12月5日。 2017 – 13 min read

コンピュータ サイエンスを学ぶ旅に出る前、私には別の方向に逃げたくなるような用語やフレーズがありました。
しかし、逃げる代わりに、その知識を装いました。会話の中でうなずき、誰かが参照しているものを知っているかのように装っても、実際はまったくわからず、その超怖いコンピュータ サイエンス用語が聞こえてきたら完全に聞くのをやめてしまっていました。 このシリーズを通して、私は多くの分野をカバーすることができ、これらの用語の多くは、実際にそれほど怖くなくなりました!
しかし、しばらく避けていた大きな用語が1つあります。 今までは、この言葉を聞くたびに、麻痺したような気分になっていたのです。 ミートアップでの何気ない会話や、時にはカンファレンスの講演でも出てきたことがあります。 毎回、機械が回転し、コンピューターが解読不可能なコードの文字列を吐き出すことを思い浮かべますが、私の周りの誰もが実際に解読できるので、何が起こっているのかわからないのは実は私だけです (おっと、どうしてこうなった!?)
おそらくそう感じたのは私だけではないはずです。 でも、この言葉が実際にどんなものなのか、お話ししたほうがいいですよね? なぜなら、私が言っているのは、常にとらえどころがなく、一見混乱している抽象構文木、略して AST (abstract syntax tree) のことだからです。 長年にわたって脅かされてきましたが、ついにこの用語に対する恐怖をやめ、いったい何なのかを本当に理解できるようになり、わくわくしています。
そろそろ抽象構文木のルートと正面から向き合い、パース ゲームのレベルを上げるときです
すべての良い探求は強固な基礎から始まり、この構造を解明する私たちの使命もまったく同じように始まるはずです。 コンパイラー設計のコンテキストでは、「AST」という用語は構文木と互換的に使用されます。

構文木について(およびその構築方法)、すでによく知られている解析木と比較して考えることがよくあります。 言い換えれば、コードの「文」に現れるすべての構文情報を含み、プログラミング言語自体の文法から直接派生します。
一方、抽象構文木は、構文木が含んでいるであろうかなりの量の構文情報を無視します。
対照的に、AST はソース テキストの分析に関連する情報のみを含み、テキストを解析する際に使用されるその他の余分なコンテンツをスキップします。
この区別は、AST の「抽象度」に焦点を当てるとより意味を持つようになります。 言い換えれば、構文木は、式、文、またはテキストがどのように見えるかを正確に表していると言えます。 基本的にはテキストそのものを直訳したもので、文章を取り出し、句読点や表現、トークンに至るまで、あらゆるパーツをツリーデータ構造に変換するのです。 文章の具体的な構文がわかるので、具体的構文木(CST)とも呼ばれます。 この構造は、コードの文法的なコピーであり、トークンごとにツリー形式であるため、具体的という言葉を使用します。 抽象的な構文木は、構文木がそうであるように、式がどのように見えるかを正確に示してはくれません。

むしろ、抽象構文木は私たちが本当に気にする「重要」部分 – コード「文」に意味を与えるもの自体を示してくれるもの- を見せてくれます。 構文木は、式の重要な部分、またはソース テキストの抽象化された構文を表示します。 したがって、具象構文木と比較して、これらの構造はコードの抽象的な表現であり (ある意味では、正確さに欠ける)、まさにその名前が付いた理由でもあります。 まず、これまでに知っているコンパイル プロセスのすべてを思い出してみましょう。

例えばこんな超短くて甘いソーステキストがあったとしましょう。 5 + (1 x 12).
コンパイル プロセスで最初に行われるのはテキストのスキャンであり、スキャナーが行う仕事です。その結果、テキストは可能な限り小さな部分(字句と呼ばれる)に分割されます。 この部分は言語に関係なく、最終的にはソース テキストの一部を取り除いたものになります。
次に、これらの語彙はレキサー/トークナイザーに渡され、ソース テキストのこれらの小さな表現を言語に固有のトークンに変換します。 トークンは次のようなものになる。 . スキャナとトークン化器の共同作業により、コンパイルの字句解析が行われます。
次に、入力がトークン化されると、その結果のトークンはパーサーに渡され、パーサーはソース テキストを受け取って解析ツリーを構築します。 下の図は、トークン化されたコードが解析ツリー形式でどのように見えるかを示しています。
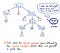
トークンを解析ツリーに変更する作業はパーシングとも呼ばれており、「構文解析フェーズ」 と呼ばれています。 構文解析フェーズは字句解析フェーズに直接依存します。したがって、コンパイラのパーサーはトークナイザーが仕事を終えてからでないと仕事ができないため、字句解析は常にコンパイル プロセスの最初に来る必要があります!
コンパイラーの各部分は、コードがテキストまたはファイルから解析ツリーに正しく変換されるように、互いに依存し合う良き友人であると考えることができます。
Condensing one tree into another
Okay, now we have two trees to keep straight in our head.その質問に答えるために、そもそも AST の必要性を理解する助けになる。 解析木はすでに持っているのに、さらに別のデータ構造を学ぶことになるとは! この AST データ構造は単純化された構文解析木に過ぎないようです。 では、なぜそれが必要なのか?
さて、私たちの解析ツリーを見てみましょう。
私たちはすでに、解析ツリーがプログラムをその最も明確な部分で表していることを知っています。
結局のところ、プログラムのすべての異なる部分が、実際には常に私たちにとってそれほど有用ではないことがあります。
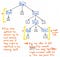
ここで、元の式である 5 + (1 x 12) を構文解析ツリーで表した図を見てみましょう。 このツリーを注意深く見ると、1 つのノードがちょうど 1 つの子を持つ例がいくつかあることがわかります。これは、1 つの子ノードしか持たないため (または 1 つの「後継」ノード)、単一後継ノードとも呼ばれます。
解析ツリーの例では、単一後継ノードは Expression または Exp の親ノードを持ち、これらは 5、1、12 などの何らかの値の単一後継を持つことになります。 しかし、ここでの Exp の親ノードは、実際には何の価値も与えていないのですね。 トークン/端末の子ノードが含まれていることはわかりますが、「expression」親ノードにはあまり関心がなく、本当に知りたいのは式が何であるかということだけです。 代わりに、私たちが本当に気になるのは、単一の子、単一の後継のノードです。 実際、このノードが重要な情報、つまり私たちにとって重要な部分、つまり数と値そのものを与えてくれるのです。 これらの親ノードが我々にとって不要であるという事実を考慮すると、この解析ツリーが一種の冗長であることは明らかです。
これらの単一サクセサーのノードはすべて、我々にとってかなり不要であり、まったく役に立ちません。 そこで、それらを取り除きましょう!
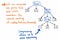
解析ツリーの単一の後継ノードが圧縮されていれば、同じ構造のより圧縮したバージョンで終了することになるでしょう。 上の図を見ると、以前とまったく同じ入れ子を維持し、ノード/トークン/終端記号がツリー内の正しい場所に表示されていることがわかります。 しかし、少しスリムにすることができました。
さらに、ツリーの一部を切り詰めることもできます。 たとえば、現時点で解析ツリーを見ると、その中にミラー構造があることがわかります。 (1 x 12) の部分式は括弧 () の中に入れ子になっており、それ自体がトークンになっています。
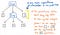
However, these parenthes does not really help us once we got in place.The tree.It can have been the past. 私たちはすでに 1 と 12 が乗算 x 演算に渡される引数であることを知っているので、この時点で括弧はそれほど多くを教えてはくれません。 実際、解析ツリーをさらに圧縮して、これらの余分なリーフ ノードを取り除くことができます。
一度、解析ツリーを圧縮して単純化し、余計な構文の「塵」を取り除くと、この時点で目に見えて異なる構造に行き着くことができます。 その構造は、実は、待望の新しい友人、抽象構文木です。

上の画像は、解析木とまったく同じ式を示しています。 5 + (1 x 12). 違いは、具体的な構文から式を抽象化したことです。 このツリーでは、括弧 () は必要ないため、それ以上表示されません。 同様に、Expのような非終端記号も見当たりません。なぜなら、私たちはすでに「式」が何であるかを理解し、私たちにとって本当に重要な値、たとえば、数字5.
を取り出すことができるのです。これはまさにASTとCSTを区別する要因なのです。 抽象構文木は、構文木が含むかなりの量の構文情報を無視し、構文解析に使用される「余分な内容」をスキップすることが分かっています。 しかし、今、それがどのように起こるかを正確に見ることができます!

自分たちの解析ツリーを凝縮したので、AST と CST とを区別するいくつかのパターンをよりうまく拾えるはずです。
- AST には、カンマ、括弧、セミコロンなどの構文の詳細は含まれません (もちろん、言語にも依存します)。
- 最後に、演算子トークン (
+,-,x,/など) は、解析ツリーで終了する葉ではなく、ツリーの内部 (親) ノードになります。
視覚的に、AST は定義上、構文の詳細を抑えた解析ツリーの圧縮バージョンであるので、常に解析ツールよりもコンパクトであると思われます。
AST が解析ツリーの圧縮バージョンである場合、最初に解析ツリーを構築するものがある場合にのみ、抽象構文木を実際に作成することができる、というのは道理にかなっていると思います。 AST は、すでに学習した構文解析ツリーに直接接続し、同時に、AST が作成される前にレキサーにその仕事をさせるよう依存しています。
![]()
AST は常にパーサの出力です。 抽象構文木は構文解析段階の最終結果で作成されます。 構文解析の主な「登場人物」として前面に出てくるパーサーは、常に解析ツリーまたは CST を生成する場合もありますし、そうでない場合もあります。 コンパイラ自身やその設計によっては、パーサが直接、構文木(AST)の構築に取りかかることもあります。 しかし、パーサーは、間に解析ツリーを作成するかどうか、または作成するために何回パスを実行する必要があるかに関係なく、常に AST を出力として生成することになります。 AST の構築方法に関する興味深い側面は、このツリーのノードに関係しています。
以下の画像は、抽象構文木における 1 つのノードの解剖学的構造を例示しています。
このノードは、いくつかのデータ (
tokenとそのvalue) を含んでいるという点で、以前に見た他のノードと似ていることに気がつくでしょう。 しかし、このノードには非常に特殊なポインタも含まれています。たとえば、
5 + (1 x 12)の単純な式は、以下のような AST の視覚化された図に構築することができます。この AST の読み取り、走査、または「解釈」は、ツリーの最下層から始まり、最終的に値または戻り値
resultを構築するために戻って作業するかもしれないと想像することができます。 さまざまなツールを活用し、既存のパーサーを使用して、式をパーサーで実行したときにどのように見えるかの簡単な例を確認することができます。 以下は、ソース テキスト5 + (1 * 12)を ECMAScript パーサーである Esprima で実行した例と、その結果の抽象構文木、およびその個別のトークンのリストです。1と12を含む値は、親操作である*のleftとrightの子であることに気づくだろう。 また、乗算演算(*)は式全体の右サブツリーを構成しており、そのためより大きなBinaryExpressionオブジェクトの中でキー"right"の下にネストされていることがわかる。 同様に、5の値はより大きなBinaryExpressionオブジェクトの単一の"left"子である。
![]()
AST を構築すると、時には複雑になることがあります。 抽象構文木の最も興味深い側面は、しかし、それらが非常にコンパクトでクリーンであるにもかかわらず、常に簡単に構築しようとするデータ構造ではないという事実です。 実際、AST の構築は、パーサーが扱う言語によってはかなり複雑になることがあります。
ほとんどのパーサーは通常、解析ツリー (CST) を構築してから、AST 形式に変換します。 パーサーが解析対象の言語の文法を知っていれば、CST を構築するのは実際にはとても簡単です。 トークンが「重要」かどうかを判断するような複雑な作業を行う必要はなく、見たものを見たままの順序で正確に受け取り、それをすべてツリーに吐き出すだけです。


コンパイラー設計において、AST は複数の理由で超重要となります。 たしかに、AST は構築するのが難しい (そして、おそらく簡単に失敗する) かもしれませんが、それだけでなく、字句解析と構文解析の段階を合わせた最後にして最後の結果なのです! 字句解析と構文解析のフェーズは、しばしば共同で解析フェーズ、またはコンパイラのフロントエンドと呼ばれます。

抽象構文木はコンパイラのフロントエンドにおける「最終プロジェクト」と考えてもよいでしょう。 これは、フロントエンドが自分自身を示す最後のものであるため、最も重要な部分です。 これは、最終的にコンパイラーがソース テキストを表現するために使用するデータ構造になるため、専門用語では中間コード表現または IR と呼ばれます。 しかし、これを少し理解したことで、この恐ろしい構造に対する認識を改め始めることができます。 7863>
Resources
そこには、さまざまな言語の AST に関するリソースがたくさんあります。 どこから始めればよいかを知ることは、特にもっと学びたい場合には、難しいことです。 以下は、初心者に優しいリソースで、あまり威圧的にならずに、より詳細に掘り下げています。 Happy asbtracting!
- The AST vs the Parse Tree, Charles N. Fischer 教授
- Parse Tree と abstract syntax tree の違いは何ですか? StackOverflow
- Abstract vs. Concrete Syntax Trees, Eli Bendersky
- Abstract Syntax Trees, Stephen A. Edwards教授
- Abstract Syntax Trees & Top-Down Parsing, Konstantinos (Kostis) Sagonas教授
- Lexical and Syntax Analysis of Programming Languages, Chris Northwood
- AST Explorer, Felix Kling