スキーマ管理の基本を理解することは、効果的な PostgreSQL データベースを構築し維持するために非常に重要です。 この記事では、Postgres スキーマを管理する従来の方法と、コードの行を書くことなく視覚的にそれを行う、より新しい効果的な方法について見ていきたいと思います。
PostgreSQLスキーマとは
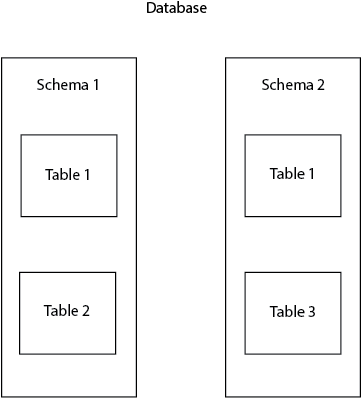
最初に、この記事の土台を築くために、いくつかの用語を整理しておきましょう。 Postgresでは、スキーマは名前空間とも呼ばれます。 名前空間はファミリ名と関連付けることができます。 データベース内の特定のオブジェクト(テーブル、ビュー、カラムなど)を識別し、区別するために使用されます。 1つのスキーマに同じ名前のテーブルを2つ作ることはできませんが、2つの異なるスキーマに作ることは可能です。 例えば、publicスキーマとpostgresスキーマにtable1という名前の2つのテーブルを作成することができます。
なぜスキーマを使うのか
スキーマはデータベースオブジェクトを論理グループに整理して名前の衝突を避けるために非常に有用です。 これに加えて、スキーマは、異なるユーザーが互いに干渉することなくデータベースを操作できるようにするためによく使用されます。 よくある例は、各データベース・ユーザーが他のユーザーと干渉せず、衝突を避けながら自分のスキーマで作業する場合です。
PostgreSQLスキーマの古典的な管理方法
以下のすべての問い合わせはPostgreSQLシェル内部から実行されます。
スキーマの作成
Postgreで新しいデータベースを作成すると、デフォルトスキーマはパブリックとなります。 次のクエリを実行することにより、新しいスキーマを作成することができます。
CREATE SCHEMA schema_1;
いくつかのテーブルを追加する前に。 2つの重要な概念を説明します。 修飾名と非修飾名です。
-
修飾名は、スキーマ名とテーブル名をドットで区切ったものです。 これは、テーブルを作成するスキーマを指定することになります。
xxxxxxxxxx
CREATE TABLE schema_name.table_name (...);
-
非限定名はテーブル名のみから構成されます。 これは、デフォルトで公開されている選択されたデータベースにテーブルを作成します。 これはsearch_pathで変更可能ですが、詳細は後述します。 非限定名の例を挙げます。
xxxxxxxxxx
CREATE TABLE table_name (...);
テーブルの列は、上記のクエリから括弧内に定義されます(…).
新しいスキーマに新しいテーブルを作成するために、以下を実行します。
を実行することになります。
xxxxxxxxxx
CREATE TABLE schema_1.persons (name text, age int);
スキーマを削除する場合。 の2つの可能性があります。 スキーマが空の場合(テーブル、ビュー、その他のオブジェクトを含まない)、実行することができます。
を実行することができます。
xxxxxxxxxx
DROP SCHEMA schema_1;
スキーマにデータベースオブジェクトが含まれている場合。 カスケードコマンドを挿入します。
を挿入する。
xxxxxxxxxx
DROP SCHEMA schema_1 CASCADE;
PostgreSQLでは、別のユーザが所有するスキーマを作成することも可能です。
xxxxxxxxxx
CREATE SCHEMA schema_name AUTHORIZATION username;
検索パス
未修飾名のコマンドを実行した場合。 Postgresはどのスキーマを使用するかを決定するために検索パスをたどります。 デフォルトでは、検索パスはパブリックスキーマに設定されています。 これを表示するには、以下を実行します。
xxxxxxxxxx
SHOW search_path;
あなたのデータベースで何も変更されていない場合は、。 このクエリは次の結果をもたらすはずです。
xxxxxxxxxx
search_path
--------------
"$user",public
search_pathは変更可能で、unqualified nameを使用するとシステムが自動的に別のスキーマを選択するようにします。 検索パスの最初のスキーマをカレント・スキーマと呼びます。 例えば、schema_1をカレント・スキーマとして設定します。
xxxxxxxxxx
SET search_path TO schema_1,public;
次のクエリは、非限定名を使用してテーブルを作成します。 これは自動的にschema_1に作成されます。
に作成されます。
xxxxxxxxxx
CREATE TABLE address (city text, street text, number int);
新しい道です。 コードなしで管理する!
すべてのスキーマ管理タスクを、コードを一切書かずに行う、よりシンプルな方法があります。 DbSchema を使用すると、直感的な GUI から数回クリックするだけで、上記のすべてのクエリを実行することができます。 データベースへの接続は数秒しかかかりません。 最初から、作業するスキーマを選択できます。
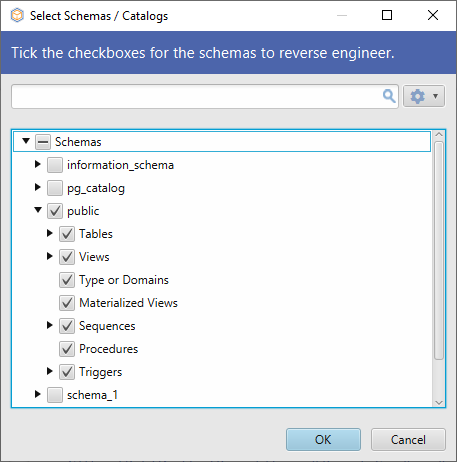
選択したスキーマは DbSchema によってリバース エンジニアリングされ、レイアウトに表示されます。
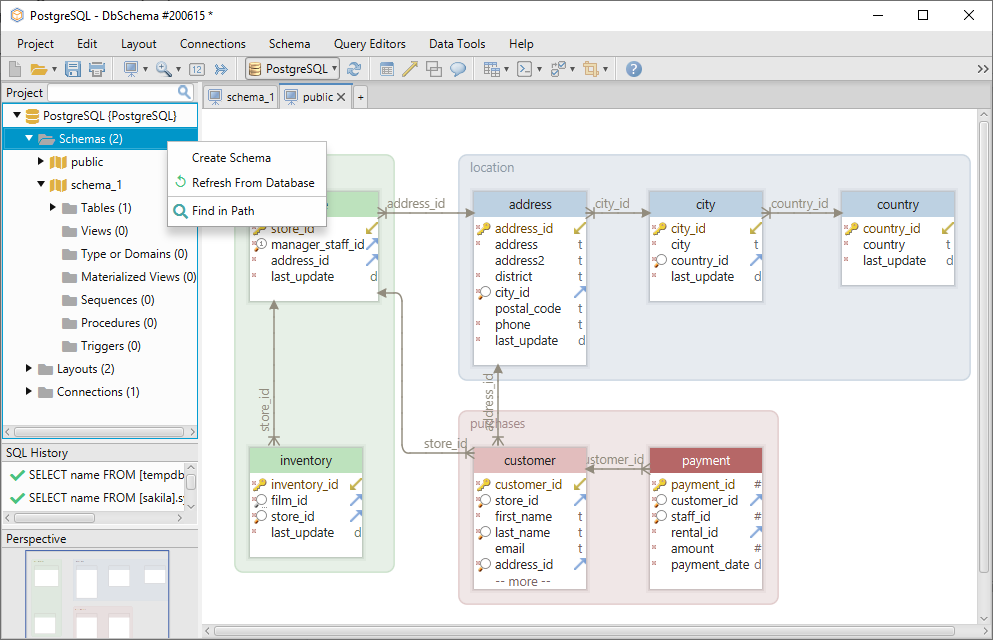
新しいスキーマを作成するには、左メニューのスキーマ フォルダを右クリックして、スキーマの作成を選択します。
スキーマ内に新しいテーブルを作成するには、レイアウトを右クリックして、テーブルの作成を選択します。
スキーマは、左メニューからその名前を右クリックすることでドロップできます。
データベースから別のスキーマを追加するには、[データベースから更新]を選択します。
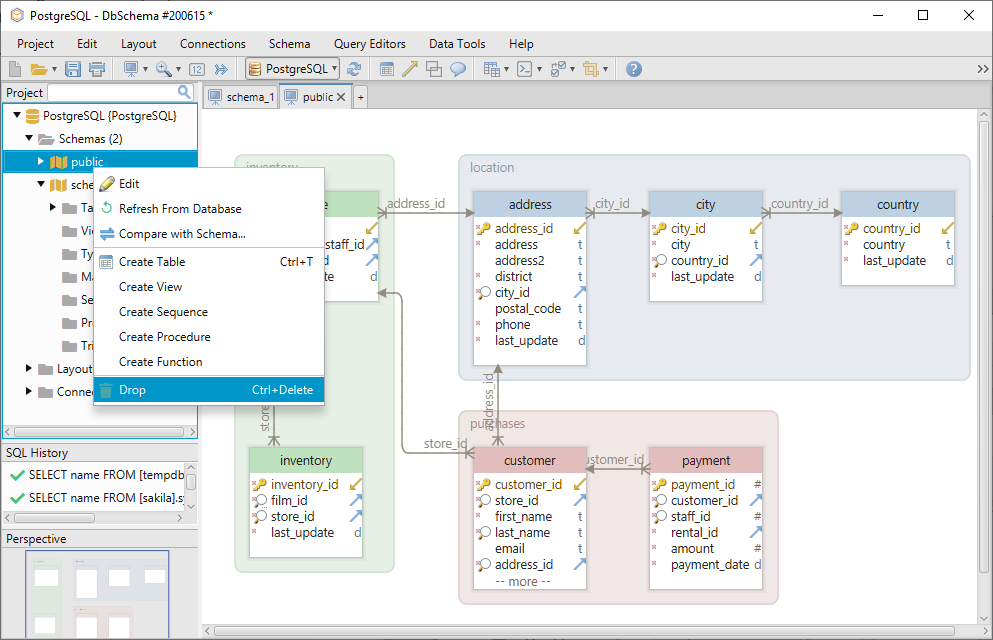
DbSchema を使用すると、レイアウト内でテーブルを直接作成できるので、show_path 構文を使用する必要はありません。 レイアウトは、テーブルを追加して編集することができる製図板に例えることができます。 各レイアウトには1つのスキーマが関連付けられており、schema_1レイアウトを使用している場合、テーブルが自動的にそこに作成されます。
Work Offline
DbSchema はスキーマのローカル イメージをローカル プロジェクト ファイルに保存します。 これは、データベース接続なしで (オフラインで) プロジェクト ファイルを開くことができることを意味します。 オフラインの間、上で紹介したすべてのアクションとそれ以上のことを行うことができますが、データがない状態です。 データベースへの再接続後、プロジェクトファイルとデータベースを比較し、どのアクションを残すか、または削除するかを選択することができます。
同じプロジェクト ファイルの異なる 2 つのバージョン間で、同じことを行うことができます。 たとえば、チームで作業している場合、複数のスキーマ (本番、テスト、開発) があり、それぞれが独自のプロジェクト ファイルを持っていることがあります。 もし、ある変更が開発版で発生し、それを他の2つのスキーマに反映させたい場合、2つのプロジェクトファイルを比較・同期させればよいのです。
まとめ
上に挙げた概念を理解することで、PostgreSQLスキーマを容易に管理できるようになります。 DbSchemaのようなビジュアルデザイナーを使用すると、コードを1行も書くことなく、すべてを視覚的に行うことができるので、作業がさらに簡単になります。