強化学習(RL)は、現代の人工知能の分野で最もホットな研究テーマの1つで、その人気は高まる一方です。 強化学習 (RL) は機械学習技術の一種で、エージェントが自身の行動や経験からのフィードバックを使用して試行錯誤することにより、対話型環境で学習できるようにします。
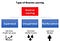
教師ありと強化学習はどちらも入力と出力間のマッピングを用いていますが、エージェントへのフィードバックがタスク実行用の正しい行動のセットである教師あり学習とは異なり、強化学習では正と負の行動に対する信号として報酬と罰が用いられています。
教師なし学習と比較すると、強化学習は目標が異なる。 教師なし学習ではデータ点間の類似点や相違点を見つけることが目標であるが、強化学習の場合はエージェントの累積報酬の総和を最大にするような適切な行動モデルを見つけることが目標である。 下図は一般的なRLモデルの行動-報酬のフィードバックループを示している。

どのようにして基本の強化学習問題を形成するのか?
RL問題の基本的な要素を表すいくつかの重要な用語があります。
- 環境 – エージェントが活動する物理世界
- 状態 – エージェントの現在の状況
- 報酬 – 環境からのフィードバック
- 政策 – エージェントの状態を行動にマッピングする方法
- 価値 – 特定の状態で行動を取ることによりエージェントが受け取るであろう将来の報酬
RL問題はゲームを使って一番うまく説明できるものである。 パックマンゲームを例にとると、エージェント(パックマン)の目標は、途中の幽霊を避けながら、グリッドにある食べ物を食べることである。 この場合、グリッドの世界はエージェントが行動するインタラクティブな環境である。 エージェントは、食べ物を食べると報酬を受け取り、ゴーストに殺されると罰を受ける(ゲームに負ける)。 状態はグリッド世界におけるエージェントの位置であり、総累積報酬はエージェントがゲームに勝つことである。

最適政策を築くために、エージェントは新しい状態を探索しながら同時に全体の報酬を最大化するというジレンマに直面することになる。 これは探索対探索のトレードオフと呼ばれる。 両者のバランスをとるために、最良の全体戦略は短期的な犠牲を伴うかもしれない。 したがって、エージェントは将来的に最適な全体的な決定を行うために十分な情報を収集すべきである。
マルコフ決定過程(MDP)はRLで環境を記述するための数学的枠組みで、ほとんどすべてのRL問題はMDPを使用して定式化することができる。 MDPは有限の環境状態S、各状態における可能な行動A(s)、実数値報酬関数R(s)、遷移モデルP(s’、s|a)の集合から構成される。 しかし、実世界の環境では、環境ダイナミクスの事前知識がない可能性が高い。 4395>
Q-learningはよく使われるモデルフリーな手法で、自己再生するパックマンエージェントを構築するのに使用することができる。 これは、状態 s でアクション a を実行したときの値を示す Q 値を更新する概念を中心に展開されます。以下の値更新ルールは、Q 学習アルゴリズムの中核となります。
Reinforcement Learningアルゴリズムでよく使われるものは?
Q-learning とSARSA (State-Action-Reward-State-Action) はよく使われるモデルフリーRLアルゴリズムである。 両者は探索戦略の点で異なるが、利用戦略は類似している。 Q-learningがオフポリシー方式で,エージェントが別のポリシーから得られる行動a*に基づいて値を学習するのに対し,SARSAはオンポリシー方式で,エージェントは現在のポリシーから得られる現在の行動aに基づいて値を学習する. この2つの方法は実装が簡単であるが、未知の状態に対する値を推定する能力を持たないため、一般性に欠ける。
これは、Q値の推定にニューラルネットワークを使用するDeep Q-Networks(DQN)などのより進んだアルゴリズムによって克服することが可能である。 しかし、DQNは離散的で低次元の行動空間しか扱えない。
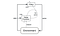
Deep Deterministic Policy Gradient(DDPG)は、高次元の連続行動空間で政策を学習することによってこの問題に取り組むモデルフリー、オフポリシー、アクタークリティックアルゴリズムである。 下図はアクタークリティックのアーキテクチャを表したものです。
Reinforcement Learningの実用化は?
強化学習は多くのデータを必要とするため、ゲームやロボット工学のようにシミュレーションデータが容易に利用できる分野で最も適用されます。
- 強化学習はコンピュータゲームをするためのAIを作る際に非常に広く使われています。 AlphaGo Zero は、古代中国の囲碁ゲームで世界チャンピオンを破った最初のコンピュータ プログラムです。 その他、ATARIゲーム、バックギャモンなど
- ロボット工学や産業オートメーションでは、RLは、ロボットが自分自身の経験や行動から学習する効率的な適応制御システムを構築できるようにするために使用されています。 DeepMind の「Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates」での研究は、その良い例です。 5305>
RL の他のアプリケーションには、抽象的なテキスト要約エンジン、ユーザーとの対話から学習し時間と共に改善する対話エージェント(テキスト、スピーチ)、ヘルスケアにおける最適な治療方針の学習、オンライン株式取引用のRLベースのエージェントが含まれます。
強化学習を始めるには?
強化学習の基本概念を理解するには、以下の資料が参考になります。
- Reinforcement Learning-An Introductionは強化学習の父、リチャード・サットンとその博士課程指導者アンドリュー・バルトによる書籍です。 この本のオンラインドラフトはこちら。
- David Silverによるビデオ講義を含む教材は、RLの素晴らしい入門コースです。
- Pieter Abbeel と John Schulman (Open AI/ Berkeley AI Research Lab) によるRLに関する技術チュートリアルもあります。
RLエージェントの構築とテストを始めるには、以下のリソースが役に立ちます。
- Andrej Karpathy による、生のピクセルから Policy Gradients を使用して Neural Network ATARI Pong エージェントをトレーニングする方法に関するこのブログは、わずか 130 行の Python コードで、最初の Deep Reinforcement Learning エージェントを立ち上げて実行できるようにするのに役立つでしょう。
- DeepMind Labは、エージェントベースのAI研究のために、豊富なシミュレーション環境を備えた、オープンソースの3Dゲームのようなプラットフォームです。
- Project Malmoは、AIの基礎研究をサポートするためのもう一つのAI実験プラットフォームです。
- OpenAI gymは強化学習アルゴリズムの構築と比較のためのツールキットです。