Introduction
If you are analysing your data using multiple regression and any of your independent variables were measured on nominal or ordinal scale, you know how to create dummy variables and interpret their results.The SPSS Statistics は、重回帰を使用してデータを分析し、独立変数のいずれかが名義尺度または序数を測定した場合、あなたはダミー変数を作成する方法を知る必要がありますとその結果を解釈します。 これは、より広くカテゴリ独立変数として知られている名目および順序独立変数が、重回帰分析に直接入力することができないからです。 その代わりに、ダミー変数に変換する必要があります。 例外は、連続独立変数として重回帰分析に入力される順序独立変数で、これはダミー変数に変換する必要がありません。 したがって、このガイドでは、カテゴリ独立変数がある場合にダミー変数を作成する方法を示します。
最初に、SPSS Statisticsの変数ビューとデータビューウィンドウでデータを設定する方法を説明する前に、SPSS Statisticsでダミー変数を作成する方法を示すために使用する例を設定し、ダミー変数を作成できるようにする必要があります。 ダミー変数の使用に慣れていない場合は、次に、ダミー変数とダミーコーディングの基本原則のいくつかについて、以下を含む、読むことをお勧めします。 (a) 分析に必要なダミー変数の数、(b) ダミー変数の作成方法とダミーコーディング。 続く手順編では、ダミー変数の作成に使用できるSPSS Statisticsのダミー変数の作成手順を3ステップで簡単に設定します。 最後に、ダミー変数がSPSS Statisticsの変数ビューとデータビューウィンドウで設定される方法を含む、ダミー変数の作成手順を実行した後のSPSS Statisticsの出力について説明します。
SPSS Statistics
このガイドで使用する例
このガイドでは、トライアスロンをするときに行う3つのスポーツ(水泳、自転車、ランニング)からお気に入りのスポーツを選択するよう求められた10人のトライアスリートを例にとって説明します。 彼らの回答は、3つのカテゴリを持つ名目独立変数favent_sportに記録されました。 「水泳」、「サイクリング」、「ランニング」である。 この名目独立変数favorite_sportは、いくつかの連続独立変数を持つ重回帰分析に含まれる予定であった。 この独立変数がカテゴリ変数(すなわち、名目変数と順序変数はカテゴリ変数として大別できる)であったので、重回帰分析に入力する前にダミー変数を作成しなければなりませんでした。
Important: Favorite_sport は名目変数ですが、順序変数に対してダミー変数も作成できることに注意してください。 さらに、ダミー変数を作成するプロセスは、順序変数または名義変数に関係なく同じですが、データをセットアップするときに、1つの小さな変更をしなければなりません。 “低”、”中”、”高 “の3つのレベルがある)。 しかし、これらの3つの用語 – “カテゴリ”、”グループ”、”レベル”- は、互換的に使用することができます。 このガイドでは、カテゴリーと呼ぶが、好みによりグループまたはレベルと呼ぶこともできる。
注2:「カテゴリー的独立変数」(すなわち、「序数」または「名目」である独立変数)の代わりに、「因子」という用語が使われることがある。 しかし、これら2つの用語、「カテゴリカル独立変数」と「因子」は、互換性を持って使用することができます。 このガイドでは、カテゴリカル独立変数と呼び、SPSS Statisticsが重回帰手順で因子ではなく独立変数と呼ぶのを見ることもできます。 しかし、あなたが好むなら、それらを因子と呼ぶことができます。
SPSS Statistics
SPSS Statisticsでデータを設定する
ダミー変数を作成すると、単一のカテゴリ独立変数(例:favorite_sport)で開始することになります。 このカテゴリ独立変数を設定するには、SPSS Statistics は、分析する変数の種類を定義する変数ビューと、この変数のデータを入力するデータビューがあります。 ここでは、まずSPSS StatisticsのVariable Viewウィンドウでカテゴリ独立変数を設定する方法を紹介し、その後にData Viewウィンドウにデータを入力する方法を紹介します。 我々は、3つのカテゴリを持つカテゴリ独立変数favorite_sportを使用してこれを行います。 「
SPSS Statisticsの変数ビュー
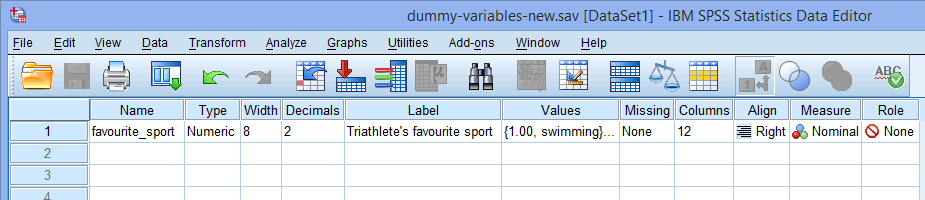
単一のカテゴリ独立変数(例えば, 注:SPSS Statistics ソフトウェアの左下隅にある ![]() タブをクリックすると、SPSS Statistics の変数ビューウィンドウにアクセスできます。
タブをクリックすると、SPSS Statistics の変数ビューウィンドウにアクセスできます。
Published with written permission from SPSS Statistics, IBM Corporation.
The name of your categorical independent variable should be entered in the cell under the ![]() column (e.g…..), “favourite_sport” を行
column (e.g…..), “favourite_sport” を行 ![]() に入力し、カテゴリ独立変数favorite_sport を表します。
に入力し、カテゴリ独立変数favorite_sport を表します。 ![]() セルには、入力できない「不正な」文字があります。 したがって、エラーメッセージが表示され、これらの違法な文字が何であるかを説明するためにSPSS Statisticsガイドを追加したい場合は、弊社までご連絡ください。
セルには、入力できない「不正な」文字があります。 したがって、エラーメッセージが表示され、これらの違法な文字が何であるかを説明するためにSPSS Statisticsガイドを追加したい場合は、弊社までご連絡ください。
Note: あなた自身の明確さのために、![]() 列に変数のラベルを提供することも可能です。 例えば、我々が「favent_sport」に入力したラベルは、「トライアスリートの好きなスポーツ」でした。
列に変数のラベルを提供することも可能です。 例えば、我々が「favent_sport」に入力したラベルは、「トライアスリートの好きなスポーツ」でした。
![]() 列の下のセルには、カテゴリ独立変数のカテゴリに関する情報を含める必要があります(例:favent_sportは「水泳」、「自転車」および「ランニング」です。 この情報を入力するには、独立変数の
列の下のセルには、カテゴリ独立変数のカテゴリに関する情報を含める必要があります(例:favent_sportは「水泳」、「自転車」および「ランニング」です。 この情報を入力するには、独立変数の![]() 列の下のセルをクリックします。
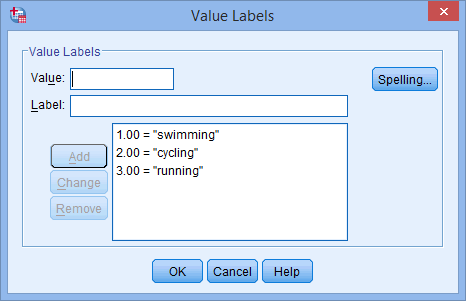
列の下のセルをクリックします。 ![]() ボタンがセルに表示されます。 このボタンをクリックすると、「値のラベル」ダイアログボックスが表示されます。 ここで、独立変数の各カテゴリに「値」を与え、「値」ボックスに入力し(例:「1」)、「ラベル」ボックスに入力し(例:「泳ぐ」)、「ラベル」を設定する必要があります。
ボタンがセルに表示されます。 このボタンをクリックすると、「値のラベル」ダイアログボックスが表示されます。 ここで、独立変数の各カテゴリに「値」を与え、「値」ボックスに入力し(例:「1」)、「ラベル」ボックスに入力し(例:「泳ぐ」)、「ラベル」を設定する必要があります。 ![]() ボタンをクリックすると、コーディングがメインボックスに表示されます(例:favorite_sportは「1.00=”swimming”」と表示されます)。 私たちのカテゴリ独立変数のセットアップは、以下の値ラベルダイアログボックスに表示されます:
ボタンをクリックすると、コーディングがメインボックスに表示されます(例:favorite_sportは「1.00=”swimming”」と表示されます)。 私たちのカテゴリ独立変数のセットアップは、以下の値ラベルダイアログボックスに表示されます:
Published with written permission from SPSS Statistics, IBM Corporation.
![]() 列下のセルには、名目独立変数(例:, favourite_sport, as in our example)、または順序独立変数(例えば、”Body Mass Index” (BMI), BMI)のような順序変数を想像してください、これは4レベルを持っています)を持っている場合は
列下のセルには、名目独立変数(例:, favourite_sport, as in our example)、または順序独立変数(例えば、”Body Mass Index” (BMI), BMI)のような順序変数を想像してください、これは4レベルを持っています)を持っている場合は![]() を表示します。 “Underweight”, “Healthy/Normal Weight”, “Overweight”, and “Obese”) の4つのレベルがあります。 最後に、
を表示します。 “Underweight”, “Healthy/Normal Weight”, “Overweight”, and “Obese”) の4つのレベルがあります。 最後に、![]() 列の下のセルに
列の下のセルに![]() .
.
注:![]() 列の下のセルを
列の下のセルを![]() から
から![]() に変更することをお勧めしますが、この変更をする必要はありません。 SPSS Statistics の特定の分析では、
に変更することをお勧めしますが、この変更をする必要はありません。 SPSS Statistics の特定の分析では、![]() の設定により、使用しているダイアログ ボックスの特定のフィールドに変数が自動的に転送されることがあるため、この変更を行うことをお勧めします。 これらの変数を転送したくない場合がありますので、これが自動的に起こらないように
の設定により、使用しているダイアログ ボックスの特定のフィールドに変数が自動的に転送されることがあるため、この変更を行うことをお勧めします。 これらの変数を転送したくない場合がありますので、これが自動的に起こらないように![]() 設定を
設定を![]() に変更することをお勧めします。
に変更することをお勧めします。
あなたは今、SPSS Statisticsが変数表示ウィンドウにあなたのカテゴリ独立変数について知る必要があるすべての情報を正常に入力しました。 次のセクションでは、データビューウィンドウにデータを入力する方法を示します。
SPSS Statisticsのデータビュー
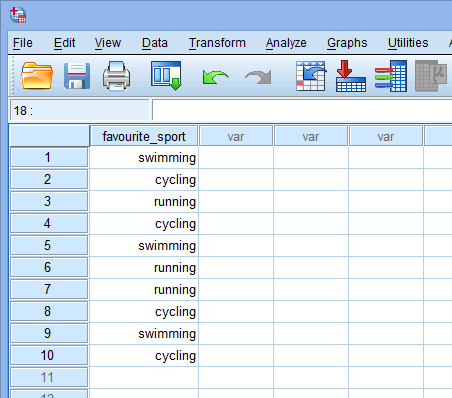
上記の変数ビューウィンドウであなたのカテゴリ独立変数のファイルセットアップに基づいて、データビューウィンドウは次のように表示されます:
注:あなたはSPSS Statisticsソフトウェアの左下隅の![]() タブをクリックしてSPSS Statisticsのデータビューウィンドウにアクセスすることができます。
タブをクリックしてSPSS Statisticsのデータビューウィンドウにアクセスすることができます。
Published with written permission from SPSS Statistics, IBM Corporation.
Your categorical independent variable will be displayed in the first column since this was the order we entered the variable in the Variable View window.これは変数表示ウィンドウに変数を入力した順序であるためです。 我々の例では、10人のトライアスリートの回答が、![]() 列の下に表示されます。 さて、この最初の列の下のセルにデータを入力する必要があります。 各行が 1 つのケースを表すことに注意してください (たとえば、ケースは 1 人の参加者である可能性があります)。 したがって、この例の
列の下に表示されます。 さて、この最初の列の下のセルにデータを入力する必要があります。 各行が 1 つのケースを表すことに注意してください (たとえば、ケースは 1 人の参加者である可能性があります)。 したがって、この例の![]() 行では、最初のケースは、好きなスポーツが「水泳」であるトライアスロン選手を表しています。 これらのセルは、最初は空白なので、データを入力するためにセルをクリックする必要があります。 あなたは
行では、最初のケースは、好きなスポーツが「水泳」であるトライアスロン選手を表しています。 これらのセルは、最初は空白なので、データを入力するためにセルをクリックする必要があります。 あなたは![]() 列の下のセルをクリックすると、SPSS Statisticsは、あなたのカテゴリがすでに入力されたドロップダウンオプションを提供することに気づくでしょう。 ダミー変数とダミーコーディングの基本原理を説明する、ダミー変数とダミーコーディングを理解する。 しかし、すでにダミー変数とダミーコーディングの基本に精通している場合は、このセクションをスキップして、ダミー変数を作成するために使用されるSPSS Statisticsのダミー変数の作成手順を設定した手順のセクションに直接行くことができます。
列の下のセルをクリックすると、SPSS Statisticsは、あなたのカテゴリがすでに入力されたドロップダウンオプションを提供することに気づくでしょう。 ダミー変数とダミーコーディングの基本原理を説明する、ダミー変数とダミーコーディングを理解する。 しかし、すでにダミー変数とダミーコーディングの基本に精通している場合は、このセクションをスキップして、ダミー変数を作成するために使用されるSPSS Statisticsのダミー変数の作成手順を設定した手順のセクションに直接行くことができます。
SPSS Statistics
Understanding dummy variables and dummy coding
As we mentioned in the Introduction, if you are analysing your data using multiple regression and any of your independent variables were measured on a nominal or ordinal scale, you need to know how to create dummy variables and interpret their results.Why did you want to have been upgraded upgraded upgraded data. これは、カテゴリ独立変数(すなわち、名義および順序独立変数)は、重回帰に直接入力することができないからです。 代わりに、それらはダミー変数に変換される必要があります。 ただし、順序独立変数は連続独立変数として重回帰に入力され、ダミー変数に変換する必要はない。 以下の節で説明する。 (a) 作成する必要のあるダミー変数の数、(b) ダミー変数の作成方法とダミーコーディングについて説明します。 一般的なルールとして、カテゴリ独立変数のカテゴリの数より1つ少ないダミー変数を作成します。 例えば、3つのカテゴリを持つカテゴリカル独立変数がある場合(例えば、favorite_sport。 “swimming”, “cycling” and “running”), 2つのダミー変数を作成して、参照カテゴリとして機能する1つのカテゴリを選択します(例: “swimming” と “cycling” がダミー変数になり、 “running” が参照カテゴリになります)。 カテゴリ独立変数のいくつかの例と、作成する必要があるダミー変数の数を示す次の表の後で、参照カテゴリについてより詳しく説明します。
| カテゴリ独立変数の名前 | 変数のタイプ | カテゴリの数 | ダミー変数の数 ダミー変数 | ||||
|---|---|---|---|---|---|---|---|
| 1 | Gender | Nominal | Two (Males & Females) |
One=Males “Females”(男)。 は参照カテゴリ |
|||
| 2 | 身長 | 順 | 2 (180cm未満 & 180cm以上) |
One=Under(以下)。 180cm 「180cm以上」は参考区分 |
|||
| 3 | 名 | Two=African American & Caucasian “Hispanic” is reference category |
|||||
| 4 | 身体活動レベル | 3 (Low, Moderate & High) |
Two=Low & Moderate 「高」は基準カテゴリー |
||||
| 5 | 職業 | Four (Surgeon.Of.Or.No, セラピスト) |
3=外科医、医師 & 看護師 「セラピスト」は参照カテゴリ |
||||
| 6 | 同意レベル | 4 (非常に同意、同意する。 同意しない、強く同意しない) |
スリー=強く同意する、同意する & 同意しない 「強く同意しない」は参照カテゴリ |
||||
| 7 | 対象分野 | 名目(ビジネス学.etc) | 5 (ビジネス学, 心理学、生物科学、工学&法学) |
フォー=ビジネス学、心理学、生物科学&工学 「法学」は参考区分 |
|||
| 8 | 年齢 | 序列 | ファイブ (18歳未満。 19-30, 31-40, 41-50, 51-60) |
Four=Under 18, 19-30, 31-40 & 41-50 “51-60” is reference category |
|||
| Table: カテゴリ独立変数とそれぞれのダミー変数の例 | |||||||
上の表にあるように、カテゴリ独立変数のカテゴリ数より1つ少ないダミー変数を作成すればよいことになります。 これは、カテゴリ独立変数があるときだけ、この数のダミー変数を重回帰に移す必要がある(べき)だからです。 しかし、カテゴリカル独立変数のすべてのカテゴリについてダミー変数を作成する正当な理由があります。 (a)より柔軟で、(b)多重比較を行うことができる(下記の注を参照)。 言い換えれば、もしカテゴリ独立変数に3つのカテゴリがあれば、2つだけでなく3つのダミー変数を作成します。
幸い、SPSS Statistics バージョン22以上のダミー変数の作成手順は、自動的にカテゴリ独立変数のすべてのカテゴリについてダミー変数を作成します。 ただし、SPSS Statistics バージョン 21 以前の Recode into Different Variables の手順では、この限りではありません。 したがって、通常の状況では、バージョン21以前またはバージョン22以上かどうかに応じて、SPSS Statisticsで次の設定を作成することになります。
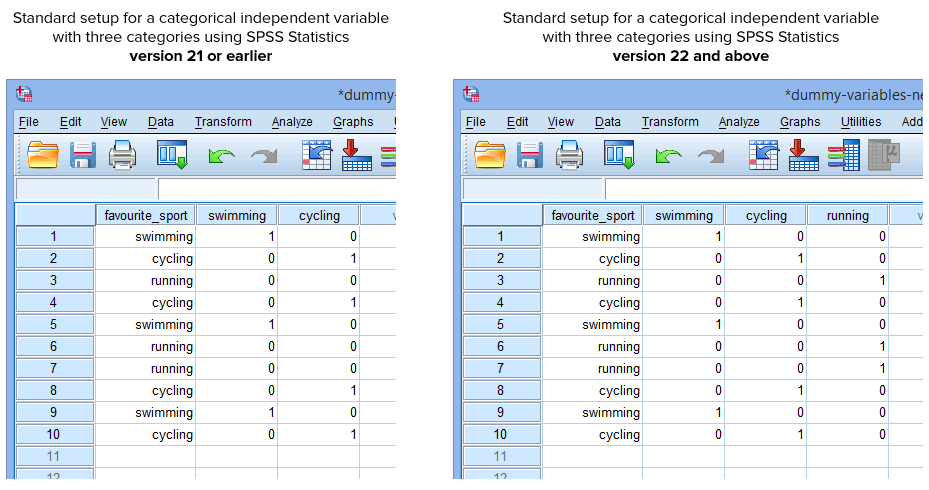
Published with written permission from SPSS Statistics, IBM Corporation.
Note: 上述のように、カテゴリ独立変数のすべてのカテゴリに対してダミー変数を作ることは二つの理由のために有益である。 (a) より柔軟であること、(b) 複数の比較ができることです。
より柔軟です:
カテゴリ独立変数のすべてのカテゴリに対してダミー変数を作成した場合、次に、任意のカテゴリを参照カテゴリとして考慮することができます。 この例では、「ランニング」カテゴリーを参照カテゴリーとみなし、「スイミング」と「サイクリング」を重回帰式に移したことになります。 しかし、後で参照カテゴリの選択について気が変わった場合、ダミー変数の手順を再度実行する必要があります(SPSS Statisticsバージョン22以上でない限り)。 たとえば、我々が今、「サイクリング」カテゴリーを参照カテゴリーとして考慮したいと仮定しよう。 ランニング」ダミー変数もあるので、「水泳」と「ランニング」ダミー変数を重回帰式に移すことができるようになりました。
これにより、多重比較が可能になります。
ダミー変数の係数は、そのダミー変数が表すカテゴリーと参照カテゴリーの差を表します。 例えば、「ランニング」を基準カテゴリーとした場合、「スイミング」ダミー変数の係数は、「スイミング」と「ランニング」カテゴリーの間の従属変数の差を表します。 この方法では、すべてのカテゴリの組み合わせが可能なわけではありません。 この問題は、異なる参照カテゴリーを用いることで解決することができる。 これは、カテゴリ変数のすべてのカテゴリにダミー変数があれば可能です。
ダミー変数の作成方法とダミーコーディング
重回帰でダミー変数をうまく設定するには、2つのステップがあります。 (1)カテゴリ独立変数のカテゴリを表すダミー変数を作成する、(2)カテゴリ独立変数のカテゴリを表すために、これらのダミー変数に値を入力する-ダミーコーディングとして知られている-。 このプロセスについて、上記の例を用いて説明します。 ダミー変数は、特定のコーディング・スキームのための「プレースホルダー」として機能する単なる新しい変数である。 それ自体は、いかなるデータも含まない。 代わりに、データ/値は、カテゴリ独立変数のカテゴリを表すという目的を果たすことができるように、これらのダミー変数に追加される必要があります。 ダミー変数に入力される値を決定するコーディング・スキームにはたくさんの種類がありますが、我々は、ダミー・コーディングまたは代替的にインジケータ・コーディング(N.B.、ダミー変数とダミー・コーディングは同じものではないので混乱しないでください)という非常に一般的なコーディング・スキームを使用します。 ダミー・コーディングは、以下に説明する参照カテゴリを除いて、カテゴリ独立変数の特定のカテゴリを識別するために、各ダミー変数を使用することによって動作します。 「水泳”、”サイクリング”、”ランニング “の3つのカテゴリがあります。 3つのカテゴリがあるので、カテゴリの2つを表す2つのダミー変数と、3番目のカテゴリを表す参照カテゴリが必要です。
注意: 重回帰は、カテゴリ独立変数のカテゴリ数(つまり、この例では2)より少ないダミー変数を移す必要があるということを上記の議論から覚えておいてください。 しかし、より大きな柔軟性と多重比較を行う能力のために、カテゴリ独立変数のすべてのカテゴリについてダミー変数を作成することができます。 それは、直接表現されないカテゴリーを “参照カテゴリー “として、カテゴリー的独立変数のカテゴリーの数より1つ少ないダミー変数を作成することです。 この場合、「ランニング」カテゴリのダミー変数は残らない。 この「ない」カテゴリーが参照カテゴリーであり、必要ない。 さらに、どのカテゴリーを参照カテゴリーとするかは、完全にあなたの判断です。 我々は、”ランニング “カテゴリーではなく、”水泳 “カテゴリーを参照カテゴリーとして選択することも同様に簡単にできました。 我々がそうしなかった唯一の理由は、デフォルトでSPSS Statisticsは、カテゴリ独立変数の変数ビューでコード化した最後のカテゴリを参照カテゴリとして使用することです(下記の注を参照)
注:前述のデータセットアップセクションで説明したように、そして値ラベルダイアログボックスで下記のように、我々のカテゴリ独立変数の第3の最後のカテゴリは「ランニング」(すなわち。 3=”running”)。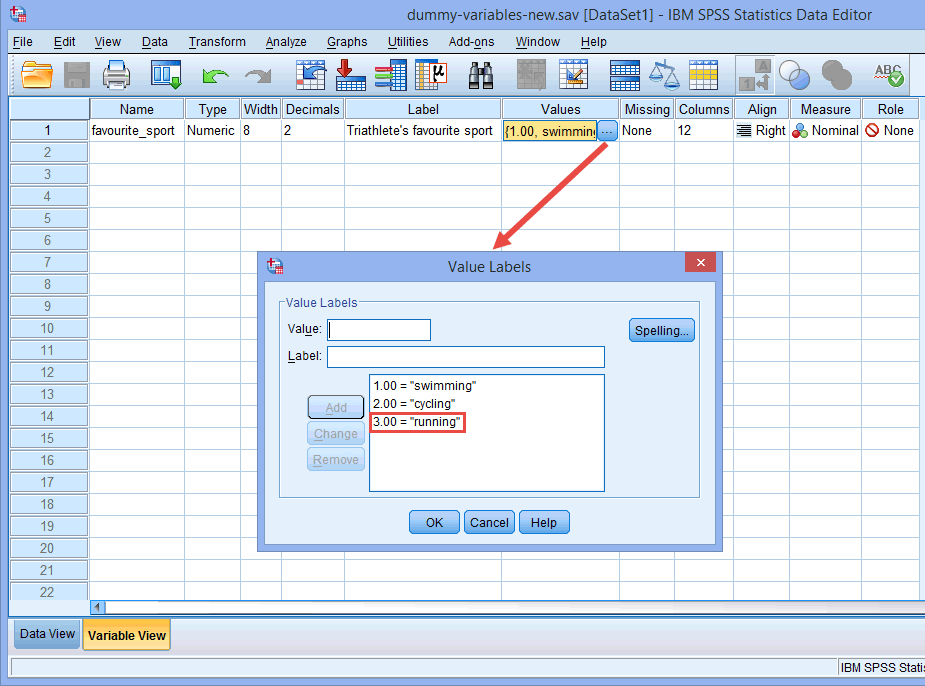
“running” カテゴリを3番目と最後のカテゴリにして、それをSPSS Statisticsのデフォルトで参照カテゴリにするという、理論的または統計的理由は何もありませんでした。 トライアスロンに参加するとき、彼らはまず泳ぎ、次に自転車をこぎ、最後に走ってゴールを目指しますから、このようにしたのです。 したがって、カテゴリ独立変数をこのようにコード化することは論理的であると思われました。 しかし、我々はそれを1=サイクリング、2=ランニング、3=水泳とコード化することができました。それは、3番目と最後のカテゴリとして、「水泳」がSPSS Statisticsのデフォルトで我々の参照カテゴリになるという事実を除いて、違いはなかったでしょう。 我々のダミー変数の各々は、我々のカテゴリ独立変数のカテゴリを表すので、各ダミー変数をそれが表すカテゴリの名前で参照することが通例です。 したがって、ダミー変数#1は、水泳のカテゴリーを表すので、”swimming “と呼びます。 同様に、ダミー変数#2は、サイクリングというカテゴリーを表すので、”cycling “と呼ぶことにする。 979>
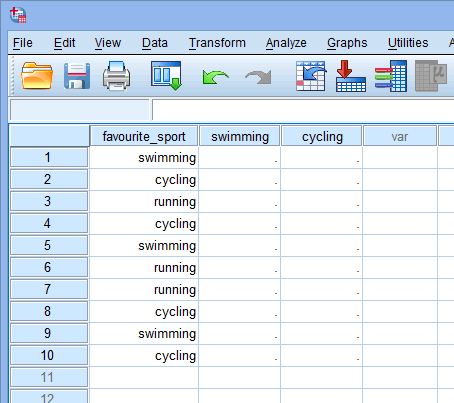
Published with written permission from SPSS Statistics, IBM Corporation.
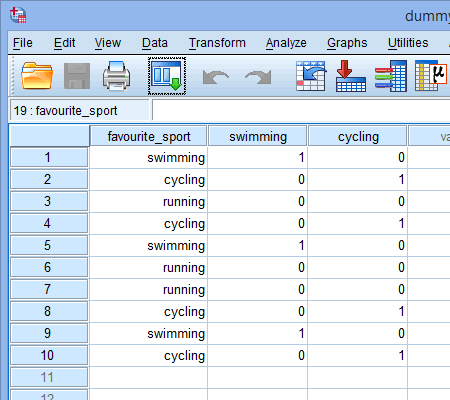
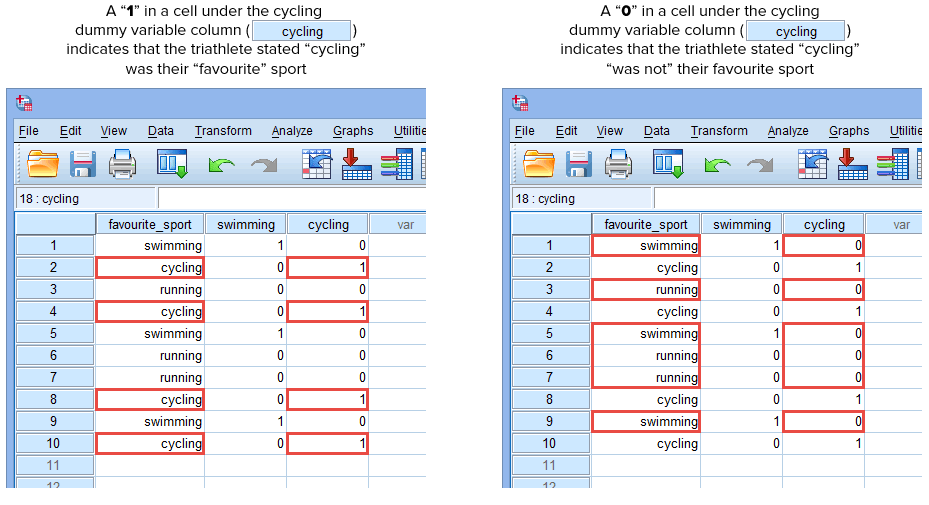
さて、二つのダミー変数を作り、適切な名前をつけたので、それぞれのダミー変数が本当にカテゴリー独立変数のそのカテゴリーを表すようにこれらの変数に値を入力しなければならない。 ダミーコーディングで、これは非常に簡単です。 あなたは、カテゴリを持つ任意のケース(たとえば、データ集合の参加者)を表すために “1 “を入力し、カテゴリを持たない場合は “0”(ゼロ)を入力します。 まず、以下に示すように「水泳」ダミー変数を考えます。
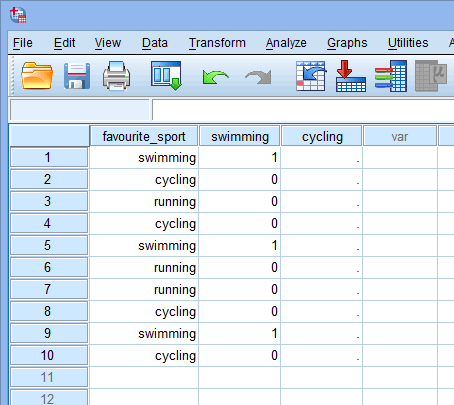
Published with written permission from SPSS Statistics, IBM Corporation.
もしトライアスリートの1人が「水泳」が自分の「好き」スポーツだと述べたなら、水泳が自分の「好き」スポーツだと述べたトライアスリートのために、水泳ダミー変数のカラム( ![]() )の下のセルへ “1” を入力することになります。 また、「サイクリング」または「ランニング」を「好きなスポーツ」とした場合は、「水泳」を「好きなスポーツではない」(「サイクリング」または「ランニング」が「好きなスポーツ」)としたトライアスリートの水泳ダミー変数のセル(
)の下のセルへ “1” を入力することになります。 また、「サイクリング」または「ランニング」を「好きなスポーツ」とした場合は、「水泳」を「好きなスポーツではない」(「サイクリング」または「ランニング」が「好きなスポーツ」)としたトライアスリートの水泳ダミー変数のセル(![]() )に “0 “を入力しています。 これは、10人のトライアスリート全員について、以下にハイライトされています:
)に “0 “を入力しています。 これは、10人のトライアスリート全員について、以下にハイライトされています:
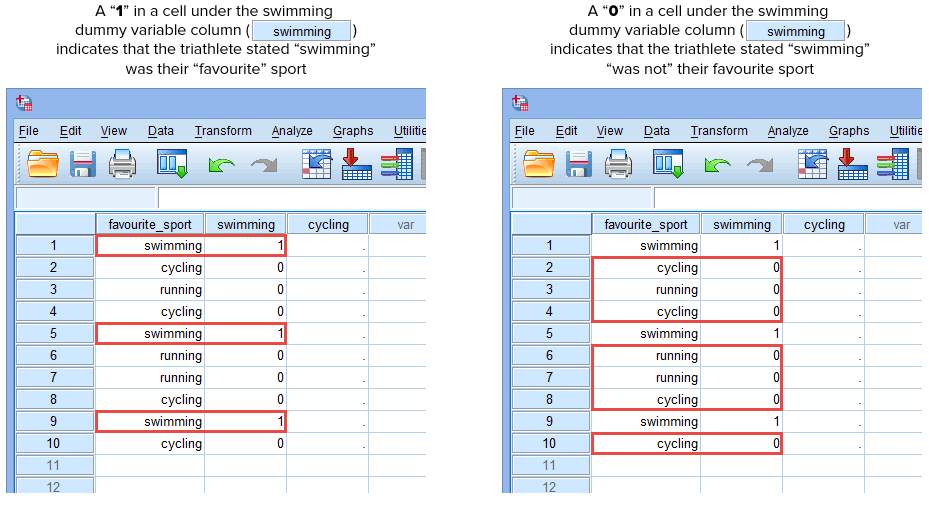
Published with written permission from SPSS Statistics, IBM Corporation.
我々は、以下に示すように他のダミー変数、「自転車」に対してこのプロセスを繰り返す:
Published with written permission from SPSS Statistics, IBM Corporation.のダミー変数、「自転車」、「ランニング」について、このプロセスを繰り返す:Published from SPSS Statistics, IBM Corporation.All of 10 triathletes.
トライアスリートの一人が「サイクリング」が「好きな」スポーツだと述べた場合、サイクリングが「好きな」スポーツだと述べたそのトライアスリートについて、サイクリングダミー変数列の下のセル(![]() )に「1」を入力します。 一方、「水泳」または「ランニング」が「好きなスポーツ」と答えたトライアスリートがいた場合、「好きなスポーツではない」(つまり、「水泳」または「ランニング」が「好きなスポーツ」)と答えたトライアスリートのサイクリングダミー変数(
)に「1」を入力します。 一方、「水泳」または「ランニング」が「好きなスポーツ」と答えたトライアスリートがいた場合、「好きなスポーツではない」(つまり、「水泳」または「ランニング」が「好きなスポーツ」)と答えたトライアスリートのサイクリングダミー変数(![]() )のセルに “0 “を入力しています。
)のセルに “0 “を入力しています。
Published with written permission from SPSS Statistics, IBM Corporation.
このようにダミー変数に「1」と「0」を入力すると、重回帰分析に入力するダミー変数のセットを作成することができます。 この後の手順編では、ダミー変数の作成手順を用いて、これらのダミー変数を作成する方法を紹介します。
SPSS Statistics
SPSS Statisticsでのダミー変数の作成手順
SPSS Statisticsには、ダミー変数の作成手順と異なる変数への再符号化の2つの手順が存在します。 このガイドでは、簡単な3ステップの手順であるダミー変数の作成手順を使用する方法を説明します。 ただし、SPSS Statisticsのバージョン22以降でなければ利用できず、バージョン26(およびSPSS Statisticsのサブスクリプション版)がSPSS Statisticsの最新バージョンとなります。 SPSS Statisticsのバージョンが不明な場合は、こちらのガイドをご覧ください。 SPSS Statistics のバージョンを識別する。 SPSS Statistics バージョン 21 またはそれ以前のバージョンを使用している場合、または重回帰分析を行うときに多重比較を行うことに興味がある場合は、以下の注意を参照してください:
注意: SPSS Statistics バージョン 21 以前を使用している場合、ダミー変数の作成手順を使用できません。 したがって、Recode into Different Variablesプロシージャは、少なくともSPSS Statisticsでダミー変数を作成することができます。 あなたはまた、SPSS Statisticsのバージョン22以降を持っている場合、ダミー変数を作成するために異なる変数にRecodeの手順を使用することができますが、それはダミー変数を作成するために専用されており、はるかに簡単かつ迅速に使用するため、このガイドではダミー変数の作成手順を設定します。 例えば、このガイドで使用される例では、ダミー変数を作成するためにわずか 3 つのステップしか必要としませんが、同じ例では異なる変数に再コード化する手順を使用して 28 ステップです。
したがって、SPSS Statistics バージョン 21 以前をお持ちの場合、Laerd Statistics のメンバーセクションのダミー変数の作成の拡張ガイドには、この 28 ステップの異なる変数への再コード化手順を実行する方法を示す専用のページが含まれています。 Laerd Statisticsに加入することで、この拡張ガイドにアクセスすることができます。
SPSS Statistics バージョン 22 以降を使用してダミー変数を作成するには、次の 3 ステップ ダミー変数の作成手順に従ってください:
- 以下に示すように、メイン メニューの変換 > ダミー変数の作成 をクリックします:

SPSS Statistics, IBM Corporation の書面による許可を受けて発行されました。
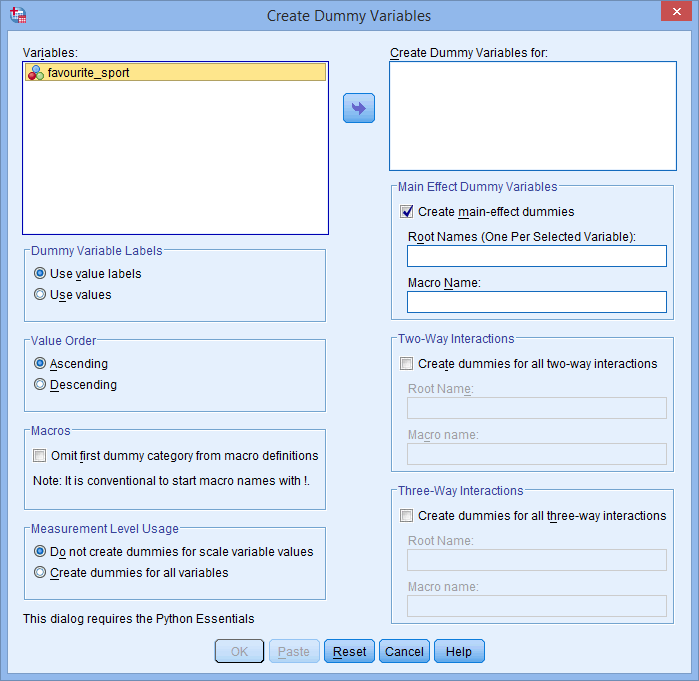
You will be presented with the Create Dummy Variables dialog box, as shown below:
Published with written permission from SPSS Statistics, IBM Corporation.
- Transfer the categorical independent variable, favourite_sport, to the Create Dummy Variables for: box by selecting it (by clicking) and then click on
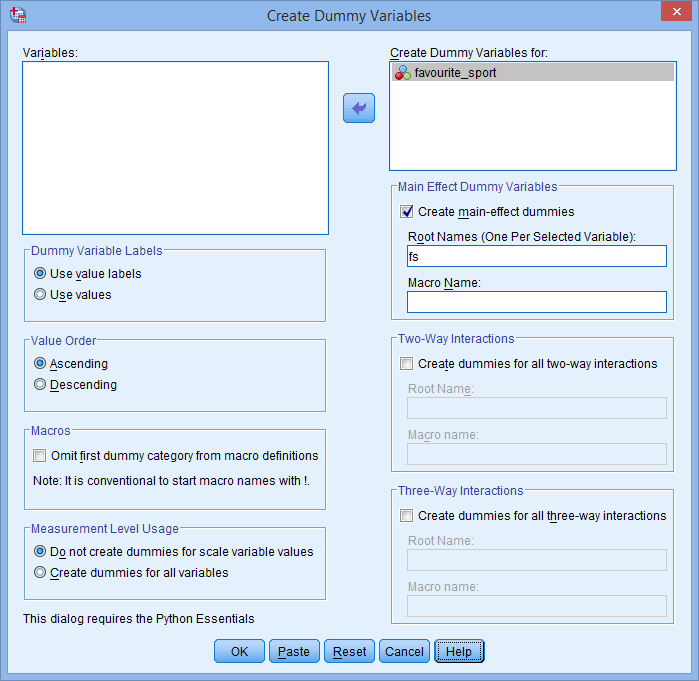
 button. また、新しいダミー変数のすべてを表すことができる「ルート」名を、-Main Effect Dummy Variables-領域のRoot Names (One Per Selected Variable): ボックスに入力する。 我々は、以下に示すように、カテゴリ独立変数「favorite_sport」の略称としてルート名「fs」を入力しました:
button. また、新しいダミー変数のすべてを表すことができる「ルート」名を、-Main Effect Dummy Variables-領域のRoot Names (One Per Selected Variable): ボックスに入力する。 我々は、以下に示すように、カテゴリ独立変数「favorite_sport」の略称としてルート名「fs」を入力しました:
Published with written permission from SPSS Statistics, IBM Corporation.
Note: SPSS Statisticsは、カテゴリ独立変数を表すために選択したルート名の最後に連続番号(すなわち1、2、3、4、等)を追加します。 作成するダミー変数ごとに連番が作成されます(例えば、2 つのダミー変数がある場合、ルート名の末尾に 1 と 2 が追加されますが、6 つのダミー変数がある場合、ルート名の末尾に 1、2、3、4、5、6 が追加されることになります)。
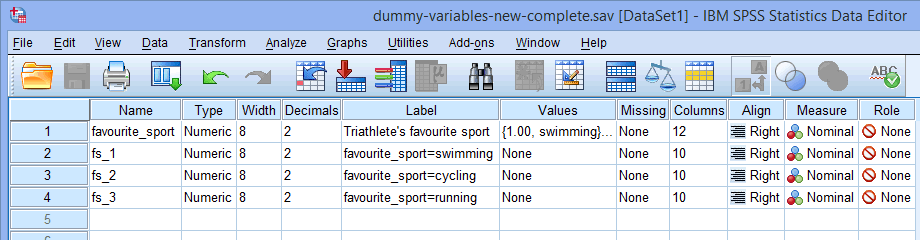
我々のカテゴリ独立変数favorite_sportは、3つのカテゴリ(すなわち、水泳、サイクリング、ランニング)を持っていたので、ダミー変数の作成プロシージャは3つのダミー変数(すなわち、水泳、サイクリング、ランニングのための1つ)を作成します。 これらの3つのダミー変数は、上記の 列で強調表示されています。 「fs_1」(水泳用)、「fs_2」(サイクリング用)、「fs_3」(ランニング用)である。 これらの名前は、後でもっと意味のあるものに変更することができます。
列で強調表示されています。 「fs_1」(水泳用)、「fs_2」(サイクリング用)、「fs_3」(ランニング用)である。 これらの名前は、後でもっと意味のあるものに変更することができます。
また、Root Names (One Per Selected Variable): ボックスに入力するルート名は、以下に示すように、カテゴリ独立変数の名前と同じにはできません(つまり、選択された変数ごとに1つ)。 ここで、ルート名「favorite_sport」を入力し、ルート名を呼ぶことができないことを説明します):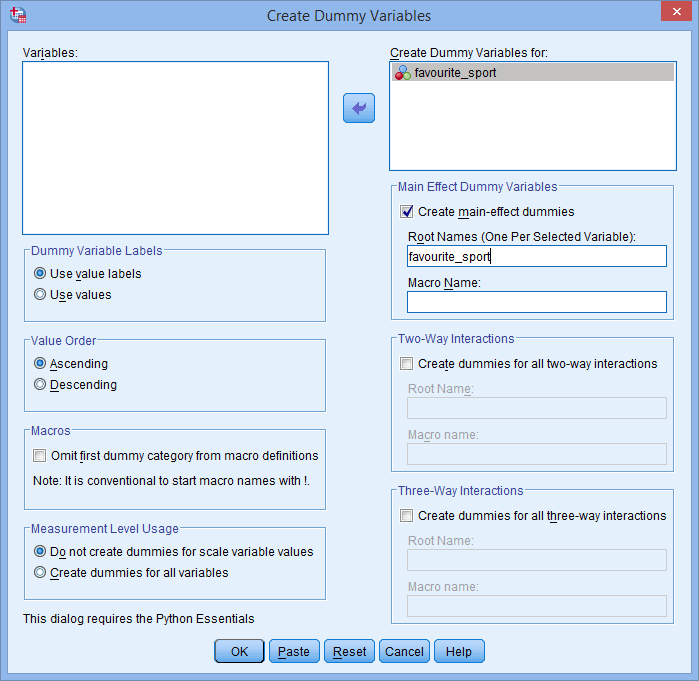
入力したルート名が、上記のようにカテゴリ独立変数の名前と同じ場合、 ボタンをクリックすると、次の警告が表示されます:
ボタンをクリックすると、次の警告が表示されます:
-
ボタンをクリックしてください。
上記の3ステップのダミー変数の作成手順を実行すると、カテゴリ独立変数用のダミー変数が作成されます。 次のセクションでは、このダミー変数の作成手順を実行した後、SPSS Statisticsの変数ビューとデータビューで作成された出力を強調表示します。
SPSS Statistics
Output and data setup in SPSS Statistics after creating dummy variables
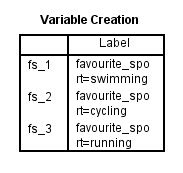
After creating your dummy variables, SPSS Statistics produce the following Variable Creation table its IBM SPSS Statistics Viewer:
IBM株式会社のSPSS Statisticsの書面による許可で公開されました。
変数作成表で、ダミー変数が正常に作成されたことを確認します。 新しいダミー変数と同じ数の行があるはずです。 今回は3つのダミー変数を作成したので、テーブルには「fs_1」「fs_2」「fs_3」の3行があり、前節のダミー変数の作成手順のステップ2で入力したルート名と連番が反映された状態になっています。 これらのダミー変数のそれぞれについて、各ダミー変数がカテゴリ独立変数のどのカテゴリを表しているかを明確にするためのラベルが、表中に記載されています。 例えば、”favorite_sport=swimming” というラベルが “fs_1” に与えられ、これは “fs_1” がカテゴリ独立変数である favourite_sport の “swimming” カテゴリ用のダミー変数であることを示しています。
次に、![]() タブでSPSS Statisticsの変数表示ウィンドウに移動してください。 以下のように3つのダミー変数が追加されます(すなわち、
タブでSPSS Statisticsの変数表示ウィンドウに移動してください。 以下のように3つのダミー変数が追加されます(すなわち、![]() 列のダミー変数「fs_1」「fs_2」「fs_3」):
列のダミー変数「fs_1」「fs_2」「fs_3」):
Published with written permission from SPSS Statistics, IBM Corporation.
Note: これが何かを明確にするために![]() 列でダミー変数の名前を変えることができます。 例えば、以下のように「fs_1」を「水泳」、「fs_2」を「サイクリング」、「fs_3」を「ランニング」に変更しました。
列でダミー変数の名前を変えることができます。 例えば、以下のように「fs_1」を「水泳」、「fs_2」を「サイクリング」、「fs_3」を「ランニング」に変更しました。
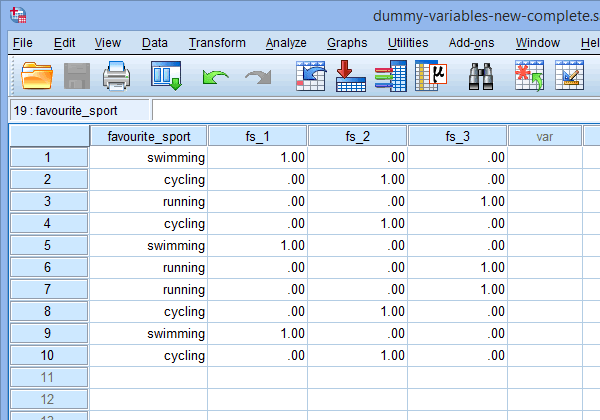
最後に、![]() タブをクリックしてSPSS統計のデータ表示ウィンドウに移動してください。 作成した各ダミー変数の下にダミーコーディングが表示される。 例えば、「fs_1」列の下の行では、「水泳」というカテゴリは「1.00」とコーディングされていますが、「サイクリング」「ランニング」というカテゴリは「.00」とコーディングされていることが、以下のようにわかります。 これらのダミー変数が、なぜこのようにダミー・コード化されるのかがわからない場合は、セクションを参照してください。 ダミー変数とダミーコーディングの理解」
タブをクリックしてSPSS統計のデータ表示ウィンドウに移動してください。 作成した各ダミー変数の下にダミーコーディングが表示される。 例えば、「fs_1」列の下の行では、「水泳」というカテゴリは「1.00」とコーディングされていますが、「サイクリング」「ランニング」というカテゴリは「.00」とコーディングされていることが、以下のようにわかります。 これらのダミー変数が、なぜこのようにダミー・コード化されるのかがわからない場合は、セクションを参照してください。 ダミー変数とダミーコーディングの理解」
Published with written permission from SPSS Statistics, IBM Corporation.
Note 1: SPSS Statisticsのデフォルト設定のため、ダミー変数はそれぞれ「1」「0」の代わりに「1.00」「.00」にコーディングされます。 これらは同一です。
注2:上記の変数表示ウィンドウの![]() 列でダミー変数の名前を変更した場合、以下のようにデータ表示ウィンドウの列でも変更されます(例えば、
列でダミー変数の名前を変更した場合、以下のようにデータ表示ウィンドウの列でも変更されます(例えば、![]() 列の見出しは現在
列の見出しは現在![]() というタイトルになっています):
というタイトルになっています): 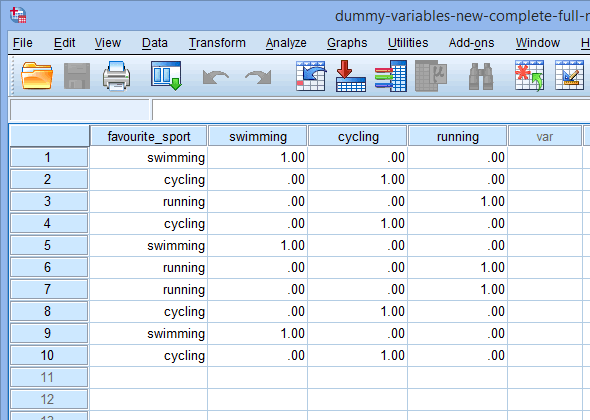
…