多少はありますが)。
その結果、TABLESAMPLE は大きなデータに対して有効であり、データセットが小さくなるほど壊滅的に悪くなります。 層別データまたはクラスタ化データからサンプリングする場合、小さなグループまたはデータのサブセットから多くのサンプルを取り、それらを集計する場合、これは良いことではありません。 8224>
Random SQL Server Data with ORDER BY NEWID()
以下は、本当にランダムなサンプルを得るための BOL からの引用です:
「本当に個々の行のランダムサンプルを取得したい場合は、TABLESAMPLE を使用せずにランダムに行をフィルタアウトするようにクエリを変更します。 たとえば、次のクエリは、NEWID 関数を使用して Sales.SalesOrderDetail テーブルの行の約 1 % を返します:
これはどのように機能するのでしょうか。 WHERE句を分割して説明しましょう。
CHECKSUM関数は、リスト内の項目に対してチェックサムを計算しています。 NEWID()は新しいランダムなGUIDを返す関数なので、ランダムな数値に定数を掛けると、どのような場合でもランダムになるはずだからです。 もしあなたが熱心な統計学者で、これを含めることを正当化できるなら、以下のコメント欄を使って、なぜ私が間違っているのかを教えてください!
CHECKSUM 関数は VARBINARY を返します。 0x7fffffff でビット単位の AND 演算を実行すると、2 進数では (111111111…) に相当し、0 と 1 のランダム文字列の表現である 10 進値が効果的に生成されます。 係数 0x7fffffff で割ると、この 10 進数値は 0 と 1 の間の数値に効果的に正規化されます。次に、最終結果セットに各行を含める価値があるかどうかを決定するために、1/x のしきい値 (この場合は 0.01) が使用され、x はサンプルとして取得するデータの割合です。 平均への回帰(この場合、ランダムな結果への傾向)の恩恵を受けるために、複数のサンプルを取り、結果が偏っているように見える場合は、これらのサブセットから選択することを確認します。 これは層別サンプリングと呼ばれるサンプリングの一種です。
How do SQL Server statistics get sampled?
SQL Server では、与えられたテーブルの行の設定閾値を変更すると、列またはユーザー定義の統計情報の自動更新が行われます。 2012 では、この閾値は SQRT(1000 * TR) で計算され、TR はテーブル内のテーブル行の数です。 2005年以前は、テーブルの行が(500行+20%の変化)ごとに自動更新統計ジョブが実行されます。 自動更新処理が開始されると、サンプリングは、*テーブルが大きくなるほどサンプリングされる行数を減らします*。言い換えれば、テーブル サンプリングの割合とテーブルのサイズの間に反比例のような関係がありますが、独自のアルゴリズムに従っています。
興味深いことに、これは TABLESAMPLE (N PERCENT) オプションと反対のようで、テーブルの行数に通常の割合でサンプリングが行われているようです。 自動統計処理を無効にし(注意)、手動で統計処理を更新することができます – これはUPDATE STATISTICS文のNORECOMPUTEを使用することで実現できます。 例えば、N行またはNパーセントのサンプリング(TABLESAMPLEと同様)、FULLSCANの実行、直近の既知の割合を使用した単純なRESAMPLEを選択することができます。
次のステップ
さらに詳しい情報については、Joseph Sack は SQL Server の統計解析の仕事で知られる Microsoft MVP です。 お読みいただきありがとうございます!
Last Updated: 2014-01-29


著者について
 Derek Colleyは英国在住のDBA、BI開発者でSQL Server、Oracle、MySQLで十数年間の経験があります。
Derek Colleyは英国在住のDBA、BI開発者でSQL Server、Oracle、MySQLで十数年間の経験があります。私のヒントをすべて見る
- More Database Developer Tips…